 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Deep Dynamics Models for Autonomous Vehicles with Multimodal Latent Mapping of Surfaces
Mar 21, 2023
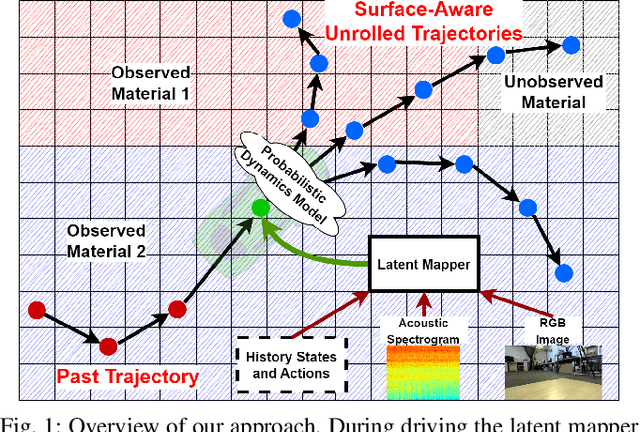
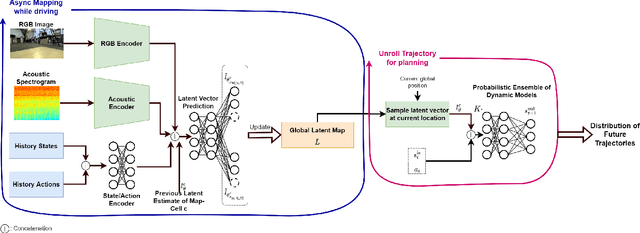

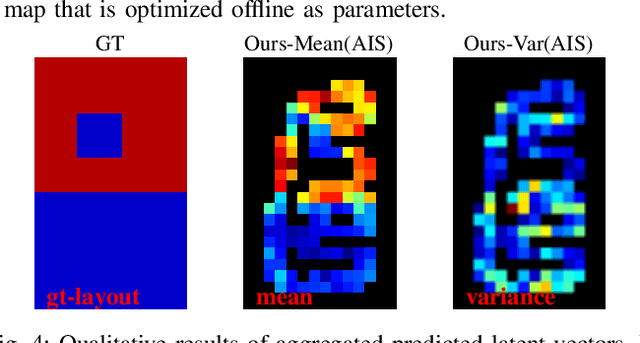
The safe deployment of autonomous vehicles relies on their ability to effectively react to environmental changes. This can require maneuvering on varying surfaces which is still a difficult problem, especially for slippery terrains. To address this issue we propose a new approach that learns a surface-aware dynamics model by conditioning it on a latent variable vector storing surface information about the current location. A latent mapper is trained to update these latent variables during inference from multiple modalities on every traversal of the corresponding locations and stores them in a map. By training everything end-to-end with the loss of the dynamics model, we enforce the latent mapper to learn an update rule for the latent map that is useful for the subsequent dynamics model. We implement and evaluate our approach on a real miniature electric car. The results show that the latent map is updated to allow more accurate predictions of the dynamics model compared to a model without this information. We further show that by using this model, the driving performance can be improved on varying and challenging surfaces.
Co-Occurrence Matters: Learning Action Relation for Temporal Action Localization
Mar 15, 2023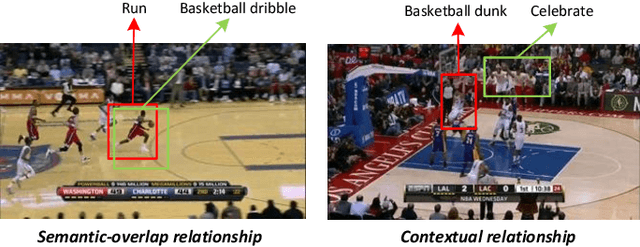
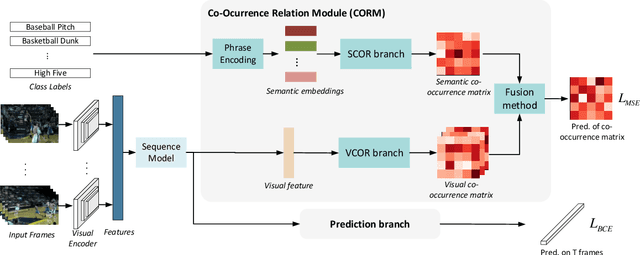
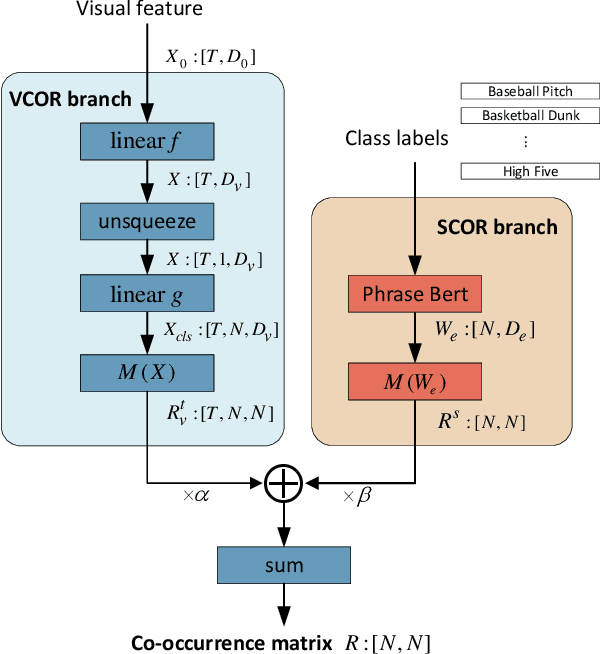
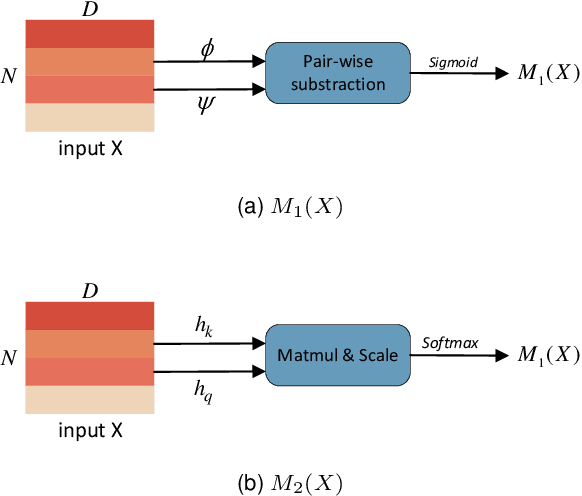
Temporal action localization (TAL) is a prevailing task due to its great application potential. Existing works in this field mainly suffer from two weaknesses: (1) They often neglect the multi-label case and only focus on temporal modeling. (2) They ignore the semantic information in class labels and only use the visual information. To solve these problems, we propose a novel Co-Occurrence Relation Module (CORM) that explicitly models the co-occurrence relationship between actions. Besides the visual information, it further utilizes the semantic embeddings of class labels to model the co-occurrence relationship. The CORM works in a plug-and-play manner and can be easily incorporated with the existing sequence models. By considering both visual and semantic co-occurrence, our method achieves high multi-label relationship modeling capacity. Meanwhile, existing datasets in TAL always focus on low-semantic atomic actions. Thus we construct a challenging multi-label dataset UCF-Crime-TAL that focuses on high-semantic actions by annotating the UCF-Crime dataset at frame level and considering the semantic overlap of different events. Extensive experiments on two commonly used TAL datasets, \textit{i.e.}, MultiTHUMOS and TSU, and our newly proposed UCF-Crime-TAL demenstrate the effectiveness of the proposed CORM, which achieves state-of-the-art performance on these datasets.
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
Mar 15, 2023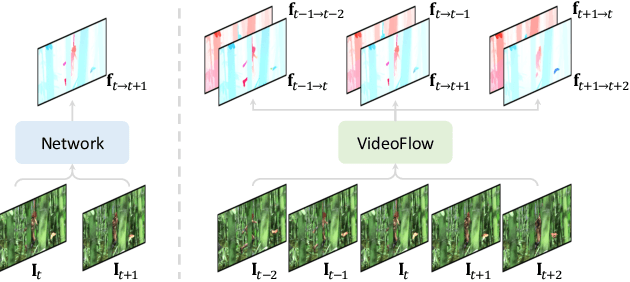
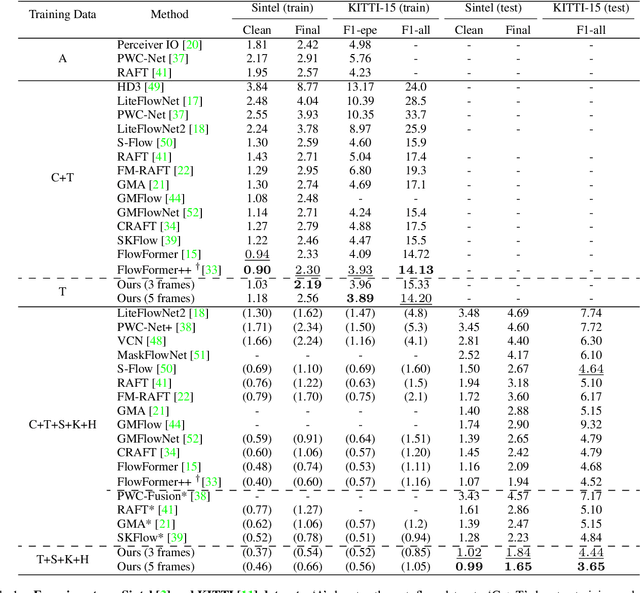
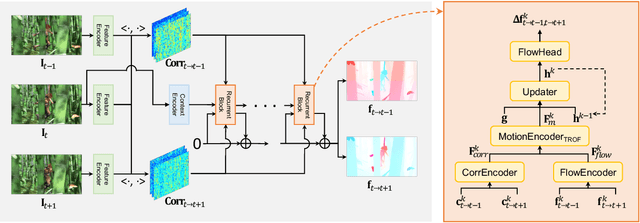
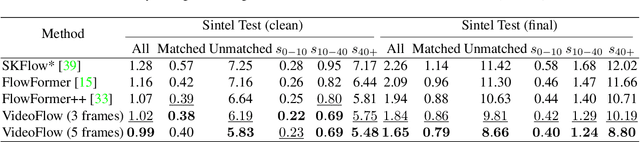
We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best published result (4.52% from FlowFormer++).
Imbalance Knowledge-Driven Multi-modal Network for Land-Cover Semantic Segmentation Using Images and LiDAR Point Clouds
Mar 28, 2023

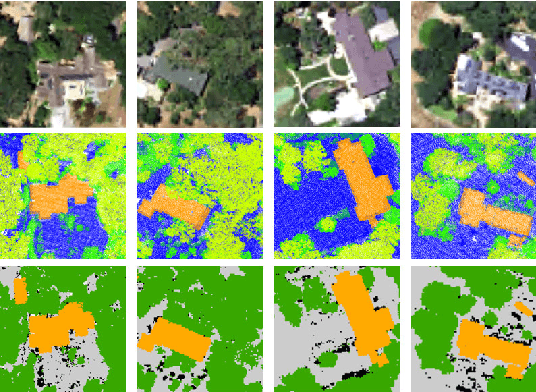
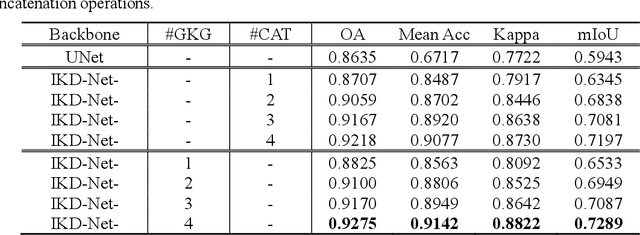
Despite the good results that have been achieved in unimodal segmentation, the inherent limitations of individual data increase the difficulty of achieving breakthroughs in performance. For that reason, multi-modal learning is increasingly being explored within the field of remote sensing. The present multi-modal methods usually map high-dimensional features to low-dimensional spaces as a preprocess before feature extraction to address the nonnegligible domain gap, which inevitably leads to information loss. To address this issue, in this paper we present our novel Imbalance Knowledge-Driven Multi-modal Network (IKD-Net) to extract features from raw multi-modal heterogeneous data directly. IKD-Net is capable of mining imbalance information across modalities while utilizing a strong modal to drive the feature map refinement of the weaker ones in the global and categorical perspectives by way of two sophisticated plug-and-play modules: the Global Knowledge-Guided (GKG) and Class Knowledge-Guided (CKG) gated modules. The whole network then is optimized using a holistic loss function. While we were developing IKD-Net, we also established a new dataset called the National Agriculture Imagery Program and 3D Elevation Program Combined dataset in California (N3C-California), which provides a particular benchmark for multi-modal joint segmentation tasks. In our experiments, IKD-Net outperformed the benchmarks and state-of-the-art methods both in the N3C-California and the small-scale ISPRS Vaihingen dataset. IKD-Net has been ranked first on the real-time leaderboard for the GRSS DFC 2018 challenge evaluation until this paper's submission.
A-MuSIC: An Adaptive Ensemble System For Visual Place Recognition In Changing Environments
Mar 24, 2023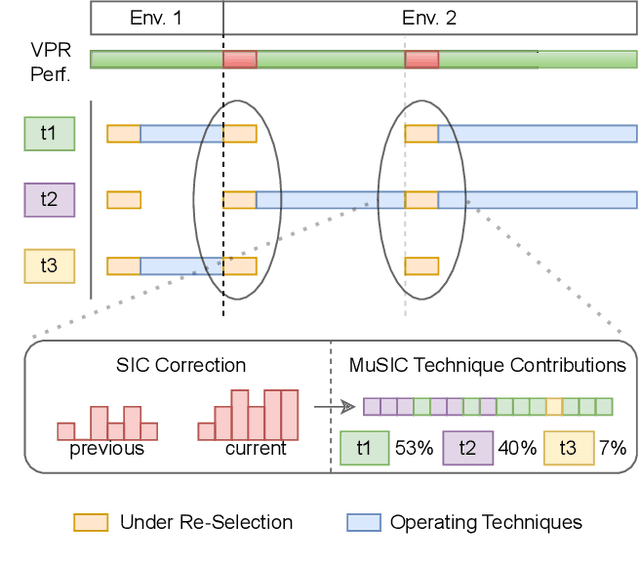
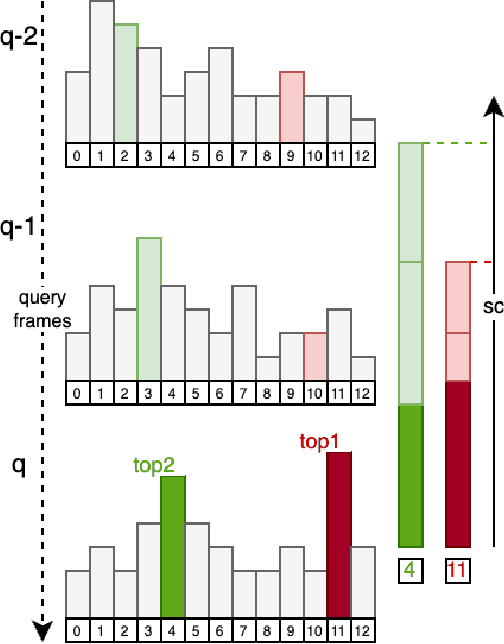
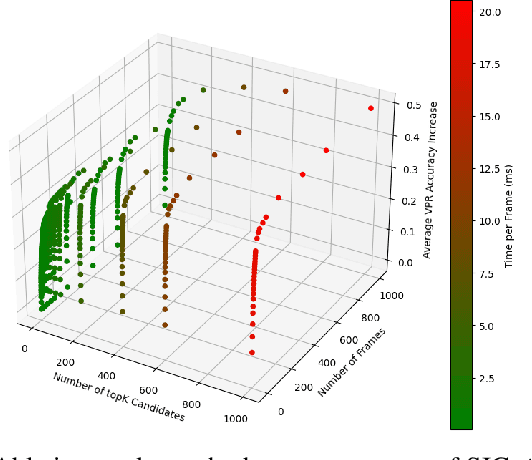
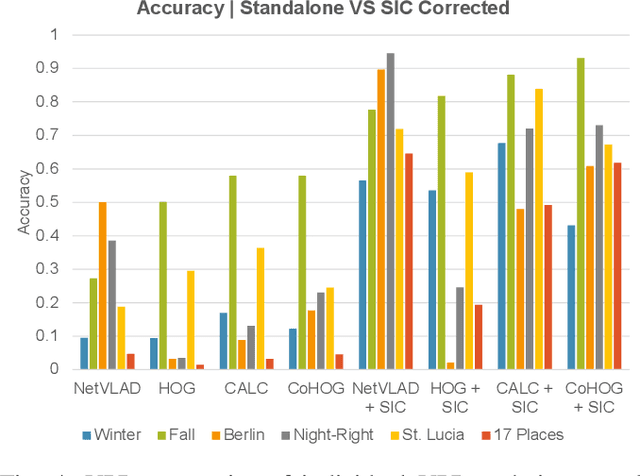
Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance under different illumination throughout the day, with seasonal weather and when observed from different viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings. As a result, VPR systems combining multiple techniques achieve more reliable VPR performance in changing environments, at the cost of higher computational loads. Addressing this shortcoming, we propose an adaptive VPR system dubbed Adaptive Multi-Self Identification and Correction (A-MuSIC). We start by developing a method to collect information of the runtime performance of a VPR technique by analysing the frame-to-frame continuity of matched queries. We then demonstrate how to operate the method on a static ensemble of techniques, generating data on which techniques are contributing the most for the current environment. A-MuSIC uses the collected information to both select a minimal subset of techniques and to decide when a re-selection is required during navigation. A-MuSIC matches or beats state-of-the-art VPR performance across all tested benchmark datasets while maintaining its computational load on par with individual techniques.
Training Language Models with Language Feedback at Scale
Apr 09, 2023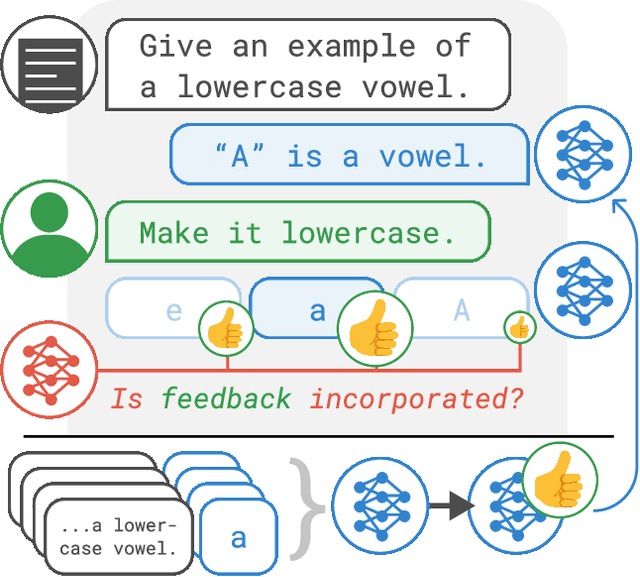


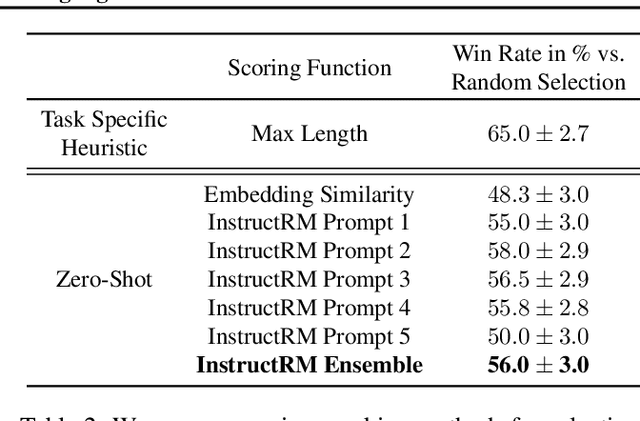
Pretrained language models often generate outputs that are not in line with human preferences, such as harmful text or factually incorrect summaries. Recent work approaches the above issues by learning from a simple form of human feedback: comparisons between pairs of model-generated outputs. However, comparison feedback only conveys limited information about human preferences. In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback. ILF consists of three steps that are applied iteratively: first, conditioning the language model on the input, an initial LM output, and feedback to generate refinements. Second, selecting the refinement incorporating the most feedback. Third, finetuning the language model to maximize the likelihood of the chosen refinement given the input. We show theoretically that ILF can be viewed as Bayesian Inference, similar to Reinforcement Learning from human feedback. We evaluate ILF's effectiveness on a carefully-controlled toy task and a realistic summarization task. Our experiments demonstrate that large language models accurately incorporate feedback and that finetuning with ILF scales well with the dataset size, even outperforming finetuning on human summaries. Learning from both language and comparison feedback outperforms learning from each alone, achieving human-level summarization performance.
HumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation
Apr 09, 2023
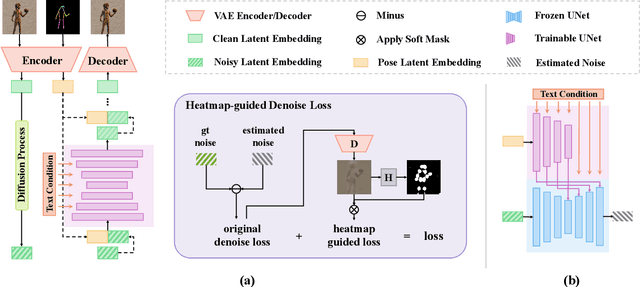
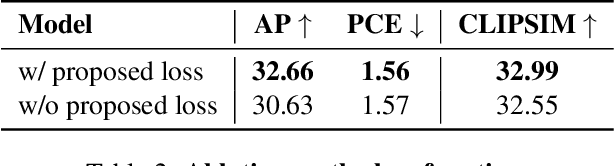
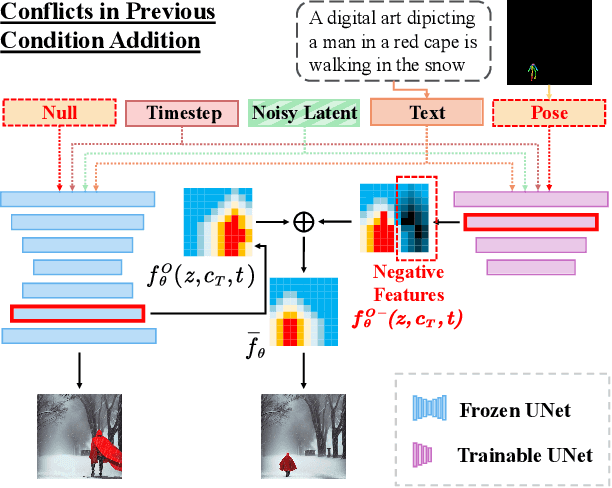
Controllable human image generation (HIG) has numerous real-life applications. State-of-the-art solutions, such as ControlNet and T2I-Adapter, introduce an additional learnable branch on top of the frozen pre-trained stable diffusion (SD) model, which can enforce various conditions, including skeleton guidance of HIG. While such a plug-and-play approach is appealing, the inevitable and uncertain conflicts between the original images produced from the frozen SD branch and the given condition incur significant challenges for the learnable branch, which essentially conducts image feature editing for condition enforcement. In this work, we propose a native skeleton-guided diffusion model for controllable HIG called HumanSD. Instead of performing image editing with dual-branch diffusion, we fine-tune the original SD model using a novel heatmap-guided denoising loss. This strategy effectively and efficiently strengthens the given skeleton condition during model training while mitigating the catastrophic forgetting effects. HumanSD is fine-tuned on the assembly of three large-scale human-centric datasets with text-image-pose information, two of which are established in this work. As shown in Figure 1, HumanSD outperforms ControlNet in terms of accurate pose control and image quality, particularly when the given skeleton guidance is sophisticated.
$\text{DC}^2$: Dual-Camera Defocus Control by Learning to Refocus
Apr 06, 2023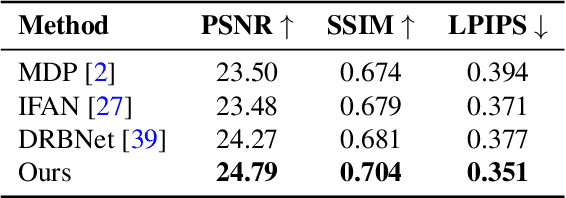
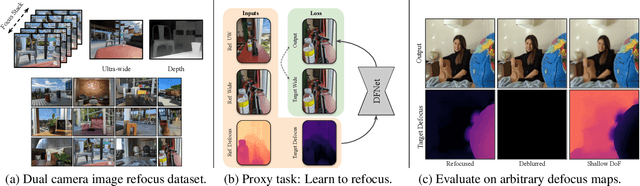
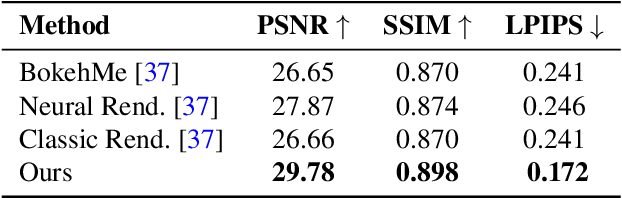
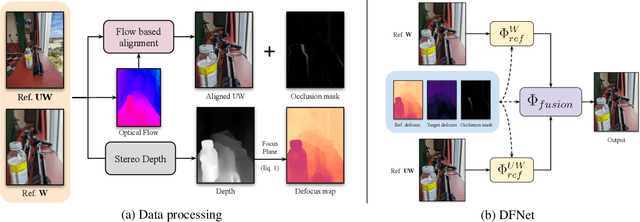
Smartphone cameras today are increasingly approaching the versatility and quality of professional cameras through a combination of hardware and software advancements. However, fixed aperture remains a key limitation, preventing users from controlling the depth of field (DoF) of captured images. At the same time, many smartphones now have multiple cameras with different fixed apertures -- specifically, an ultra-wide camera with wider field of view and deeper DoF and a higher resolution primary camera with shallower DoF. In this work, we propose $\text{DC}^2$, a system for defocus control for synthetically varying camera aperture, focus distance and arbitrary defocus effects by fusing information from such a dual-camera system. Our key insight is to leverage real-world smartphone camera dataset by using image refocus as a proxy task for learning to control defocus. Quantitative and qualitative evaluations on real-world data demonstrate our system's efficacy where we outperform state-of-the-art on defocus deblurring, bokeh rendering, and image refocus. Finally, we demonstrate creative post-capture defocus control enabled by our method, including tilt-shift and content-based defocus effects.
Robust Calibrate Proxy Loss for Deep Metric Learning
Apr 06, 2023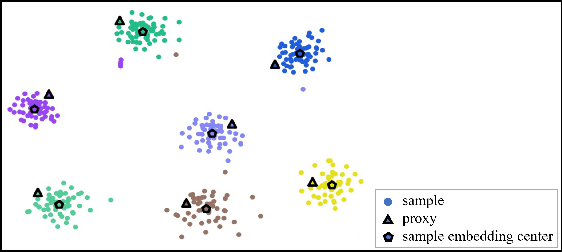
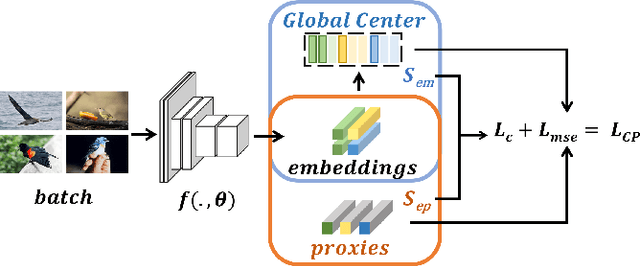
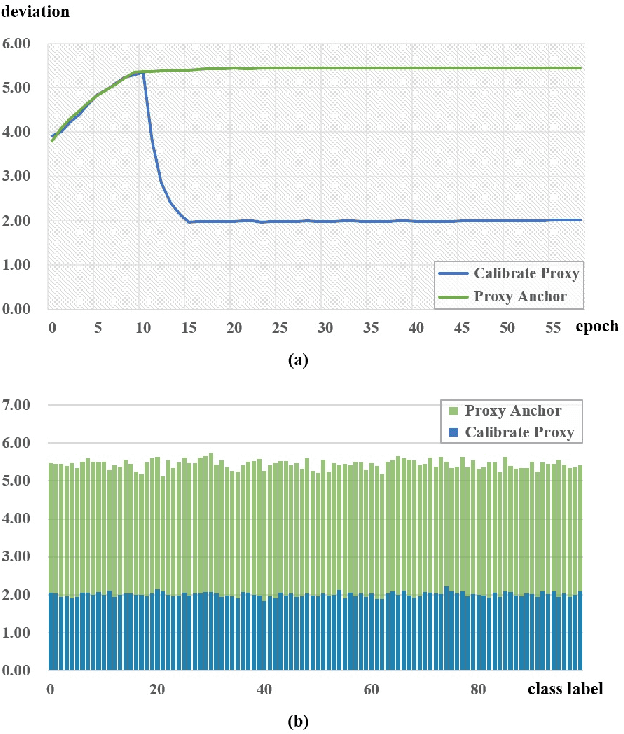
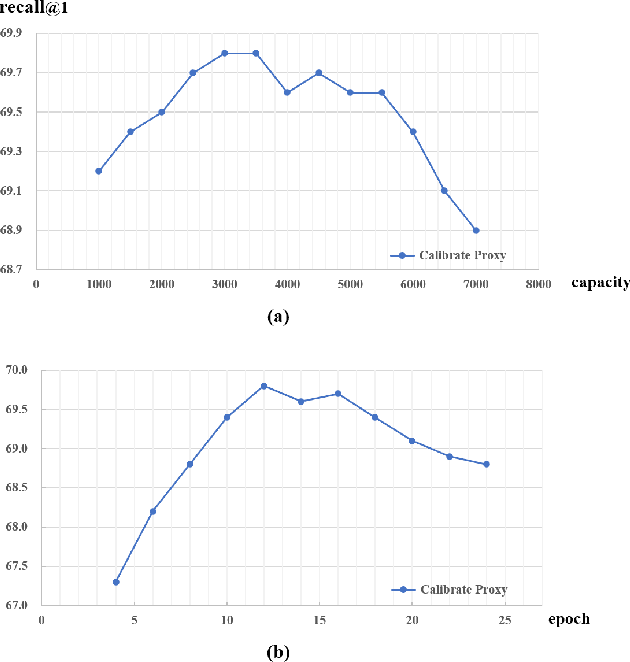
The mainstream researche in deep metric learning can be divided into two genres: proxy-based and pair-based methods. Proxy-based methods have attracted extensive attention due to the lower training complexity and fast network convergence. However, these methods have limitations as the poxy optimization is done by network, which makes it challenging for the proxy to accurately represent the feature distrubtion of the real class of data. In this paper, we propose a Calibrate Proxy (CP) structure, which uses the real sample information to improve the similarity calculation in proxy-based loss and introduces a calibration loss to constraint the proxy optimization towards the center of the class features. At the same time, we set a small number of proxies for each class to alleviate the impact of intra-class differences on retrieval performance. The effectiveness of our method is evaluated by extensive experiments on three public datasets and multiple synthetic label-noise datasets. The results show that our approach can effectively improve the performance of commonly used proxy-based losses on both regular and noisy datasets.
TBDetector:Transformer-Based Detector for Advanced Persistent Threats with Provenance Graph
Apr 06, 2023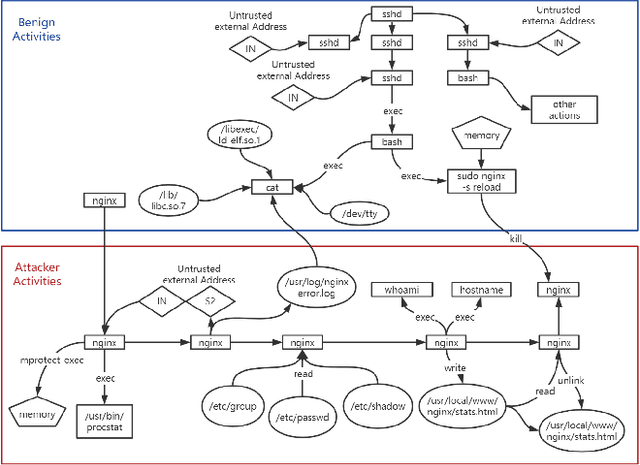
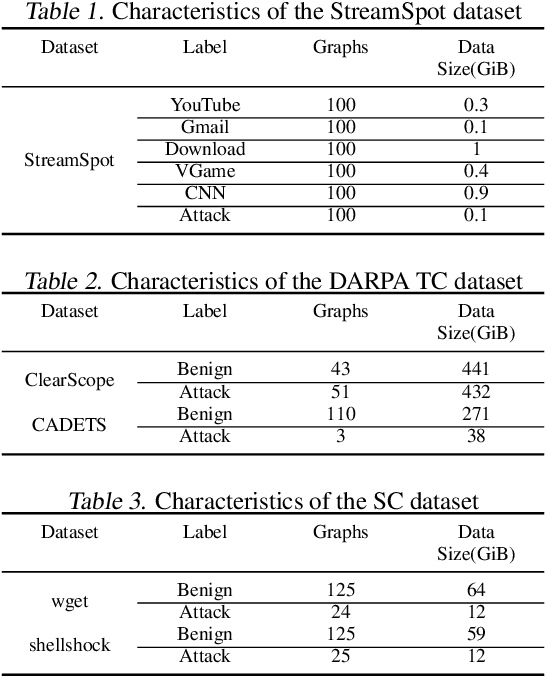
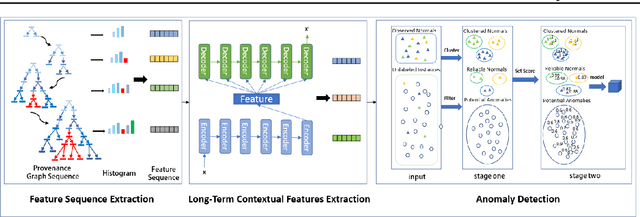
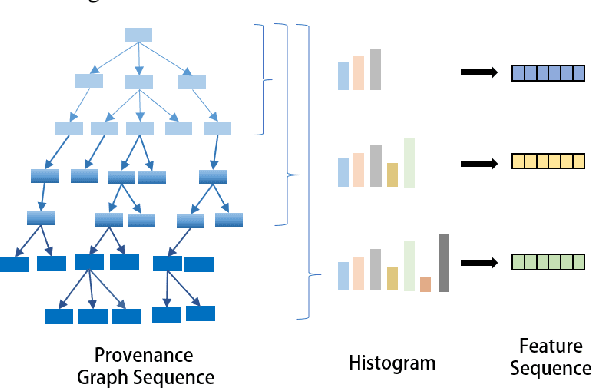
APT detection is difficult to detect due to the long-term latency, covert and slow multistage attack patterns of Advanced Persistent Threat (APT). To tackle these issues, we propose TBDetector, a transformer-based advanced persistent threat detection method for APT attack detection. Considering that provenance graphs provide rich historical information and have the powerful attacks historic correlation ability to identify anomalous activities, TBDetector employs provenance analysis for APT detection, which summarizes long-running system execution with space efficiency and utilizes transformer with self-attention based encoder-decoder to extract long-term contextual features of system states to detect slow-acting attacks. Furthermore, we further introduce anomaly scores to investigate the anomaly of different system states, where each state is calculated with an anomaly score corresponding to its similarity score and isolation score. To evaluate the effectiveness of the proposed method, we have conducted experiments on five public datasets, i.e., streamspot, cadets, shellshock, clearscope, and wget_baseline. Experimental results and comparisons with state-of-the-art methods have exhibited better performance of our proposed method.