 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Manually Selecting The Data Function for Supervised Learning of small datasets
Mar 07, 2023
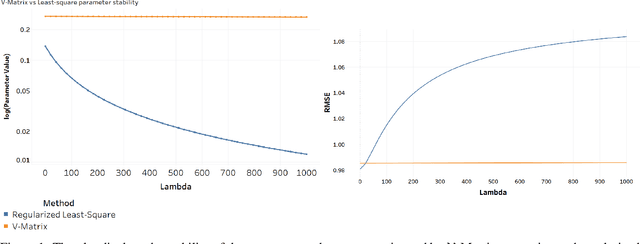
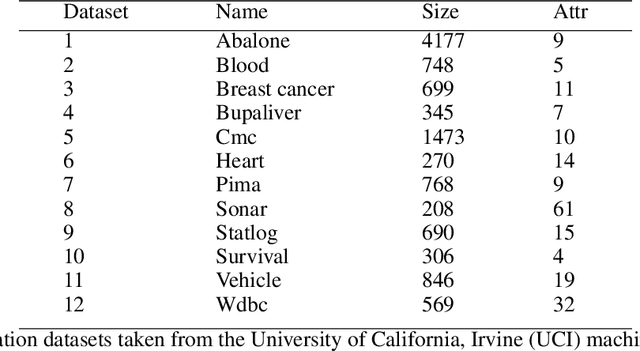
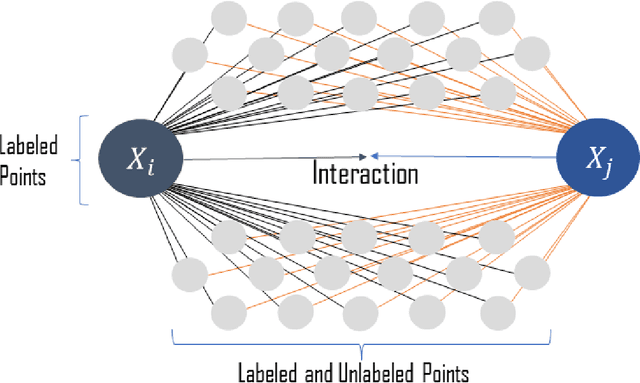
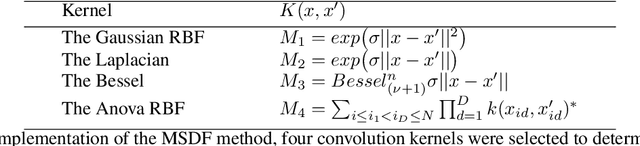
Supervised learning problems may become ill-posed when there is a lack of information, resulting in unstable and non-unique solutions. However, instead of solely relying on regularization, initializing an informative ill-posed operator is akin to posing better questions to achieve more accurate answers. The Fredholm integral equation of the first kind (FIFK) is a reliable ill-posed operator that can integrate distributions and prior knowledge as input information. By incorporating input distributions and prior knowledge, the FIFK operator can address the limitations of using high-dimensional input distributions by semi-supervised assumptions, leading to more precise approximations of the integral operator. Additionally, the FIFK's incorporation of probabilistic principles can further enhance the accuracy and effectiveness of solutions. In cases of noisy operator equations and limited data, the FIFK's flexibility in defining problems using prior information or cross-validation with various kernel designs is especially advantageous. This capability allows for detailed problem definitions and facilitates achieving high levels of accuracy and stability in solutions. In our study, we examined the FIFK through two different approaches. Firstly, we implemented a semi-supervised assumption by using the same Fredholm operator kernel and data function kernel and incorporating unlabeled information. Secondly, we used the MSDF method, which involves selecting different kernels on both sides of the equation to define when the mapping kernel is different from the data function kernel. To assess the effectiveness of the FIFK and the proposed methods in solving ill-posed problems, we conducted experiments on a real-world dataset. Our goal was to compare the performance of these methods against the widely used least-squares method and other comparable methods.
Model-Agnostic Decentralized Collaborative Learning for On-Device POI Recommendation
Apr 08, 2023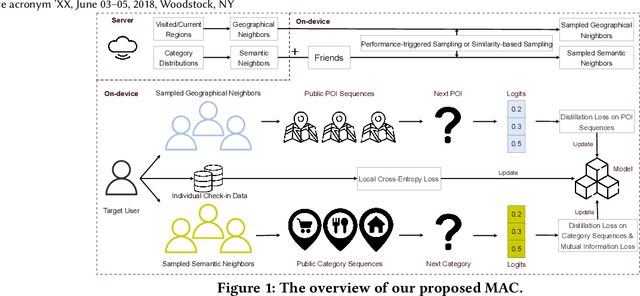
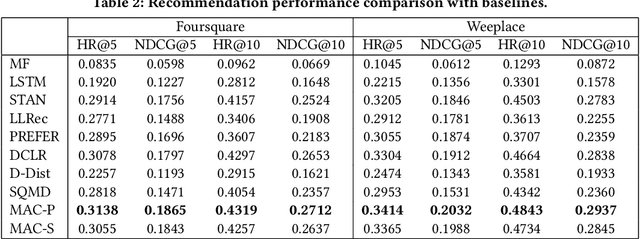
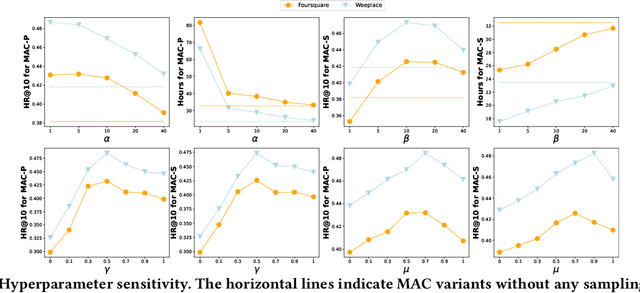
As an indispensable personalized service in Location-based Social Networks (LBSNs), the next Point-of-Interest (POI) recommendation aims to help people discover attractive and interesting places. Currently, most POI recommenders are based on the conventional centralized paradigm that heavily relies on the cloud to train the recommendation models with large volumes of collected users' sensitive check-in data. Although a few recent works have explored on-device frameworks for resilient and privacy-preserving POI recommendations, they invariably hold the assumption of model homogeneity for parameters/gradients aggregation and collaboration. However, users' mobile devices in the real world have various hardware configurations (e.g., compute resources), leading to heterogeneous on-device models with different architectures and sizes. In light of this, We propose a novel on-device POI recommendation framework, namely Model-Agnostic Collaborative learning for on-device POI recommendation (MAC), allowing users to customize their own model structures (e.g., dimension \& number of hidden layers). To counteract the sparsity of on-device user data, we propose to pre-select neighbors for collaboration based on physical distances, category-level preferences, and social networks. To assimilate knowledge from the above-selected neighbors in an efficient and secure way, we adopt the knowledge distillation framework with mutual information maximization. Instead of sharing sensitive models/gradients, clients in MAC only share their soft decisions on a preloaded reference dataset. To filter out low-quality neighbors, we propose two sampling strategies, performance-triggered sampling and similarity-based sampling, to speed up the training process and obtain optimal recommenders. In addition, we design two novel approaches to generate more effective reference datasets while protecting users' privacy.
Deep Fair Clustering via Maximizing and Minimizing Mutual Information
Sep 26, 2022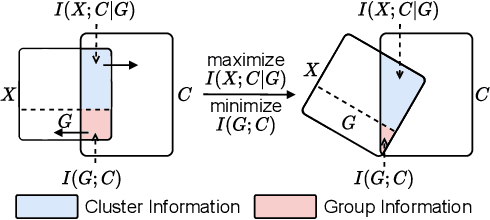
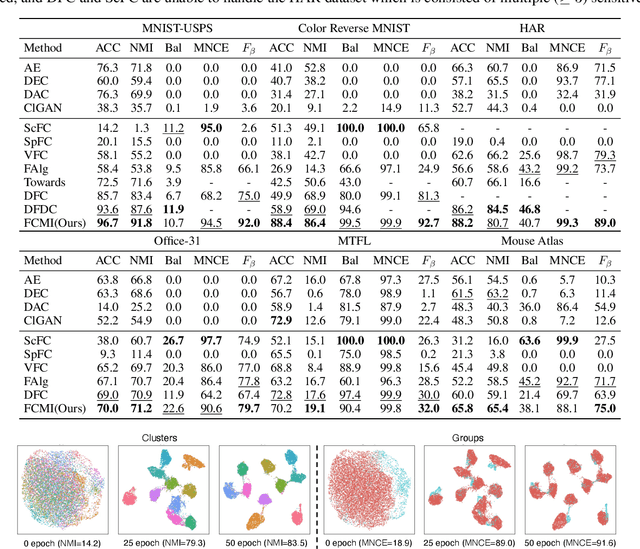
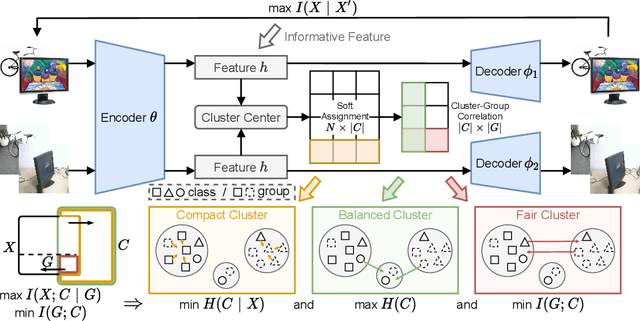
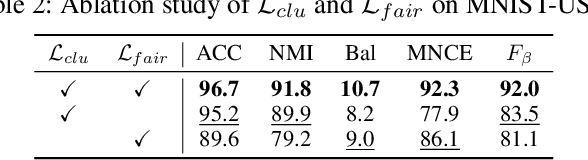
Fair clustering aims to divide data into distinct clusters, while preventing sensitive attributes (e.g., gender, race, RNA sequencing technique) from dominating the clustering. Although a number of works have been conducted and achieved huge success in recent, most of them are heuristical, and there lacks a unified theory for algorithm design. In this work, we fill this blank by developing a mutual information theory for deep fair clustering and accordingly designing a novel algorithm, dubbed FCMI. In brief, through maximizing and minimizing mutual information, FCMI is designed to achieve four characteristics highly expected by deep fair clustering, i.e., compact, balanced, and fair clusters, as well as informative features. Besides the contributions to theory and algorithm, another contribution of this work is proposing a novel fair clustering metric built upon information theory as well. Unlike existing evaluation metrics, our metric measures the clustering quality and fairness in a whole instead of separate manner. To verify the effectiveness of the proposed FCMI, we carry out experiments on six benchmarks including a single-cell RNA-seq atlas compared with 11 state-of-the-art methods in terms of five metrics. Code will be released after the acceptance.
Supervised classification methods applied to airborne hyperspectral images: Comparative study using mutual information
Oct 27, 2022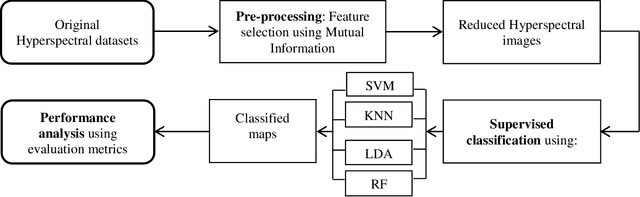
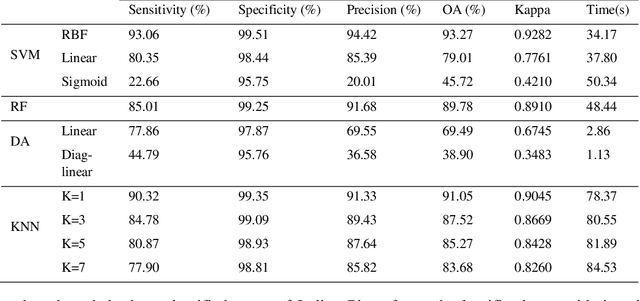
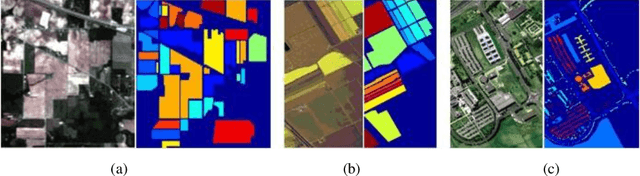
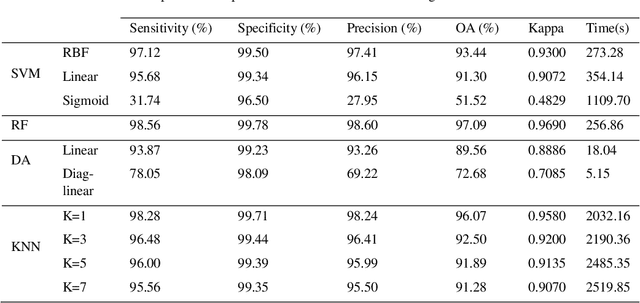
Nowadays, the hyperspectral remote sensing imagery HSI becomes an important tool to observe the Earth's surface, detect the climatic changes and many other applications. The classification of HSI is one of the most challenging tasks due to the large amount of spectral information and the presence of redundant and irrelevant bands. Although great progresses have been made on classification techniques, few studies have been done to provide practical guidelines to determine the appropriate classifier for HSI. In this paper, we investigate the performance of four supervised learning algorithms, namely, Support Vector Machines SVM, Random Forest RF, K-Nearest Neighbors KNN and Linear Discriminant Analysis LDA with different kernels in terms of classification accuracies. The experiments have been performed on three real hyperspectral datasets taken from the NASA's Airborne Visible/Infrared Imaging Spectrometer Sensor AVIRIS and the Reflective Optics System Imaging Spectrometer ROSIS sensors. The mutual information had been used to reduce the dimensionality of the used datasets for better classification efficiency. The extensive experiments demonstrate that the SVM classifier with RBF kernel and RF produced statistically better results and seems to be respectively the more suitable as supervised classifiers for the hyperspectral remote sensing images. Keywords: hyperspectral images, mutual information, dimension reduction, Support Vector Machines, K-Nearest Neighbors, Random Forest, Linear Discriminant Analysis.
GVP: Generative Volumetric Primitives
Mar 31, 2023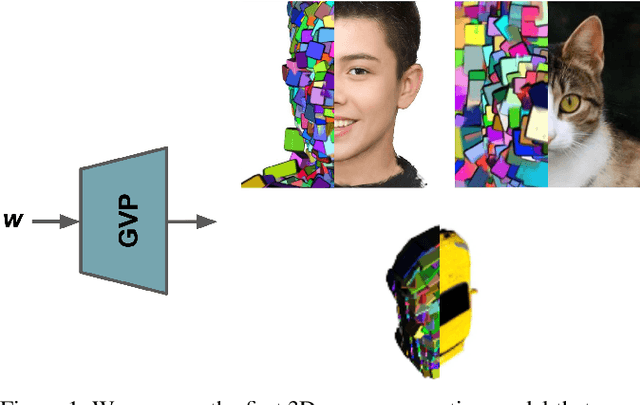
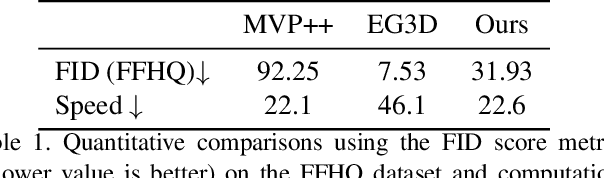
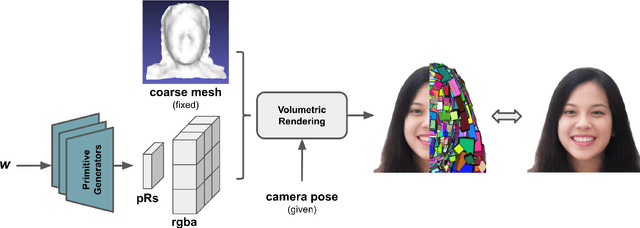

Advances in 3D-aware generative models have pushed the boundary of image synthesis with explicit camera control. To achieve high-resolution image synthesis, several attempts have been made to design efficient generators, such as hybrid architectures with both 3D and 2D components. However, such a design compromises multiview consistency, and the design of a pure 3D generator with high resolution is still an open problem. In this work, we present Generative Volumetric Primitives (GVP), the first pure 3D generative model that can sample and render 512-resolution images in real-time. GVP jointly models a number of volumetric primitives and their spatial information, both of which can be efficiently generated via a 2D convolutional network. The mixture of these primitives naturally captures the sparsity and correspondence in the 3D volume. The training of such a generator with a high degree of freedom is made possible through a knowledge distillation technique. Experiments on several datasets demonstrate superior efficiency and 3D consistency of GVP over the state-of-the-art.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023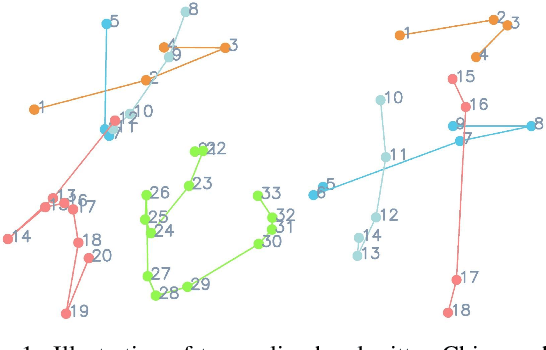
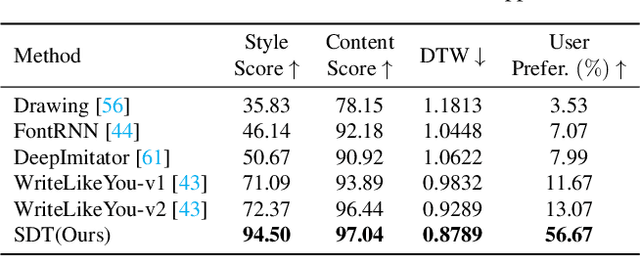

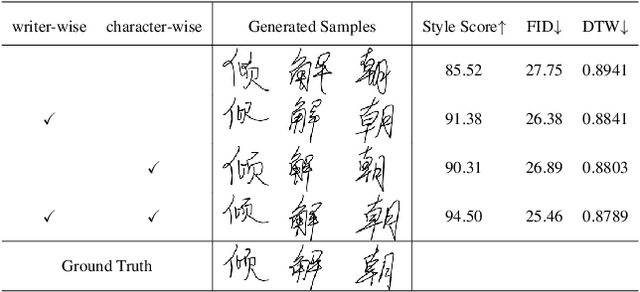
Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Automatic Detection of Out-of-body Frames in Surgical Videos for Privacy Protection Using Self-supervised Learning and Minimal Labels
Mar 31, 2023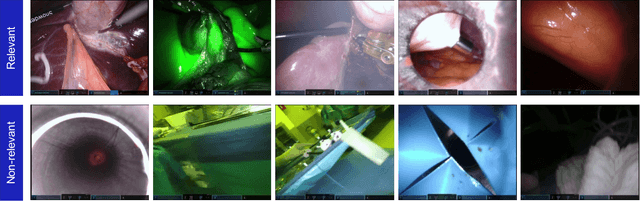
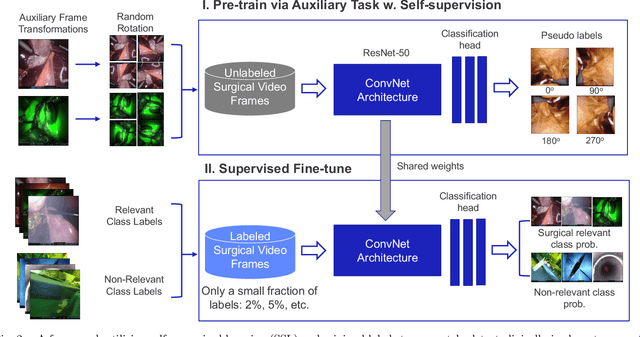
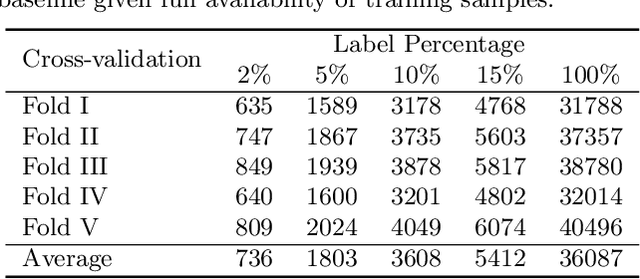
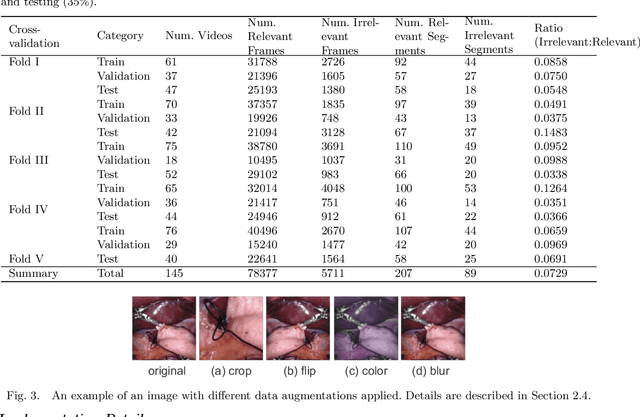
Endoscopic video recordings are widely used in minimally invasive robot-assisted surgery, but when the endoscope is outside the patient's body, it can capture irrelevant segments that may contain sensitive information. To address this, we propose a framework that accurately detects out-of-body frames in surgical videos by leveraging self-supervision with minimal data labels. We use a massive amount of unlabeled endoscopic images to learn meaningful representations in a self-supervised manner. Our approach, which involves pre-training on an auxiliary task and fine-tuning with limited supervision, outperforms previous methods for detecting out-of-body frames in surgical videos captured from da Vinci X and Xi surgical systems. The average F1 scores range from 96.00 to 98.02. Remarkably, using only 5% of the training labels, our approach still maintains an average F1 score performance above 97, outperforming fully-supervised methods with 95% fewer labels. These results demonstrate the potential of our framework to facilitate the safe handling of surgical video recordings and enhance data privacy protection in minimally invasive surgery.
Learning to Tokenize for Generative Retrieval
Apr 09, 2023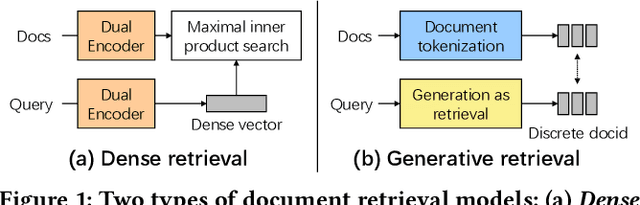
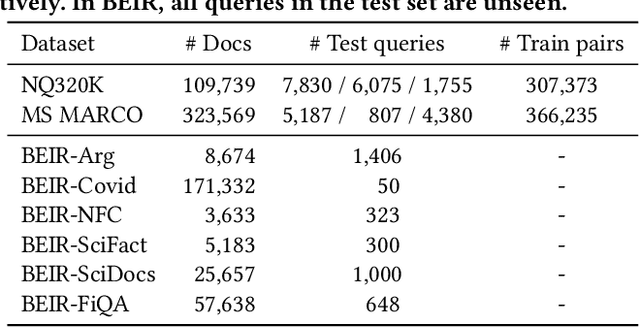
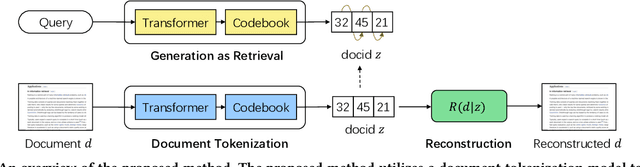
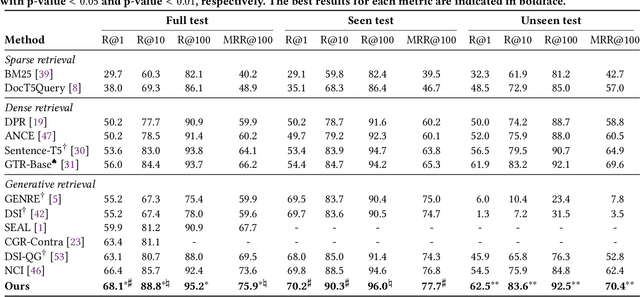
Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.
Fast Latent Factor Analysis via a Fuzzy PID-Incorporated Stochastic Gradient Descent Algorithm
Mar 07, 2023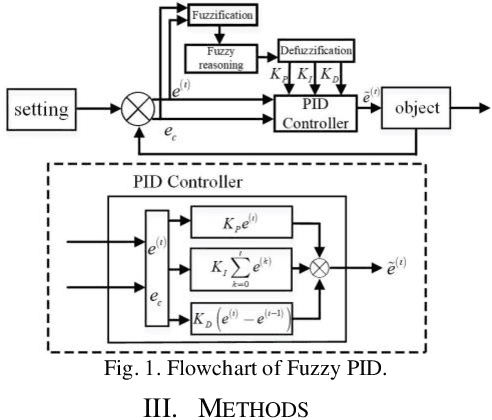

A high-dimensional and incomplete (HDI) matrix can describe the complex interactions among numerous nodes in various big data-related applications. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm learns a latent factor relying on the stochastic gradient of current instance error only without considering past update information. To address this critical issue, this paper innovatively proposes a Fuzzy PID-incorporated SGD (FPS) algorithm with two-fold ideas: 1) rebuilding the instance learning error by considering the past update information in an efficient way following the principle of PID, and 2) implementing hyper-parameters and gain parameters adaptation following the fuzzy rules. With it, an FPS-incorporated LFA model is further achieved for fast processing an HDI matrix. Empirical studies on six HDI datasets demonstrate that the proposed FPS-incorporated LFA model significantly outperforms the state-of-the-art LFA models in terms of computational efficiency for predicting the missing data of an HDI matrix with competitive accuracy.
Data Games: A Game-Theoretic Approach to Swarm Robotic Data Collection
Mar 07, 2023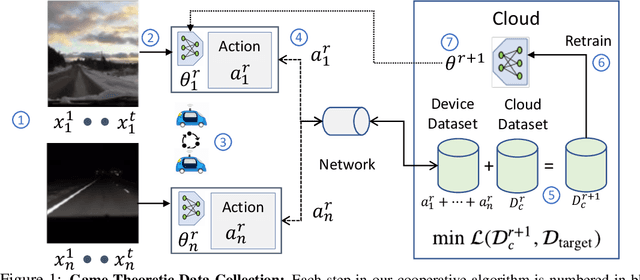
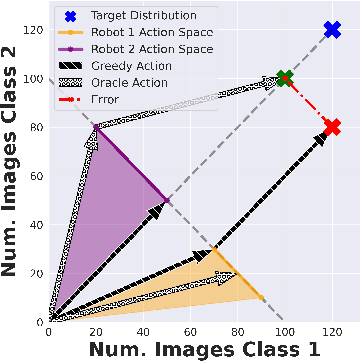
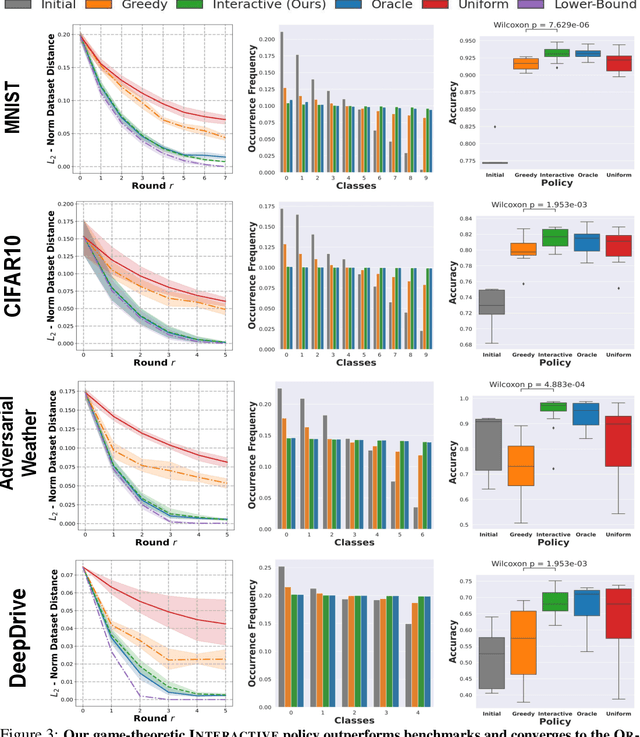
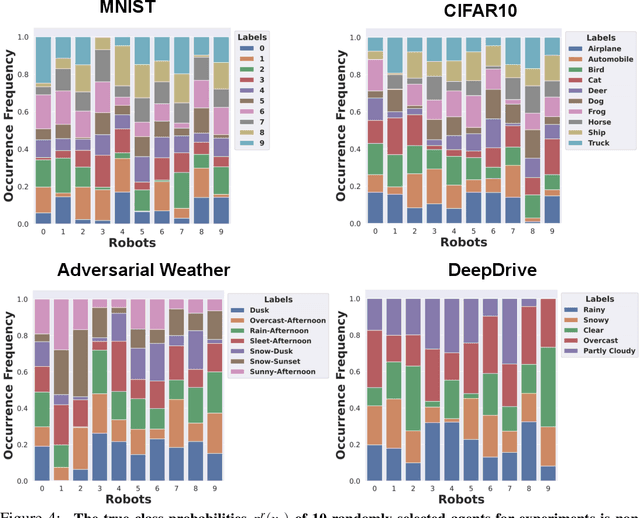
Fleets of networked autonomous vehicles (AVs) collect terabytes of sensory data, which is often transmitted to central servers (the ''cloud'') for training machine learning (ML) models. Ideally, these fleets should upload all their data, especially from rare operating contexts, in order to train robust ML models. However, this is infeasible due to prohibitive network bandwidth and data labeling costs. Instead, we propose a cooperative data sampling strategy where geo-distributed AVs collaborate to collect a diverse ML training dataset in the cloud. Since the AVs have a shared objective but minimal information about each other's local data distribution and perception model, we can naturally cast cooperative data collection as an $N$-player mathematical game. We show that our cooperative sampling strategy uses minimal information to converge to a centralized oracle policy with complete information about all AVs. Moreover, we theoretically characterize the performance benefits of our game-theoretic strategy compared to greedy sampling. Finally, we experimentally demonstrate that our method outperforms standard benchmarks by up to $21.9\%$ on 4 perception datasets, including for autonomous driving in adverse weather conditions. Crucially, our experimental results on real-world datasets closely align with our theoretical guarantees.