 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Training-Free Layout Control with Cross-Attention Guidance
Apr 06, 2023
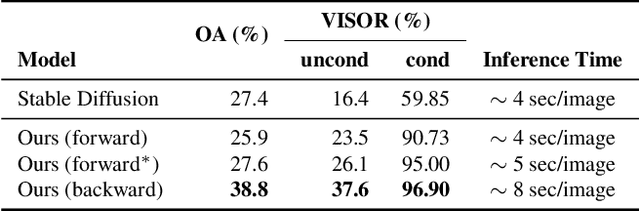
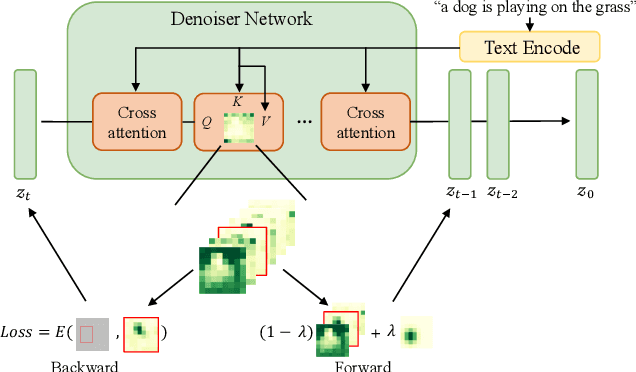
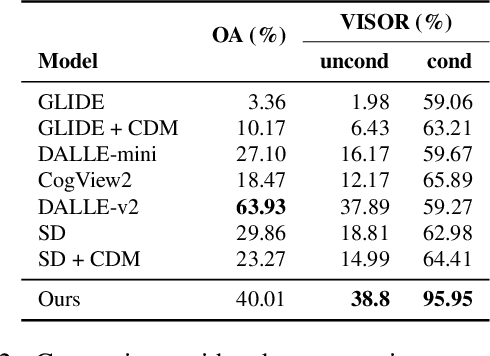
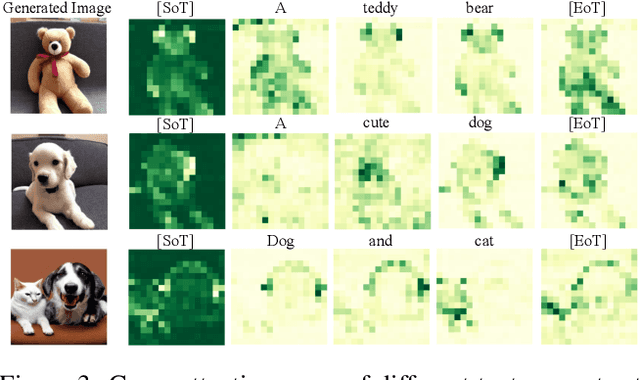
Recent diffusion-based generators can produce high-quality images based only on textual prompts. However, they do not correctly interpret instructions that specify the spatial layout of the composition. We propose a simple approach that can achieve robust layout control without requiring training or fine-tuning the image generator. Our technique, which we call layout guidance, manipulates the cross-attention layers that the model uses to interface textual and visual information and steers the reconstruction in the desired direction given, e.g., a user-specified layout. In order to determine how to best guide attention, we study the role of different attention maps when generating images and experiment with two alternative strategies, forward and backward guidance. We evaluate our method quantitatively and qualitatively with several experiments, validating its effectiveness. We further demonstrate its versatility by extending layout guidance to the task of editing the layout and context of a given real image.
Exactly mergeable summaries
Mar 25, 2023In the analysis of large/big data sets, aggregation (replacing values of a variable over a group by a single value) is a standard way of reducing the size (complexity) of the data. Data analysis programs provide different aggregation functions. Recently some books dealing with the theoretical and algorithmic background of traditional aggregation functions were published. A problem with traditional aggregation is that often too much information is discarded thus reducing the precision of the obtained results. A much better, preserving more information, summarization of original data can be achieved by representing aggregated data using selected types of complex data. In complex data analysis the measured values over a selected group $A$ are aggregated into a complex object $\Sigma(A)$ and not into a single value. Most of the aggregation functions theory does not apply directly. In our contribution, we present an attempt to start building a theoretical background of complex aggregation. We introduce and discuss exactly mergeable summaries for which it holds for merging of disjoint sets of units \[ \Sigma(A \cup B) = F( \Sigma(A),\Sigma(B)),\qquad \mbox{ for } \quad A\cap B = \emptyset .\]
A New Paradigm for Device-free Indoor Localization: Deep Learning with Error Vector Spectrum in Wi-Fi Systems
Mar 25, 2023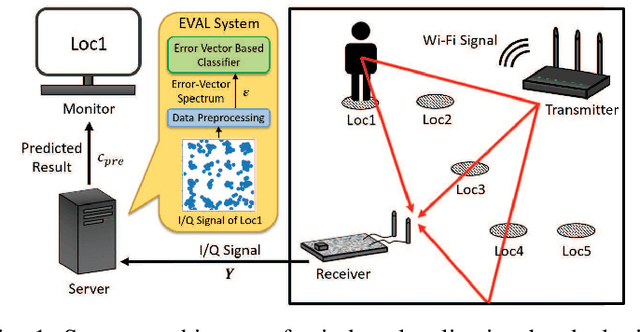
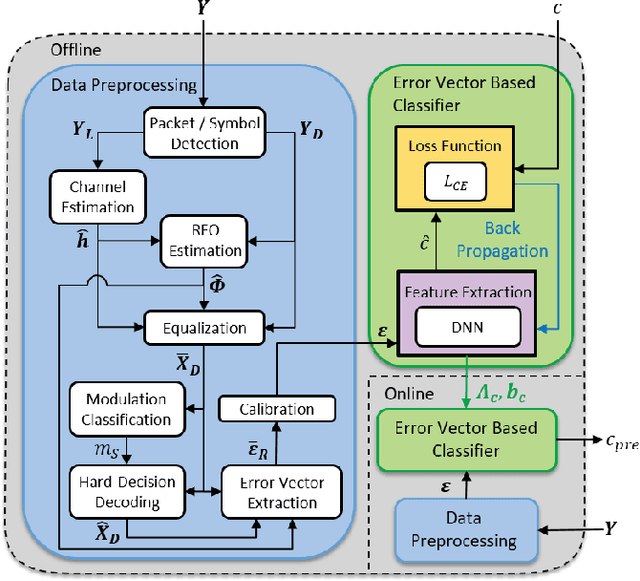
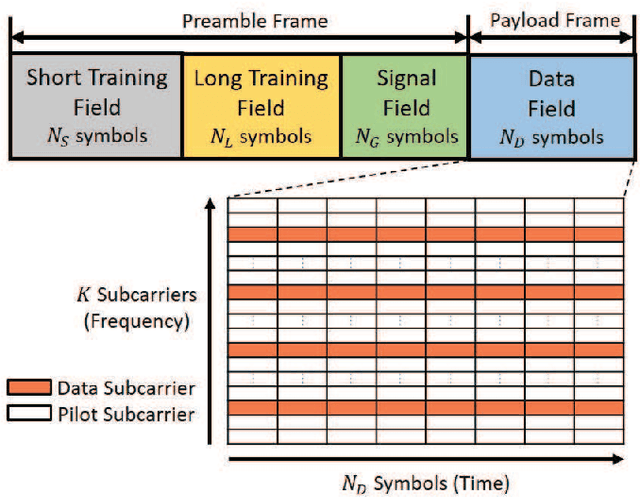
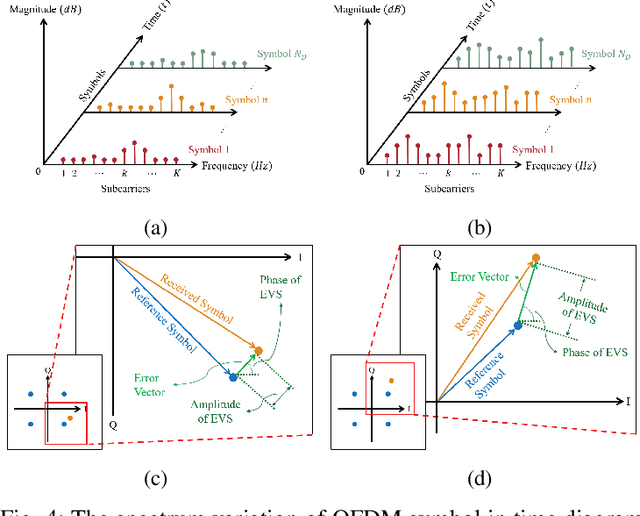
The demand for device-free indoor localization using commercial Wi-Fi devices has rapidly increased in various fields due to its convenience and versatile applications. However, random frequency offset (RFO) in wireless channels poses challenges to the accuracy of indoor localization when using fluctuating channel state information (CSI). To mitigate the RFO problem, an error vector spectrum (EVS) is conceived thanks to its higher resolution of signal and robustness to RFO. To address these challenges, this paper proposed a novel error vector assisted learning (EVAL) for device-free indoor localization. The proposed EVAL scheme employs deep neural networks to classify the location of a person in the indoor environment by extracting ample channel features from the physical layer signals. We conducted realistic experiments based on OpenWiFi project to extract both EVS and CSI to examine the performance of different device-free localization techniques. Experimental results show that our proposed EVAL scheme outperforms conventional machine learning methods and benchmarks utilizing either CSI amplitude or phase information. Compared to most existing CSI-based localization schemes, a new paradigm with higher positioning accuracy by adopting EVS is revealed by our proposed EVAL system.
Multi-fidelity prediction of fluid flow and temperature field based on transfer learning using Fourier Neural Operator
Apr 14, 2023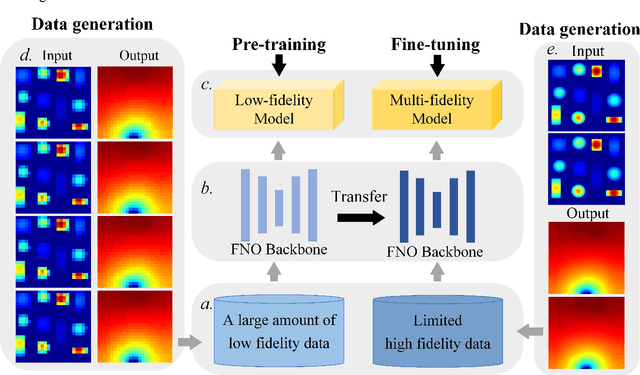
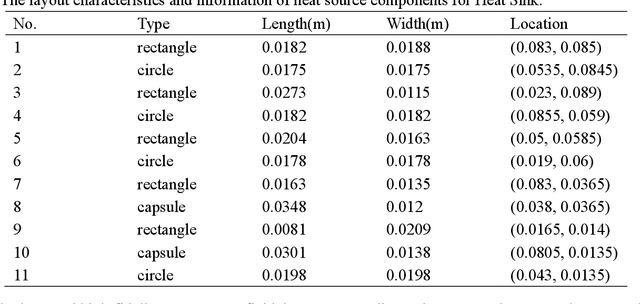
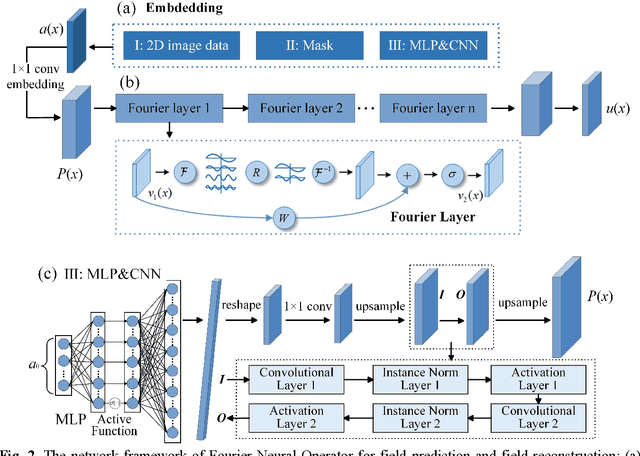
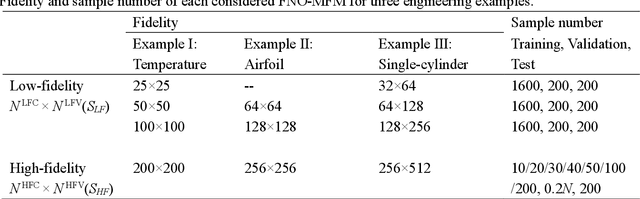
Data-driven prediction of fluid flow and temperature distribution in marine and aerospace engineering has received extensive research and demonstrated its potential in real-time prediction recently. However, usually large amounts of high-fidelity data are required to describe and accurately predict the complex physical information, while in reality, only limited high-fidelity data is available due to the high experiment/computational cost. Therefore, this work proposes a novel multi-fidelity learning method based on the Fourier Neural Operator by jointing abundant low-fidelity data and limited high-fidelity data under transfer learning paradigm. First, as a resolution-invariant operator, the Fourier Neural Operator is first and gainfully applied to integrate multi-fidelity data directly, which can utilize the scarce high-fidelity data and abundant low-fidelity data simultaneously. Then, the transfer learning framework is developed for the current task by extracting the rich low-fidelity data knowledge to assist high-fidelity modeling training, to further improve data-driven prediction accuracy. Finally, three typical fluid and temperature prediction problems are chosen to validate the accuracy of the proposed multi-fidelity model. The results demonstrate that our proposed method has high effectiveness when compared with other high-fidelity models, and has the high modeling accuracy of 99% for all the selected physical field problems. Significantly, the proposed multi-fidelity learning method has the potential of a simple structure with high precision, which can provide a reference for the construction of the subsequent model.
AGNN: Alternating Graph-Regularized Neural Networks to Alleviate Over-Smoothing
Apr 14, 2023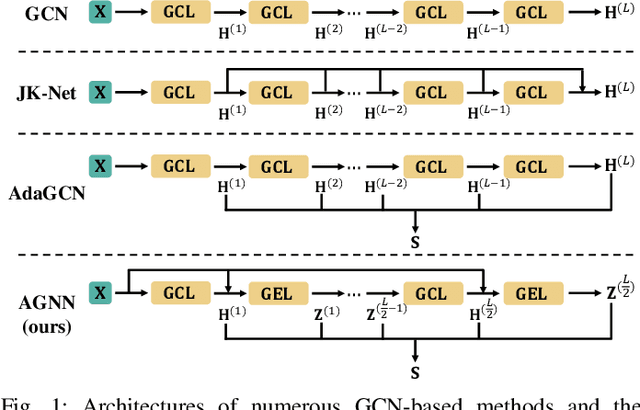
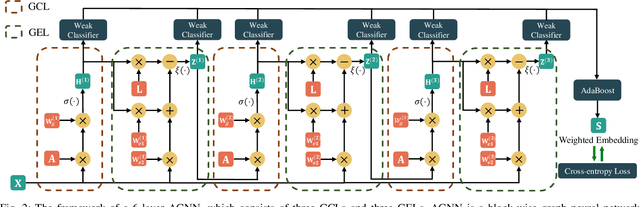
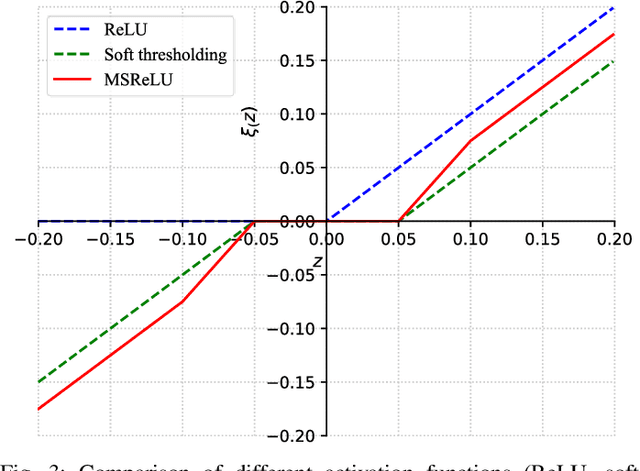
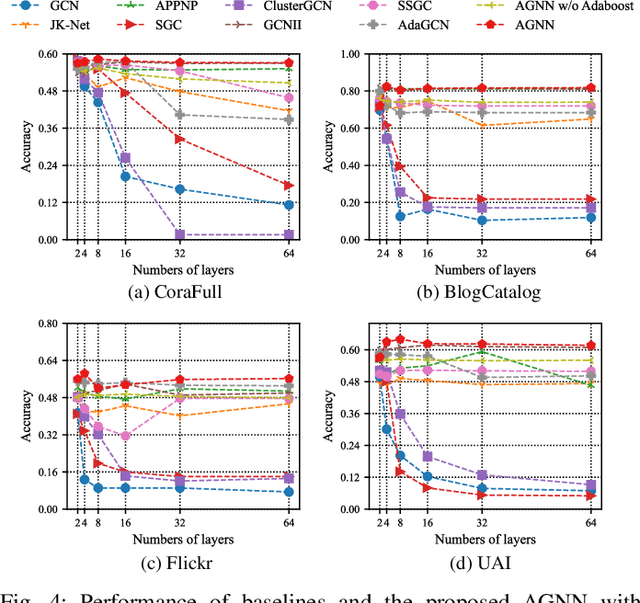
Graph Convolutional Network (GCN) with the powerful capacity to explore graph-structural data has gained noticeable success in recent years. Nonetheless, most of the existing GCN-based models suffer from the notorious over-smoothing issue, owing to which shallow networks are extensively adopted. This may be problematic for complex graph datasets because a deeper GCN should be beneficial to propagating information across remote neighbors. Recent works have devoted effort to addressing over-smoothing problems, including establishing residual connection structure or fusing predictions from multi-layer models. Because of the indistinguishable embeddings from deep layers, it is reasonable to generate more reliable predictions before conducting the combination of outputs from various layers. In light of this, we propose an Alternating Graph-regularized Neural Network (AGNN) composed of Graph Convolutional Layer (GCL) and Graph Embedding Layer (GEL). GEL is derived from the graph-regularized optimization containing Laplacian embedding term, which can alleviate the over-smoothing problem by periodic projection from the low-order feature space onto the high-order space. With more distinguishable features of distinct layers, an improved Adaboost strategy is utilized to aggregate outputs from each layer, which explores integrated embeddings of multi-hop neighbors. The proposed model is evaluated via a large number of experiments including performance comparison with some multi-layer or multi-order graph neural networks, which reveals the superior performance improvement of AGNN compared with state-of-the-art models.
Robust Body Exposure (RoBE): A Graph-based Dynamics Modeling Approach to Manipulating Blankets over People
Apr 10, 2023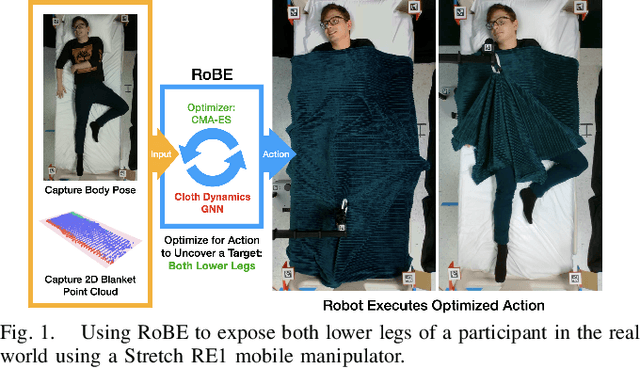



Robotic caregivers could potentially improve the quality of life of many who require physical assistance. However, in order to assist individuals who are lying in bed, robots must be capable of dealing with a significant obstacle: the blanket or sheet that will almost always cover the person's body. We propose a method for targeted bedding manipulation over people lying supine in bed where we first learn a model of the cloth's dynamics. Then, we optimize over this model to uncover a given target limb using information about human body shape and pose that only needs to be provided at run-time. We show how this approach enables greater robustness to variation relative to geometric and reinforcement learning baselines via a number of generalization evaluations in simulation and in the real world. We further evaluate our approach in a human study with 12 participants where we demonstrate that a mobile manipulator can adapt to real variation in human body shape, size, pose, and blanket configuration to uncover target body parts without exposing the rest of the body. Source code and supplementary materials are available online.
MERMAIDE: Learning to Align Learners using Model-Based Meta-Learning
Apr 10, 2023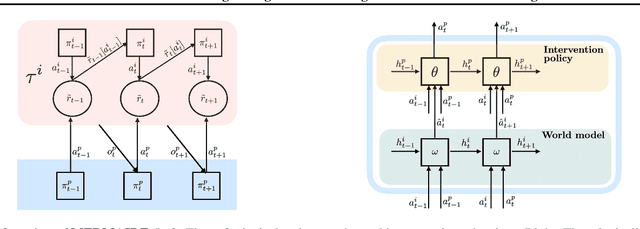
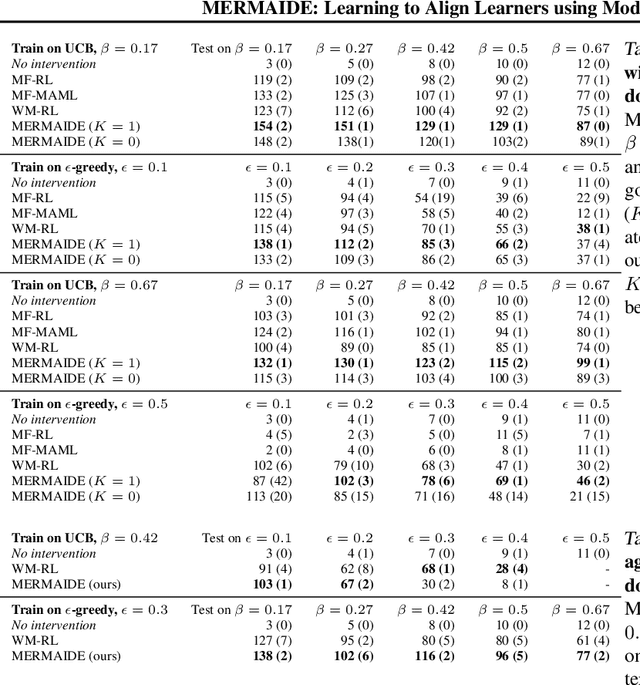
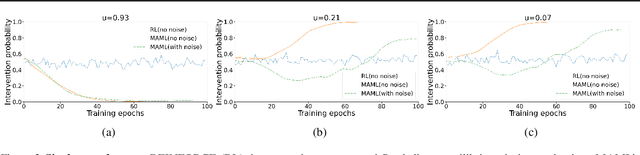
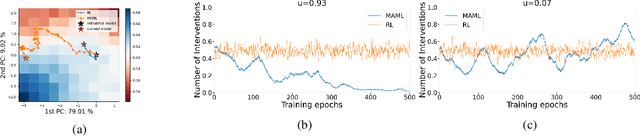
We study how a principal can efficiently and effectively intervene on the rewards of a previously unseen learning agent in order to induce desirable outcomes. This is relevant to many real-world settings like auctions or taxation, where the principal may not know the learning behavior nor the rewards of real people. Moreover, the principal should be few-shot adaptable and minimize the number of interventions, because interventions are often costly. We introduce MERMAIDE, a model-based meta-learning framework to train a principal that can quickly adapt to out-of-distribution agents with different learning strategies and reward functions. We validate this approach step-by-step. First, in a Stackelberg setting with a best-response agent, we show that meta-learning enables quick convergence to the theoretically known Stackelberg equilibrium at test time, although noisy observations severely increase the sample complexity. We then show that our model-based meta-learning approach is cost-effective in intervening on bandit agents with unseen explore-exploit strategies. Finally, we outperform baselines that use either meta-learning or agent behavior modeling, in both $0$-shot and $K=1$-shot settings with partial agent information.
PoseFusion: Robust Object-in-Hand Pose Estimation with SelectLSTM
Apr 10, 2023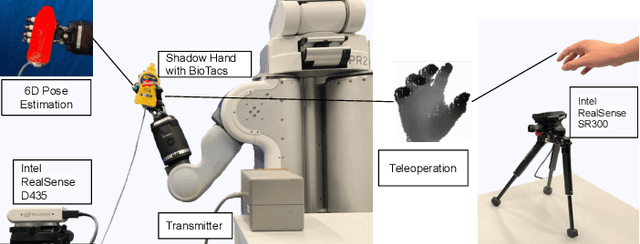
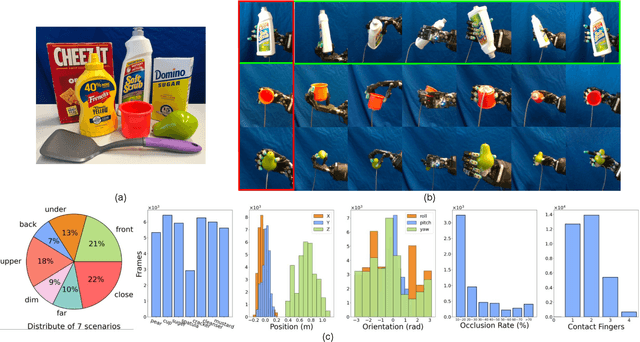

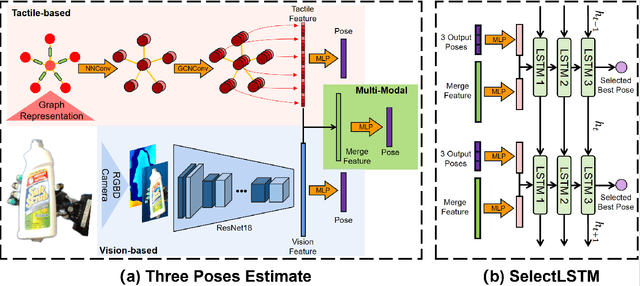
Accurate estimation of the relative pose between an object and a robot hand is critical for many manipulation tasks. However, most of the existing object-in-hand pose datasets use two-finger grippers and also assume that the object remains fixed in the hand without any relative movements, which is not representative of real-world scenarios. To address this issue, a 6D object-in-hand pose dataset is proposed using a teleoperation method with an anthropomorphic Shadow Dexterous hand. Our dataset comprises RGB-D images, proprioception and tactile data, covering diverse grasping poses, finger contact states, and object occlusions. To overcome the significant hand occlusion and limited tactile sensor contact in real-world scenarios, we propose PoseFusion, a hybrid multi-modal fusion approach that integrates the information from visual and tactile perception channels. PoseFusion generates three candidate object poses from three estimators (tactile only, visual only, and visuo-tactile fusion), which are then filtered by a SelectLSTM network to select the optimal pose, avoiding inferior fusion poses resulting from modality collapse. Extensive experiments demonstrate the robustness and advantages of our framework. All data and codes are available on the project website: https://elevenjiang1.github.io/ObjectInHand-Dataset/
Learning solution of nonlinear constitutive material models using physics-informed neural networks: COMM-PINN
Apr 10, 2023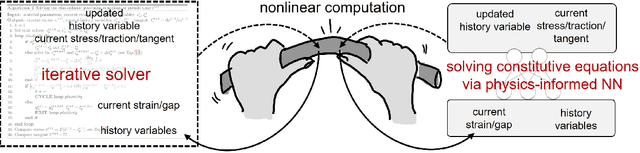
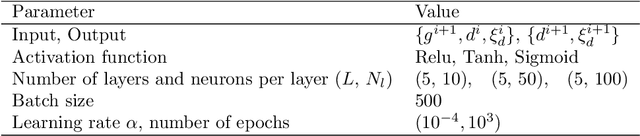
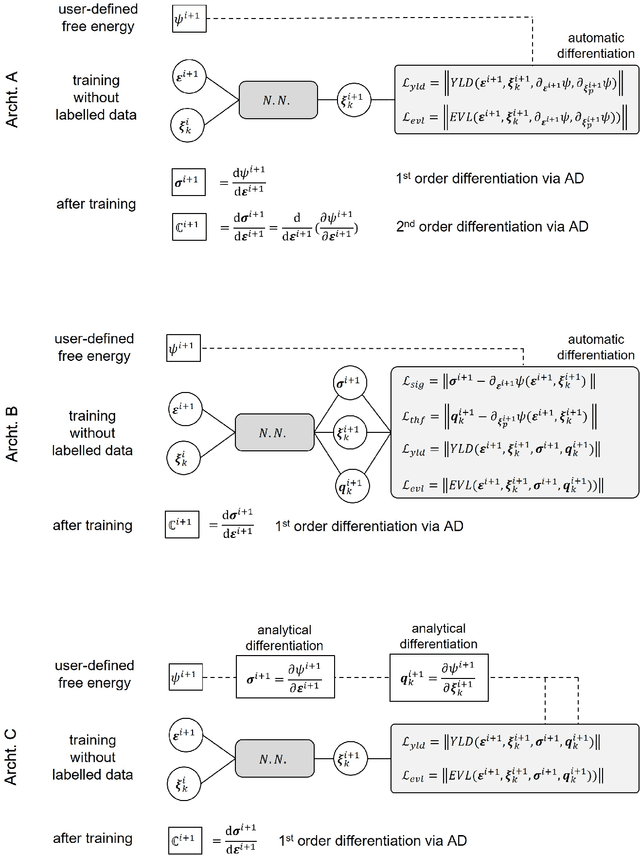

We applied physics-informed neural networks to solve the constitutive relations for nonlinear, path-dependent material behavior. As a result, the trained network not only satisfies all thermodynamic constraints but also instantly provides information about the current material state (i.e., free energy, stress, and the evolution of internal variables) under any given loading scenario without requiring initial data. One advantage of this work is that it bypasses the repetitive Newton iterations needed to solve nonlinear equations in complex material models. Additionally, strategies are provided to reduce the required order of derivation for obtaining the tangent operator. The trained model can be directly used in any finite element package (or other numerical methods) as a user-defined material model. However, challenges remain in the proper definition of collocation points and in integrating several non-equality constraints that become active or non-active simultaneously. We tested this methodology on rate-independent processes such as the classical von Mises plasticity model with a nonlinear hardening law, as well as local damage models for interface cracking behavior with a nonlinear softening law. Finally, we discuss the potential and remaining challenges for future developments of this new approach.
MS3D: Leveraging Multiple Detectors for Unsupervised Domain Adaptation in 3D Object Detection
Apr 10, 2023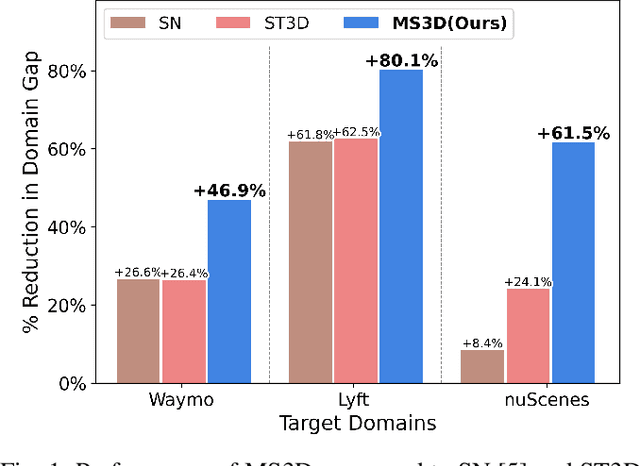
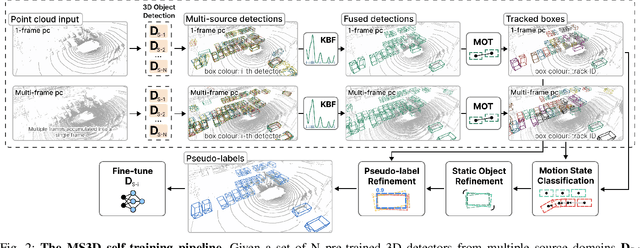
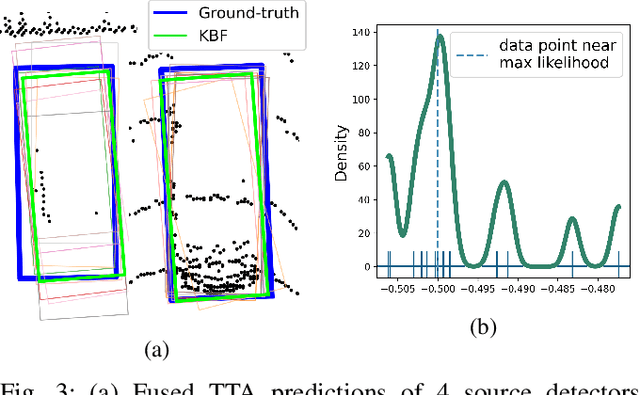
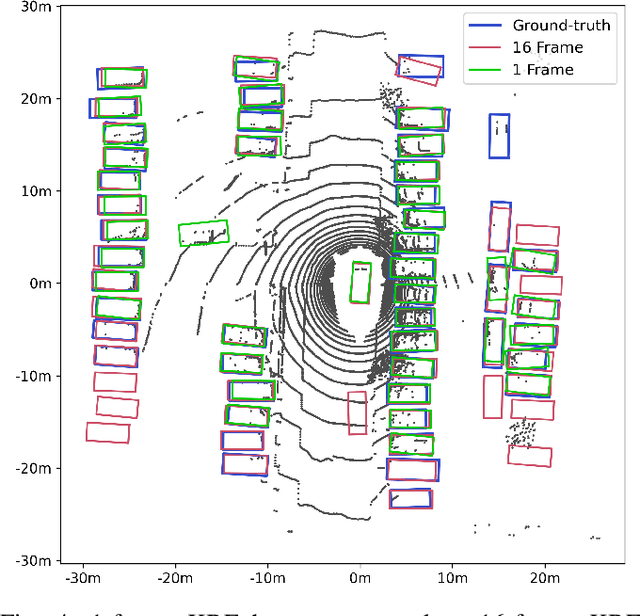
We introduce Multi-Source 3D (MS3D), a new self-training pipeline for unsupervised domain adaptation in 3D object detection. Despite the remarkable accuracy of 3D detectors, they often overfit to specific domain biases, leading to suboptimal performance in various sensor setups and environments. Existing methods typically focus on adapting a single detector to the target domain, overlooking the fact that different detectors possess distinct expertise on different unseen domains. MS3D leverages this by combining different pre-trained detectors from multiple source domains and incorporating temporal information to produce high-quality pseudo-labels for fine-tuning. Our proposed Kernel-Density Estimation (KDE) Box Fusion method fuses box proposals from multiple domains to obtain pseudo-labels that surpass the performance of the best source domain detectors. MS3D exhibits greater robustness to domain shifts and produces accurate pseudo-labels over greater distances, making it well-suited for high-to-low beam domain adaptation and vice versa. Our method achieved state-of-the-art performance on all evaluated datasets, and we demonstrate that the choice of pre-trained source detectors has minimal impact on the self-training result, making MS3D suitable for real-world applications.