 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Domain Adaptation for Endoscopic Visual Odometry
Mar 16, 2024
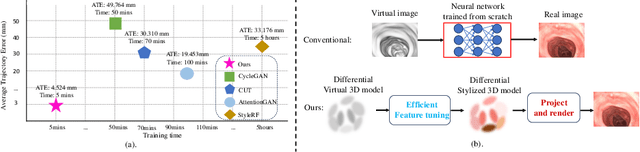
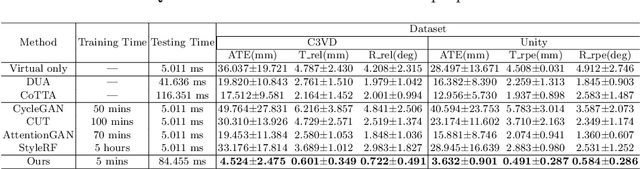
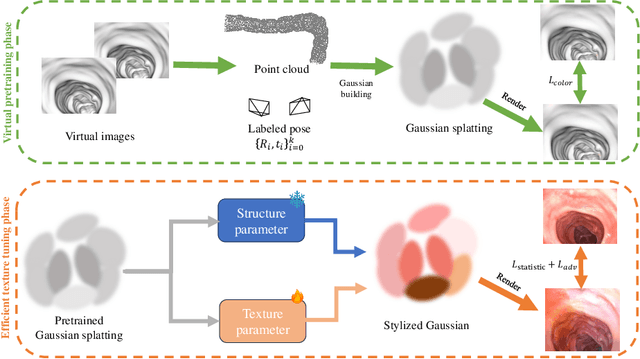
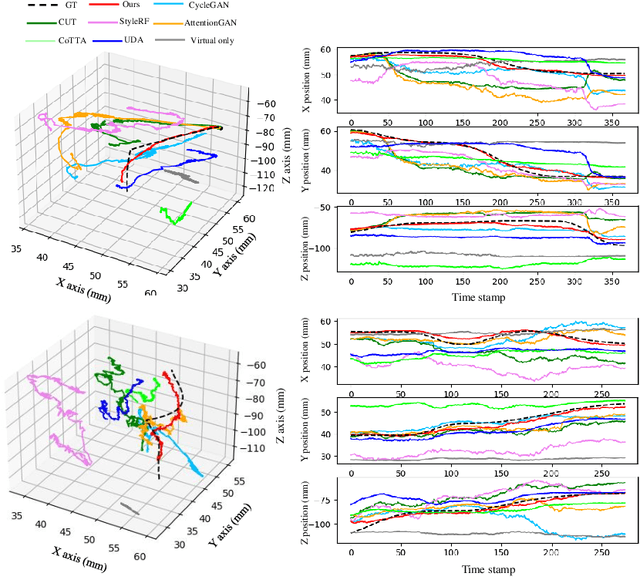
Visual odometry plays a crucial role in endoscopic imaging, yet the scarcity of realistic images with ground truth poses poses a significant challenge. Therefore, domain adaptation offers a promising approach to bridge the pre-operative planning domain with the intra-operative real domain for learning odometry information. However, existing methodologies suffer from inefficiencies in the training time. In this work, an efficient neural style transfer framework for endoscopic visual odometry is proposed, which compresses the time from pre-operative planning to testing phase to less than five minutes. For efficient traing, this work focuses on training modules with only a limited number of real images and we exploit pre-operative prior information to dramatically reduce training duration. Moreover, during the testing phase, we propose a novel Test Time Adaptation (TTA) method to mitigate the gap in lighting conditions between training and testing datasets. Experimental evaluations conducted on two public endoscope datasets showcase that our method achieves state-of-the-art accuracy in visual odometry tasks while boasting the fastest training speeds. These results demonstrate significant promise for intra-operative surgery applications.
MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections
Mar 16, 2024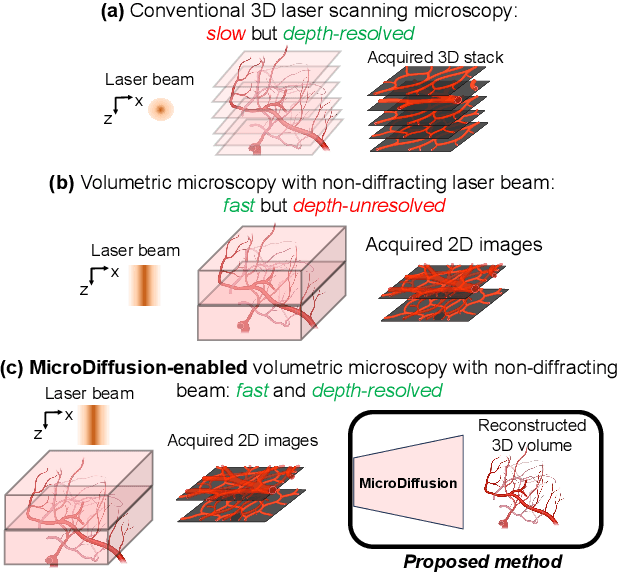
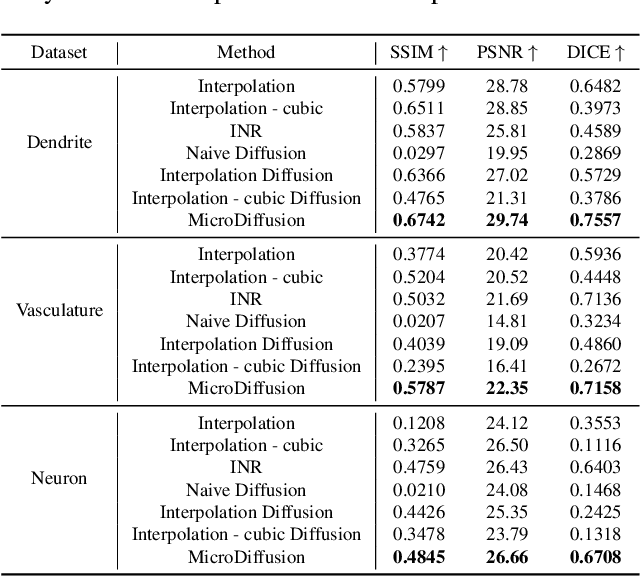
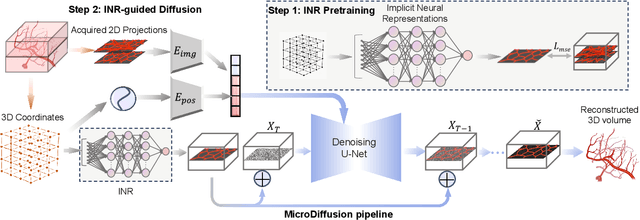
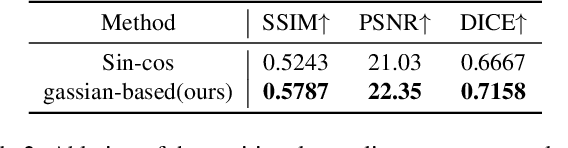
Volumetric optical microscopy using non-diffracting beams enables rapid imaging of 3D volumes by projecting them axially to 2D images but lacks crucial depth information. Addressing this, we introduce MicroDiffusion, a pioneering tool facilitating high-quality, depth-resolved 3D volume reconstruction from limited 2D projections. While existing Implicit Neural Representation (INR) models often yield incomplete outputs and Denoising Diffusion Probabilistic Models (DDPM) excel at capturing details, our method integrates INR's structural coherence with DDPM's fine-detail enhancement capabilities. We pretrain an INR model to transform 2D axially-projected images into a preliminary 3D volume. This pretrained INR acts as a global prior guiding DDPM's generative process through a linear interpolation between INR outputs and noise inputs. This strategy enriches the diffusion process with structured 3D information, enhancing detail and reducing noise in localized 2D images. By conditioning the diffusion model on the closest 2D projection, MicroDiffusion substantially enhances fidelity in resulting 3D reconstructions, surpassing INR and standard DDPM outputs with unparalleled image quality and structural fidelity. Our code and dataset are available at https://github.com/UCSC-VLAA/MicroDiffusion.
Augment Before Copy-Paste: Data and Memory Efficiency-Oriented Instance Segmentation Framework for Sport-scenes
Mar 18, 2024

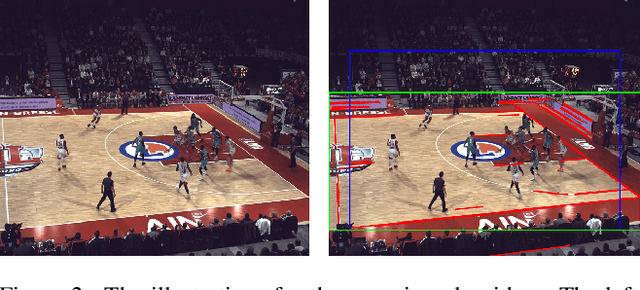
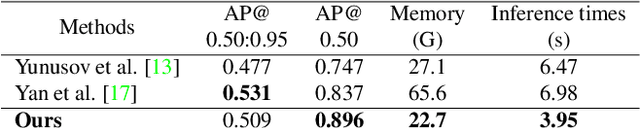
Instance segmentation is a fundamental task in computer vision with broad applications across various industries. In recent years, with the proliferation of deep learning and artificial intelligence applications, how to train effective models with limited data has become a pressing issue for both academia and industry. In the Visual Inductive Priors challenge (VIPriors2023), participants must train a model capable of precisely locating individuals on a basketball court, all while working with limited data and without the use of transfer learning or pre-trained models. We propose Memory effIciency inStance Segmentation framework based on visual inductive prior flow propagation that effectively incorporates inherent prior information from the dataset into both the data preprocessing and data augmentation stages, as well as the inference phase. Our team (ACVLAB) experiments demonstrate that our model achieves promising performance (0.509 AP@0.50:0.95) even under limited data and memory constraints.
Advanced Knowledge Extraction of Physical Design Drawings, Translation and conversion to CAD formats using Deep Learning
Mar 17, 2024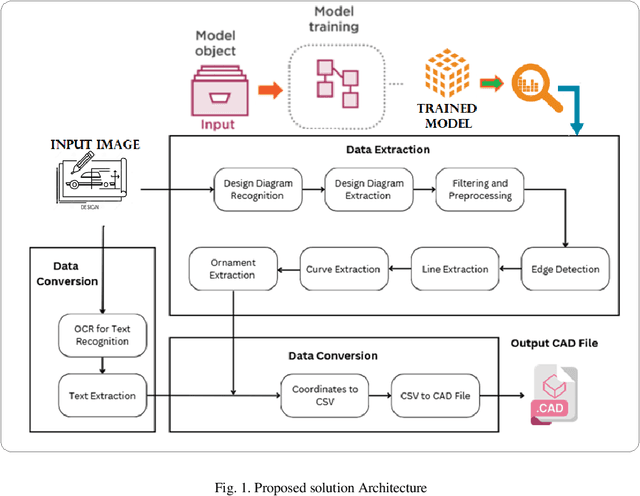
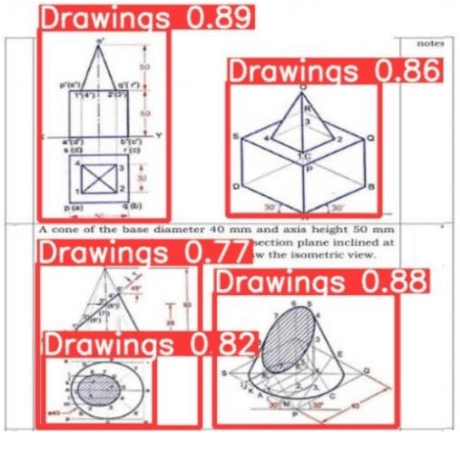
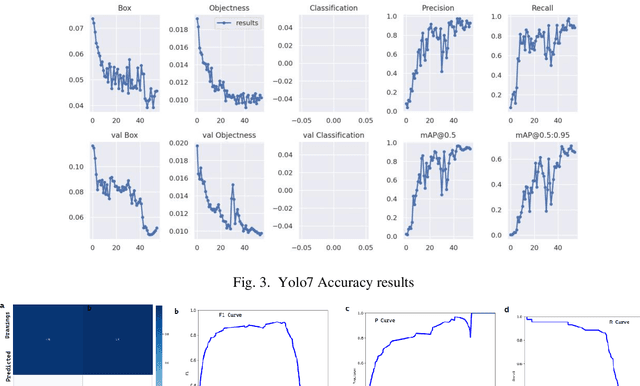
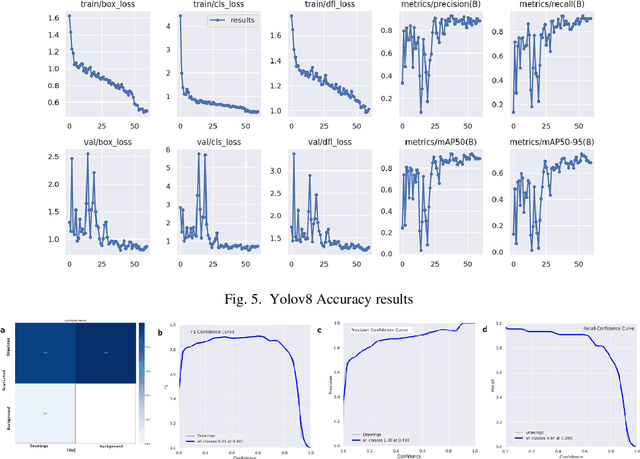
The maintenance, archiving and usage of the design drawings is cumbersome in physical form in different industries for longer period. It is hard to extract information by simple scanning of drawing sheets. Converting them to their digital formats such as Computer-Aided Design (CAD), with needed knowledge extraction can solve this problem. The conversion of these machine drawings to its digital form is a crucial challenge which requires advanced techniques. This research proposes an innovative methodology utilizing Deep Learning methods. The approach employs object detection model, such as Yolov7, Faster R-CNN, to detect physical drawing objects present in the images followed by, edge detection algorithms such as canny filter to extract and refine the identified lines from the drawing region and curve detection techniques to detect circle. Also ornaments (complex shapes) within the drawings are extracted. To ensure comprehensive conversion, an Optical Character Recognition (OCR) tool is integrated to identify and extract the text elements from the drawings. The extracted data which includes the lines, shapes and text is consolidated and stored in a structured comma separated values(.csv) file format. The accuracy and the efficiency of conversion is evaluated. Through this, conversion can be automated to help organizations enhance their productivity, facilitate seamless collaborations and preserve valuable design information in a digital format easily accessible. Overall, this study contributes to the advancement of CAD conversions, providing accurate results from the translating process. Future research can focus on handling diverse drawing types, enhanced accuracy in shape and line detection and extraction.
HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning
Mar 19, 2024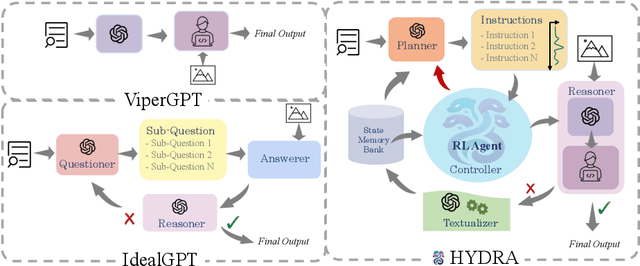
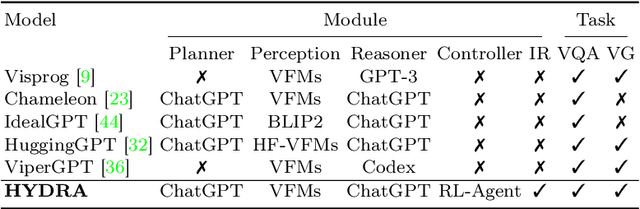
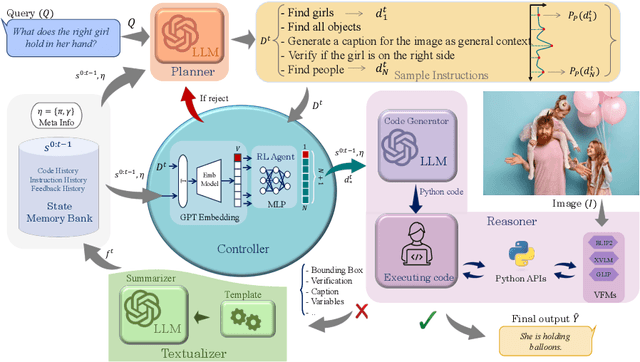
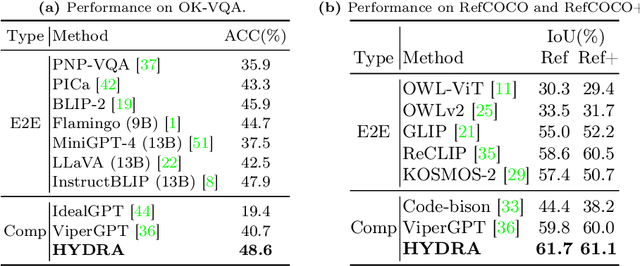
Recent advances in visual reasoning (VR), particularly with the aid of Large Vision-Language Models (VLMs), show promise but require access to large-scale datasets and face challenges such as high computational costs and limited generalization capabilities. Compositional visual reasoning approaches have emerged as effective strategies; however, they heavily rely on the commonsense knowledge encoded in Large Language Models (LLMs) to perform planning, reasoning, or both, without considering the effect of their decisions on the visual reasoning process, which can lead to errors or failed procedures. To address these challenges, we introduce HYDRA, a multi-stage dynamic compositional visual reasoning framework designed for reliable and incrementally progressive general reasoning. HYDRA integrates three essential modules: a planner, a Reinforcement Learning (RL) agent serving as a cognitive controller, and a reasoner. The planner and reasoner modules utilize an LLM to generate instruction samples and executable code from the selected instruction, respectively, while the RL agent dynamically interacts with these modules, making high-level decisions on selection of the best instruction sample given information from the historical state stored through a feedback loop. This adaptable design enables HYDRA to adjust its actions based on previous feedback received during the reasoning process, leading to more reliable reasoning outputs and ultimately enhancing its overall effectiveness. Our framework demonstrates state-of-the-art performance in various VR tasks on four different widely-used datasets.
WaterVG: Waterway Visual Grounding based on Text-Guided Vision and mmWave Radar
Mar 19, 2024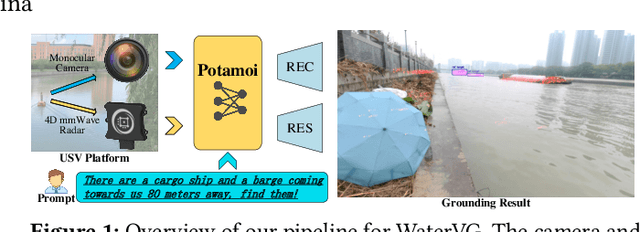
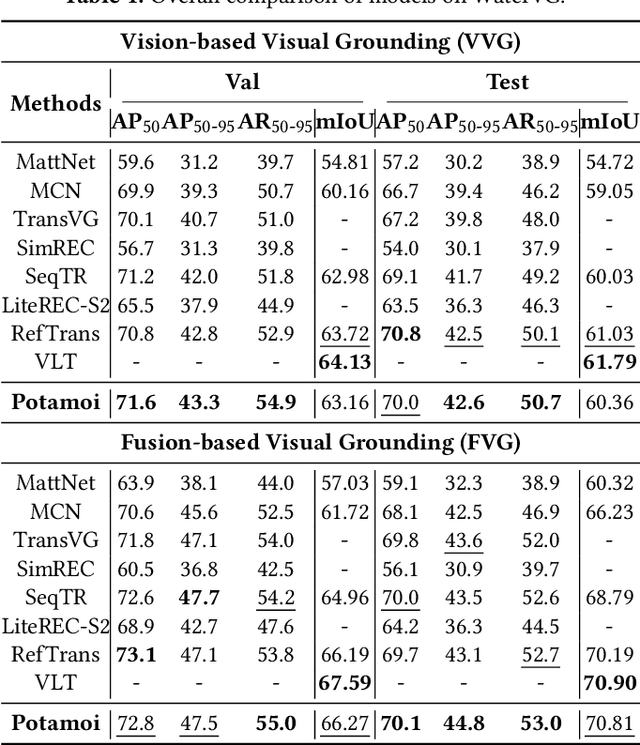

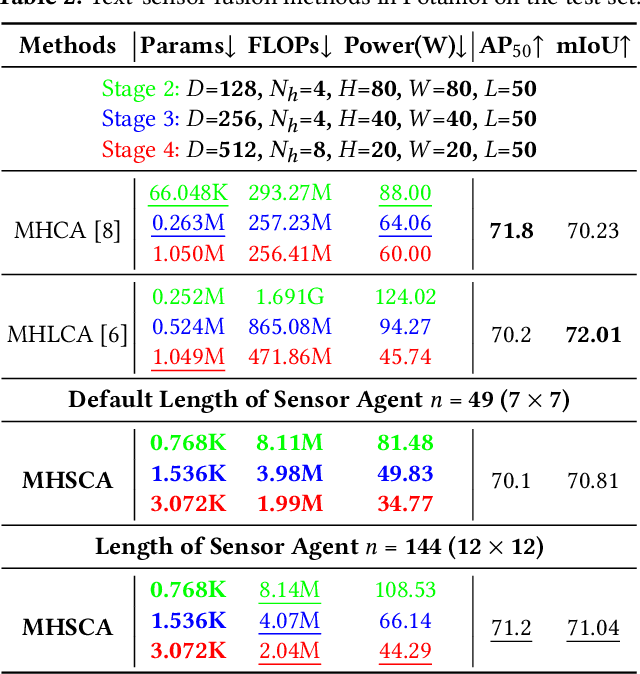
The perception of waterways based on human intent holds significant importance for autonomous navigation and operations of Unmanned Surface Vehicles (USVs) in water environments. Inspired by visual grounding, in this paper, we introduce WaterVG, the first visual grounding dataset designed for USV-based waterway perception based on human intention prompts. WaterVG encompasses prompts describing multiple targets, with annotations at the instance level including bounding boxes and masks. Notably, WaterVG includes 11,568 samples with 34,950 referred targets, which integrates both visual and radar characteristics captured by monocular camera and millimeter-wave (mmWave) radar, enabling a finer granularity of text prompts. Furthermore, we propose a novel multi-modal visual grounding model, Potamoi, which is a multi-modal and multi-task model based on the one-stage paradigm with a designed Phased Heterogeneous Modality Fusion (PHMF) structure, including Adaptive Radar Weighting (ARW) and Multi-Head Slim Cross Attention (MHSCA). In specific, MHSCA is a low-cost and efficient fusion module with a remarkably small parameter count and FLOPs, elegantly aligning and fusing scenario context information captured by two sensors with linguistic features, which can effectively address tasks of referring expression comprehension and segmentation based on fine-grained prompts. Comprehensive experiments and evaluations have been conducted on WaterVG, where our Potamoi archives state-of-the-art performances compared with counterparts.
Enhancing Formal Theorem Proving: A Comprehensive Dataset for Training AI Models on Coq Code
Mar 19, 2024
In the realm of formal theorem proving, the Coq proof assistant stands out for its rigorous approach to verifying mathematical assertions and software correctness. Despite the advances in artificial intelligence and machine learning, the specialized nature of Coq syntax and semantics poses unique challenges for Large Language Models (LLMs). Addressing this gap, we present a comprehensive dataset specifically designed to enhance LLMs' proficiency in interpreting and generating Coq code. This dataset, derived from a collection of over 10,000 Coq source files, encompasses a wide array of propositions, proofs, and definitions, enriched with metadata including source references and licensing information. Our primary aim is to facilitate the development of LLMs capable of generating syntactically correct and semantically meaningful Coq constructs, thereby advancing the frontier of automated theorem proving. Initial experiments with this dataset have showcased its significant potential; models trained on this data exhibited enhanced accuracy in Coq code generation. Notably, a particular experiment revealed that a fine-tuned LLM was capable of generating 141 valid proofs for a basic lemma, highlighting the dataset's utility in facilitating the discovery of diverse and valid proof strategies. This paper discusses the dataset's composition, the methodology behind its creation, and the implications of our findings for the future of machine learning in formal verification. The dataset is accessible for further research and exploration: https://huggingface.co/datasets/florath/coq-facts-props-proofs-gen0-v1
Simple Hack for Transformers against Heavy Long-Text Classification on a Time- and Memory-Limited GPU Service
Mar 19, 2024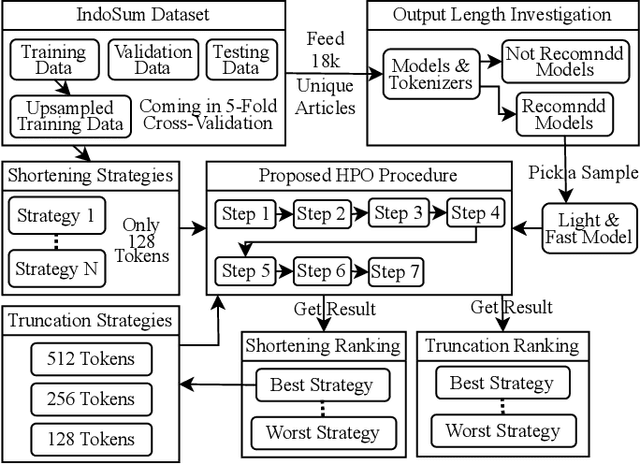

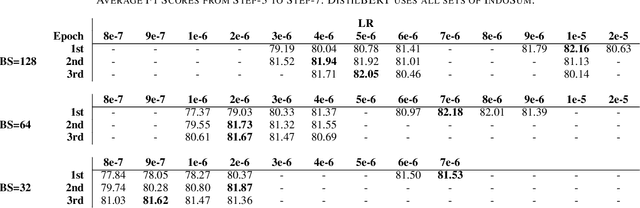
Many NLP researchers rely on free computational services, such as Google Colab, to fine-tune their Transformer models, causing a limitation for hyperparameter optimization (HPO) in long-text classification due to the method having quadratic complexity and needing a bigger resource. In Indonesian, only a few works were found on long-text classification using Transformers. Most only use a small amount of data and do not report any HPO. In this study, using 18k news articles, we investigate which pretrained models are recommended to use based on the output length of the tokenizer. We then compare some hacks to shorten and enrich the sequences, which are the removals of stopwords, punctuation, low-frequency words, and recurring words. To get a fair comparison, we propose and run an efficient and dynamic HPO procedure that can be done gradually on a limited resource and does not require a long-running optimization library. Using the best hack found, we then compare 512, 256, and 128 tokens length. We find that removing stopwords while keeping punctuation and low-frequency words is the best hack. Some of our setups manage to outperform taking 512 first tokens using a smaller 128 or 256 first tokens which manage to represent the same information while requiring less computational resources. The findings could help developers to efficiently pursue optimal performance of the models using limited resources.
ExACT: Language-guided Conceptual Reasoning and Uncertainty Estimation for Event-based Action Recognition and More
Mar 19, 2024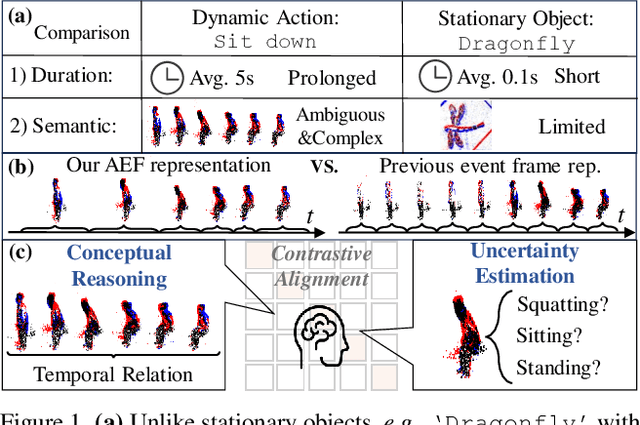
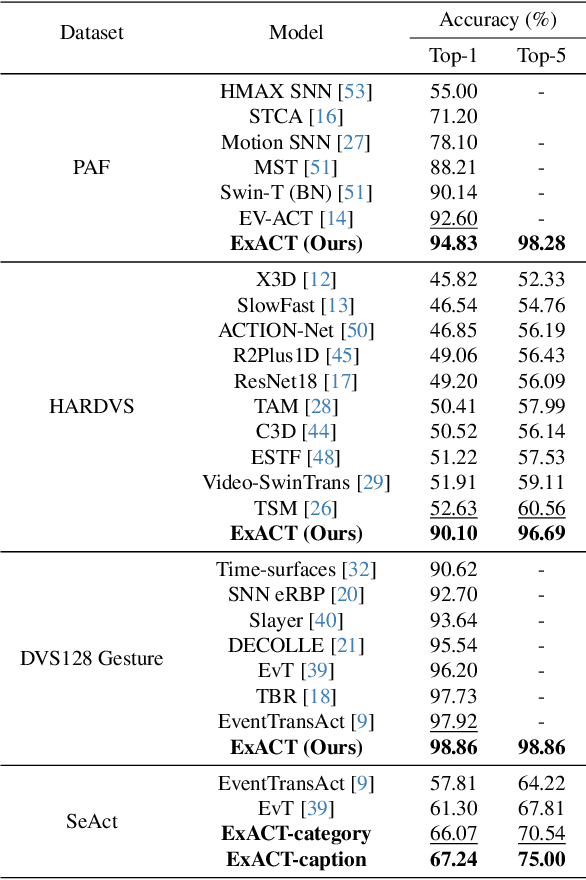
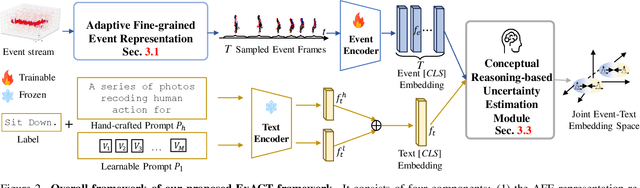
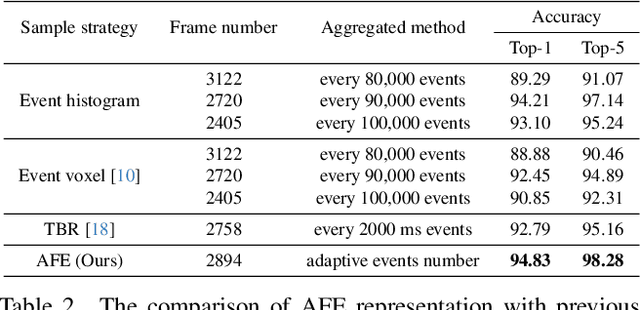
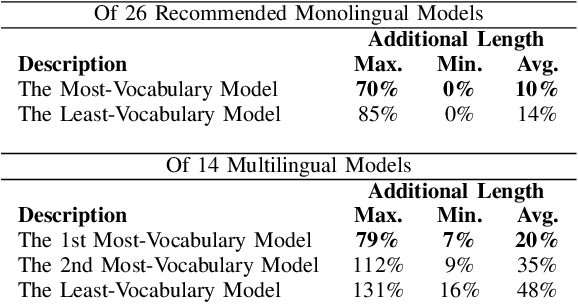
Event cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior recognition accuracy of 94.83%(+2.23%), 90.10%(+37.47%) and 67.24% on PAF, HARDVS and our SeAct datasets respectively.
Urban Sound Propagation: a Benchmark for 1-Step Generative Modeling of Complex Physical Systems
Mar 19, 2024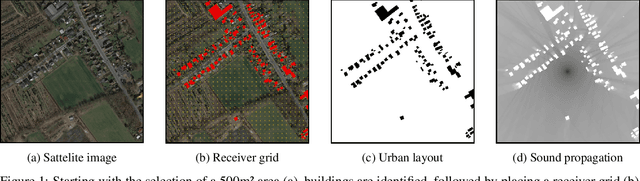

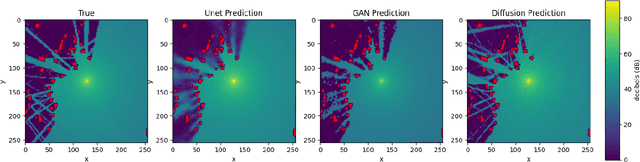
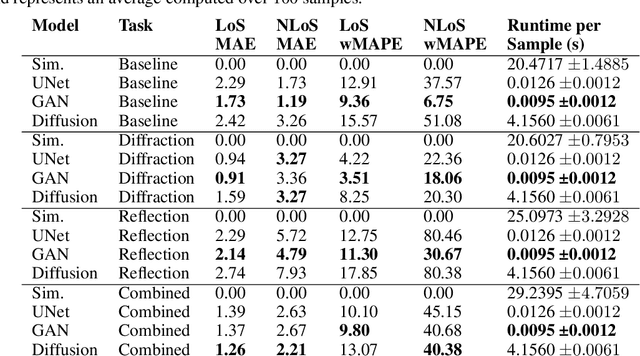
Data-driven modeling of complex physical systems is receiving a growing amount of attention in the simulation and machine learning communities. Since most physical simulations are based on compute-intensive, iterative implementations of differential equation systems, a (partial) replacement with learned, 1-step inference models has the potential for significant speedups in a wide range of application areas. In this context, we present a novel benchmark for the evaluation of 1-step generative learning models in terms of speed and physical correctness. Our Urban Sound Propagation benchmark is based on the physically complex and practically relevant, yet intuitively easy to grasp task of modeling the 2d propagation of waves from a sound source in an urban environment. We provide a dataset with 100k samples, where each sample consists of pairs of real 2d building maps drawn from OpenStreetmap, a parameterized sound source, and a simulated ground truth sound propagation for the given scene. The dataset provides four different simulation tasks with increasing complexity regarding reflection, diffraction and source variance. A first baseline evaluation of common generative U-Net, GAN and Diffusion models shows, that while these models are very well capable of modeling sound propagations in simple cases, the approximation of sub-systems represented by higher order equations systematically fails. Information about the dataset, download instructions and source codes are provided on our website: https://www.urban-sound-data.org.