 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
Apr 08, 2023
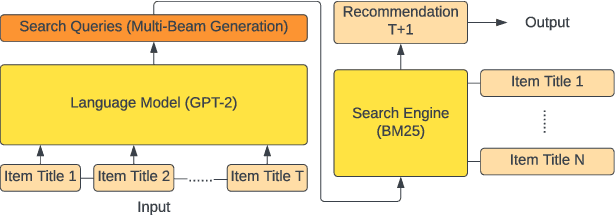
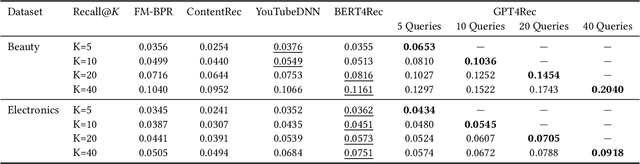

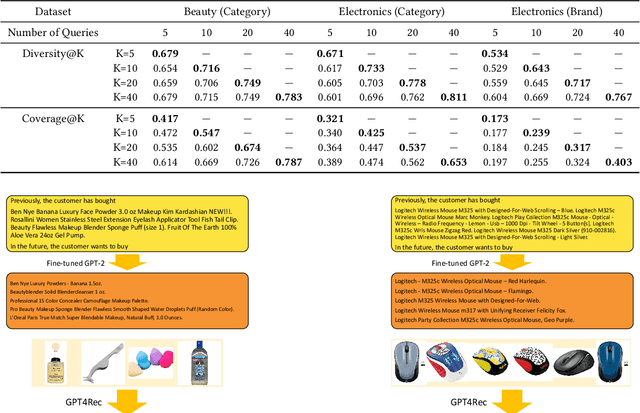
Recent advancements in Natural Language Processing (NLP) have led to the development of NLP-based recommender systems that have shown superior performance. However, current models commonly treat items as mere IDs and adopt discriminative modeling, resulting in limitations of (1) fully leveraging the content information of items and the language modeling capabilities of NLP models; (2) interpreting user interests to improve relevance and diversity; and (3) adapting practical circumstances such as growing item inventories. To address these limitations, we present GPT4Rec, a novel and flexible generative framework inspired by search engines. It first generates hypothetical "search queries" given item titles in a user's history, and then retrieves items for recommendation by searching these queries. The framework overcomes previous limitations by learning both user and item embeddings in the language space. To well-capture user interests with different aspects and granularity for improving relevance and diversity, we propose a multi-query generation technique with beam search. The generated queries naturally serve as interpretable representations of user interests and can be searched to recommend cold-start items. With GPT-2 language model and BM25 search engine, our framework outperforms state-of-the-art methods by $75.7\%$ and $22.2\%$ in Recall@K on two public datasets. Experiments further revealed that multi-query generation with beam search improves both the diversity of retrieved items and the coverage of a user's multi-interests. The adaptiveness and interpretability of generated queries are discussed with qualitative case studies.
A Reinforcement Learning-assisted Genetic Programming Algorithm for Team Formation Problem Considering Person-Job Matching
Apr 08, 2023
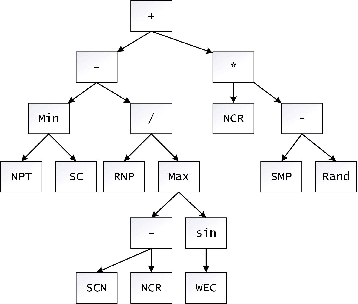
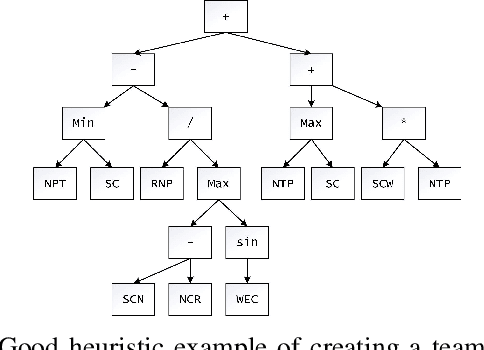
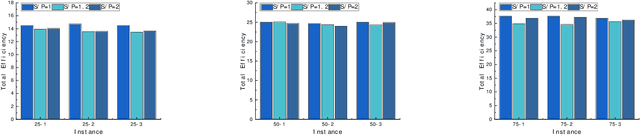
An efficient team is essential for the company to successfully complete new projects. To solve the team formation problem considering person-job matching (TFP-PJM), a 0-1 integer programming model is constructed, which considers both person-job matching and team members' willingness to communicate on team efficiency, with the person-job matching score calculated using intuitionistic fuzzy numbers. Then, a reinforcement learning-assisted genetic programming algorithm (RL-GP) is proposed to enhance the quality of solutions. The RL-GP adopts the ensemble population strategies. Before the population evolution at each generation, the agent selects one from four population search modes according to the information obtained, thus realizing a sound balance of exploration and exploitation. In addition, surrogate models are used in the algorithm to evaluate the formation plans generated by individuals, which speeds up the algorithm learning process. Afterward, a series of comparison experiments are conducted to verify the overall performance of RL-GP and the effectiveness of the improved strategies within the algorithm. The hyper-heuristic rules obtained through efficient learning can be utilized as decision-making aids when forming project teams. This study reveals the advantages of reinforcement learning methods, ensemble strategies, and the surrogate model applied to the GP framework. The diversity and intelligent selection of search patterns along with fast adaptation evaluation, are distinct features that enable RL-GP to be deployed in real-world enterprise environments.
Audience Expansion for Multi-show Release Based on an Edge-prompted Heterogeneous Graph Network
Apr 08, 2023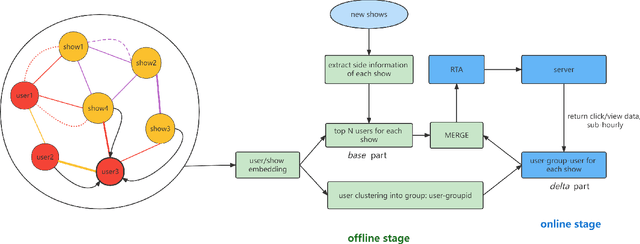

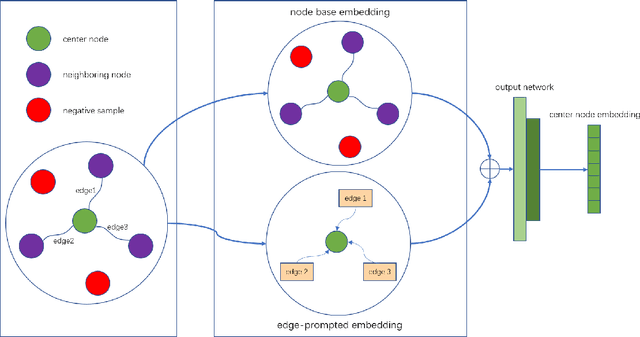
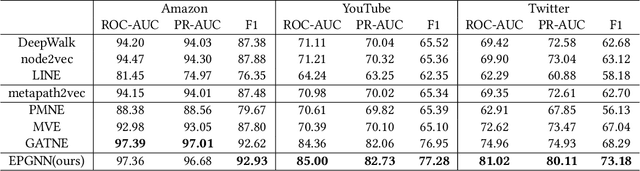
In the user targeting and expanding of new shows on a video platform, the key point is how their embeddings are generated. It's supposed to be personalized from the perspective of both users and shows. Furthermore, the pursue of both instant (click) and long-time (view time) rewards, and the cold-start problem for new shows bring additional challenges. Such a problem is suitable for processing by heterogeneous graph models, because of the natural graph structure of data. But real-world networks usually have billions of nodes and various types of edges. Few existing methods focus on handling large-scale data and exploiting different types of edges, especially the latter. In this paper, we propose a two-stage audience expansion scheme based on an edge-prompted heterogeneous graph network which can take different double-sided interactions and features into account. In the offline stage, to construct the graph, user IDs and specific side information combinations of the shows are chosen to be the nodes, and click/co-click relations and view time are used to build the edges. Embeddings and clustered user groups are then calculated. When new shows arrive, their embeddings and subsequent matching users can be produced within a consistent space. In the online stage, posterior data including click/view users are employed as seeds to look for similar users. The results on the public datasets and our billion-scale data demonstrate the accuracy and efficiency of our approach.
Contrastive Cross-Domain Sequential Recommendation
Apr 08, 2023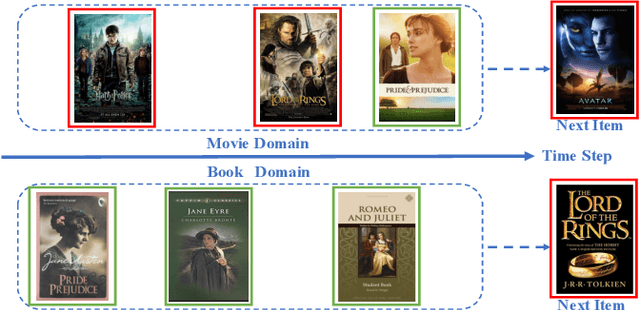
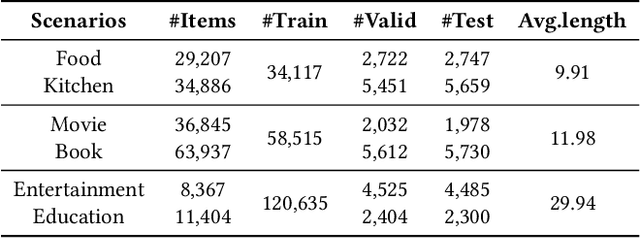

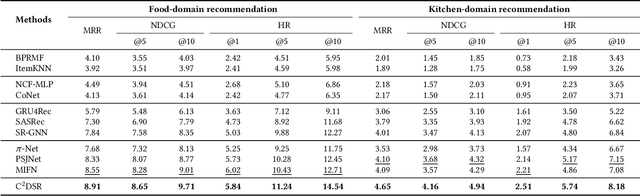
Cross-Domain Sequential Recommendation (CDSR) aims to predict future interactions based on user's historical sequential interactions from multiple domains. Generally, a key challenge of CDSR is how to mine precise cross-domain user preference based on the intra-sequence and inter-sequence item interactions. Existing works first learn single-domain user preference only with intra-sequence item interactions, and then build a transferring module to obtain cross-domain user preference. However, such a pipeline and implicit solution can be severely limited by the bottleneck of the designed transferring module, and ignores to consider inter-sequence item relationships. In this paper, we propose C^2DSR to tackle the above problems to capture precise user preferences. The main idea is to simultaneously leverage the intra- and inter- sequence item relationships, and jointly learn the single- and cross- domain user preferences. Specifically, we first utilize a graph neural network to mine inter-sequence item collaborative relationship, and then exploit sequential attentive encoder to capture intra-sequence item sequential relationship. Based on them, we devise two different sequential training objectives to obtain user single-domain and cross-domain representations. Furthermore, we present a novel contrastive cross-domain infomax objective to enhance the correlation between single- and cross- domain user representations by maximizing their mutual information. To validate the effectiveness of C^2DSR, we first re-split four e-comerce datasets, and then conduct extensive experiments to demonstrate the effectiveness of our approach C^2DSR.
Estimation of Ground NO2 Measurements from Sentinel-5P Tropospheric Data through Categorical Boosting
Apr 08, 2023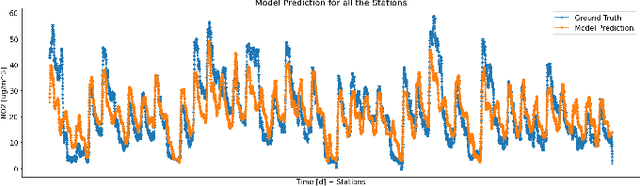
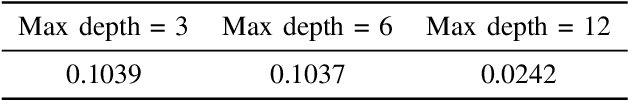

Atmospheric pollution has been largely considered by the scientific community as a primary threat to human health and ecosystems, above all for its impact on climate change. Therefore, its containment and reduction are gaining interest and commitment from institutions and researchers, although the solutions are not immediate. It becomes of primary importance to identify the distribution of air pollutants and evaluate their concentration levels in order to activate the right countermeasures. Among other tools, satellite-based measurements have been used for monitoring and obtaining information on air pollutants, and over the years their performance has increased in terms of both resolution and data reliability. This study aims to analyze the NO2 pollution in the Emilia Romagna Region (Northern Italy) during 2019, with the help of satellite retrievals from the {\nobreak Sentinel\nobreak-5P} mission of the European Copernicus Programme and ground-based measurements, obtained from the ARPA site (Regional Agency for the Protection of the Environment). The final goal is the estimation of ground NO2 measurements when only satellite data are available. For this task, we used a Machine Learning (ML) model, Categorical Boosting, which was demonstrated to work quite well and allowed us to achieve a Root-Mean-Square Error (RMSE) of 0.0242 over the 43 stations utilized to get the Ground Truth values. This procedure, applicable to other areas of Italy and the world and on longer timelines, represents the starting point to understand which other actions must be taken to improve its final performance.
Predicting Human Attention using Computational Attention
Apr 04, 2023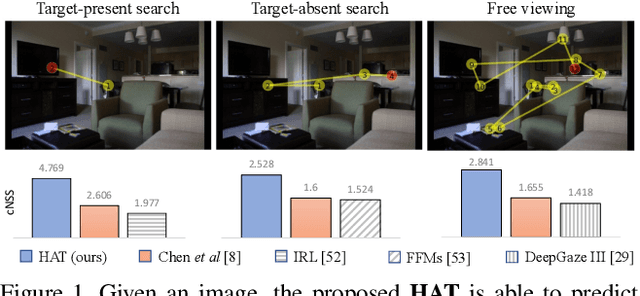
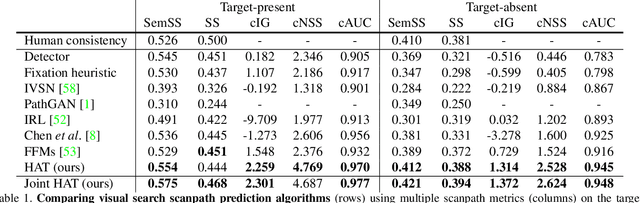
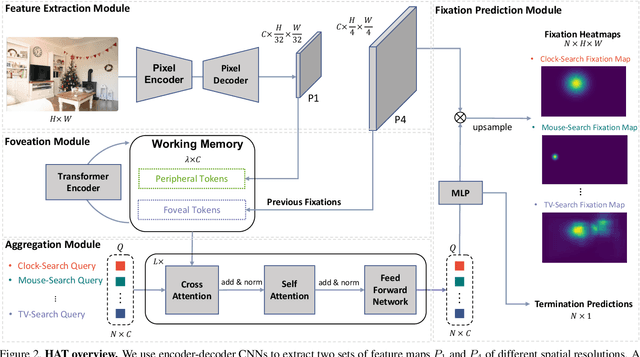
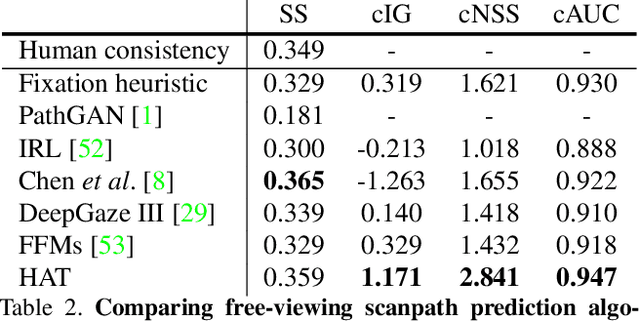
Most models of visual attention are aimed at predicting either top-down or bottom-up control, as studied using different visual search and free-viewing tasks. We propose Human Attention Transformer (HAT), a single model predicting both forms of attention control. HAT is the new state-of-the-art (SOTA) in predicting the scanpath of fixations made during target-present and target-absent search, and matches or exceeds SOTA in the prediction of taskless free-viewing fixation scanpaths. HAT achieves this new SOTA by using a novel transformer-based architecture and a simplified foveated retina that collectively create a spatio-temporal awareness akin to the dynamic visual working memory of humans. Unlike previous methods that rely on a coarse grid of fixation cells and experience information loss due to fixation discretization, HAT features a dense-prediction architecture and outputs a dense heatmap for each fixation, thus avoiding discretizing fixations. HAT sets a new standard in computational attention, which emphasizes both effectiveness and generality. HAT's demonstrated scope and applicability will likely inspire the development of new attention models that can better predict human behavior in various attention-demanding scenarios.
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
Apr 04, 2023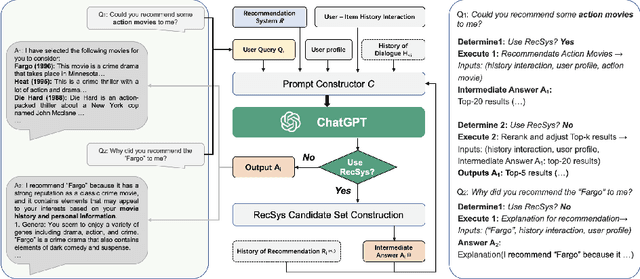


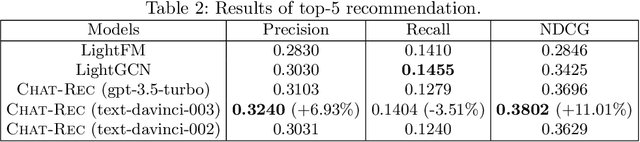
Large language models (LLMs) have demonstrated their significant potential to be applied for addressing various application tasks. However, traditional recommender systems continue to face great challenges such as poor interactivity and explainability, which actually also hinder their broad deployment in real-world systems. To address these limitations, this paper proposes a novel paradigm called Chat-Rec (ChatGPT Augmented Recommender System) that innovatively augments LLMs for building conversational recommender systems by converting user profiles and historical interactions into prompts. Chat-Rec is demonstrated to be effective in learning user preferences and establishing connections between users and products through in-context learning, which also makes the recommendation process more interactive and explainable. What's more, within the Chat-Rec framework, user's preferences can transfer to different products for cross-domain recommendations, and prompt-based injection of information into LLMs can also handle the cold-start scenarios with new items. In our experiments, Chat-Rec effectively improve the results of top-k recommendations and performs better in zero-shot rating prediction task. Chat-Rec offers a novel approach to improving recommender systems and presents new practical scenarios for the implementation of AIGC (AI generated content) in recommender system studies.
SEM-POS: Grammatically and Semantically Correct Video Captioning
Apr 04, 2023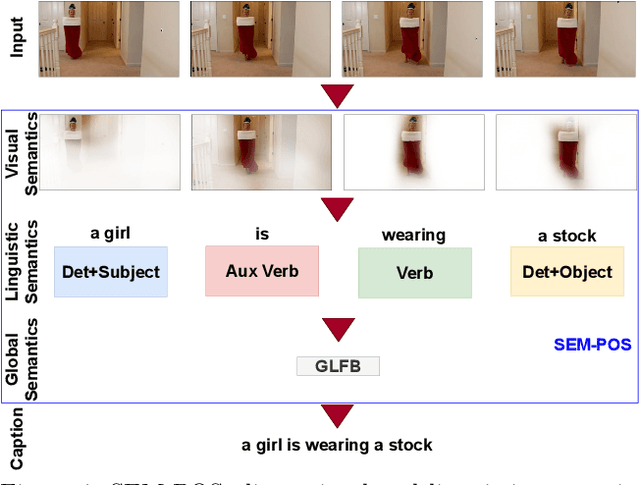
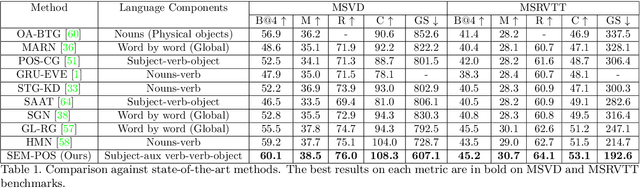
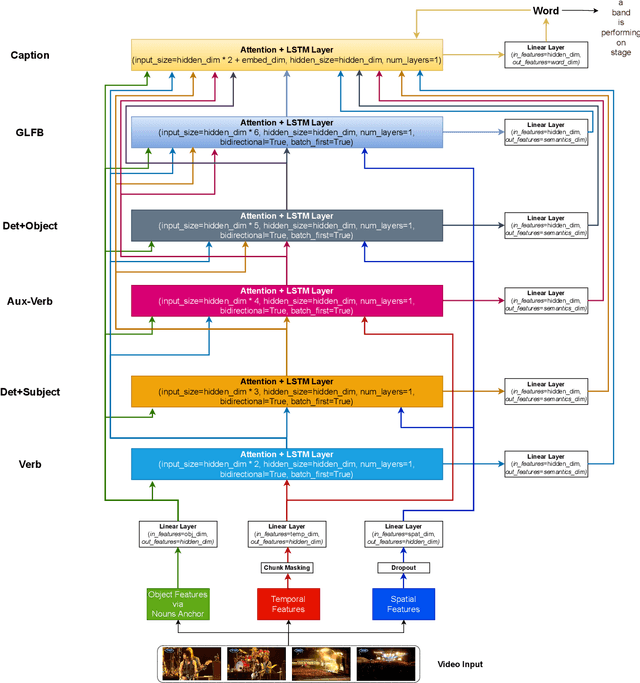
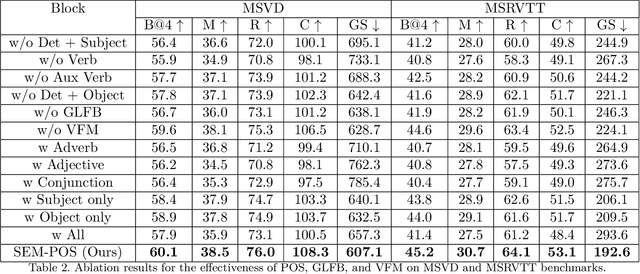
Generating grammatically and semantically correct captions in video captioning is a challenging task. The captions generated from the existing methods are either word-by-word that do not align with grammatical structure or miss key information from the input videos. To address these issues, we introduce a novel global-local fusion network, with a Global-Local Fusion Block (GLFB) that encodes and fuses features from different parts of speech (POS) components with visual-spatial features. We use novel combinations of different POS components - 'determinant + subject', 'auxiliary verb', 'verb', and 'determinant + object' for supervision of the POS blocks - Det + Subject, Aux Verb, Verb, and Det + Object respectively. The novel global-local fusion network together with POS blocks helps align the visual features with language description to generate grammatically and semantically correct captions. Extensive qualitative and quantitative experiments on benchmark MSVD and MSRVTT datasets demonstrate that the proposed approach generates more grammatically and semantically correct captions compared to the existing methods, achieving the new state-of-the-art. Ablations on the POS blocks and the GLFB demonstrate the impact of the contributions on the proposed method.
FREDOM: Fairness Domain Adaptation Approach to Semantic Scene Understanding
Apr 04, 2023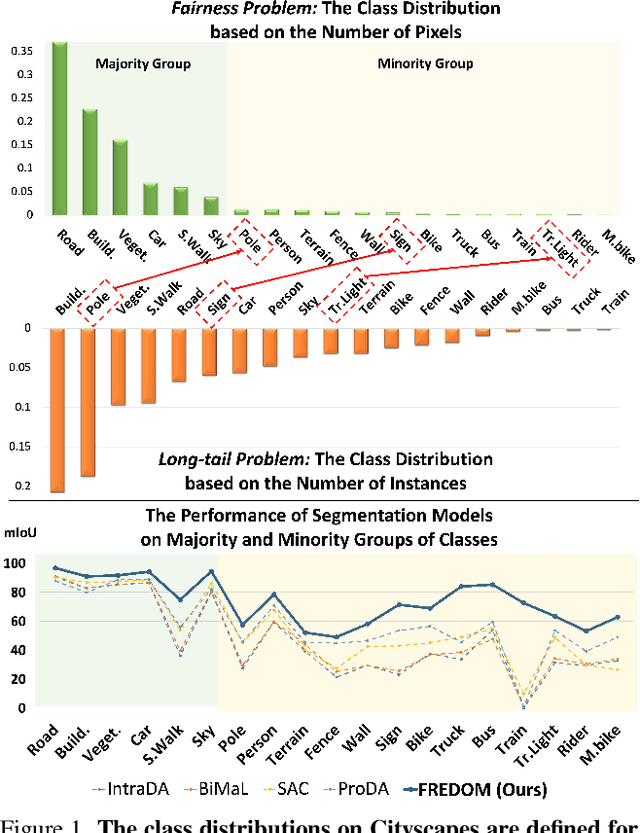
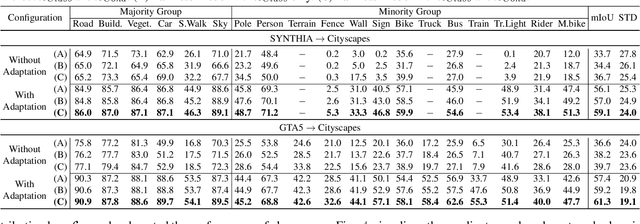

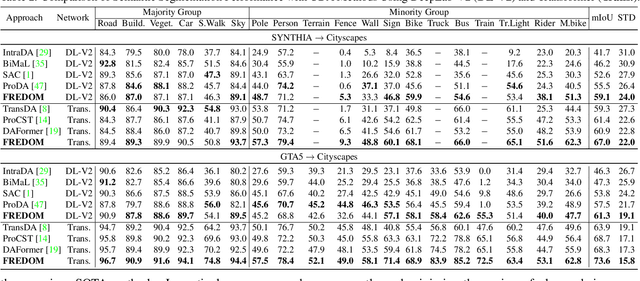
Although Domain Adaptation in Semantic Scene Segmentation has shown impressive improvement in recent years, the fairness concerns in the domain adaptation have yet to be well defined and addressed. In addition, fairness is one of the most critical aspects when deploying the segmentation models into human-related real-world applications, e.g., autonomous driving, as any unfair predictions could influence human safety. In this paper, we propose a novel Fairness Domain Adaptation (FREDOM) approach to semantic scene segmentation. In particular, from the proposed formulated fairness objective, a new adaptation framework will be introduced based on the fair treatment of class distributions. Moreover, to generally model the context of structural dependency, a new conditional structural constraint is introduced to impose the consistency of predicted segmentation. Thanks to the proposed Conditional Structure Network, the self-attention mechanism has sufficiently modeled the structural information of segmentation. Through the ablation studies, the proposed method has shown the performance improvement of the segmentation models and promoted fairness in the model predictions. The experimental results on the two standard benchmarks, i.e., SYNTHIA $\to$ Cityscapes and GTA5 $\to$ Cityscapes, have shown that our method achieved State-of-the-Art (SOTA) performance.
Label-guided Attention Distillation for Lane Segmentation
Apr 04, 2023
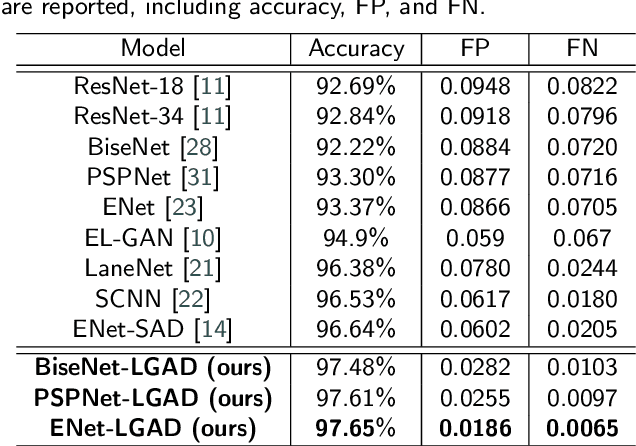

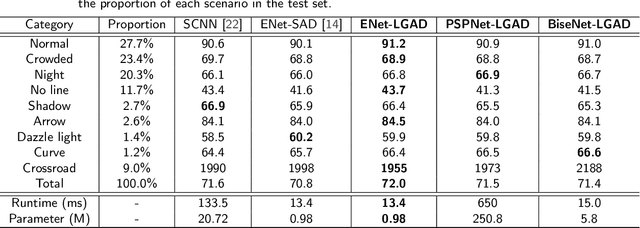
Contemporary segmentation methods are usually based on deep fully convolutional networks (FCNs). However, the layer-by-layer convolutions with a growing receptive field is not good at capturing long-range contexts such as lane markers in the scene. In this paper, we address this issue by designing a distillation method that exploits label structure when training segmentation network. The intuition is that the ground-truth lane annotations themselves exhibit internal structure. We broadcast the structure hints throughout a teacher network, i.e., we train a teacher network that consumes a lane label map as input and attempts to replicate it as output. Then, the attention maps of the teacher network are adopted as supervisors of the student segmentation network. The teacher network, with label structure information embedded, knows distinctly where the convolution layers should pay visual attention into. The proposed method is named as Label-guided Attention Distillation (LGAD). It turns out that the student network learns significantly better with LGAD than when learning alone. As the teacher network is deprecated after training, our method do not increase the inference time. Note that LGAD can be easily incorporated in any lane segmentation network.
* Accepted to Neurocomputing 2021