 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning
Oct 09, 2022

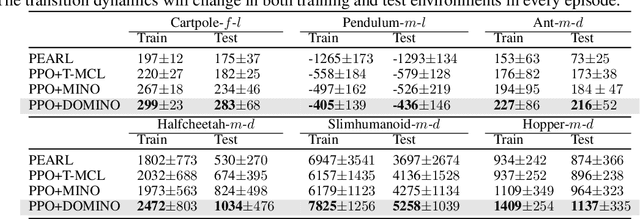
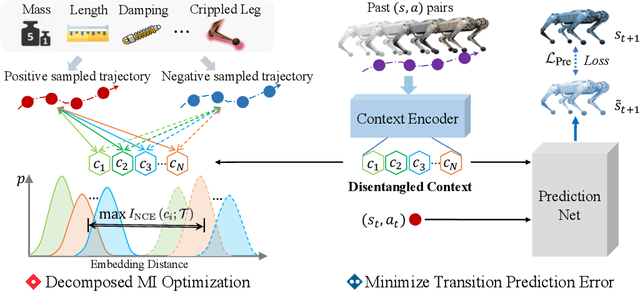
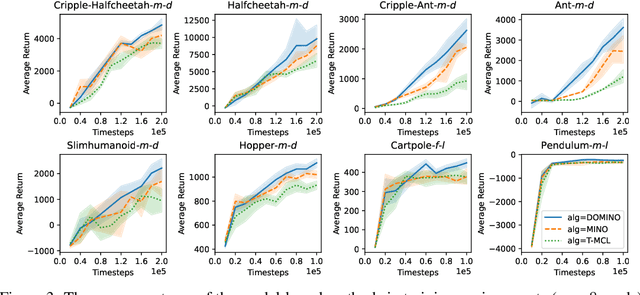
Adapting to the changes in transition dynamics is essential in robotic applications. By learning a conditional policy with a compact context, context-aware meta-reinforcement learning provides a flexible way to adjust behavior according to dynamics changes. However, in real-world applications, the agent may encounter complex dynamics changes. Multiple confounders can influence the transition dynamics, making it challenging to infer accurate context for decision-making. This paper addresses such a challenge by Decomposed Mutual INformation Optimization (DOMINO) for context learning, which explicitly learns a disentangled context to maximize the mutual information between the context and historical trajectories, while minimizing the state transition prediction error. Our theoretical analysis shows that DOMINO can overcome the underestimation of the mutual information caused by multi-confounded challenges via learning disentangled context and reduce the demand for the number of samples collected in various environments. Extensive experiments show that the context learned by DOMINO benefits both model-based and model-free reinforcement learning algorithms for dynamics generalization in terms of sample efficiency and performance in unseen environments.
Multi-Fidelity Bayesian Optimization with Unreliable Information Sources
Oct 25, 2022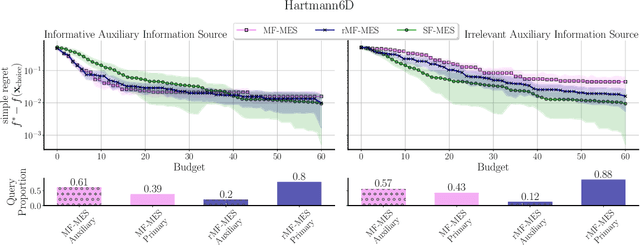

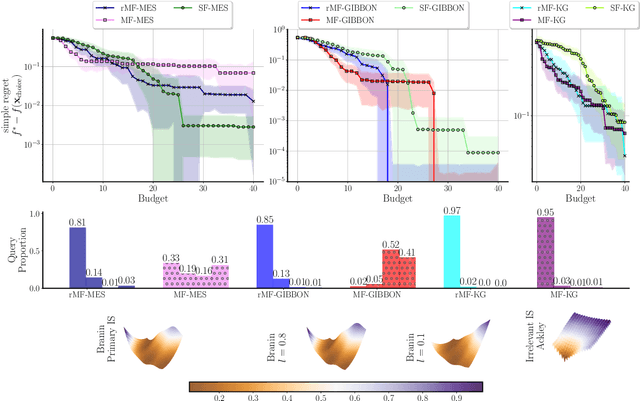
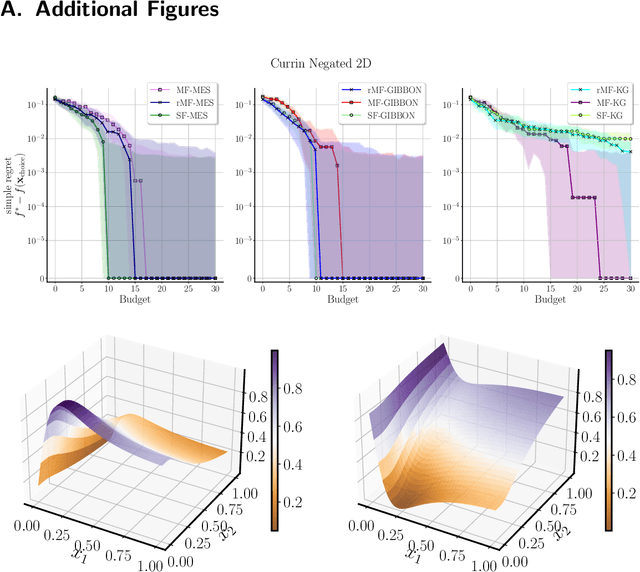
Bayesian optimization (BO) is a powerful framework for optimizing black-box, expensive-to-evaluate functions. Over the past decade, many algorithms have been proposed to integrate cheaper, lower-fidelity approximations of the objective function into the optimization process, with the goal of converging towards the global optimum at a reduced cost. This task is generally referred to as multi-fidelity Bayesian optimization (MFBO). However, MFBO algorithms can lead to higher optimization costs than their vanilla BO counterparts, especially when the low-fidelity sources are poor approximations of the objective function, therefore defeating their purpose. To address this issue, we propose rMFBO (robust MFBO), a methodology to make any GP-based MFBO scheme robust to the addition of unreliable information sources. rMFBO comes with a theoretical guarantee that its performance can be bound to its vanilla BO analog, with high controllable probability. We demonstrate the effectiveness of the proposed methodology on a number of numerical benchmarks, outperforming earlier MFBO methods on unreliable sources. We expect rMFBO to be particularly useful to reliably include human experts with varying knowledge within BO processes.
FVQA 2.0: Introducing Adversarial Samples into Fact-based Visual Question Answering
Mar 19, 2023
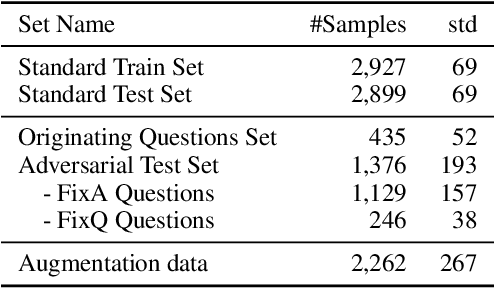
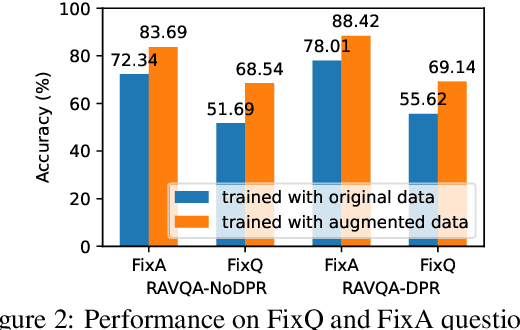

The widely used Fact-based Visual Question Answering (FVQA) dataset contains visually-grounded questions that require information retrieval using common sense knowledge graphs to answer. It has been observed that the original dataset is highly imbalanced and concentrated on a small portion of its associated knowledge graph. We introduce FVQA 2.0 which contains adversarial variants of test questions to address this imbalance. We show that systems trained with the original FVQA train sets can be vulnerable to adversarial samples and we demonstrate an augmentation scheme to reduce this vulnerability without human annotations.
Audio Visual Language Maps for Robot Navigation
Mar 13, 2023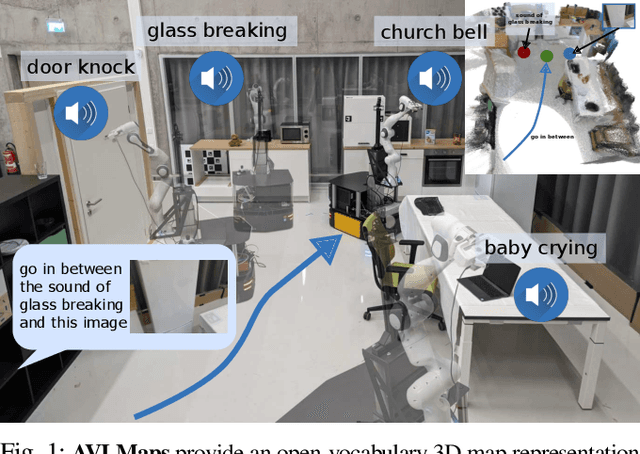
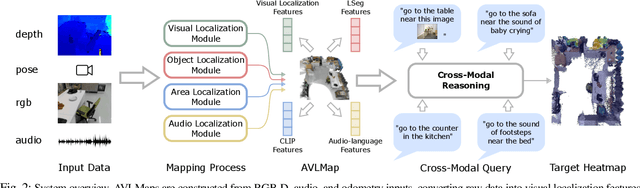
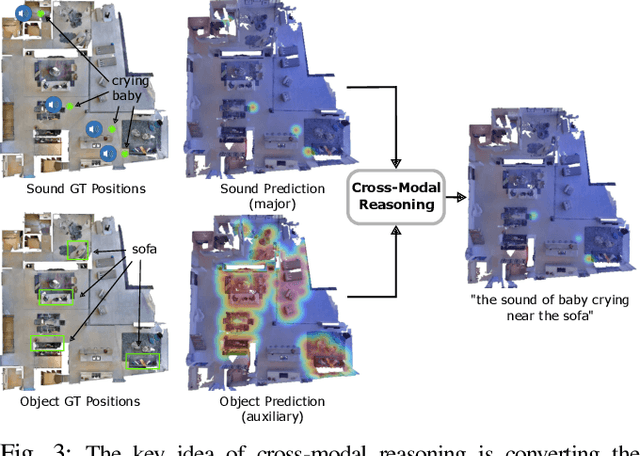

While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world - navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at: https://avlmaps.github.io.
Align and Attend: Multimodal Summarization with Dual Contrastive Losses
Mar 13, 2023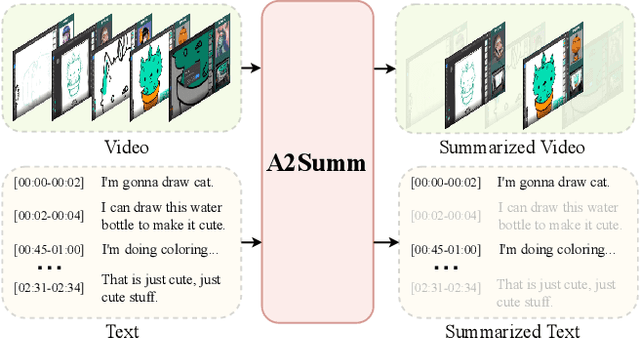
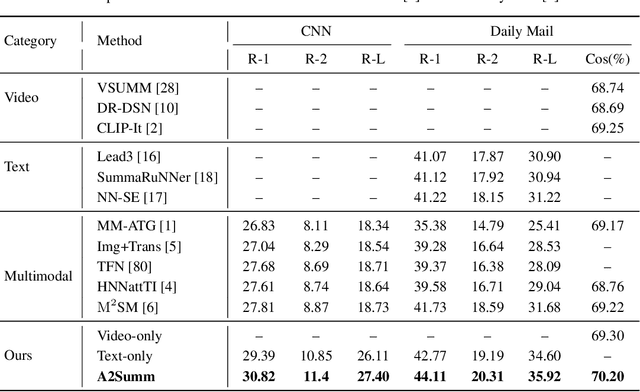
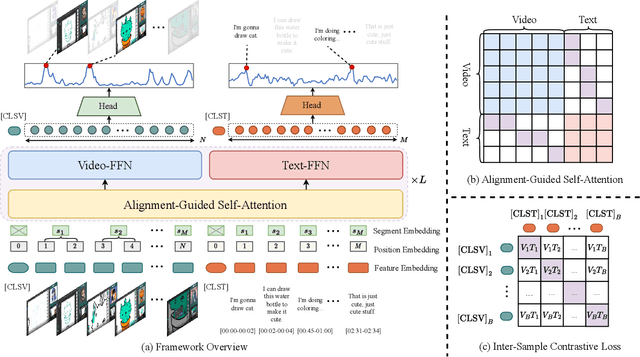

The goal of multimodal summarization is to extract the most important information from different modalities to form summaries. Unlike unimodal summarization, the multimodal summarization task explicitly leverages cross-modal information to help generate more reliable and high-quality summaries. However, existing methods fail to leverage the temporal correspondence between different modalities and ignore the intrinsic correlation between different samples. To address this issue, we introduce Align and Attend Multimodal Summarization (A2Summ), a unified multimodal transformer-based model which can effectively align and attend the multimodal input. In addition, we propose two novel contrastive losses to model both inter-sample and intra-sample correlations. Extensive experiments on two standard video summarization datasets (TVSum and SumMe) and two multimodal summarization datasets (Daily Mail and CNN) demonstrate the superiority of A2Summ, achieving state-of-the-art performances on all datasets. Moreover, we collected a large-scale multimodal summarization dataset BLiSS, which contains livestream videos and transcribed texts with annotated summaries. Our code and dataset are publicly available at ~\url{https://boheumd.github.io/A2Summ/}.
Group Testing with Side Information via Generalized Approximate Message Passing
Nov 07, 2022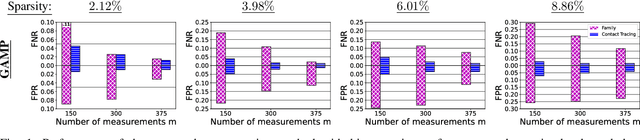
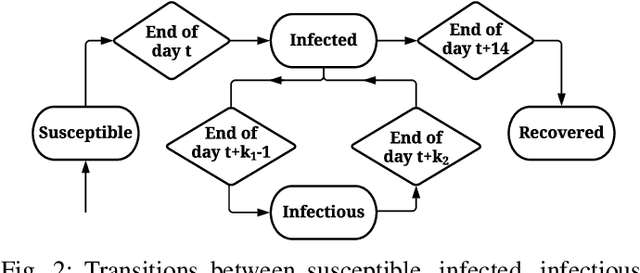
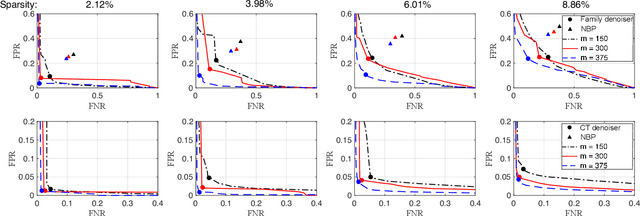
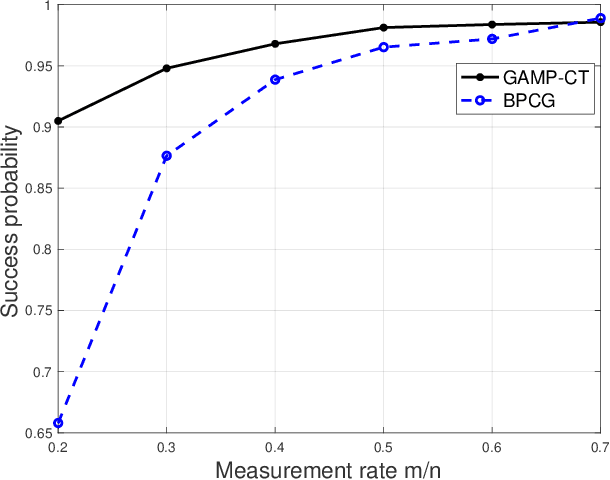
Group testing can help maintain a widespread testing program using fewer resources amid a pandemic. In a group testing setup, we are given n samples, one per individual. Each individual is either infected or uninfected. These samples are arranged into m < n pooled samples, where each pool is obtained by mixing a subset of the n individual samples. Infected individuals are then identified using a group testing algorithm. In this paper, we incorporate side information (SI) collected from contact tracing (CT) into nonadaptive/single-stage group testing algorithms. We generate different types of possible CT SI data by incorporating different possible characteristics of the spread of the disease. These data are fed into a group testing framework based on generalized approximate message passing (GAMP). Numerical results show that our GAMP-based algorithms provide improved accuracy. Compared to a loopy belief propagation algorithm, our proposed framework can increase the success probability by 0.25 for a group testing problem of n = 500 individuals with m = 100 pooled samples.
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023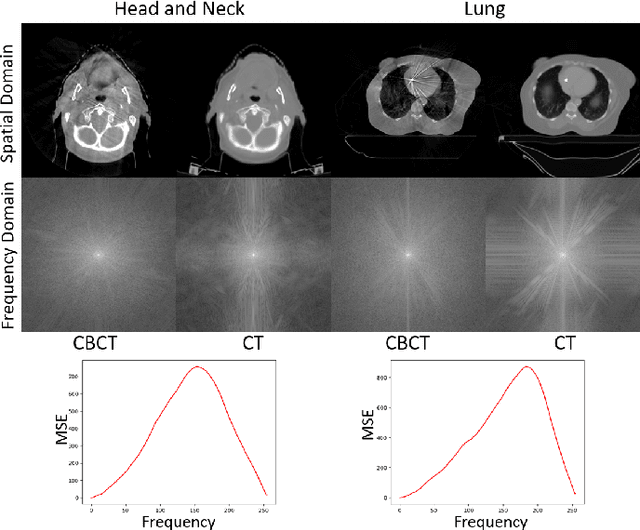

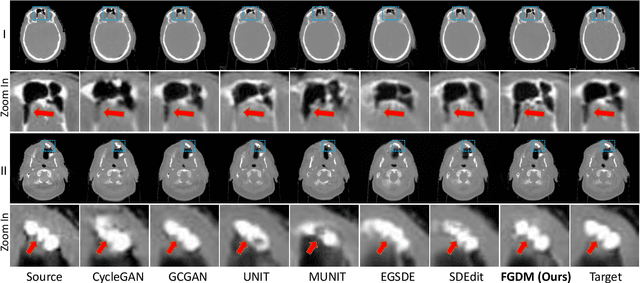
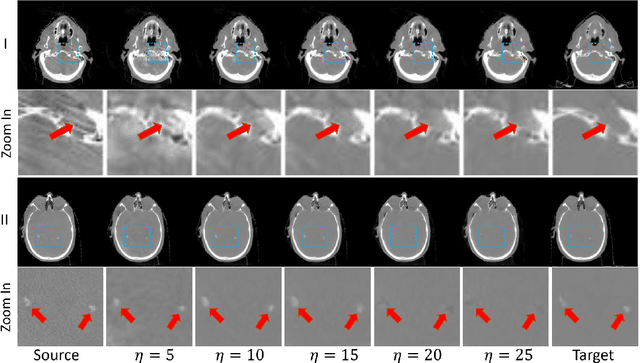
Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.
Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
Apr 05, 2023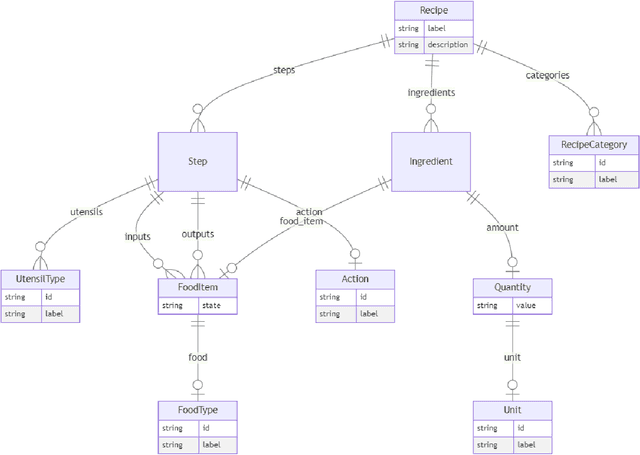
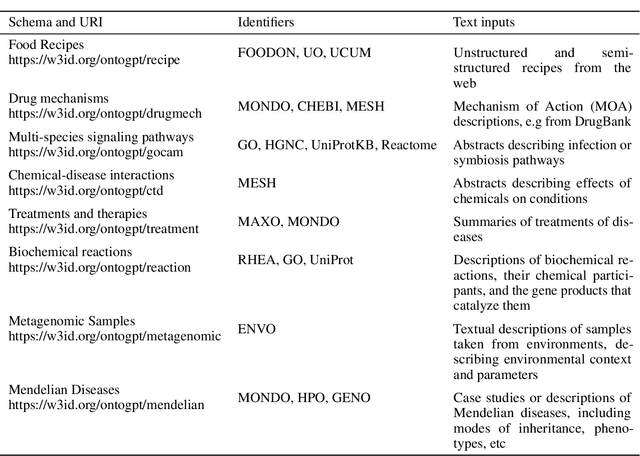
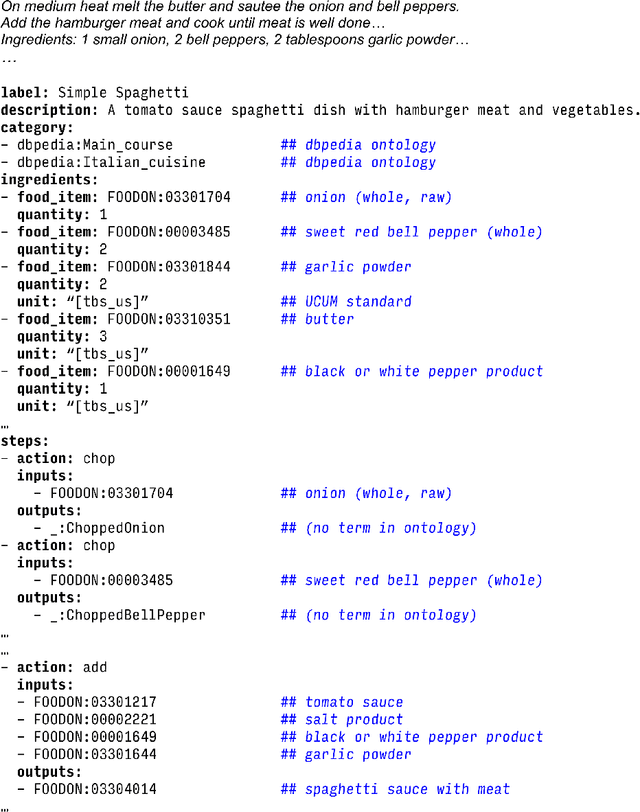

Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
Detecting and Grounding Multi-Modal Media Manipulation
Apr 05, 2023
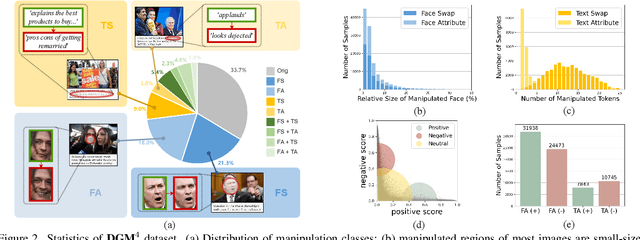
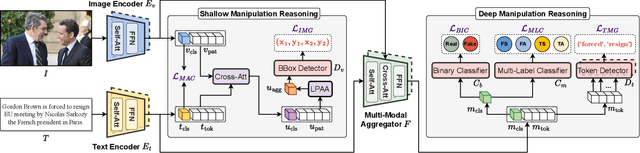

Misinformation has become a pressing issue. Fake media, in both visual and textual forms, is widespread on the web. While various deepfake detection and text fake news detection methods have been proposed, they are only designed for single-modality forgery based on binary classification, let alone analyzing and reasoning subtle forgery traces across different modalities. In this paper, we highlight a new research problem for multi-modal fake media, namely Detecting and Grounding Multi-Modal Media Manipulation (DGM^4). DGM^4 aims to not only detect the authenticity of multi-modal media, but also ground the manipulated content (i.e., image bounding boxes and text tokens), which requires deeper reasoning of multi-modal media manipulation. To support a large-scale investigation, we construct the first DGM^4 dataset, where image-text pairs are manipulated by various approaches, with rich annotation of diverse manipulations. Moreover, we propose a novel HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER) to fully capture the fine-grained interaction between different modalities. HAMMER performs 1) manipulation-aware contrastive learning between two uni-modal encoders as shallow manipulation reasoning, and 2) modality-aware cross-attention by multi-modal aggregator as deep manipulation reasoning. Dedicated manipulation detection and grounding heads are integrated from shallow to deep levels based on the interacted multi-modal information. Finally, we build an extensive benchmark and set up rigorous evaluation metrics for this new research problem. Comprehensive experiments demonstrate the superiority of our model; several valuable observations are also revealed to facilitate future research in multi-modal media manipulation.
User Manual of Automatic Data Curation Tool(ADCT): A bulk data curator software in Library and Information Science
Oct 31, 2022In library and information science, document storage and user-specific document retrieval are the main aspects of digital library services. To preserve the cultural heritage, documents, and literature, we need a common platform where all types of documents are available in a specific format. Our proposed software tool, ADCT can handle a bulk amount of data and transforms different types of raw data into specified metadata information. It generalizes multiple forms of curation logic applied to the source data. As state of the art, many research activities is done in various university to manage their research data in digital library services. The author provides descriptive statistics of library and information service (LIS) activities for information storage and retrieval. The paper shows research on methodology, information gathering, and scientific communication done on library data as an activity of the LIS community. The analysis of LIS data and the change of interest in information storage and retrieval from classification and indexing to retrieval are much important. For Building these types of digitized educational services, automatic data curation is an important stepping stone. The paper shows that automation can complement expertise and knowledge. The author builds an automated data transformation and curation tool that assists users in the analysis of metadata information and effort towards conforming to generic standards using a catalog when a librarian wants to see the adjacent related metadata for an archival collection of congressional correspondence.