 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identifying TBI Physiological States by Clustering of Multivariate Clinical Time-Series
Mar 30, 2023
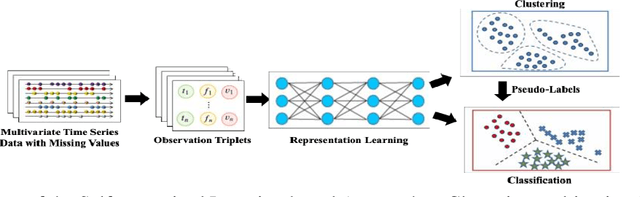
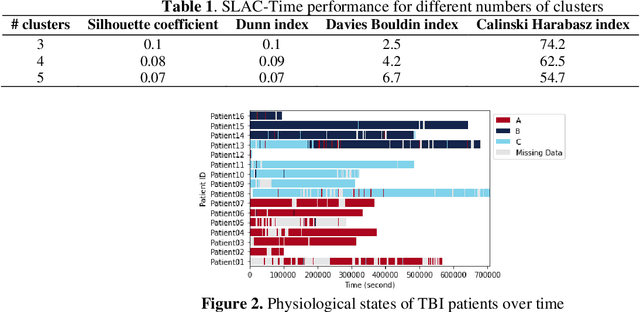


Determining clinically relevant physiological states from multivariate time series data with missing values is essential for providing appropriate treatment for acute conditions such as Traumatic Brain Injury (TBI), respiratory failure, and heart failure. Utilizing non-temporal clustering or data imputation and aggregation techniques may lead to loss of valuable information and biased analyses. In our study, we apply the SLAC-Time algorithm, an innovative self-supervision-based approach that maintains data integrity by avoiding imputation or aggregation, offering a more useful representation of acute patient states. By using SLAC-Time to cluster data in a large research dataset, we identified three distinct TBI physiological states and their specific feature profiles. We employed various clustering evaluation metrics and incorporated input from a clinical domain expert to validate and interpret the identified physiological states. Further, we discovered how specific clinical events and interventions can influence patient states and state transitions.
DRIP: Deep Regularizers for Inverse Problems
Mar 30, 2023
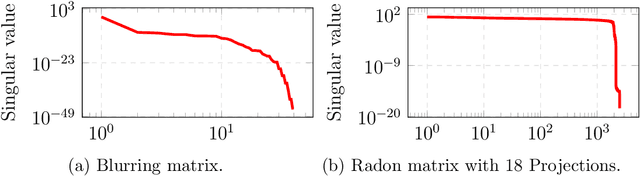

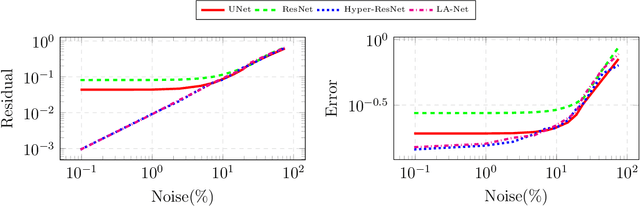
Inverse problems are mathematically ill-posed. Thus, given some (noisy) data, there is more than one solution that fits the data. In recent years, deep neural techniques that find the most appropriate solution, in the sense that it contains a-priori information, were developed. However, they suffer from several shortcomings. First, most techniques cannot guarantee that the solution fits the data at inference. Second, while the derivation of the techniques is inspired by the existence of a valid scalar regularization function, such techniques do not in practice rely on such a function, and therefore veer away from classical variational techniques. In this work we introduce a new family of neural regularizers for the solution of inverse problems. These regularizers are based on a variational formulation and are guaranteed to fit the data. We demonstrate their use on a number of highly ill-posed problems, from image deblurring to limited angle tomography.
Grounding Graph Network Simulators using Physical Sensor Observations
Mar 07, 2023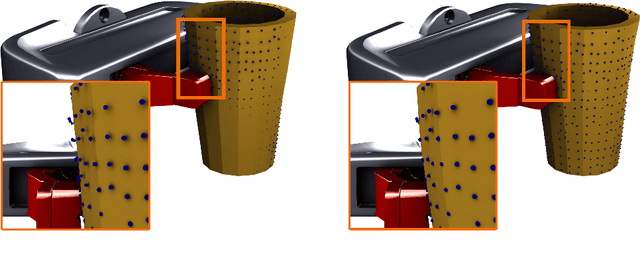

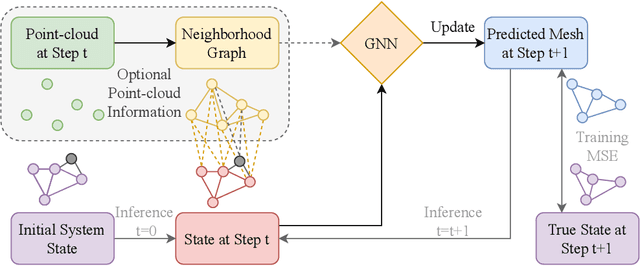
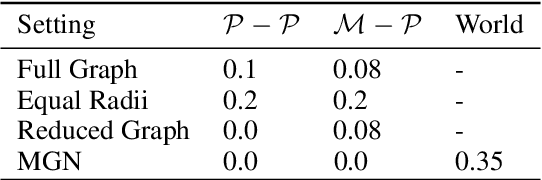
Physical simulations that accurately model reality are crucial for many engineering disciplines such as mechanical engineering and robotic motion planning. In recent years, learned Graph Network Simulators produced accurate mesh-based simulations while requiring only a fraction of the computational cost of traditional simulators. Yet, the resulting predictors are confined to learning from data generated by existing mesh-based simulators and thus cannot include real world sensory information such as point cloud data. As these predictors have to simulate complex physical systems from only an initial state, they exhibit a high error accumulation for long-term predictions. In this work, we integrate sensory information to ground Graph Network Simulators on real world observations. In particular, we predict the mesh state of deformable objects by utilizing point cloud data. The resulting model allows for accurate predictions over longer time horizons, even under uncertainties in the simulation, such as unknown material properties. Since point clouds are usually not available for every time step, especially in online settings, we employ an imputation-based model. The model can make use of such additional information only when provided, and resorts to a standard Graph Network Simulator, otherwise. We experimentally validate our approach on a suite of prediction tasks for mesh-based interactions between soft and rigid bodies. Our method results in utilization of additional point cloud information to accurately predict stable simulations where existing Graph Network Simulators fail.
Structured Epipolar Matcher for Local Feature Matching
Mar 29, 2023
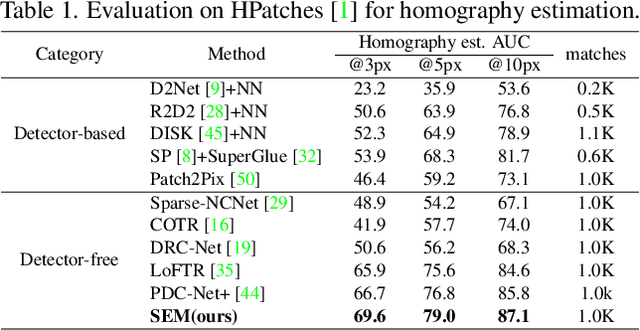

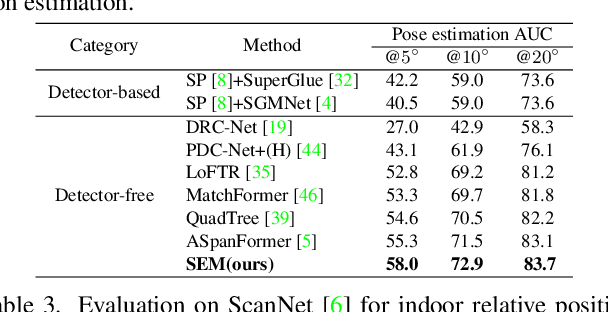
Local feature matching is challenging due to the textureless and repetitive pattern. Existing methods foucs on using appearance features and global interaction and matching, while the importance of geometry prior in local feature matching has not been fully exploited. Different from these methods, in this paper, we delve into the importance of geometry prior and propose Structured Epipolar Matcher (SEM) for local feature matching, which can leverage the geometric information in a iterative matching way. The proposed model enjoys several merits. First, our proposed Structured Feature Extractor can model the relative positional relationship between pixels and high-confidence anchor points. Second, our proposed Epipolar Attention and Matching can filter out irrelevant areas by utilizing the epipolar constraint. Extensive experimental results on five standard benchmarks demonstrate the superior performance of our SEM compared to state-of-the-art methods.
NeuralMind-UNICAMP at 2022 TREC NeuCLIR: Large Boring Rerankers for Cross-lingual Retrieval
Mar 28, 2023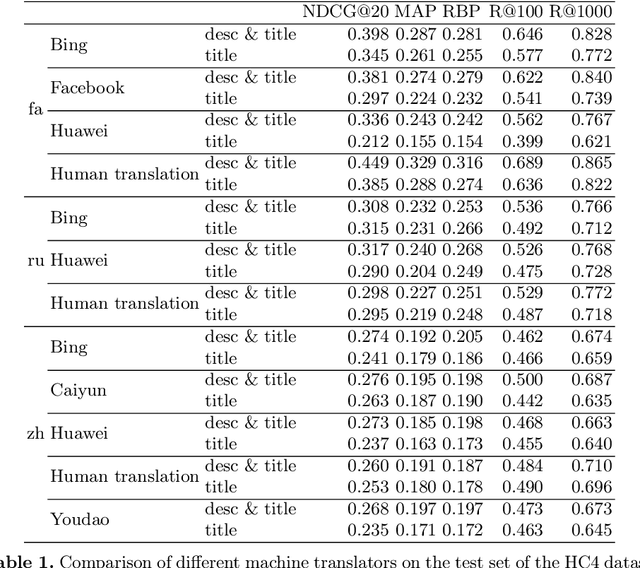
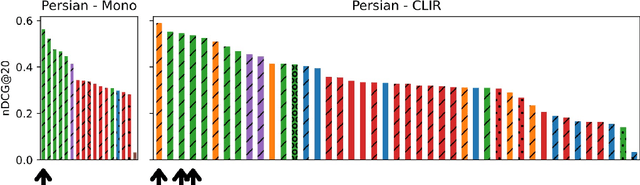
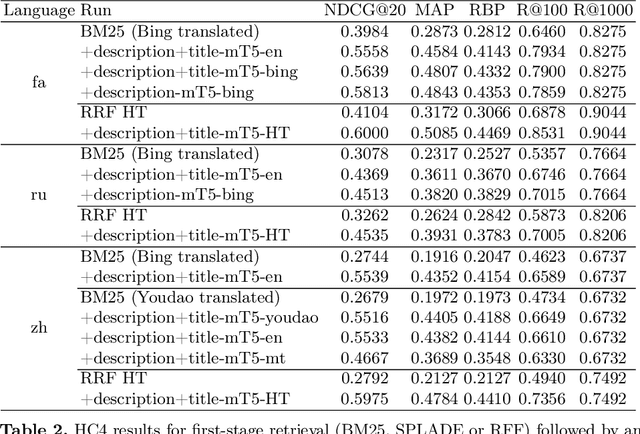
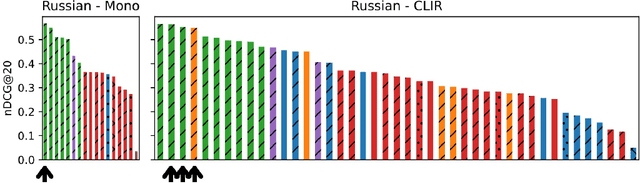
This paper reports on a study of cross-lingual information retrieval (CLIR) using the mT5-XXL reranker on the NeuCLIR track of TREC 2022. Perhaps the biggest contribution of this study is the finding that despite the mT5 model being fine-tuned only on query-document pairs of the same language it proved to be viable for CLIR tasks, where query-document pairs are in different languages, even in the presence of suboptimal first-stage retrieval performance. The results of the study show outstanding performance across all tasks and languages, leading to a high number of winning positions. Finally, this study provides valuable insights into the use of mT5 in CLIR tasks and highlights its potential as a viable solution. For reproduction refer to https://github.com/unicamp-dl/NeuCLIR22-mT5
Scalable, Detailed and Mask-Free Universal Photometric Stereo
Mar 28, 2023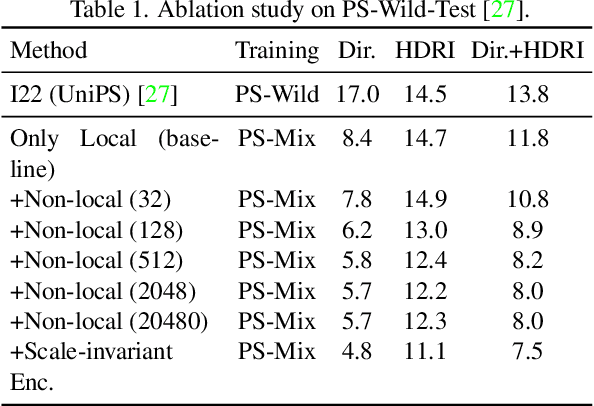
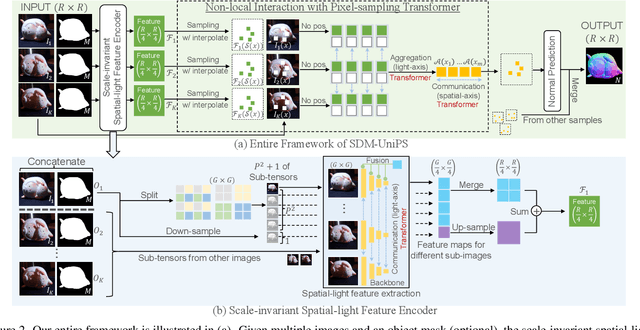
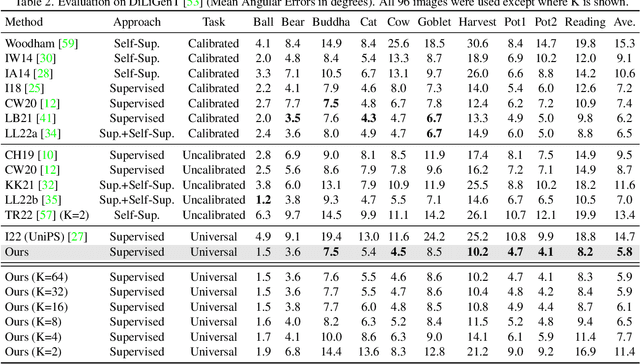

In this paper, we introduce SDM-UniPS, a groundbreaking Scalable, Detailed, Mask-free, and Universal Photometric Stereo network. Our approach can recover astonishingly intricate surface normal maps, rivaling the quality of 3D scanners, even when images are captured under unknown, spatially-varying lighting conditions in uncontrolled environments. We have extended previous universal photometric stereo networks to extract spatial-light features, utilizing all available information in high-resolution input images and accounting for non-local interactions among surface points. Moreover, we present a new synthetic training dataset that encompasses a diverse range of shapes, materials, and illumination scenarios found in real-world scenes. Through extensive evaluation, we demonstrate that our method not only surpasses calibrated, lighting-specific techniques on public benchmarks, but also excels with a significantly smaller number of input images even without object masks.
Reinforcement learning for optimization of energy trading strategy
Mar 28, 2023
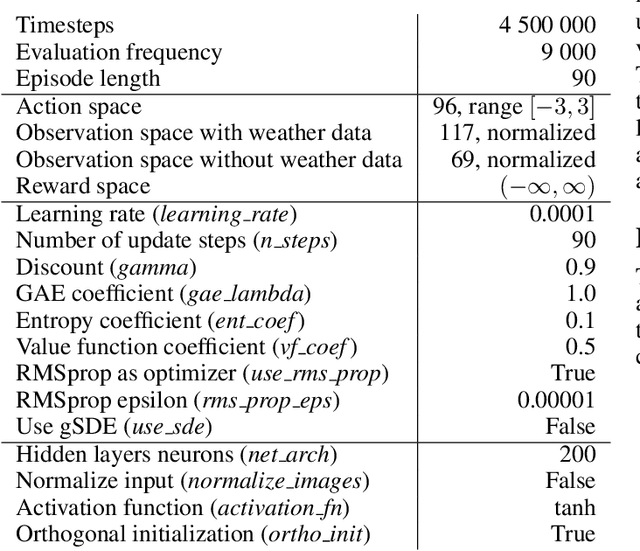

An increasing part of energy is produced from renewable sources by a large number of small producers. The efficiency of these sources is volatile and, to some extent, random, exacerbating the energy market balance problem. In many countries, that balancing is performed on day-ahead (DA) energy markets. In this paper, we consider automated trading on a DA energy market by a medium size prosumer. We model this activity as a Markov Decision Process and formalize a framework in which a ready-to-use strategy can be optimized with real-life data. We synthesize parametric trading strategies and optimize them with an evolutionary algorithm. We also use state-of-the-art reinforcement learning algorithms to optimize a black-box trading strategy fed with available information from the environment that can impact future prices.
BS-GAT Behavior Similarity Based Graph Attention Network for Network Intrusion Detection
Apr 07, 2023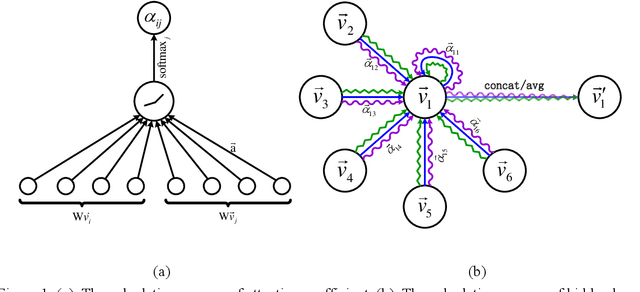
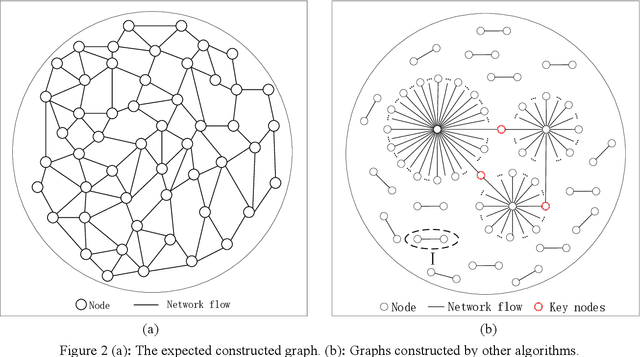
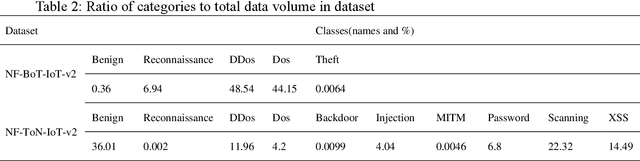
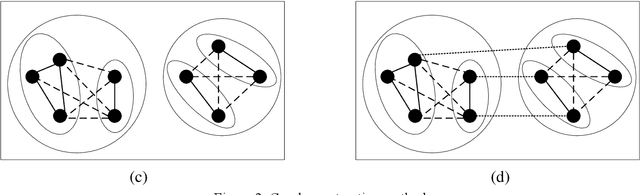
With the development of the Internet of Things (IoT), network intrusion detection is becoming more complex and extensive. It is essential to investigate an intelligent, automated, and robust network intrusion detection method. Graph neural networks based network intrusion detection methods have been proposed. However, it still needs further studies because the graph construction method of the existing methods does not fully adapt to the characteristics of the practical network intrusion datasets. To address the above issue, this paper proposes a graph neural network algorithm based on behavior similarity (BS-GAT) using graph attention network. First, a novel graph construction method is developed using the behavior similarity by analyzing the characteristics of the practical datasets. The data flows are treated as nodes in the graph, and the behavior rules of nodes are used as edges in the graph, constructing a graph with a relatively uniform number of neighbors for each node. Then, the edge behavior relationship weights are incorporated into the graph attention network to utilize the relationship between data flows and the structure information of the graph, which is used to improve the performance of the network intrusion detection. Finally, experiments are conducted based on the latest datasets to evaluate the performance of the proposed behavior similarity based graph attention network for the network intrusion detection. The results show that the proposed method is effective and has superior performance comparing to existing solutions.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023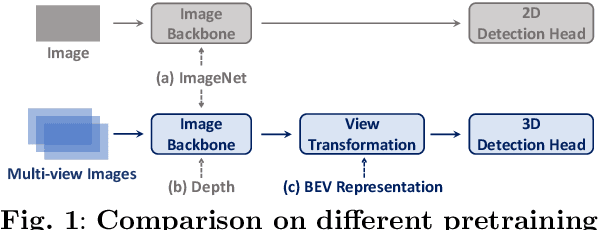
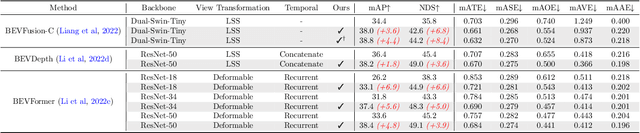
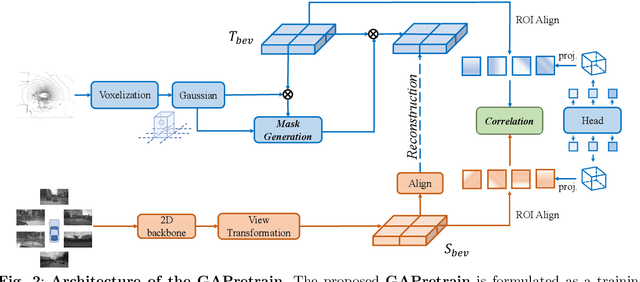
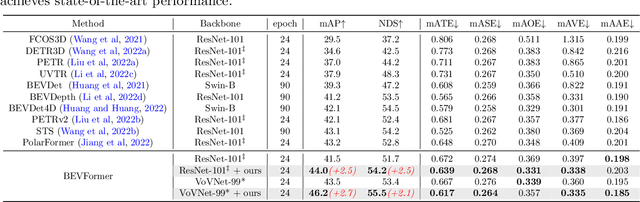
Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
Apr 03, 2023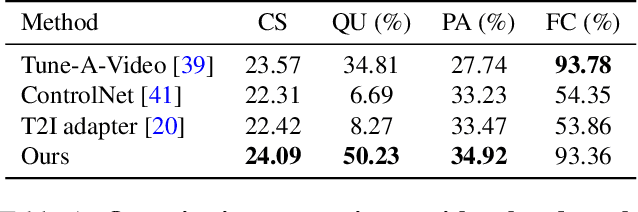
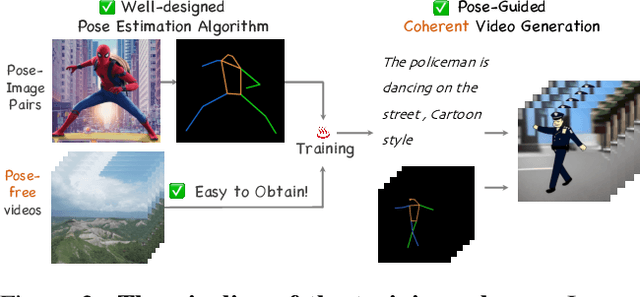
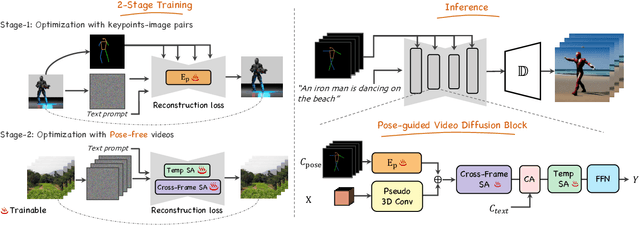

Generating text-editable and pose-controllable character videos have an imperious demand in creating various digital human. Nevertheless, this task has been restricted by the absence of a comprehensive dataset featuring paired video-pose captions and the generative prior models for videos. In this work, we design a novel two-stage training scheme that can utilize easily obtained datasets (i.e.,image pose pair and pose-free video) and the pre-trained text-to-image (T2I) model to obtain the pose-controllable character videos. Specifically, in the first stage, only the keypoint-image pairs are used only for a controllable text-to-image generation. We learn a zero-initialized convolu- tional encoder to encode the pose information. In the second stage, we finetune the motion of the above network via a pose-free video dataset by adding the learnable temporal self-attention and reformed cross-frame self-attention blocks. Powered by our new designs, our method successfully generates continuously pose-controllable character videos while keeps the editing and concept composition ability of the pre-trained T2I model. The code and models will be made publicly available.