 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PEOPL: Characterizing Privately Encoded Open Datasets with Public Labels
Mar 31, 2023
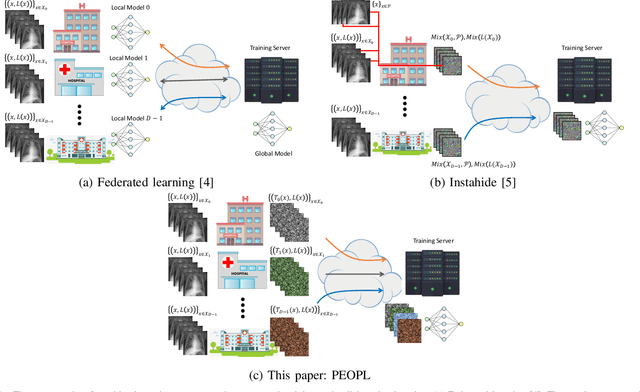
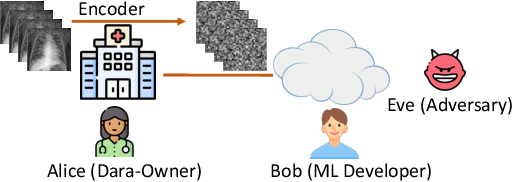
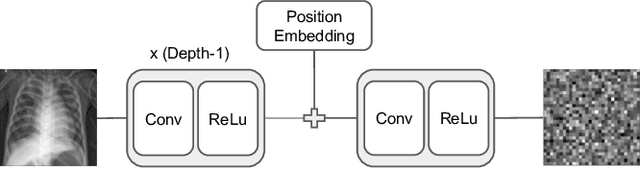

Allowing organizations to share their data for training of machine learning (ML) models without unintended information leakage is an open problem in practice. A promising technique for this still-open problem is to train models on the encoded data. Our approach, called Privately Encoded Open Datasets with Public Labels (PEOPL), uses a certain class of randomly constructed transforms to encode sensitive data. Organizations publish their randomly encoded data and associated raw labels for ML training, where training is done without knowledge of the encoding realization. We investigate several important aspects of this problem: We introduce information-theoretic scores for privacy and utility, which quantify the average performance of an unfaithful user (e.g., adversary) and a faithful user (e.g., model developer) that have access to the published encoded data. We then theoretically characterize primitives in building families of encoding schemes that motivate the use of random deep neural networks. Empirically, we compare the performance of our randomized encoding scheme and a linear scheme to a suite of computational attacks, and we also show that our scheme achieves competitive prediction accuracy to raw-sample baselines. Moreover, we demonstrate that multiple institutions, using independent random encoders, can collaborate to train improved ML models.
Medical Image Analysis using Deep Relational Learning
Mar 28, 2023
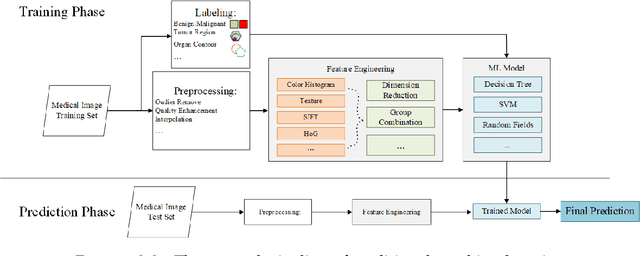
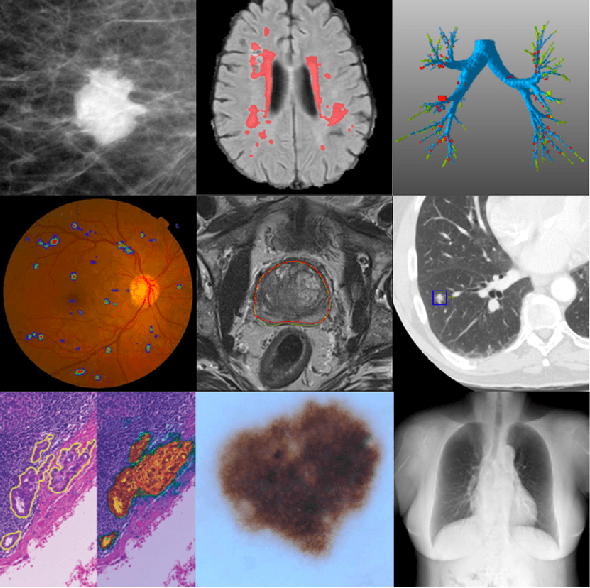
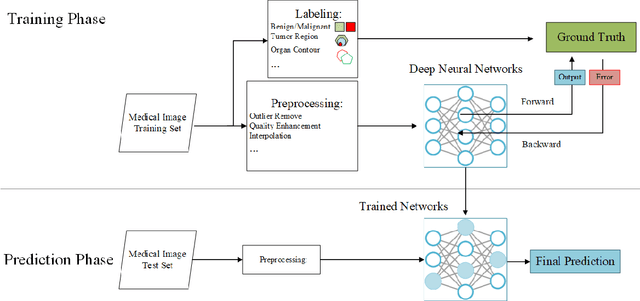
In the past ten years, with the help of deep learning, especially the rapid development of deep neural networks, medical image analysis has made remarkable progress. However, how to effectively use the relational information between various tissues or organs in medical images is still a very challenging problem, and it has not been fully studied. In this thesis, we propose two novel solutions to this problem based on deep relational learning. First, we propose a context-aware fully convolutional network that effectively models implicit relation information between features to perform medical image segmentation. The network achieves the state-of-the-art segmentation results on the Multi Modal Brain Tumor Segmentation 2017 (BraTS2017) and Multi Modal Brain Tumor Segmentation 2018 (BraTS2018) data sets. Subsequently, we propose a new hierarchical homography estimation network to achieve accurate medical image mosaicing by learning the explicit spatial relationship between adjacent frames. We use the UCL Fetoscopy Placenta dataset to conduct experiments and our hierarchical homography estimation network outperforms the other state-of-the-art mosaicing methods while generating robust and meaningful mosaicing result on unseen frames.
Sejarah dan Perkembangan Teknik Natural Language Processing (NLP) Bahasa Indonesia: Tinjauan tentang sejarah, perkembangan teknologi, dan aplikasi NLP dalam bahasa Indonesia
Mar 28, 2023

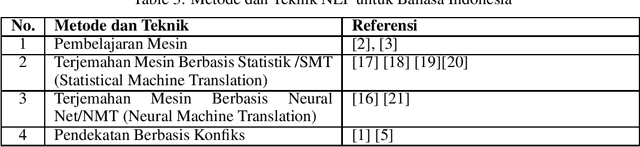
This study provides an overview of the history of the development of Natural Language Processing (NLP) in the context of the Indonesian language, with a focus on the basic technologies, methods, and practical applications that have been developed. This review covers developments in basic NLP technologies such as stemming, part-of-speech tagging, and related methods; practical applications in cross-language information retrieval systems, information extraction, and sentiment analysis; and methods and techniques used in Indonesian language NLP research, such as machine learning, statistics-based machine translation, and conflict-based approaches. This study also explores the application of NLP in Indonesian language industry and research and identifies challenges and opportunities in Indonesian language NLP research and development. Recommendations for future Indonesian language NLP research and development include developing more efficient methods and technologies, expanding NLP applications, increasing sustainability, further research into the potential of NLP, and promoting interdisciplinary collaboration. It is hoped that this review will help researchers, practitioners, and the government to understand the development of Indonesian language NLP and identify opportunities for further research and development.
Predicting quantum chemical property with easy-to-obtain geometry via positional denoising
Mar 28, 2023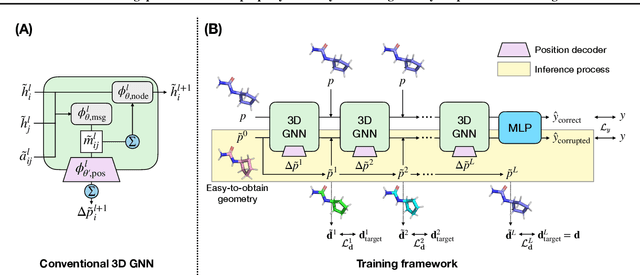
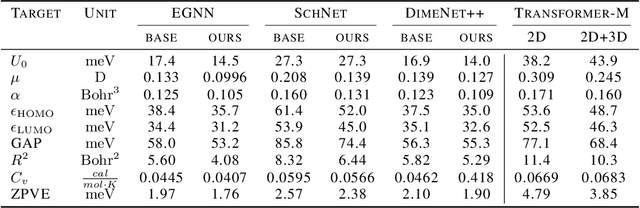
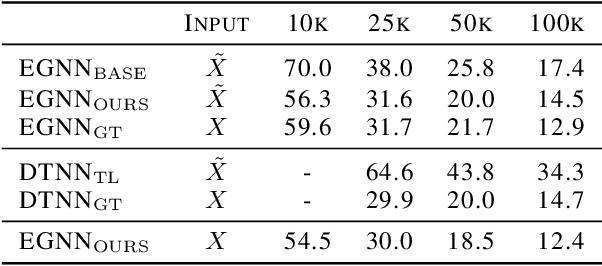
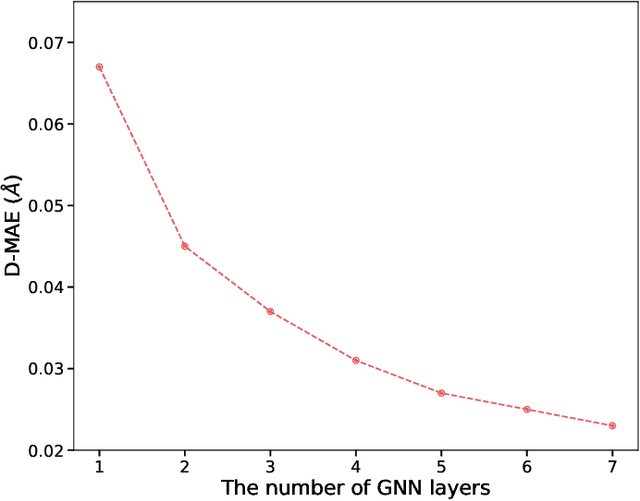
As quantum chemical properties have a significant dependence on their geometries, graph neural networks (GNNs) using 3D geometric information have achieved high prediction accuracy in many tasks. However, they often require 3D geometries obtained from high-level quantum mechanical calculations, which are practically infeasible, limiting their applicability in real-world problems. To tackle this, we propose a method to accurately predict the properties with relatively easy-to-obtain geometries (e.g., optimized geometries from the molecular force field). In this method, the input geometry, regarded as the corrupted geometry of the correct one, gradually approaches the correct one as it passes through the stacked denoising layers. We investigated the performance of the proposed method using 3D message-passing architectures for two prediction tasks: molecular properties and chemical reaction property. The reduction of positional errors through the denoising process contributed to performance improvement by increasing the mutual information between the correct and corrupted geometries. Moreover, our analysis of the correlation between denoising power and predictive accuracy demonstrates the effectiveness of the denoising process.
De-novo Identification of Small Molecules from Their GC-EI-MS Spectra
Apr 04, 2023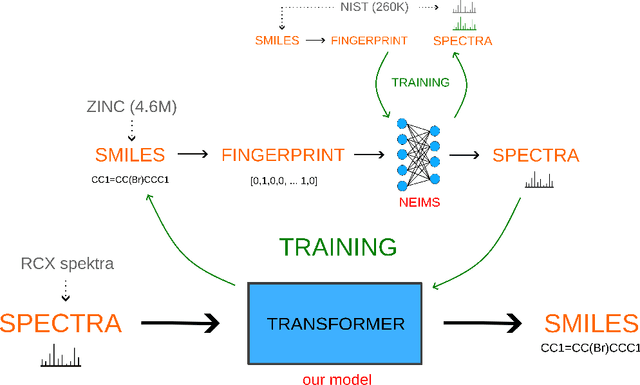
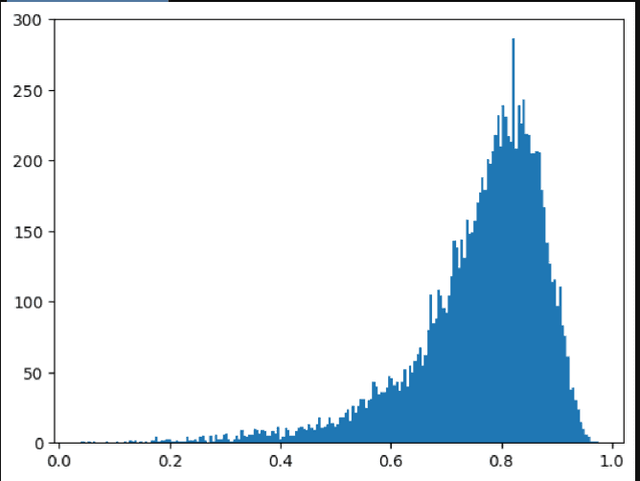
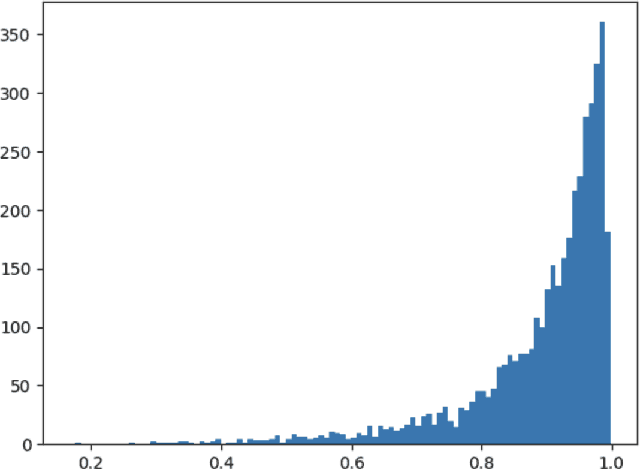
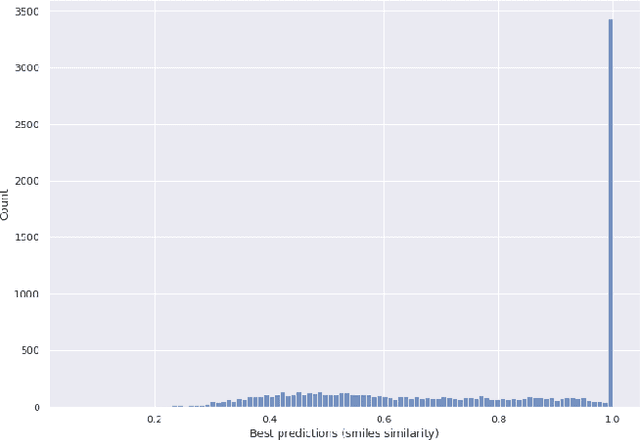
Identification of experimentally acquired mass spectra of unknown compounds presents a~particular challenge because reliable spectral databases do not cover the potential chemical space with sufficient density. Therefore machine learning based \emph{de-novo} methods, which derive molecular structure directly from its mass spectrum gained attention recently. We present a~novel method in this family, addressing a~specific usecase of GC-EI-MS spectra, which is particularly hard due to lack of additional information from the first stage of MS/MS experiments, on which the previously published methods rely. We analyze strengths and drawbacks or our approach and discuss future directions.
High Dynamic Range Imaging with Context-aware Transformer
Apr 17, 2023
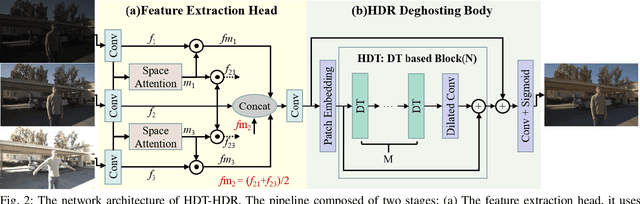
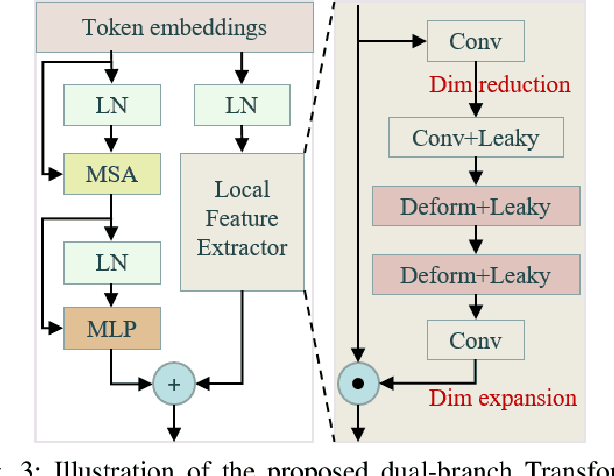

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
Collaborative Residual Metric Learning
Apr 17, 2023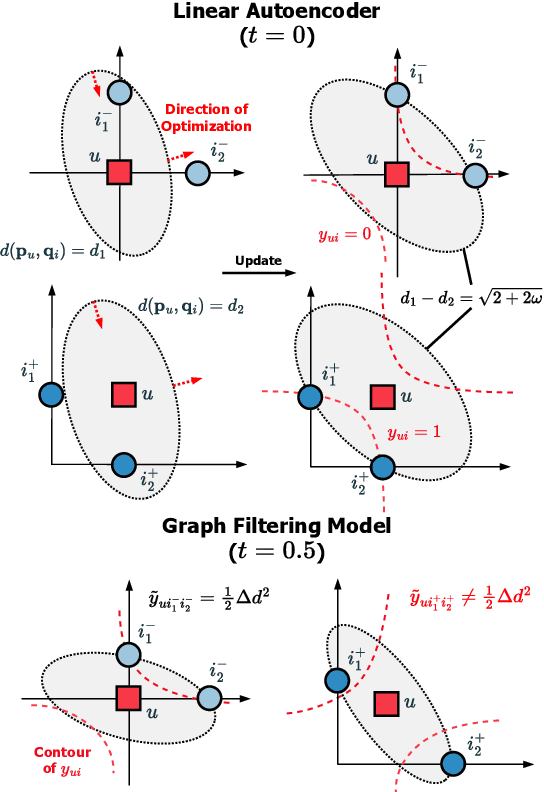
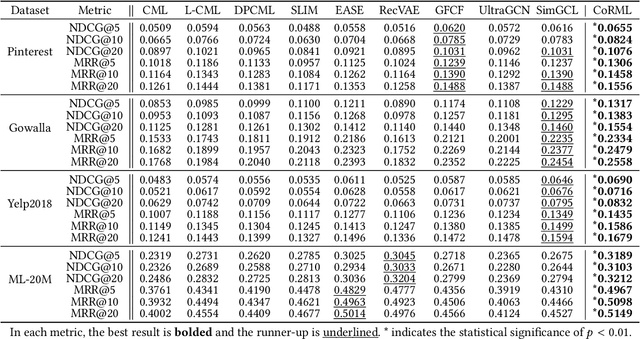
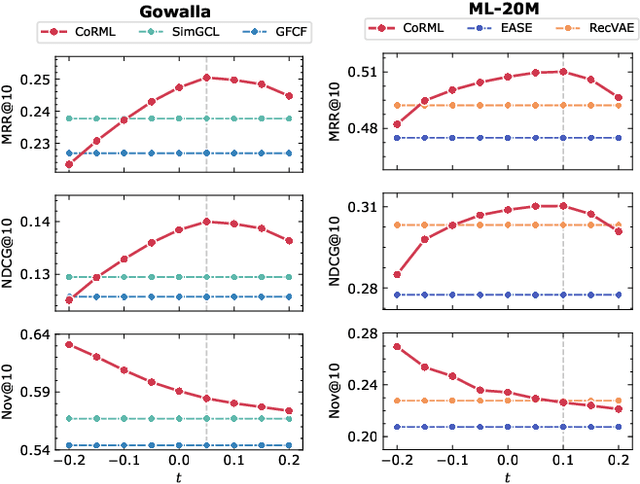
In collaborative filtering, distance metric learning has been applied to matrix factorization techniques with promising results. However, matrix factorization lacks the ability of capturing collaborative information, which has been remarked by recent works and improved by interpreting user interactions as signals. This paper aims to find out how metric learning connect to these signal-based models. By adopting a generalized distance metric, we discovered that in signal-based models, it is easier to estimate the residual of distances, which refers to the difference between the distances from a user to a target item and another item, rather than estimating the distances themselves. Further analysis also uncovers a link between the normalization strength of interaction signals and the novelty of recommendation, which has been overlooked by existing studies. Based on the above findings, we propose a novel model to learn a generalized distance user-item distance metric to capture user preference in interaction signals by modeling the residuals of distance. The proposed CoRML model is then further improved in training efficiency by a newly introduced approximated ranking weight. Extensive experiments conducted on 4 public datasets demonstrate the superior performance of CoRML compared to the state-of-the-art baselines in collaborative filtering, along with high efficiency and the ability of providing novelty-promoted recommendations, shedding new light on the study of metric learning-based recommender systems.
Political corpus creation through automatic speech recognition on EU debates
Apr 17, 2023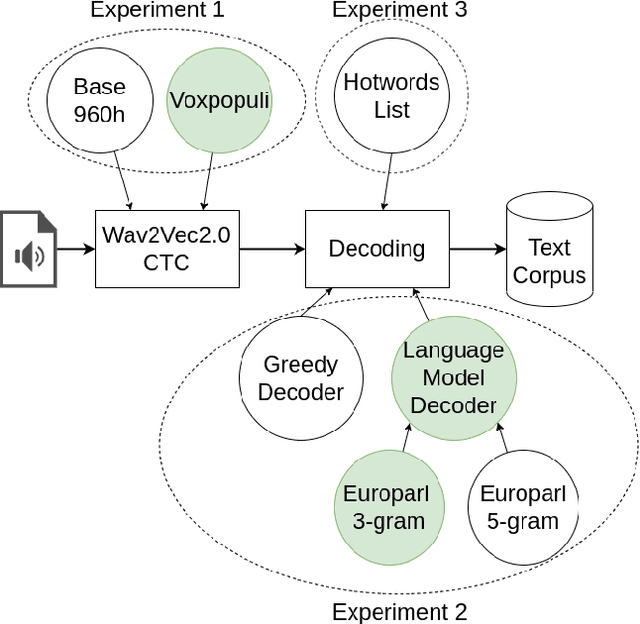

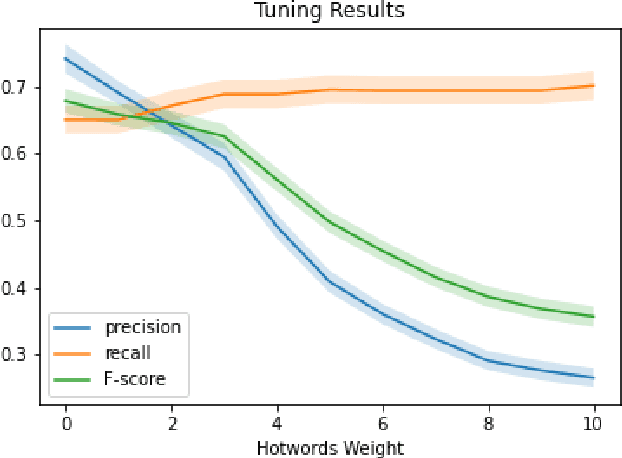
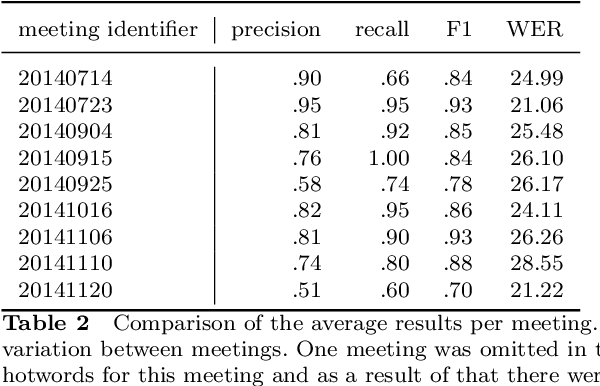
In this paper, we present a transcribed corpus of the LIBE committee of the EU parliament, totalling 3.6 Million running words. The meetings of parliamentary committees of the EU are a potentially valuable source of information for political scientists but the data is not readily available because only disclosed as speech recordings together with limited metadata. The meetings are in English, partly spoken by non-native speakers, and partly spoken by interpreters. We investigated the most appropriate Automatic Speech Recognition (ASR) model to create an accurate text transcription of the audio recordings of the meetings in order to make their content available for research and analysis. We focused on the unsupervised domain adaptation of the ASR pipeline. Building on the transformer-based Wav2vec2.0 model, we experimented with multiple acoustic models, language models and the addition of domain-specific terms. We found that a domain-specific acoustic model and a domain-specific language model give substantial improvements to the ASR output, reducing the word error rate (WER) from 28.22 to 17.95. The use of domain-specific terms in the decoding stage did not have a positive effect on the quality of the ASR in terms of WER. Initial topic modelling results indicated that the corpus is useful for downstream analysis tasks. We release the resulting corpus and our analysis pipeline for future research.
Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Models
Apr 17, 2023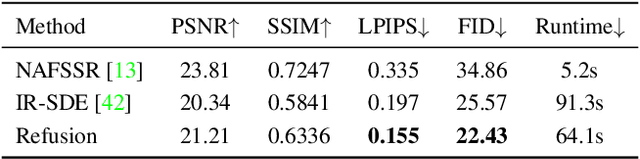
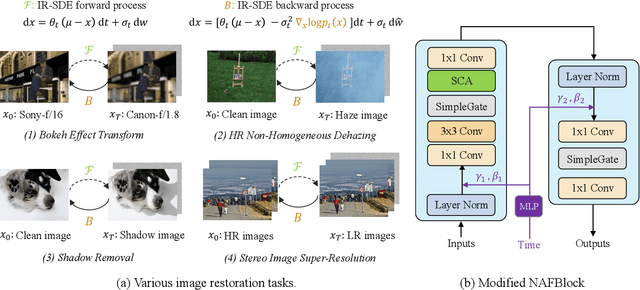
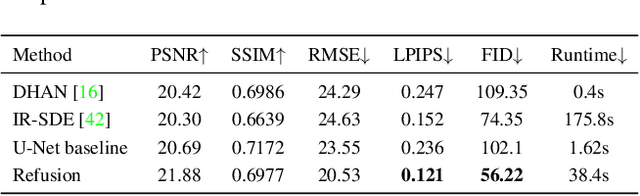
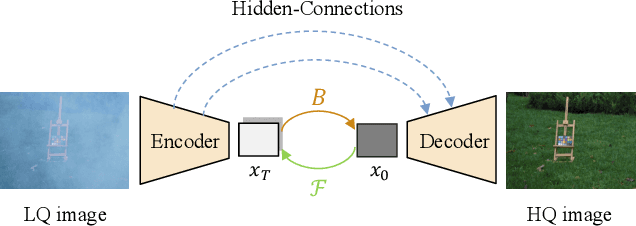
This work aims to improve the applicability of diffusion models in realistic image restoration. Specifically, we enhance the diffusion model in several aspects such as network architecture, noise level, denoising steps, training image size, and optimizer/scheduler. We show that tuning these hyperparameters allows us to achieve better performance on both distortion and perceptual scores. We also propose a U-Net based latent diffusion model which performs diffusion in a low-resolution latent space while preserving high-resolution information from the original input for the decoding process. Compared to the previous latent-diffusion model which trains a VAE-GAN to compress the image, our proposed U-Net compression strategy is significantly more stable and can recover highly accurate images without relying on adversarial optimization. Importantly, these modifications allow us to apply diffusion models to various image restoration tasks, including real-world shadow removal, HR non-homogeneous dehazing, stereo super-resolution, and bokeh effect transformation. By simply replacing the datasets and slightly changing the noise network, our model, named Refusion, is able to deal with large-size images (e.g., 6000 x 4000 x 3 in HR dehazing) and produces good results on all the above restoration problems. Our Refusion achieves the best perceptual performance in the NTIRE 2023 Image Shadow Removal Challenge and wins 2nd place overall.
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020