 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpretable Linear Dimensionality Reduction based on Bias-Variance Analysis
Mar 26, 2023

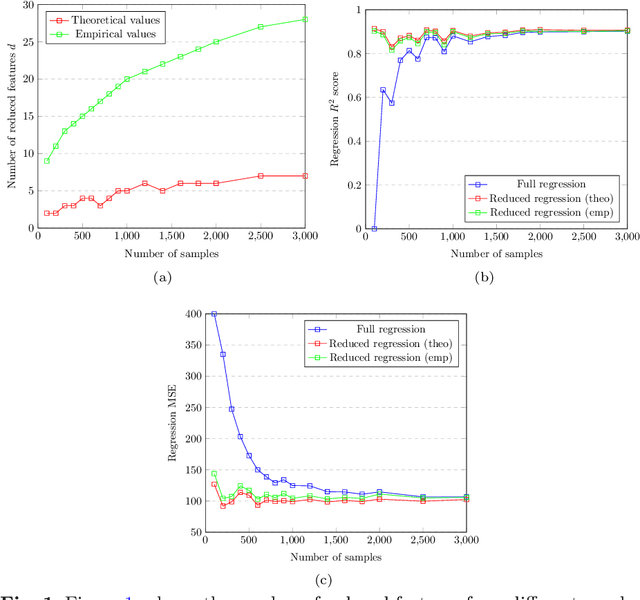
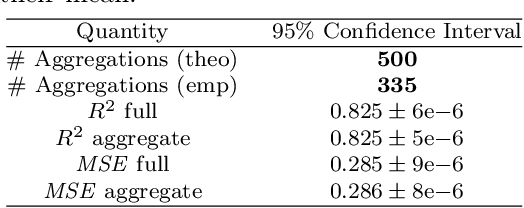
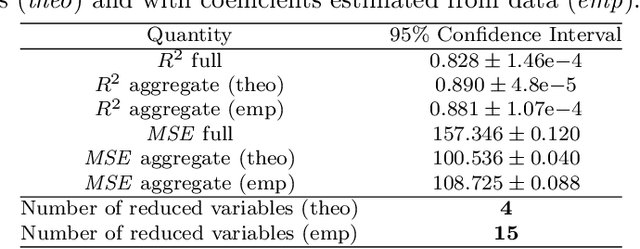
One of the central issues of several machine learning applications on real data is the choice of the input features. Ideally, the designer should select only the relevant, non-redundant features to preserve the complete information contained in the original dataset, with little collinearity among features and a smaller dimension. This procedure helps mitigate problems like overfitting and the curse of dimensionality, which arise when dealing with high-dimensional problems. On the other hand, it is not desirable to simply discard some features, since they may still contain information that can be exploited to improve results. Instead, dimensionality reduction techniques are designed to limit the number of features in a dataset by projecting them into a lower-dimensional space, possibly considering all the original features. However, the projected features resulting from the application of dimensionality reduction techniques are usually difficult to interpret. In this paper, we seek to design a principled dimensionality reduction approach that maintains the interpretability of the resulting features. Specifically, we propose a bias-variance analysis for linear models and we leverage these theoretical results to design an algorithm, Linear Correlated Features Aggregation (LinCFA), which aggregates groups of continuous features with their average if their correlation is "sufficiently large". In this way, all features are considered, the dimensionality is reduced and the interpretability is preserved. Finally, we provide numerical validations of the proposed algorithm both on synthetic datasets to confirm the theoretical results and on real datasets to show some promising applications.
Wait-info Policy: Balancing Source and Target at Information Level for Simultaneous Machine Translation
Oct 20, 2022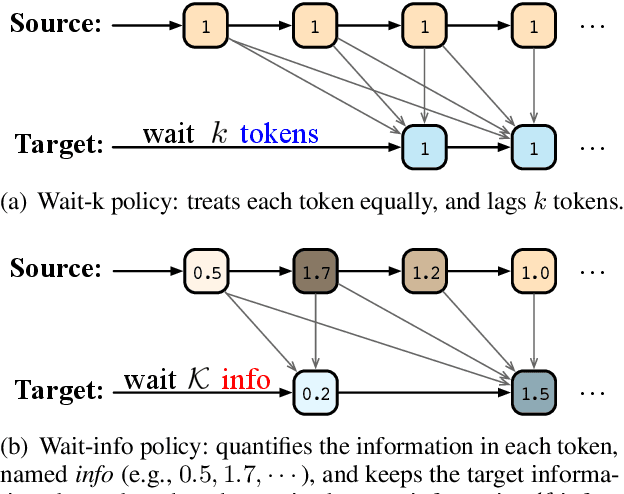
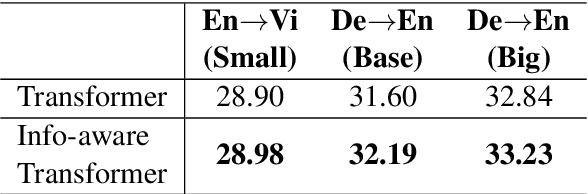
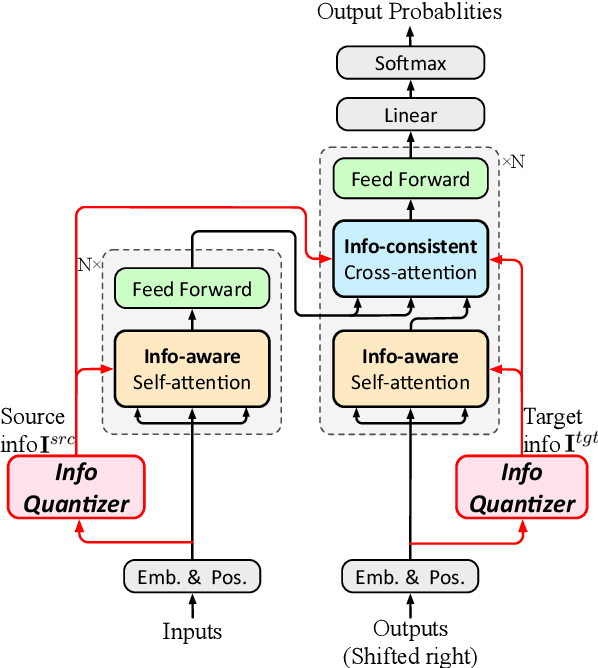
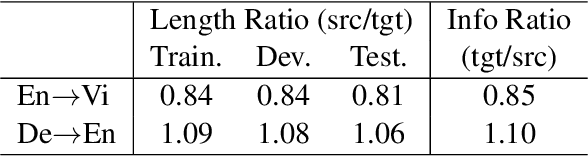
Simultaneous machine translation (SiMT) outputs the translation while receiving the source inputs, and hence needs to balance the received source information and translated target information to make a reasonable decision between waiting for inputs or outputting translation. Previous methods always balance source and target information at the token level, either directly waiting for a fixed number of tokens or adjusting the waiting based on the current token. In this paper, we propose a Wait-info Policy to balance source and target at the information level. We first quantify the amount of information contained in each token, named info. Then during simultaneous translation, the decision of waiting or outputting is made based on the comparison results between the total info of previous target outputs and received source inputs. Experiments show that our method outperforms strong baselines under and achieves better balance via the proposed info.
The Graph feature fusion technique for speaker recognition based on wav2vec2.0 framework
Mar 19, 2023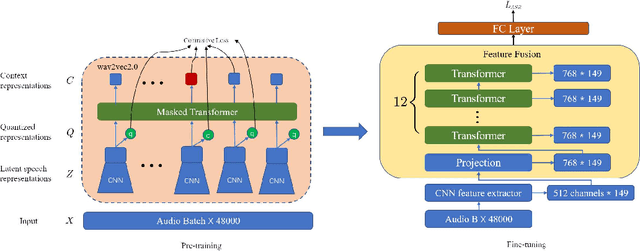
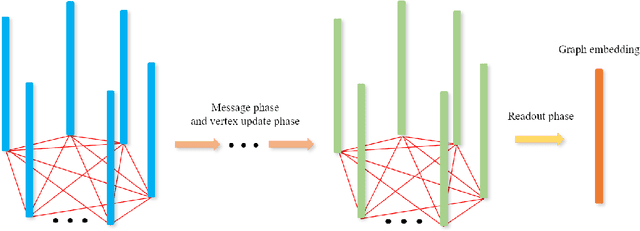
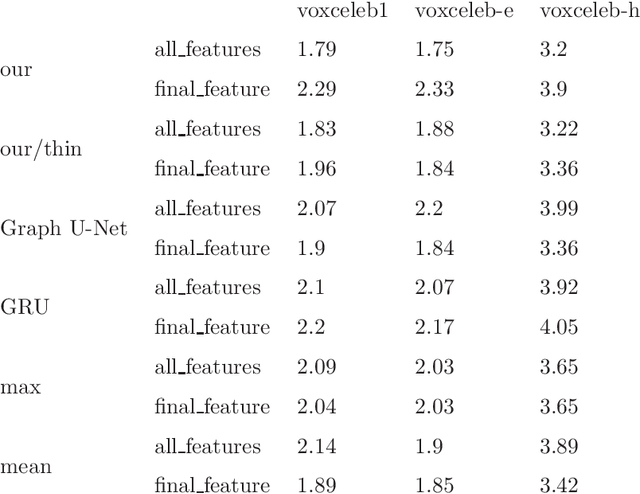
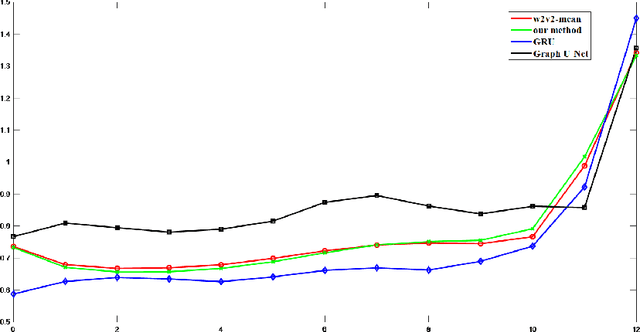
Pre-trained wav2vec2.0 model has been proved its effectiveness for speaker recognition. However, current feature processing methods are focusing on classical pooling on the output features of the pre-trained wav2vec2.0 model, such as mean pooling, max pooling etc. That methods take the features as the independent and irrelevant units, ignoring the inter-relationship among all the features, and do not take the features as an overall representation of a speaker. Gated Recurrent Unit (GRU), as a feature fusion method, can also be considered as a complicated pooling technique, mainly focuses on the temporal information, which may show poor performance in some situations that the main information is not on the temporal dimension. In this paper, we investigate the graph neural network (GNN) as a backend processing module based on wav2vec2.0 framework to provide a solution for the mentioned matters. The GNN takes all the output features as the graph signal data and extracts the related graph structure information of features for speaker recognition. Specifically, we first give a simple proof that the GNN feature fusion method can outperform than the mean, max, random pooling methods and so on theoretically. Then, we model the output features of wav2vec2.0 as the vertices of a graph, and construct the graph adjacency matrix by graph attention network (GAT). Finally, we follow the message passing neural network (MPNN) to design our message function, vertex update function and readout function to transform the speaker features into the graph features. The experiments show our performance can provide a relative improvement compared to the baseline methods. Code is available at xxx.
Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos
Apr 11, 2023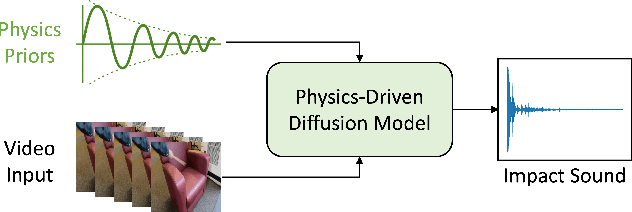
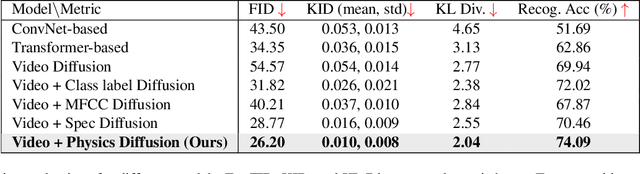
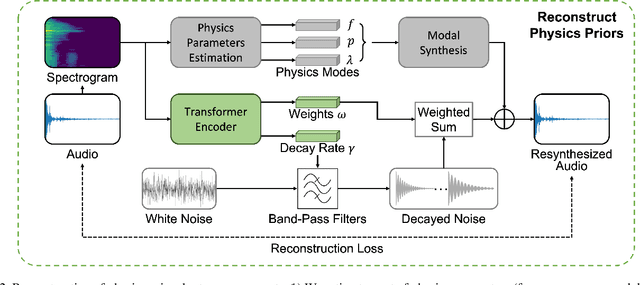
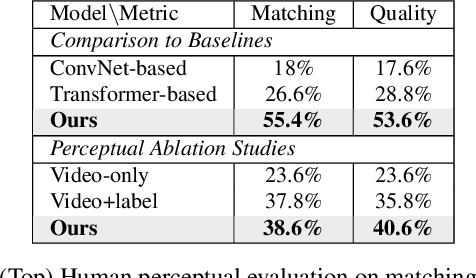
Modeling sounds emitted from physical object interactions is critical for immersive perceptual experiences in real and virtual worlds. Traditional methods of impact sound synthesis use physics simulation to obtain a set of physics parameters that could represent and synthesize the sound. However, they require fine details of both the object geometries and impact locations, which are rarely available in the real world and can not be applied to synthesize impact sounds from common videos. On the other hand, existing video-driven deep learning-based approaches could only capture the weak correspondence between visual content and impact sounds since they lack of physics knowledge. In this work, we propose a physics-driven diffusion model that can synthesize high-fidelity impact sound for a silent video clip. In addition to the video content, we propose to use additional physics priors to guide the impact sound synthesis procedure. The physics priors include both physics parameters that are directly estimated from noisy real-world impact sound examples without sophisticated setup and learned residual parameters that interpret the sound environment via neural networks. We further implement a novel diffusion model with specific training and inference strategies to combine physics priors and visual information for impact sound synthesis. Experimental results show that our model outperforms several existing systems in generating realistic impact sounds. More importantly, the physics-based representations are fully interpretable and transparent, thus enabling us to perform sound editing flexibly.
Feudal Graph Reinforcement Learning
Apr 11, 2023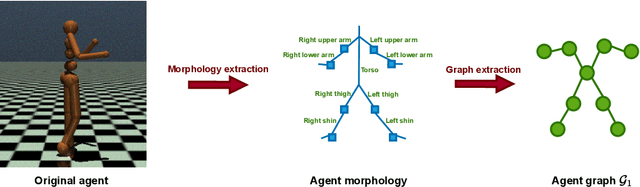
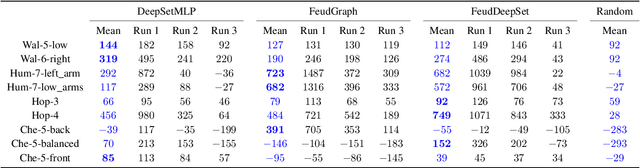
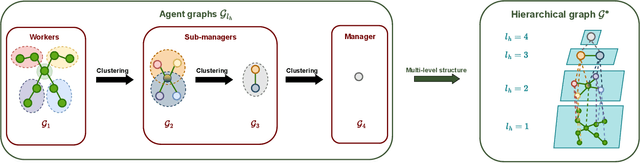

We focus on learning composable policies to control a variety of physical agents with possibly different structures. Among state-of-the-art methods, prominent approaches exploit graph-based representations and weight-sharing modular policies based on the message-passing framework. However, as shown by recent literature, message passing can create bottlenecks in information propagation and hinder global coordination. This drawback can become even more problematic in tasks where high-level planning is crucial. In fact, in similar scenarios, each modular policy - e.g., controlling a joint of a robot - would request to coordinate not only for basic locomotion but also achieve high-level goals, such as navigating a maze. A classical solution to avoid similar pitfalls is to resort to hierarchical decision-making. In this work, we adopt the Feudal Reinforcement Learning paradigm to develop agents where control actions are the outcome of a hierarchical (pyramidal) message-passing process. In the proposed Feudal Graph Reinforcement Learning (FGRL) framework, high-level decisions at the top level of the hierarchy are propagated through a layered graph representing a hierarchy of policies. Lower layers mimic the morphology of the physical system and upper layers can capture more abstract sub-modules. The purpose of this preliminary work is to formalize the framework and provide proof-of-concept experiments on benchmark environments (MuJoCo locomotion tasks). Empirical evaluation shows promising results on both standard benchmarks and zero-shot transfer learning settings.
Coarse-to-Fine Covid-19 Segmentation via Vision-Language Alignment
Mar 01, 2023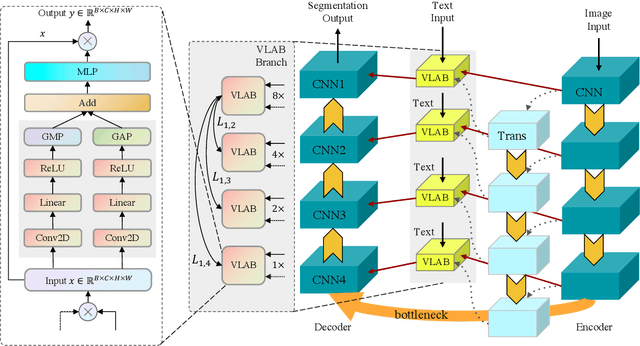
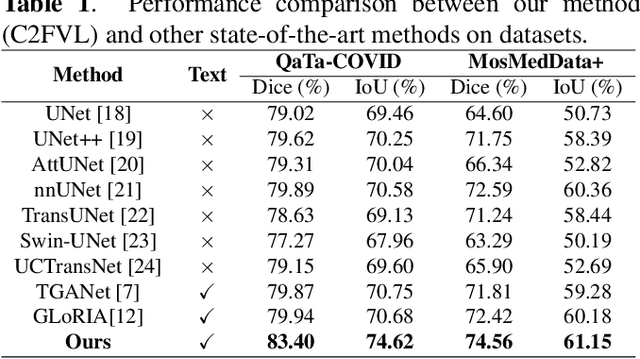

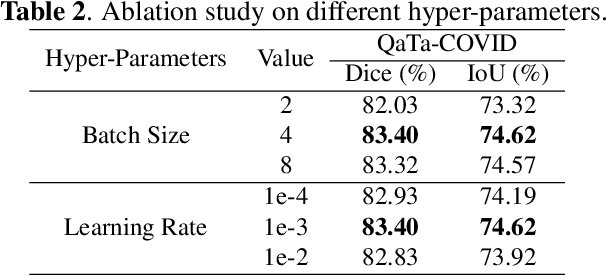
Segmentation of COVID-19 lesions can assist physicians in better diagnosis and treatment of COVID-19. However, there are few relevant studies due to the lack of detailed information and high-quality annotation in the COVID-19 dataset. To solve the above problem, we propose C2FVL, a Coarse-to-Fine segmentation framework via Vision-Language alignment to merge text information containing the number of lesions and specific locations of image information. The introduction of text information allows the network to achieve better prediction results on challenging datasets. We conduct extensive experiments on two COVID-19 datasets including chest X-ray and CT, and the results demonstrate that our proposed method outperforms other state-of-the-art segmentation methods.
Fisher information lower bounds for sampling
Oct 05, 2022We prove two lower bounds for the complexity of non-log-concave sampling within the framework of Balasubramanian et al. (2022), who introduced the use of Fisher information (FI) bounds as a notion of approximate first-order stationarity in sampling. Our first lower bound shows that averaged LMC is optimal for the regime of large FI by reducing the problem of finding stationary points in non-convex optimization to sampling. Our second lower bound shows that in the regime of small FI, obtaining a FI of at most $\varepsilon^2$ from the target distribution requires $\text{poly}(1/\varepsilon)$ queries, which is surprising as it rules out the existence of high-accuracy algorithms (e.g., algorithms using Metropolis-Hastings filters) in this context.
Weakly Supervised Knowledge Transfer with Probabilistic Logical Reasoning for Object Detection
Mar 09, 2023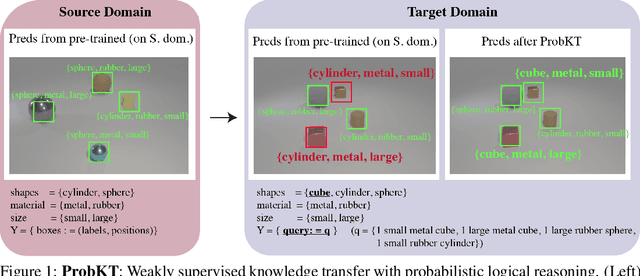
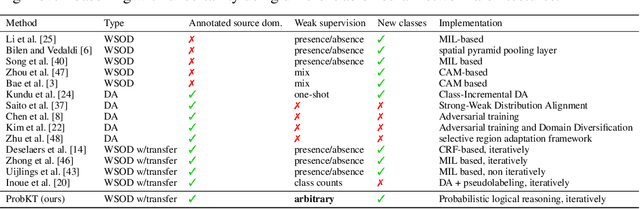
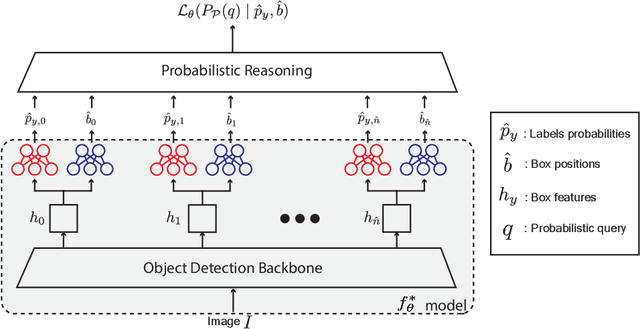
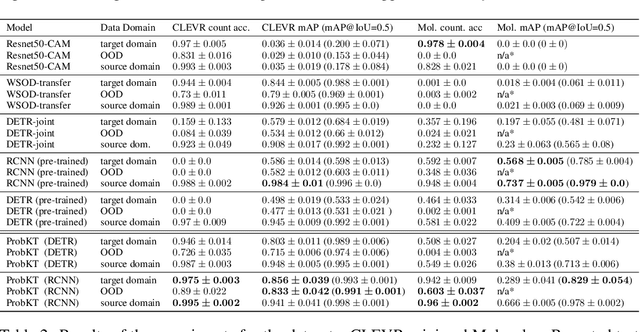
Training object detection models usually requires instance-level annotations, such as the positions and labels of all objects present in each image. Such supervision is unfortunately not always available and, more often, only image-level information is provided, also known as weak supervision. Recent works have addressed this limitation by leveraging knowledge from a richly annotated domain. However, the scope of weak supervision supported by these approaches has been very restrictive, preventing them to use all available information. In this work, we propose ProbKT, a framework based on probabilistic logical reasoning that allows to train object detection models with arbitrary types of weak supervision. We empirically show on different datasets that using all available information is beneficial as our ProbKT leads to significant improvement on target domain and better generalization compared to existing baselines. We also showcase the ability of our approach to handle complex logic statements as supervision signal.
Overview of the ICASSP 2023 General Meeting Understanding and Generation Challenge (MUG)
Mar 24, 2023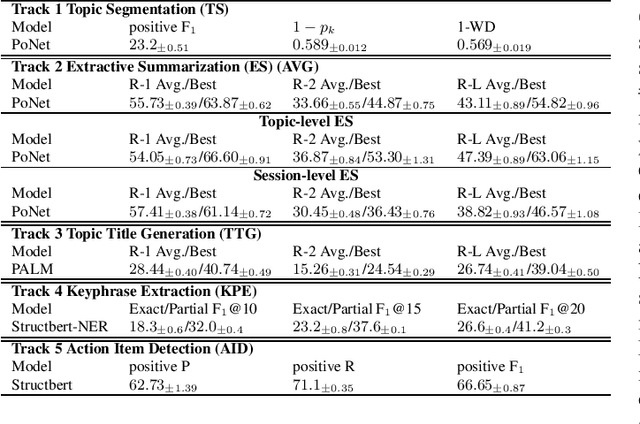
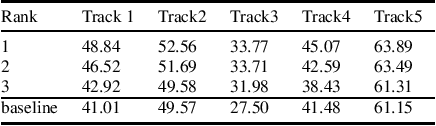
ICASSP2023 General Meeting Understanding and Generation Challenge (MUG) focuses on prompting a wide range of spoken language processing (SLP) research on meeting transcripts, as SLP applications are critical to improve users' efficiency in grasping important information in meetings. MUG includes five tracks, including topic segmentation, topic-level and session-level extractive summarization, topic title generation, keyphrase extraction, and action item detection. To facilitate MUG, we construct and release a large-scale meeting dataset, the AliMeeting4MUG Corpus.
Hyperspectral Image Segmentation: A Preliminary Study on the Oral and Dental Spectral Image Database (ODSI-DB)
Mar 14, 2023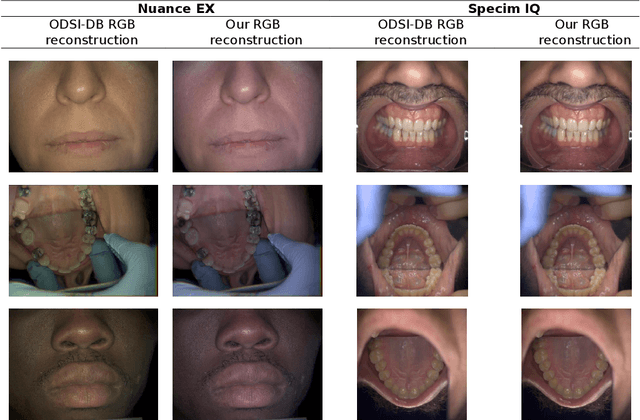
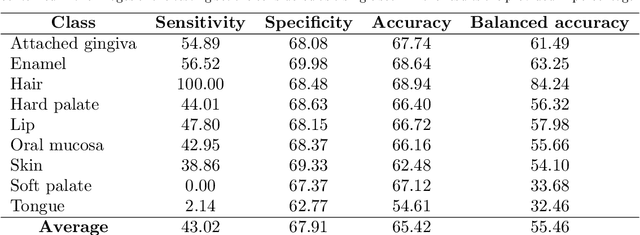
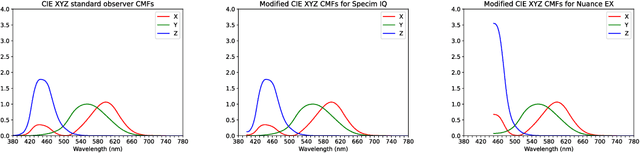
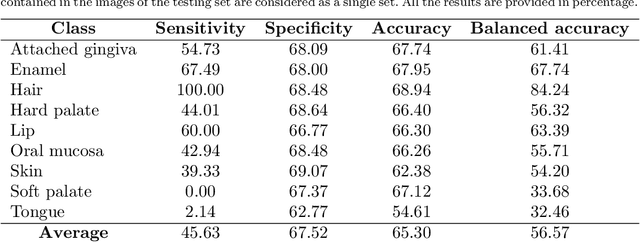
Visual discrimination of clinical tissue types remains challenging, with traditional RGB imaging providing limited contrast for such tasks. Hyperspectral imaging (HSI) is a promising technology providing rich spectral information that can extend far beyond three-channel RGB imaging. Moreover, recently developed snapshot HSI cameras enable real-time imaging with significant potential for clinical applications. Despite this, the investigation into the relative performance of HSI over RGB imaging for semantic segmentation purposes has been limited, particularly in the context of medical imaging. Here we compare the performance of state-of-the-art deep learning image segmentation methods when trained on hyperspectral images, RGB images, hyperspectral pixels (minus spatial context), and RGB pixels (disregarding spatial context). To achieve this, we employ the recently released Oral and Dental Spectral Image Database (ODSI-DB), which consists of 215 manually segmented dental reflectance spectral images with 35 different classes across 30 human subjects. The recent development of snapshot HSI cameras has made real-time clinical HSI a distinct possibility, though successful application requires a comprehensive understanding of the additional information HSI offers. Our work highlights the relative importance of spectral resolution, spectral range, and spatial information to both guide the development of HSI cameras and inform future clinical HSI applications.