 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
Mar 01, 2023
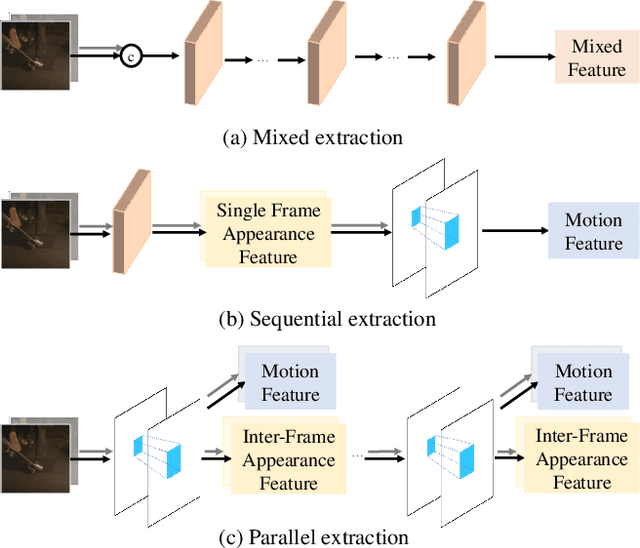
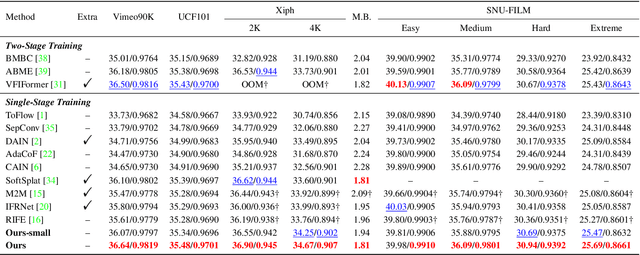
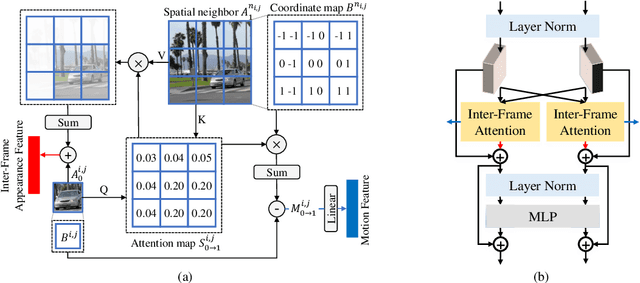
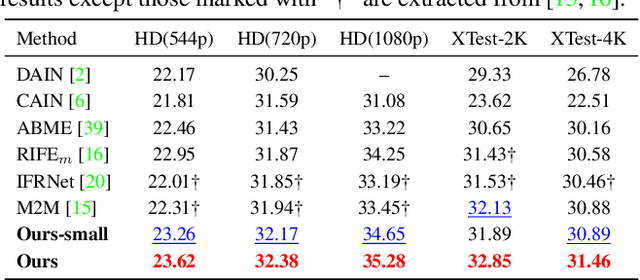
Effectively extracting inter-frame motion and appearance information is important for video frame interpolation (VFI). Previous works either extract both types of information in a mixed way or elaborate separate modules for each type of information, which lead to representation ambiguity and low efficiency. In this paper, we propose a novel module to explicitly extract motion and appearance information via a unifying operation. Specifically, we rethink the information process in inter-frame attention and reuse its attention map for both appearance feature enhancement and motion information extraction. Furthermore, for efficient VFI, our proposed module could be seamlessly integrated into a hybrid CNN and Transformer architecture. This hybrid pipeline can alleviate the computational complexity of inter-frame attention as well as preserve detailed low-level structure information. Experimental results demonstrate that, for both fixed- and arbitrary-timestep interpolation, our method achieves state-of-the-art performance on various datasets. Meanwhile, our approach enjoys a lighter computation overhead over models with close performance. The source code and models are available at https://github.com/MCG-NJU/EMA-VFI.
Communication-Efficient Design for Quantized Decentralized Federated Learning
Mar 15, 2023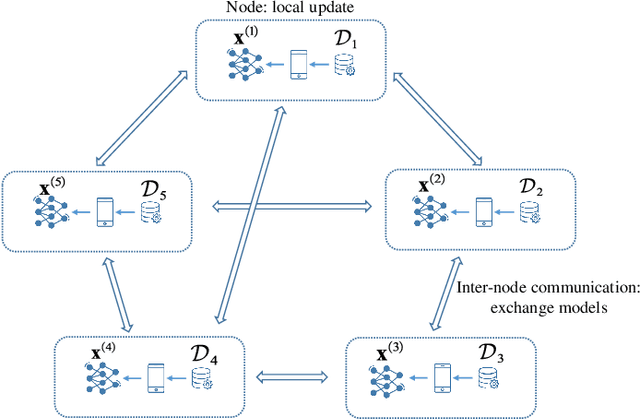
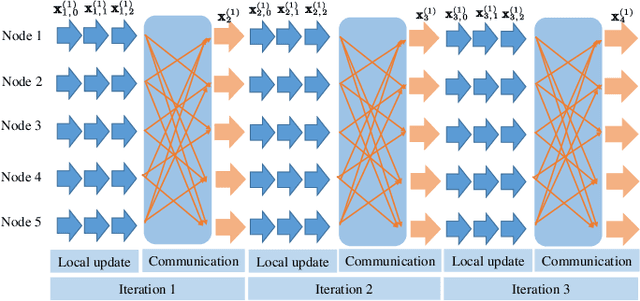
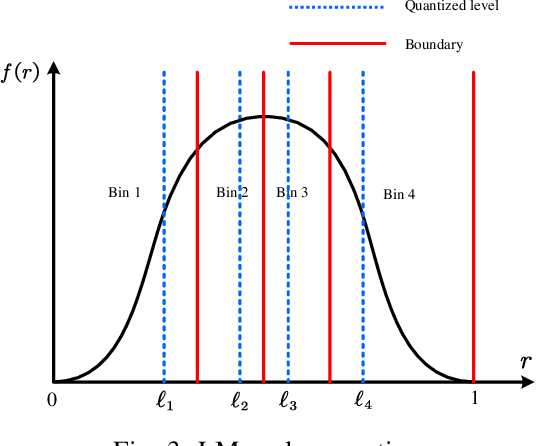
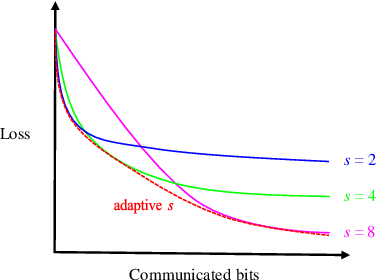
Decentralized federated learning (DFL) is a variant of federated learning, where edge nodes only communicate with their one-hop neighbors to learn the optimal model. However, as information exchange is restricted in a range of one-hop in DFL, inefficient information exchange leads to more communication rounds to reach the targeted training loss. This greatly reduces the communication efficiency. In this paper, we propose a new non-uniform quantization of model parameters to improve DFL convergence. Specifically, we apply the Lloyd-Max algorithm to DFL (LM-DFL) first to minimize the quantization distortion by adjusting the quantization levels adaptively. Convergence guarantee of LM-DFL is established without convex loss assumption. Based on LM-DFL, we then propose a new doubly-adaptive DFL, which jointly considers the ascending number of quantization levels to reduce the amount of communicated information in the training and adapts the quantization levels for non-uniform gradient distributions. Experiment results based on MNIST and CIFAR-10 datasets illustrate the superiority of LM-DFL with the optimal quantized distortion and show that doubly-adaptive DFL can greatly improve communication efficiency.
Partial Information Decomposition Reveals the Structure of Neural Representations
Sep 21, 2022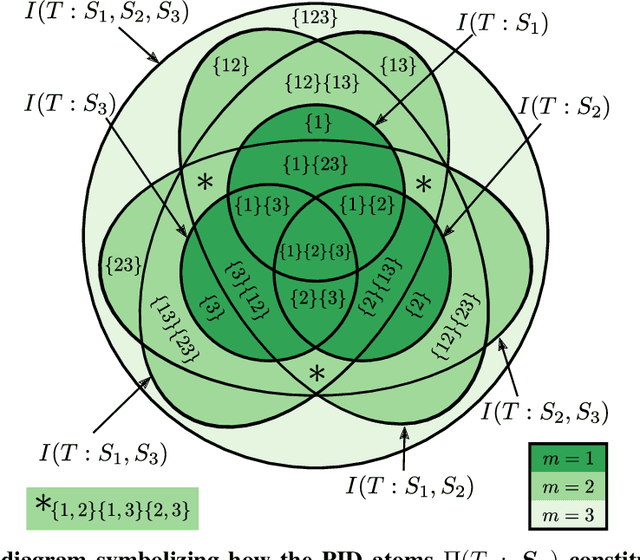
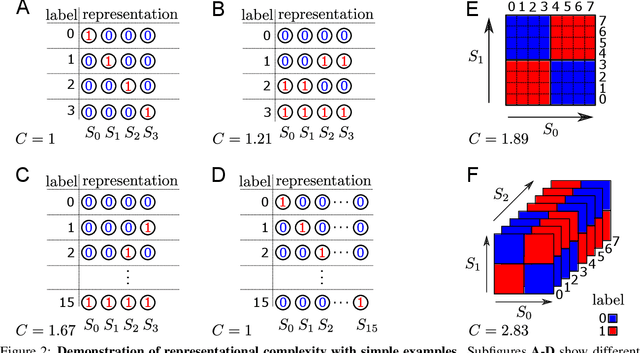
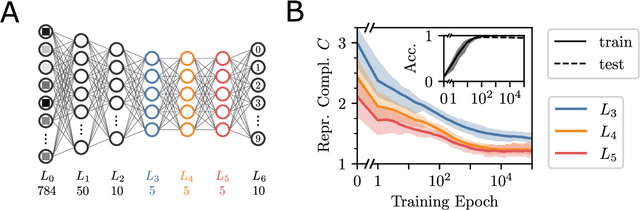
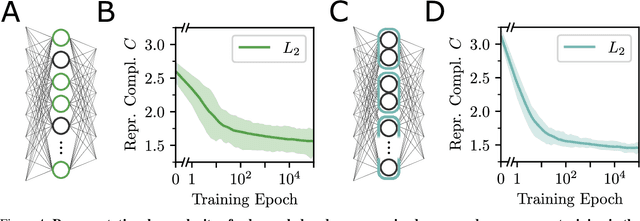
In neural networks, task-relevant information is represented jointly by groups of neurons. However, the specific way in which the information is distributed among the individual neurons is not well understood: While parts of it may only be obtainable from specific single neurons, other parts are carried redundantly or synergistically by multiple neurons. We show how Partial Information Decomposition (PID), a recent extension of information theory, can disentangle these contributions. From this, we introduce the measure of "Representational Complexity", which quantifies the difficulty of accessing information spread across multiple neurons. We show how this complexity is directly computable for smaller layers. For larger layers, we propose subsampling and coarse-graining procedures and prove corresponding bounds on the latter. Empirically, for quantized deep neural networks solving the MNIST task, we observe that representational complexity decreases both through successive hidden layers and over training. Overall, we propose representational complexity as a principled and interpretable summary statistic for analyzing the structure of neural representations.
[CLS] Token is All You Need for Zero-Shot Semantic Segmentation
Apr 13, 2023![Figure 1 for [CLS] Token is All You Need for Zero-Shot Semantic Segmentation](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F41e4032fd65266a6199b32e4d33b02ab3e960885%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for [CLS] Token is All You Need for Zero-Shot Semantic Segmentation](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F41e4032fd65266a6199b32e4d33b02ab3e960885%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for [CLS] Token is All You Need for Zero-Shot Semantic Segmentation](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F41e4032fd65266a6199b32e4d33b02ab3e960885%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [CLS] Token is All You Need for Zero-Shot Semantic Segmentation](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F41e4032fd65266a6199b32e4d33b02ab3e960885%2F6-Table2-1.png&w=640&q=75)
In this paper, we propose an embarrassingly simple yet highly effective zero-shot semantic segmentation (ZS3) method, based on the pre-trained vision-language model CLIP. First, our study provides a couple of key discoveries: (i) the global tokens (a.k.a [CLS] tokens in Transformer) of the text branch in CLIP provide a powerful representation of semantic information and (ii) these text-side [CLS] tokens can be regarded as category priors to guide CLIP visual encoder pay more attention on the corresponding region of interest. Based on that, we build upon the CLIP model as a backbone which we extend with a One-Way [CLS] token navigation from text to the visual branch that enables zero-shot dense prediction, dubbed \textbf{ClsCLIP}. Specifically, we use the [CLS] token output from the text branch, as an auxiliary semantic prompt, to replace the [CLS] token in shallow layers of the ViT-based visual encoder. This one-way navigation embeds such global category prior earlier and thus promotes semantic segmentation. Furthermore, to better segment tiny objects in ZS3, we further enhance ClsCLIP with a local zoom-in strategy, which employs a region proposal pre-processing and we get ClsCLIP+. Extensive experiments demonstrate that our proposed ZS3 method achieves a SOTA performance, and it is even comparable with those few-shot semantic segmentation methods.
Dynamic Mobile-Former: Strengthening Dynamic Convolution with Attention and Residual Connection in Kernel Space
Apr 13, 2023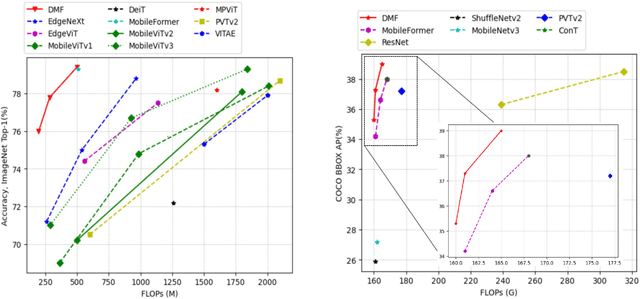
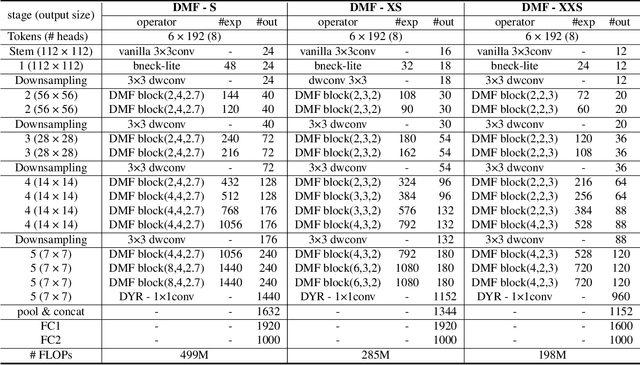
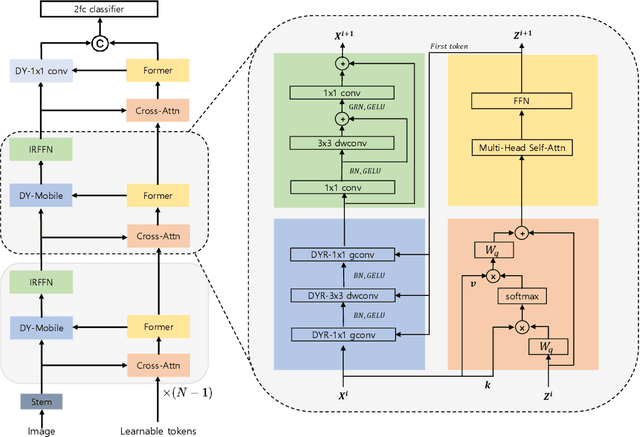
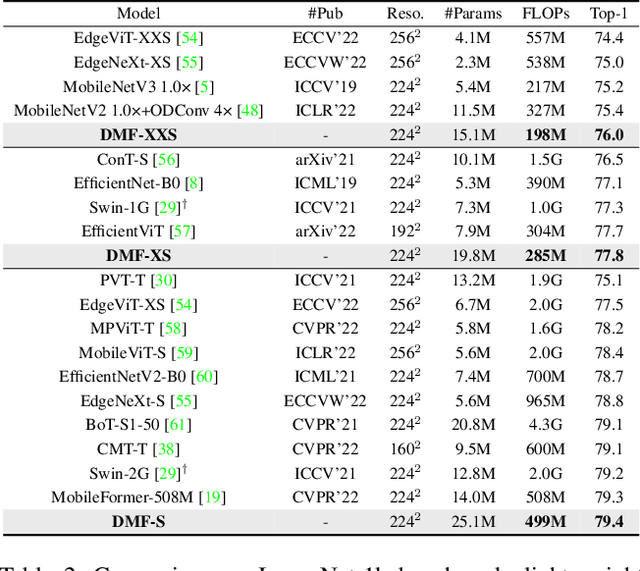
We introduce Dynamic Mobile-Former(DMF), maximizes the capabilities of dynamic convolution by harmonizing it with efficient operators.Our Dynamic MobileFormer effectively utilizes the advantages of Dynamic MobileNet (MobileNet equipped with dynamic convolution) using global information from light-weight attention.A Transformer in Dynamic Mobile-Former only requires a few randomly initialized tokens to calculate global features, making it computationally efficient.And a bridge between Dynamic MobileNet and Transformer allows for bidirectional integration of local and global features.We also simplify the optimization process of vanilla dynamic convolution by splitting the convolution kernel into an input-agnostic kernel and an input-dependent kernel.This allows for optimization in a wider kernel space, resulting in enhanced capacity.By integrating lightweight attention and enhanced dynamic convolution, our Dynamic Mobile-Former achieves not only high efficiency, but also strong performance.We benchmark the Dynamic Mobile-Former on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection, and instanace segmentation.For example, our DMF hits the top-1 accuracy of 79.4% on ImageNet-1K, much higher than PVT-Tiny by 4.3% with only 1/4 FLOPs.Additionally,our proposed DMF-S model performed well on challenging vision datasets such as COCO, achieving a 39.0% mAP,which is 1% higher than that of the Mobile-Former 508M model, despite using 3 GFLOPs less computations.Code and models are available at https://github.com/ysj9909/DMF
Fast vehicle detection algorithm based on lightweight YOLO7-tiny
Apr 13, 2023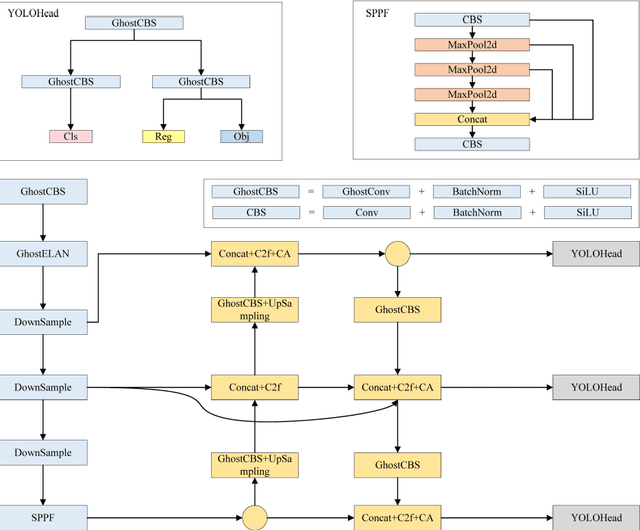
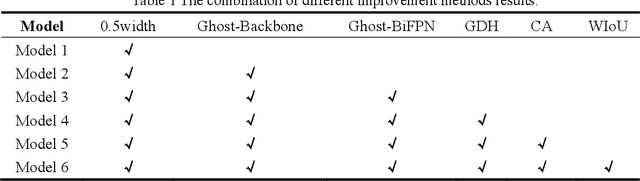
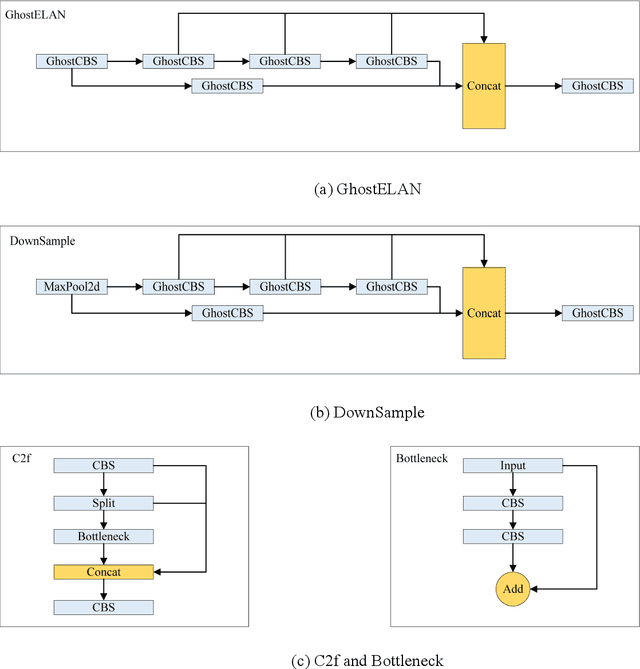
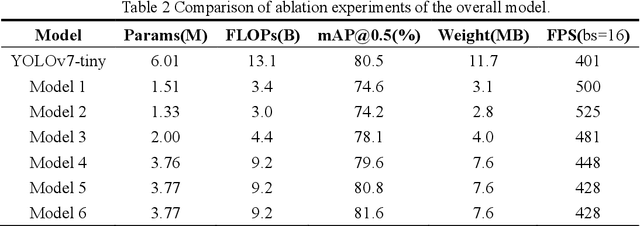
The swift and precise detection of vehicles holds significant research significance in intelligent transportation systems (ITS). However, current vehicle detection algorithms encounter challenges such as high computational complexity, low detection rate, and limited feasibility on mobile devices. To address these issues, this paper proposes a lightweight vehicle detection algorithm for YOLOv7-tiny called Ghost-YOLOv7. The model first scales the width multiple to 0.5 and replaces the standard convolution of the backbone network with Ghost convolution to achieve a lighter network and improve the detection speed; secondly, a Ghost bi-directional feature pyramid network (Ghost-BiFPN) neck network is designed to enhance feature extraction capability of the algorithm and enrich semantic information; thirdly, a Ghost Decouoled Head (GDH) is employed for accurate prediction of vehicle location and class, enhancing model accuracy; finally, a coordinate attention mechanism is introduced in the output layer to suppress environmental interference, and the WIoU loss function is employed to enhance the detection accuracy further. Experimental results on the PASCAL VOC dataset demonstrate that Ghost-YOLOv7 outperforms the original YOLOv7-tiny model, achieving a 29.8% reduction in computation, 37.3% reduction in the number of parameters, 35.1% reduction in model weights, and 1.1% higher mean average precision (mAP), while achieving a detection speed of 428 FPS. These results validate the effectiveness of the proposed method.
High Dynamic Range Imaging with Context-aware Transformer
Apr 13, 2023
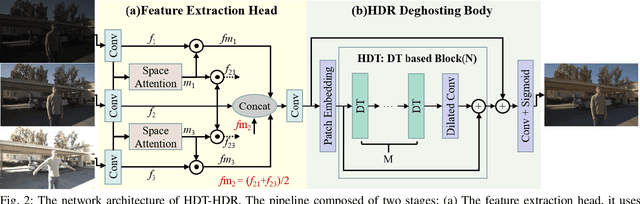
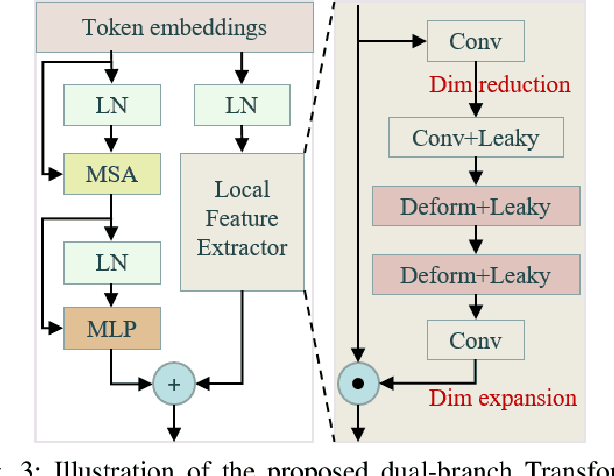

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
Boosting Convolutional Neural Networks with Middle Spectrum Grouped Convolution
Apr 13, 2023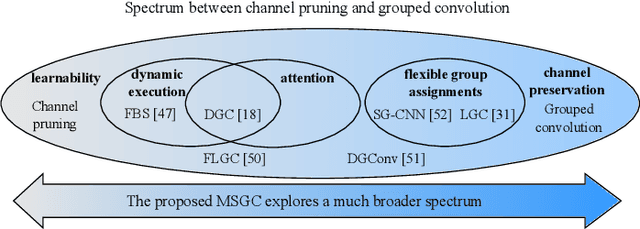
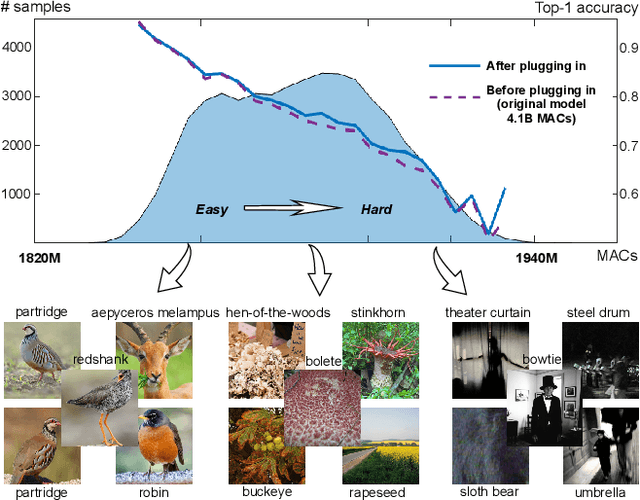
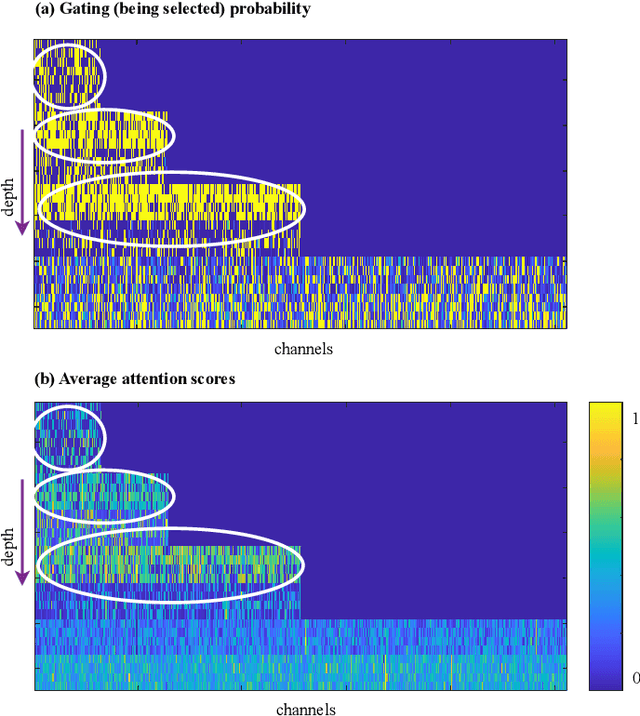
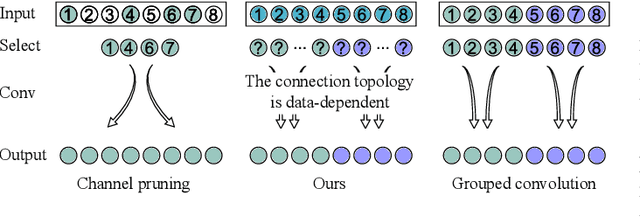
This paper proposes a novel module called middle spectrum grouped convolution (MSGC) for efficient deep convolutional neural networks (DCNNs) with the mechanism of grouped convolution. It explores the broad "middle spectrum" area between channel pruning and conventional grouped convolution. Compared with channel pruning, MSGC can retain most of the information from the input feature maps due to the group mechanism; compared with grouped convolution, MSGC benefits from the learnability, the core of channel pruning, for constructing its group topology, leading to better channel division. The middle spectrum area is unfolded along four dimensions: group-wise, layer-wise, sample-wise, and attention-wise, making it possible to reveal more powerful and interpretable structures. As a result, the proposed module acts as a booster that can reduce the computational cost of the host backbones for general image recognition with even improved predictive accuracy. For example, in the experiments on ImageNet dataset for image classification, MSGC can reduce the multiply-accumulates (MACs) of ResNet-18 and ResNet-50 by half but still increase the Top-1 accuracy by more than 1%. With 35% reduction of MACs, MSGC can also increase the Top-1 accuracy of the MobileNetV2 backbone. Results on MS COCO dataset for object detection show similar observations. Our code and trained models are available at https://github.com/hellozhuo/msgc.
A new perspective on building efficient and expressive 3D equivariant graph neural networks
Apr 07, 2023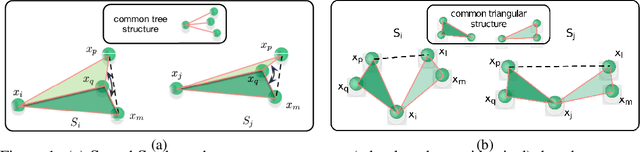
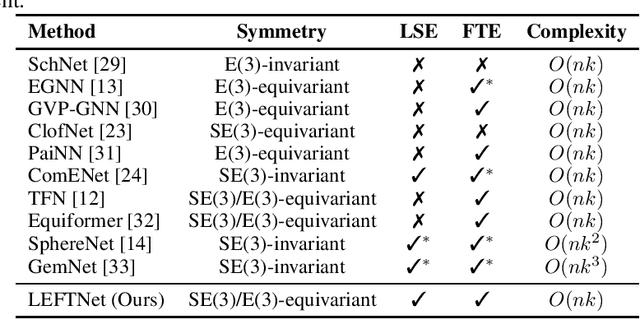
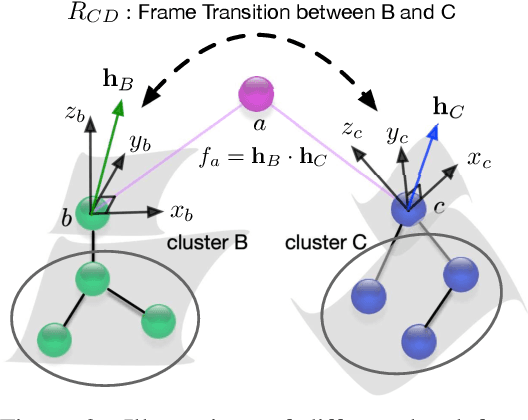
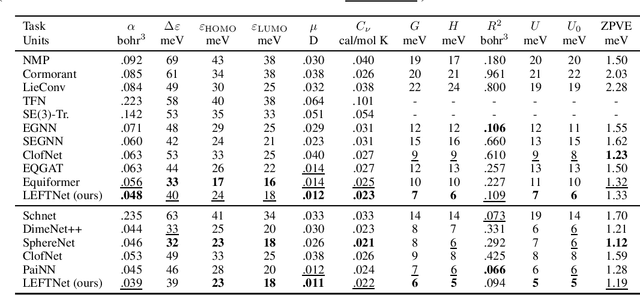
Geometric deep learning enables the encoding of physical symmetries in modeling 3D objects. Despite rapid progress in encoding 3D symmetries into Graph Neural Networks (GNNs), a comprehensive evaluation of the expressiveness of these networks through a local-to-global analysis lacks today. In this paper, we propose a local hierarchy of 3D isomorphism to evaluate the expressive power of equivariant GNNs and investigate the process of representing global geometric information from local patches. Our work leads to two crucial modules for designing expressive and efficient geometric GNNs; namely local substructure encoding (LSE) and frame transition encoding (FTE). To demonstrate the applicability of our theory, we propose LEFTNet which effectively implements these modules and achieves state-of-the-art performance on both scalar-valued and vector-valued molecular property prediction tasks. We further point out the design space for future developments of equivariant graph neural networks. Our codes are available at \url{https://github.com/yuanqidu/LeftNet}.
Iteratively Coupled Multiple Instance Learning from Instance to Bag Classifier for Whole Slide Image Classification
Mar 28, 2023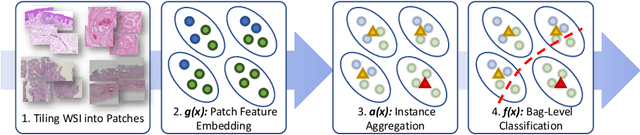

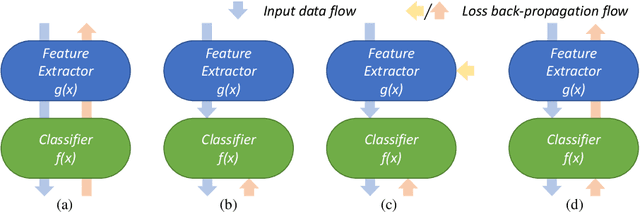
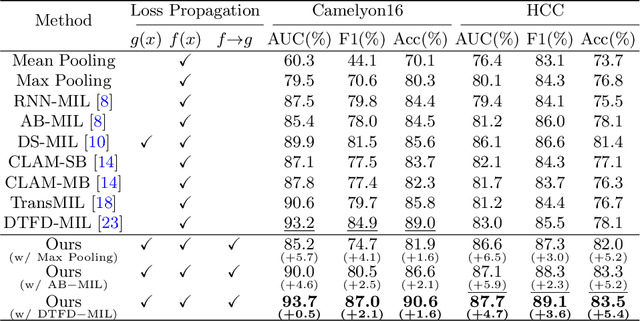
Whole Slide Image (WSI) classification remains a challenge due to their extremely high resolution and the absence of fine-grained labels. Presently, WSIs are usually classified as a Multiple Instance Learning (MIL) problem when only slide-level labels are available. MIL methods involve a patch embedding process and a bag-level classification process, but they are prohibitively expensive to be trained end-to-end. Therefore, existing methods usually train them separately, or directly skip the training of the embedder. Such schemes hinder the patch embedder's access to slide-level labels, resulting in inconsistencies within the entire MIL pipeline. To overcome this issue, we propose a novel framework called Iteratively Coupled MIL (ICMIL), which bridges the loss back-propagation process from the bag-level classifier to the patch embedder. In ICMIL, we use category information in the bag-level classifier to guide the patch-level fine-tuning of the patch feature extractor. The refined embedder then generates better instance representations for achieving a more accurate bag-level classifier. By coupling the patch embedder and bag classifier at a low cost, our proposed framework enables information exchange between the two processes, benefiting the entire MIL classification model. We tested our framework on two datasets using three different backbones, and our experimental results demonstrate consistent performance improvements over state-of-the-art MIL methods. Code will be made available upon acceptance.