 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Graph Neural Network with Adaptive Edge Attributes for Air Quality Predictions
Feb 20, 2023
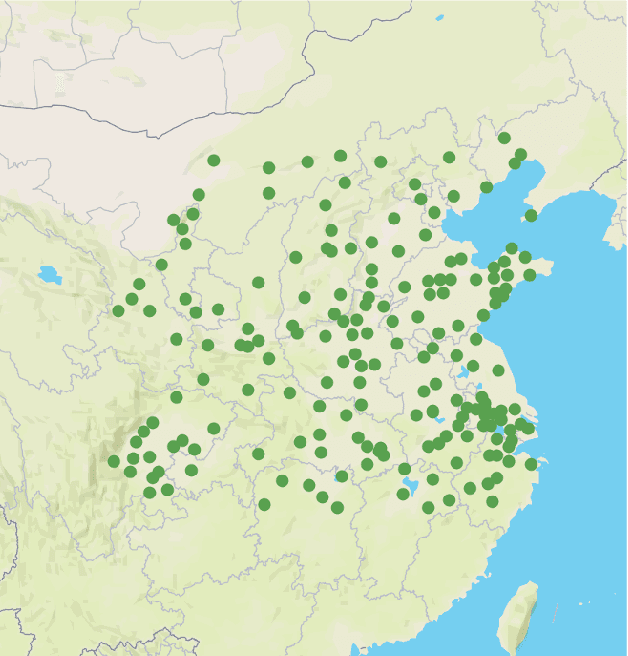
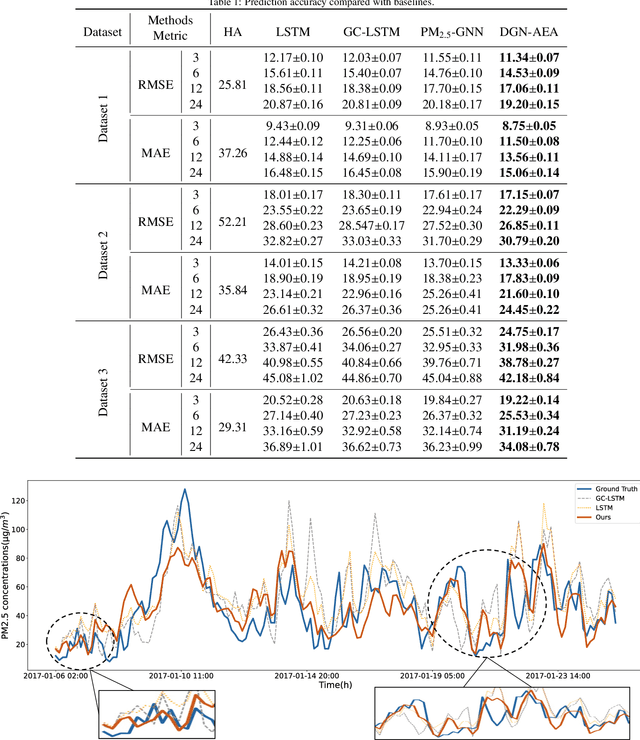
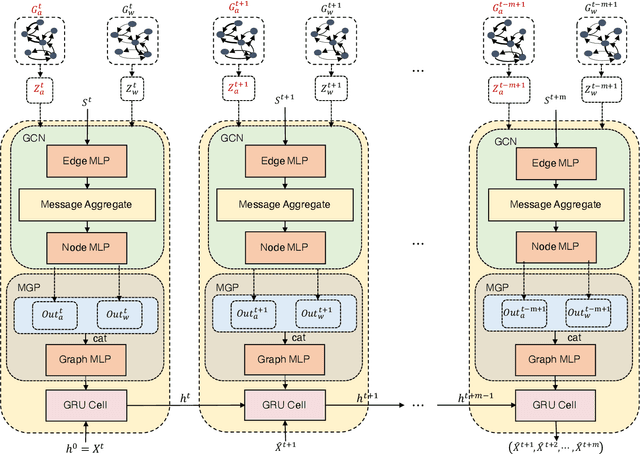
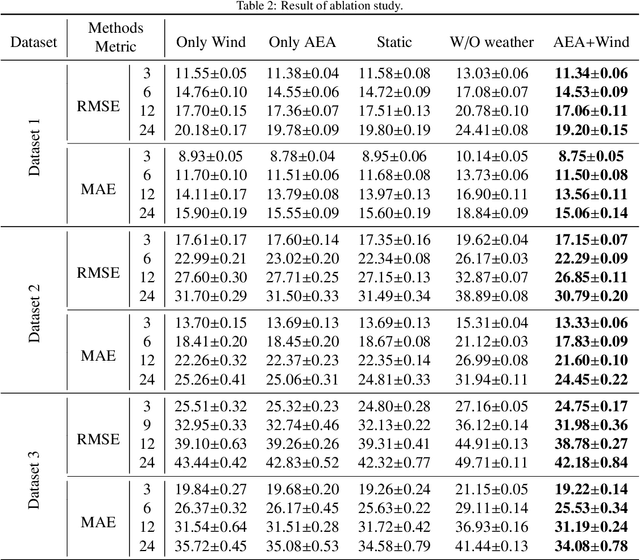
Air quality prediction is a typical spatio-temporal modeling problem, which always uses different components to handle spatial and temporal dependencies in complex systems separately. Previous models based on time series analysis and Recurrent Neural Network (RNN) methods have only modeled time series while ignoring spatial information. Previous GCNs-based methods usually require providing spatial correlation graph structure of observation sites in advance. The correlations among these sites and their strengths are usually calculated using prior information. However, due to the limitations of human cognition, limited prior information cannot reflect the real station-related structure or bring more effective information for accurate prediction. To this end, we propose a novel Dynamic Graph Neural Network with Adaptive Edge Attributes (DGN-AEA) on the message passing network, which generates the adaptive bidirected dynamic graph by learning the edge attributes as model parameters. Unlike prior information to establish edges, our method can obtain adaptive edge information through end-to-end training without any prior information. Thus reduced the complexity of the problem. Besides, the hidden structural information between the stations can be obtained as model by-products, which can help make some subsequent decision-making analyses. Experimental results show that our model received state-of-the-art performance than other baselines.
Graph Neural Networks for Multi-Robot Active Information Acquisition
Sep 24, 2022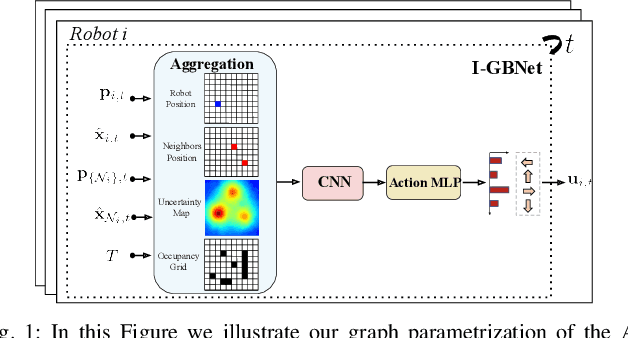
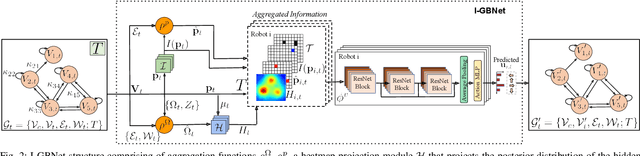
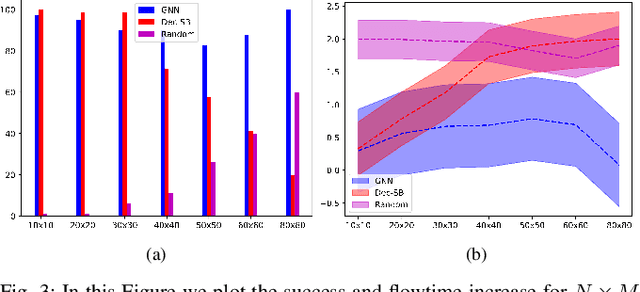
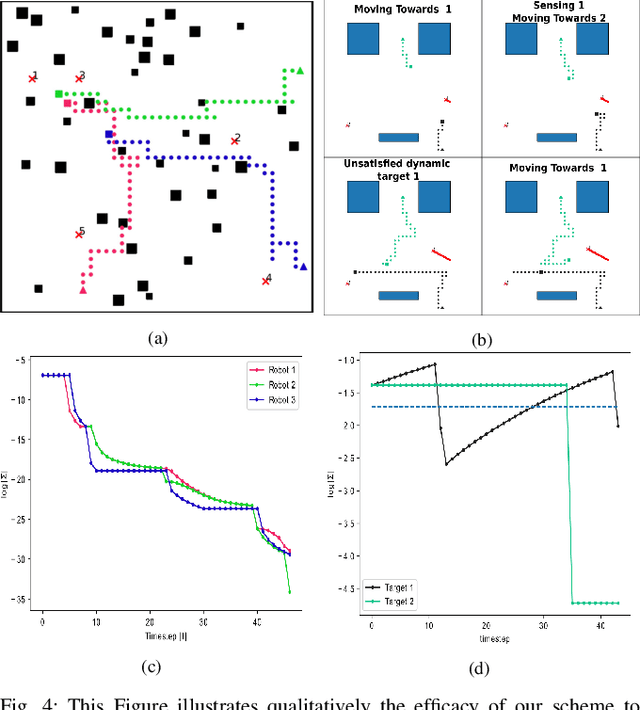
This paper addresses the Multi-Robot Active Information Acquisition (AIA) problem, where a team of mobile robots, communicating through an underlying graph, estimates a hidden state expressing a phenomenon of interest. Applications like target tracking, coverage and SLAM can be expressed in this framework. Existing approaches, though, are either not scalable, unable to handle dynamic phenomena or not robust to changes in the communication graph. To counter these shortcomings, we propose an Information-aware Graph Block Network (I-GBNet), an AIA adaptation of Graph Neural Networks, that aggregates information over the graph representation and provides sequential-decision making in a distributed manner. The I-GBNet, trained via imitation learning with a centralized sampling-based expert solver, exhibits permutation equivariance and time invariance, while harnessing the superior scalability, robustness and generalizability to previously unseen environments and robot configurations. Experiments on significantly larger graphs and dimensionality of the hidden state and more complex environments than those seen in training validate the properties of the proposed architecture and its efficacy in the application of localization and tracking of dynamic targets.
Incomplete Multi-View Multi-Label Learning via Label-Guided Masked View- and Category-Aware Transformers
Mar 13, 2023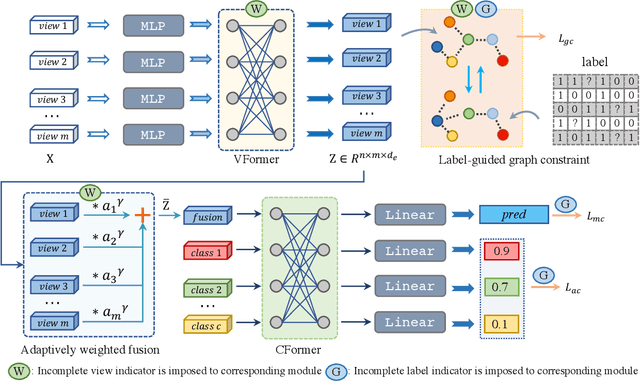

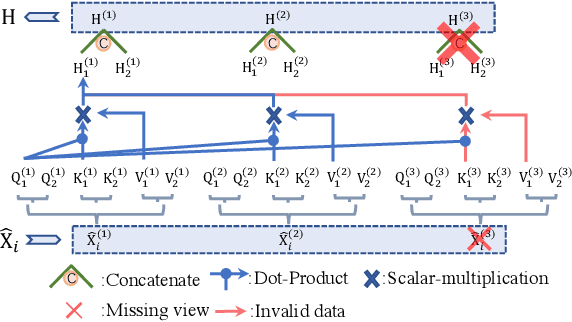

As we all know, multi-view data is more expressive than single-view data and multi-label annotation enjoys richer supervision information than single-label, which makes multi-view multi-label learning widely applicable for various pattern recognition tasks. In this complex representation learning problem, three main challenges can be characterized as follows: i) How to learn consistent representations of samples across all views? ii) How to exploit and utilize category correlations of multi-label to guide inference? iii) How to avoid the negative impact resulting from the incompleteness of views or labels? To cope with these problems, we propose a general multi-view multi-label learning framework named label-guided masked view- and category-aware transformers in this paper. First, we design two transformer-style based modules for cross-view features aggregation and multi-label classification, respectively. The former aggregates information from different views in the process of extracting view-specific features, and the latter learns subcategory embedding to improve classification performance. Second, considering the imbalance of expressive power among views, an adaptively weighted view fusion module is proposed to obtain view-consistent embedding features. Third, we impose a label manifold constraint in sample-level representation learning to maximize the utilization of supervised information. Last but not least, all the modules are designed under the premise of incomplete views and labels, which makes our method adaptable to arbitrary multi-view and multi-label data. Extensive experiments on five datasets confirm that our method has clear advantages over other state-of-the-art methods.
Synergistic information supports modality integration and flexible learning in neural networks solving multiple tasks
Oct 06, 2022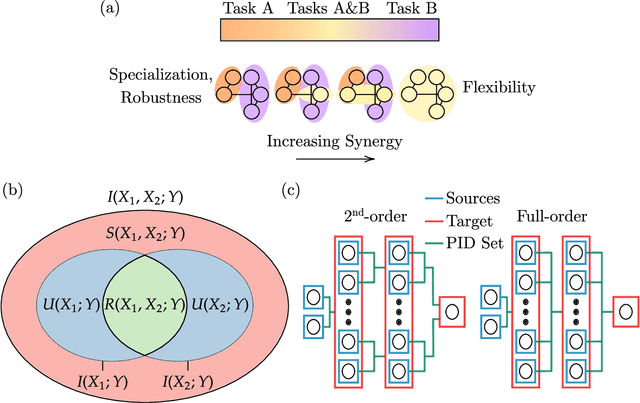
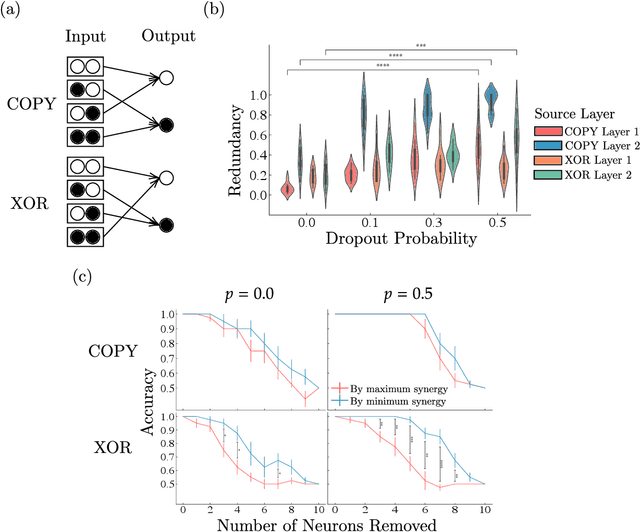
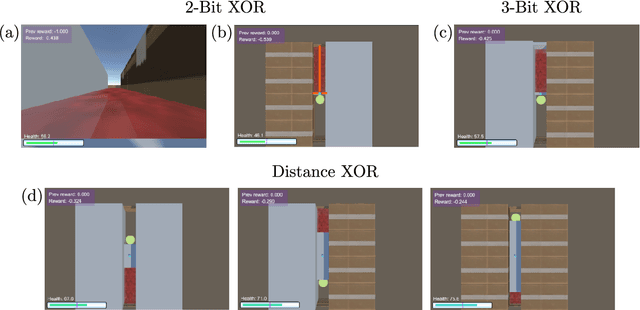
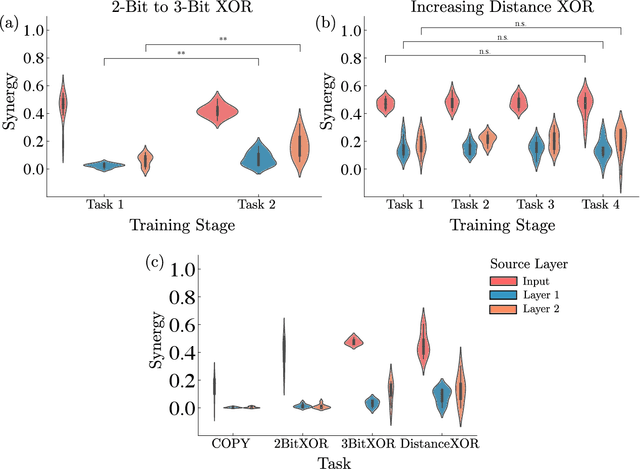
Striking progress has recently been made in understanding human cognition by analyzing how its neuronal underpinnings are engaged in different modes of information processing. Specifically, neural information can be decomposed into synergistic, redundant, and unique features, with synergistic components being particularly aligned with complex cognition. However, two fundamental questions remain unanswered: (a) precisely how and why a cognitive system can become highly synergistic; and (b) how these informational states map onto artificial neural networks in various learning modes. To address these questions, here we employ an information-decomposition framework to investigate the information processing strategies adopted by simple artificial neural networks performing a variety of cognitive tasks in both supervised and reinforcement learning settings. Our results show that synergy increases as neural networks learn multiple diverse tasks. Furthermore, performance in tasks requiring integration of multiple information sources critically relies on synergistic neurons. Finally, randomly turning off neurons during training through dropout increases network redundancy, corresponding to an increase in robustness. Overall, our results suggest that while redundant information is required for robustness to perturbations in the learning process, synergistic information is used to combine information from multiple modalities -- and more generally for flexible and efficient learning. These findings open the door to new ways of investigating how and why learning systems employ specific information-processing strategies, and support the principle that the capacity for general-purpose learning critically relies in the system's information dynamics.
A Codec Information Assisted Framework for Efficient Compressed Video Super-Resolution
Oct 15, 2022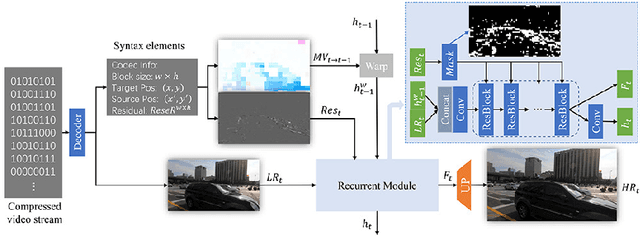

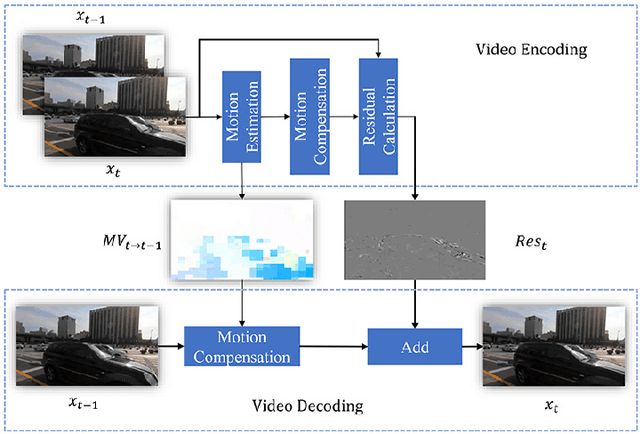
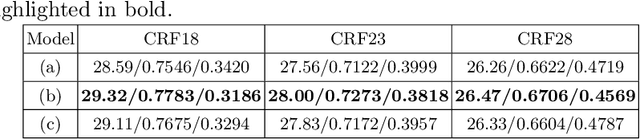
Online processing of compressed videos to increase their resolutions attracts increasing and broad attention. Video Super-Resolution (VSR) using recurrent neural network architecture is a promising solution due to its efficient modeling of long-range temporal dependencies. However, state-of-the-art recurrent VSR models still require significant computation to obtain a good performance, mainly because of the complicated motion estimation for frame/feature alignment and the redundant processing of consecutive video frames. In this paper, considering the characteristics of compressed videos, we propose a Codec Information Assisted Framework (CIAF) to boost and accelerate recurrent VSR models for compressed videos. Firstly, the framework reuses the coded video information of Motion Vectors to model the temporal relationships between adjacent frames. Experiments demonstrate that the models with Motion Vector based alignment can significantly boost the performance with negligible additional computation, even comparable to those using more complex optical flow based alignment. Secondly, by further making use of the coded video information of Residuals, the framework can be informed to skip the computation on redundant pixels. Experiments demonstrate that the proposed framework can save up to 70% of the computation without performance drop on the REDS4 test videos encoded by H.264 when CRF is 23.
Adaptive Voronoi NeRFs
Mar 30, 2023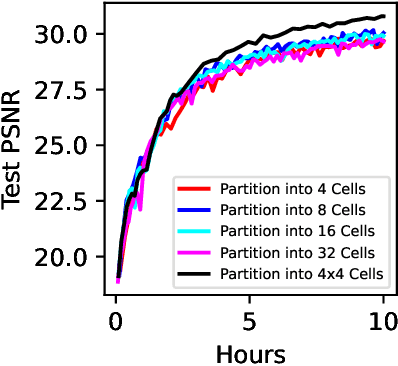
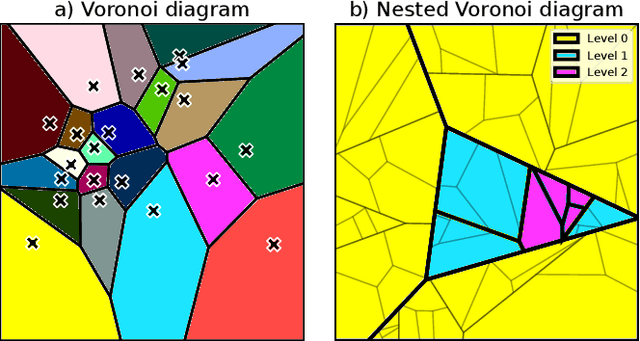

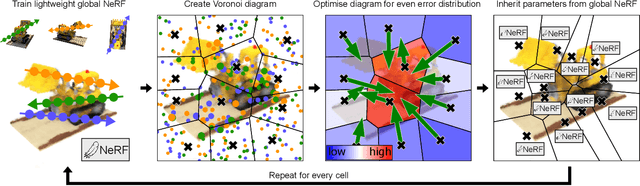
Neural Radiance Fields (NeRFs) learn to represent a 3D scene from just a set of registered images. Increasing sizes of a scene demands more complex functions, typically represented by neural networks, to capture all details. Training and inference then involves querying the neural network millions of times per image, which becomes impractically slow. Since such complex functions can be replaced by multiple simpler functions to improve speed, we show that a hierarchy of Voronoi diagrams is a suitable choice to partition the scene. By equipping each Voronoi cell with its own NeRF, our approach is able to quickly learn a scene representation. We propose an intuitive partitioning of the space that increases quality gains during training by distributing information evenly among the networks and avoids artifacts through a top-down adaptive refinement. Our framework is agnostic to the underlying NeRF method and easy to implement, which allows it to be applied to various NeRF variants for improved learning and rendering speeds.
Probabilistic Shaping for High-Speed Unamplified IM/DD Systems with an O-Band EML
Mar 30, 2023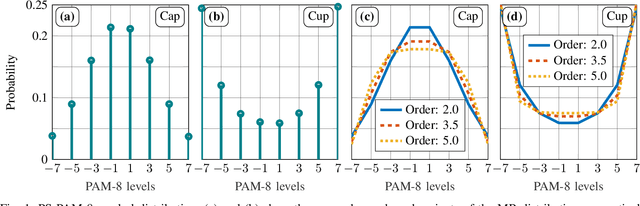
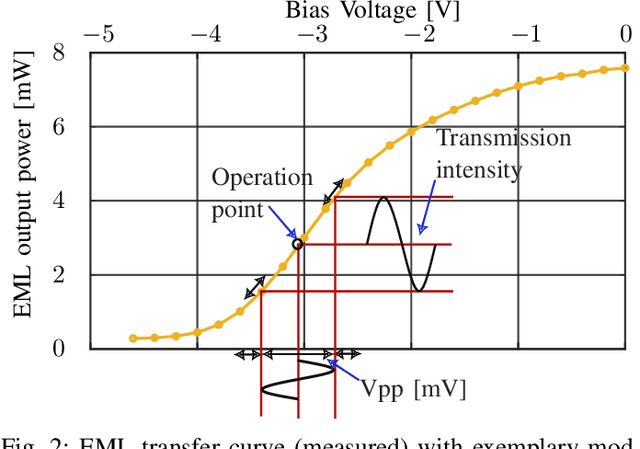

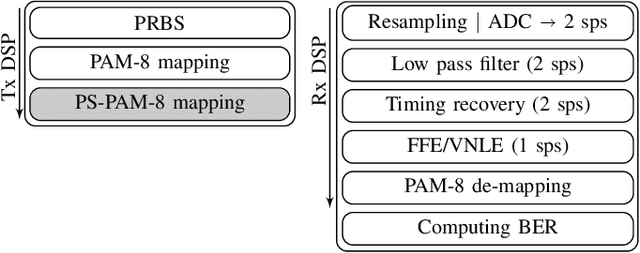
Probabilistic constellation shaping has been used in long-haul optically amplified coherent systems for its capability to approach the Shannon limit and realize fine rate granularity. The availability of high-bandwidth optical-electronic components and the previously mentioned advantages have invigorated researchers to explore probabilistic shaping (PS) in intensity-modulation and direct-detection (IM/DD) systems. This article presents an extensive comparison of uniform 8-ary pulse amplitude modulation (PAM) with PS PAM-8 using cap and cup Maxwell-Boltzmann (MB) distributions as well as MB distributions of different Gaussian orders. We report that in the presence of linear equalization, PS-PAM-8 outperforms uniform PAM-8 in terms of bit error ratio, achievable information rate and operational net bit rate indicating that cap-shaped PS-PAM-8 shows high tolerance against nonlinearities. In this paper, we have focused our investigations on O-band electro-absorption modulated laser unamplified IM/DD systems, which are operated close to the zero dispersion wavelength.
* 9 pages, 12 figures
HybridCVLNet: A Hybrid CSI Feedback System and its Domain Adaptation
Mar 30, 2023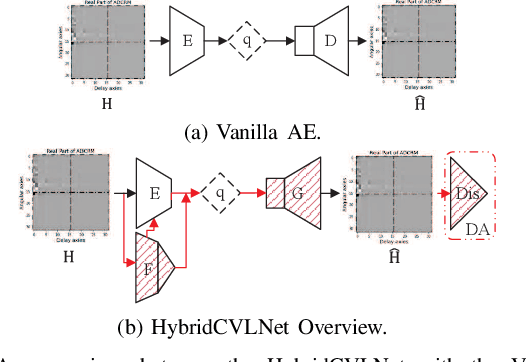
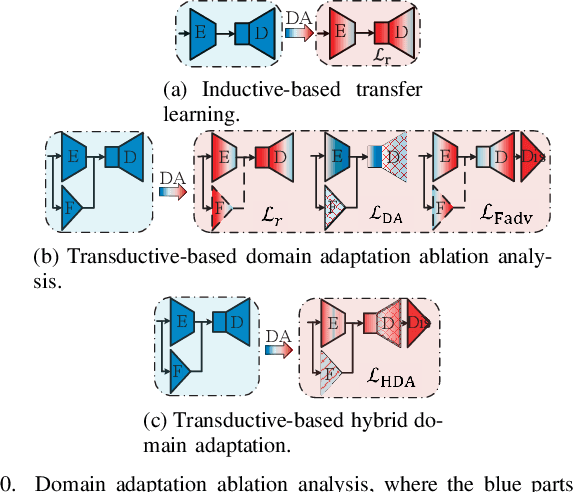
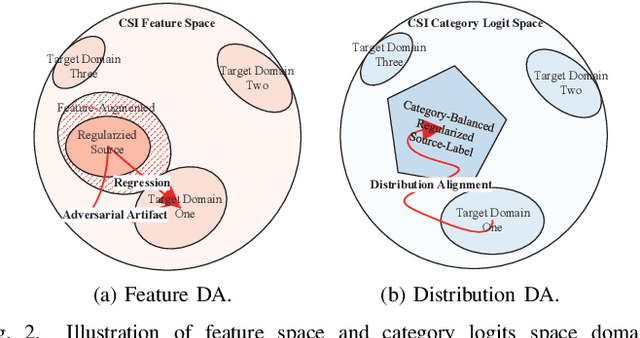
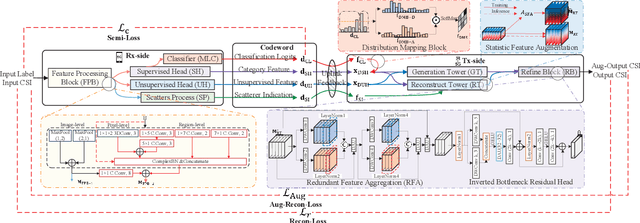
Deep Learning (DL)-based channel state information (CSI) feedback is a promising technique for the transmitter to accurately acquire the CSI of massive multiple-input multiple-output (MIMO) systems. As a critical concern about DL-based physical layer application, although most existing CSI feedback methods have shown advantages in dedicated channel environments and scenarios, the generalization and adaptivity of these methods remain challenging. Therefore, we propose a Hybrid Complex-Valued Lightweight framework, namely HybridCVLNet, with a hybrid structure, task, and codeword and correspondent domain adaptation scheme to overcome the data drift and dataset bias for CSI feedback. The experiment verifies the validity of the proposed lightweight HybridCVLNet regularization to the regression process. It achieves stable generalizability and performance gain over the SOTA feedback schemes in an intra-domain multi-category setting. In addition, its hybrid domain adaptation scheme is more efficient and superior to the online direct-finetune method under the unseen cross-domain dataset.
Learning Spiking Neural Systems with the Event-Driven Forward-Forward Process
Mar 30, 2023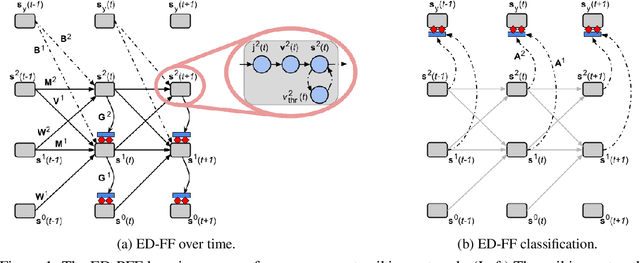
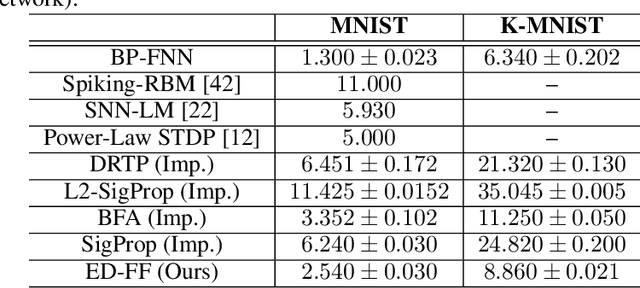
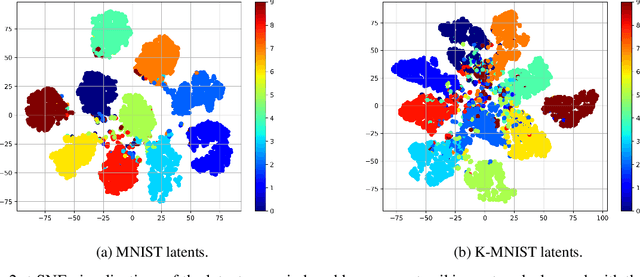

We develop a novel credit assignment algorithm for information processing with spiking neurons without requiring feedback synapses. Specifically, we propose an event-driven generalization of the forward-forward and the predictive forward-forward learning processes for a spiking neural system that iteratively processes sensory input over a stimulus window. As a result, the recurrent circuit computes the membrane potential of each neuron in each layer as a function of local bottom-up, top-down, and lateral signals, facilitating a dynamic, layer-wise parallel form of neural computation. Unlike spiking neural coding, which relies on feedback synapses to adjust neural electrical activity, our model operates purely online and forward in time, offering a promising way to learn distributed representations of sensory data patterns with temporal spike signals. Notably, our experimental results on several pattern datasets demonstrate that the even-driven forward-forward (ED-FF) framework works well for training a dynamic recurrent spiking system capable of both classification and reconstruction.
Task Oriented Conversational Modelling With Subjective Knowledge
Mar 30, 2023
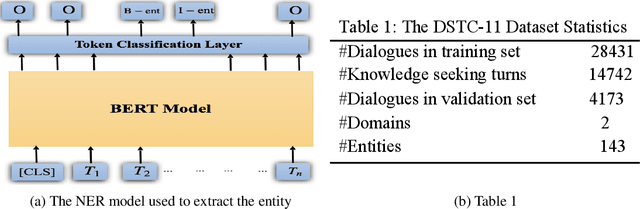

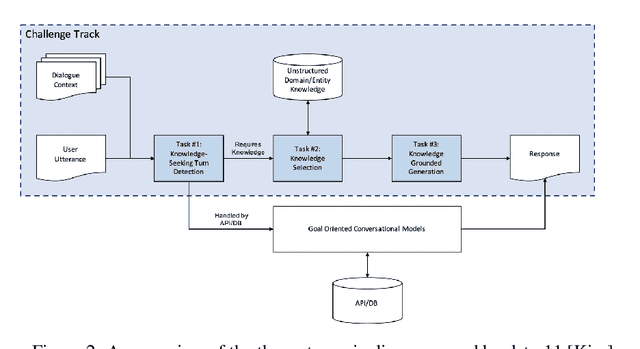
Existing conversational models are handled by a database(DB) and API based systems. However, very often users' questions require information that cannot be handled by such systems. Nonetheless, answers to these questions are available in the form of customer reviews and FAQs. DSTC-11 proposes a three stage pipeline consisting of knowledge seeking turn detection, knowledge selection and response generation to create a conversational model grounded on this subjective knowledge. In this paper, we focus on improving the knowledge selection module to enhance the overall system performance. In particular, we propose entity retrieval methods which result in an accurate and faster knowledge search. Our proposed Named Entity Recognition (NER) based entity retrieval method results in 7X faster search compared to the baseline model. Additionally, we also explore a potential keyword extraction method which can improve the accuracy of knowledge selection. Preliminary results show a 4 \% improvement in exact match score on knowledge selection task. The code is available https://github.com/raja-kumar/knowledge-grounded-TODS