 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-domain Speech Enhancement Assisted by Multi-resolution Frequency Encoder and Decoder
Mar 26, 2023
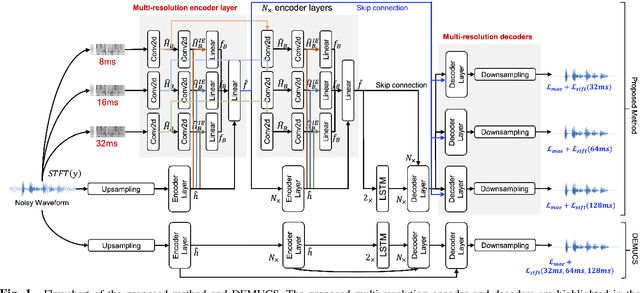

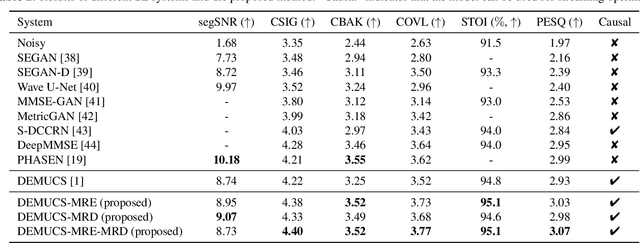

Time-domain speech enhancement (SE) has recently been intensively investigated. Among recent works, DEMUCS introduces multi-resolution STFT loss to enhance performance. However, some resolutions used for STFT contain non-stationary signals, and it is challenging to learn multi-resolution frequency losses simultaneously with only one output. For better use of multi-resolution frequency information, we supplement multiple spectrograms in different frame lengths into the time-domain encoders. They extract stationary frequency information in both narrowband and wideband. We also adopt multiple decoder outputs, each of which computes its corresponding resolution frequency loss. Experimental results show that (1) it is more effective to fuse stationary frequency features than non-stationary features in the encoder, and (2) the multiple outputs consistent with the frequency loss improve performance. Experiments on the Voice-Bank dataset show that the proposed method obtained a 0.14 PESQ improvement.
Determining Accessible Sidewalk Width by Extracting Obstacle Information from Point Clouds
Nov 08, 2022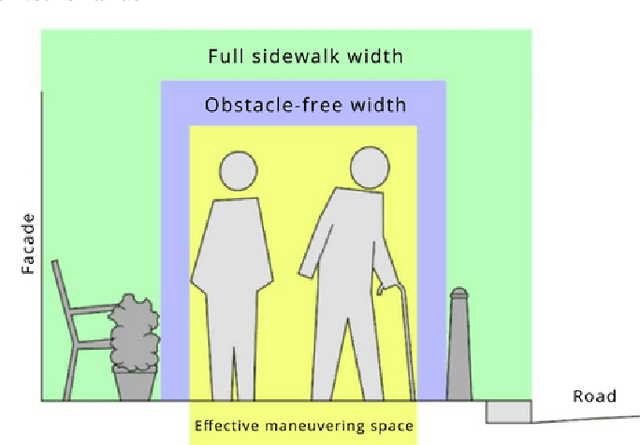
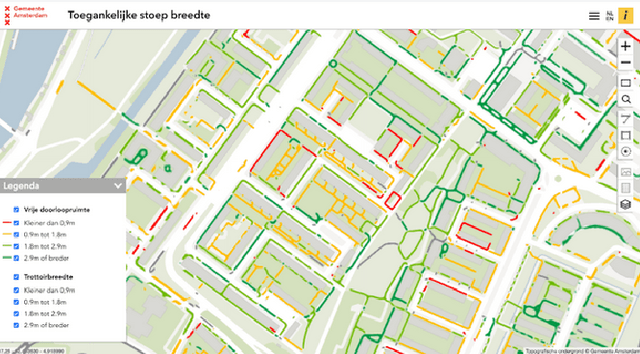

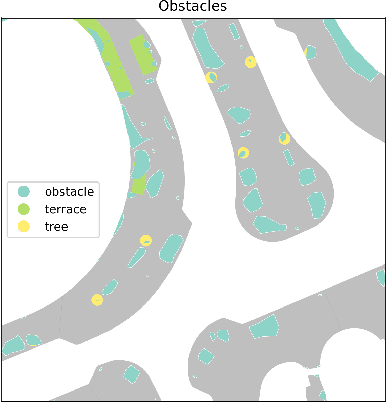
Obstacles on the sidewalk often block the path, limiting passage and resulting in frustration and wasted time, especially for citizens and visitors who use assistive devices (wheelchairs, walkers, strollers, canes, etc). To enable equal participation and use of the city, all citizens should be able to perform and complete their daily activities in a similar amount of time and effort. Therefore, we aim to offer accessibility information regarding sidewalks, so that citizens can better plan their routes, and to help city officials identify the location of bottlenecks and act on them. In this paper we propose a novel pipeline to estimate obstacle-free sidewalk widths based on 3D point cloud data of the city of Amsterdam, as the first step to offer a more complete set of information regarding sidewalk accessibility.
Towards Open Temporal Graph Neural Networks
Mar 27, 2023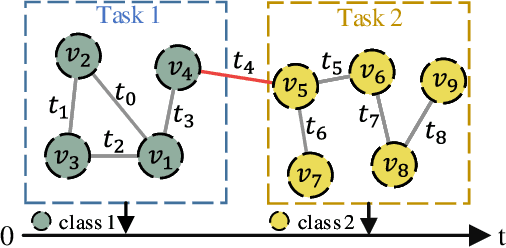
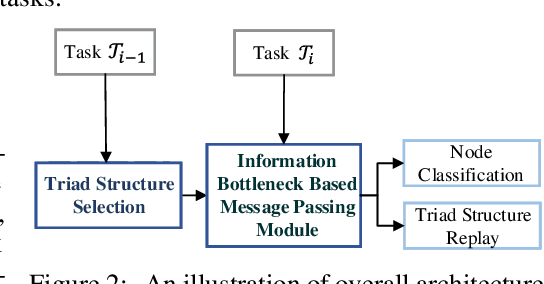
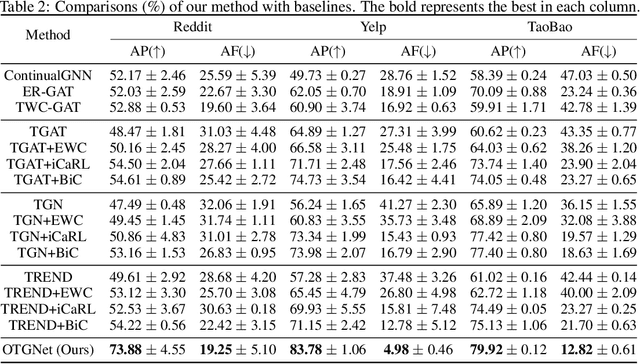
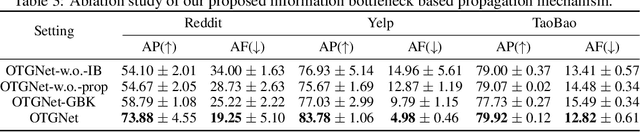
Graph neural networks (GNNs) for temporal graphs have recently attracted increasing attentions, where a common assumption is that the class set for nodes is closed. However, in real-world scenarios, it often faces the open set problem with the dynamically increased class set as the time passes by. This will bring two big challenges to the existing dynamic GNN methods: (i) How to dynamically propagate appropriate information in an open temporal graph, where new class nodes are often linked to old class nodes. This case will lead to a sharp contradiction. This is because typical GNNs are prone to make the embeddings of connected nodes become similar, while we expect the embeddings of these two interactive nodes to be distinguishable since they belong to different classes. (ii) How to avoid catastrophic knowledge forgetting over old classes when learning new classes occurred in temporal graphs. In this paper, we propose a general and principled learning approach for open temporal graphs, called OTGNet, with the goal of addressing the above two challenges. We assume the knowledge of a node can be disentangled into class-relevant and class-agnostic one, and thus explore a new message passing mechanism by extending the information bottleneck principle to only propagate class-agnostic knowledge between nodes of different classes, avoiding aggregating conflictive information. Moreover, we devise a strategy to select both important and diverse triad sub-graph structures for effective class-incremental learning. Extensive experiments on three real-world datasets of different domains demonstrate the superiority of our method, compared to the baselines.
Inverting the Fundamental Diagram and Forecasting Boundary Conditions: How Machine Learning Can Improve Macroscopic Models for Traffic Flow
Mar 21, 2023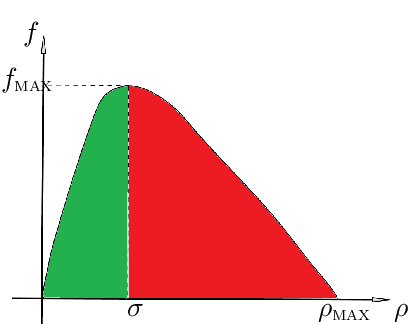
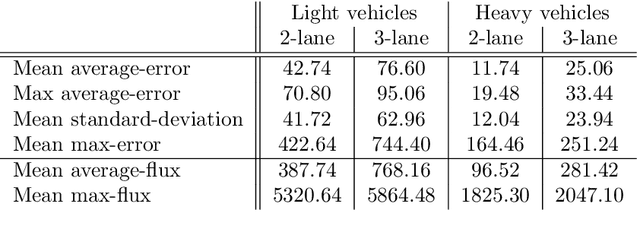
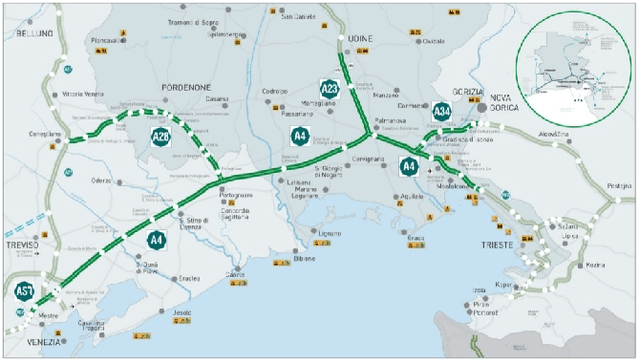
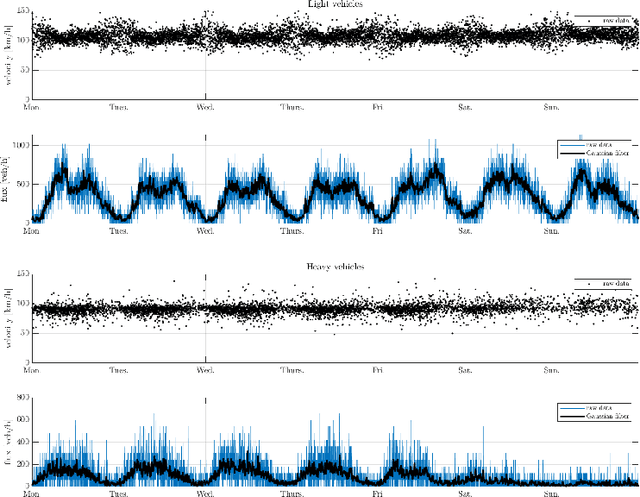
In this paper, we aim at developing new methods to join machine learning techniques and macroscopic differential models for vehicular traffic estimation and forecast. It is well known that data-driven and model-driven approaches have (sometimes complementary) advantages and drawbacks. We consider here a dataset with flux and velocity data of vehicles moving on a highway, collected by fixed sensors and classified by lane and by class of vehicle. By means of a machine learning model based on an LSTM recursive neural network, we extrapolate two important pieces of information: 1) if congestion is appearing under the sensor, and 2) the total amount of vehicles which is going to pass under the sensor in the next future (30 min). These pieces of information are then used to improve the accuracy of an LWR-based first-order multi-class model describing the dynamics of traffic flow between sensors. The first piece of information is used to invert the (concave) fundamental diagram, thus recovering the density of vehicles from the flux data, and then inject directly the density datum in the model. This allows one to better approximate the dynamics between sensors, especially if an accident happens in a not monitored stretch of the road. The second piece of information is used instead as boundary conditions for the equations underlying the traffic model, to better reconstruct the total amount of vehicles on the road at any future time. Some examples motivated by real scenarios will be discussed. Real data are provided by the Italian motorway company Autovie Venete S.p.A.
mHealth hyperspectral learning for instantaneous spatiospectral imaging of hemodynamics
Apr 05, 2023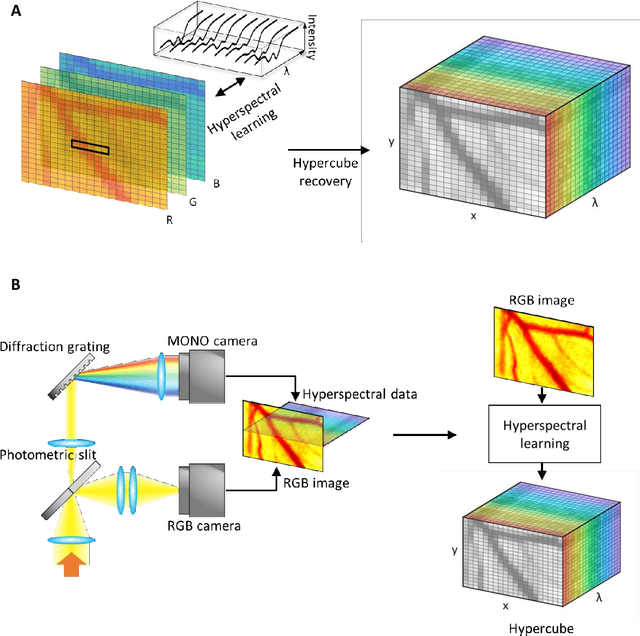
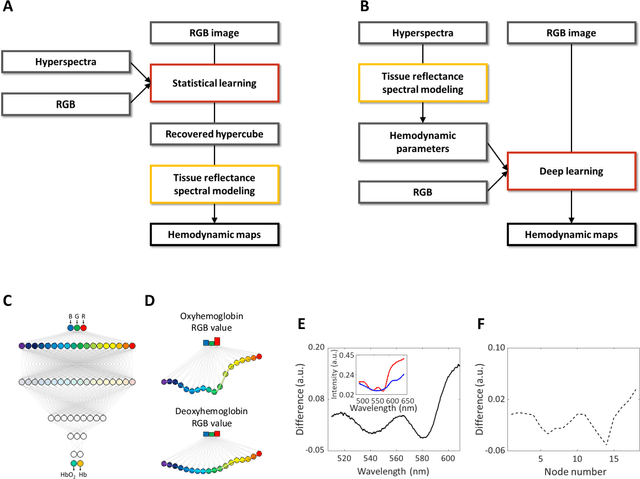
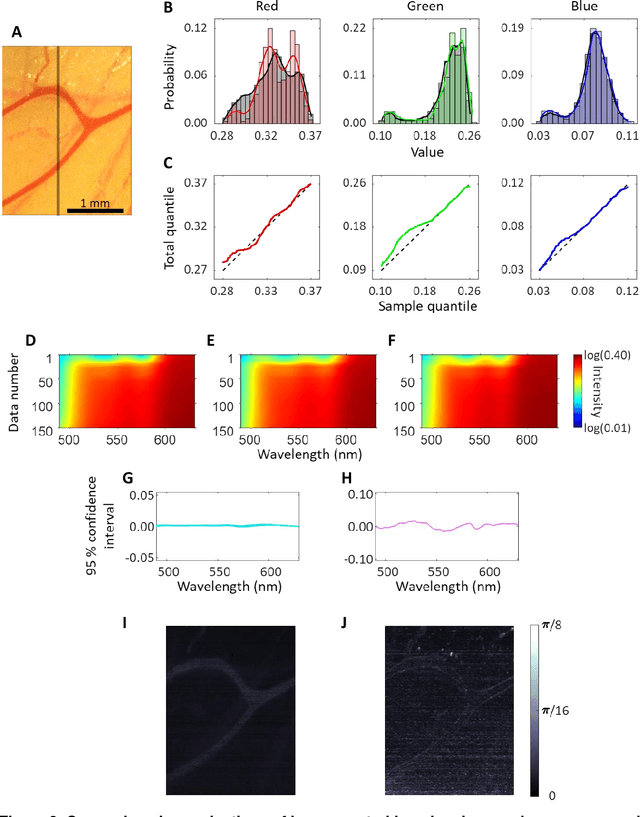
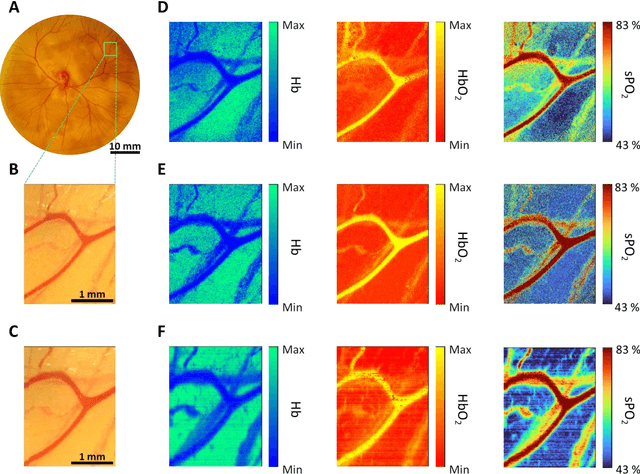
Hyperspectral imaging acquires data in both the spatial and frequency domains to offer abundant physical or biological information. However, conventional hyperspectral imaging has intrinsic limitations of bulky instruments, slow data acquisition rate, and spatiospectral tradeoff. Here we introduce hyperspectral learning for snapshot hyperspectral imaging in which sampled hyperspectral data in a small subarea are incorporated into a learning algorithm to recover the hypercube. Hyperspectral learning exploits the idea that a photograph is more than merely a picture and contains detailed spectral information. A small sampling of hyperspectral data enables spectrally informed learning to recover a hypercube from an RGB image. Hyperspectral learning is capable of recovering full spectroscopic resolution in the hypercube, comparable to high spectral resolutions of scientific spectrometers. Hyperspectral learning also enables ultrafast dynamic imaging, leveraging ultraslow video recording in an off-the-shelf smartphone, given that a video comprises a time series of multiple RGB images. To demonstrate its versatility, an experimental model of vascular development is used to extract hemodynamic parameters via statistical and deep-learning approaches. Subsequently, the hemodynamics of peripheral microcirculation is assessed at an ultrafast temporal resolution up to a millisecond, using a conventional smartphone camera. This spectrally informed learning method is analogous to compressed sensing; however, it further allows for reliable hypercube recovery and key feature extractions with a transparent learning algorithm. This learning-powered snapshot hyperspectral imaging method yields high spectral and temporal resolutions and eliminates the spatiospectral tradeoff, offering simple hardware requirements and potential applications of various machine-learning techniques.
FACE-AUDITOR: Data Auditing in Facial Recognition Systems
Apr 05, 2023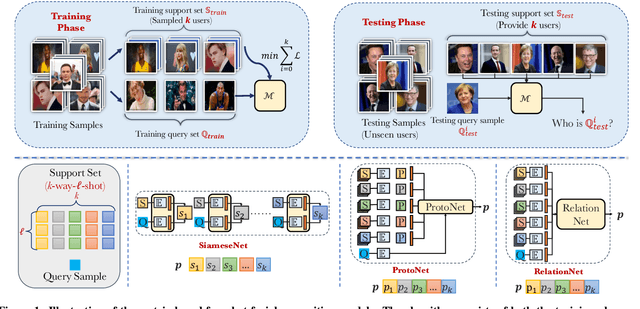

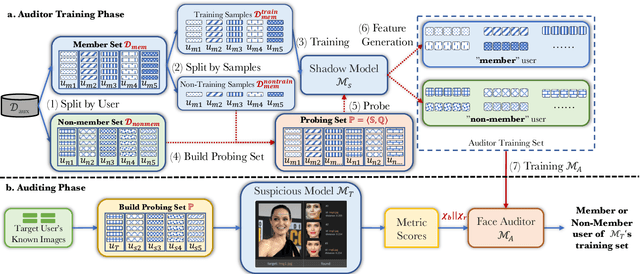
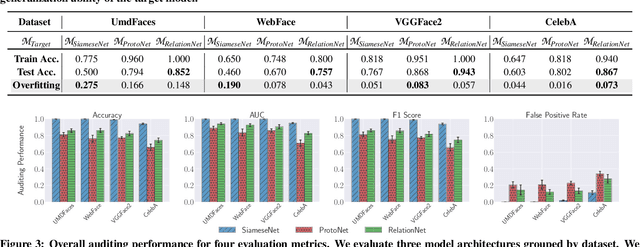
Few-shot-based facial recognition systems have gained increasing attention due to their scalability and ability to work with a few face images during the model deployment phase. However, the power of facial recognition systems enables entities with moderate resources to canvas the Internet and build well-performed facial recognition models without people's awareness and consent. To prevent the face images from being misused, one straightforward approach is to modify the raw face images before sharing them, which inevitably destroys the semantic information, increases the difficulty of retroactivity, and is still prone to adaptive attacks. Therefore, an auditing method that does not interfere with the facial recognition model's utility and cannot be quickly bypassed is urgently needed. In this paper, we formulate the auditing process as a user-level membership inference problem and propose a complete toolkit FACE-AUDITOR that can carefully choose the probing set to query the few-shot-based facial recognition model and determine whether any of a user's face images is used in training the model. We further propose to use the similarity scores between the original face images as reference information to improve the auditing performance. Extensive experiments on multiple real-world face image datasets show that FACE-AUDITOR can achieve auditing accuracy of up to $99\%$. Finally, we show that FACE-AUDITOR is robust in the presence of several perturbation mechanisms to the training images or the target models. The source code of our experiments can be found at \url{https://github.com/MinChen00/Face-Auditor}.
Multimodal and multicontrast image fusion via deep generative models
Mar 28, 2023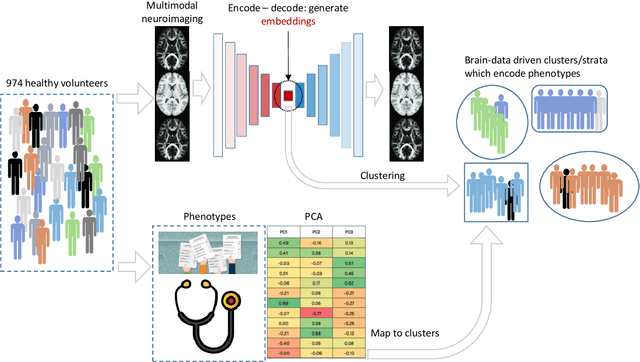
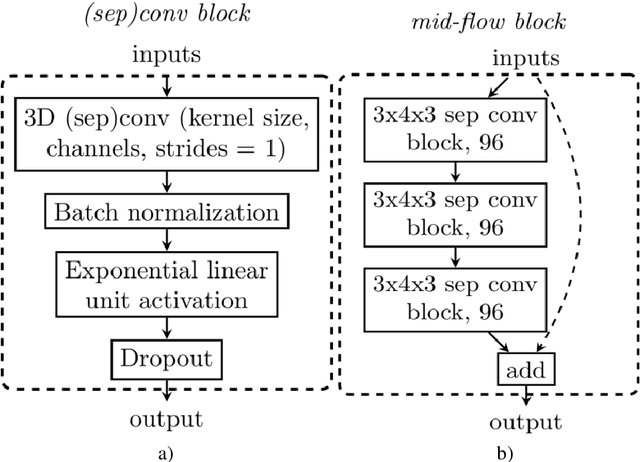

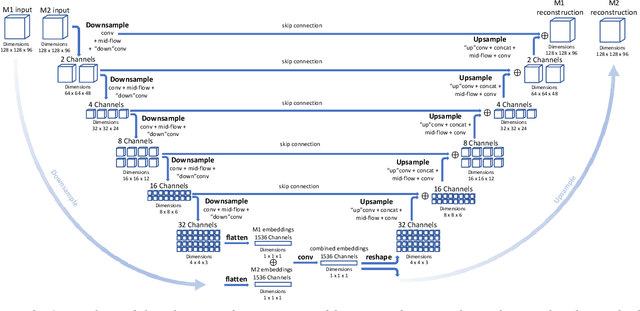
Recently, it has become progressively more evident that classic diagnostic labels are unable to reliably describe the complexity and variability of several clinical phenotypes. This is particularly true for a broad range of neuropsychiatric illnesses (e.g., depression, anxiety disorders, behavioral phenotypes). Patient heterogeneity can be better described by grouping individuals into novel categories based on empirically derived sections of intersecting continua that span across and beyond traditional categorical borders. In this context, neuroimaging data carry a wealth of spatiotemporally resolved information about each patient's brain. However, they are usually heavily collapsed a priori through procedures which are not learned as part of model training, and consequently not optimized for the downstream prediction task. This is because every individual participant usually comes with multiple whole-brain 3D imaging modalities often accompanied by a deep genotypic and phenotypic characterization, hence posing formidable computational challenges. In this paper we design a deep learning architecture based on generative models rooted in a modular approach and separable convolutional blocks to a) fuse multiple 3D neuroimaging modalities on a voxel-wise level, b) convert them into informative latent embeddings through heavy dimensionality reduction, c) maintain good generalizability and minimal information loss. As proof of concept, we test our architecture on the well characterized Human Connectome Project database demonstrating that our latent embeddings can be clustered into easily separable subject strata which, in turn, map to different phenotypical information which was not included in the embedding creation process. This may be of aid in predicting disease evolution as well as drug response, hence supporting mechanistic disease understanding and empowering clinical trials.
Fast Convergent Federated Learning with Aggregated Gradients
Apr 01, 2023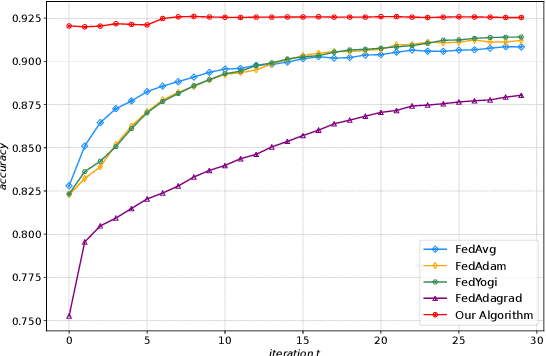
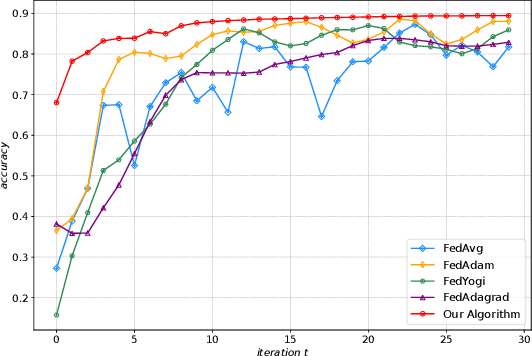
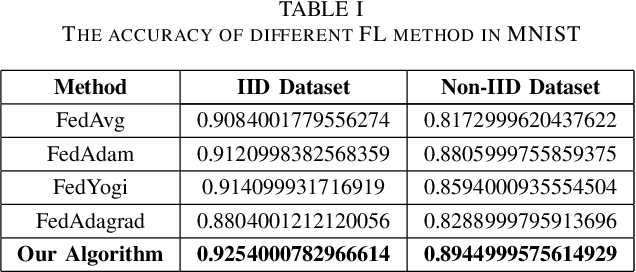
Federated Learning (FL) is a novel machine learning framework, which enables multiple distributed devices cooperatively to train a shared model scheduled by a central server while protecting private data locally. However, the non-independent-and-identically-distributed (Non-IID) data samples and frequent communication across participants may significantly slow down the convergent rate and increase communication costs. To achieve fast convergence, we ameliorate the conventional local updating rule by introducing the aggregated gradients at each local update epoch, and propose an adaptive learning rate algorithm that further takes the deviation of local parameter and global parameter into consideration. The above adaptive learning rate design requires all clients' local information including the local parameters and gradients, which is challenging as there is no communication during the local update epochs. To obtain a decentralized adaptive learning rate for each client, we utilize the mean field approach by introducing two mean field terms to estimate the average local parameters and gradients respectively, which does not require the clients to exchange their local information with each other at each local epoch. Numerical results show that our proposed framework is superior to the state-of-art FL schemes in both model accuracy and convergent rate for IID and Non-IID datasets.
Bipartite Graph Convolutional Hashing for Effective and Efficient Top-N Search in Hamming Space
Apr 01, 2023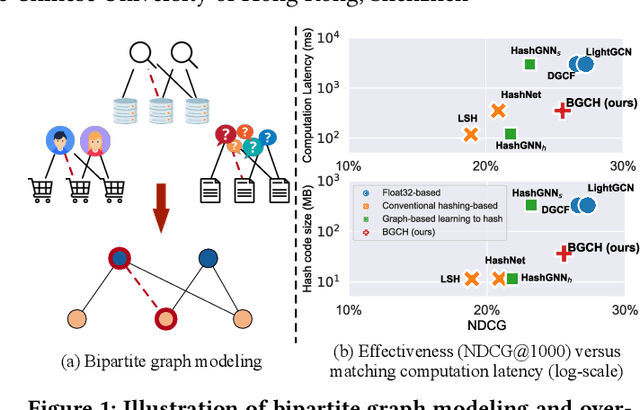
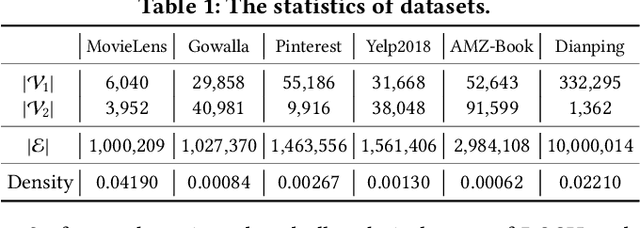
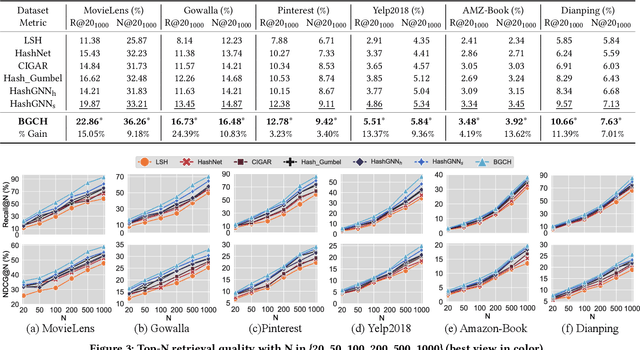
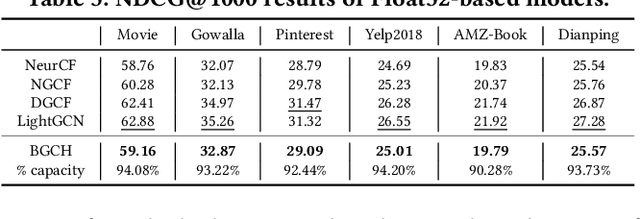
Searching on bipartite graphs is basal and versatile to many real-world Web applications, e.g., online recommendation, database retrieval, and query-document searching. Given a query node, the conventional approaches rely on the similarity matching with the vectorized node embeddings in the continuous Euclidean space. To efficiently manage intensive similarity computation, developing hashing techniques for graph structured data has recently become an emerging research direction. Despite the retrieval efficiency in Hamming space, prior work is however confronted with catastrophic performance decay. In this work, we investigate the problem of hashing with Graph Convolutional Network on bipartite graphs for effective Top-N search. We propose an end-to-end Bipartite Graph Convolutional Hashing approach, namely BGCH, which consists of three novel and effective modules: (1) adaptive graph convolutional hashing, (2) latent feature dispersion, and (3) Fourier serialized gradient estimation. Specifically, the former two modules achieve the substantial retention of the structural information against the inevitable information loss in hash encoding; the last module develops Fourier Series decomposition to the hashing function in the frequency domain mainly for more accurate gradient estimation. The extensive experiments on six real-world datasets not only show the performance superiority over the competing hashing-based counterparts, but also demonstrate the effectiveness of all proposed model components contained therein.
RADIFUSION: A multi-radiomics deep learning based breast cancer risk prediction model using sequential mammographic images with image attention and bilateral asymmetry refinement
Apr 01, 2023
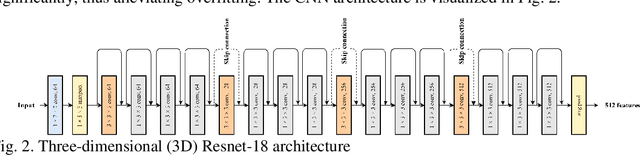

Breast cancer is a significant public health concern and early detection is critical for triaging high risk patients. Sequential screening mammograms can provide important spatiotemporal information about changes in breast tissue over time. In this study, we propose a deep learning architecture called RADIFUSION that utilizes sequential mammograms and incorporates a linear image attention mechanism, radiomic features, a new gating mechanism to combine different mammographic views, and bilateral asymmetry-based finetuning for breast cancer risk assessment. We evaluate our model on a screening dataset called Cohort of Screen-Aged Women (CSAW) dataset. Based on results obtained on the independent testing set consisting of 1,749 women, our approach achieved superior performance compared to other state-of-the-art models with area under the receiver operating characteristic curves (AUCs) of 0.905, 0.872 and 0.866 in the three respective metrics of 1-year AUC, 2-year AUC and > 2-year AUC. Our study highlights the importance of incorporating various deep learning mechanisms, such as image attention, radiomic features, gating mechanism, and bilateral asymmetry-based fine-tuning, to improve the accuracy of breast cancer risk assessment. We also demonstrate that our model's performance was enhanced by leveraging spatiotemporal information from sequential mammograms. Our findings suggest that RADIFUSION can provide clinicians with a powerful tool for breast cancer risk assessment.