 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
Mar 13, 2024
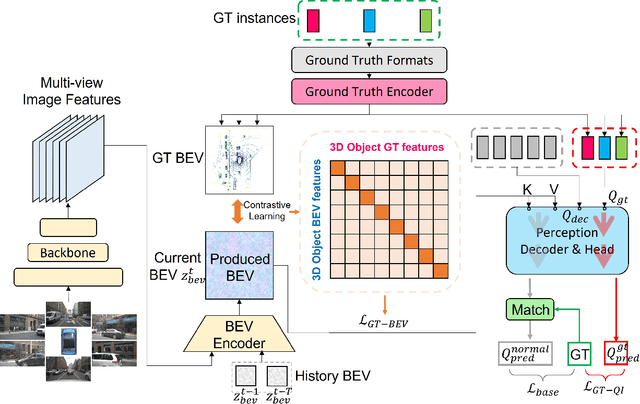
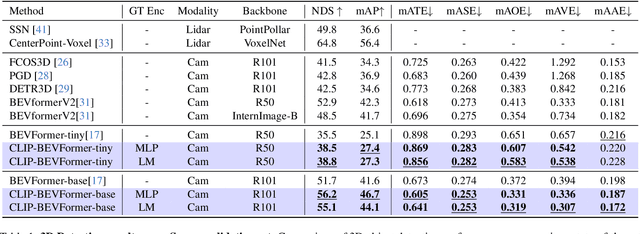
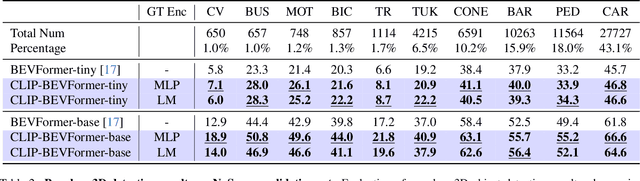

Autonomous driving stands as a pivotal domain in computer vision, shaping the future of transportation. Within this paradigm, the backbone of the system plays a crucial role in interpreting the complex environment. However, a notable challenge has been the loss of clear supervision when it comes to Bird's Eye View elements. To address this limitation, we introduce CLIP-BEVFormer, a novel approach that leverages the power of contrastive learning techniques to enhance the multi-view image-derived BEV backbones with ground truth information flow. We conduct extensive experiments on the challenging nuScenes dataset and showcase significant and consistent improvements over the SOTA. Specifically, CLIP-BEVFormer achieves an impressive 8.5\% and 9.2\% enhancement in terms of NDS and mAP, respectively, over the previous best BEV model on the 3D object detection task.
* CVPR 2024
The Geography of Information Diffusion in Online Discourse on Europe and Migration
Feb 21, 2024The online diffusion of information related to Europe and migration has been little investigated from an external point of view. However, this is a very relevant topic, especially if users have had no direct contact with Europe and its perception depends solely on information retrieved online. In this work we analyse the information circulating online about Europe and migration after retrieving a large amount of data from social media (Twitter), to gain new insights into topics, magnitude, and dynamics of their diffusion. We combine retweets and hashtags network analysis with geolocation of users, linking thus data to geography and allowing analysis from an "outside Europe" perspective, with a special focus on Africa. We also introduce a novel approach based on cross-lingual quotes, i.e. when content in a language is commented and retweeted in another language, assuming these interactions are a proxy for connections between very distant communities. Results show how the majority of online discussions occurs at a national level, especially when discussing migration. Language (English) is pivotal for information to become transnational and reach far. Transnational information flow is strongly unbalanced, with content mainly produced in Europe and amplified outside. Conversely Europe-based accounts tend to be self-referential when they discuss migration-related topics. Football is the most exported topic from Europe worldwide. Moreover, important nodes in the communities discussing migration-related topics include accounts of official institutions and international agencies, together with journalists, news, commentators and activists.
KELLMRec: Knowledge-Enhanced Large Language Models for Recommendation
Mar 11, 2024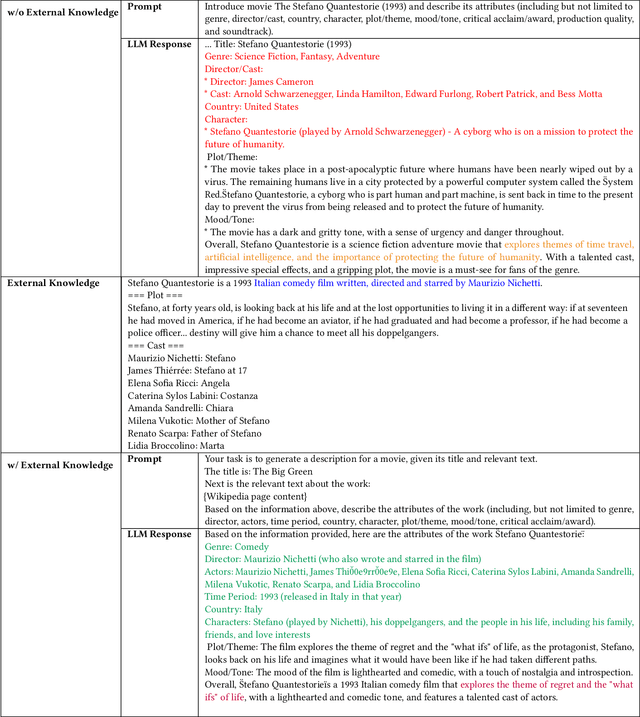
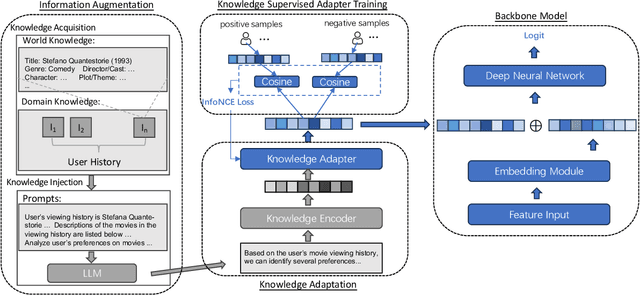
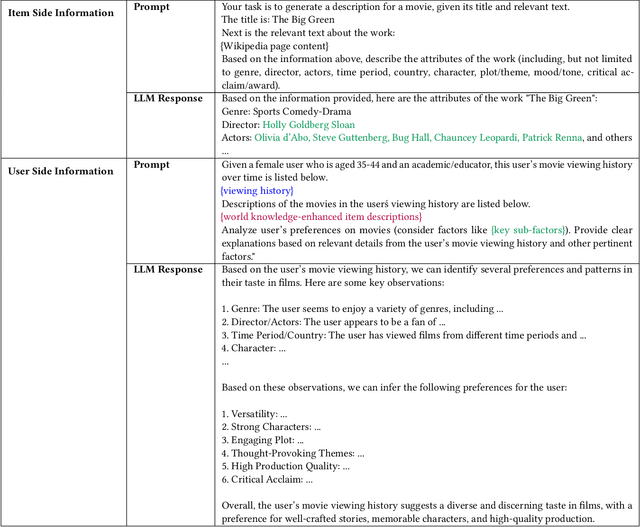

The utilization of semantic information is an important research problem in the field of recommender systems, which aims to complement the missing parts of mainstream ID-based approaches. With the rise of LLM, its ability to act as a knowledge base and its reasoning capability have opened up new possibilities for this research area, making LLM-based recommendation an emerging research direction. However, directly using LLM to process semantic information for recommendation scenarios is unreliable and sub-optimal due to several problems such as hallucination. A promising way to cope with this is to use external knowledge to aid LLM in generating truthful and usable text. Inspired by the above motivation, we propose a Knowledge-Enhanced LLMRec method. In addition to using external knowledge in prompts, the proposed method also includes a knowledge-based contrastive learning scheme for training. Experiments on public datasets and in-enterprise datasets validate the effectiveness of the proposed method.
Multi-modal Semantic Understanding with Contrastive Cross-modal Feature Alignment
Mar 11, 2024
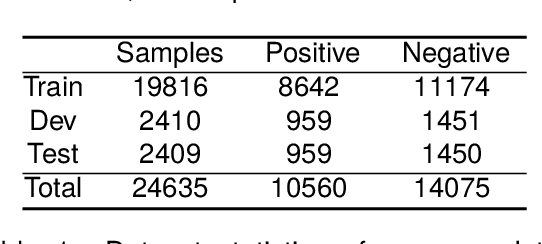
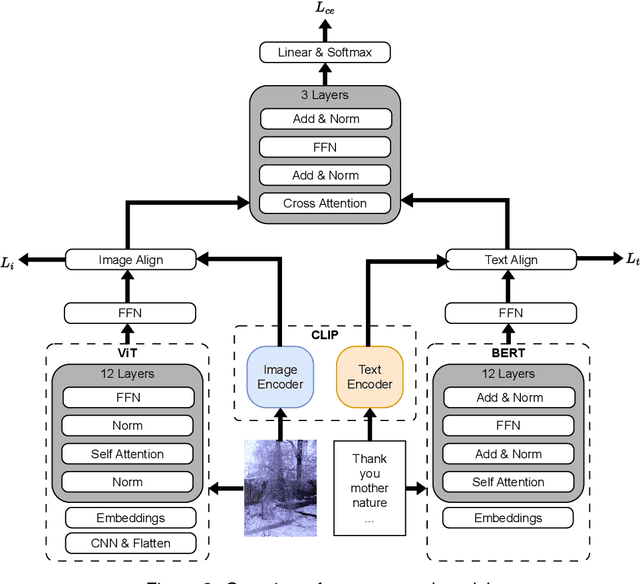
Multi-modal semantic understanding requires integrating information from different modalities to extract users' real intention behind words. Most previous work applies a dual-encoder structure to separately encode image and text, but fails to learn cross-modal feature alignment, making it hard to achieve cross-modal deep information interaction. This paper proposes a novel CLIP-guided contrastive-learning-based architecture to perform multi-modal feature alignment, which projects the features derived from different modalities into a unified deep space. On multi-modal sarcasm detection (MMSD) and multi-modal sentiment analysis (MMSA) tasks, the experimental results show that our proposed model significantly outperforms several baselines, and our feature alignment strategy brings obvious performance gain over models with different aggregating methods and models even enriched with knowledge. More importantly, our model is simple to implement without using task-specific external knowledge, and thus can easily migrate to other multi-modal tasks. Our source codes are available at https://github.com/ChangKe123/CLFA.
SPA: Towards A Computational Friendly Cloud-Base and On-Devices Collaboration Seq2seq Personalized Generation
Mar 11, 2024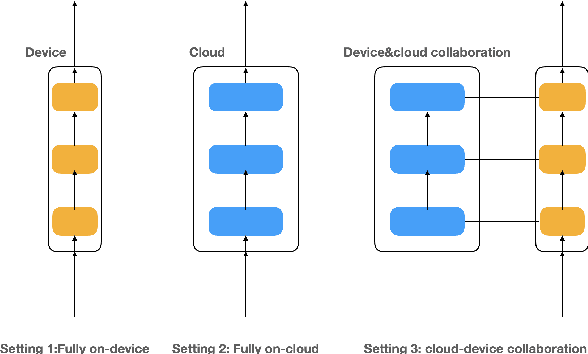
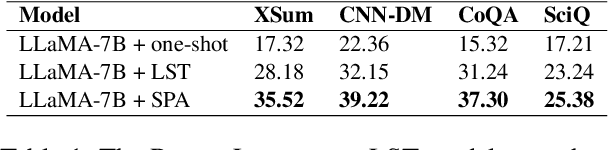
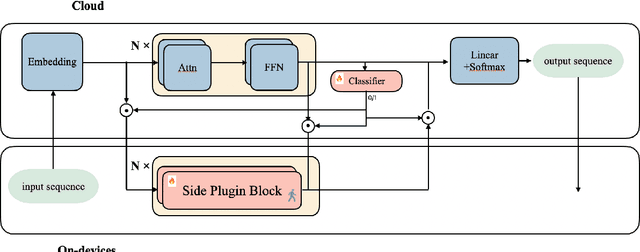

Large language models(LLMs) have shown its outperforming ability on various tasks and question answering. However, LLMs require high computation cost and large memory cost. At the same time, LLMs may cause privacy leakage when training or prediction procedure contains sensitive information. In this paper, we propose SPA(Side Plugin Adaption), a lightweight architecture for fast on-devices inference and privacy retaining on the constraints of strict on-devices computation and memory constraints. Compared with other on-devices seq2seq generation, SPA could make a fast and stable inference on low-resource constraints, allowing it to obtain cost effiency. Our method establish an interaction between a pretrained LLMs on-cloud and additive parameters on-devices, which could provide the knowledge on both pretrained LLMs and private personal feature.Further more, SPA provides a framework to keep feature-base parameters on private guaranteed but low computational devices while leave the parameters containing general information on the high computational devices.
ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
Mar 09, 2024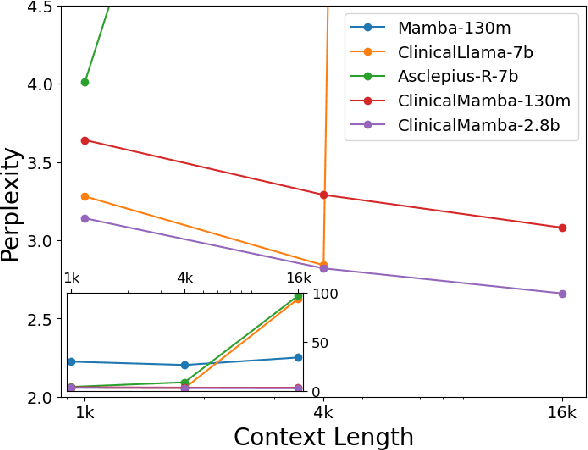
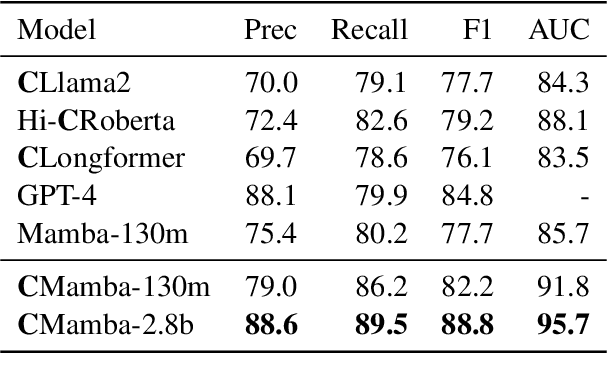
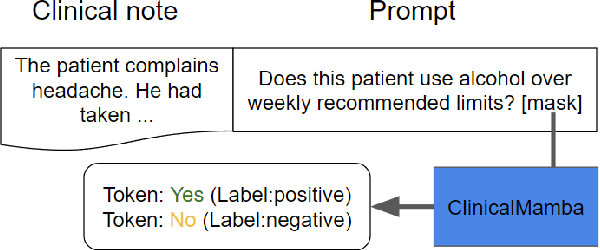
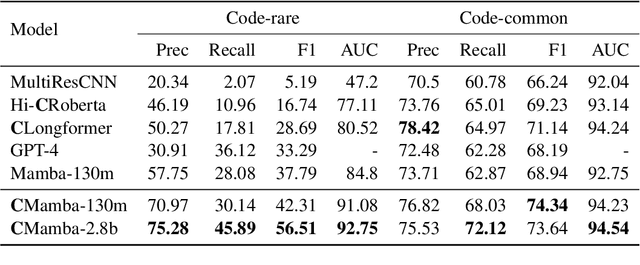
The advancement of natural language processing (NLP) systems in healthcare hinges on language model ability to interpret the intricate information contained within clinical notes. This process often requires integrating information from various time points in a patient's medical history. However, most earlier clinical language models were pretrained with a context length limited to roughly one clinical document. In this study, We introduce ClinicalMamba, a specialized version of the Mamba language model, pretrained on a vast corpus of longitudinal clinical notes to address the unique linguistic characteristics and information processing needs of the medical domain. ClinicalMamba, with 130 million and 2.8 billion parameters, demonstrates a superior performance in modeling clinical language across extended text lengths compared to Mamba and clinical Llama. With few-shot learning, ClinicalMamba achieves notable benchmarks in speed and accuracy, outperforming existing clinical language models and general domain large models like GPT-4 in longitudinal clinical notes information extraction tasks.
Robust Subgraph Learning by Monitoring Early Training Representations
Mar 14, 2024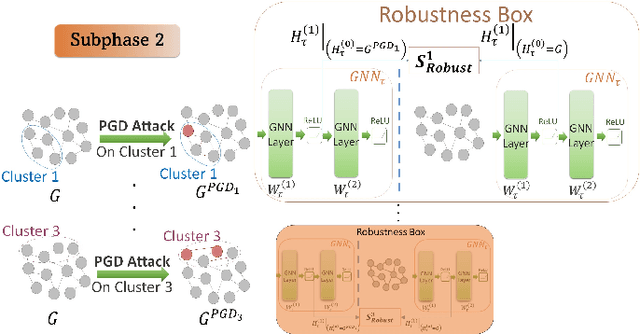
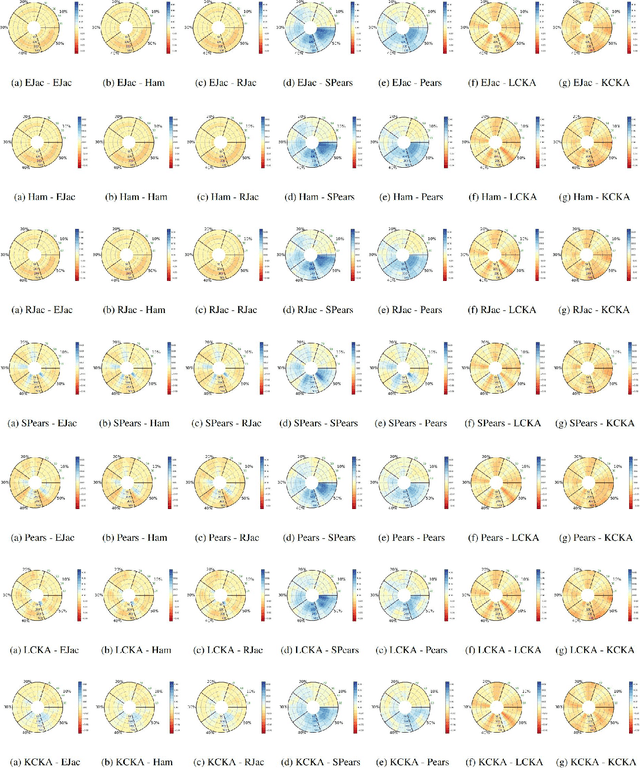
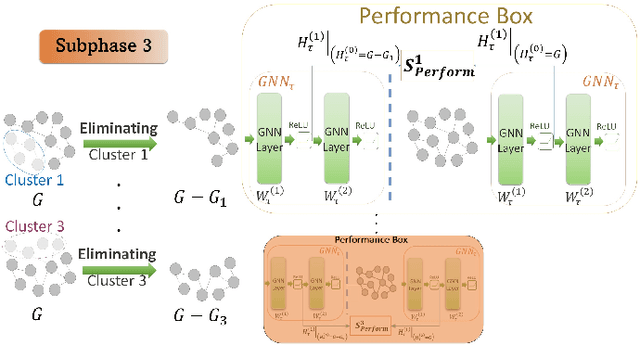
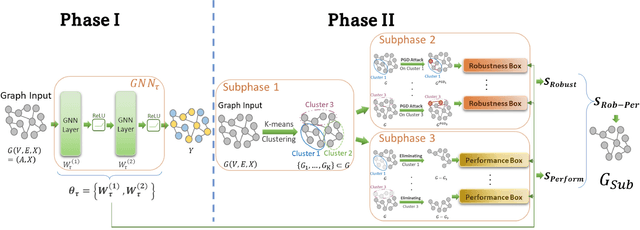
Graph neural networks (GNNs) have attracted significant attention for their outstanding performance in graph learning and node classification tasks. However, their vulnerability to adversarial attacks, particularly through susceptible nodes, poses a challenge in decision-making. The need for robust graph summarization is evident in adversarial challenges resulting from the propagation of attacks throughout the entire graph. In this paper, we address both performance and adversarial robustness in graph input by introducing the novel technique SHERD (Subgraph Learning Hale through Early Training Representation Distances). SHERD leverages information from layers of a partially trained graph convolutional network (GCN) to detect susceptible nodes during adversarial attacks using standard distance metrics. The method identifies "vulnerable (bad)" nodes and removes such nodes to form a robust subgraph while maintaining node classification performance. Through our experiments, we demonstrate the increased performance of SHERD in enhancing robustness by comparing the network's performance on original and subgraph inputs against various baselines alongside existing adversarial attacks. Our experiments across multiple datasets, including citation datasets such as Cora, Citeseer, and Pubmed, as well as microanatomical tissue structures of cell graphs in the placenta, highlight that SHERD not only achieves substantial improvement in robust performance but also outperforms several baselines in terms of node classification accuracy and computational complexity.
A Modified da Vinci Surgical Instrument for OCE based Elasticity Estimation with Deep Learning
Mar 14, 2024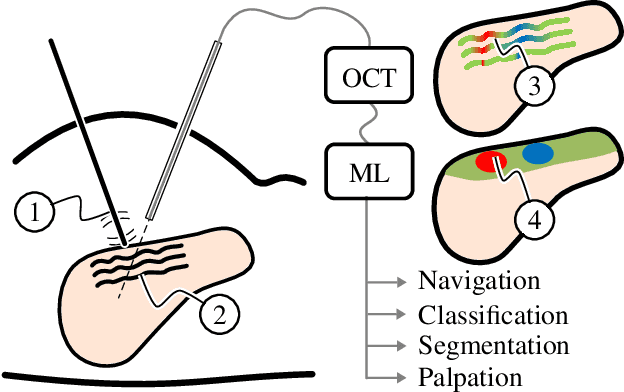
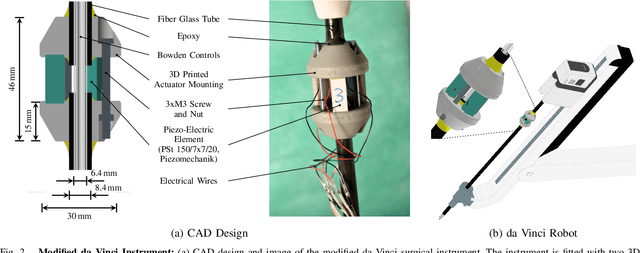
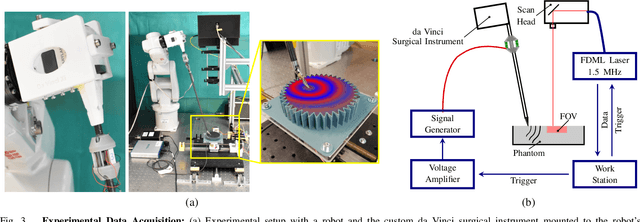
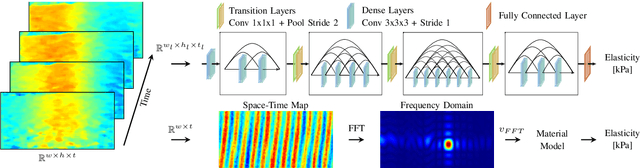
Robot-assisted surgery has advantages compared to conventional laparoscopic procedures, e.g., precise movement of the surgical instruments, improved dexterity, and high-resolution visualization of the surgical field. However, mechanical tissue properties may provide additional information, e.g., on the location of lesions or vessels. While elastographic imaging has been proposed, it is not readily available as an online modality during robot-assisted surgery. We propose modifying a da~Vinci surgical instrument to realize optical coherence elastography (OCE) for quantitative elasticity estimation. The modified da~Vinci instrument is equipped with piezoelectric elements for shear wave excitation and we employ fast optical coherence tomography (OCT) imaging to track propagating wave fields, which are directly related to biomechanical tissue properties. All high-voltage components are mounted at the proximal end outside the patient. We demonstrate that external excitation at the instrument shaft can effectively stimulate shear waves, even when considering damping. Comparing conventional and deep learning-based signal processing, resulting in mean absolute errors of 19.27 kPa and 6.29 kPa, respectively. These results illustrate that precise quantitative elasticity estimates can be obtained. We also demonstrate quantitative elasticity estimation on ex-vivo tissue samples of heart, liver and stomach, and show that the measurements can be used to distinguish soft and stiff tissue types.
Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior
Mar 14, 2024


Recent works on text-to-3d generation show that using only 2D diffusion supervision for 3D generation tends to produce results with inconsistent appearances (e.g., faces on the back view) and inaccurate shapes (e.g., animals with extra legs). Existing methods mainly address this issue by retraining diffusion models with images rendered from 3D data to ensure multi-view consistency while struggling to balance 2D generation quality with 3D consistency. In this paper, we present a new framework Sculpt3D that equips the current pipeline with explicit injection of 3D priors from retrieved reference objects without re-training the 2D diffusion model. Specifically, we demonstrate that high-quality and diverse 3D geometry can be guaranteed by keypoints supervision through a sparse ray sampling approach. Moreover, to ensure accurate appearances of different views, we further modulate the output of the 2D diffusion model to the correct patterns of the template views without altering the generated object's style. These two decoupled designs effectively harness 3D information from reference objects to generate 3D objects while preserving the generation quality of the 2D diffusion model. Extensive experiments show our method can largely improve the multi-view consistency while retaining fidelity and diversity. Our project page is available at: https://stellarcheng.github.io/Sculpt3D/.
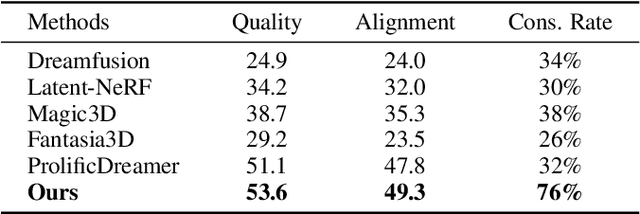
VDNA-PR: Using General Dataset Representations for Robust Sequential Visual Place Recognition
Mar 14, 2024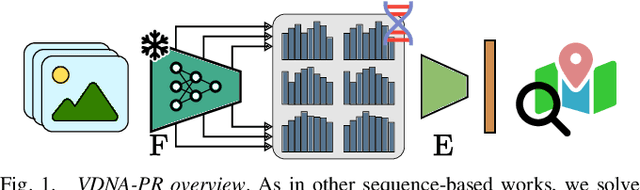
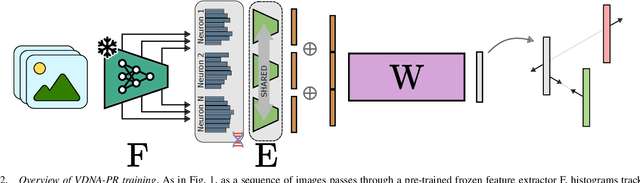

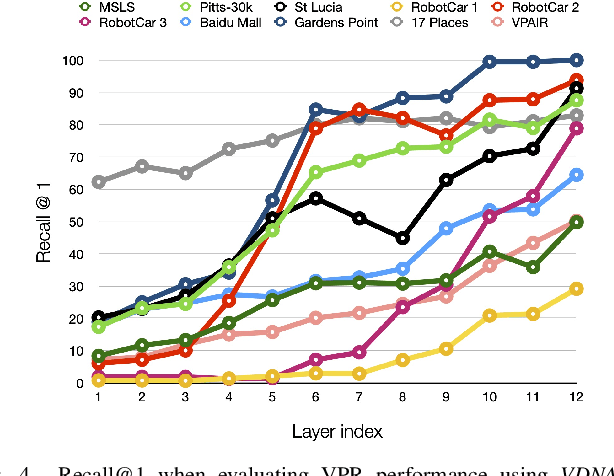
This paper adapts a general dataset representation technique to produce robust Visual Place Recognition (VPR) descriptors, crucial to enable real-world mobile robot localisation. Two parallel lines of work on VPR have shown, on one side, that general-purpose off-the-shelf feature representations can provide robustness to domain shifts, and, on the other, that fused information from sequences of images improves performance. In our recent work on measuring domain gaps between image datasets, we proposed a Visual Distribution of Neuron Activations (VDNA) representation to represent datasets of images. This representation can naturally handle image sequences and provides a general and granular feature representation derived from a general-purpose model. Moreover, our representation is based on tracking neuron activation values over the list of images to represent and is not limited to a particular neural network layer, therefore having access to high- and low-level concepts. This work shows how VDNAs can be used for VPR by learning a very lightweight and simple encoder to generate task-specific descriptors. Our experiments show that our representation can allow for better robustness than current solutions to serious domain shifts away from the training data distribution, such as to indoor environments and aerial imagery.