 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RIFormer: Keep Your Vision Backbone Effective While Removing Token Mixer
Apr 12, 2023
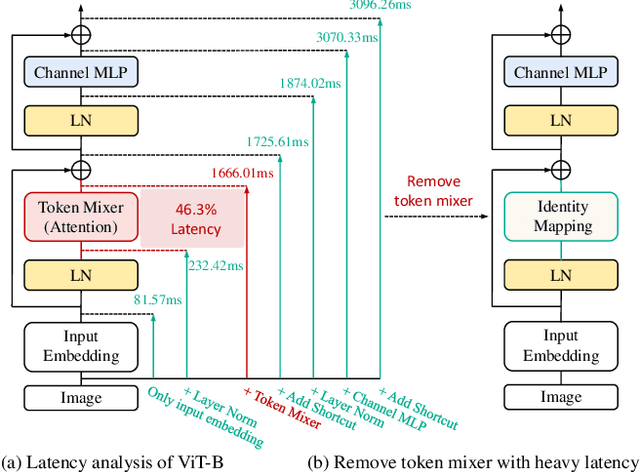
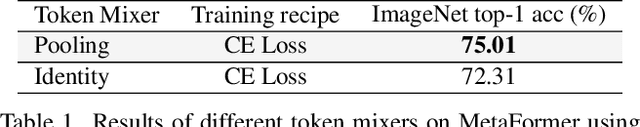
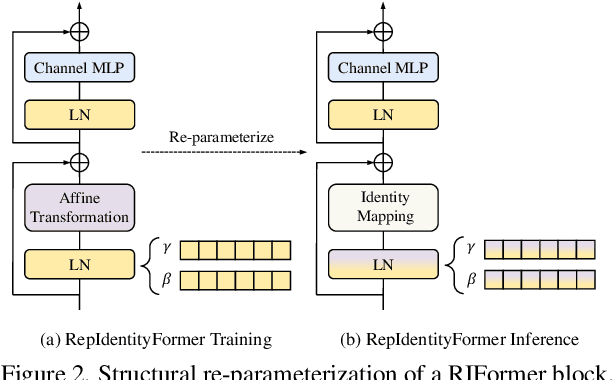
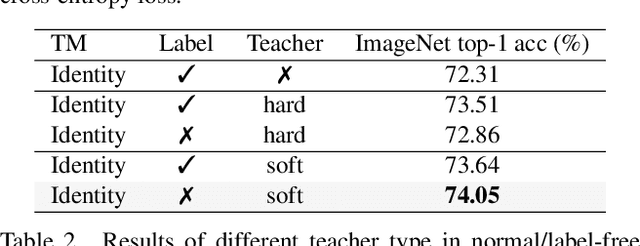
This paper studies how to keep a vision backbone effective while removing token mixers in its basic building blocks. Token mixers, as self-attention for vision transformers (ViTs), are intended to perform information communication between different spatial tokens but suffer from considerable computational cost and latency. However, directly removing them will lead to an incomplete model structure prior, and thus brings a significant accuracy drop. To this end, we first develop an RepIdentityFormer base on the re-parameterizing idea, to study the token mixer free model architecture. And we then explore the improved learning paradigm to break the limitation of simple token mixer free backbone, and summarize the empirical practice into 5 guidelines. Equipped with the proposed optimization strategy, we are able to build an extremely simple vision backbone with encouraging performance, while enjoying the high efficiency during inference. Extensive experiments and ablative analysis also demonstrate that the inductive bias of network architecture, can be incorporated into simple network structure with appropriate optimization strategy. We hope this work can serve as a starting point for the exploration of optimization-driven efficient network design. Project page: https://techmonsterwang.github.io/RIFormer/.
TactoFind: A Tactile Only System for Object Retrieval
Mar 23, 2023
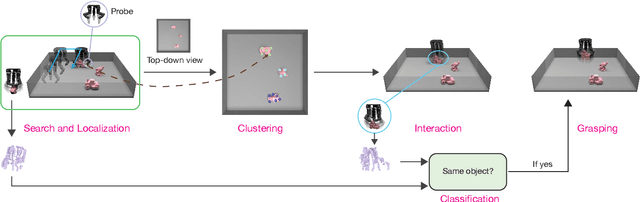
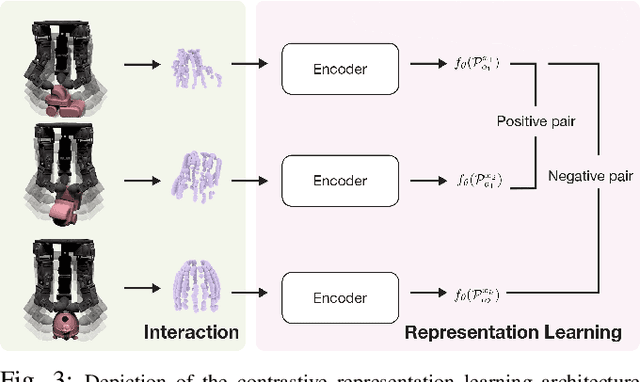

We study the problem of object retrieval in scenarios where visual sensing is absent, object shapes are unknown beforehand and objects can move freely, like grabbing objects out of a drawer. Successful solutions require localizing free objects, identifying specific object instances, and then grasping the identified objects, only using touch feedback. Unlike vision, where cameras can observe the entire scene, touch sensors are local and only observe parts of the scene that are in contact with the manipulator. Moreover, information gathering via touch sensors necessitates applying forces on the touched surface which may disturb the scene itself. Reasoning with touch, therefore, requires careful exploration and integration of information over time -- a challenge we tackle. We present a system capable of using sparse tactile feedback from fingertip touch sensors on a dexterous hand to localize, identify and grasp novel objects without any visual feedback. Videos are available at https://taochenshh.github.io/projects/tactofind.
Deep-Learning-based Fast and Accurate 3D CT Deformable Image Registration in Lung Cancer
Apr 21, 2023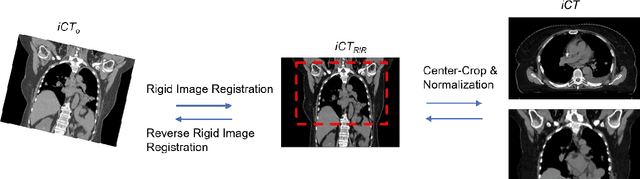
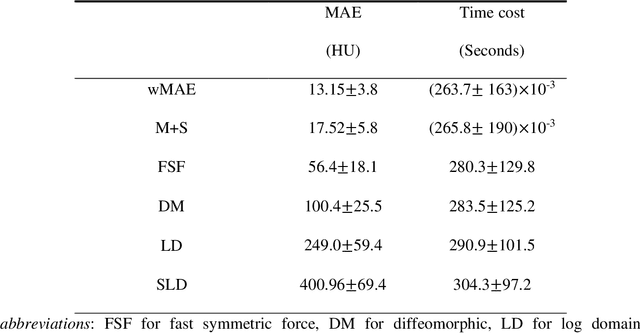
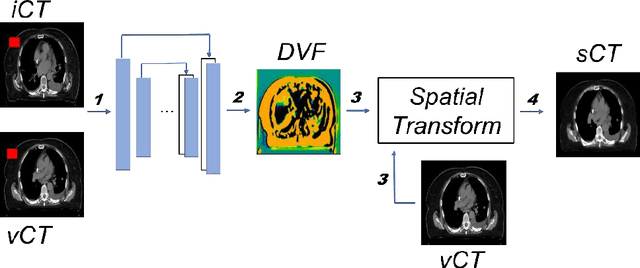
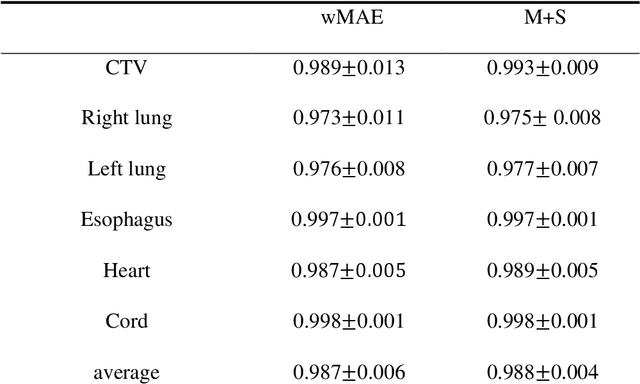
Purpose: In some proton therapy facilities, patient alignment relies on two 2D orthogonal kV images, taken at fixed, oblique angles, as no 3D on-the-bed imaging is available. The visibility of the tumor in kV images is limited since the patient's 3D anatomy is projected onto a 2D plane, especially when the tumor is behind high-density structures such as bones. This can lead to large patient setup errors. A solution is to reconstruct the 3D CT image from the kV images obtained at the treatment isocenter in the treatment position. Methods: An asymmetric autoencoder-like network built with vision-transformer blocks was developed. The data was collected from 1 head and neck patient: 2 orthogonal kV images (1024x1024 voxels), 1 3D CT with padding (512x512x512) acquired from the in-room CT-on-rails before kVs were taken and 2 digitally-reconstructed-radiograph (DRR) images (512x512) based on the CT. We resampled kV images every 8 voxels and DRR and CT every 4 voxels, thus formed a dataset consisting of 262,144 samples, in which the images have a dimension of 128 for each direction. In training, both kV and DRR images were utilized, and the encoder was encouraged to learn the jointed feature map from both kV and DRR images. In testing, only independent kV images were used. The full-size synthetic CT (sCT) was achieved by concatenating the sCTs generated by the model according to their spatial information. The image quality of the synthetic CT (sCT) was evaluated using mean absolute error (MAE) and per-voxel-absolute-CT-number-difference volume histogram (CDVH). Results: The model achieved a speed of 2.1s and a MAE of <40HU. The CDVH showed that <5% of the voxels had a per-voxel-absolute-CT-number-difference larger than 185 HU. Conclusion: A patient-specific vision-transformer-based network was developed and shown to be accurate and efficient to reconstruct 3D CT images from kV images.
Unifying Approaches in Data Subset Selection via Fisher Information and Information-Theoretic Quantities
Aug 01, 2022

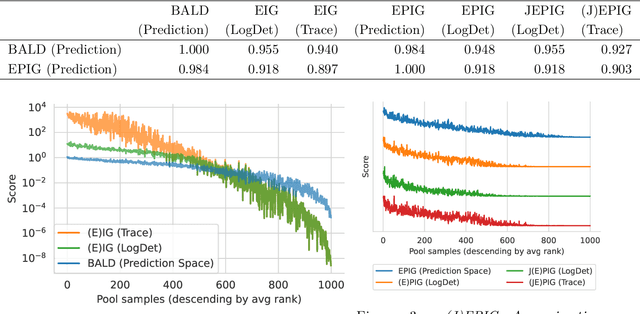
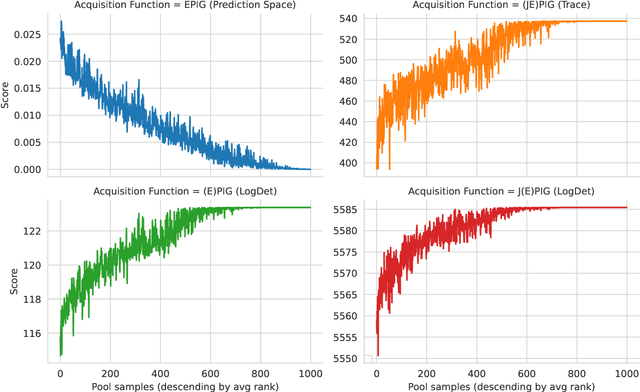
The mutual information between predictions and model parameters -- also referred to as expected information gain or BALD in machine learning -- measures informativeness. It is a popular acquisition function in Bayesian active learning and Bayesian optimal experiment design. In data subset selection, i.e. active learning and active sampling, several recent works use Fisher information, Hessians, similarity matrices based on the gradients, or simply the gradient lengths to compute the acquisition scores that guide sample selection. Are these different approaches connected, and if so how? In this paper, we revisit the Fisher information and use it to show how several otherwise disparate methods are connected as approximations of information-theoretic quantities.
SPeC: A Soft Prompt-Based Calibration on Mitigating Performance Variability in Clinical Notes Summarization
Mar 27, 2023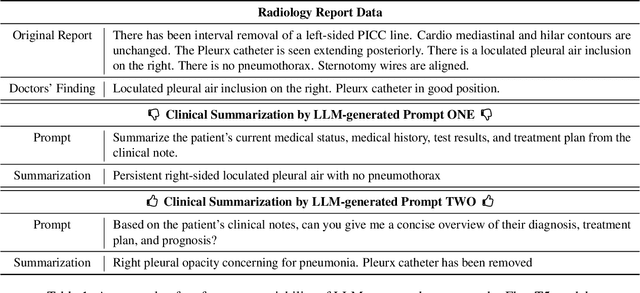
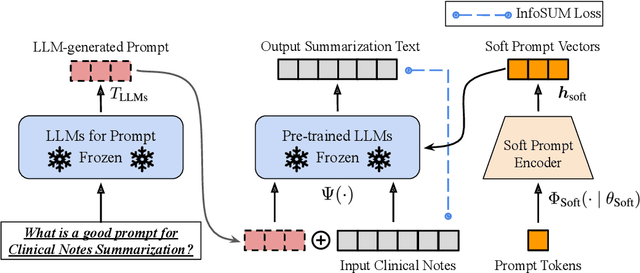

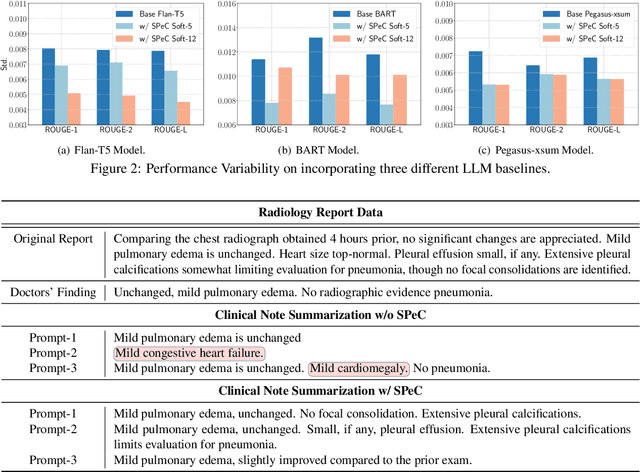
Electronic health records (EHRs) store an extensive array of patient information, encompassing medical histories, diagnoses, treatments, and test outcomes. These records are crucial for enabling healthcare providers to make well-informed decisions regarding patient care. Summarizing clinical notes further assists healthcare professionals in pinpointing potential health risks and making better-informed decisions. This process contributes to reducing errors and enhancing patient outcomes by ensuring providers have access to the most pertinent and current patient data. Recent research has shown that incorporating prompts with large language models (LLMs) substantially boosts the efficacy of summarization tasks. However, we show that this approach also leads to increased output variance, resulting in notably divergent outputs even when prompts share similar meanings. To tackle this challenge, we introduce a model-agnostic Soft Prompt-Based Calibration (SPeC) pipeline that employs soft prompts to diminish variance while preserving the advantages of prompt-based summarization. Experimental findings on multiple clinical note tasks and LLMs indicate that our method not only bolsters performance but also effectively curbs variance for various LLMs, providing a more uniform and dependable solution for summarizing vital medical information.
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities
Mar 27, 2023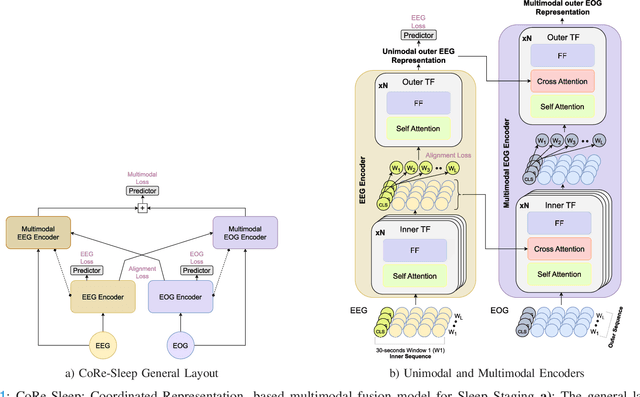
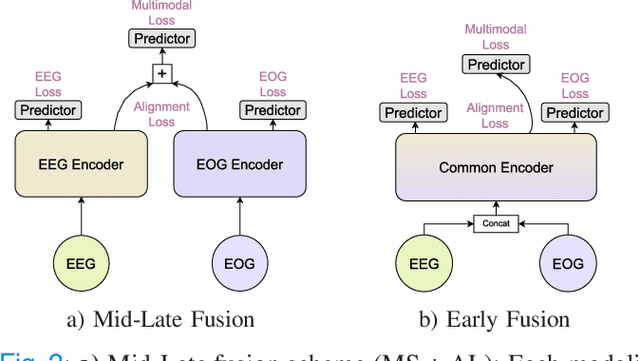
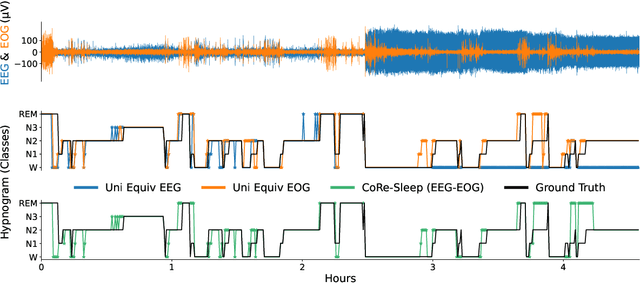
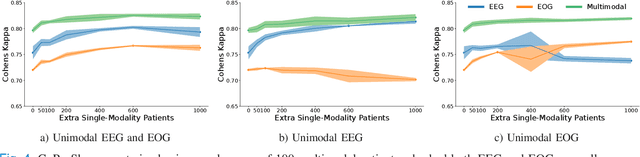
Sleep abnormalities can have severe health consequences. Automated sleep staging, i.e. labelling the sequence of sleep stages from the patient's physiological recordings, could simplify the diagnostic process. Previous work on automated sleep staging has achieved great results, mainly relying on the EEG signal. However, often multiple sources of information are available beyond EEG. This can be particularly beneficial when the EEG recordings are noisy or even missing completely. In this paper, we propose CoRe-Sleep, a Coordinated Representation multimodal fusion network that is particularly focused on improving the robustness of signal analysis on imperfect data. We demonstrate how appropriately handling multimodal information can be the key to achieving such robustness. CoRe-Sleep tolerates noisy or missing modalities segments, allowing training on incomplete data. Additionally, it shows state-of-the-art performance when testing on both multimodal and unimodal data using a single model on SHHS-1, the largest publicly available study that includes sleep stage labels. The results indicate that training the model on multimodal data does positively influence performance when tested on unimodal data. This work aims at bridging the gap between automated analysis tools and their clinical utility.
Sibling-Attack: Rethinking Transferable Adversarial Attacks against Face Recognition
Mar 22, 2023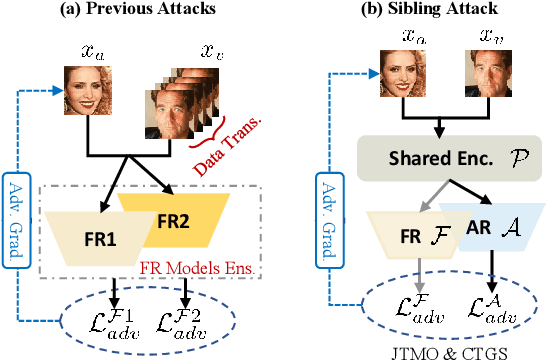


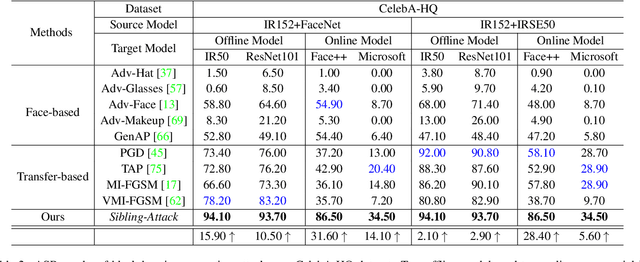
A hard challenge in developing practical face recognition (FR) attacks is due to the black-box nature of the target FR model, i.e., inaccessible gradient and parameter information to attackers. While recent research took an important step towards attacking black-box FR models through leveraging transferability, their performance is still limited, especially against online commercial FR systems that can be pessimistic (e.g., a less than 50% ASR--attack success rate on average). Motivated by this, we present Sibling-Attack, a new FR attack technique for the first time explores a novel multi-task perspective (i.e., leveraging extra information from multi-correlated tasks to boost attacking transferability). Intuitively, Sibling-Attack selects a set of tasks correlated with FR and picks the Attribute Recognition (AR) task as the task used in Sibling-Attack based on theoretical and quantitative analysis. Sibling-Attack then develops an optimization framework that fuses adversarial gradient information through (1) constraining the cross-task features to be under the same space, (2) a joint-task meta optimization framework that enhances the gradient compatibility among tasks, and (3) a cross-task gradient stabilization method which mitigates the oscillation effect during attacking. Extensive experiments demonstrate that Sibling-Attack outperforms state-of-the-art FR attack techniques by a non-trivial margin, boosting ASR by 12.61% and 55.77% on average on state-of-the-art pre-trained FR models and two well-known, widely used commercial FR systems.
Information Removal at the bottleneck in Deep Neural Networks
Sep 30, 2022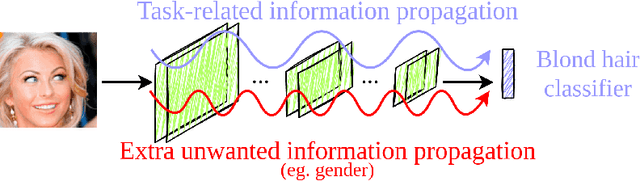
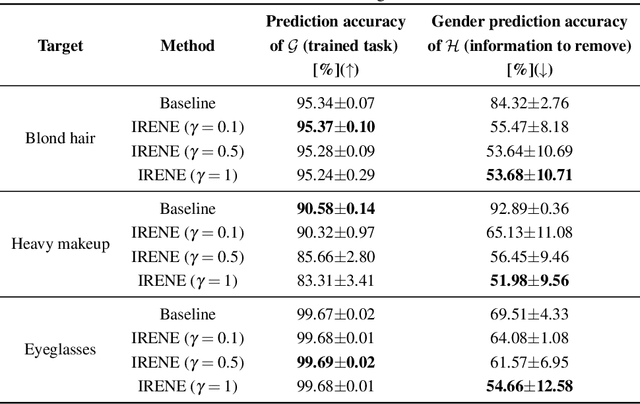
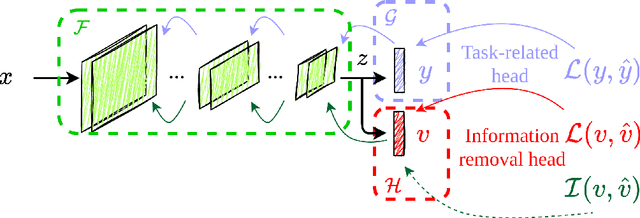

Deep learning models are nowadays broadly deployed to solve an incredibly large variety of tasks. Commonly, leveraging over the availability of "big data", deep neural networks are trained as black-boxes, minimizing an objective function at its output. This however does not allow control over the propagation of some specific features through the model, like gender or race, for solving some an uncorrelated task. This raises issues either in the privacy domain (considering the propagation of unwanted information) and of bias (considering that these features are potentially used to solve the given task). In this work we propose IRENE, a method to achieve information removal at the bottleneck of deep neural networks, which explicitly minimizes the estimated mutual information between the features to be kept ``private'' and the target. Experiments on a synthetic dataset and on CelebA validate the effectiveness of the proposed approach, and open the road towards the development of approaches guaranteeing information removal in deep neural networks.
Stochastic Subgraph Neighborhood Pooling for Subgraph Classification
Apr 17, 2023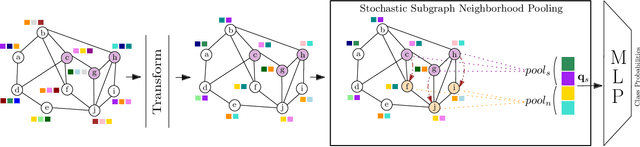
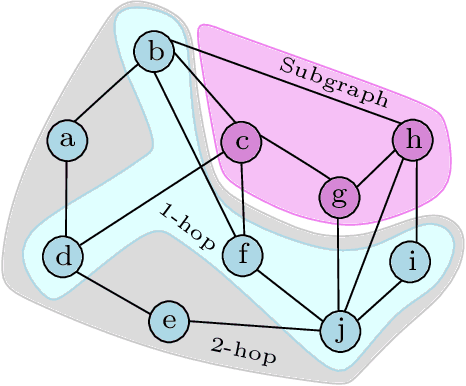
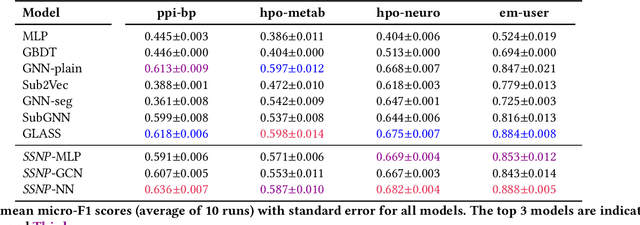
Subgraph classification is an emerging field in graph representation learning where the task is to classify a group of nodes (i.e., a subgraph) within a graph. Subgraph classification has applications such as predicting the cellular function of a group of proteins or identifying rare diseases given a collection of phenotypes. Graph neural networks (GNNs) are the de facto solution for node, link, and graph-level tasks but fail to perform well on subgraph classification tasks. Even GNNs tailored for graph classification are not directly transferable to subgraph classification as they ignore the external topology of the subgraph, thus failing to capture how the subgraph is located within the larger graph. The current state-of-the-art models for subgraph classification address this shortcoming through either labeling tricks or multiple message-passing channels, both of which impose a computation burden and are not scalable to large graphs. To address the scalability issue while maintaining generalization, we propose Stochastic Subgraph Neighborhood Pooling (SSNP), which jointly aggregates the subgraph and its neighborhood (i.e., external topology) information without any computationally expensive operations such as labeling tricks. To improve scalability and generalization further, we also propose a simple data augmentation pre-processing step for SSNP that creates multiple sparse views of the subgraph neighborhood. We show that our model is more expressive than GNNs without labeling tricks. Our extensive experiments demonstrate that our models outperform current state-of-the-art methods (with a margin of up to 2%) while being up to 3X faster in training.
Sub-meter resolution canopy height maps using self-supervised learning and a vision transformer trained on Aerial and GEDI Lidar
Apr 17, 2023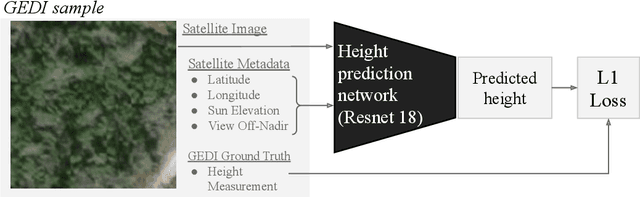
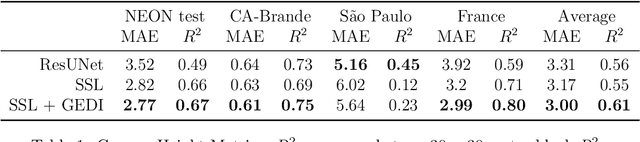
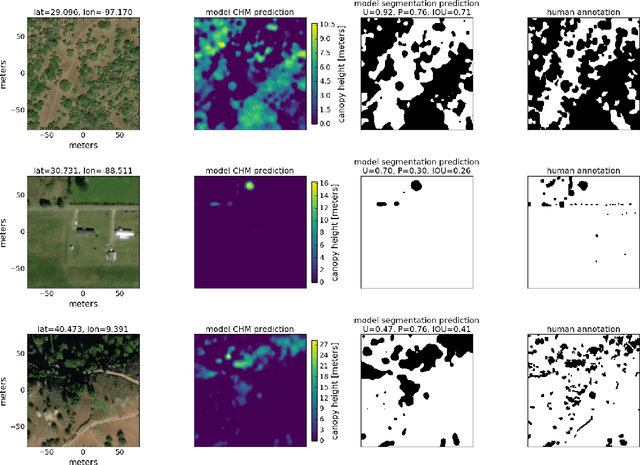
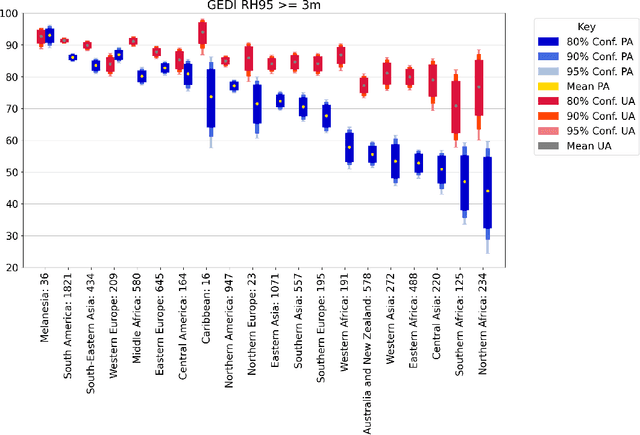
Vegetation structure mapping is critical for understanding the global carbon cycle and monitoring nature-based approaches to climate adaptation and mitigation. Repeat measurements of these data allow for the observation of deforestation or degradation of existing forests, natural forest regeneration, and the implementation of sustainable agricultural practices like agroforestry. Assessments of tree canopy height and crown projected area at a high spatial resolution are also important for monitoring carbon fluxes and assessing tree-based land uses, since forest structures can be highly spatially heterogeneous, especially in agroforestry systems. Very high resolution satellite imagery (less than one meter (1m) ground sample distance) makes it possible to extract information at the tree level while allowing monitoring at a very large scale. This paper presents the first high-resolution canopy height map concurrently produced for multiple sub-national jurisdictions. Specifically, we produce canopy height maps for the states of California and S\~{a}o Paolo, at sub-meter resolution, a significant improvement over the ten meter (10m) resolution of previous Sentinel / GEDI based worldwide maps of canopy height. The maps are generated by applying a vision transformer to features extracted from a self-supervised model in Maxar imagery from 2017 to 2020, and are trained against aerial lidar and GEDI observations. We evaluate the proposed maps with set-aside validation lidar data as well as by comparing with other remotely sensed maps and field-collected data, and find our model produces an average Mean Absolute Error (MAE) within set-aside validation areas of 3.0 meters.