 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforcement Learning-Based Black-Box Model Inversion Attacks
Apr 10, 2023
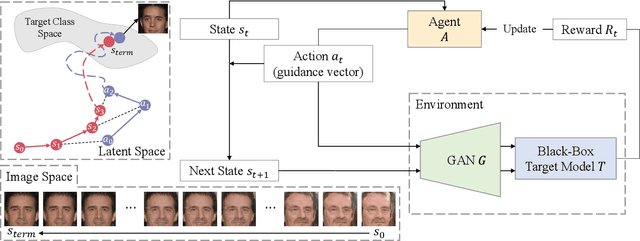
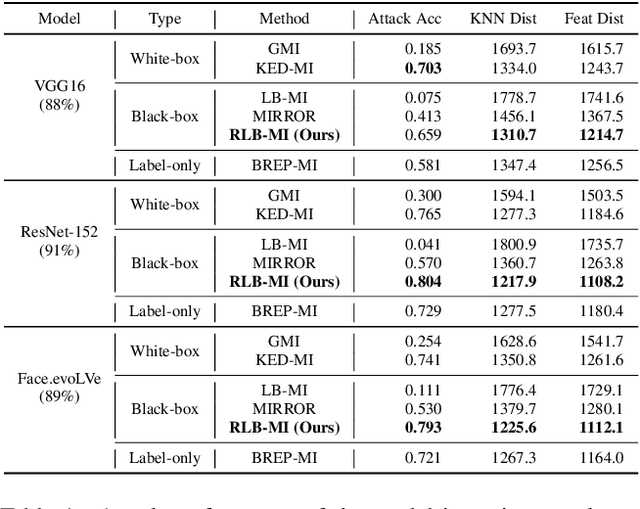

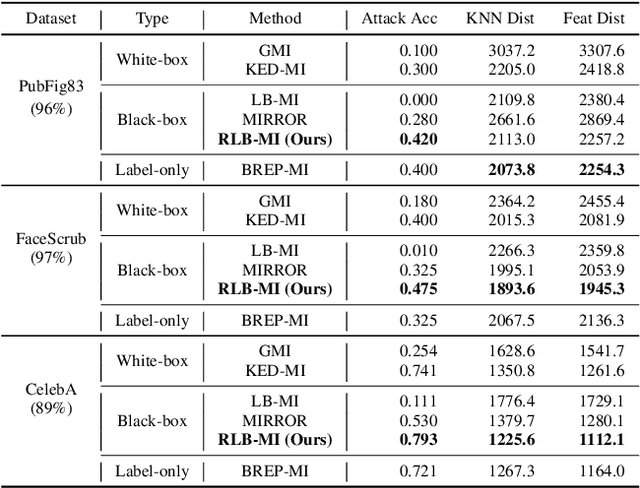
Model inversion attacks are a type of privacy attack that reconstructs private data used to train a machine learning model, solely by accessing the model. Recently, white-box model inversion attacks leveraging Generative Adversarial Networks (GANs) to distill knowledge from public datasets have been receiving great attention because of their excellent attack performance. On the other hand, current black-box model inversion attacks that utilize GANs suffer from issues such as being unable to guarantee the completion of the attack process within a predetermined number of query accesses or achieve the same level of performance as white-box attacks. To overcome these limitations, we propose a reinforcement learning-based black-box model inversion attack. We formulate the latent space search as a Markov Decision Process (MDP) problem and solve it with reinforcement learning. Our method utilizes the confidence scores of the generated images to provide rewards to an agent. Finally, the private data can be reconstructed using the latent vectors found by the agent trained in the MDP. The experiment results on various datasets and models demonstrate that our attack successfully recovers the private information of the target model by achieving state-of-the-art attack performance. We emphasize the importance of studies on privacy-preserving machine learning by proposing a more advanced black-box model inversion attack.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023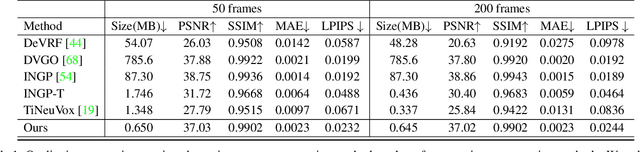
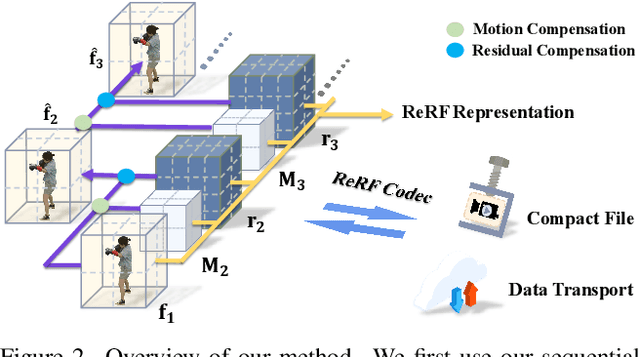
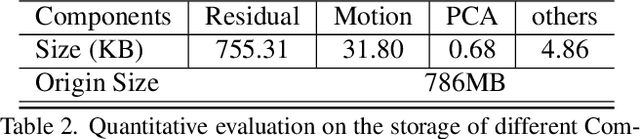
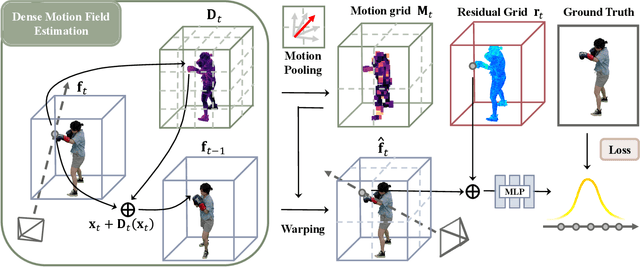
The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023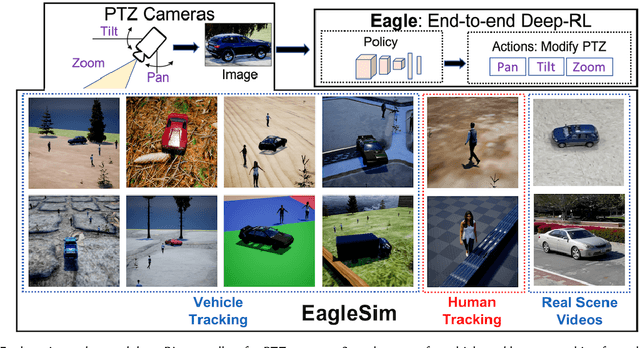

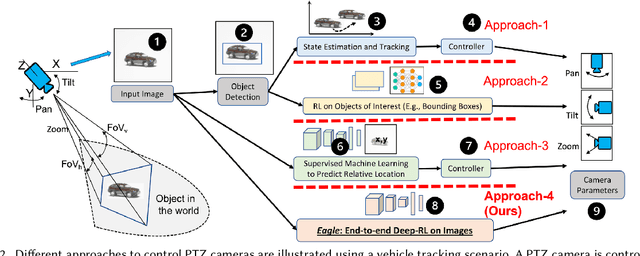
Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.
On the Possibilities of AI-Generated Text Detection
Apr 10, 2023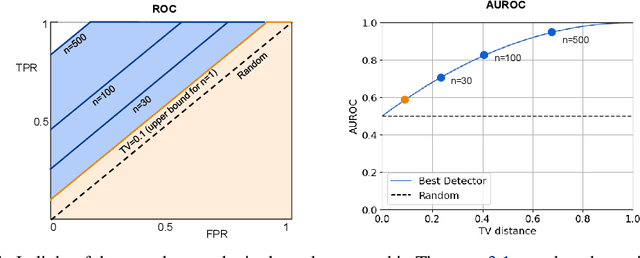

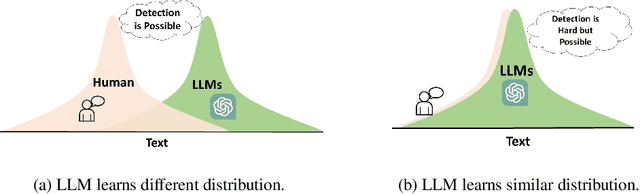
Our work focuses on the challenge of detecting outputs generated by Large Language Models (LLMs) from those generated by humans. The ability to distinguish between the two is of utmost importance in numerous applications. However, the possibility and impossibility of such discernment have been subjects of debate within the community. Therefore, a central question is whether we can detect AI-generated text and, if so, when. In this work, we provide evidence that it should almost always be possible to detect the AI-generated text unless the distributions of human and machine generated texts are exactly the same over the entire support. This observation follows from the standard results in information theory and relies on the fact that if the machine text is becoming more like a human, we need more samples to detect it. We derive a precise sample complexity bound of AI-generated text detection, which tells how many samples are needed to detect. This gives rise to additional challenges of designing more complicated detectors that take in n samples to detect than just one, which is the scope of future research on this topic. Our empirical evaluations support our claim about the existence of better detectors demonstrating that AI-Generated text detection should be achievable in the majority of scenarios. Our results emphasize the importance of continued research in this area
How Efficient Are Today's Continual Learning Algorithms?
Apr 03, 2023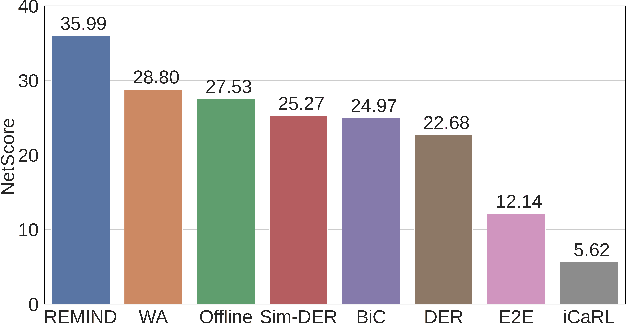
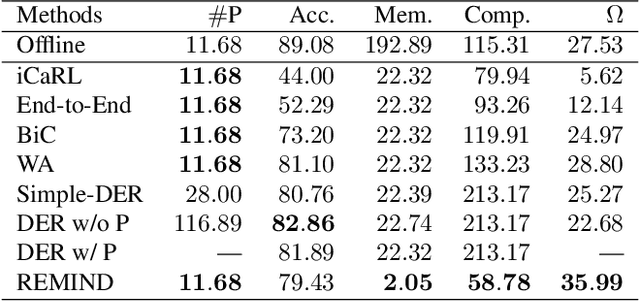
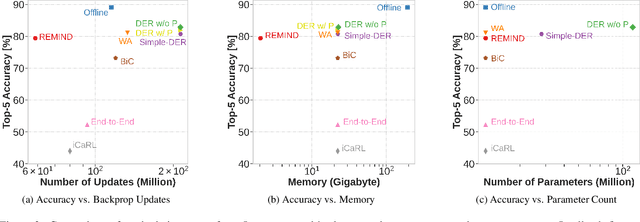
Supervised Continual learning involves updating a deep neural network (DNN) from an ever-growing stream of labeled data. While most work has focused on overcoming catastrophic forgetting, one of the major motivations behind continual learning is being able to efficiently update a network with new information, rather than retraining from scratch on the training dataset as it grows over time. Despite recent continual learning methods largely solving the catastrophic forgetting problem, there has been little attention paid to the efficiency of these algorithms. Here, we study recent methods for incremental class learning and illustrate that many are highly inefficient in terms of compute, memory, and storage. Some methods even require more compute than training from scratch! We argue that for continual learning to have real-world applicability, the research community cannot ignore the resources used by these algorithms. There is more to continual learning than mitigating catastrophic forgetting.
CAP-VSTNet: Content Affinity Preserved Versatile Style Transfer
Mar 31, 2023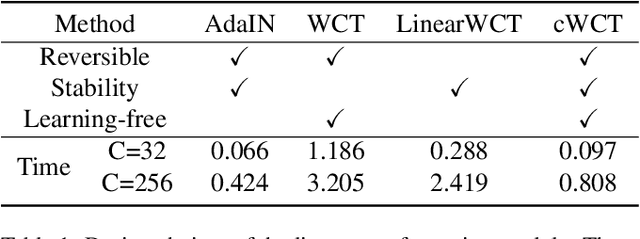
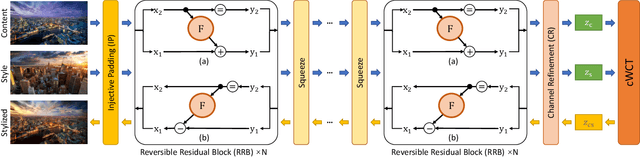


Content affinity loss including feature and pixel affinity is a main problem which leads to artifacts in photorealistic and video style transfer. This paper proposes a new framework named CAP-VSTNet, which consists of a new reversible residual network and an unbiased linear transform module, for versatile style transfer. This reversible residual network can not only preserve content affinity but not introduce redundant information as traditional reversible networks, and hence facilitate better stylization. Empowered by Matting Laplacian training loss which can address the pixel affinity loss problem led by the linear transform, the proposed framework is applicable and effective on versatile style transfer. Extensive experiments show that CAP-VSTNet can produce better qualitative and quantitative results in comparison with the state-of-the-art methods.
Multi-Modal Facial Expression Recognition with Transformer-Based Fusion Networks and Dynamic Sampling
Mar 15, 2023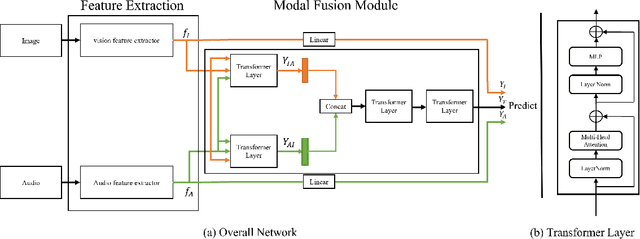
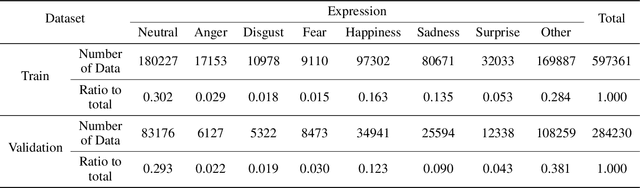
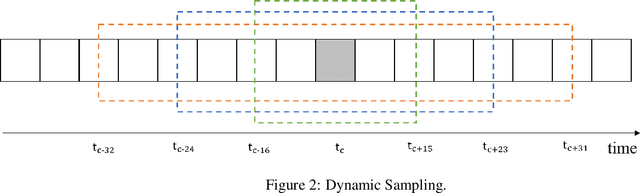
Facial expression recognition is important for various purpose such as emotion detection, mental health analysis, and human-machine interaction. In facial expression recognition, incorporating audio information along with still images can provide a more comprehensive understanding of an expression state. This paper presents the Multi-modal facial expression recognition methods for Affective Behavior in-the-wild (ABAW) challenge at CVPR 2023. We propose a Modal Fusion Module (MFM) to fuse audio-visual information. The modalities used are image and audio, and features are extracted based on Swin Transformer to forward the MFM. Our approach also addresses imbalances in the dataset through data resampling in training dataset and leverages the rich modal in a single frame using dynmaic data sampling, leading to improved performance.
Extended FastSLAM Using Cellular Multipath Component Delays and Angular Information
Jan 18, 2023
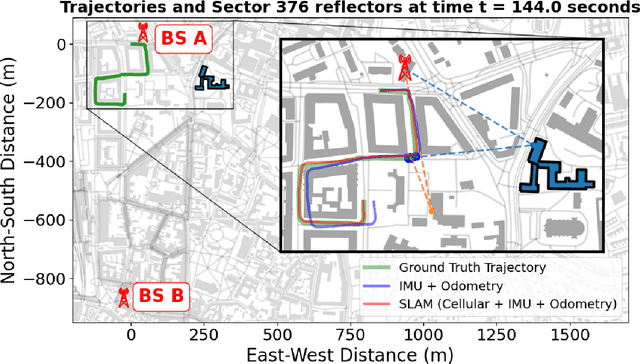
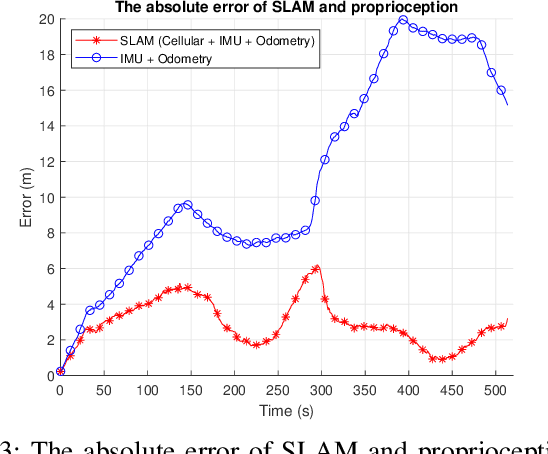
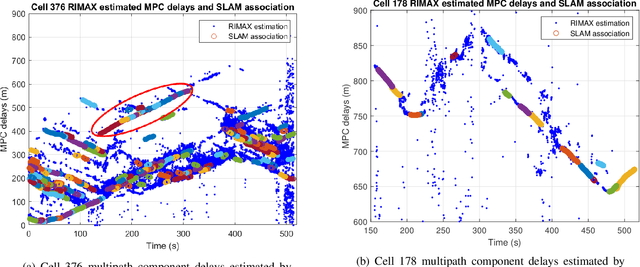
Opportunistic navigation using cellular signals is appealing for scenarios where other navigation technologies face challenges. In this paper, long-term evolution (LTE) downlink signals from two neighboring commercial base stations (BS) are received by a massive antenna array mounted on a passenger vehicle. Multipath component (MPC) delays and angle-of-arrival (AOA) extracted from the received signals are used to jointly estimate the positions of the vehicle, transmitters, and virtual transmitters (VT) with an extended fast simultaneous localization and mapping (FastSLAM) algorithm. The results show that the algorithm can accurately estimate the positions of the vehicle and the transmitters (and virtual transmitters). The vehicle's horizontal position error of SLAM fused with proprioception is less than 6 meters after a traversed distance of 530 meters, whereas un-aided proprioception results in a horizontal error of 15 meters.
MMT: A Multilingual and Multi-Topic Indian Social Media Dataset
Apr 02, 2023

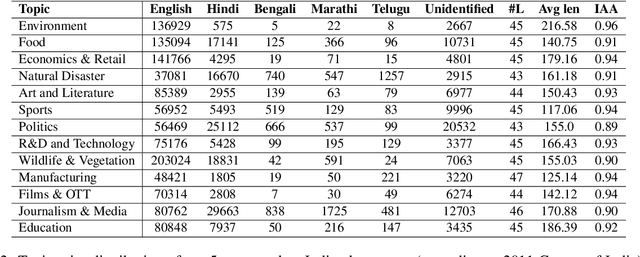
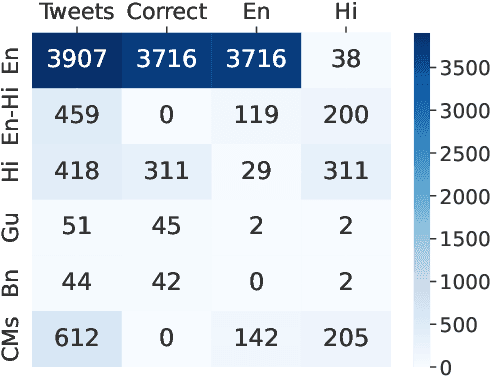
Social media plays a significant role in cross-cultural communication. A vast amount of this occurs in code-mixed and multilingual form, posing a significant challenge to Natural Language Processing (NLP) tools for processing such information, like language identification, topic modeling, and named-entity recognition. To address this, we introduce a large-scale multilingual, and multi-topic dataset (MMT) collected from Twitter (1.7 million Tweets), encompassing 13 coarse-grained and 63 fine-grained topics in the Indian context. We further annotate a subset of 5,346 tweets from the MMT dataset with various Indian languages and their code-mixed counterparts. Also, we demonstrate that the currently existing tools fail to capture the linguistic diversity in MMT on two downstream tasks, i.e., topic modeling and language identification. To facilitate future research, we will make the anonymized and annotated dataset available in the public domain.
Coarse-to-Fine Covid-19 Segmentation via Vision-Language Alignment
Mar 01, 2023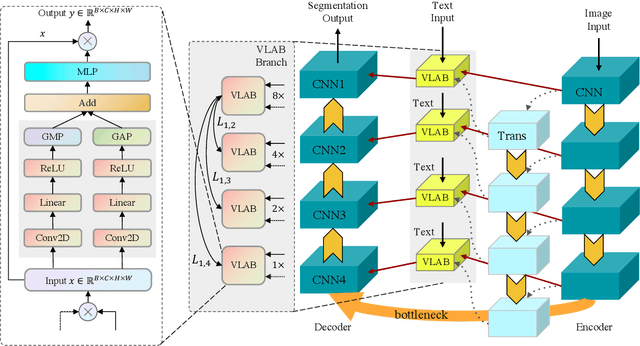
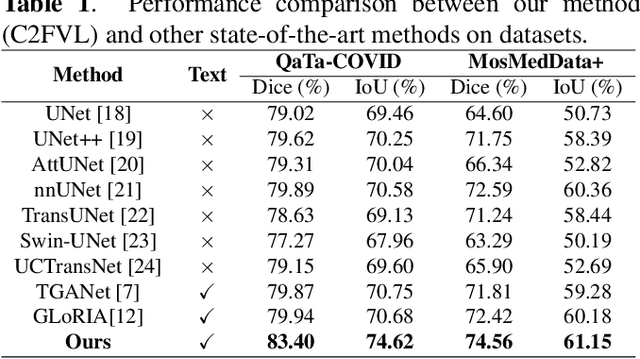

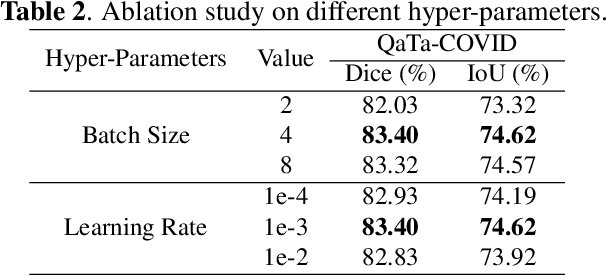
Segmentation of COVID-19 lesions can assist physicians in better diagnosis and treatment of COVID-19. However, there are few relevant studies due to the lack of detailed information and high-quality annotation in the COVID-19 dataset. To solve the above problem, we propose C2FVL, a Coarse-to-Fine segmentation framework via Vision-Language alignment to merge text information containing the number of lesions and specific locations of image information. The introduction of text information allows the network to achieve better prediction results on challenging datasets. We conduct extensive experiments on two COVID-19 datasets including chest X-ray and CT, and the results demonstrate that our proposed method outperforms other state-of-the-art segmentation methods.