 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Phoneme-Informed Neural Network Model for Note-Level Singing Transcription
Apr 12, 2023
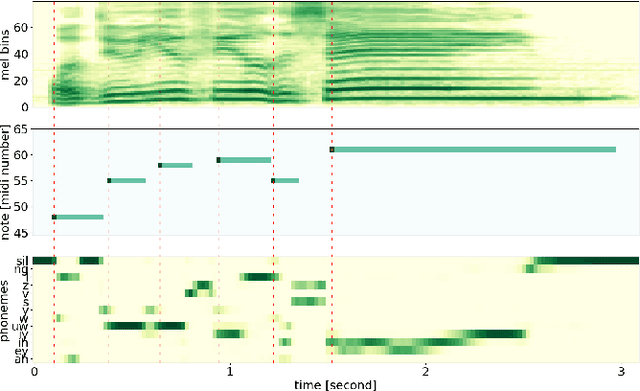
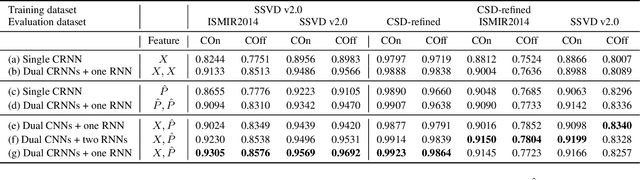
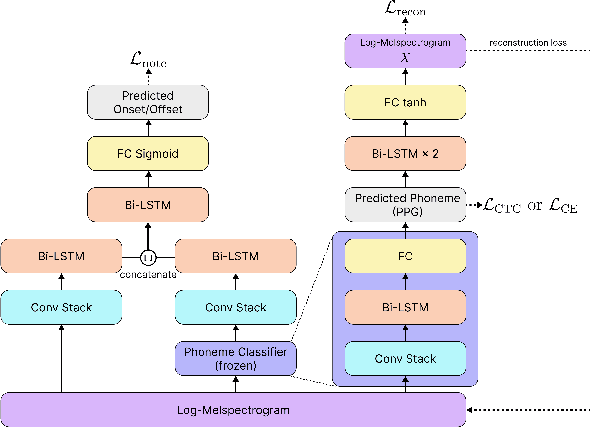

Note-level automatic music transcription is one of the most representative music information retrieval (MIR) tasks and has been studied for various instruments to understand music. However, due to the lack of high-quality labeled data, transcription of many instruments is still a challenging task. In particular, in the case of singing, it is difficult to find accurate notes due to its expressiveness in pitch, timbre, and dynamics. In this paper, we propose a method of finding note onsets of singing voice more accurately by leveraging the linguistic characteristics of singing, which are not seen in other instruments. The proposed model uses mel-scaled spectrogram and phonetic posteriorgram (PPG), a frame-wise likelihood of phoneme, as an input of the onset detection network while PPG is generated by the pre-trained network with singing and speech data. To verify how linguistic features affect onset detection, we compare the evaluation results through the dataset with different languages and divide onset types for detailed analysis. Our approach substantially improves the performance of singing transcription and therefore emphasizes the importance of linguistic features in singing analysis.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 12, 2023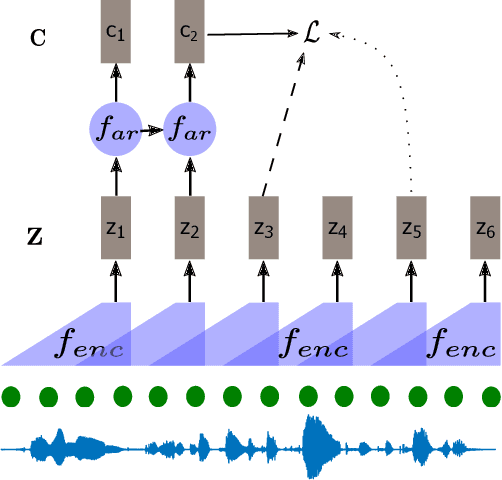
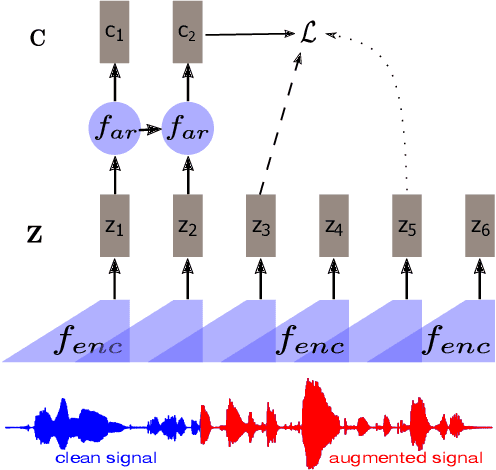
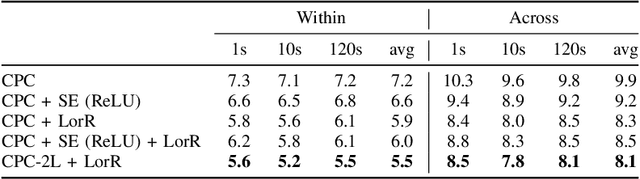
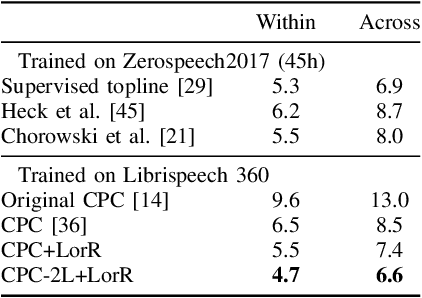
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models.
HaDR: Applying Domain Randomization for Generating Synthetic Multimodal Dataset for Hand Instance Segmentation in Cluttered Industrial Environments
Apr 12, 2023
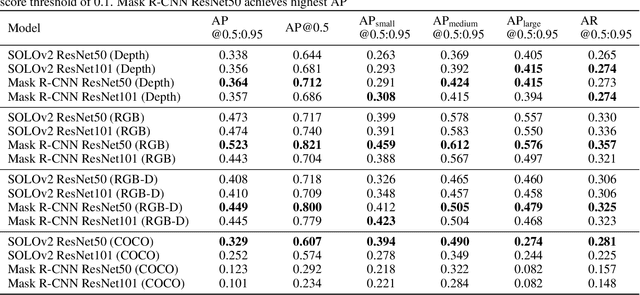

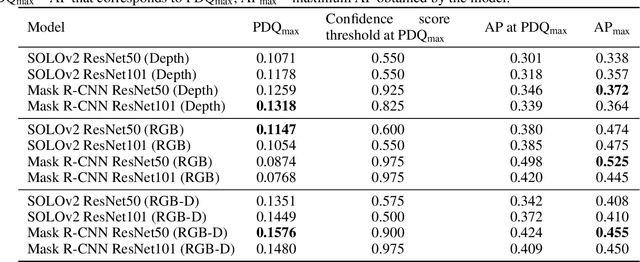
This study uses domain randomization to generate a synthetic RGB-D dataset for training multimodal instance segmentation models, aiming to achieve colour-agnostic hand localization in cluttered industrial environments. Domain randomization is a simple technique for addressing the "reality gap" by randomly rendering unrealistic features in a simulation scene to force the neural network to learn essential domain features. We provide a new synthetic dataset for various hand detection applications in industrial environments, as well as ready-to-use pretrained instance segmentation models. To achieve robust results in a complex unstructured environment, we use multimodal input that includes both colour and depth information, which we hypothesize helps to improve the accuracy of the model prediction. In order to test this assumption, we analyze the influence of each modality and their synergy. The evaluated models were trained solely on our synthetic dataset; yet we show that our approach enables the models to outperform corresponding models trained on existing state-of-the-art datasets in terms of Average Precision and Probability-based Detection Quality.
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Apr 03, 2023
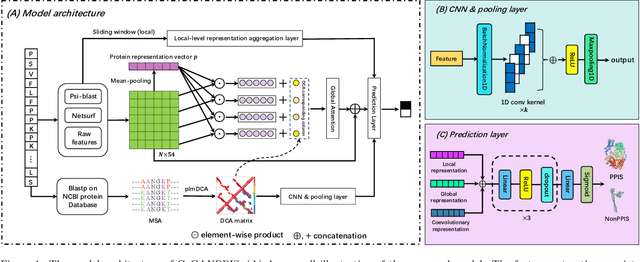
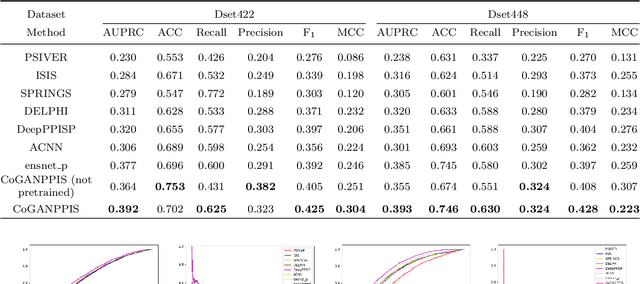
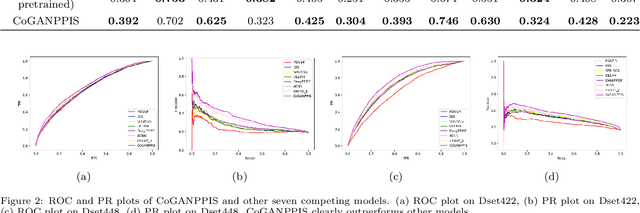
Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
Analysing the Masked predictive coding training criterion for pre-training a Speech Representation Model
Mar 13, 2023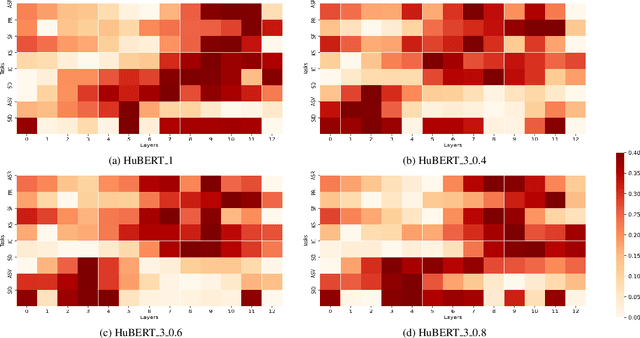

Recent developments in pre-trained speech representation utilizing self-supervised learning (SSL) have yielded exceptional results on a variety of downstream tasks. One such technique, known as masked predictive coding (MPC), has been employed by some of the most high-performing models. In this study, we investigate the impact of MPC loss on the type of information learnt at various layers in the HuBERT model, using nine probing tasks. Our findings indicate that the amount of content information learned at various layers of the HuBERT model has a positive correlation to the MPC loss. Additionally, it is also observed that any speaker-related information learned at intermediate layers of the model, is an indirect consequence of the learning process, and therefore cannot be controlled using the MPC loss. These findings may serve as inspiration for further research in the speech community, specifically in the development of new pre-training tasks or the exploration of new pre-training criterion's that directly preserves both speaker and content information at various layers of a learnt model.
Sensor Control for Information Gain in Dynamic, Sparse and Partially Observed Environments
Nov 03, 2022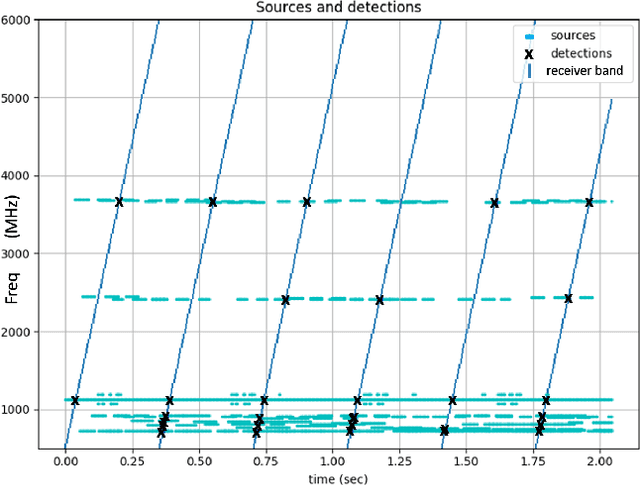

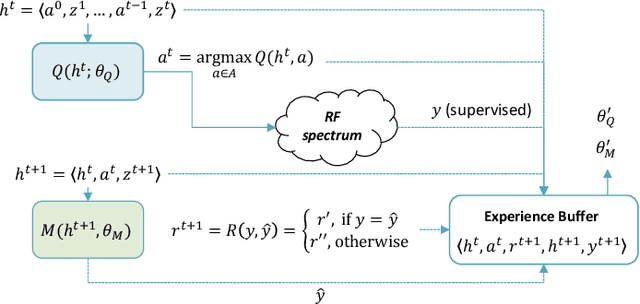

We present an approach for autonomous sensor control for information gathering under partially observable, dynamic and sparsely sampled environments. We consider the problem of controlling a sensor that makes partial observations in some space of interest such that it maximizes information about entities present in that space. We describe our approach for the task of Radio-Frequency (RF) spectrum monitoring, where the goal is to search for and track unknown, dynamic signals in the environment. To this end, we develop and demonstrate enhancements of the Deep Anticipatory Network (DAN) Reinforcement Learning (RL) framework that uses prediction and information-gain rewards to learn information-maximization policies in reward-sparse environments. We also extend this problem to situations in which taking samples from the actual RF spectrum/field is limited and expensive, and propose a model-based version of the original RL algorithm that fine-tunes the controller using a model of the environment that is iteratively improved from limited samples taken from the RF field. Our approach was thoroughly validated by testing against baseline expert-designed controllers in simulated RF environments of different complexity, using different rewards schemes and evaluation metrics. The results show that our system outperforms the standard DAN architecture and is more flexible and robust than several hand-coded agents. We also show that our approach is adaptable to non-stationary environments where the agent has to learn to adapt to changes from the emitting sources.
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
Mar 30, 2023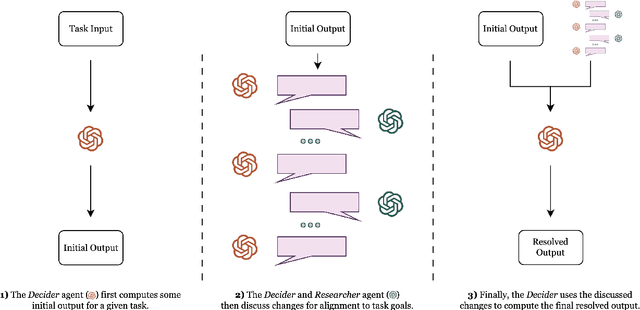
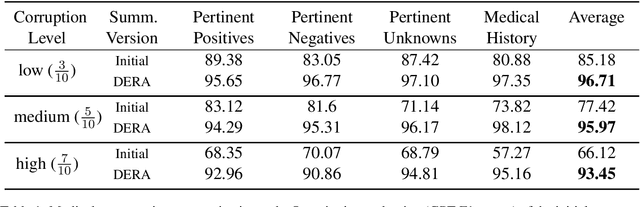
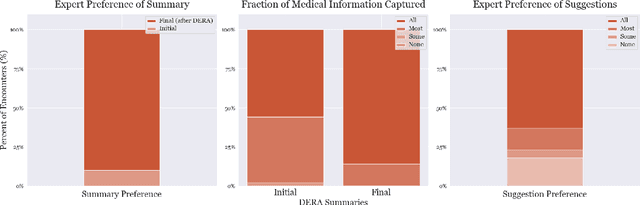

Large language models (LLMs) have emerged as valuable tools for many natural language understanding tasks. In safety-critical applications such as healthcare, the utility of these models is governed by their ability to generate outputs that are factually accurate and complete. In this work, we present dialog-enabled resolving agents (DERA). DERA is a paradigm made possible by the increased conversational abilities of LLMs, namely GPT-4. It provides a simple, interpretable forum for models to communicate feedback and iteratively improve output. We frame our dialog as a discussion between two agent types - a Researcher, who processes information and identifies crucial problem components, and a Decider, who has the autonomy to integrate the Researcher's information and makes judgments on the final output. We test DERA against three clinically-focused tasks. For medical conversation summarization and care plan generation, DERA shows significant improvement over the base GPT-4 performance in both human expert preference evaluations and quantitative metrics. In a new finding, we also show that GPT-4's performance (70%) on an open-ended version of the MedQA question-answering (QA) dataset (Jin et al. 2021, USMLE) is well above the passing level (60%), with DERA showing similar performance. We release the open-ended MEDQA dataset at https://github.com/curai/curai-research/tree/main/DERA.
Audio Visual Language Maps for Robot Navigation
Mar 27, 2023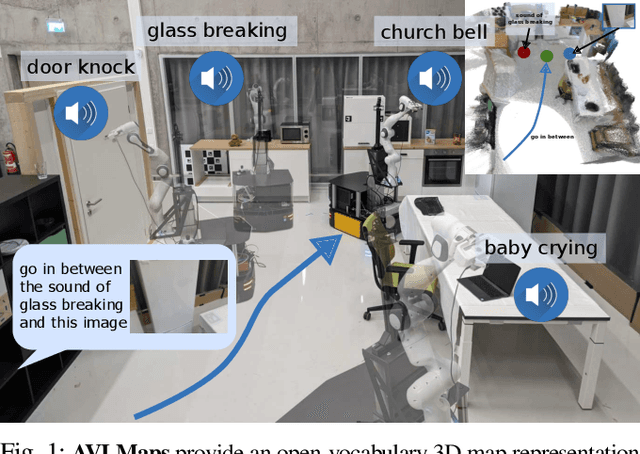
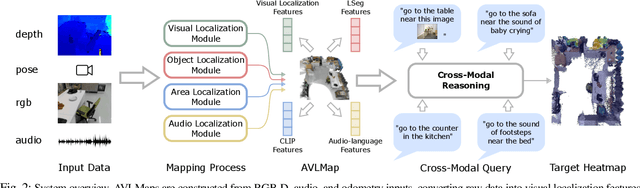
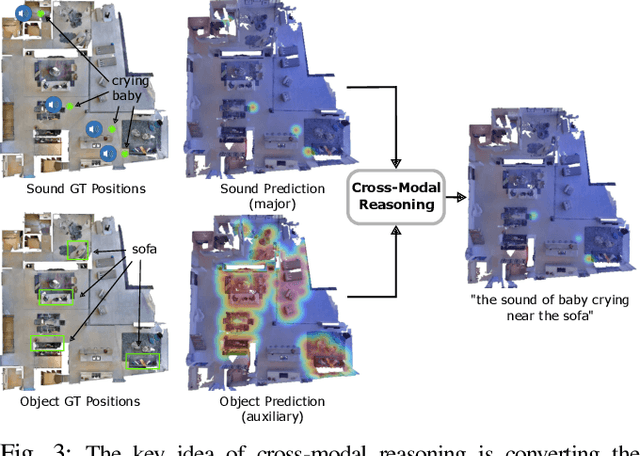

While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world - navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at: https://avlmaps.github.io.
Multi-contrast MRI Super-resolution via Implicit Neural Representations
Mar 27, 2023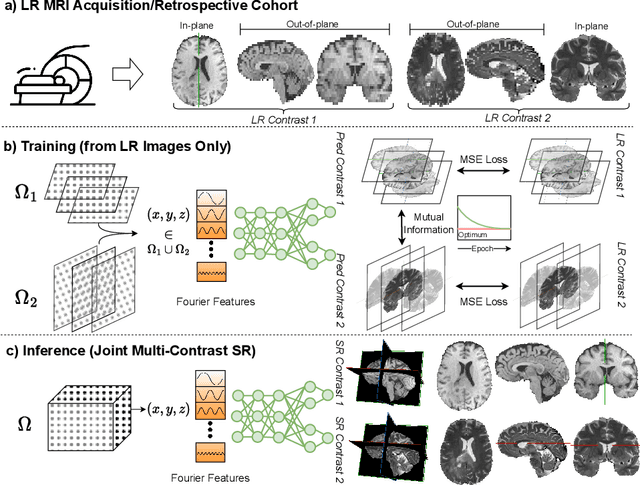
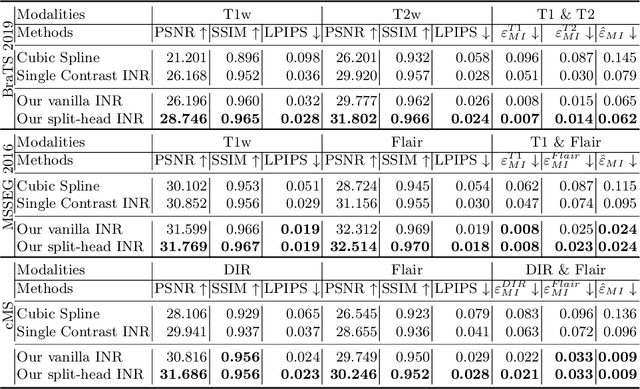
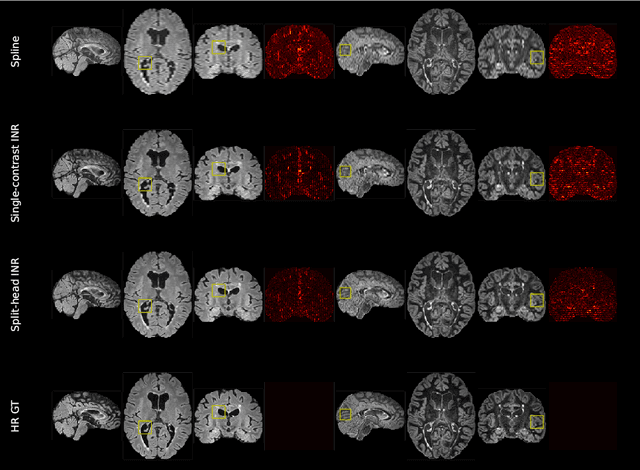

Clinical routine and retrospective cohorts commonly include multi-parametric Magnetic Resonance Imaging; however, they are mostly acquired in different anisotropic 2D views due to signal-to-noise-ratio and scan-time constraints. Thus acquired views suffer from poor out-of-plane resolution and affect downstream volumetric image analysis that typically requires isotropic 3D scans. Combining different views of multi-contrast scans into high-resolution isotropic 3D scans is challenging due to the lack of a large training cohort, which calls for a subject-specific framework.This work proposes a novel solution to this problem leveraging Implicit Neural Representations (INR). Our proposed INR jointly learns two different contrasts of complementary views in a continuous spatial function and benefits from exchanging anatomical information between them. Trained within minutes on a single commodity GPU, our model provides realistic super-resolution across different pairs of contrasts in our experiments with three datasets. Using Mutual Information (MI) as a metric, we find that our model converges to an optimum MI amongst sequences, achieving anatomically faithful reconstruction. Code is available at: https://github.com/jqmcginnis/multi_contrast_inr.
CAT: Learning to Collaborate Channel and Spatial Attention from Multi-Information Fusion
Dec 13, 2022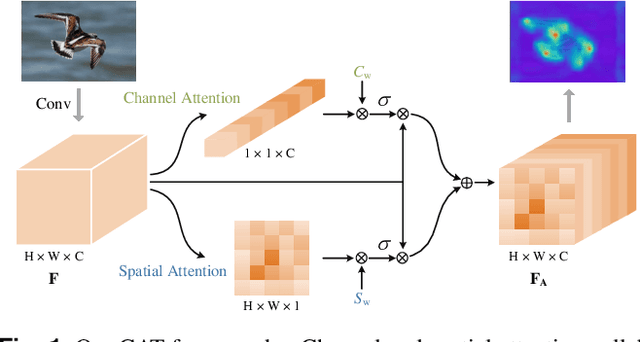
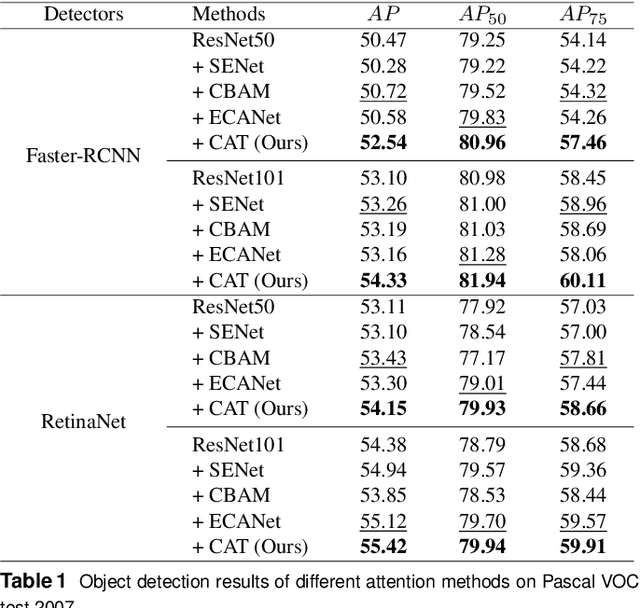
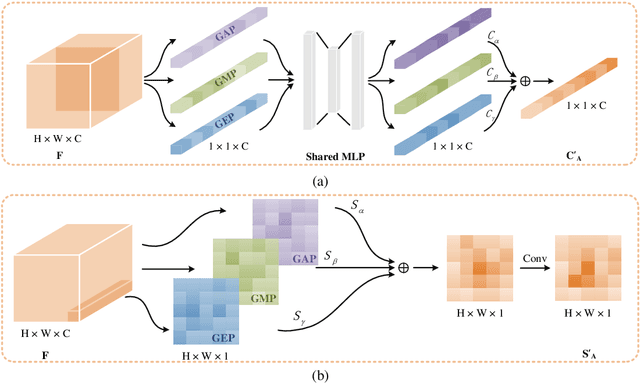
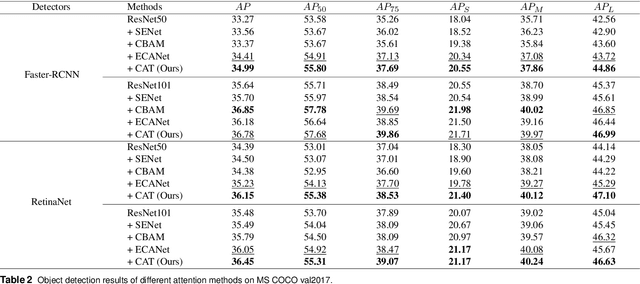
Channel and spatial attention mechanism has proven to provide an evident performance boost of deep convolution neural networks (CNNs). Most existing methods focus on one or run them parallel (series), neglecting the collaboration between the two attentions. In order to better establish the feature interaction between the two types of attention, we propose a plug-and-play attention module, which we term "CAT"-activating the Collaboration between spatial and channel Attentions based on learned Traits. Specifically, we represent traits as trainable coefficients (i.e., colla-factors) to adaptively combine contributions of different attention modules to fit different image hierarchies and tasks better. Moreover, we propose the global entropy pooling (GEP) apart from global average pooling (GAP) and global maximum pooling (GMP) operators, an effective component in suppressing noise signals by measuring the information disorder of feature maps. We introduce a three-way pooling operation into attention modules and apply the adaptive mechanism to fuse their outcomes. Extensive experiments on MS COCO, Pascal-VOC, Cifar-100, and ImageNet show that our CAT outperforms existing state-of-the-art attention mechanisms in object detection, instance segmentation, and image classification. The model and code will be released soon.
* 8 pages, 5 figures