 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LADER: Log-Augmented DEnse Retrieval for Biomedical Literature Search
Apr 10, 2023
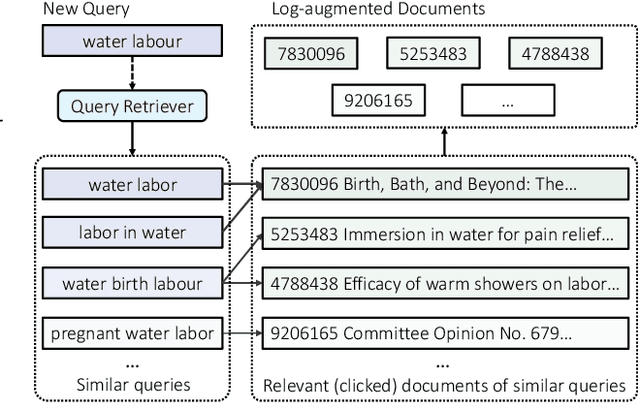
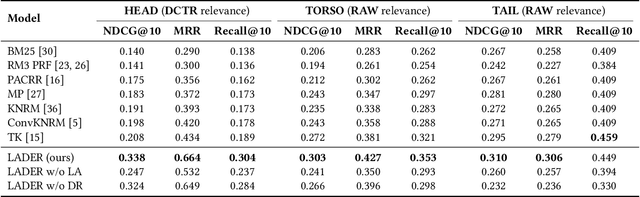
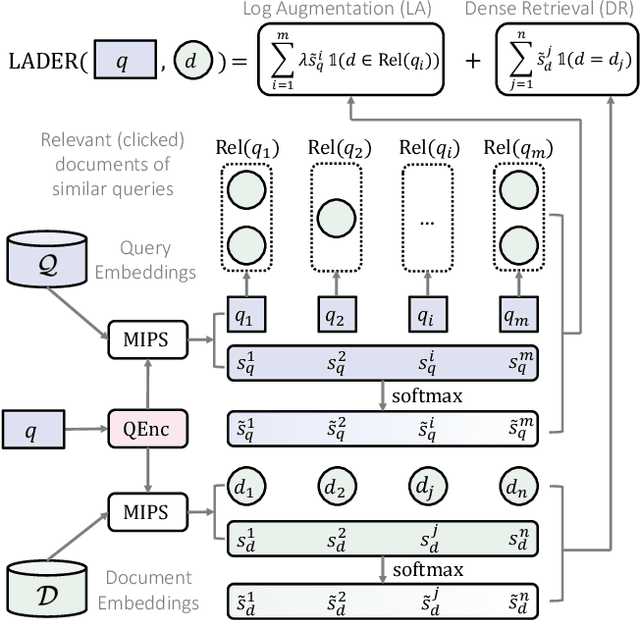
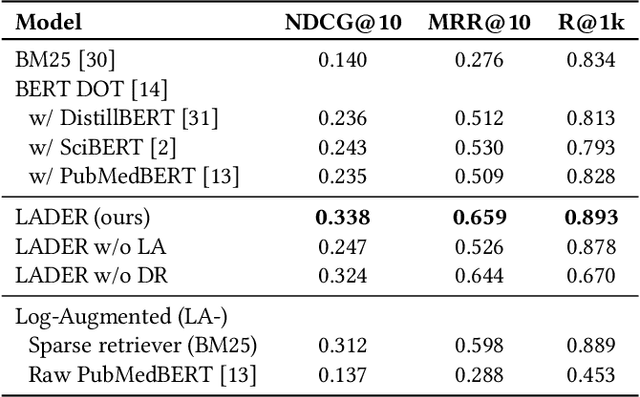
Queries with similar information needs tend to have similar document clicks, especially in biomedical literature search engines where queries are generally short and top documents account for most of the total clicks. Motivated by this, we present a novel architecture for biomedical literature search, namely Log-Augmented DEnse Retrieval (LADER), which is a simple plug-in module that augments a dense retriever with the click logs retrieved from similar training queries. Specifically, LADER finds both similar documents and queries to the given query by a dense retriever. Then, LADER scores relevant (clicked) documents of similar queries weighted by their similarity to the input query. The final document scores by LADER are the average of (1) the document similarity scores from the dense retriever and (2) the aggregated document scores from the click logs of similar queries. Despite its simplicity, LADER achieves new state-of-the-art (SOTA) performance on TripClick, a recently released benchmark for biomedical literature retrieval. On the frequent (HEAD) queries, LADER largely outperforms the best retrieval model by 39% relative NDCG@10 (0.338 v.s. 0.243). LADER also achieves better performance on the less frequent (TORSO) queries with 11% relative NDCG@10 improvement over the previous SOTA (0.303 v.s. 0.272). On the rare (TAIL) queries where similar queries are scarce, LADER still compares favorably to the previous SOTA method (NDCG@10: 0.310 v.s. 0.295). On all queries, LADER can improve the performance of a dense retriever by 24%-37% relative NDCG@10 while not requiring additional training, and further performance improvement is expected from more logs. Our regression analysis has shown that queries that are more frequent, have higher entropy of query similarity and lower entropy of document similarity, tend to benefit more from log augmentation.
A Clustering Method Based on Information Entropy Payload
Sep 13, 2022
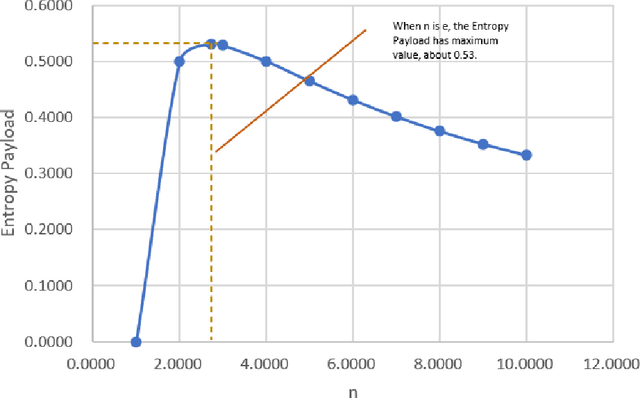

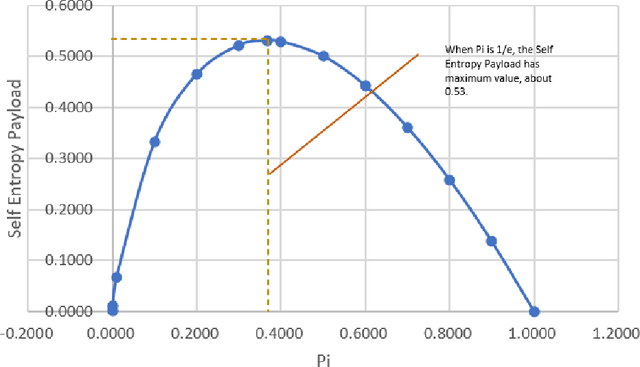
Existing clustering algorithms such as K-means often need to preset parameters such as the number of categories K, and such parameters may lead to the failure to output objective and consistent clustering results. This paper introduces a clustering method based on the information theory, by which clusters in the clustering result have maximum average information entropy (called entropy payload in this paper). This method can bring the following benefits: firstly, this method does not need to preset any super parameter such as category number or other similar thresholds, secondly, the clustering results have the maximum information expression efficiency. it can be used in image segmentation, object classification, etc., and could be the basis of unsupervised learning.
Grounding Graph Network Simulators using Physical Sensor Observations
Mar 07, 2023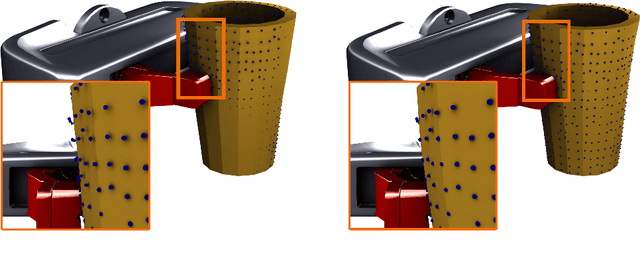

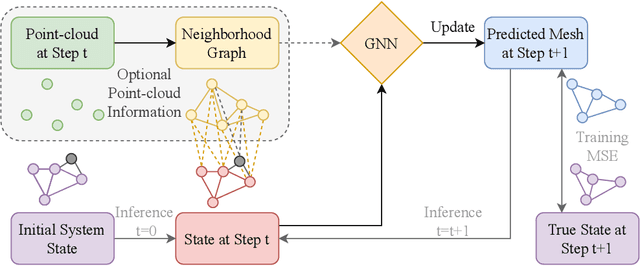
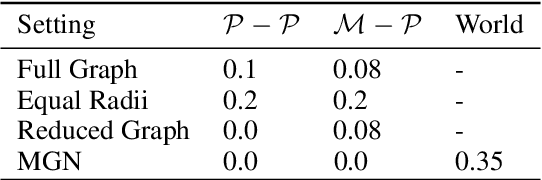
Physical simulations that accurately model reality are crucial for many engineering disciplines such as mechanical engineering and robotic motion planning. In recent years, learned Graph Network Simulators produced accurate mesh-based simulations while requiring only a fraction of the computational cost of traditional simulators. Yet, the resulting predictors are confined to learning from data generated by existing mesh-based simulators and thus cannot include real world sensory information such as point cloud data. As these predictors have to simulate complex physical systems from only an initial state, they exhibit a high error accumulation for long-term predictions. In this work, we integrate sensory information to ground Graph Network Simulators on real world observations. In particular, we predict the mesh state of deformable objects by utilizing point cloud data. The resulting model allows for accurate predictions over longer time horizons, even under uncertainties in the simulation, such as unknown material properties. Since point clouds are usually not available for every time step, especially in online settings, we employ an imputation-based model. The model can make use of such additional information only when provided, and resorts to a standard Graph Network Simulator, otherwise. We experimentally validate our approach on a suite of prediction tasks for mesh-based interactions between soft and rigid bodies. Our method results in utilization of additional point cloud information to accurately predict stable simulations where existing Graph Network Simulators fail.
LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion
Mar 14, 2023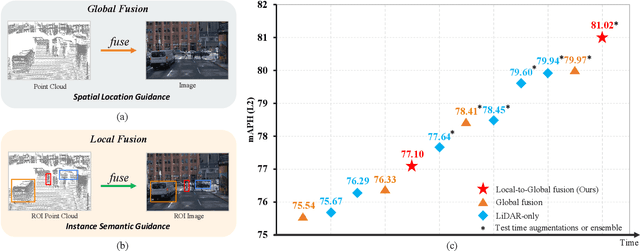
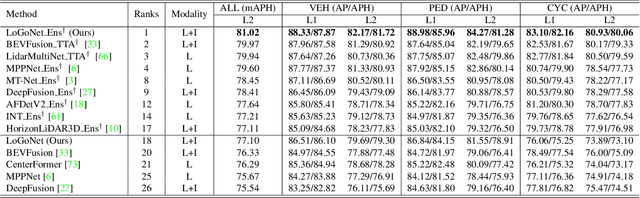
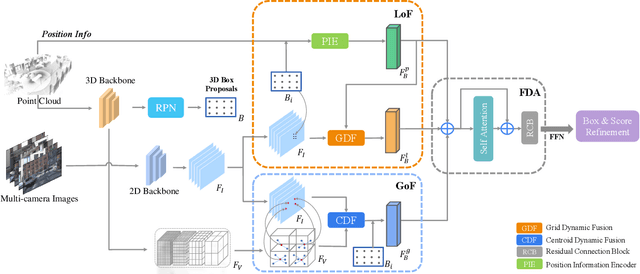
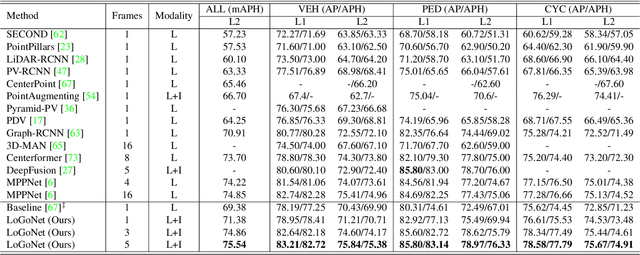
LiDAR-camera fusion methods have shown impressive performance in 3D object detection. Recent advanced multi-modal methods mainly perform global fusion, where image features and point cloud features are fused across the whole scene. Such practice lacks fine-grained region-level information, yielding suboptimal fusion performance. In this paper, we present the novel Local-to-Global fusion network (LoGoNet), which performs LiDAR-camera fusion at both local and global levels. Concretely, the Global Fusion (GoF) of LoGoNet is built upon previous literature, while we exclusively use point centroids to more precisely represent the position of voxel features, thus achieving better cross-modal alignment. As to the Local Fusion (LoF), we first divide each proposal into uniform grids and then project these grid centers to the images. The image features around the projected grid points are sampled to be fused with position-decorated point cloud features, maximally utilizing the rich contextual information around the proposals. The Feature Dynamic Aggregation (FDA) module is further proposed to achieve information interaction between these locally and globally fused features, thus producing more informative multi-modal features. Extensive experiments on both Waymo Open Dataset (WOD) and KITTI datasets show that LoGoNet outperforms all state-of-the-art 3D detection methods. Notably, LoGoNet ranks 1st on Waymo 3D object detection leaderboard and obtains 81.02 mAPH (L2) detection performance. It is noteworthy that, for the first time, the detection performance on three classes surpasses 80 APH (L2) simultaneously. Code will be available at \url{https://github.com/sankin97/LoGoNet}.
Conceptual Reinforcement Learning for Language-Conditioned Tasks
Mar 09, 2023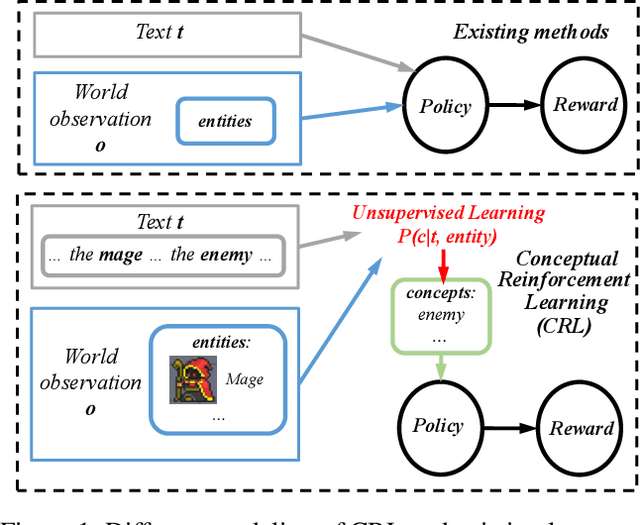
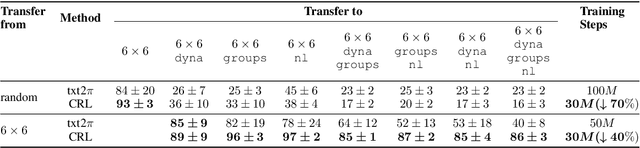
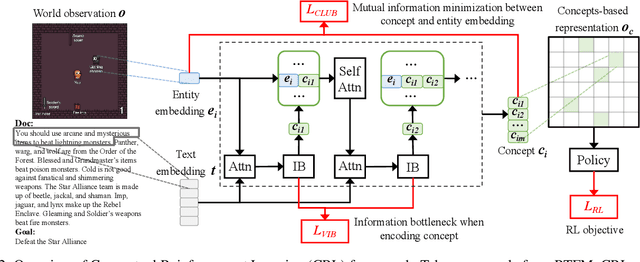
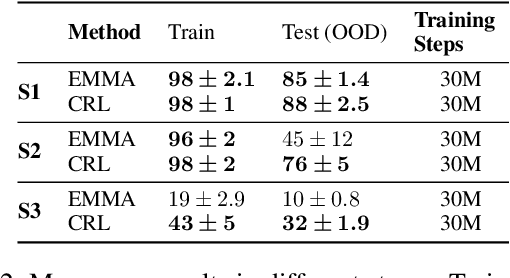
Despite the broad application of deep reinforcement learning (RL), transferring and adapting the policy to unseen but similar environments is still a significant challenge. Recently, the language-conditioned policy is proposed to facilitate policy transfer through learning the joint representation of observation and text that catches the compact and invariant information across environments. Existing studies of language-conditioned RL methods often learn the joint representation as a simple latent layer for the given instances (episode-specific observation and text), which inevitably includes noisy or irrelevant information and cause spurious correlations that are dependent on instances, thus hurting generalization performance and training efficiency. To address this issue, we propose a conceptual reinforcement learning (CRL) framework to learn the concept-like joint representation for language-conditioned policy. The key insight is that concepts are compact and invariant representations in human cognition through extracting similarities from numerous instances in real-world. In CRL, we propose a multi-level attention encoder and two mutual information constraints for learning compact and invariant concepts. Verified in two challenging environments, RTFM and Messenger, CRL significantly improves the training efficiency (up to 70%) and generalization ability (up to 30%) to the new environment dynamics.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 04, 2023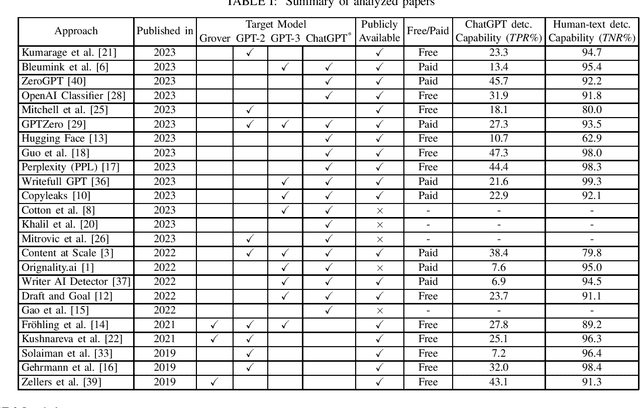
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Apr 04, 2023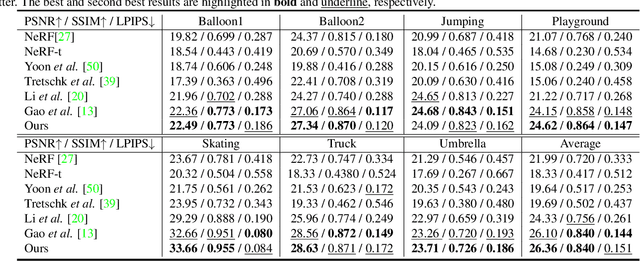

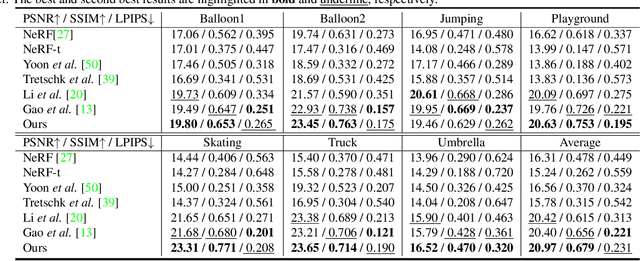
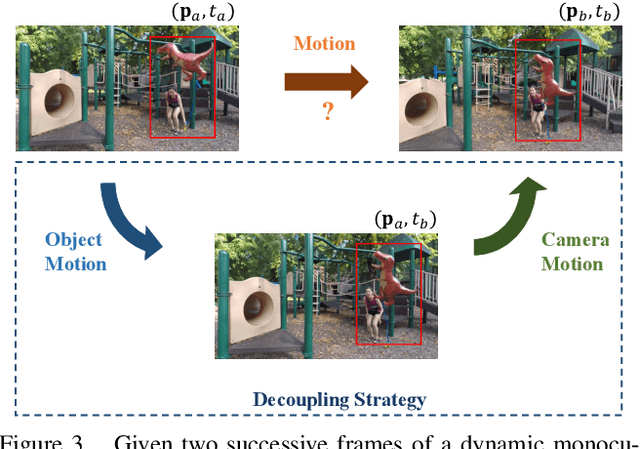
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the dynamic objects of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by additional methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision. We will make the code publicly available.
Privacy Amplification via Compression: Achieving the Optimal Privacy-Accuracy-Communication Trade-off in Distributed Mean Estimation
Apr 04, 2023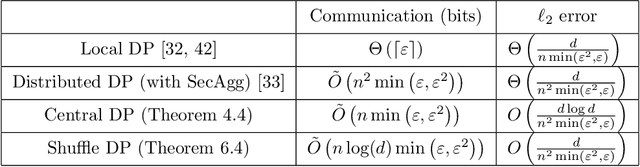
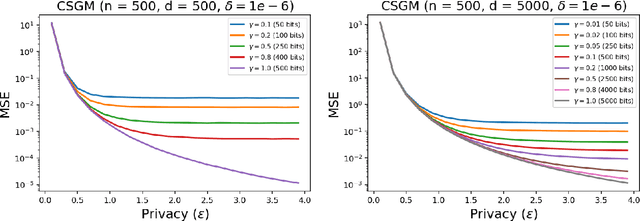
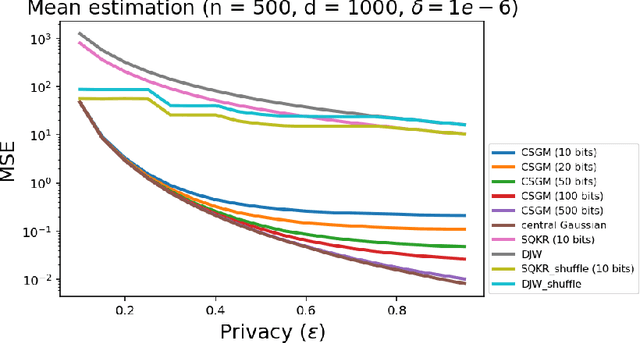
Privacy and communication constraints are two major bottlenecks in federated learning (FL) and analytics (FA). We study the optimal accuracy of mean and frequency estimation (canonical models for FL and FA respectively) under joint communication and $(\varepsilon, \delta)$-differential privacy (DP) constraints. We show that in order to achieve the optimal error under $(\varepsilon, \delta)$-DP, it is sufficient for each client to send $\Theta\left( n \min\left(\varepsilon, \varepsilon^2\right)\right)$ bits for FL and $\Theta\left(\log\left( n\min\left(\varepsilon, \varepsilon^2\right) \right)\right)$ bits for FA to the server, where $n$ is the number of participating clients. Without compression, each client needs $O(d)$ bits and $\log d$ bits for the mean and frequency estimation problems respectively (where $d$ corresponds to the number of trainable parameters in FL or the domain size in FA), which means that we can get significant savings in the regime $ n \min\left(\varepsilon, \varepsilon^2\right) = o(d)$, which is often the relevant regime in practice. Our algorithms leverage compression for privacy amplification: when each client communicates only partial information about its sample, we show that privacy can be amplified by randomly selecting the part contributed by each client.
Multi model LSTM architecture for Track Association based on Automatic Identification System Data
Apr 04, 2023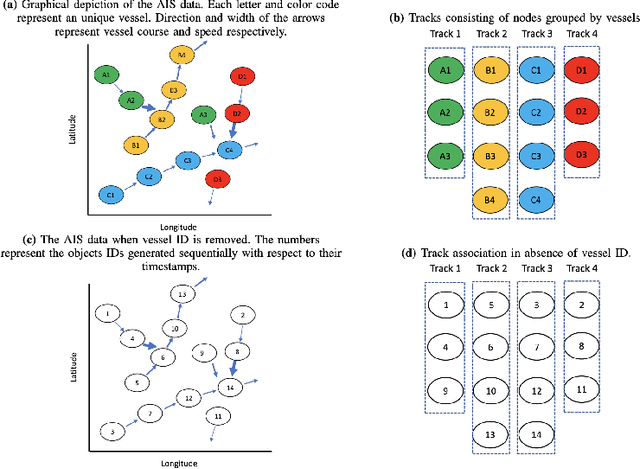

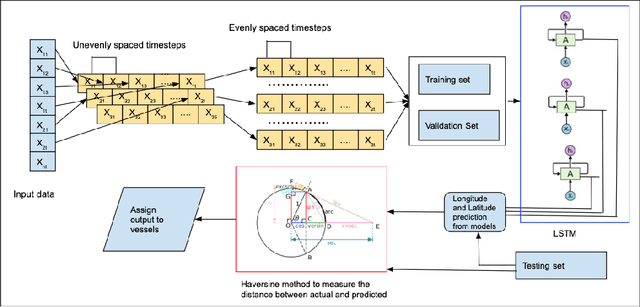

For decades, track association has been a challenging problem in marine surveillance, which involves the identification and association of vessel observations over time. However, the Automatic Identification System (AIS) has provided a new opportunity for researchers to tackle this problem by offering a large database of dynamic and geo-spatial information of marine vessels. With the availability of such large databases, researchers can now develop sophisticated models and algorithms that leverage the increased availability of data to address the track association challenge effectively. Furthermore, with the advent of deep learning, track association can now be approached as a data-intensive problem. In this study, we propose a Long Short-Term Memory (LSTM) based multi-model framework for track association. LSTM is a recurrent neural network architecture that is capable of processing multivariate temporal data collected over time in a sequential manner, enabling it to predict current vessel locations from historical observations. Based on these predictions, a geodesic distance based similarity metric is then utilized to associate the unclassified observations to their true tracks (vessels). We evaluate the performance of our approach using standard performance metrics, such as precision, recall, and F1 score, which provide a comprehensive summary of the accuracy of the proposed framework.
ConvFormer: Parameter Reduction in Transformer Models for 3D Human Pose Estimation by Leveraging Dynamic Multi-Headed Convolutional Attention
Apr 04, 2023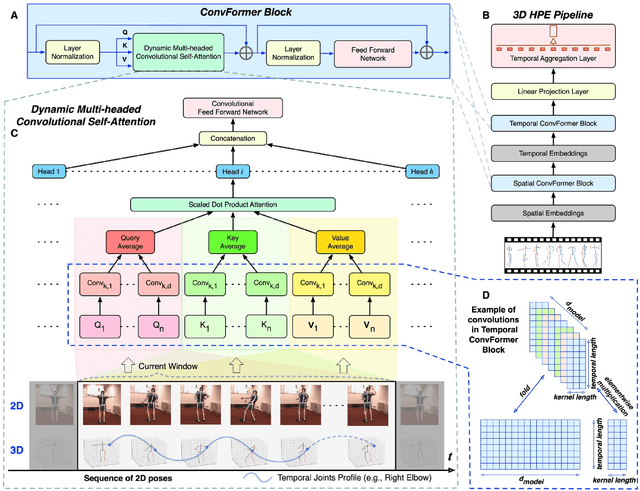
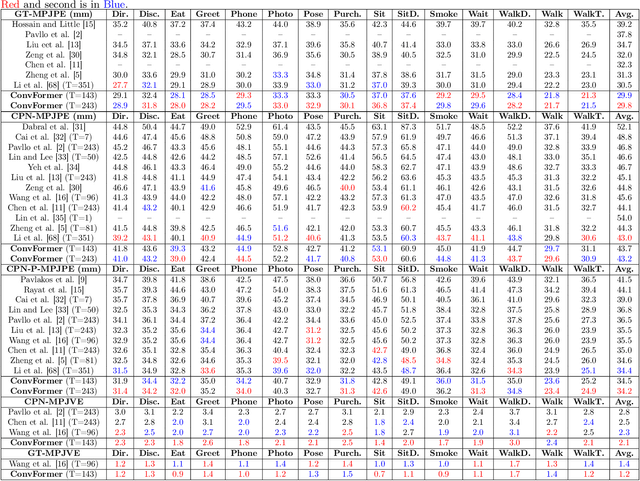
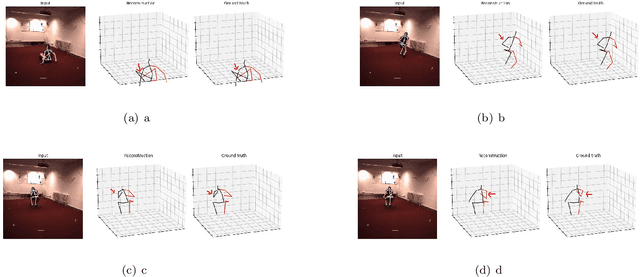

Recently, fully-transformer architectures have replaced the defacto convolutional architecture for the 3D human pose estimation task. In this paper we propose \textbf{\textit{ConvFormer}}, a novel convolutional transformer that leverages a new \textbf{\textit{dynamic multi-headed convolutional self-attention}} mechanism for monocular 3D human pose estimation. We designed a spatial and temporal convolutional transformer to comprehensively model human joint relations within individual frames and globally across the motion sequence. Moreover, we introduce a novel notion of \textbf{\textit{temporal joints profile}} for our temporal ConvFormer that fuses complete temporal information immediately for a local neighborhood of joint features. We have quantitatively and qualitatively validated our method on three common benchmark datasets: Human3.6M, MPI-INF-3DHP, and HumanEva. Extensive experiments have been conducted to identify the optimal hyper-parameter set. These experiments demonstrated that we achieved a \textbf{significant parameter reduction relative to prior transformer models} while attaining State-of-the-Art (SOTA) or near SOTA on all three datasets. Additionally, we achieved SOTA for Protocol III on H36M for both GT and CPN detection inputs. Finally, we obtained SOTA on all three metrics for the MPI-INF-3DHP dataset and for all three subjects on HumanEva under Protocol II.