 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AVOID: Autonomous Vehicle Operation Incident Dataset Across the Globe
Mar 22, 2023
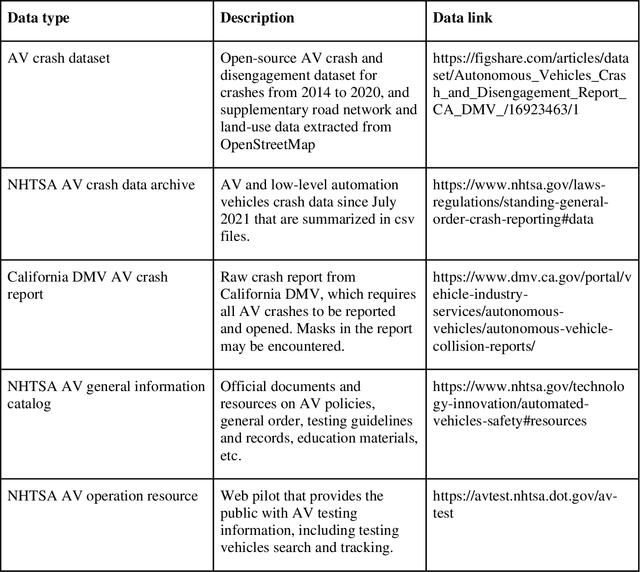
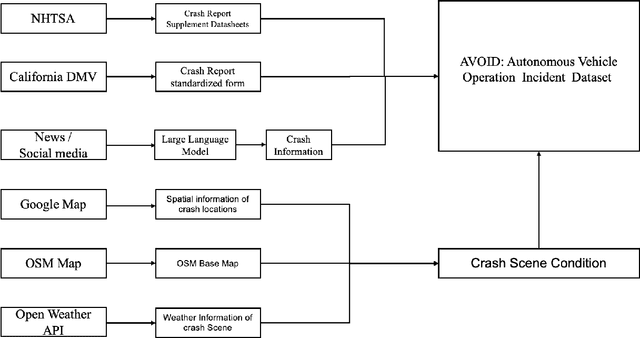
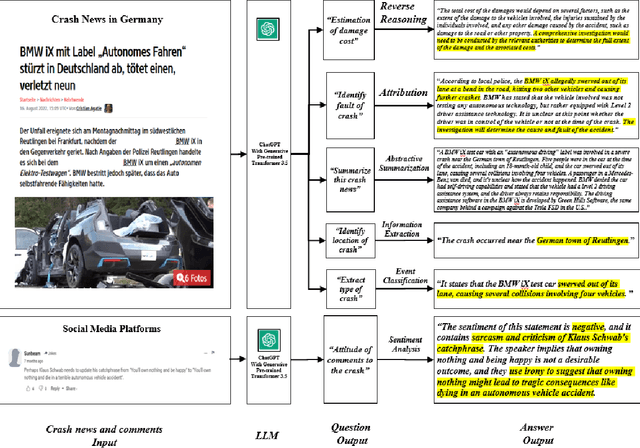
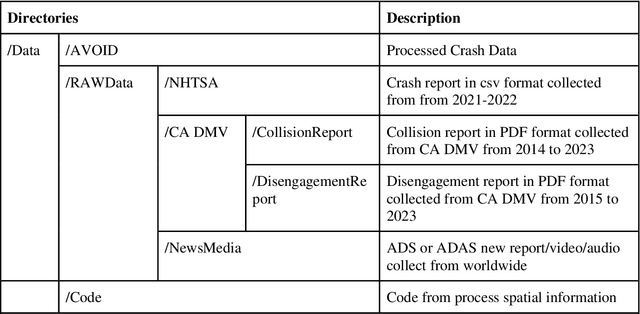
Crash data of autonomous vehicles (AV) or vehicles equipped with advanced driver assistance systems (ADAS) are the key information to understand the crash nature and to enhance the automation systems. However, most of the existing crash data sources are either limited by the sample size or suffer from missing or unverified data. To contribute to the AV safety research community, we introduce AVOID: an open AV crash dataset. Three types of vehicles are considered: Advanced Driving System (ADS) vehicles, Advanced Driver Assistance Systems (ADAS) vehicles, and low-speed autonomous shuttles. The crash data are collected from the National Highway Traffic Safety Administration (NHTSA), California Department of Motor Vehicles (CA DMV) and incident news worldwide, and the data are manually verified and summarized in ready-to-use format. In addition, land use, weather, and geometry information are also provided. The dataset is expected to accelerate the research on AV crash analysis and potential risk identification by providing the research community with data of rich samples, diverse data sources, clear data structure, and high data quality.
Improving Masked Autoencoders by Learning Where to Mask
Mar 12, 2023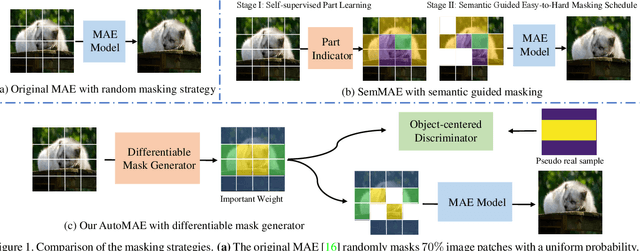

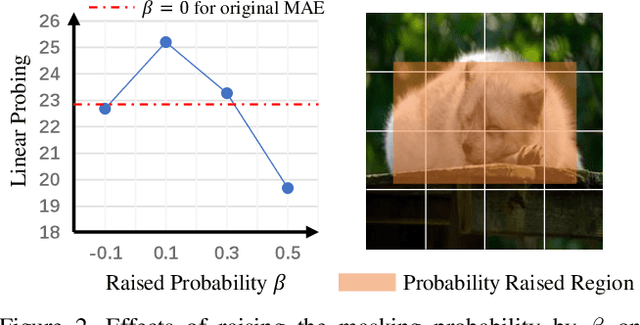

Masked image modeling is a promising self-supervised learning method for visual data. It is typically built upon image patches with random masks, which largely ignores the variation of information density between them. The question is: Is there a better masking strategy than random sampling and how can we learn it? We empirically study this problem and initially find that introducing object-centric priors in mask sampling can significantly improve the learned representations. Inspired by this observation, we present AutoMAE, a fully differentiable framework that uses Gumbel-Softmax to interlink an adversarially-trained mask generator and a mask-guided image modeling process. In this way, our approach can adaptively find patches with higher information density for different images, and further strike a balance between the information gain obtained from image reconstruction and its practical training difficulty. In our experiments, AutoMAE is shown to provide effective pretraining models on standard self-supervised benchmarks and downstream tasks.
PP-MobileSeg: Explore the Fast and Accurate Semantic Segmentation Model on Mobile Devices
Apr 11, 2023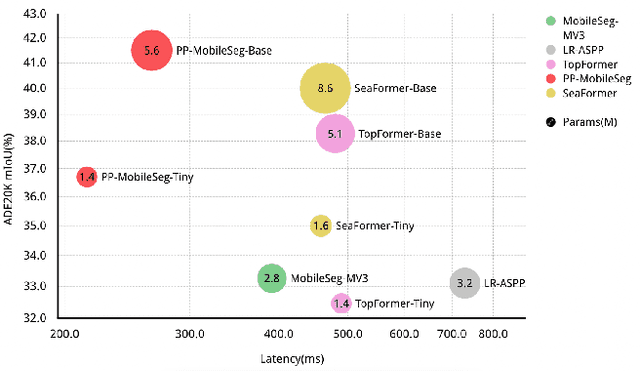
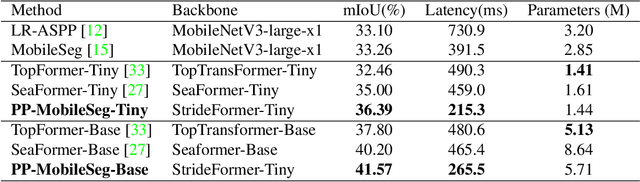
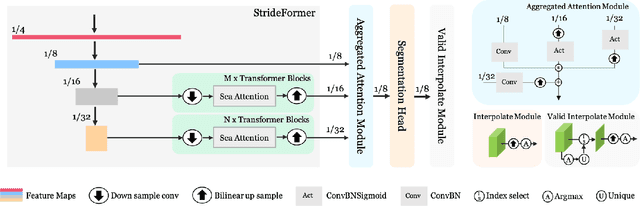

The success of transformers in computer vision has led to several attempts to adapt them for mobile devices, but their performance remains unsatisfactory in some real-world applications. To address this issue, we propose PP-MobileSeg, a semantic segmentation model that achieves state-of-the-art performance on mobile devices. PP-MobileSeg comprises three novel parts: the StrideFormer backbone, the Aggregated Attention Module (AAM), and the Valid Interpolate Module (VIM). The four-stage StrideFormer backbone is built with MV3 blocks and strided SEA attention, and it is able to extract rich semantic and detailed features with minimal parameter overhead. The AAM first filters the detailed features through semantic feature ensemble voting and then combines them with semantic features to enhance the semantic information. Furthermore, we proposed VIM to upsample the downsampled feature to the resolution of the input image. It significantly reduces model latency by only interpolating classes present in the final prediction, which is the most significant contributor to overall model latency. Extensive experiments show that PP-MobileSeg achieves a superior tradeoff between accuracy, model size, and latency compared to other methods. On the ADE20K dataset, PP-MobileSeg achieves 1.57% higher accuracy in mIoU than SeaFormer-Base with 32.9% fewer parameters and 42.3% faster acceleration on Qualcomm Snapdragon 855. Source codes are available at https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.8.
EvAC3D: From Event-based Apparent Contours to 3D Models via Continuous Visual Hulls
Apr 11, 20233D reconstruction from multiple views is a successful computer vision field with multiple deployments in applications. State of the art is based on traditional RGB frames that enable optimization of photo-consistency cross views. In this paper, we study the problem of 3D reconstruction from event-cameras, motivated by the advantages of event-based cameras in terms of low power and latency as well as by the biological evidence that eyes in nature capture the same data and still perceive well 3D shape. The foundation of our hypothesis that 3D reconstruction is feasible using events lies in the information contained in the occluding contours and in the continuous scene acquisition with events. We propose Apparent Contour Events (ACE), a novel event-based representation that defines the geometry of the apparent contour of an object. We represent ACE by a spatially and temporally continuous implicit function defined in the event x-y-t space. Furthermore, we design a novel continuous Voxel Carving algorithm enabled by the high temporal resolution of the Apparent Contour Events. To evaluate the performance of the method, we collect MOEC-3D, a 3D event dataset of a set of common real-world objects. We demonstrate the ability of EvAC3D to reconstruct high-fidelity mesh surfaces from real event sequences while allowing the refinement of the 3D reconstruction for each individual event.
A Game-theoretic Framework for Federated Learning
Apr 11, 2023
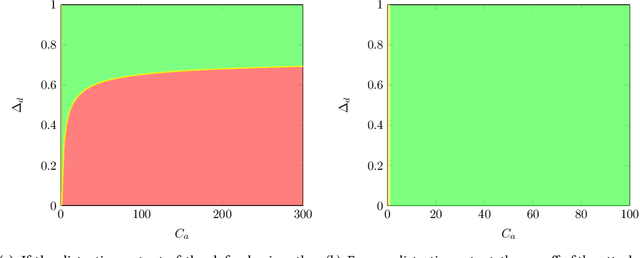

In federated learning, benign participants aim to optimize a global model collaboratively. However, the risk of \textit{privacy leakage} cannot be ignored in the presence of \textit{semi-honest} adversaries. Existing research has focused either on designing protection mechanisms or on inventing attacking mechanisms. While the battle between defenders and attackers seems never-ending, we are concerned with one critical question: is it possible to prevent potential attacks in advance? To address this, we propose the first game-theoretic framework that considers both FL defenders and attackers in terms of their respective payoffs, which include computational costs, FL model utilities, and privacy leakage risks. We name this game the Federated Learning Security Game (FLSG), in which neither defenders nor attackers are aware of all participants' payoffs. To handle the \textit{incomplete information} inherent in this situation, we propose associating the FLSG with an \textit{oracle} that has two primary responsibilities. First, the oracle provides lower and upper bounds of the payoffs for the players. Second, the oracle acts as a correlation device, privately providing suggested actions to each player. With this novel framework, we analyze the optimal strategies of defenders and attackers. Furthermore, we derive and demonstrate conditions under which the attacker, as a rational decision-maker, should always follow the oracle's suggestion \textit{not to attack}.
Policy Gradient Methods for Discrete Time Linear Quadratic Regulator With Random Parameters
Mar 29, 2023This paper studies an infinite horizon optimal control problem for discrete-time linear system and quadratic criteria, both with random parameters which are independent and identically distributed with respect to time. In this general setting, we apply the policy gradient method, a reinforcement learning technique, to search for the optimal control without requiring knowledge of statistical information of the parameters. We investigate the sub-Gaussianity of the state process and establish global linear convergence guarantee for this approach based on assumptions that are weaker and easier to verify compared to existing results. Numerical experiments are presented to illustrate our result.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023
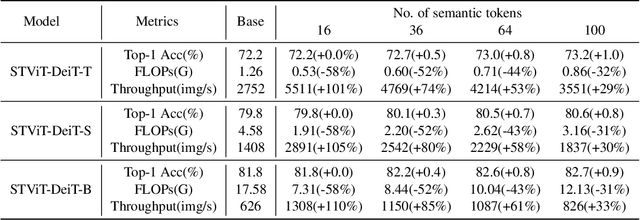
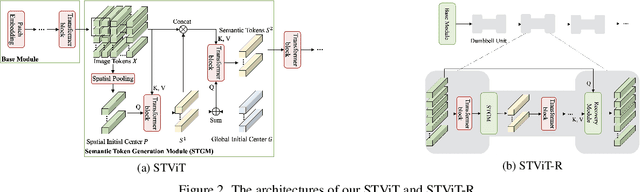
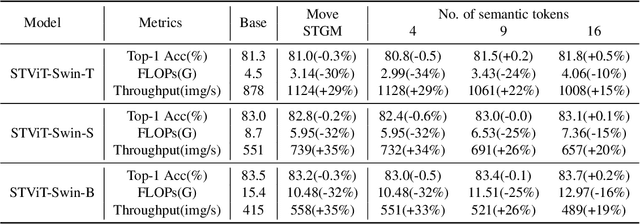
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
FairGen: Towards Fair Graph Generation
Mar 30, 2023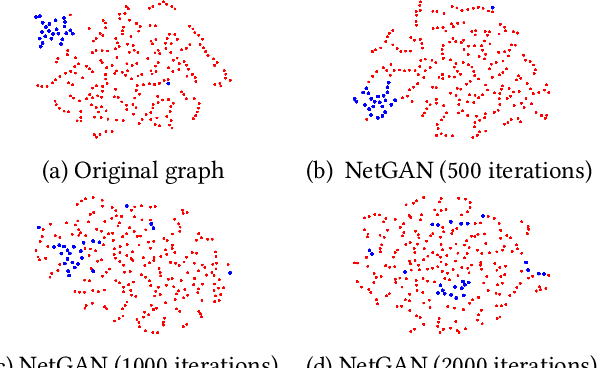
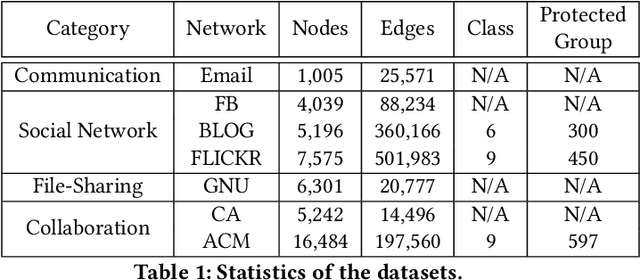
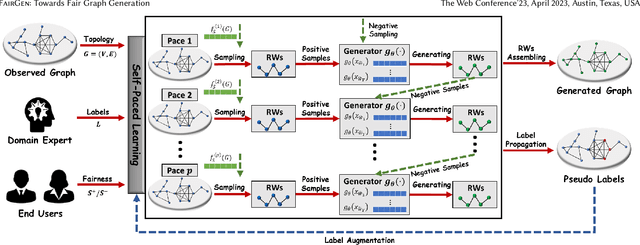
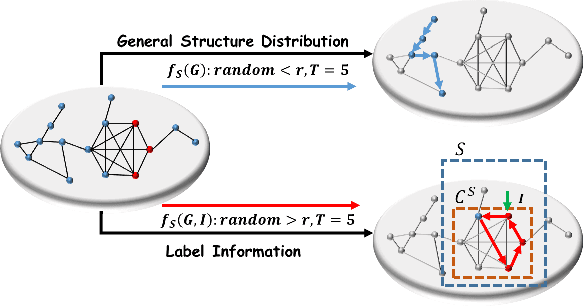
There have been tremendous efforts over the past decades dedicated to the generation of realistic graphs in a variety of domains, ranging from social networks to computer networks, from gene regulatory networks to online transaction networks. Despite the remarkable success, the vast majority of these works are unsupervised in nature and are typically trained to minimize the expected graph reconstruction loss, which would result in the representation disparity issue in the generated graphs, i.e., the protected groups (often minorities) contribute less to the objective and thus suffer from systematically higher errors. In this paper, we aim to tailor graph generation to downstream mining tasks by leveraging label information and user-preferred parity constraint. In particular, we start from the investigation of representation disparity in the context of graph generative models. To mitigate the disparity, we propose a fairness-aware graph generative model named FairGen. Our model jointly trains a label-informed graph generation module and a fair representation learning module by progressively learning the behaviors of the protected and unprotected groups, from the `easy' concepts to the `hard' ones. In addition, we propose a generic context sampling strategy for graph generative models, which is proven to be capable of fairly capturing the contextual information of each group with a high probability. Experimental results on seven real-world data sets, including web-based graphs, demonstrate that FairGen (1) obtains performance on par with state-of-the-art graph generative models across six network properties, (2) mitigates the representation disparity issues in the generated graphs, and (3) substantially boosts the model performance by up to 17% in downstream tasks via data augmentation.
SGDViT: Saliency-Guided Dynamic Vision Transformer for UAV Tracking
Mar 08, 2023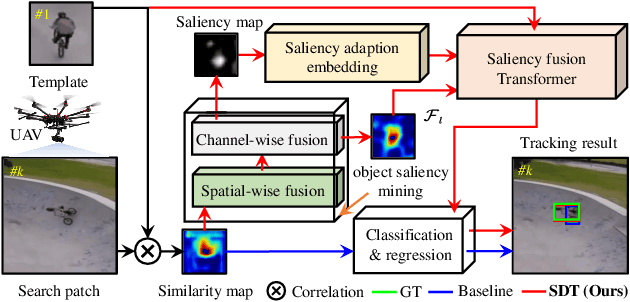
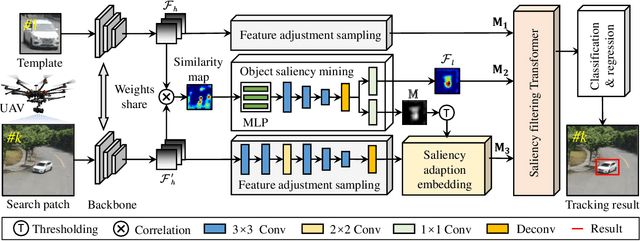
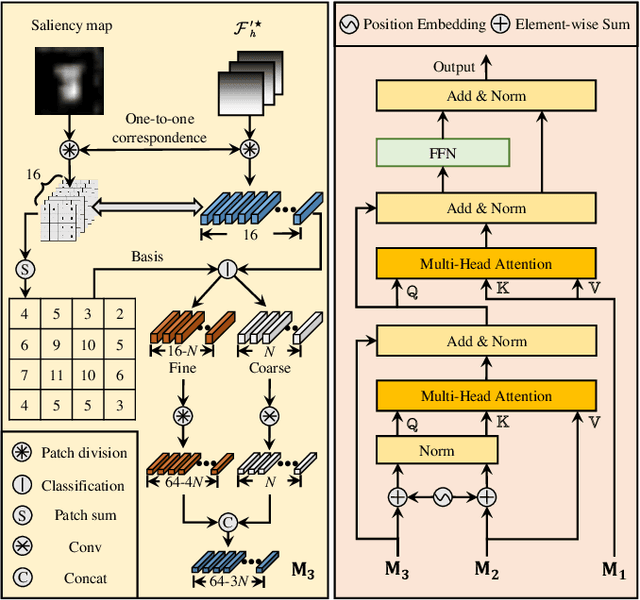
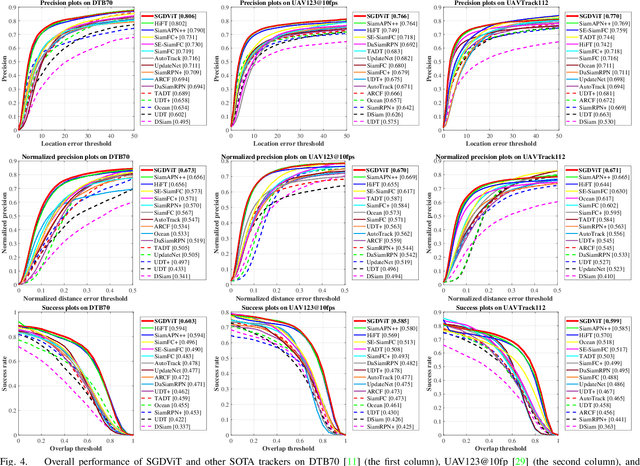
Vision-based object tracking has boosted extensive autonomous applications for unmanned aerial vehicles (UAVs). However, the dynamic changes in flight maneuver and viewpoint encountered in UAV tracking pose significant difficulties, e.g. , aspect ratio change, and scale variation. The conventional cross-correlation operation, while commonly used, has limitations in effectively capturing perceptual similarity and incorporates extraneous background information. To mitigate these limitations, this work presents a novel saliency-guided dynamic vision Transformer (SGDViT) for UAV tracking. The proposed method designs a new task-specific object saliency mining network to refine the cross-correlation operation and effectively discriminate foreground and background information. Additionally, a saliency adaptation embedding operation dynamically generates tokens based on initial saliency, thereby reducing the computational complexity of the Transformer architecture. Finally, a lightweight saliency filtering Transformer further refines saliency information and increases the focus on appearance information. The efficacy and robustness of the proposed approach have been thoroughly assessed through experiments on three widely-used UAV tracking benchmarks and real-world scenarios, with results demonstrating its superiority. The source code and demo videos are available at https://github.com/vision4robotics/SGDViT.
Semantically Consistent Multi-view Representation Learning
Mar 08, 2023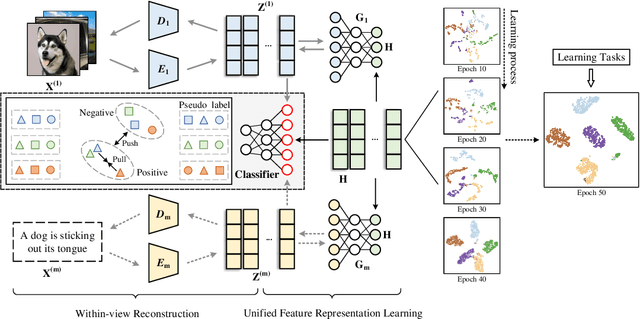
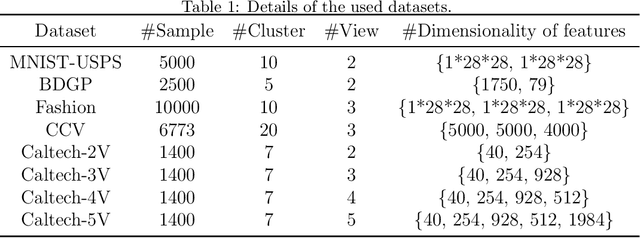

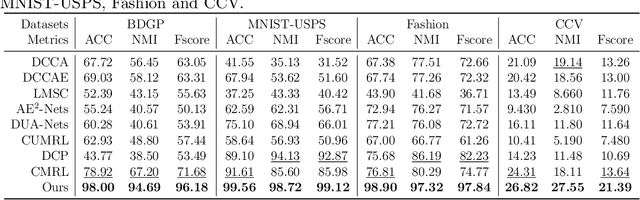
In this work, we devote ourselves to the challenging task of Unsupervised Multi-view Representation Learning (UMRL), which requires learning a unified feature representation from multiple views in an unsupervised manner. Existing UMRL methods mainly concentrate on the learning process in the feature space while ignoring the valuable semantic information hidden in different views. To address this issue, we propose a novel Semantically Consistent Multi-view Representation Learning (SCMRL), which makes efforts to excavate underlying multi-view semantic consensus information and utilize the information to guide the unified feature representation learning. Specifically, SCMRL consists of a within-view reconstruction module and a unified feature representation learning module, which are elegantly integrated by the contrastive learning strategy to simultaneously align semantic labels of both view-specific feature representations and the learned unified feature representation. In this way, the consensus information in the semantic space can be effectively exploited to constrain the learning process of unified feature representation. Compared with several state-of-the-art algorithms, extensive experiments demonstrate its superiority.