 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact of NOMA on Age of Information: A Grant-Free Transmission Perspective
Nov 24, 2022
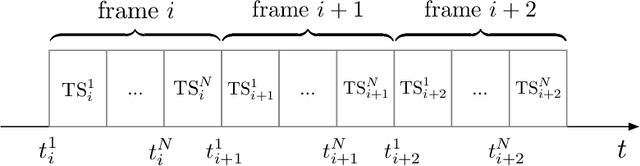
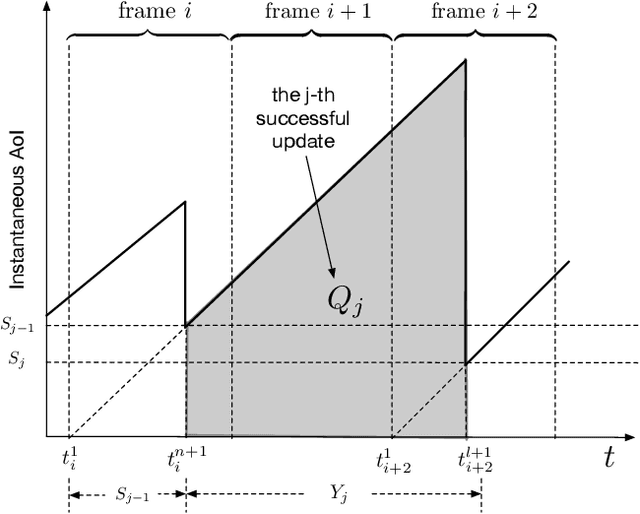
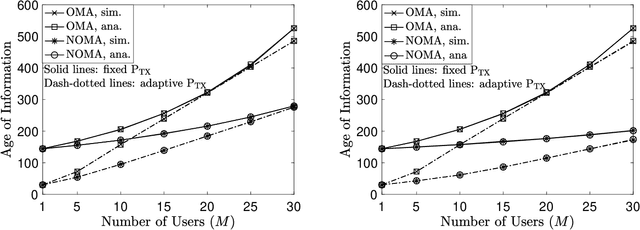
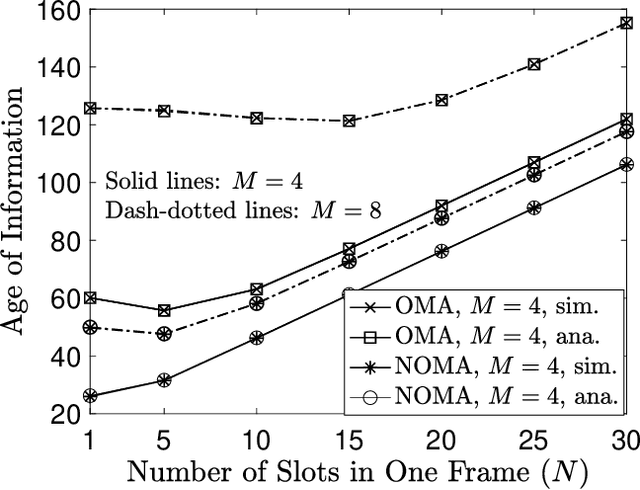
The aim of this paper is to characterize the impact of non-orthogonal multiple access (NOMA) on the age of information (AoI) of grant-free transmission. In particular, a low-complexity form of NOMA, termed NOMA-assisted random access, is applied to grant-free transmission in order to illustrate the two benefits of NOMA for AoI reduction, namely increasing channel access and reducing user collisions. Closed-form analytical expressions for the AoI achieved by NOMA assisted grant-free transmission are obtained, and asymptotic studies are carried out to demonstrate that the use of the simplest form of NOMA is already sufficient to reduce the AoI of orthogonal multiple access (OMA) by more than 40%. In addition, the developed analytical expressions are also shown to be useful for optimizing the users' transmission attempt probabilities, which are key parameters for grant-free transmission.
Disentangling the Link Between Image Statistics and Human Perception
Mar 17, 2023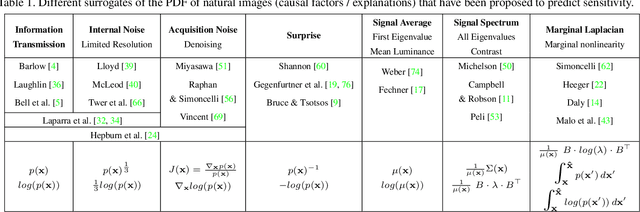

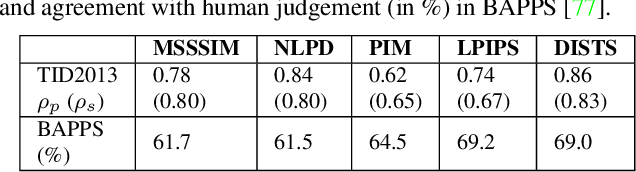

In the 1950s Horace Barlow and Fred Attneave suggested a connection between sensory systems and how they are adapted to the environment: early vision evolved to maximise the information it conveys about incoming signals. Following Shannon's definition, this information was described using the probability of the images taken from natural scenes. Previously, direct accurate predictions of image probabilities were not possible due to computational limitations. Despite the exploration of this idea being indirect, mainly based on oversimplified models of the image density or on system design methods, these methods had success in reproducing a wide range of physiological and psychophysical phenomena. In this paper, we directly evaluate the probability of natural images and analyse how it may determine perceptual sensitivity. We employ image quality metrics that correlate well with human opinion as a surrogate of human vision, and an advanced generative model to directly estimate the probability. Specifically, we analyse how the sensitivity of full-reference image quality metrics can be predicted from quantities derived directly from the probability distribution of natural images. First, we compute the mutual information between a wide range of probability surrogates and the sensitivity of the metrics and find that the most influential factor is the probability of the noisy image. Then we explore how these probability surrogates can be combined using a simple model to predict the metric sensitivity, giving an upper bound for the correlation of 0.85 between the model predictions and the actual perceptual sensitivity. Finally, we explore how to combine the probability surrogates using simple expressions, and obtain two functional forms (using one or two surrogates) that can be used to predict the sensitivity of the human visual system given a particular pair of images.
TeSLA: Test-Time Self-Learning With Automatic Adversarial Augmentation
Mar 17, 2023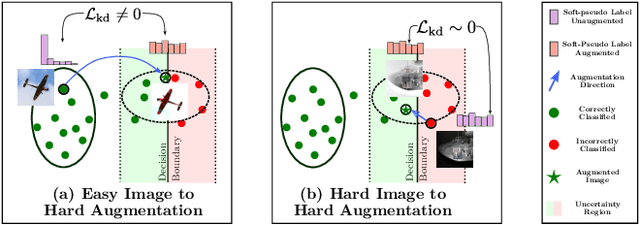
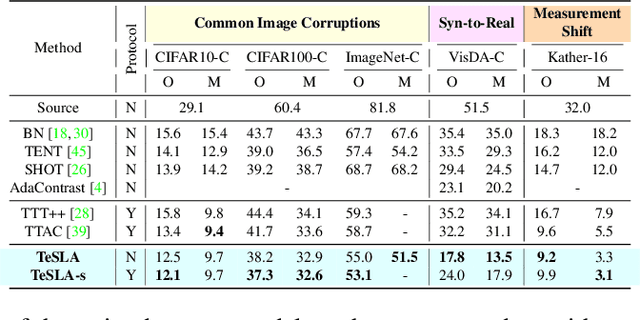
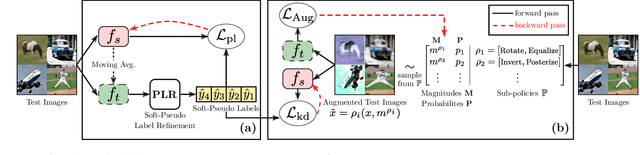
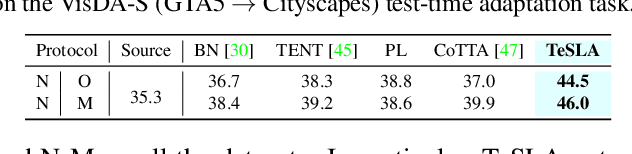
Most recent test-time adaptation methods focus on only classification tasks, use specialized network architectures, destroy model calibration or rely on lightweight information from the source domain. To tackle these issues, this paper proposes a novel Test-time Self-Learning method with automatic Adversarial augmentation dubbed TeSLA for adapting a pre-trained source model to the unlabeled streaming test data. In contrast to conventional self-learning methods based on cross-entropy, we introduce a new test-time loss function through an implicitly tight connection with the mutual information and online knowledge distillation. Furthermore, we propose a learnable efficient adversarial augmentation module that further enhances online knowledge distillation by simulating high entropy augmented images. Our method achieves state-of-the-art classification and segmentation results on several benchmarks and types of domain shifts, particularly on challenging measurement shifts of medical images. TeSLA also benefits from several desirable properties compared to competing methods in terms of calibration, uncertainty metrics, insensitivity to model architectures, and source training strategies, all supported by extensive ablations. Our code and models are available on GitHub.
Conversational Tree Search: A New Hybrid Dialog Task
Mar 17, 2023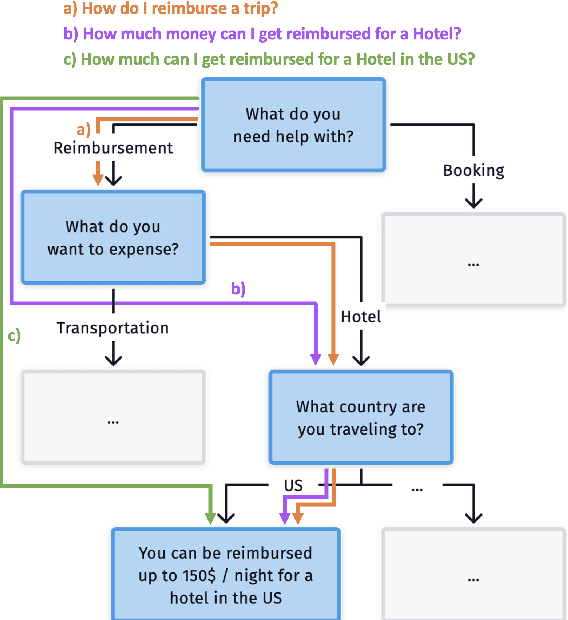

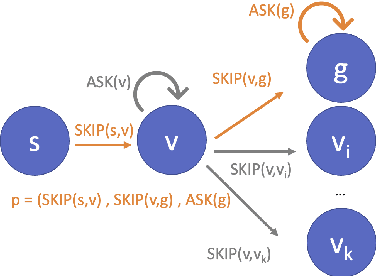
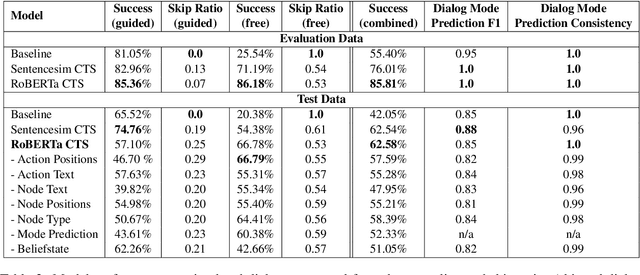
Conversational interfaces provide a flexible and easy way for users to seek information that may otherwise be difficult or inconvenient to obtain. However, existing interfaces generally fall into one of two categories: FAQs, where users must have a concrete question in order to retrieve a general answer, or dialogs, where users must follow a predefined path but may receive a personalized answer. In this paper, we introduce Conversational Tree Search (CTS) as a new task that bridges the gap between FAQ-style information retrieval and task-oriented dialog, allowing domain-experts to define dialog trees which can then be converted to an efficient dialog policy that learns only to ask the questions necessary to navigate a user to their goal. We collect a dataset for the travel reimbursement domain and demonstrate a baseline as well as a novel deep Reinforcement Learning architecture for this task. Our results show that the new architecture combines the positive aspects of both the FAQ and dialog system used in the baseline and achieves higher goal completion while skipping unnecessary questions.
Reliable Multimodality Eye Disease Screening via Mixture of Student's t Distributions
Mar 17, 2023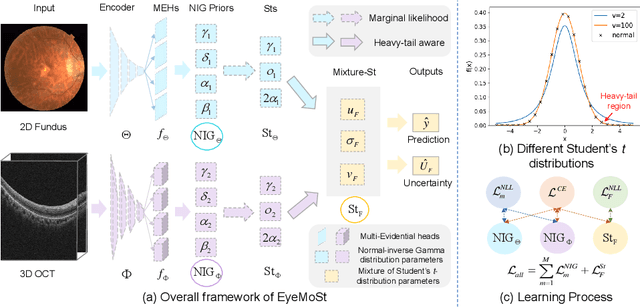
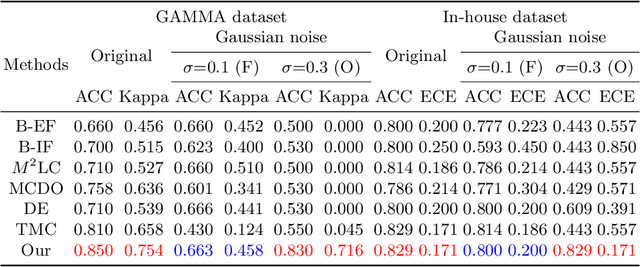
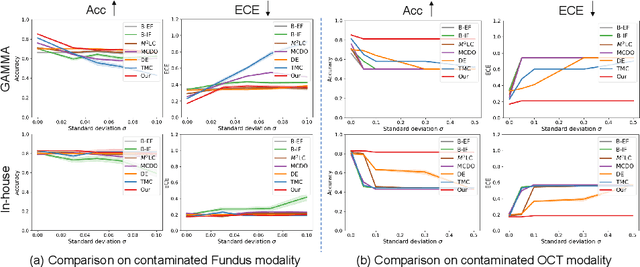
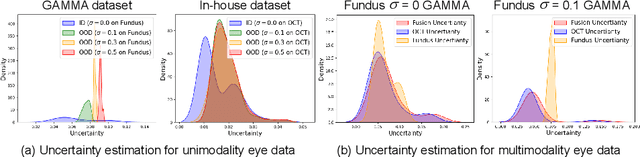
Multimodality eye disease screening is crucial in ophthalmology as it integrates information from diverse sources to complement their respective performances. However, the existing methods are weak in assessing the reliability of each unimodality, and directly fusing an unreliable modality may cause screening errors. To address this issue, we introduce a novel multimodality evidential fusion pipeline for eye disease screening, EyeMoS$t$, which provides a measure of confidence for unimodality and elegantly integrates the multimodality information from a multi-distribution fusion perspective. Specifically, our model estimates both local uncertainty for unimodality and global uncertainty for the fusion modality to produce reliable classification results. More importantly, the proposed mixture of Student's $t$ distributions adaptively integrates different modalities to endow the model with heavy-tailed properties, increasing robustness and reliability. Our experimental findings on both public and in-house datasets show that our model is more reliable than current methods. Additionally, EyeMos$t$ has the potential ability to serve as a data quality discriminator, enabling reliable decision-making for multimodality eye disease screening.
Fixed Design Analysis of Regularization-Based Continual Learning
Mar 17, 2023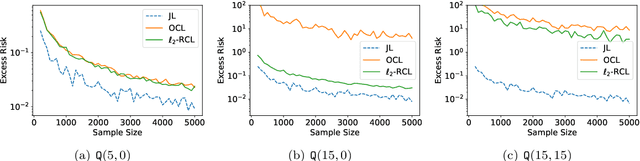
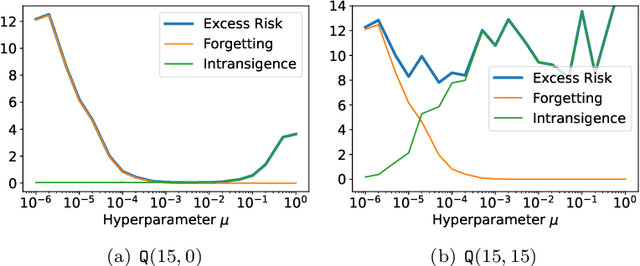
We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $\ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $\ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $\ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $\ell_2$-regularization can partially mitigate this issue by introducing intransigence.
Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
Mar 24, 2023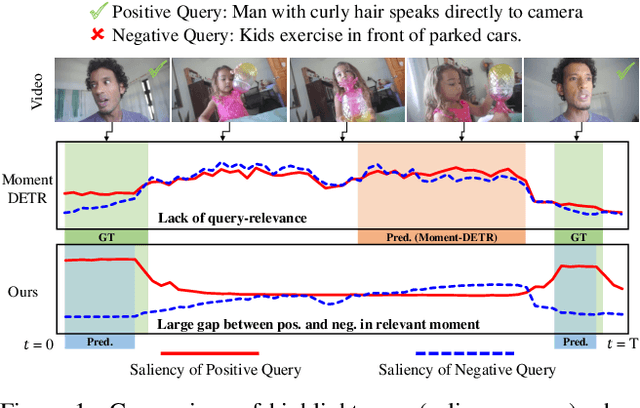
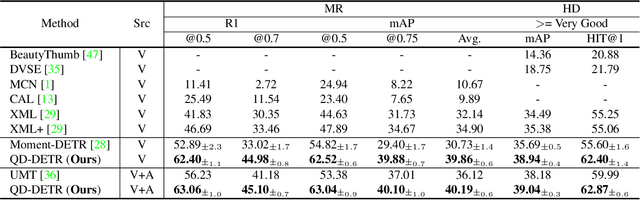
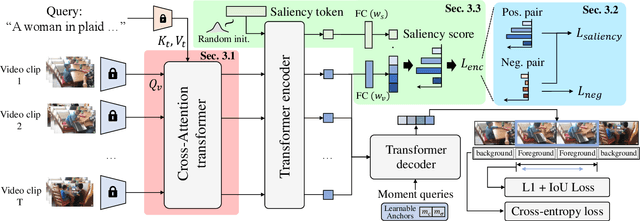
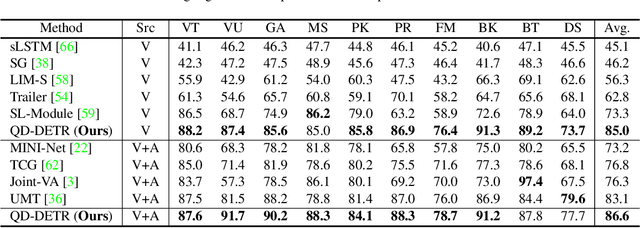
Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model's capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets. Codes are available at github.com/wjun0830/QD-DETR.
Combining information-seeking exploration and reward maximization: Unified inference on continuous state and action spaces under partial observability
Dec 15, 2022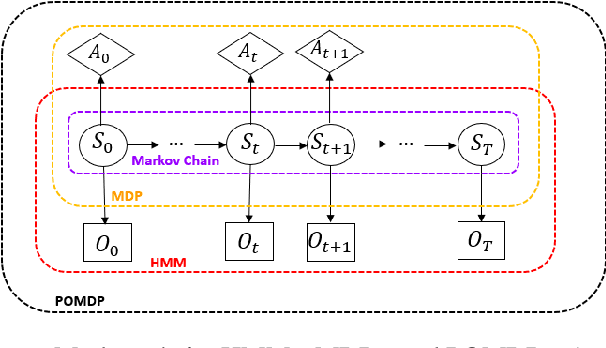

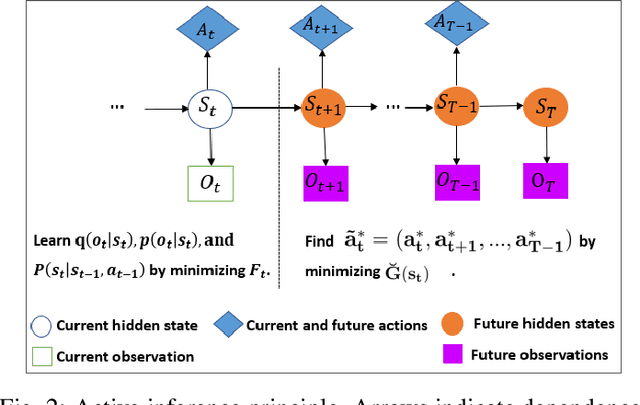

Reinforcement learning (RL) gained considerable attention by creating decision-making agents that maximize rewards received from fully observable environments. However, many real-world problems are partially or noisily observable by nature, where agents do not receive the true and complete state of the environment. Such problems are formulated as partially observable Markov decision processes (POMDPs). Some studies applied RL to POMDPs by recalling previous decisions and observations or inferring the true state of the environment from received observations. Nevertheless, aggregating observations and decisions over time is impractical for environments with high-dimensional continuous state and action spaces. Moreover, so-called inference-based RL approaches require large number of samples to perform well since agents eschew uncertainty in the inferred state for the decision-making. Active inference is a framework that is naturally formulated in POMDPs and directs agents to select decisions by minimising expected free energy (EFE). This supplies reward-maximising (exploitative) behaviour in RL, with an information-seeking (exploratory) behaviour. Despite this exploratory behaviour of active inference, its usage is limited to discrete state and action spaces due to the computational difficulty of the EFE. We propose a unified principle for joint information-seeking and reward maximization that clarifies a theoretical connection between active inference and RL, unifies active inference and RL, and overcomes their aforementioned limitations. Our findings are supported by strong theoretical analysis. The proposed framework's superior exploration property is also validated by experimental results on partial observable tasks with high-dimensional continuous state and action spaces. Moreover, the results show that our model solves reward-free problems, making task reward design optional.
On the Impact of Voice Anonymization on Speech-Based COVID-19 Detection
Apr 05, 2023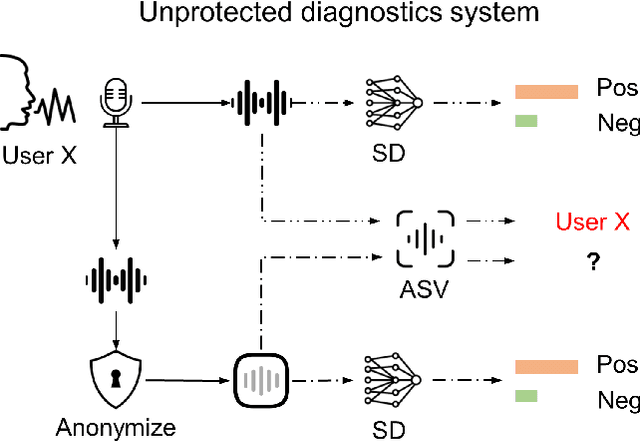
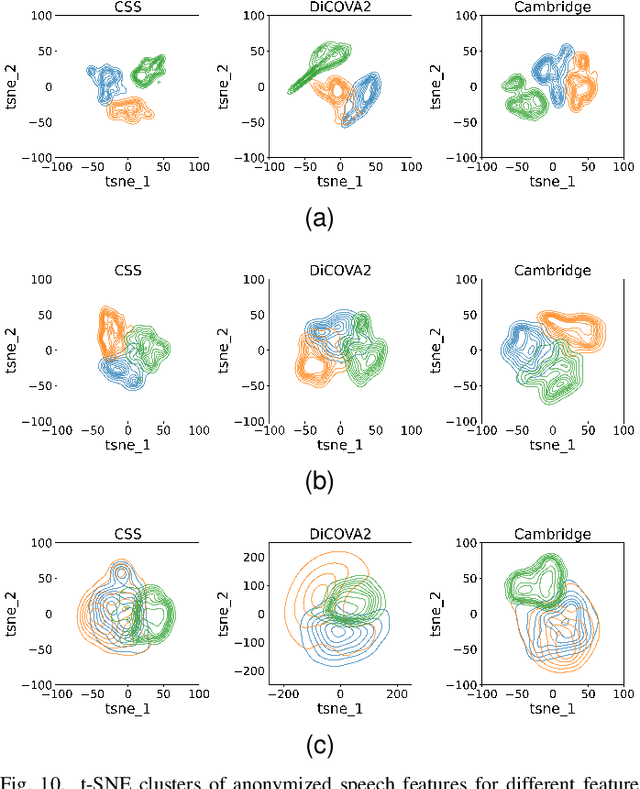
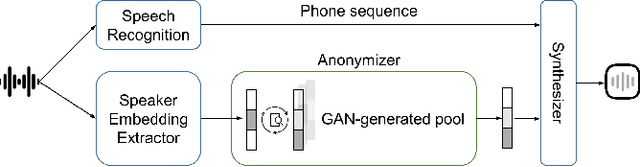
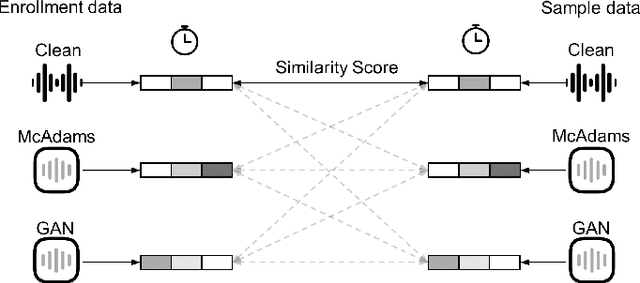
With advances seen in deep learning, voice-based applications are burgeoning, ranging from personal assistants, affective computing, to remote disease diagnostics. As the voice contains both linguistic and paralinguistic information (e.g., vocal pitch, intonation, speech rate, loudness), there is growing interest in voice anonymization to preserve speaker privacy and identity. Voice privacy challenges have emerged over the last few years and focus has been placed on removing speaker identity while keeping linguistic content intact. For affective computing and disease monitoring applications, however, the paralinguistic content may be more critical. Unfortunately, the effects that anonymization may have on these systems are still largely unknown. In this paper, we fill this gap and focus on one particular health monitoring application: speech-based COVID-19 diagnosis. We test two popular anonymization methods and their impact on five different state-of-the-art COVID-19 diagnostic systems using three public datasets. We validate the effectiveness of the anonymization methods, compare their computational complexity, and quantify the impact across different testing scenarios for both within- and across-dataset conditions. Lastly, we show the benefits of anonymization as a data augmentation tool to help recover some of the COVID-19 diagnostic accuracy loss seen with anonymized data.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 05, 2023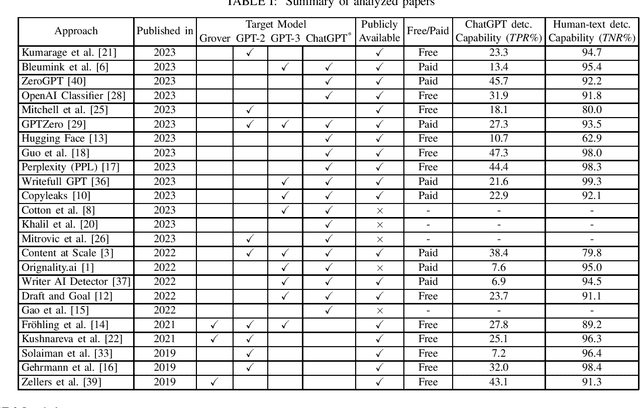
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.