 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comprehensive Survey on Deep Graph Representation Learning
Apr 11, 2023
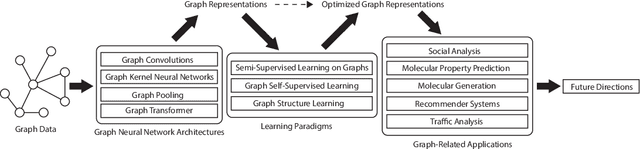
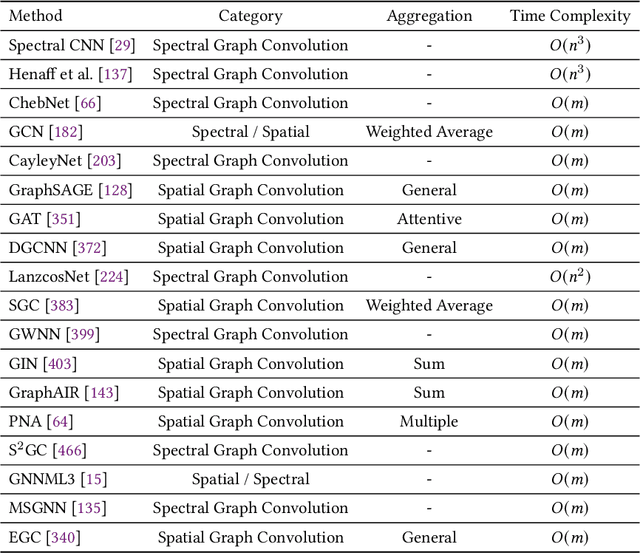
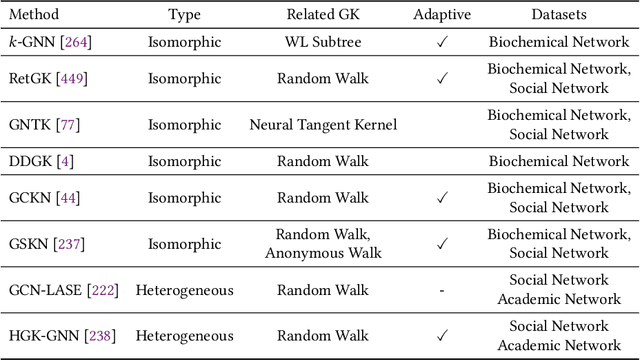
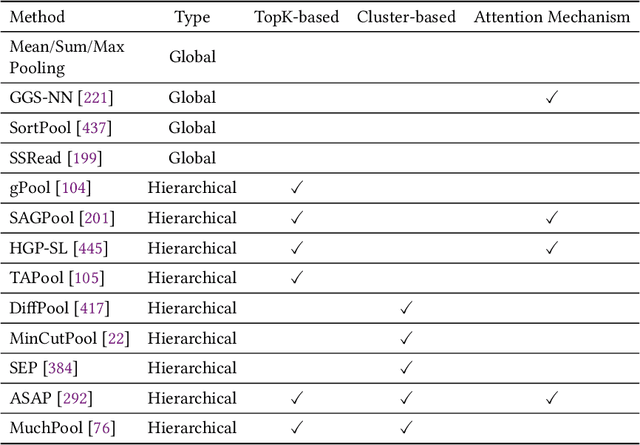
Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied in a range of fields, including machine learning and data mining. Classic graph embedding methods follow the basic idea that the embedding vectors of interconnected nodes in the graph can still maintain a relatively close distance, thereby preserving the structural information between the nodes in the graph. However, this is sub-optimal due to: (i) traditional methods have limited model capacity which limits the learning performance; (ii) existing techniques typically rely on unsupervised learning strategies and fail to couple with the latest learning paradigms; (iii) representation learning and downstream tasks are dependent on each other which should be jointly enhanced. With the remarkable success of deep learning, deep graph representation learning has shown great potential and advantages over shallow (traditional) methods, there exist a large number of deep graph representation learning techniques have been proposed in the past decade, especially graph neural networks. In this survey, we conduct a comprehensive survey on current deep graph representation learning algorithms by proposing a new taxonomy of existing state-of-the-art literature. Specifically, we systematically summarize the essential components of graph representation learning and categorize existing approaches by the ways of graph neural network architectures and the most recent advanced learning paradigms. Moreover, this survey also provides the practical and promising applications of deep graph representation learning. Last but not least, we state new perspectives and suggest challenging directions which deserve further investigations in the future.
ChatGPT Beyond English: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning
Apr 12, 2023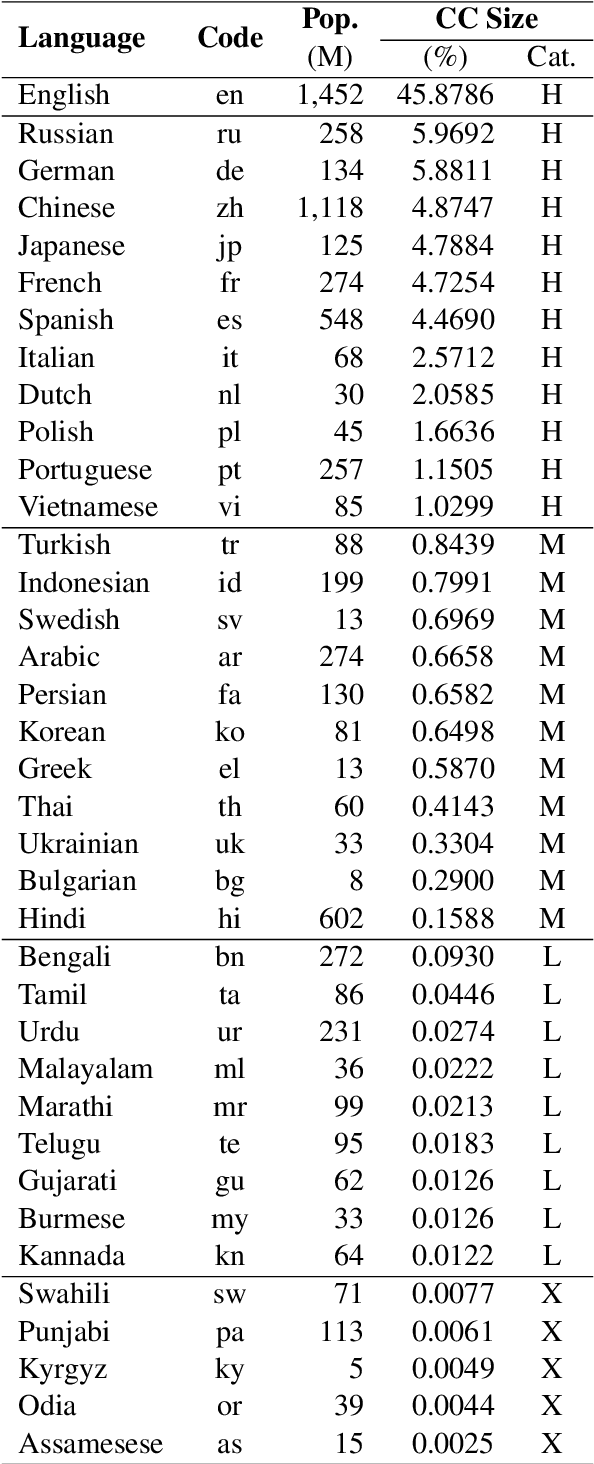
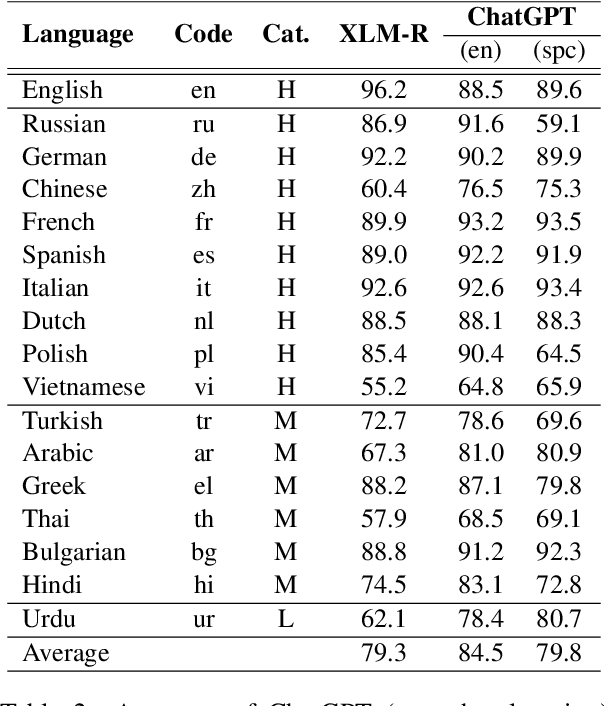
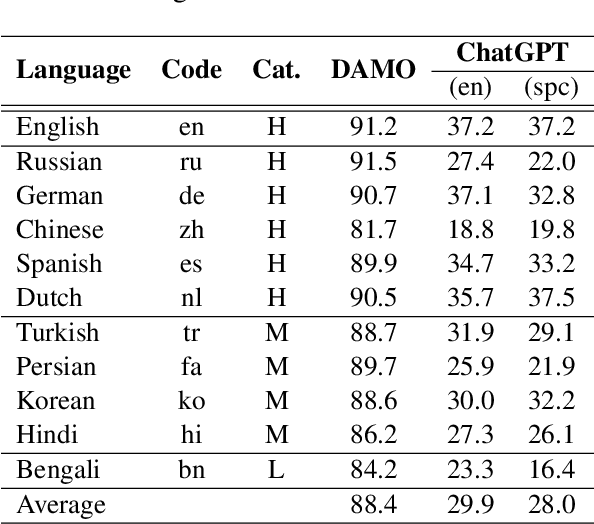
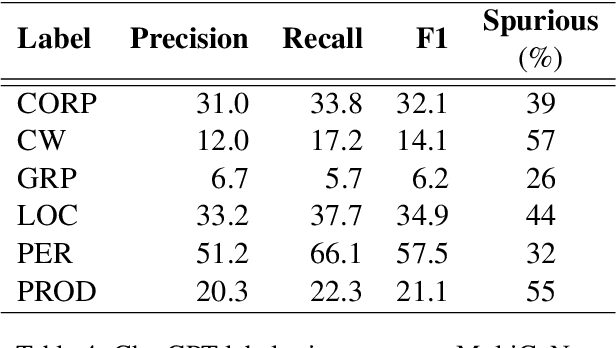
Over the last few years, large language models (LLMs) have emerged as the most important breakthroughs in natural language processing (NLP) that fundamentally transform research and developments in the field. ChatGPT represents one of the most exciting LLM systems developed recently to showcase impressive skills for language generation and highly attract public attention. Among various exciting applications discovered for ChatGPT in English, the model can process and generate texts for multiple languages due to its multilingual training data. Given the broad adoption of ChatGPT for English in different problems and areas, a natural question is whether ChatGPT can also be applied effectively for other languages or it is necessary to develop more language-specific technologies. The answer to this question requires a thorough evaluation of ChatGPT over multiple tasks with diverse languages and large datasets (i.e., beyond reported anecdotes), which is still missing or limited in current research. Our work aims to fill this gap for the evaluation of ChatGPT and similar LLMs to provide more comprehensive information for multilingual NLP applications. While this work will be an ongoing effort to include additional experiments in the future, our current paper evaluates ChatGPT on 7 different tasks, covering 37 diverse languages with high, medium, low, and extremely low resources. We also focus on the zero-shot learning setting for ChatGPT to improve reproducibility and better simulate the interactions of general users. Compared to the performance of previous models, our extensive experimental results demonstrate a worse performance of ChatGPT for different NLP tasks and languages, calling for further research to develop better models and understanding for multilingual learning.
Impact of NOMA on Age of Information: A Grant-Free Transmission Perspective
Nov 24, 2022
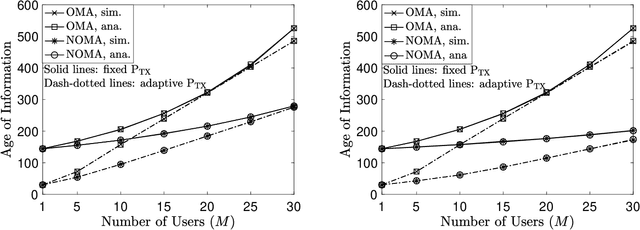
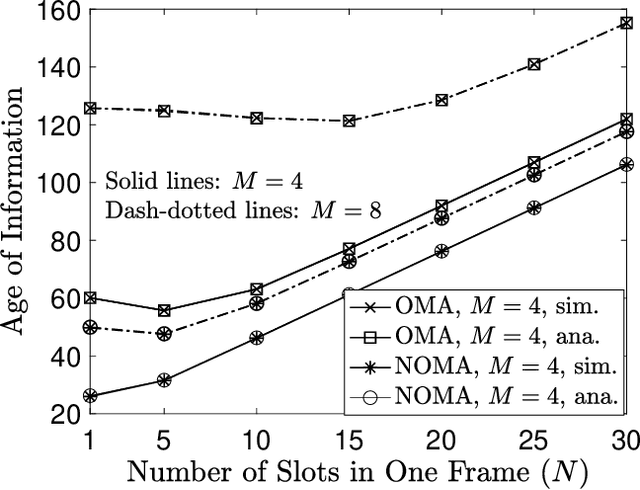
The aim of this paper is to characterize the impact of non-orthogonal multiple access (NOMA) on the age of information (AoI) of grant-free transmission. In particular, a low-complexity form of NOMA, termed NOMA-assisted random access, is applied to grant-free transmission in order to illustrate the two benefits of NOMA for AoI reduction, namely increasing channel access and reducing user collisions. Closed-form analytical expressions for the AoI achieved by NOMA assisted grant-free transmission are obtained, and asymptotic studies are carried out to demonstrate that the use of the simplest form of NOMA is already sufficient to reduce the AoI of orthogonal multiple access (OMA) by more than 40%. In addition, the developed analytical expressions are also shown to be useful for optimizing the users' transmission attempt probabilities, which are key parameters for grant-free transmission.
Neglected Free Lunch; Learning Image Classifiers Using Annotation Byproducts
Apr 04, 2023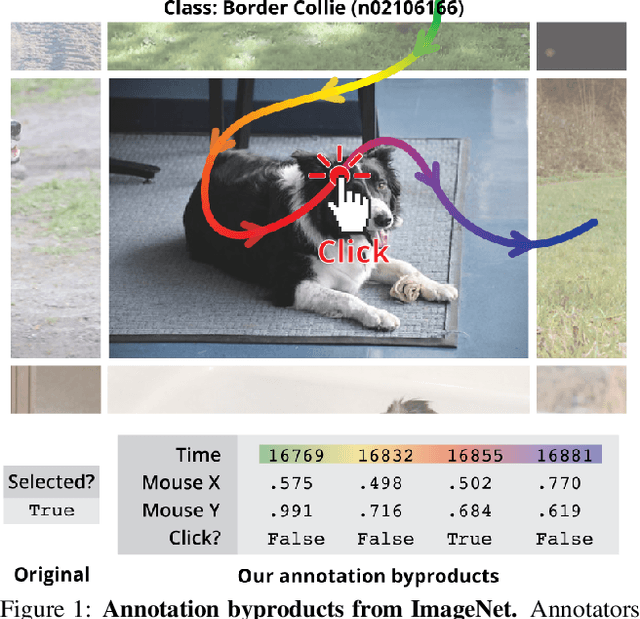
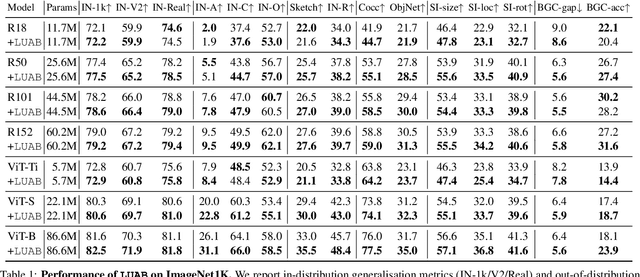
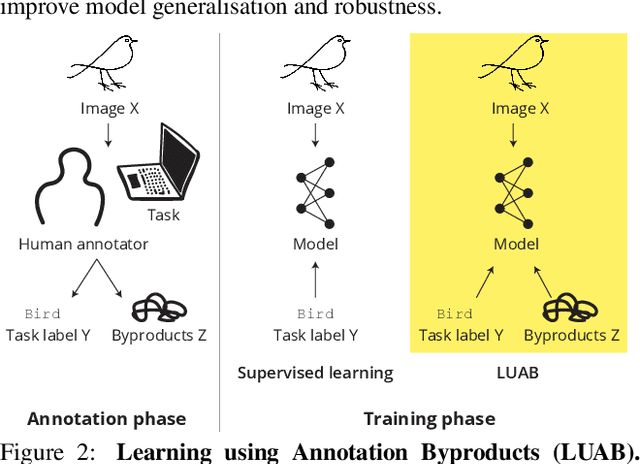
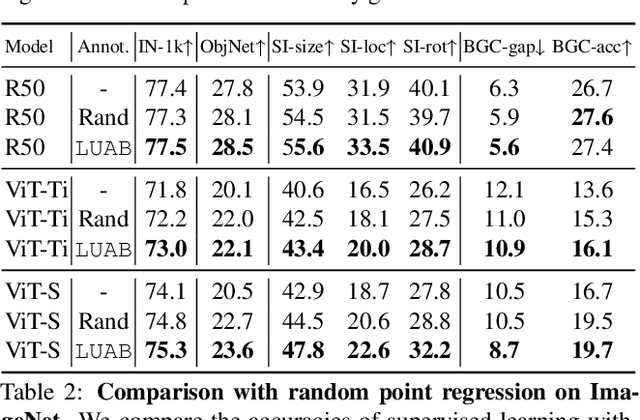
Supervised learning of image classifiers distills human knowledge into a parametric model through pairs of images and corresponding labels (X,Y). We argue that this simple and widely used representation of human knowledge neglects rich auxiliary information from the annotation procedure, such as the time-series of mouse traces and clicks left after image selection. Our insight is that such annotation byproducts Z provide approximate human attention that weakly guides the model to focus on the foreground cues, reducing spurious correlations and discouraging shortcut learning. To verify this, we create ImageNet-AB and COCO-AB. They are ImageNet and COCO training sets enriched with sample-wise annotation byproducts, collected by replicating the respective original annotation tasks. We refer to the new paradigm of training models with annotation byproducts as learning using annotation byproducts (LUAB). We show that a simple multitask loss for regressing Z together with Y already improves the generalisability and robustness of the learned models. Compared to the original supervised learning, LUAB does not require extra annotation costs. ImageNet-AB and COCO-AB are at https://github.com/naver-ai/NeglectedFreeLunch.
Joint Person Identity, Gender and Age Estimation from Hand Images using Deep Multi-Task Representation Learning
Apr 04, 2023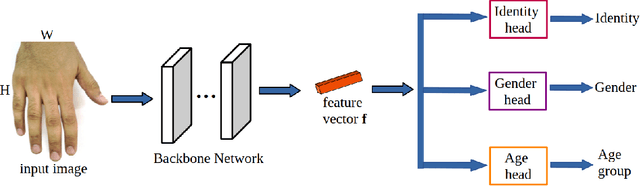
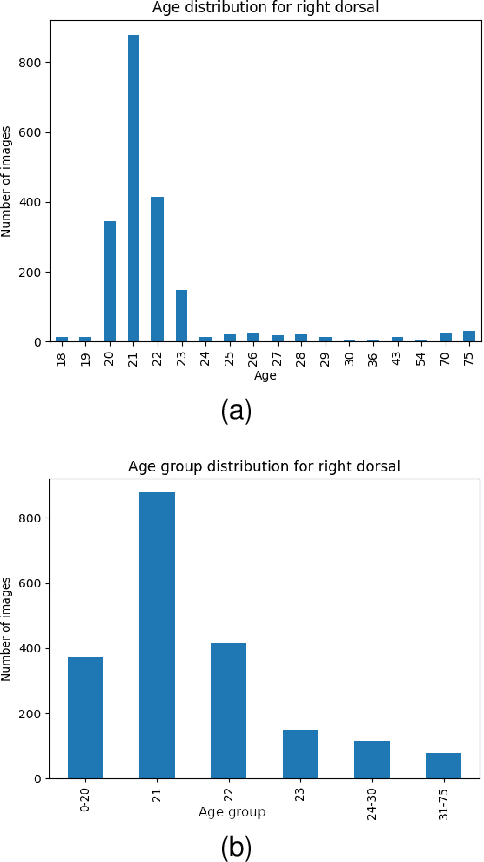
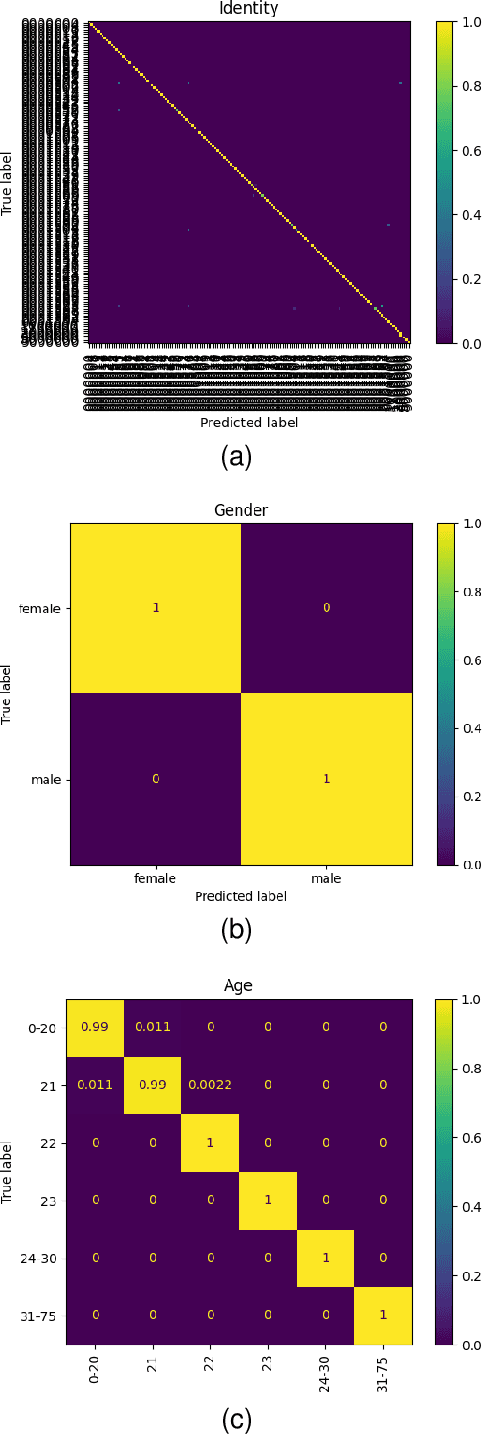
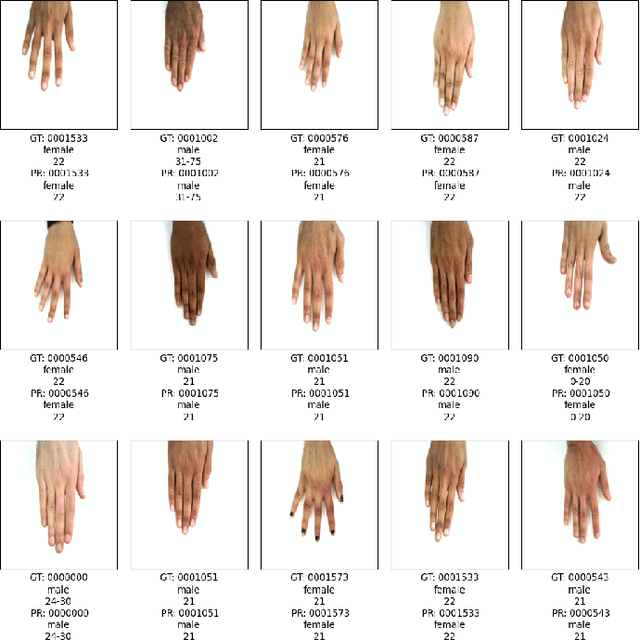
In this paper, we propose a multi-task representation learning framework to jointly estimate the identity, gender and age of individuals from their hand images for the purpose of criminal investigations since the hand images are often the only available information in cases of serious crime such as sexual abuse. We investigate different up-to-date deep learning architectures and compare their performance for joint estimation of identity, gender and age from hand images of perpetrators of serious crime. To overcome the data imbalance and simplify the age prediction, we create age groups for the age estimation. We make extensive evaluations and comparisons of both convolution-based and transformer-based deep learning architectures on a publicly available 11k hands dataset. Our experimental analysis shows that it is possible to efficiently estimate not only identity but also other attributes such as gender and age of suspects jointly from hand images for criminal investigations, which is crucial in assisting international police forces in the court to identify and convict abusers.
An interpretability framework for Similar case matching
Apr 04, 2023
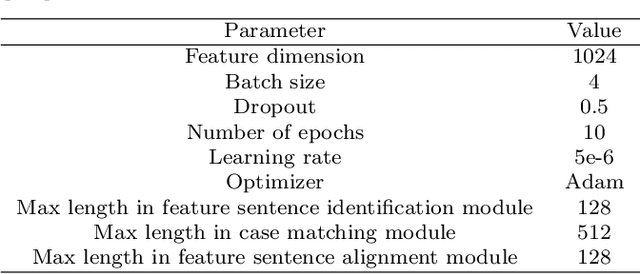
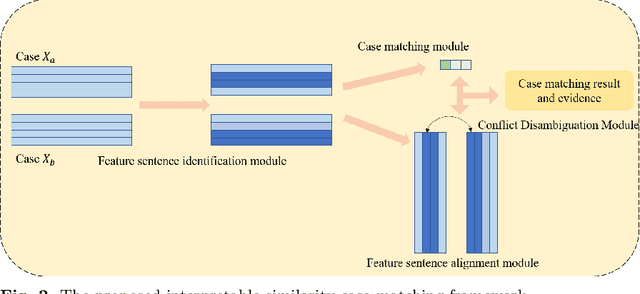
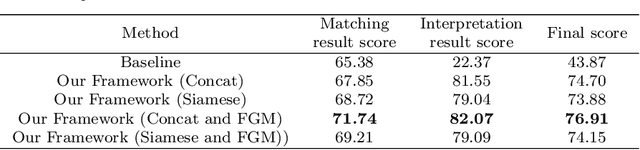
Similar Case Matching (SCM) is designed to determine whether two cases are similar. The task has an essential role in the legal system, helping legal professionals to find relevant cases quickly and thus deal with them more efficiently. Existing research has focused on improving the model's performance but not on its interpretability. Therefore, this paper proposes a pipeline framework for interpretable SCM, which consists of four modules: a judicial feature sentence identification module, a case matching module, a feature sentence alignment module, and a conflict disambiguation module. Unlike existing SCM methods, our framework will identify feature sentences in a case that contain essential information, perform similar case matching based on the extracted feature sentence results, and align the feature sentences in the two cases to provide evidence for the similarity of the cases. SCM results may conflict with feature sentence alignment results, and our framework further disambiguates against this inconsistency. The experimental results show the effectiveness of our framework, and our work provides a new benchmark for interpretable SCM.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023
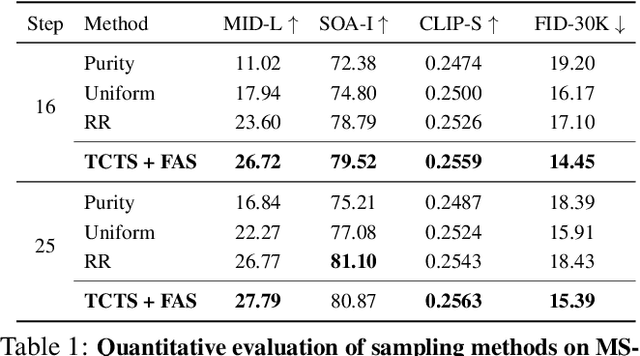

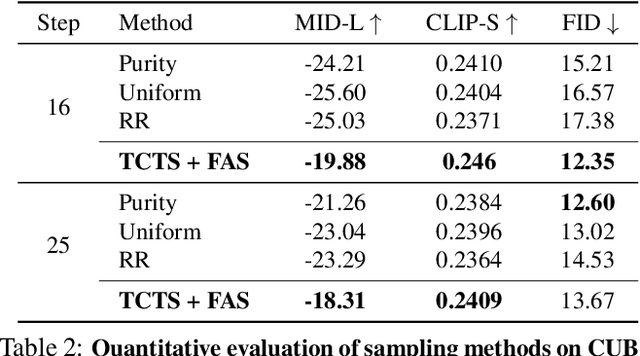
Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
Recover Triggered States: Protect Model Against Backdoor Attack in Reinforcement Learning
Apr 04, 2023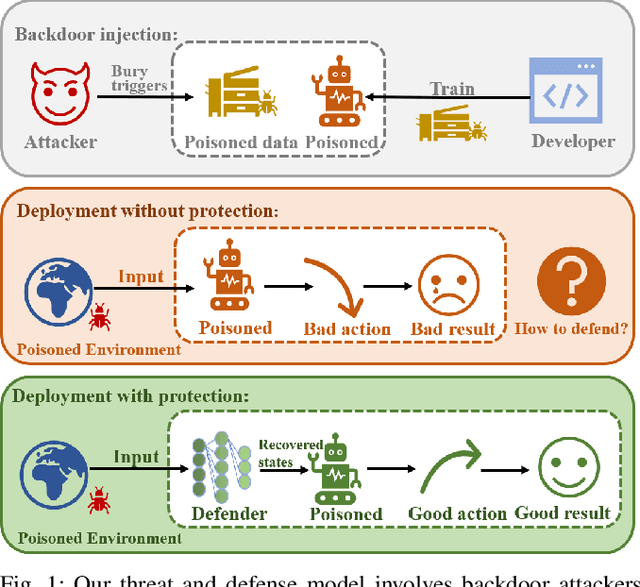
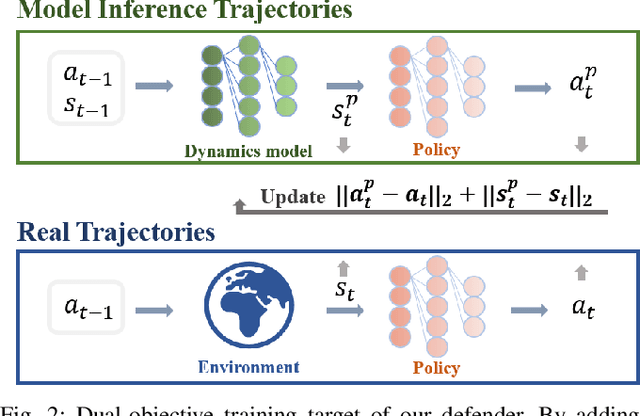
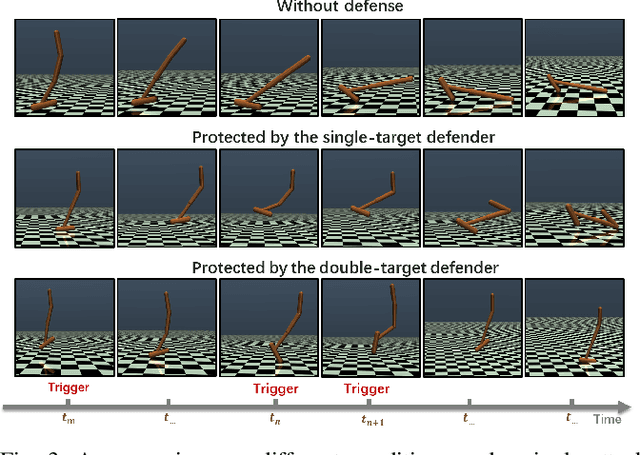
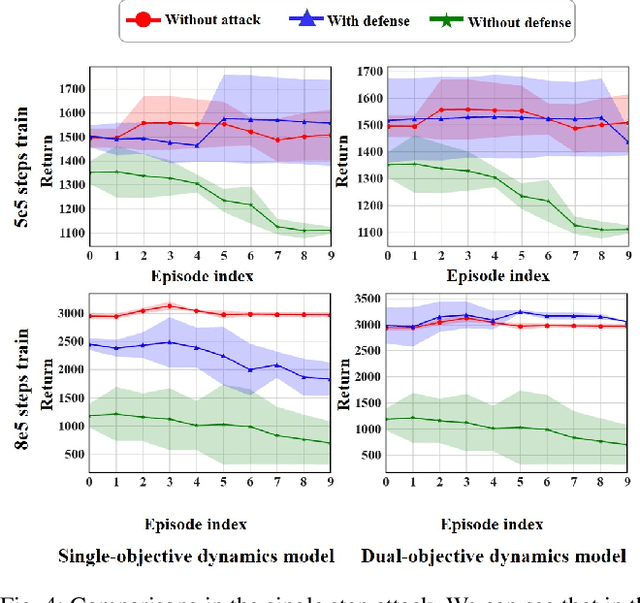
A backdoor attack allows a malicious user to manipulate the environment or corrupt the training data, thus inserting a backdoor into the trained agent. Such attacks compromise the RL system's reliability, leading to potentially catastrophic results in various key fields. In contrast, relatively limited research has investigated effective defenses against backdoor attacks in RL. This paper proposes the Recovery Triggered States (RTS) method, a novel approach that effectively protects the victim agents from backdoor attacks. RTS involves building a surrogate network to approximate the dynamics model. Developers can then recover the environment from the triggered state to a clean state, thereby preventing attackers from activating backdoors hidden in the agent by presenting the trigger. When training the surrogate to predict states, we incorporate agent action information to reduce the discrepancy between the actions taken by the agent on predicted states and the actions taken on real states. RTS is the first approach to defend against backdoor attacks in a single-agent setting. Our results show that using RTS, the cumulative reward only decreased by 1.41% under the backdoor attack.
Robustness Benchmark of Road User Trajectory Prediction Models for Automated Driving
Apr 04, 2023
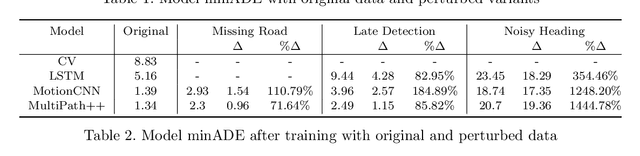
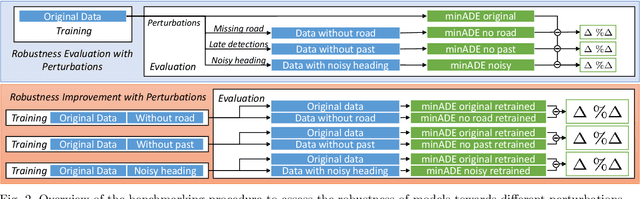

Accurate and robust trajectory predictions of road users are needed to enable safe automated driving. To do this, machine learning models are often used, which can show erratic behavior when presented with previously unseen inputs. In this work, two environment-aware models (MotionCNN and MultiPath++) and two common baselines (Constant Velocity and an LSTM) are benchmarked for robustness against various perturbations that simulate functional insufficiencies observed during model deployment in a vehicle: unavailability of road information, late detections, and noise. Results show significant performance degradation under the presence of these perturbations, with errors increasing up to +1444.8\% in commonly used trajectory prediction evaluation metrics. Training the models with similar perturbations effectively reduces performance degradation, with error increases of up to +87.5\%. We argue that despite being an effective mitigation strategy, data augmentation through perturbations during training does not guarantee robustness towards unforeseen perturbations, since identification of all possible on-road complications is unfeasible. Furthermore, degrading the inputs sometimes leads to more accurate predictions, suggesting that the models are unable to learn the true relationships between the different elements in the data.
Explaining the Performance of Collaborative Filtering Methods With Optimal Data Characteristics
Mar 17, 2023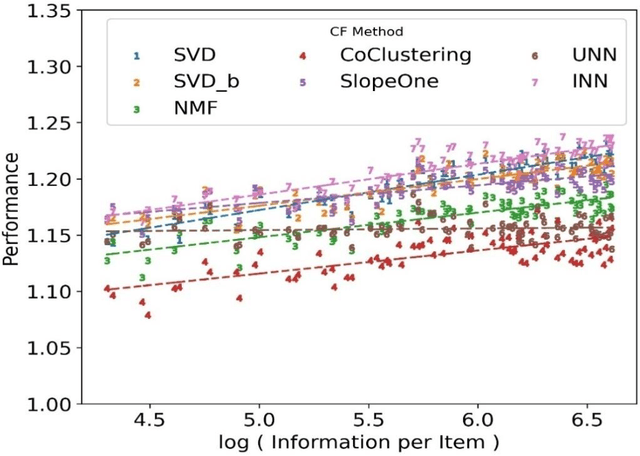
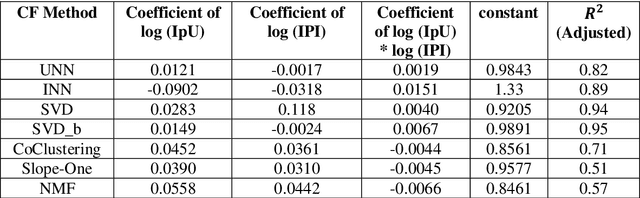
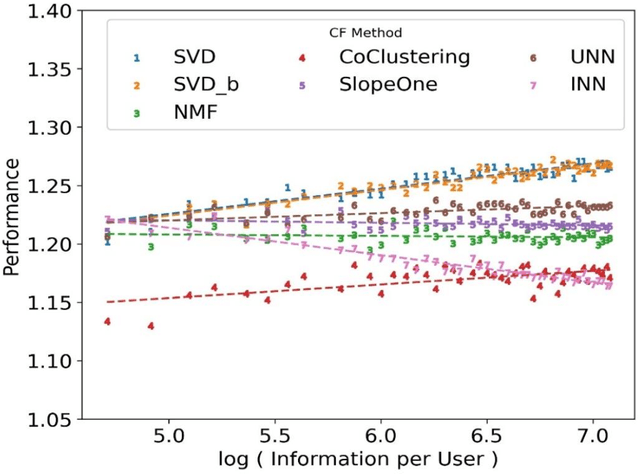
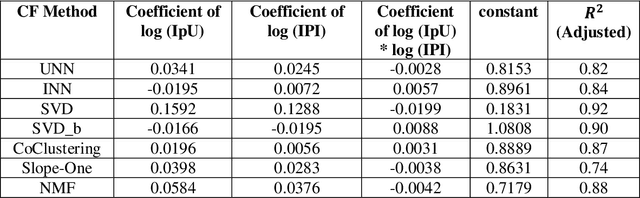
The performance of a Collaborative Filtering (CF) method is based on the properties of a User-Item Rating Matrix (URM). And the properties or Rating Data Characteristics (RDC) of a URM are constantly changing. Recent studies significantly explained the variation in the performances of CF methods resulted due to the change in URM using six or more RDC. Here, we found that the significant proportion of variation in the performances of different CF techniques can be accounted to two RDC only. The two RDC are the number of ratings per user or Information per User (IpU) and the number of ratings per item or Information per Item (IpI). And the performances of CF algorithms are quadratic to IpU (or IpI) for a square URM. The findings of this study are based on seven well-established CF methods and three popular public recommender datasets: 1M MovieLens, 25M MovieLens, and Yahoo! Music Rating datasets