 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023
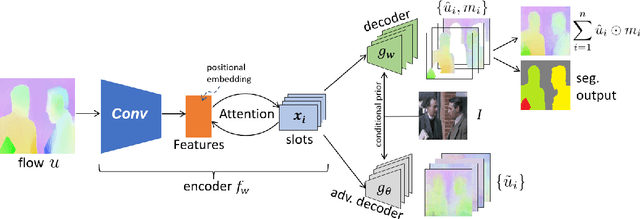
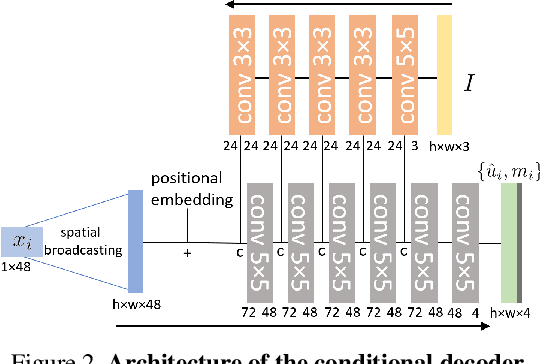
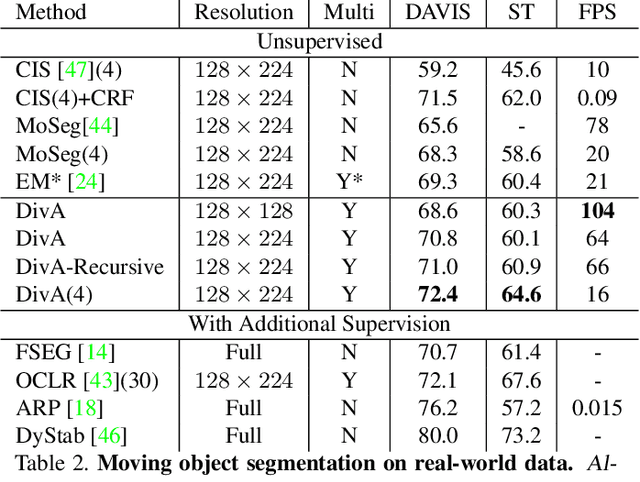

We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.
Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
Apr 04, 2023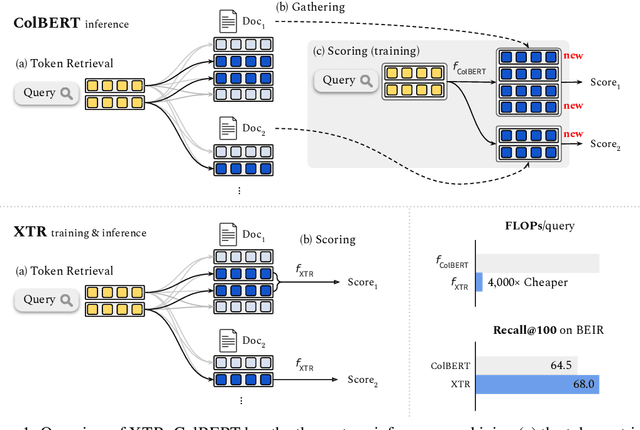

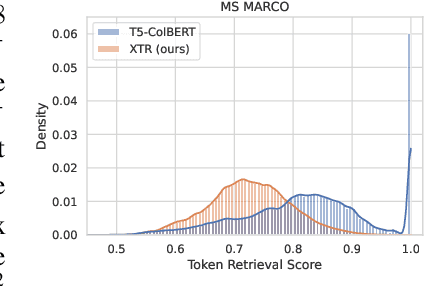
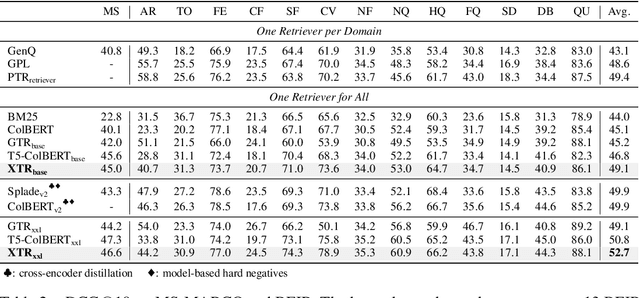
Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
Robust Outlier Rejection for 3D Registration with Variational Bayes
Apr 04, 2023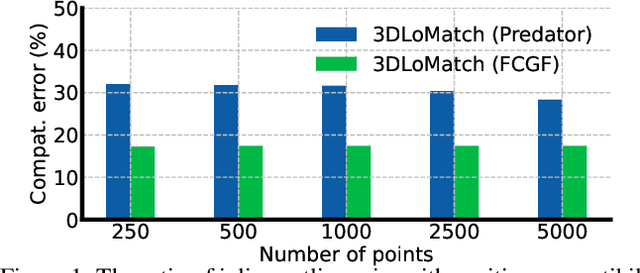
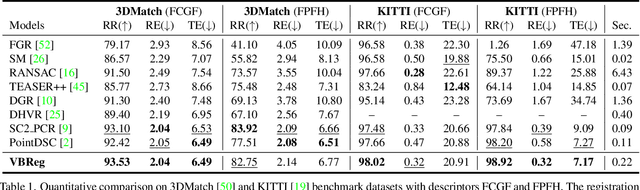
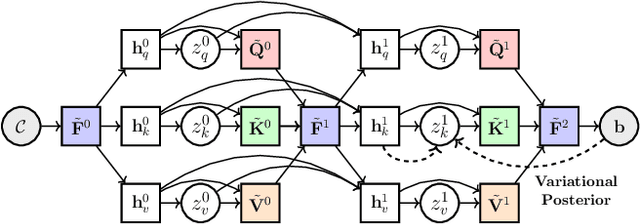
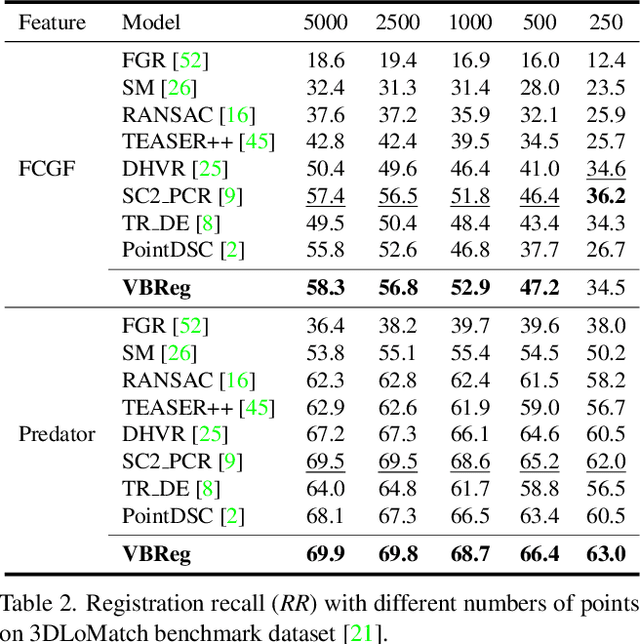
Learning-based outlier (mismatched correspondence) rejection for robust 3D registration generally formulates the outlier removal as an inlier/outlier classification problem. The core for this to be successful is to learn the discriminative inlier/outlier feature representations. In this paper, we develop a novel variational non-local network-based outlier rejection framework for robust alignment. By reformulating the non-local feature learning with variational Bayesian inference, the Bayesian-driven long-range dependencies can be modeled to aggregate discriminative geometric context information for inlier/outlier distinction. Specifically, to achieve such Bayesian-driven contextual dependencies, each query/key/value component in our non-local network predicts a prior feature distribution and a posterior one. Embedded with the inlier/outlier label, the posterior feature distribution is label-dependent and discriminative. Thus, pushing the prior to be close to the discriminative posterior in the training step enables the features sampled from this prior at test time to model high-quality long-range dependencies. Notably, to achieve effective posterior feature guidance, a specific probabilistic graphical model is designed over our non-local model, which lets us derive a variational low bound as our optimization objective for model training. Finally, we propose a voting-based inlier searching strategy to cluster the high-quality hypothetical inliers for transformation estimation. Extensive experiments on 3DMatch, 3DLoMatch, and KITTI datasets verify the effectiveness of our method.
Hierarchical Supervision and Shuffle Data Augmentation for 3D Semi-Supervised Object Detection
Apr 04, 2023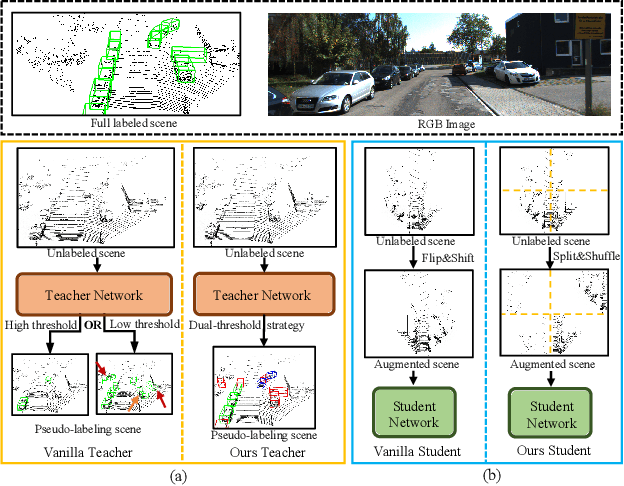

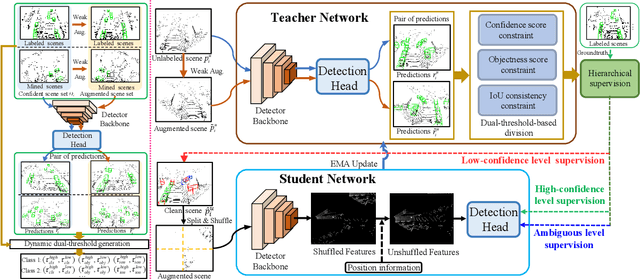

State-of-the-art 3D object detectors are usually trained on large-scale datasets with high-quality 3D annotations. However, such 3D annotations are often expensive and time-consuming, which may not be practical for real applications. A natural remedy is to adopt semi-supervised learning (SSL) by leveraging a limited amount of labeled samples and abundant unlabeled samples. Current pseudolabeling-based SSL object detection methods mainly adopt a teacher-student framework, with a single fixed threshold strategy to generate supervision signals, which inevitably brings confused supervision when guiding the student network training. Besides, the data augmentation of the point cloud in the typical teacher-student framework is too weak, and only contains basic down sampling and flip-and-shift (i.e., rotate and scaling), which hinders the effective learning of feature information. Hence, we address these issues by introducing a novel approach of Hierarchical Supervision and Shuffle Data Augmentation (HSSDA), which is a simple yet effective teacher-student framework. The teacher network generates more reasonable supervision for the student network by designing a dynamic dual-threshold strategy. Besides, the shuffle data augmentation strategy is designed to strengthen the feature representation ability of the student network. Extensive experiments show that HSSDA consistently outperforms the recent state-of-the-art methods on different datasets. The code will be released at https://github.com/azhuantou/HSSDA.
Decentralized Riemannian natural gradient methods with Kronecker-product approximations
Mar 16, 2023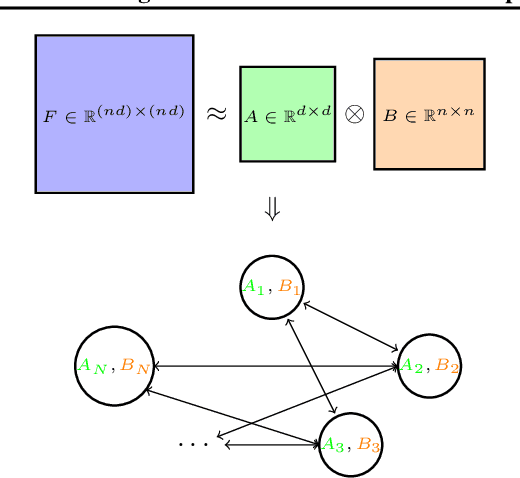
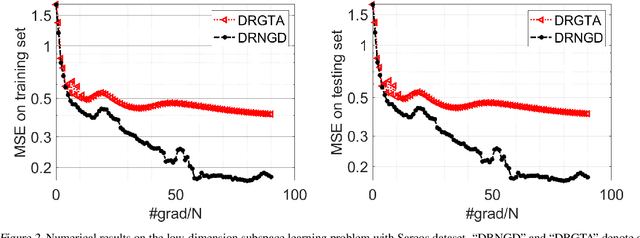
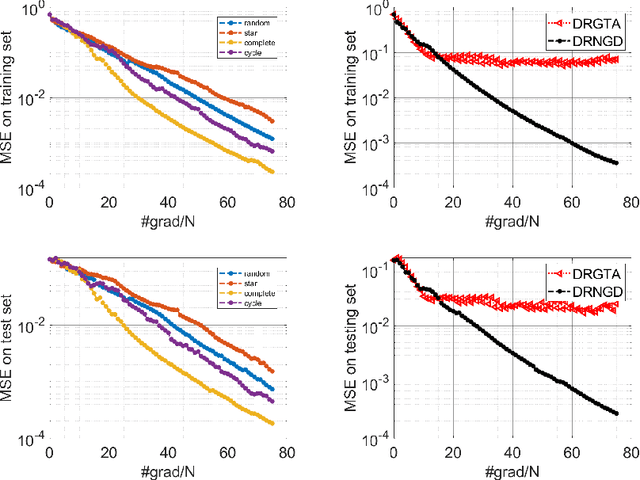

With a computationally efficient approximation of the second-order information, natural gradient methods have been successful in solving large-scale structured optimization problems. We study the natural gradient methods for the large-scale decentralized optimization problems on Riemannian manifolds, where the local objective function defined by the local dataset is of a log-probability type. By utilizing the structure of the Riemannian Fisher information matrix (RFIM), we present an efficient decentralized Riemannian natural gradient descent (DRNGD) method. To overcome the communication issue of the high-dimension RFIM, we consider a class of structured problems for which the RFIM can be approximated by a Kronecker product of two low-dimension matrices. By performing the communications over the Kronecker factors, a high-quality approximation of the RFIM can be obtained in a low cost. We prove that DRNGD converges to a stationary point with the best-known rate of $\mathcal{O}(1/K)$. Numerical experiments demonstrate the efficiency of our proposed method compared with the state-of-the-art ones. To the best of our knowledge, this is the first Riemannian second-order method for solving decentralized manifold optimization problems.
Manually Selecting The Data Function for Supervised Learning of small datasets
Mar 07, 2023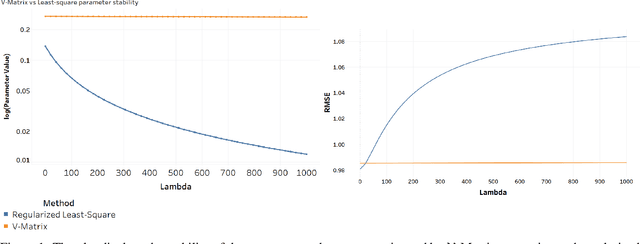
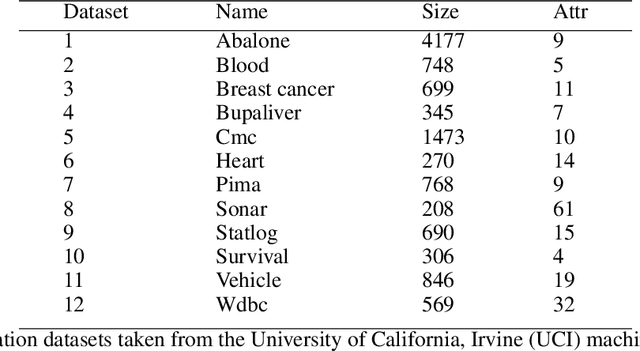
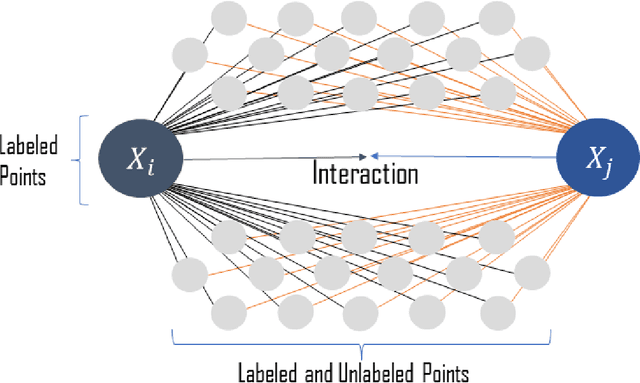
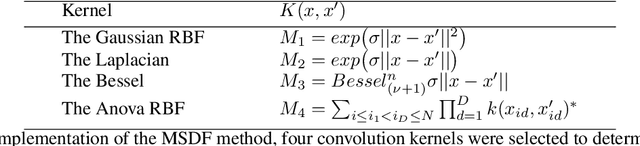
Supervised learning problems may become ill-posed when there is a lack of information, resulting in unstable and non-unique solutions. However, instead of solely relying on regularization, initializing an informative ill-posed operator is akin to posing better questions to achieve more accurate answers. The Fredholm integral equation of the first kind (FIFK) is a reliable ill-posed operator that can integrate distributions and prior knowledge as input information. By incorporating input distributions and prior knowledge, the FIFK operator can address the limitations of using high-dimensional input distributions by semi-supervised assumptions, leading to more precise approximations of the integral operator. Additionally, the FIFK's incorporation of probabilistic principles can further enhance the accuracy and effectiveness of solutions. In cases of noisy operator equations and limited data, the FIFK's flexibility in defining problems using prior information or cross-validation with various kernel designs is especially advantageous. This capability allows for detailed problem definitions and facilitates achieving high levels of accuracy and stability in solutions. In our study, we examined the FIFK through two different approaches. Firstly, we implemented a semi-supervised assumption by using the same Fredholm operator kernel and data function kernel and incorporating unlabeled information. Secondly, we used the MSDF method, which involves selecting different kernels on both sides of the equation to define when the mapping kernel is different from the data function kernel. To assess the effectiveness of the FIFK and the proposed methods in solving ill-posed problems, we conducted experiments on a real-world dataset. Our goal was to compare the performance of these methods against the widely used least-squares method and other comparable methods.
Transformer and Snowball Graph Convolution Learning for Biomedical Graph Classification
Mar 28, 2023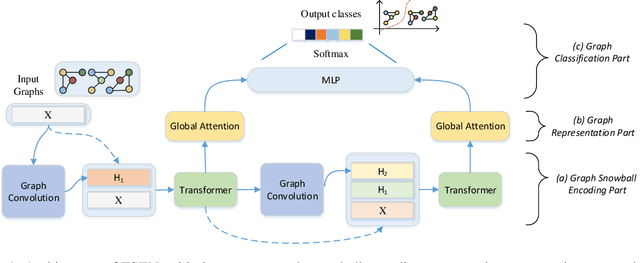
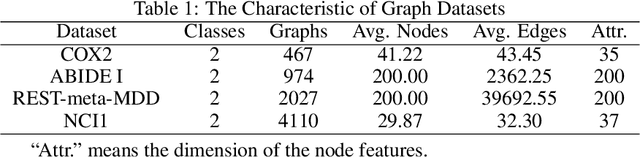
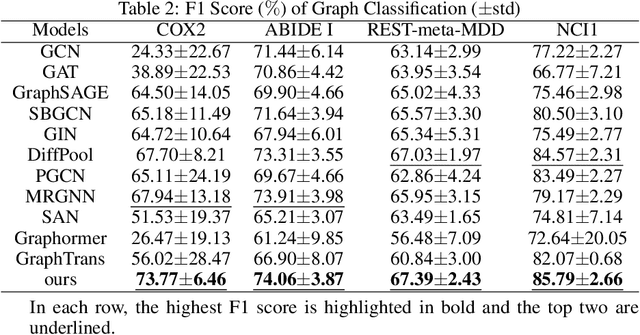

Graph or network has been widely used for describing and modeling complex systems in biomedicine. Deep learning methods, especially graph neural networks (GNNs), have been developed to learn and predict with such structured data. In this paper, we proposed a novel transformer and snowball encoding networks (TSEN) for biomedical graph classification, which introduced transformer architecture with graph snowball connection into GNNs for learning whole-graph representation. TSEN combined graph snowball connection with graph transformer by snowball encoding layers, which enhanced the power to capture multi-scale information and global patterns to learn the whole-graph features. On the other hand, TSEN also used snowball graph convolution as position embedding in transformer structure, which was a simple yet effective method for capturing local patterns naturally. Results of experiments using four graph classification datasets demonstrated that TSEN outperformed the state-of-the-art typical GNN models and the graph-transformer based GNN models.
Fast Latent Factor Analysis via a Fuzzy PID-Incorporated Stochastic Gradient Descent Algorithm
Mar 07, 2023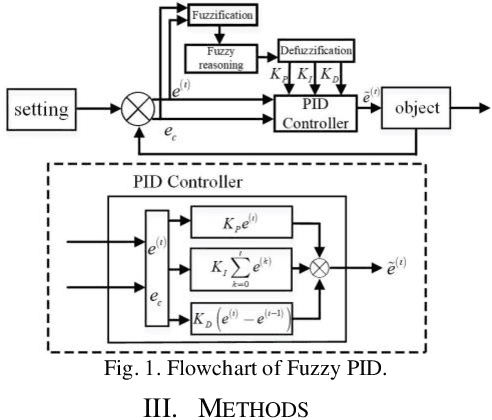

A high-dimensional and incomplete (HDI) matrix can describe the complex interactions among numerous nodes in various big data-related applications. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm learns a latent factor relying on the stochastic gradient of current instance error only without considering past update information. To address this critical issue, this paper innovatively proposes a Fuzzy PID-incorporated SGD (FPS) algorithm with two-fold ideas: 1) rebuilding the instance learning error by considering the past update information in an efficient way following the principle of PID, and 2) implementing hyper-parameters and gain parameters adaptation following the fuzzy rules. With it, an FPS-incorporated LFA model is further achieved for fast processing an HDI matrix. Empirical studies on six HDI datasets demonstrate that the proposed FPS-incorporated LFA model significantly outperforms the state-of-the-art LFA models in terms of computational efficiency for predicting the missing data of an HDI matrix with competitive accuracy.
Data Games: A Game-Theoretic Approach to Swarm Robotic Data Collection
Mar 07, 2023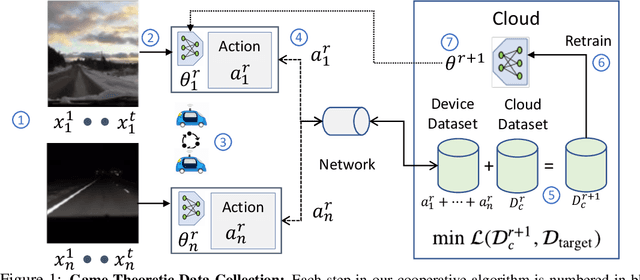
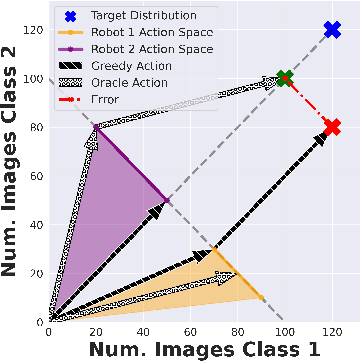
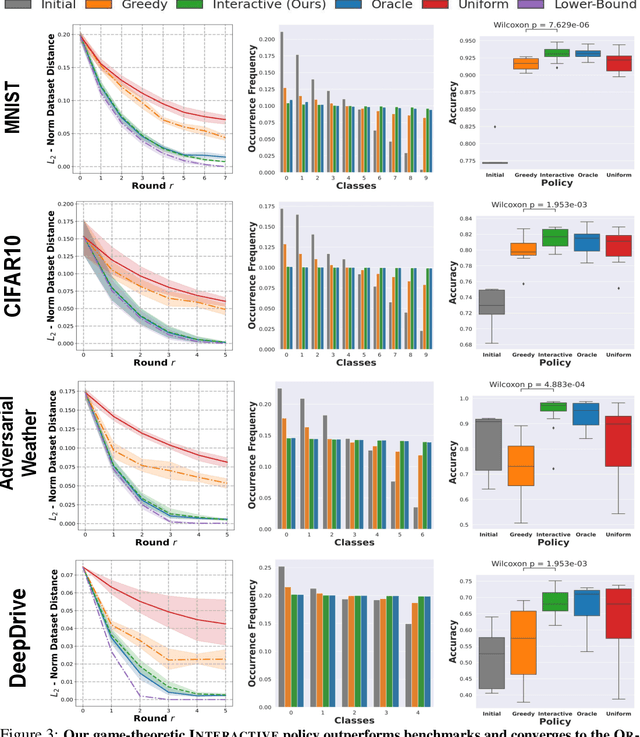
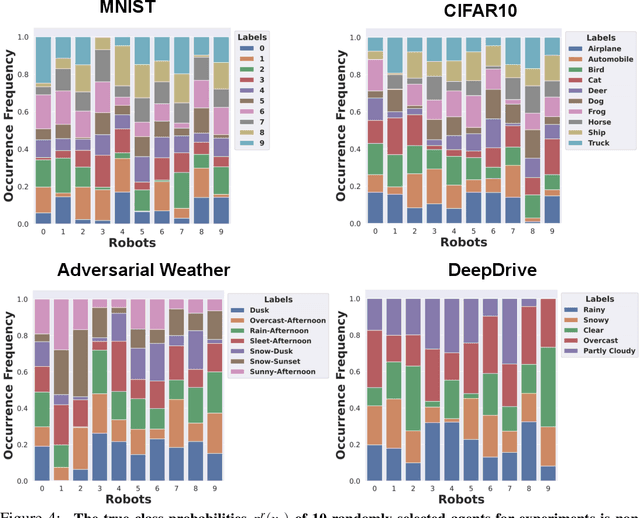
Fleets of networked autonomous vehicles (AVs) collect terabytes of sensory data, which is often transmitted to central servers (the ''cloud'') for training machine learning (ML) models. Ideally, these fleets should upload all their data, especially from rare operating contexts, in order to train robust ML models. However, this is infeasible due to prohibitive network bandwidth and data labeling costs. Instead, we propose a cooperative data sampling strategy where geo-distributed AVs collaborate to collect a diverse ML training dataset in the cloud. Since the AVs have a shared objective but minimal information about each other's local data distribution and perception model, we can naturally cast cooperative data collection as an $N$-player mathematical game. We show that our cooperative sampling strategy uses minimal information to converge to a centralized oracle policy with complete information about all AVs. Moreover, we theoretically characterize the performance benefits of our game-theoretic strategy compared to greedy sampling. Finally, we experimentally demonstrate that our method outperforms standard benchmarks by up to $21.9\%$ on 4 perception datasets, including for autonomous driving in adverse weather conditions. Crucially, our experimental results on real-world datasets closely align with our theoretical guarantees.
Adaptive Skill Coordination for Robotic Mobile Manipulation
Apr 01, 2023
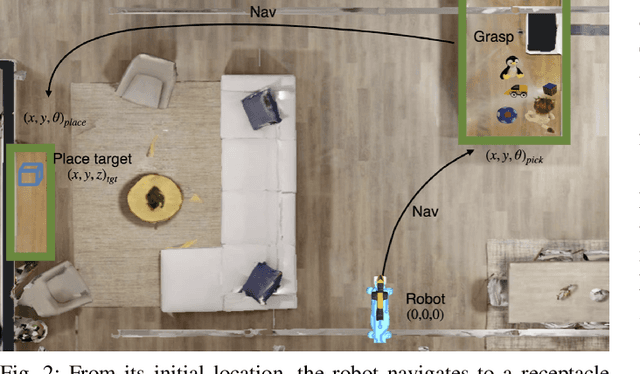
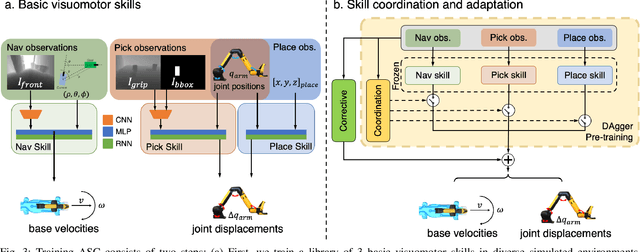

We present Adaptive Skill Coordination (ASC) - an approach for accomplishing long-horizon tasks (e.g., mobile pick-and-place, consisting of navigating to an object, picking it, navigating to another location, placing it, repeating). ASC consists of three components - (1) a library of basic visuomotor skills (navigation, pick, place), (2) a skill coordination policy that chooses which skills are appropriate to use when, and (3) a corrective policy that adapts pre-trained skills when out-of-distribution states are perceived. All components of ASC rely only on onboard visual and proprioceptive sensing, without access to privileged information like pre-built maps or precise object locations, easing real-world deployment. We train ASC in simulated indoor environments, and deploy it zero-shot in two novel real-world environments on the Boston Dynamics Spot robot. ASC achieves near-perfect performance at mobile pick-and-place, succeeding in 59/60 (98%) episodes, while sequentially executing skills succeeds in only 44/60 (73%) episodes. It is robust to hand-off errors, changes in the environment layout, dynamic obstacles (e.g., people), and unexpected disturbances, making it an ideal framework for complex, long-horizon tasks. Supplementary videos available at adaptiveskillcoordination.github.io.