 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GNeRP: Gaussian-guided Neural Reconstruction of Reflective Objects with Noisy Polarization Priors
Mar 18, 2024
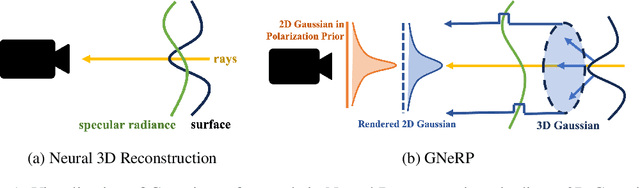
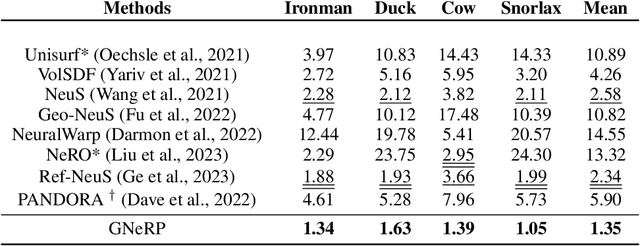
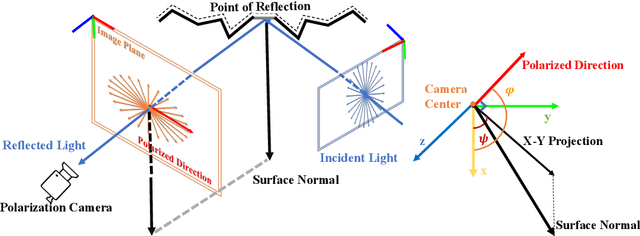

Learning surfaces from neural radiance field (NeRF) became a rising topic in Multi-View Stereo (MVS). Recent Signed Distance Function (SDF)-based methods demonstrated their ability to reconstruct accurate 3D shapes of Lambertian scenes. However, their results on reflective scenes are unsatisfactory due to the entanglement of specular radiance and complicated geometry. To address the challenges, we propose a Gaussian-based representation of normals in SDF fields. Supervised by polarization priors, this representation guides the learning of geometry behind the specular reflection and captures more details than existing methods. Moreover, we propose a reweighting strategy in the optimization process to alleviate the noise issue of polarization priors. To validate the effectiveness of our design, we capture polarimetric information, and ground truth meshes in additional reflective scenes with various geometry. We also evaluated our framework on the PANDORA dataset. Comparisons prove our method outperforms existing neural 3D reconstruction methods in reflective scenes by a large margin.
Complete and Efficient Graph Transformers for Crystal Material Property Prediction
Mar 18, 2024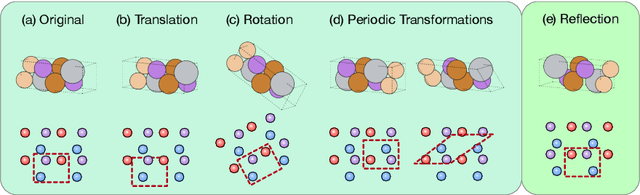
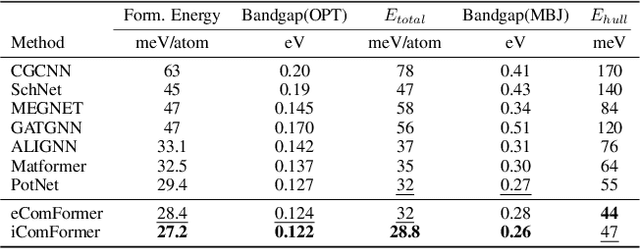
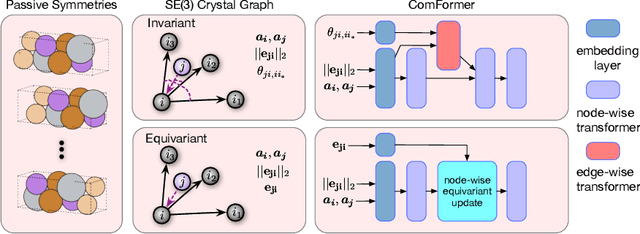
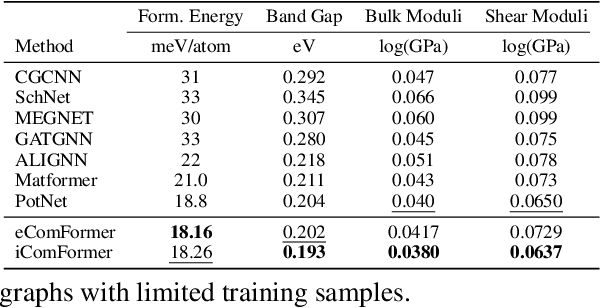
Crystal structures are characterized by atomic bases within a primitive unit cell that repeats along a regular lattice throughout 3D space. The periodic and infinite nature of crystals poses unique challenges for geometric graph representation learning. Specifically, constructing graphs that effectively capture the complete geometric information of crystals and handle chiral crystals remains an unsolved and challenging problem. In this paper, we introduce a novel approach that utilizes the periodic patterns of unit cells to establish the lattice-based representation for each atom, enabling efficient and expressive graph representations of crystals. Furthermore, we propose ComFormer, a SE(3) transformer designed specifically for crystalline materials. ComFormer includes two variants; namely, iComFormer that employs invariant geometric descriptors of Euclidean distances and angles, and eComFormer that utilizes equivariant vector representations. Experimental results demonstrate the state-of-the-art predictive accuracy of ComFormer variants on various tasks across three widely-used crystal benchmarks. Our code is publicly available as part of the AIRS library (https://github.com/divelab/AIRS).
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024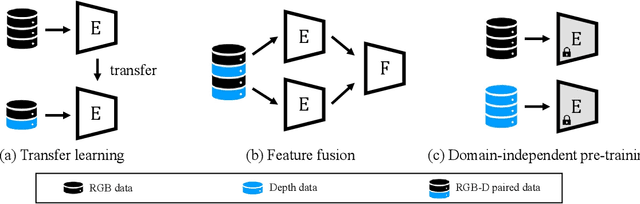
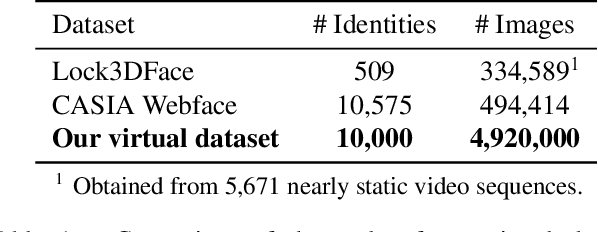
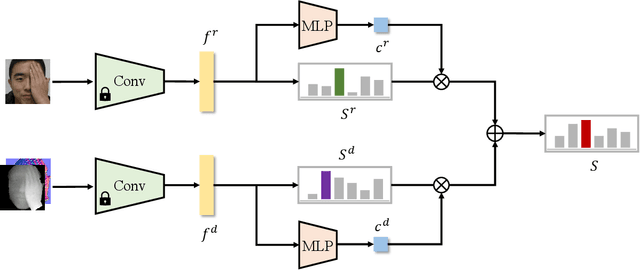
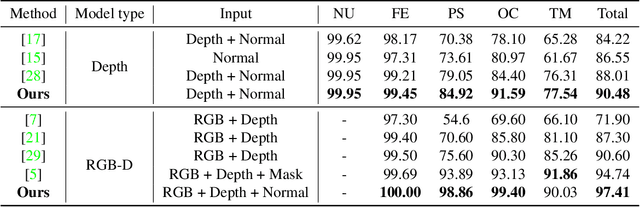
2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
MSI-NeRF: Linking Omni-Depth with View Synthesis through Multi-Sphere Image aided Generalizable Neural Radiance Field
Mar 16, 2024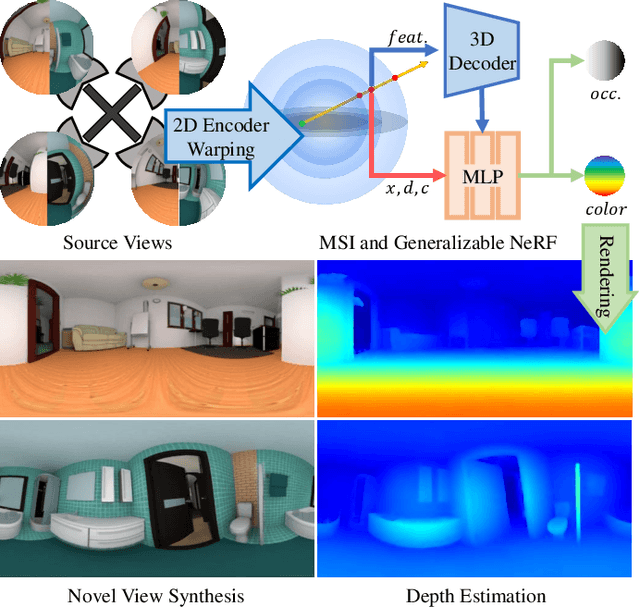
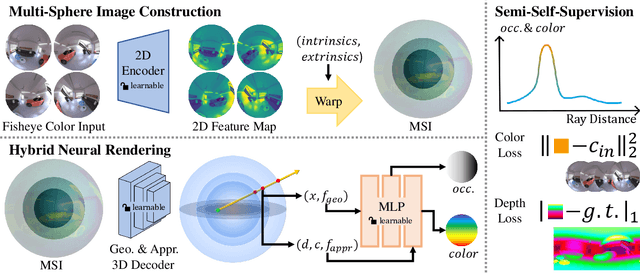

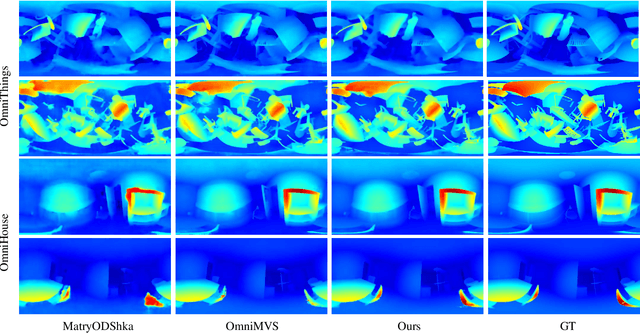
Panoramic observation using fisheye cameras is significant in robot perception, reconstruction, and remote operation. However, panoramic images synthesized by traditional methods lack depth information and can only provide three degrees-of-freedom (3DoF) rotation rendering in virtual reality applications. To fully preserve and exploit the parallax information within the original fisheye cameras, we introduce MSI-NeRF, which combines deep learning omnidirectional depth estimation and novel view rendering. We first construct a multi-sphere image as a cost volume through feature extraction and warping of the input images. It is then processed by geometry and appearance decoders, respectively. Unlike methods that regress depth maps directly, we further build an implicit radiance field using spatial points and interpolated 3D feature vectors as input. In this way, we can simultaneously realize omnidirectional depth estimation and 6DoF view synthesis. Our method is trained in a semi-self-supervised manner. It does not require target view images and only uses depth data for supervision. Our network has the generalization ability to reconstruct unknown scenes efficiently using only four images. Experimental results show that our method outperforms existing methods in depth estimation and novel view synthesis tasks.
Tokensome: Towards a Genetic Vision-Language GPT for Explainable and Cognitive Karyotyping
Mar 17, 2024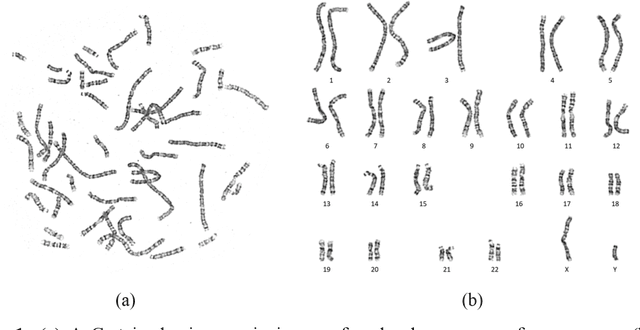
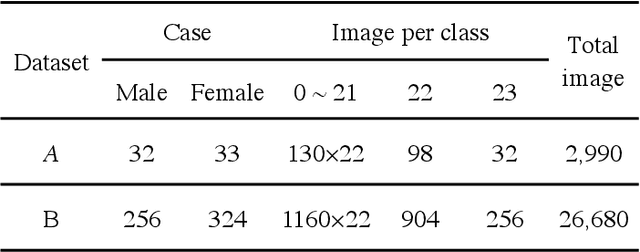
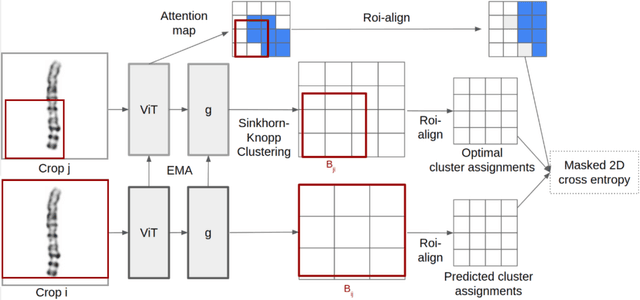
Automatic karyotype analysis is often defined as a visual perception task focused solely on chromosomal object-level modeling. This definition has led most existing methods to overlook componential and holistic information, significantly constraining model performance. Moreover, the lack of interpretability in current technologies hinders clinical adoption. In this paper, we introduce Tokensome, a novel vision-language model based on chromosome tokenization for explainable and cognitive karyotyping. Tokensome elevates the method from the conventional visual perception layer to the cognitive decision-making layer. This elevation enables the integration of domain knowledge and cognitive reasoning via knowledge graphs and LLMs, markedly enhancing model's explainability and facilitating abnormality detection.
Segment Anything for comprehensive analysis of grapevine cluster architecture and berry properties
Mar 19, 2024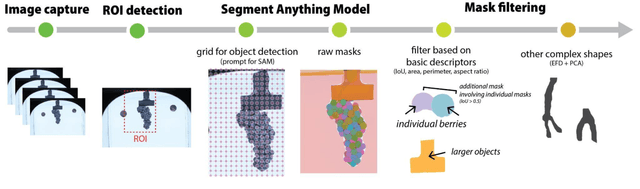
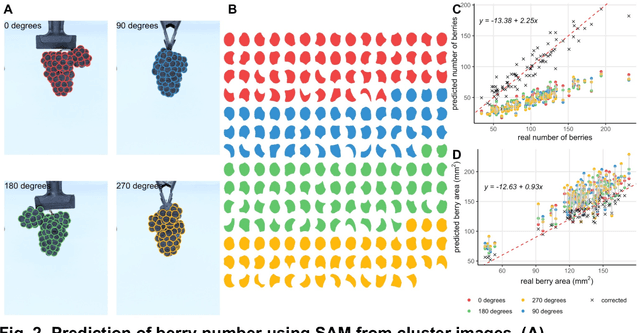
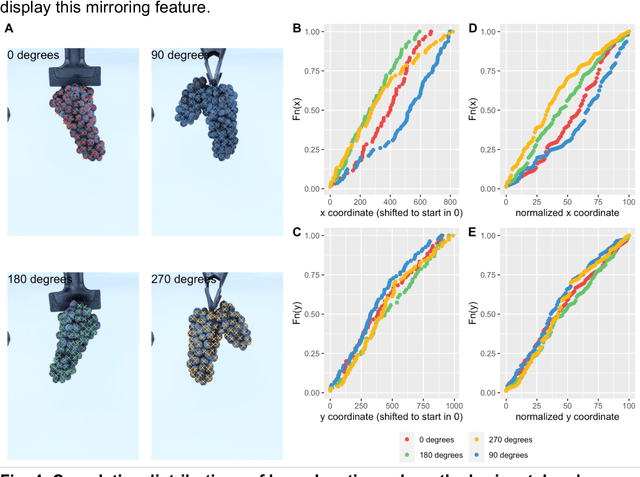

Grape cluster architecture and compactness are complex traits influencing disease susceptibility, fruit quality, and yield. Evaluation methods for these traits include visual scoring, manual methodologies, and computer vision, with the latter being the most scalable approach. Most of the existing computer vision approaches for processing cluster images often rely on conventional segmentation or machine learning with extensive training and limited generalization. The Segment Anything Model (SAM), a novel foundation model trained on a massive image dataset, enables automated object segmentation without additional training. This study demonstrates out-of-the-box SAM's high accuracy in identifying individual berries in 2D cluster images. Using this model, we managed to segment approximately 3,500 cluster images, generating over 150,000 berry masks, each linked with spatial coordinates within their clusters. The correlation between human-identified berries and SAM predictions was very strong (Pearson r2=0.96). Although the visible berry count in images typically underestimates the actual cluster berry count due to visibility issues, we demonstrated that this discrepancy could be adjusted using a linear regression model (adjusted R2=0.87). We emphasized the critical importance of the angle at which the cluster is imaged, noting its substantial effect on berry counts and architecture. We proposed different approaches in which berry location information facilitated the calculation of complex features related to cluster architecture and compactness. Finally, we discussed SAM's potential integration into currently available pipelines for image generation and processing in vineyard conditions.
Diffusion-Driven Self-Supervised Learning for Shape Reconstruction and Pose Estimation
Mar 19, 2024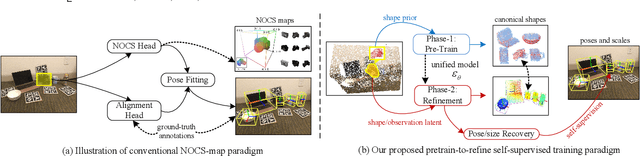

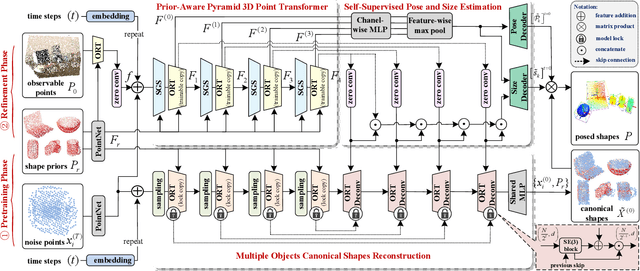
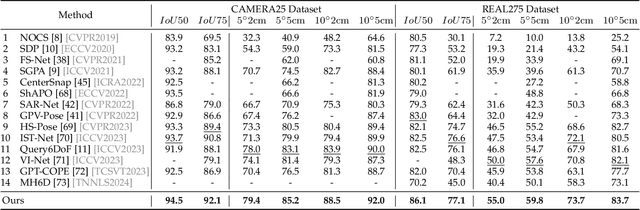
Fully-supervised category-level pose estimation aims to determine the 6-DoF poses of unseen instances from known categories, requiring expensive mannual labeling costs. Recently, various self-supervised category-level pose estimation methods have been proposed to reduce the requirement of the annotated datasets. However, most methods rely on synthetic data or 3D CAD model for self-supervised training, and they are typically limited to addressing single-object pose problems without considering multi-objective tasks or shape reconstruction. To overcome these challenges and limitations, we introduce a diffusion-driven self-supervised network for multi-object shape reconstruction and categorical pose estimation, only leveraging the shape priors. Specifically, to capture the SE(3)-equivariant pose features and 3D scale-invariant shape information, we present a Prior-Aware Pyramid 3D Point Transformer in our network. This module adopts a point convolutional layer with radial-kernels for pose-aware learning and a 3D scale-invariant graph convolution layer for object-level shape representation, respectively. Furthermore, we introduce a pretrain-to-refine self-supervised training paradigm to train our network. It enables proposed network to capture the associations between shape priors and observations, addressing the challenge of intra-class shape variations by utilising the diffusion mechanism. Extensive experiments conducted on four public datasets and a self-built dataset demonstrate that our method significantly outperforms state-of-the-art self-supervised category-level baselines and even surpasses some fully-supervised instance-level and category-level methods.
Learning Cross-view Visual Geo-localization without Ground Truth
Mar 19, 2024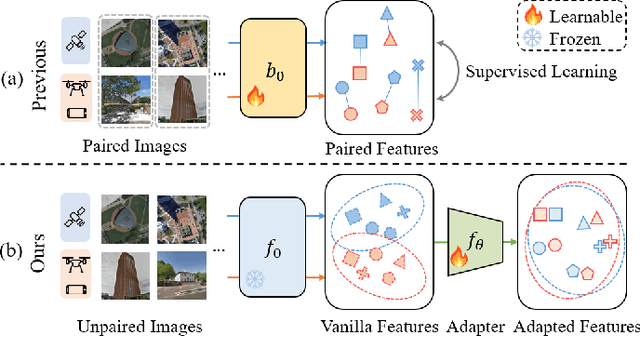
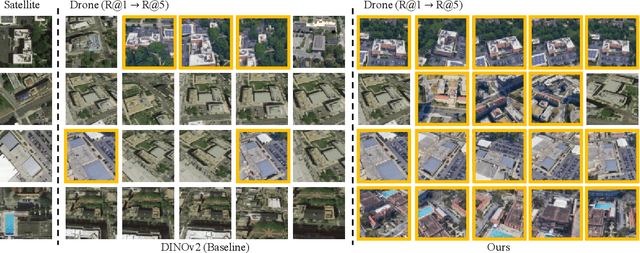
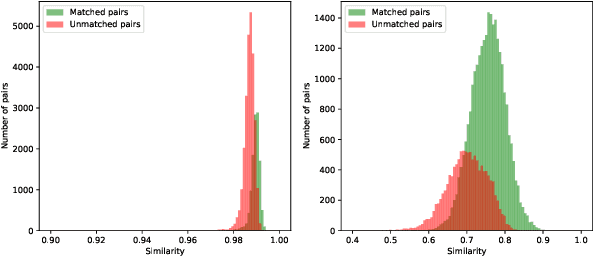
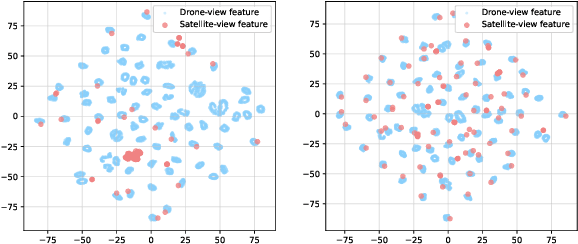
Cross-View Geo-Localization (CVGL) involves determining the geographical location of a query image by matching it with a corresponding GPS-tagged reference image. Current state-of-the-art methods predominantly rely on training models with labeled paired images, incurring substantial annotation costs and training burdens. In this study, we investigate the adaptation of frozen models for CVGL without requiring ground truth pair labels. We observe that training on unlabeled cross-view images presents significant challenges, including the need to establish relationships within unlabeled data and reconcile view discrepancies between uncertain queries and references. To address these challenges, we propose a self-supervised learning framework to train a learnable adapter for a frozen Foundation Model (FM). This adapter is designed to map feature distributions from diverse views into a uniform space using unlabeled data exclusively. To establish relationships within unlabeled data, we introduce an Expectation-Maximization-based Pseudo-labeling module, which iteratively estimates associations between cross-view features and optimizes the adapter. To maintain the robustness of the FM's representation, we incorporate an information consistency module with a reconstruction loss, ensuring that adapted features retain strong discriminative ability across views. Experimental results demonstrate that our proposed method achieves significant improvements over vanilla FMs and competitive accuracy compared to supervised methods, while necessitating fewer training parameters and relying solely on unlabeled data. Evaluation of our adaptation for task-specific models further highlights its broad applicability.
InBox: Recommendation with Knowledge Graph using Interest Box Embedding
Mar 19, 2024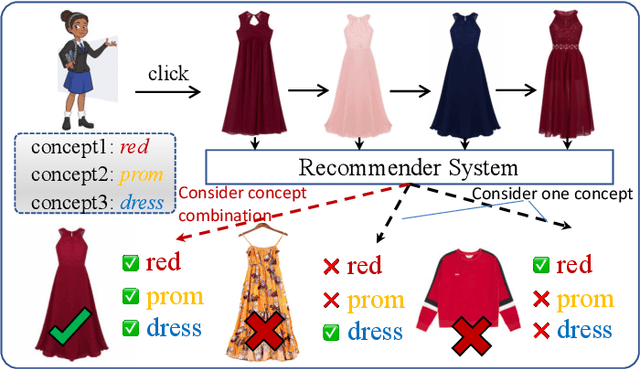
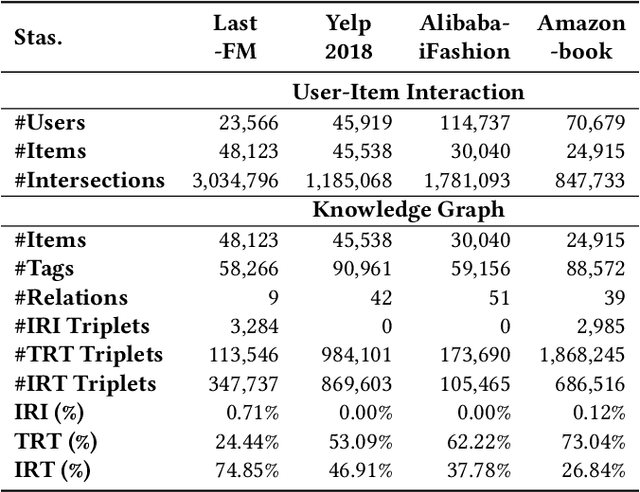
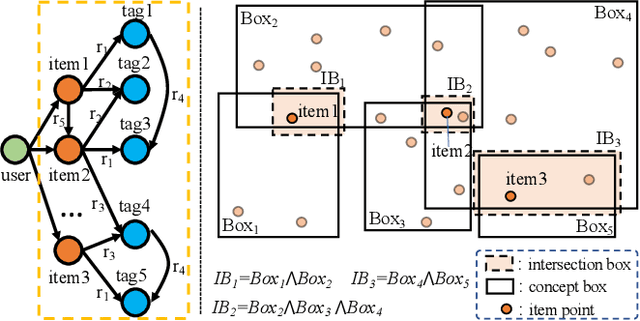
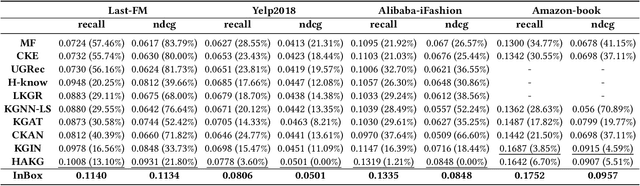
Knowledge graphs (KGs) have become vitally important in modern recommender systems, effectively improving performance and interpretability. Fundamentally, recommender systems aim to identify user interests based on historical interactions and recommend suitable items. However, existing works overlook two key challenges: (1) an interest corresponds to a potentially large set of related items, and (2) the lack of explicit, fine-grained exploitation of KG information and interest connectivity. This leads to an inability to reflect distinctions between entities and interests when modeling them in a single way. Additionally, the granularity of concepts in the knowledge graphs used for recommendations tends to be coarse, failing to match the fine-grained nature of user interests. This homogenization limits the precise exploitation of knowledge graph data and interest connectivity. To address these limitations, we introduce a novel embedding-based model called InBox. Specifically, various knowledge graph entities and relations are embedded as points or boxes, while user interests are modeled as boxes encompassing interaction history. Representing interests as boxes enables containing collections of item points related to that interest. We further propose that an interest comprises diverse basic concepts, and box intersection naturally supports concept combination. Across three training steps, InBox significantly outperforms state-of-the-art methods like HAKG and KGIN on recommendation tasks. Further analysis provides meaningful insights into the variable value of different KG data for recommendations. In summary, InBox advances recommender systems through box-based interest and concept modeling for sophisticated knowledge graph exploitation.
Electioneering the Network: Dynamic Multi-Step Adversarial Attacks for Community Canvassing
Mar 19, 2024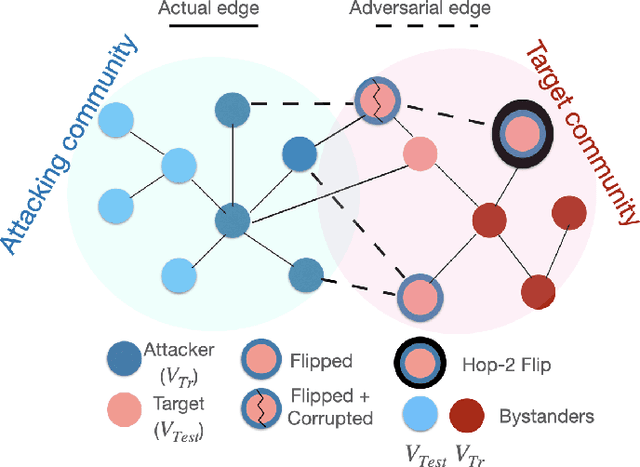
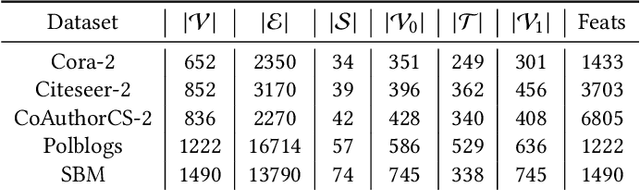
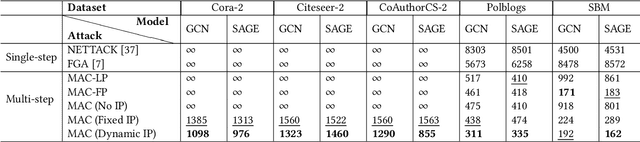
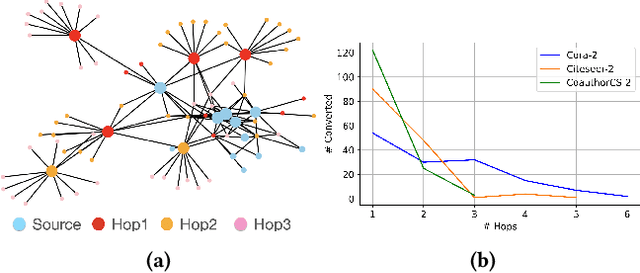
The problem of online social network manipulation for community canvassing is of real concern in today's world. Motivated by the study of voter models, opinion and polarization dynamics on networks, we model community canvassing as a dynamic process over a network enabled via gradient-based attacks on GNNs. Existing attacks on GNNs are all single-step and do not account for the dynamic cascading nature of information diffusion in networks. We consider the realistic scenario where an adversary uses a GNN as a proxy to predict and manipulate voter preferences, especially uncertain voters. Gradient-based attacks on the GNN inform the adversary of strategic manipulations that can be made to proselytize targeted voters. In particular, we explore $\textit{minimum budget attacks for community canvassing}$ (MBACC). We show that the MBACC problem is NP-Hard and propose Dynamic Multi-Step Adversarial Community Canvassing (MAC) to address it. MAC makes dynamic local decisions based on the heuristic of low budget and high second-order influence to convert and perturb target voters. MAC is a dynamic multi-step attack that discovers low-budget and high-influence targets from which efficient cascading attacks can happen. We evaluate MAC against single-step baselines on the MBACC problem with multiple underlying networks and GNN models. Our experiments show the superiority of MAC which is able to discover efficient multi-hop attacks for adversarial community canvassing. Our code implementation and data is available at https://github.com/saurabhsharma1993/mac.