 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023


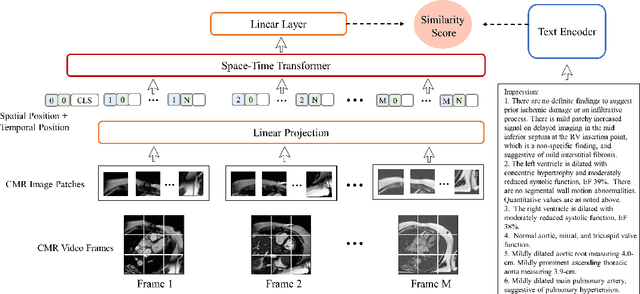
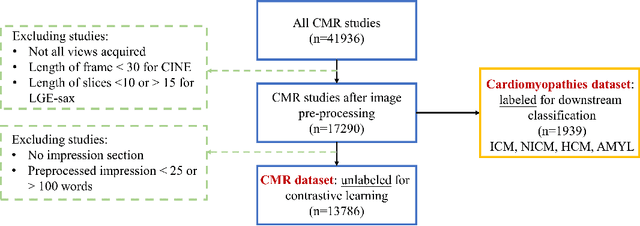
Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
Time-series Anomaly Detection via Contextual Discriminative Contrastive Learning
Apr 16, 2023
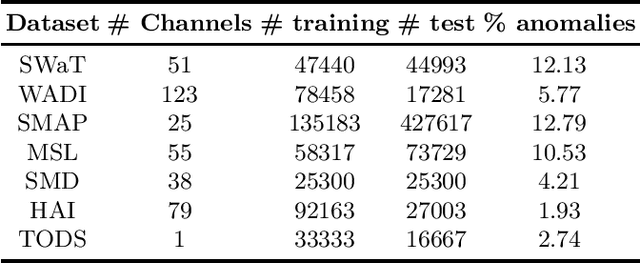
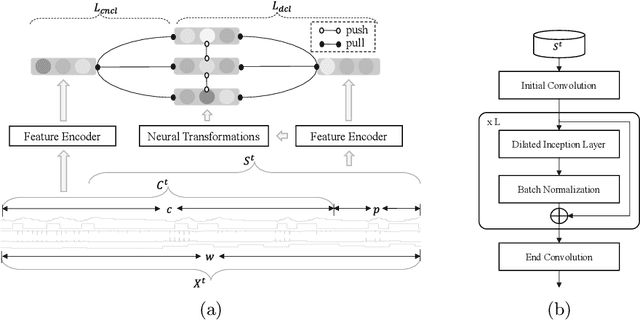
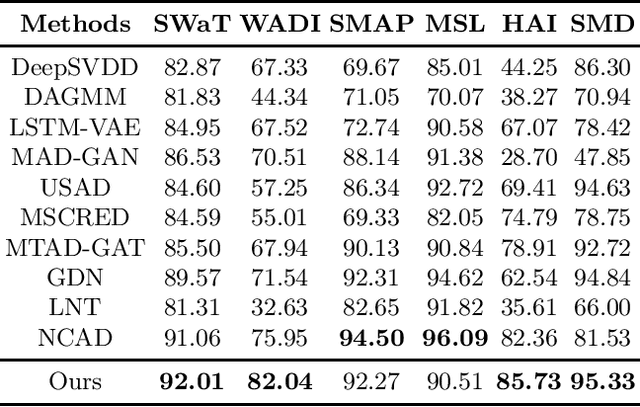
Detecting anomalies in temporal data is challenging due to anomalies being dependent on temporal dynamics. One-class classification methods are commonly used for anomaly detection tasks, but they have limitations when applied to temporal data. In particular, mapping all normal instances into a single hypersphere to capture their global characteristics can lead to poor performance in detecting context-based anomalies where the abnormality is defined with respect to local information. To address this limitation, we propose a novel approach inspired by the loss function of DeepSVDD. Instead of mapping all normal instances into a single hypersphere center, each normal instance is pulled toward a recent context window. However, this approach is prone to a representation collapse issue where the neural network that encodes a given instance and its context is optimized towards a constant encoder solution. To overcome this problem, we combine our approach with a deterministic contrastive loss from Neutral AD, a promising self-supervised learning anomaly detection approach. We provide a theoretical analysis to demonstrate that the incorporation of the deterministic contrastive loss can effectively prevent the occurrence of a constant encoder solution. Experimental results show superior performance of our model over various baselines and model variants on real-world industrial datasets.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 21, 2023


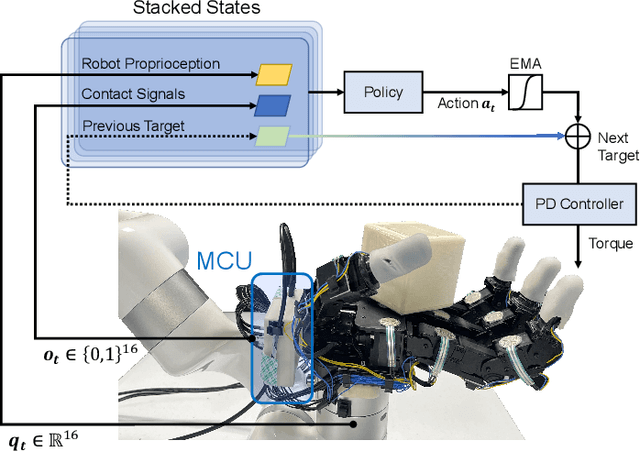
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
Model Robustness Meets Data Privacy: Adversarial Robustness Distillation without Original Data
Mar 21, 2023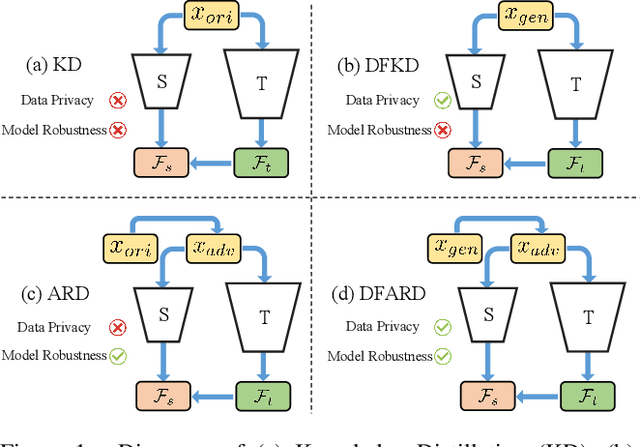


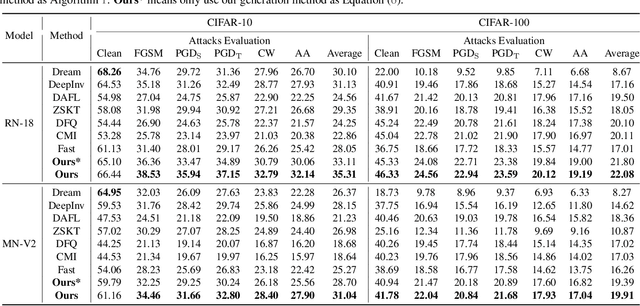
Large-scale deep learning models have achieved great performance based on large-scale datasets. Moreover, the existing Adversarial Training (AT) can further improve the robustness of these large models. However, these large models are difficult to deploy to mobile devices, and the effect of AT on small models is very limited. In addition, the data privacy issue (e.g., face data and diagnosis report) may lead to the original data being unavailable, which relies on data-free knowledge distillation technology for training. To tackle these issues, we propose a challenging novel task called Data-Free Adversarial Robustness Distillation (DFARD), which tries to train small, easily deployable, robust models without relying on the original data. We find the combination of existing techniques resulted in degraded model performance due to fixed training objectives and scarce information content. First, an interactive strategy is designed for more efficient knowledge transfer to find more suitable training objectives at each epoch. Then, we explore an adaptive balance method to suppress information loss and obtain more data information than previous methods. Experiments show that our method improves baseline performance on the novel task.
Self-Paced Neutral Expression-Disentangled Learning for Facial Expression Recognition
Mar 21, 2023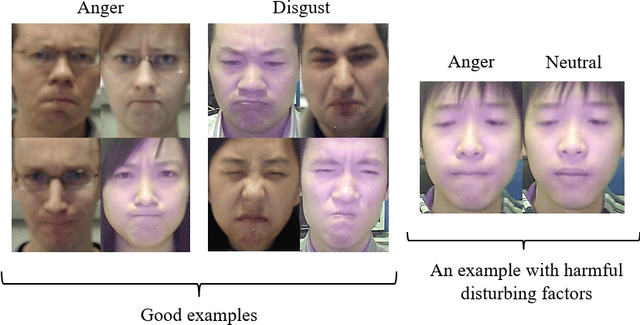
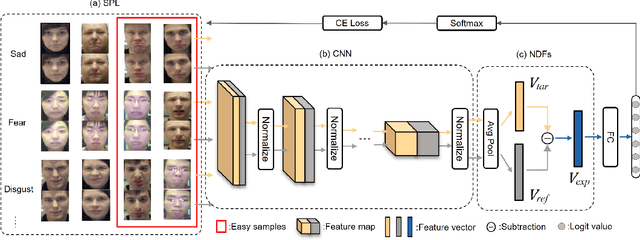
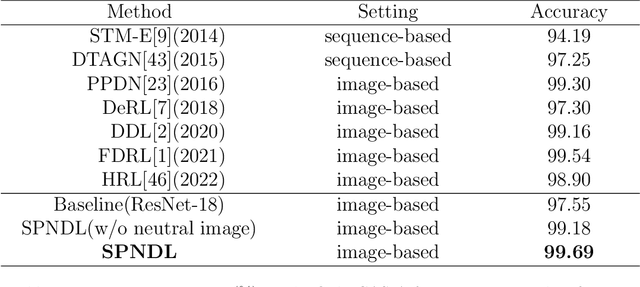
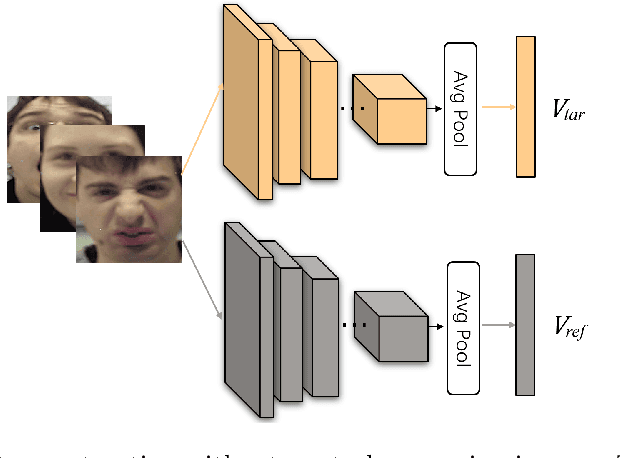
The accuracy of facial expression recognition is typically affected by the following factors: high similarities across different expressions, disturbing factors, and micro-facial movement of rapid and subtle changes. One potentially viable solution for addressing these barriers is to exploit the neutral information concealed in neutral expression images. To this end, in this paper we propose a self-Paced Neutral Expression-Disentangled Learning (SPNDL) model. SPNDL disentangles neutral information from facial expressions, making it easier to extract key and deviation features. Specifically, it allows to capture discriminative information among similar expressions and perceive micro-facial movements. In order to better learn these neutral expression-disentangled features (NDFs) and to alleviate the non-convex optimization problem, a self-paced learning (SPL) strategy based on NDFs is proposed in the training stage. SPL learns samples from easy to complex by increasing the number of samples selected into the training process, which enables to effectively suppress the negative impacts introduced by low-quality samples and inconsistently distributed NDFs. Experiments on three popular databases (i.e., CK+, Oulu-CASIA, and RAF-DB) show the effectiveness of our proposed method.
RoboBEV: Towards Robust Bird's Eye View Perception under Corruptions
Apr 13, 2023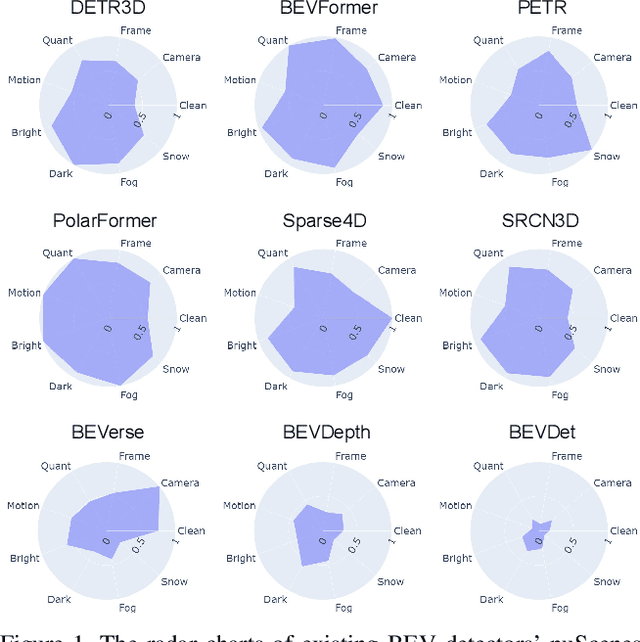
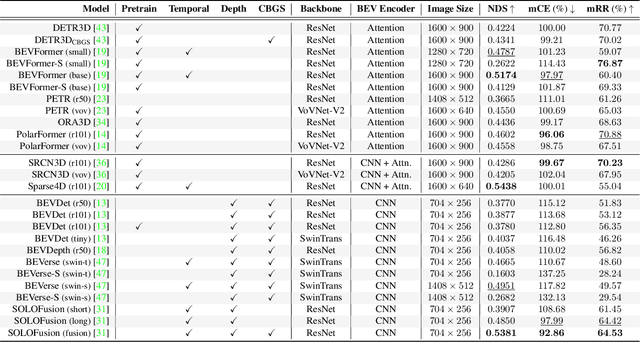

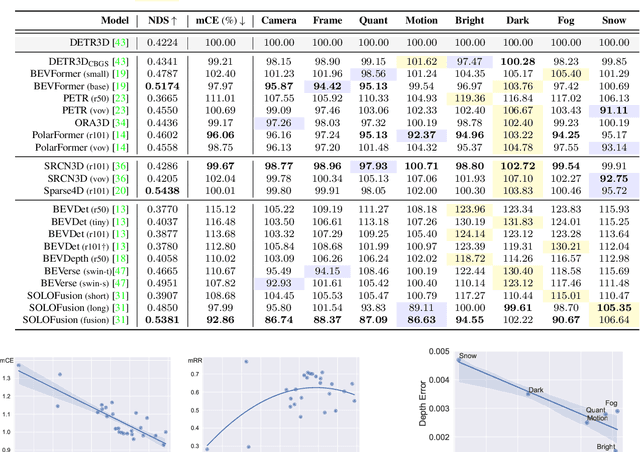
The recent advances in camera-based bird's eye view (BEV) representation exhibit great potential for in-vehicle 3D perception. Despite the substantial progress achieved on standard benchmarks, the robustness of BEV algorithms has not been thoroughly examined, which is critical for safe operations. To bridge this gap, we introduce RoboBEV, a comprehensive benchmark suite that encompasses eight distinct corruptions, including Bright, Dark, Fog, Snow, Motion Blur, Color Quant, Camera Crash, and Frame Lost. Based on it, we undertake extensive evaluations across a wide range of BEV-based models to understand their resilience and reliability. Our findings indicate a strong correlation between absolute performance on in-distribution and out-of-distribution datasets. Nonetheless, there are considerable variations in relative performance across different approaches. Our experiments further demonstrate that pre-training and depth-free BEV transformation has the potential to enhance out-of-distribution robustness. Additionally, utilizing long and rich temporal information largely helps with robustness. Our findings provide valuable insights for designing future BEV models that can achieve both accuracy and robustness in real-world deployments.
Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions
Apr 13, 2023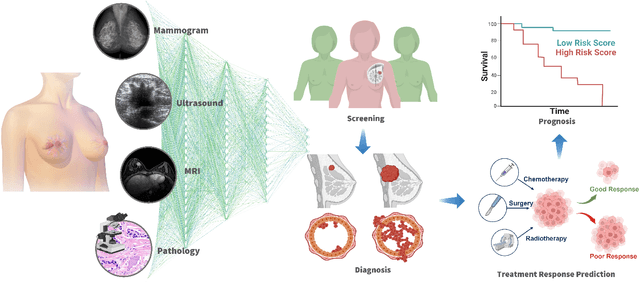
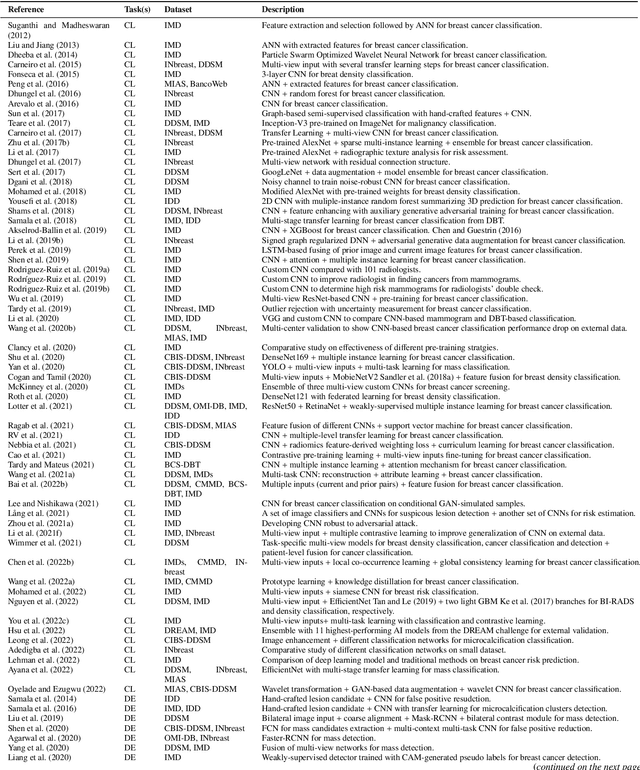
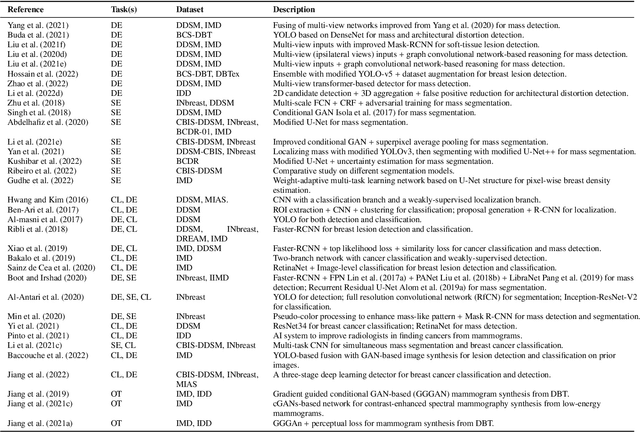
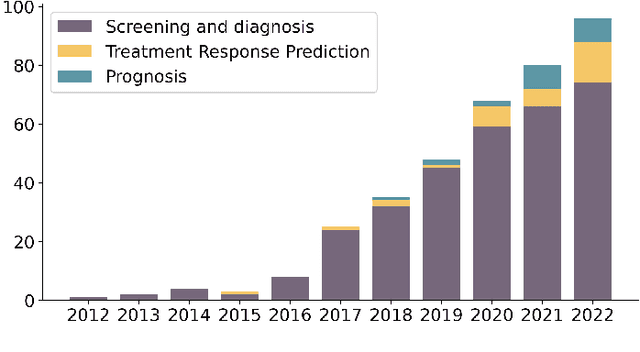
Breast cancer has reached the highest incidence rate worldwide among all malignancies since 2020. Breast imaging plays a significant role in early diagnosis and intervention to improve the outcome of breast cancer patients. In the past decade, deep learning has shown remarkable progress in breast cancer imaging analysis, holding great promise in interpreting the rich information and complex context of breast imaging modalities. Considering the rapid improvement in the deep learning technology and the increasing severity of breast cancer, it is critical to summarize past progress and identify future challenges to be addressed. In this paper, we provide an extensive survey of deep learning-based breast cancer imaging research, covering studies on mammogram, ultrasound, magnetic resonance imaging, and digital pathology images over the past decade. The major deep learning methods, publicly available datasets, and applications on imaging-based screening, diagnosis, treatment response prediction, and prognosis are described in detail. Drawn from the findings of this survey, we present a comprehensive discussion of the challenges and potential avenues for future research in deep learning-based breast cancer imaging.
Priors for symbolic regression
Apr 13, 2023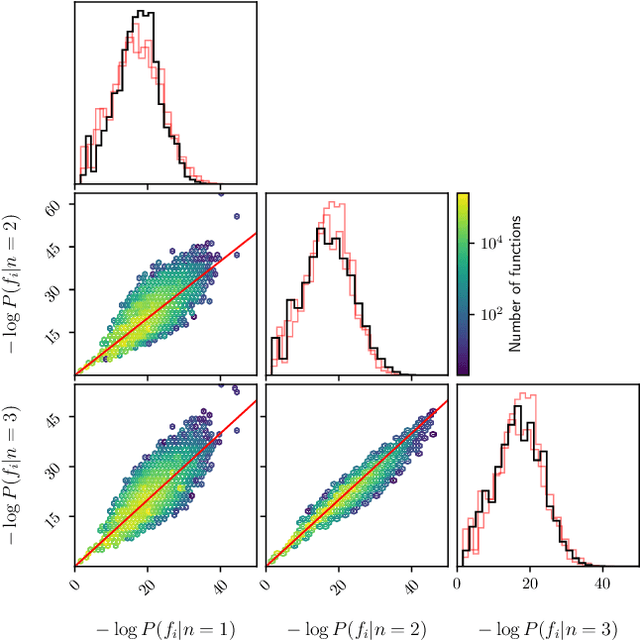
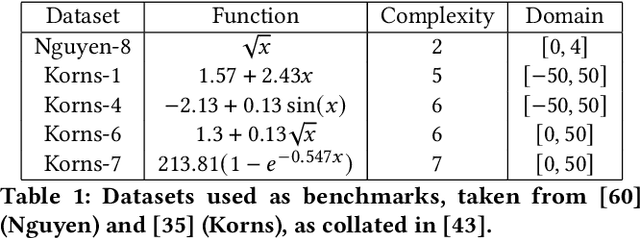
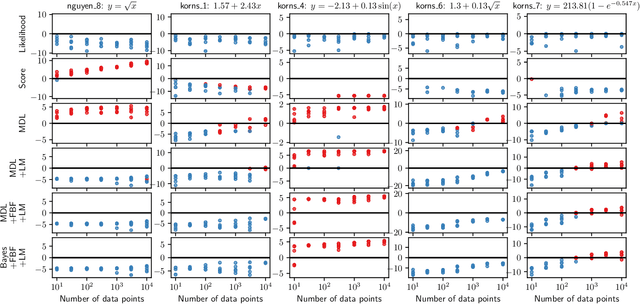
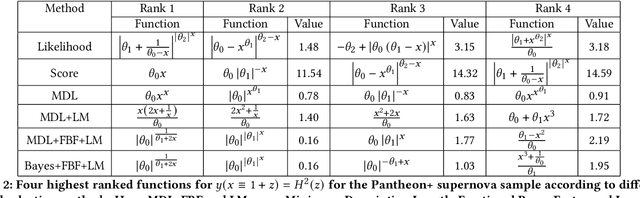
When choosing between competing symbolic models for a data set, a human will naturally prefer the "simpler" expression or the one which more closely resembles equations previously seen in a similar context. This suggests a non-uniform prior on functions, which is, however, rarely considered within a symbolic regression (SR) framework. In this paper we develop methods to incorporate detailed prior information on both functions and their parameters into SR. Our prior on the structure of a function is based on a $n$-gram language model, which is sensitive to the arrangement of operators relative to one another in addition to the frequency of occurrence of each operator. We also develop a formalism based on the Fractional Bayes Factor to treat numerical parameter priors in such a way that models may be fairly compared though the Bayesian evidence, and explicitly compare Bayesian, Minimum Description Length and heuristic methods for model selection. We demonstrate the performance of our priors relative to literature standards on benchmarks and a real-world dataset from the field of cosmology.
AutoPV: Automated photovoltaic forecasts with limited information using an ensemble of pre-trained models
Dec 13, 2022
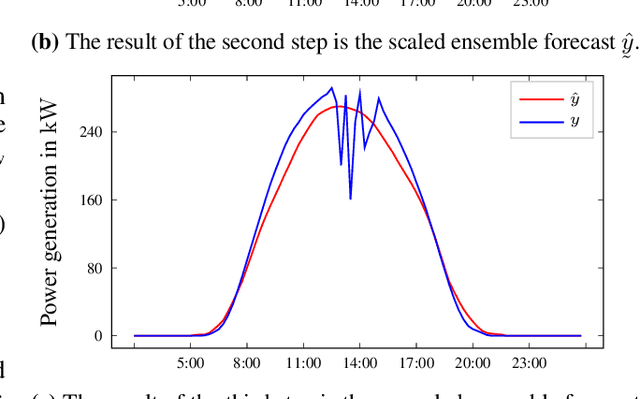
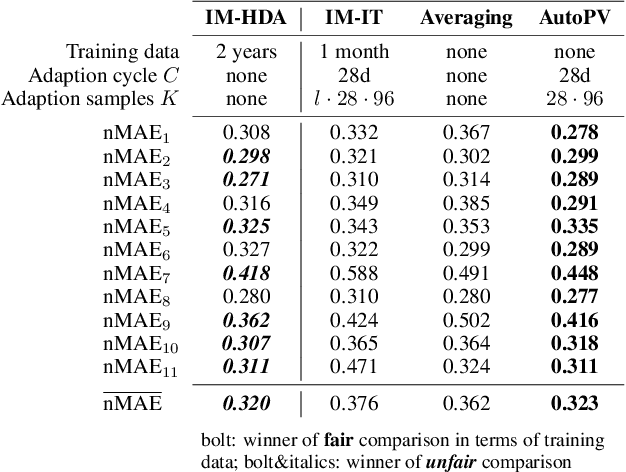
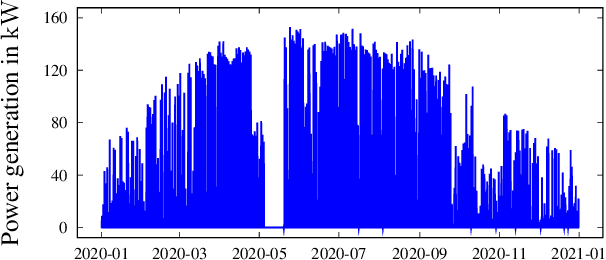
Accurate PhotoVoltaic (PV) power generation forecasting is vital for the efficient operation of Smart Grids. The automated design of such accurate forecasting models for individual PV plants includes two challenges: First, information about the PV mounting configuration (i.e. inclination and azimuth angles) is often missing. Second, for new PV plants, the amount of historical data available to train a forecasting model is limited (cold-start problem). We address these two challenges by proposing a new method for day-ahead PV power generation forecasts called AutoPV. AutoPV is a weighted ensemble of forecasting models that represent different PV mounting configurations. This representation is achieved by pre-training each forecasting model on a separate PV plant and by scaling the model's output with the peak power rating of the corresponding PV plant. To tackle the cold-start problem, we initially weight each forecasting model in the ensemble equally. To tackle the problem of missing information about the PV mounting configuration, we use new data that become available during operation to adapt the ensemble weights to minimize the forecasting error. AutoPV is advantageous as the unknown PV mounting configuration is implicitly reflected in the ensemble weights, and only the PV plant's peak power rating is required to re-scale the ensemble's output. AutoPV also allows to represent PV plants with panels distributed on different roofs with varying alignments, as these mounting configurations can be reflected proportionally in the weighting. Additionally, the required computing memory is decoupled when scaling AutoPV to hundreds of PV plants, which is beneficial in Smart Grids with limited computing capabilities. For a real-world data set with 11 PV plants, the accuracy of AutoPV is comparable to a model trained on two years of data and outperforms an incrementally trained model.
Q2ATransformer: Improving Medical VQA via an Answer Querying Decoder
Apr 04, 2023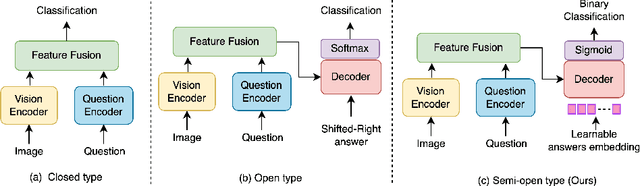
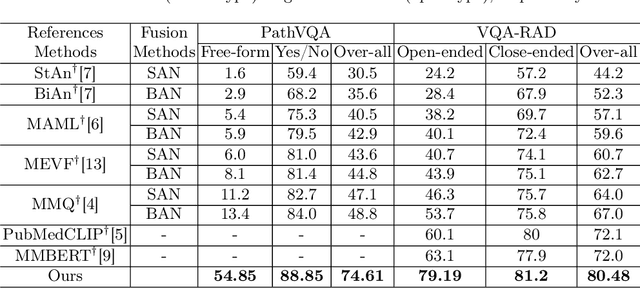
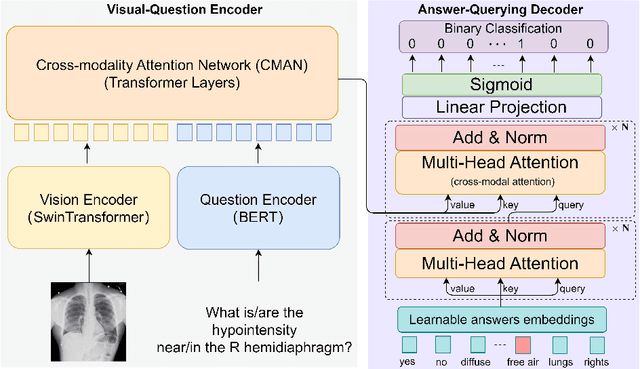
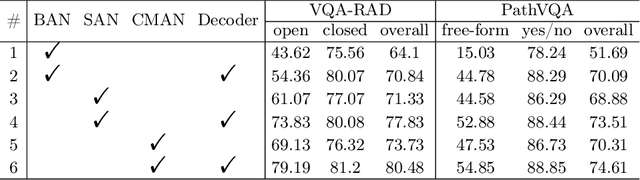
Medical Visual Question Answering (VQA) systems play a supporting role to understand clinic-relevant information carried by medical images. The questions to a medical image include two categories: close-end (such as Yes/No question) and open-end. To obtain answers, the majority of the existing medical VQA methods relies on classification approaches, while a few works attempt to use generation approaches or a mixture of the two. The classification approaches are relatively simple but perform poorly on long open-end questions. To bridge this gap, in this paper, we propose a new Transformer based framework for medical VQA (named as Q2ATransformer), which integrates the advantages of both the classification and the generation approaches and provides a unified treatment for the close-end and open-end questions. Specifically, we introduce an additional Transformer decoder with a set of learnable candidate answer embeddings to query the existence of each answer class to a given image-question pair. Through the Transformer attention, the candidate answer embeddings interact with the fused features of the image-question pair to make the decision. In this way, despite being a classification-based approach, our method provides a mechanism to interact with the answer information for prediction like the generation-based approaches. On the other hand, by classification, we mitigate the task difficulty by reducing the search space of answers. Our method achieves new state-of-the-art performance on two medical VQA benchmarks. Especially, for the open-end questions, we achieve 79.19% on VQA-RAD and 54.85% on PathVQA, with 16.09% and 41.45% absolute improvements, respectively.