 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Reuse and Recycling of Lithium-ion Batteries: Tele-robotics for Disassembly of Electric Vehicle Batteries
Apr 03, 2023
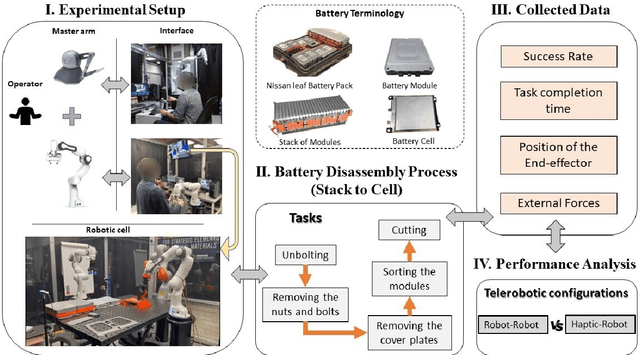
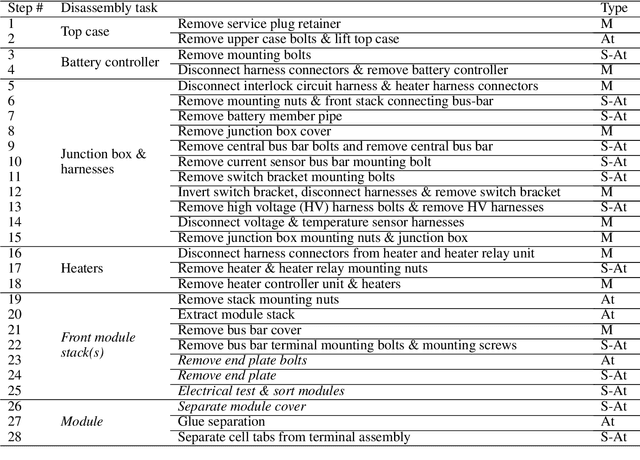


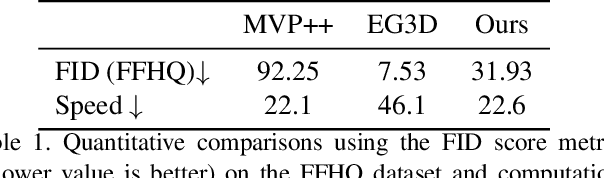
Disassembly of electric vehicle batteries is a critical stage in recovery, recycling and re-use of high-value battery materials, but is complicated by limited standardisation, design complexity, compounded by uncertainty and safety issues from varying end-of-life condition. Telerobotics presents an avenue for semi-autonomous robotic disassembly that addresses these challenges. However, it is suggested that quality and realism of the user's haptic interactions with the environment is important for precise, contact-rich and safety-critical tasks. To investigate this proposition, we demonstrate the disassembly of a Nissan Leaf 2011 module stack as a basis for a comparative study between a traditional asymmetric haptic-'cobot' master-slave framework and identical master and slave cobots based on task completion time and success rate metrics. We demonstrate across a range of disassembly tasks a time reduction of 22%-57% is achieved using identical cobots, yet this improvement arises chiefly from an expanded workspace and 1:1 positional mapping, and suffers a 10-30% reduction in first attempt success rate. For unbolting and grasping, the realism of force feedback was comparatively less important than directional information encoded in the interaction, however, 1:1 force mapping strengthened environmental tactile cues for vacuum pick-and-place and contact cutting tasks.
smProbLog: Stable Model Semantics in ProbLog for Probabilistic Argumentation
Apr 03, 2023
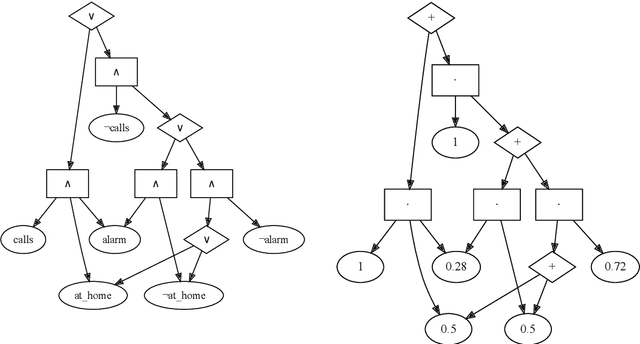

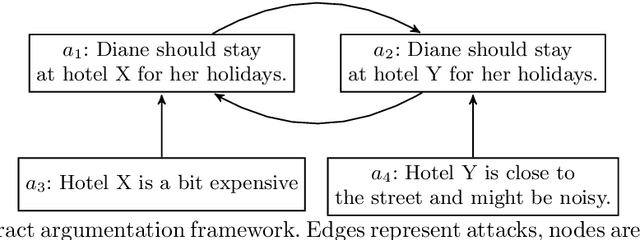
Argumentation problems are concerned with determining the acceptability of a set of arguments from their relational structure. When the available information is uncertain, probabilistic argumentation frameworks provide modelling tools to account for it. The first contribution of this paper is a novel interpretation of probabilistic argumentation frameworks as probabilistic logic programs. Probabilistic logic programs are logic programs in which some of the facts are annotated with probabilities. We show that the programs representing probabilistic argumentation frameworks do not satisfy a common assumption in probabilistic logic programming (PLP) semantics, which is, that probabilistic facts fully capture the uncertainty in the domain under investigation. The second contribution of this paper is then a novel PLP semantics for programs where a choice of probabilistic facts does not uniquely determine the truth assignment of the logical atoms. The third contribution of this paper is the implementation of a PLP system supporting this semantics: smProbLog. smProbLog is a novel PLP framework based on the probabilistic logic programming language ProbLog. smProbLog supports many inference and learning tasks typical of PLP, which, together with our first contribution, provide novel reasoning tools for probabilistic argumentation. We evaluate our approach with experiments analyzing the computational cost of the proposed algorithms and their application to a dataset of argumentation problems.
Joint Device Activity Detection, Channel Estimation and Signal Detection for Massive Grant-free Access via BiGAMP
Apr 03, 2023
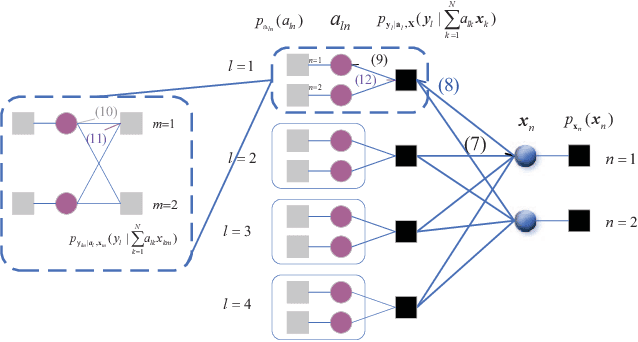
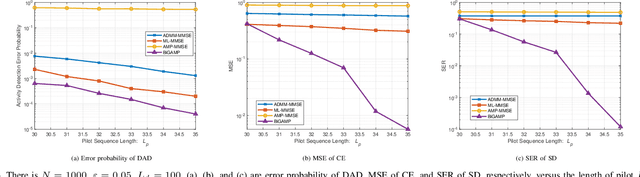
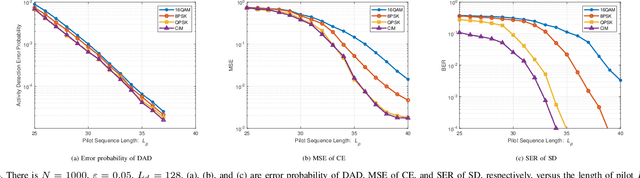
Massive access has been challenging for the fifth generation (5G) and beyond since the abundance of devices causes communication overload to skyrocket. In an uplink massive access scenario, device traffic is sporadic in any given coherence time. Thus, channels across the antennas of each device exhibit correlation, which can be characterized by the row sparse channel matrix structure. In this work, we develop a bilinear generalized approximate message passing (BiGAMP) algorithm based on the row sparse channel matrix structure. This algorithm can jointly detect device activities, estimate channels, and detect signals in massive multiple-input multiple-output (MIMO) systems by alternating updates between channel matrices and signal matrices. The signal observation provides additional information for performance improvement compared to the existing algorithms. We further analyze state evolution (SE) to measure the performance of the proposed algorithm and characterize the convergence condition for SE. Moreover, we perform theoretical analysis on the error probability of device activity detection, the mean square error of channel estimation, and the symbol error rate of signal detection. The numerical results demonstrate the superiority of the proposed algorithm over the state-of-the-art methods in DADCE-SD, and the numerical results are relatively close to the theoretical analysis results.
Lithium-ion Battery Online Knee Onset Detection by Matrix Profile
Apr 03, 2023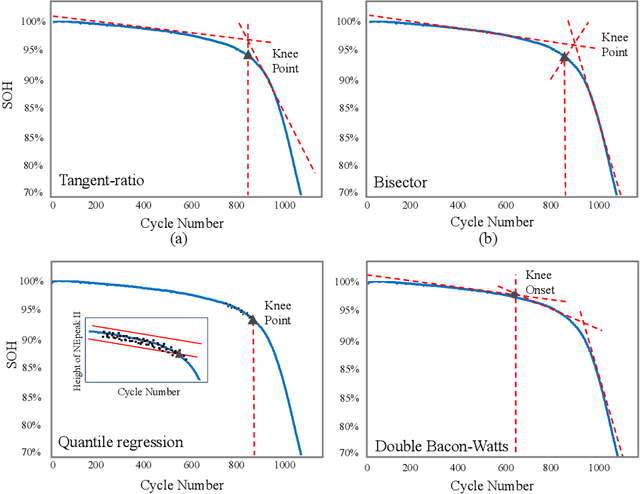
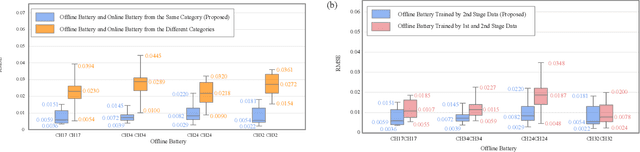
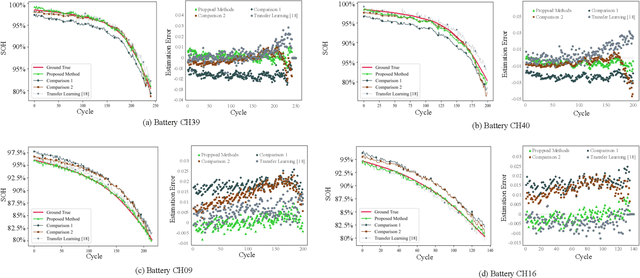

Lithium-ion batteries (LiBs) degrade slightly until the knee onset, after which the deterioration accelerates to end of life (EOL). The knee onset, which marks the initiation of the accelerated degradation rate, is crucial in providing an early warning of the battery's performance changes. However, there is only limited literature on online knee onset identification. Furthermore, it is good to perform such identification using easily collected measurements. To solve these challenges, an online knee onset identification method is developed by exploiting the temporal information within the discharge data. First, the temporal dynamics embedded in the discharge voltage cycles from the slight degradation stage are extracted by the dynamic time warping. Second, the anomaly is exposed by Matrix Profile during subsequence similarity search. The knee onset is detected when the temporal dynamics of the new cycle exceed the control limit and the profile index indicates a change in regime. Finally, the identified knee onset is utilized to categorize the battery into long-range or short-range categories by its strong correlation with the battery's EOL cycles. With the support of the battery categorization and the training data acquired under the same statistic distribution, the proposed SOH estimation model achieves enhanced estimation results with a root mean squared error as low as 0.22%.
GVP: Generative Volumetric Primitives
Mar 31, 2023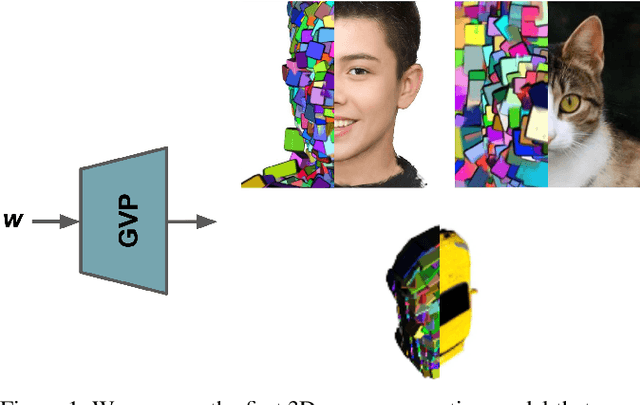
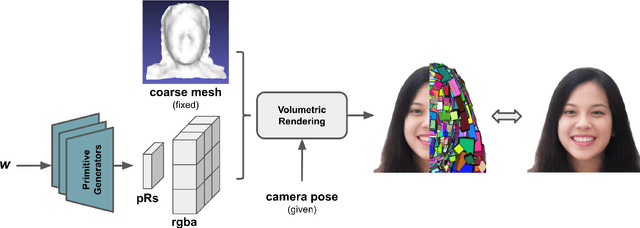

Advances in 3D-aware generative models have pushed the boundary of image synthesis with explicit camera control. To achieve high-resolution image synthesis, several attempts have been made to design efficient generators, such as hybrid architectures with both 3D and 2D components. However, such a design compromises multiview consistency, and the design of a pure 3D generator with high resolution is still an open problem. In this work, we present Generative Volumetric Primitives (GVP), the first pure 3D generative model that can sample and render 512-resolution images in real-time. GVP jointly models a number of volumetric primitives and their spatial information, both of which can be efficiently generated via a 2D convolutional network. The mixture of these primitives naturally captures the sparsity and correspondence in the 3D volume. The training of such a generator with a high degree of freedom is made possible through a knowledge distillation technique. Experiments on several datasets demonstrate superior efficiency and 3D consistency of GVP over the state-of-the-art.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023
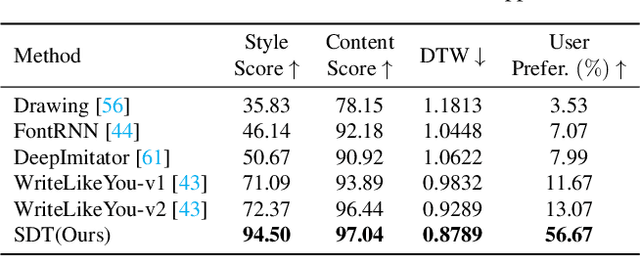

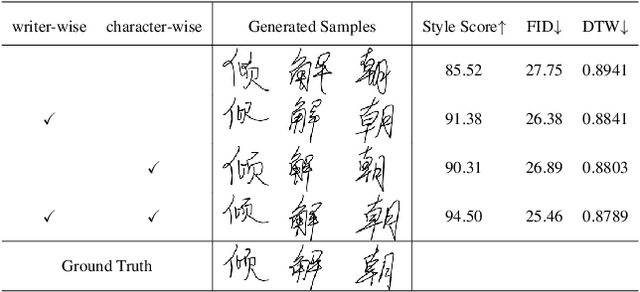
Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Automatic Detection of Out-of-body Frames in Surgical Videos for Privacy Protection Using Self-supervised Learning and Minimal Labels
Mar 31, 2023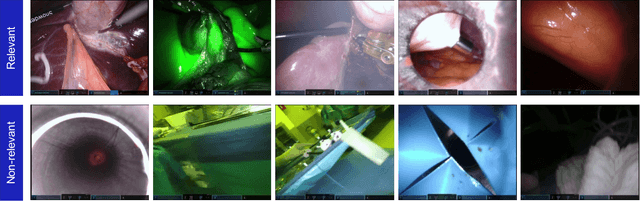
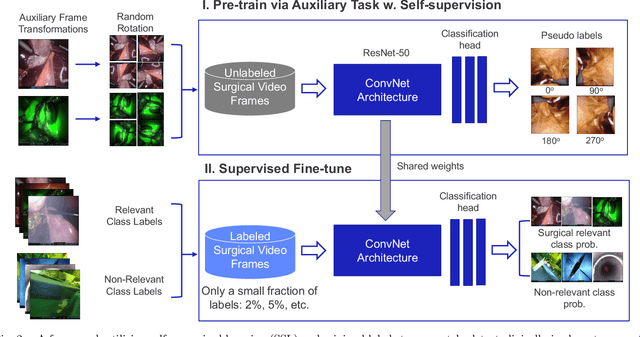
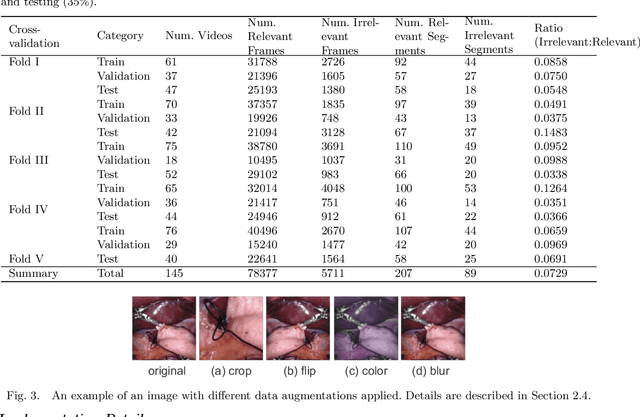
Endoscopic video recordings are widely used in minimally invasive robot-assisted surgery, but when the endoscope is outside the patient's body, it can capture irrelevant segments that may contain sensitive information. To address this, we propose a framework that accurately detects out-of-body frames in surgical videos by leveraging self-supervision with minimal data labels. We use a massive amount of unlabeled endoscopic images to learn meaningful representations in a self-supervised manner. Our approach, which involves pre-training on an auxiliary task and fine-tuning with limited supervision, outperforms previous methods for detecting out-of-body frames in surgical videos captured from da Vinci X and Xi surgical systems. The average F1 scores range from 96.00 to 98.02. Remarkably, using only 5% of the training labels, our approach still maintains an average F1 score performance above 97, outperforming fully-supervised methods with 95% fewer labels. These results demonstrate the potential of our framework to facilitate the safe handling of surgical video recordings and enhance data privacy protection in minimally invasive surgery.
Dynamic Graph Neural Network with Adaptive Edge Attributes for Air Quality Predictions
Feb 20, 2023
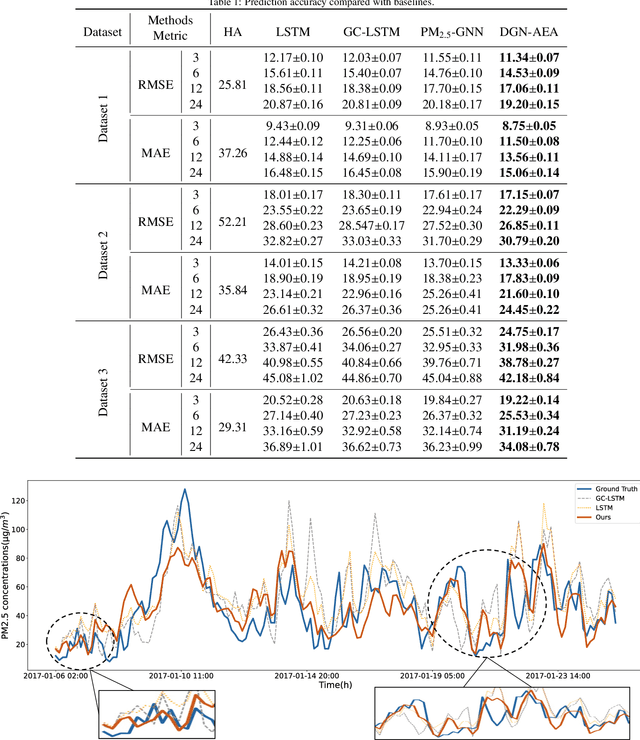
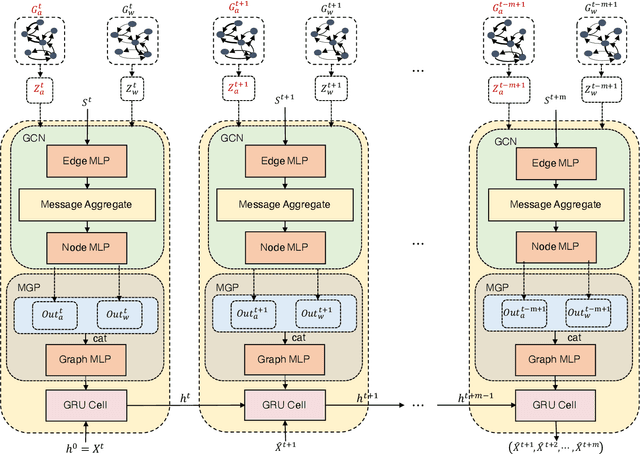
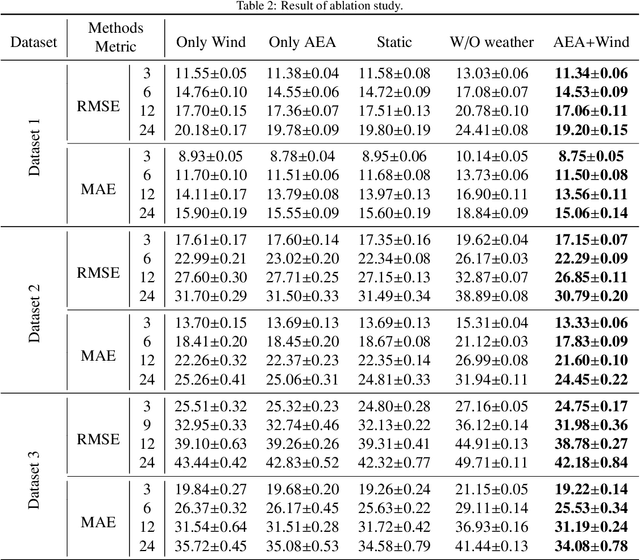
Air quality prediction is a typical spatio-temporal modeling problem, which always uses different components to handle spatial and temporal dependencies in complex systems separately. Previous models based on time series analysis and Recurrent Neural Network (RNN) methods have only modeled time series while ignoring spatial information. Previous GCNs-based methods usually require providing spatial correlation graph structure of observation sites in advance. The correlations among these sites and their strengths are usually calculated using prior information. However, due to the limitations of human cognition, limited prior information cannot reflect the real station-related structure or bring more effective information for accurate prediction. To this end, we propose a novel Dynamic Graph Neural Network with Adaptive Edge Attributes (DGN-AEA) on the message passing network, which generates the adaptive bidirected dynamic graph by learning the edge attributes as model parameters. Unlike prior information to establish edges, our method can obtain adaptive edge information through end-to-end training without any prior information. Thus reduced the complexity of the problem. Besides, the hidden structural information between the stations can be obtained as model by-products, which can help make some subsequent decision-making analyses. Experimental results show that our model received state-of-the-art performance than other baselines.
Localization-based OFDM framework for RIS-aided systems
Mar 22, 2023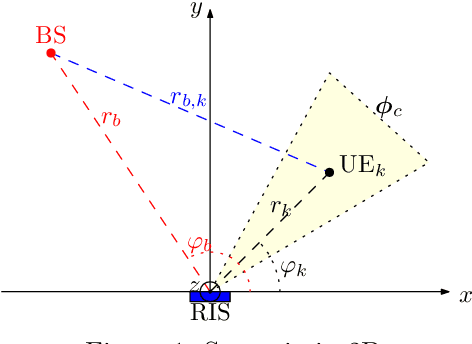
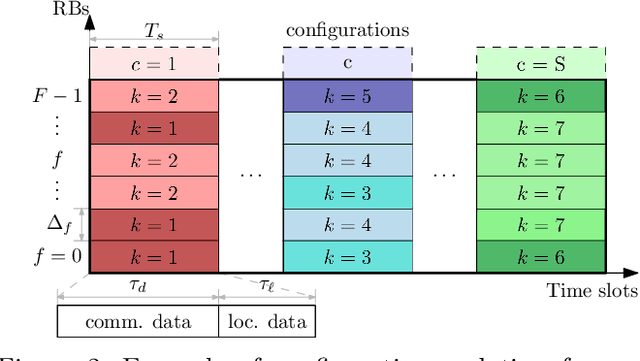
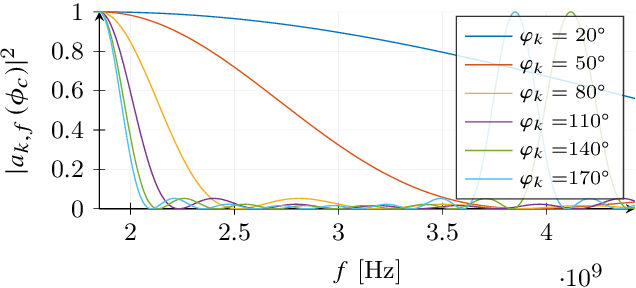
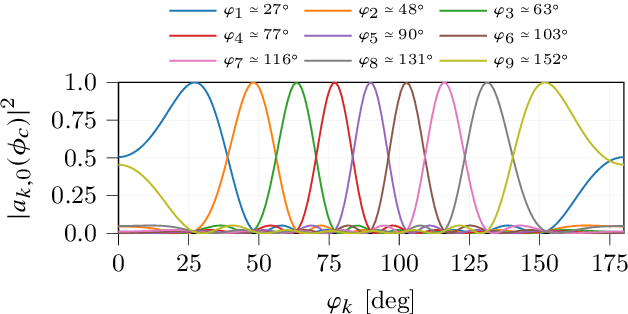
Efficient integration of reconfigurable intelligent surfaces (RISs) into the current wireless network standard is not a trivial task due to the overhead generated by performing channel estimation (CE) and phase-shift optimization. In this paper, we propose a framework enabling the coexistence between orthogonal-frequency division multiplexing (OFDM) and RIS technologies. Instead of wasting communication symbols for the CE and optimization, the proposed framework exploits the localization information obtainable by RIS-aided communications to provide a robust allocation strategy for user multiplexing. The results demonstrate the effectiveness of the proposed approach with respect to CE-based transmission methods.
Why and When: Understanding System Initiative during Conversational Collaborative Search
Mar 23, 2023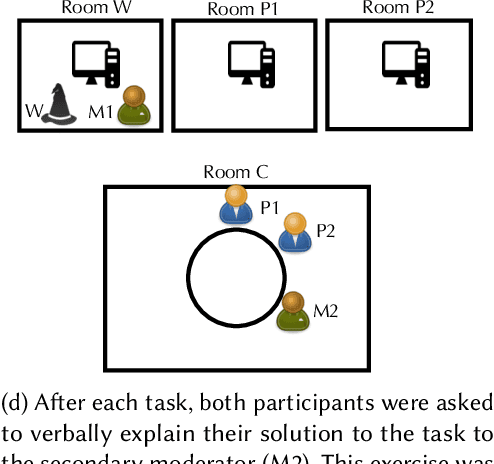
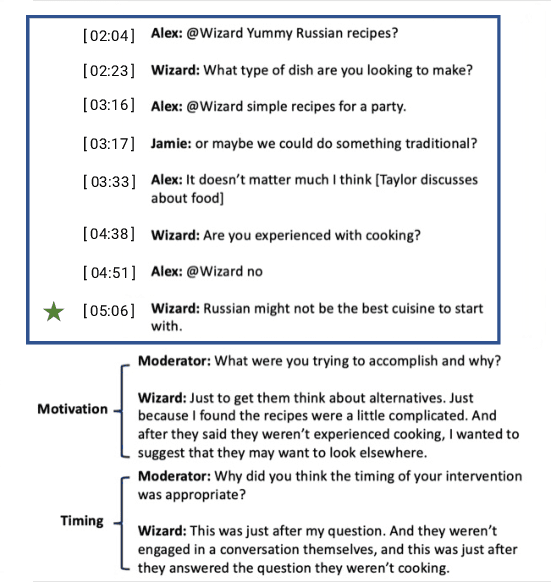
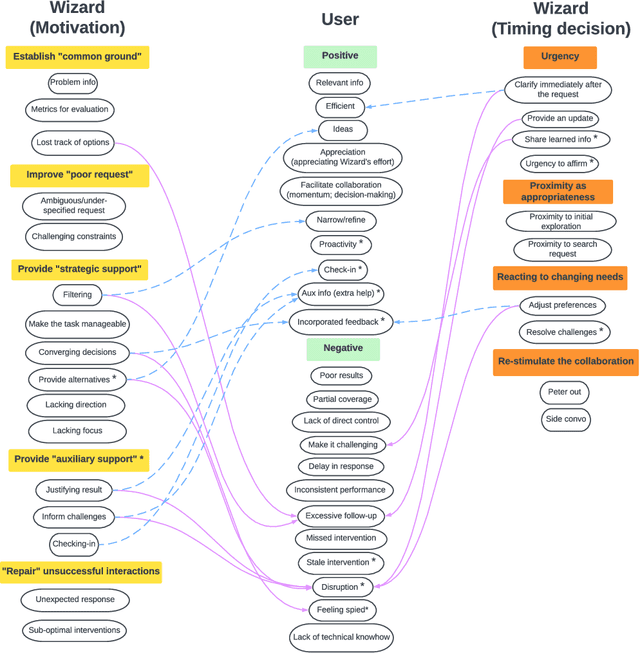
In the last decade, conversational search has attracted considerable attention. However, most research has focused on systems that can support a \emph{single} searcher. In this paper, we explore how systems can support \emph{multiple} searchers collaborating over an instant messaging platform (i.e., Slack). We present a ``Wizard of Oz'' study in which 27 participant pairs collaborated on three information-seeking tasks over Slack. Participants were unable to search on their own and had to gather information by interacting with a \emph{searchbot} directly from the Slack channel. The role of the searchbot was played by a reference librarian. Conversational search systems must be capable of engaging in \emph{mixed-initiative} interaction by taking and relinquishing control of the conversation to fulfill different objectives. Discourse analysis research suggests that conversational agents can take \emph{two} levels of initiative: dialog- and task-level initiative. Agents take dialog-level initiative to establish mutual belief between agents and task-level initiative to influence the goals of the other agents. During the study, participants were exposed to three experimental conditions in which the searchbot could take different levels of initiative: (1) no initiative, (2) only dialog-level initiative, and (3) both dialog- and task-level initiative. In this paper, we focus on understanding the Wizard's actions. Specifically, we focus on understanding the Wizard's motivations for taking initiative and their rationale for the timing of each intervention. To gain insights about the Wizard's actions, we conducted a stimulated recall interview with the Wizard. We present findings from a qualitative analysis of this interview data and discuss implications for designing conversational search systems to support collaborative search.