 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-scale Geometry-aware Transformer for 3D Point Cloud Classification
Apr 12, 2023
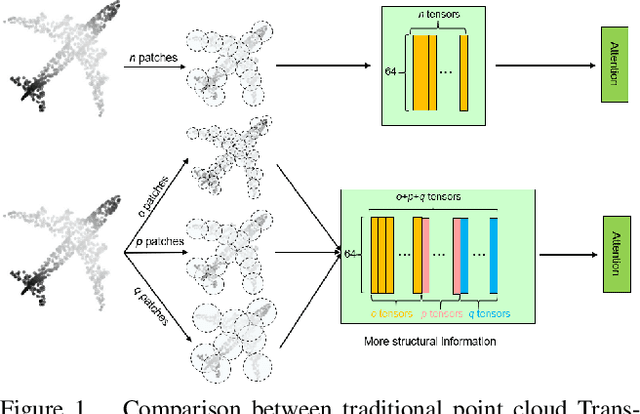

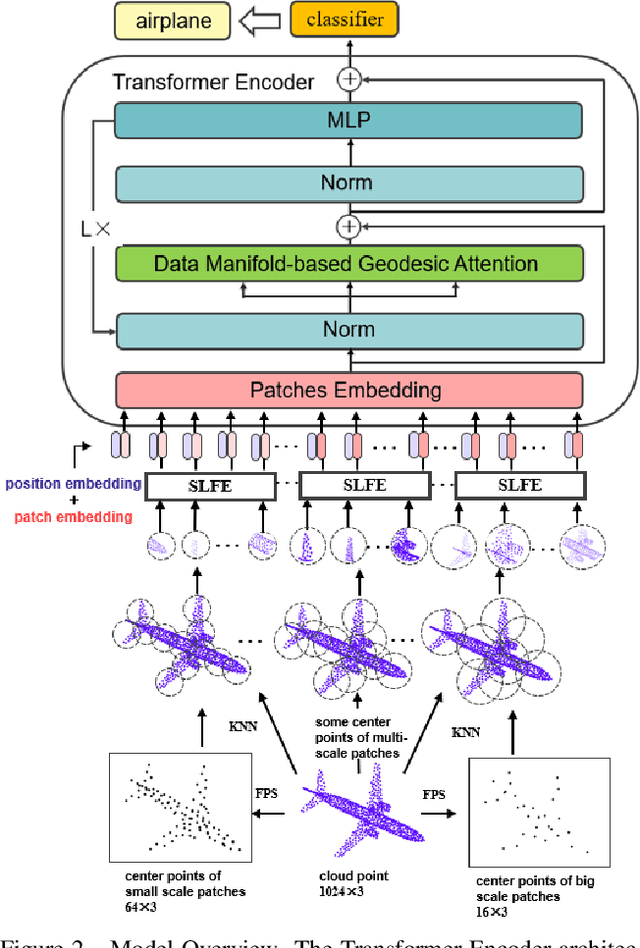
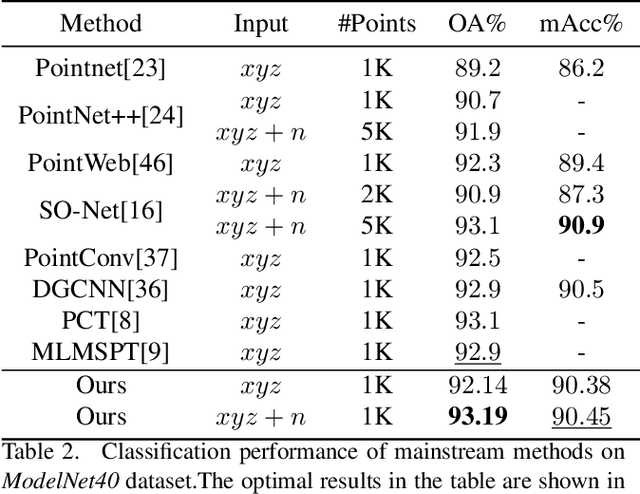
Self-attention modules have demonstrated remarkable capabilities in capturing long-range relationships and improving the performance of point cloud tasks. However, point cloud objects are typically characterized by complex, disordered, and non-Euclidean spatial structures with multiple scales, and their behavior is often dynamic and unpredictable. The current self-attention modules mostly rely on dot product multiplication and dimension alignment among query-key-value features, which cannot adequately capture the multi-scale non-Euclidean structures of point cloud objects. To address these problems, this paper proposes a self-attention plug-in module with its variants, Multi-scale Geometry-aware Transformer (MGT). MGT processes point cloud data with multi-scale local and global geometric information in the following three aspects. At first, the MGT divides point cloud data into patches with multiple scales. Secondly, a local feature extractor based on sphere mapping is proposed to explore the geometry inner each patch and generate a fixed-length representation for each patch. Thirdly, the fixed-length representations are fed into a novel geodesic-based self-attention to capture the global non-Euclidean geometry between patches. Finally, all the modules are integrated into the framework of MGT with an end-to-end training scheme. Experimental results demonstrate that the MGT vastly increases the capability of capturing multi-scale geometry using the self-attention mechanism and achieves strong competitive performance on mainstream point cloud benchmarks.
Frame Error Rate Prediction for Non-Stationary Wireless Vehicular Communication Links
Apr 12, 2023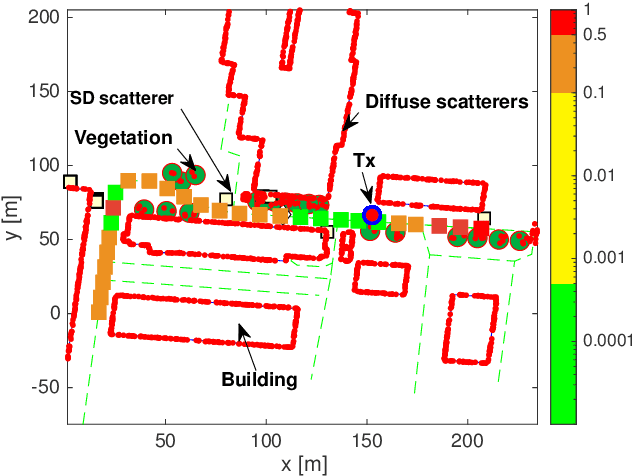
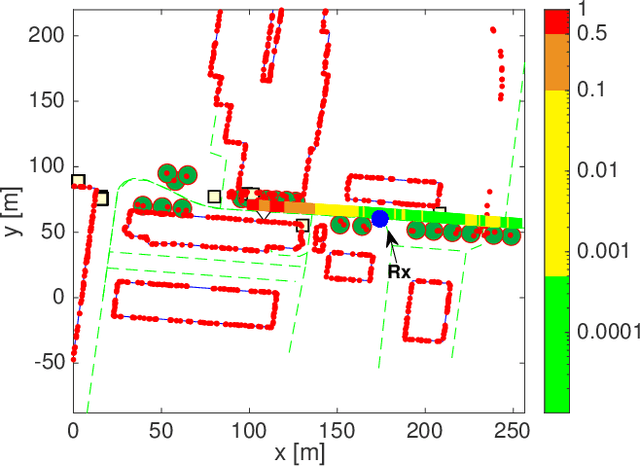
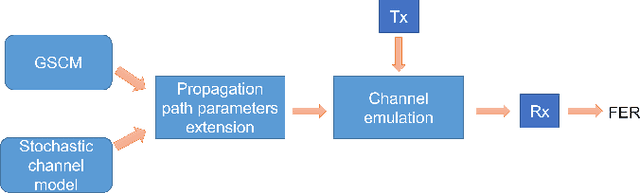
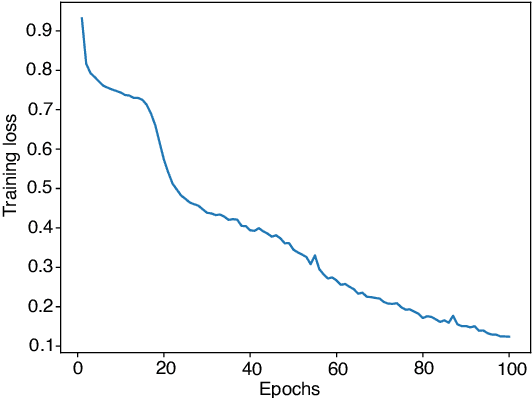
Wireless vehicular communication will increase the safety of road users. The reliability of vehicular communication links is of high importance as links with low reliability may diminish the advantage of having situational traffic information. The goal of our investigation is to obtain a reliable coverage area for non-stationary vehicular scenarios. Therefore we propose a deep neural network (DNN) for predicting the expected frame error rate (FER). The DNN is trained in a supervised fashion, where a time-limited sequence of channel frequency responses has been labeled with its corresponding FER values assuming an underlying wireless communication system, i.e. IEEE 802.11p. For generating the training dataset we use a geometry-based stochastic channel model (GSCM). We obtain the ground truth FER by emulating the time-varying frequency responses using a hardware-in-the-loop setup. Our GSCM provides the propagation path parameters which we use to fix the statistics of the fading process at one point in space for an arbitrary amount of time, enabling accurate FER estimation. Using this dataset we achieve an accuracy of 85% of the DNN. We use the trained model to predict the FER for measured time-varying channel transfer functions obtained during a measurement campaign. We compare the predicted output of the DNN to the measured FER on the road and obtain a prediction accuracy of 78%.
Distributed Compressed Sparse Row Format for Spiking Neural Network Simulation, Serialization, and Interoperability
Apr 12, 2023With the increasing development of neuromorphic platforms and their related software tools as well as the increasing scale of spiking neural network (SNN) models, there is a pressure for interoperable and scalable representations of network state. In response to this, we discuss a parallel extension of a widely used format for efficiently representing sparse matrices, the compressed sparse row (CSR), in the context of supporting the simulation and serialization of large-scale SNNs. Sparse matrices for graph adjacency structure provide a natural fit for describing the connectivity of an SNN, and prior work in the area of parallel graph partitioning has developed the distributed CSR (dCSR) format for storing and ingesting large graphs. We contend that organizing additional network information, such as neuron and synapse state, in alignment with its adjacency as dCSR provides a straightforward partition-based distribution of network state. For large-scale simulations, this means each parallel process is only responsible for its own partition of state, which becomes especially useful when the size of an SNN exceeds the memory resources of a single compute node. For potentially long-running simulations, this also enables network serialization to and from disk (e.g. for checkpoint/restart fault-tolerant computing) to be performed largely independently between parallel processes. We also provide a potential implementation, and put it forward for adoption within the neural computing community.
CLCLSA: Cross-omics Linked embedding with Contrastive Learning and Self Attention for multi-omics integration with incomplete multi-omics data
Apr 12, 2023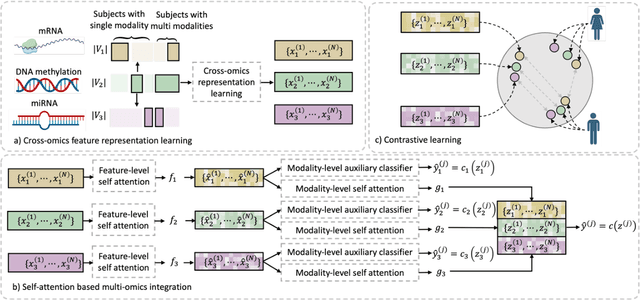
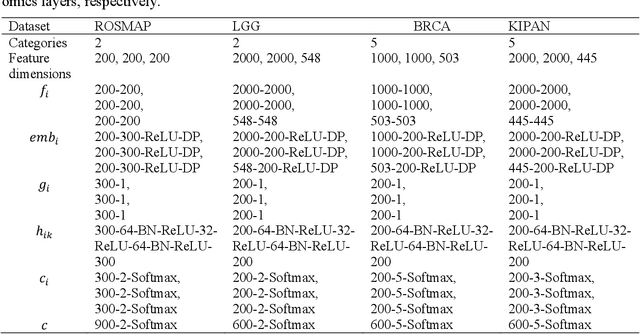
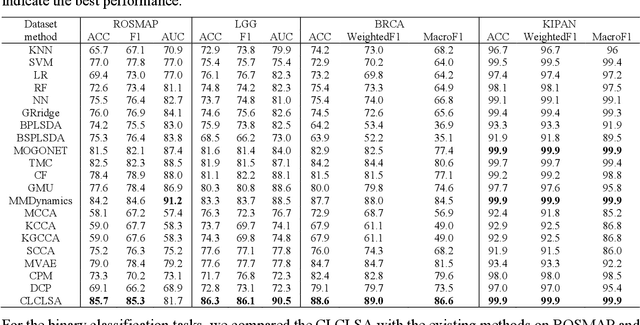
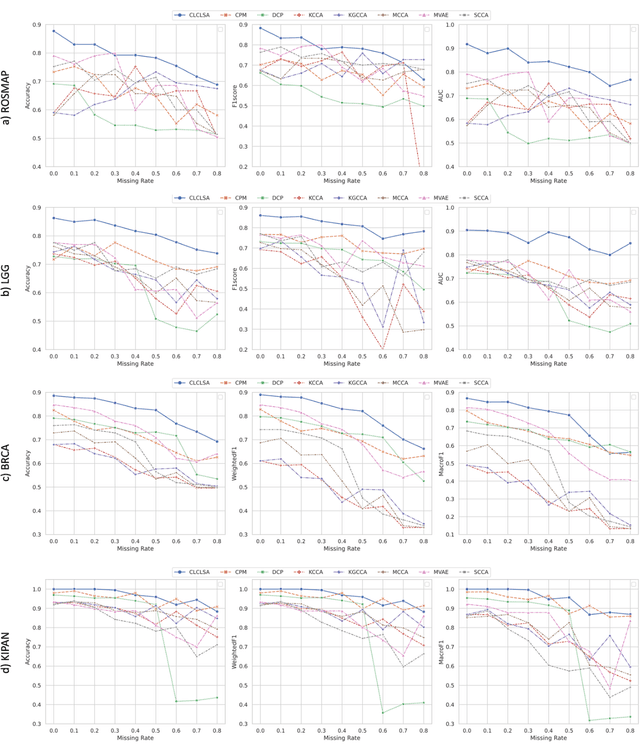
Integration of heterogeneous and high-dimensional multi-omics data is becoming increasingly important in understanding genetic data. Each omics technique only provides a limited view of the underlying biological process and integrating heterogeneous omics layers simultaneously would lead to a more comprehensive and detailed understanding of diseases and phenotypes. However, one obstacle faced when performing multi-omics data integration is the existence of unpaired multi-omics data due to instrument sensitivity and cost. Studies may fail if certain aspects of the subjects are missing or incomplete. In this paper, we propose a deep learning method for multi-omics integration with incomplete data by Cross-omics Linked unified embedding with Contrastive Learning and Self Attention (CLCLSA). Utilizing complete multi-omics data as supervision, the model employs cross-omics autoencoders to learn the feature representation across different types of biological data. The multi-omics contrastive learning, which is used to maximize the mutual information between different types of omics, is employed before latent feature concatenation. In addition, the feature-level self-attention and omics-level self-attention are employed to dynamically identify the most informative features for multi-omics data integration. Extensive experiments were conducted on four public multi-omics datasets. The experimental results indicated that the proposed CLCLSA outperformed the state-of-the-art approaches for multi-omics data classification using incomplete multi-omics data.
Towards Unsupervised Learning based Denoising of Cyber Physical System Data to Mitigate Security Concerns
Mar 13, 2023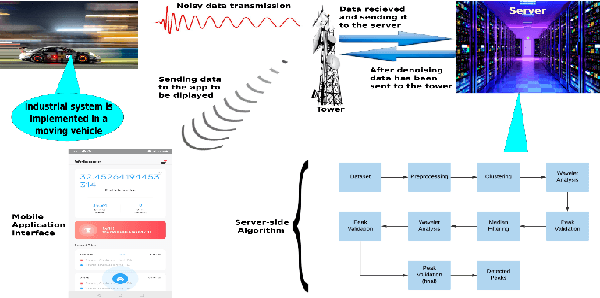
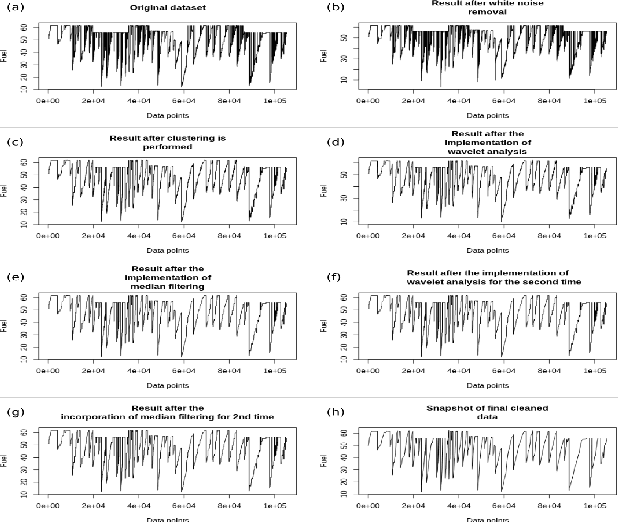
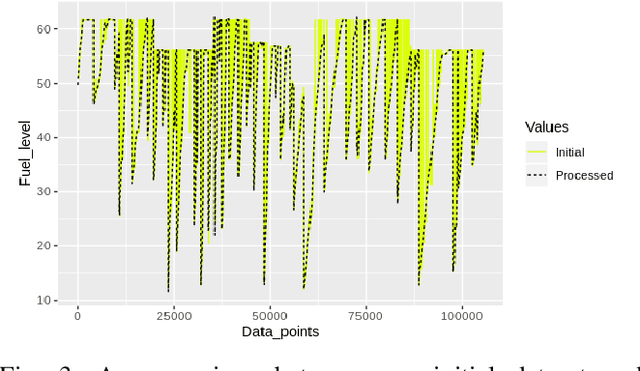
A dataset, collected under an industrial setting, often contains a significant portion of noises. In many cases, using trivial filters is not enough to retrieve useful information i.e., accurate value without the noise. One such data is time-series sensor readings collected from moving vehicles containing fuel information. Due to the noisy dynamics and mobile environment, the sensor readings can be very noisy. Denoising such a dataset is a prerequisite for any useful application and security issues. Security is a primitive concern in present vehicular schemes. The server side for retrieving the fuel information can be easily hacked. Providing the accurate and noise free fuel information via vehicular networks become crutial. Therefore, it has led us to develop a system that can remove noise and keep the original value. The system is also helpful for vehicle industry, fuel station, and power-plant station that require fuel. In this work, we have only considered the value of fuel level, and we have come up with a unique solution to filter out the noise of high magnitudes using several algorithms such as interpolation, extrapolation, spectral clustering, agglomerative clustering, wavelet analysis, and median filtering. We have also employed peak detection and peak validation algorithms to detect fuel refill and consumption in charge-discharge cycles. We have used the R-squared metric to evaluate our model, and it is 98 percent In most cases, the difference between detected value and real value remains within the range of 1L.
A novel information gain-based approach for classification and dimensionality reduction of hyperspectral images
Oct 26, 2022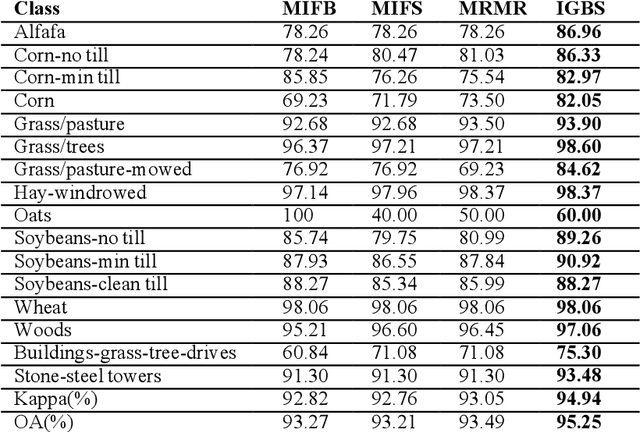
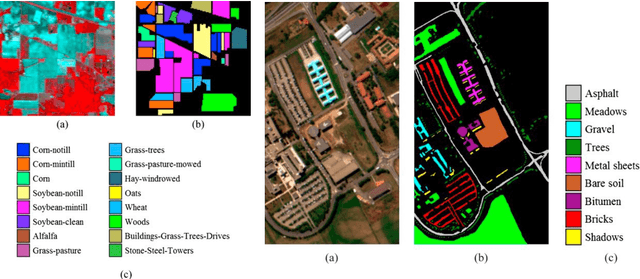
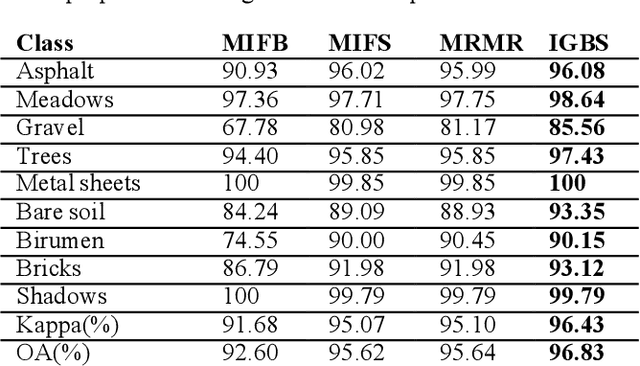
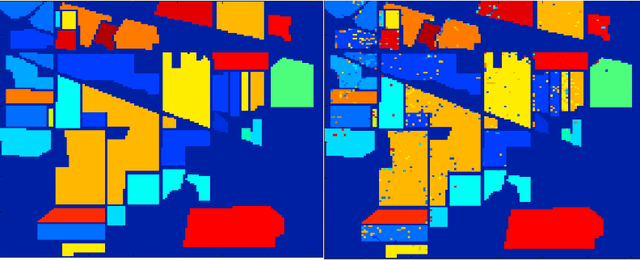
Recently, the hyperspectral sensors have improved our ability to monitor the earth surface with high spectral resolution. However, the high dimensionality of spectral data brings challenges for the image processing. Consequently, the dimensionality reduction is a necessary step in order to reduce the computational complexity and increase the classification accuracy. In this paper, we propose a new filter approach based on information gain for dimensionality reduction and classification of hyperspectral images. A special strategy based on hyperspectral bands selection is adopted to pick the most informative bands and discard the irrelevant and noisy ones. The algorithm evaluates the relevancy of the bands based on the information gain function with the support vector machine classifier. The proposed method is compared using two benchmark hyperspectral datasets (Indiana, Pavia) with three competing methods. The comparison results showed that the information gain filter approach outperforms the other methods on the tested datasets and could significantly reduce the computation cost while improving the classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy.
Towards Self-Explainability of Deep Neural Networks with Heatmap Captioning and Large-Language Models
Apr 05, 2023
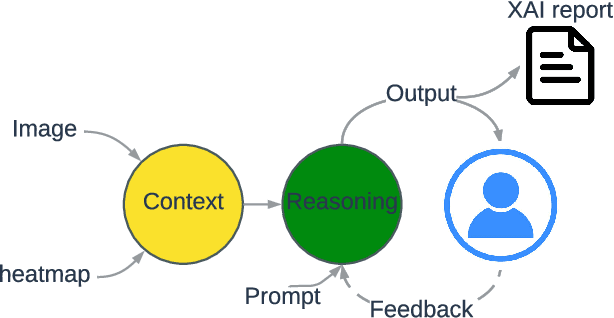
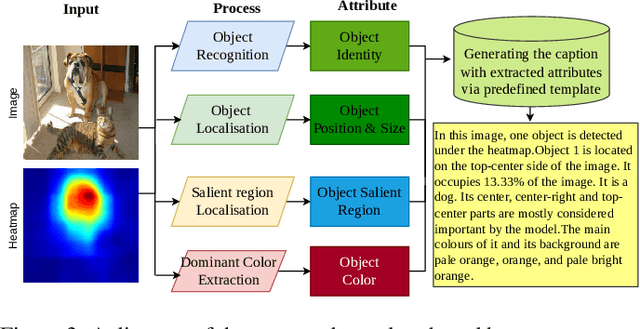
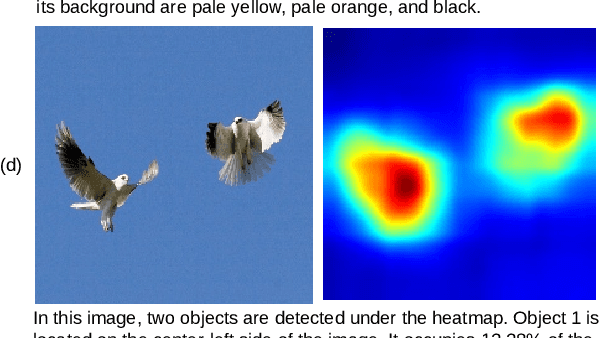
Heatmaps are widely used to interpret deep neural networks, particularly for computer vision tasks, and the heatmap-based explainable AI (XAI) techniques are a well-researched topic. However, most studies concentrate on enhancing the quality of the generated heatmap or discovering alternate heatmap generation techniques, and little effort has been devoted to making heatmap-based XAI automatic, interactive, scalable, and accessible. To address this gap, we propose a framework that includes two modules: (1) context modelling and (2) reasoning. We proposed a template-based image captioning approach for context modelling to create text-based contextual information from the heatmap and input data. The reasoning module leverages a large language model to provide explanations in combination with specialised knowledge. Our qualitative experiments demonstrate the effectiveness of our framework and heatmap captioning approach. The code for the proposed template-based heatmap captioning approach will be publicly available.
Artificial neural networks and time series of counts: A class of nonlinear INGARCH models
Apr 03, 2023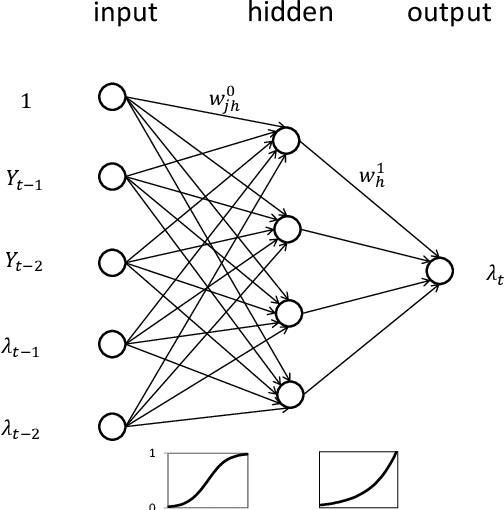
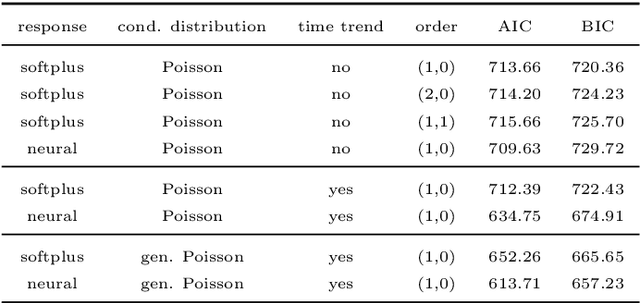
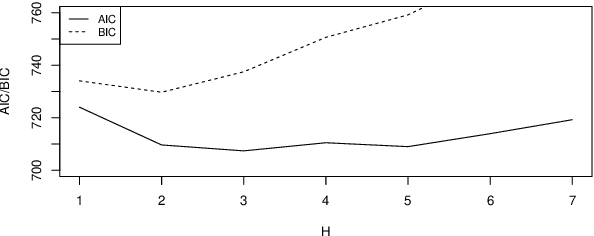
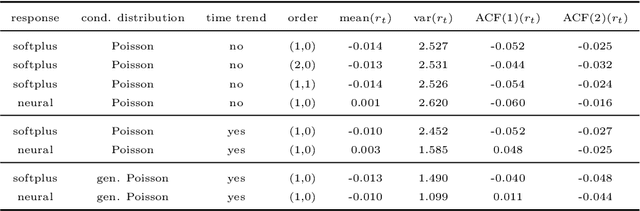
Time series of counts are frequently analyzed using generalized integer-valued autoregressive models with conditional heteroskedasticity (INGARCH). These models employ response functions to map a vector of past observations and past conditional expectations to the conditional expectation of the present observation. In this paper, it is shown how INGARCH models can be combined with artificial neural network (ANN) response functions to obtain a class of nonlinear INGARCH models. The ANN framework allows for the interpretation of many existing INGARCH models as a degenerate version of a corresponding neural model. Details on maximum likelihood estimation, marginal effects and confidence intervals are given. The empirical analysis of time series of bounded and unbounded counts reveals that the neural INGARCH models are able to outperform reasonable degenerate competitor models in terms of the information loss.
Just Noticeable Visual Redundancy Forecasting: A Deep Multimodal-driven Approach
Mar 18, 2023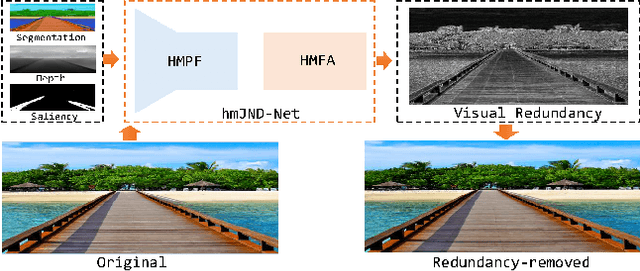


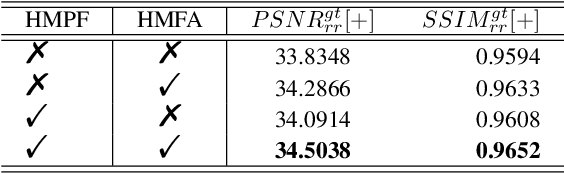
Just noticeable difference (JND) refers to the maximum visual change that human eyes cannot perceive, and it has a wide range of applications in multimedia systems. However, most existing JND approaches only focus on a single modality, and rarely consider the complementary effects of multimodal information. In this article, we investigate the JND modeling from an end-to-end homologous multimodal perspective, namely hmJND-Net. Specifically, we explore three important visually sensitive modalities, including saliency, depth, and segmentation. To better utilize homologous multimodal information, we establish an effective fusion method via summation enhancement and subtractive offset, and align homologous multimodal features based on a self-attention driven encoder-decoder paradigm. Extensive experimental results on eight different benchmark datasets validate the superiority of our hmJND-Net over eight representative methods.
Continual Graph Convolutional Network for Text Classification
Apr 09, 2023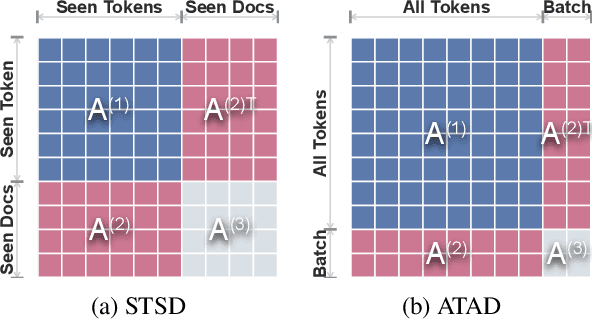
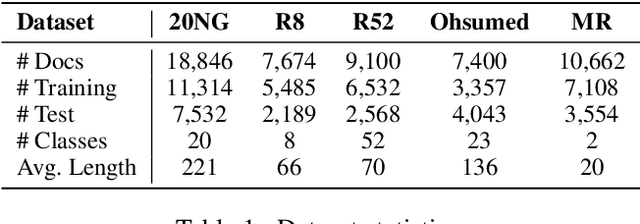
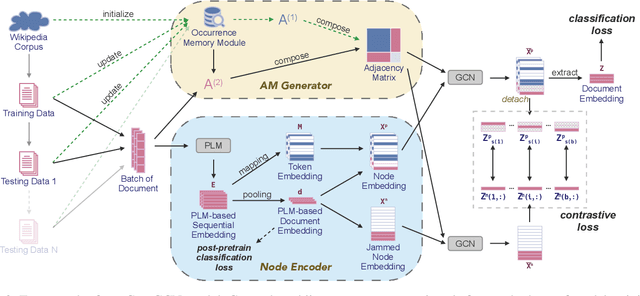
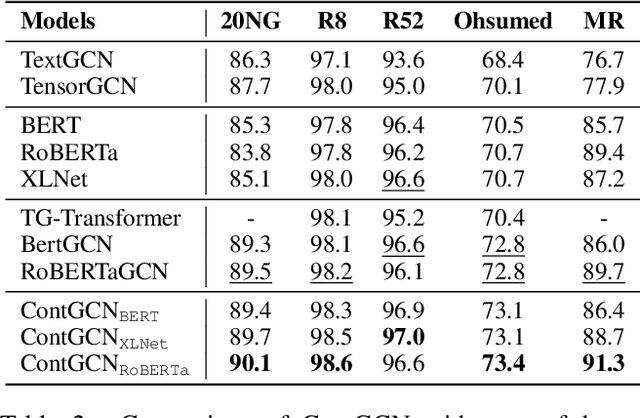
Graph convolutional network (GCN) has been successfully applied to capture global non-consecutive and long-distance semantic information for text classification. However, while GCN-based methods have shown promising results in offline evaluations, they commonly follow a seen-token-seen-document paradigm by constructing a fixed document-token graph and cannot make inferences on new documents. It is a challenge to deploy them in online systems to infer steaming text data. In this work, we present a continual GCN model (ContGCN) to generalize inferences from observed documents to unobserved documents. Concretely, we propose a new all-token-any-document paradigm to dynamically update the document-token graph in every batch during both the training and testing phases of an online system. Moreover, we design an occurrence memory module and a self-supervised contrastive learning objective to update ContGCN in a label-free manner. A 3-month A/B test on Huawei public opinion analysis system shows ContGCN achieves 8.86% performance gain compared with state-of-the-art methods. Offline experiments on five public datasets also show ContGCN can improve inference quality. The source code will be released at https://github.com/Jyonn/ContGCN.