 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023
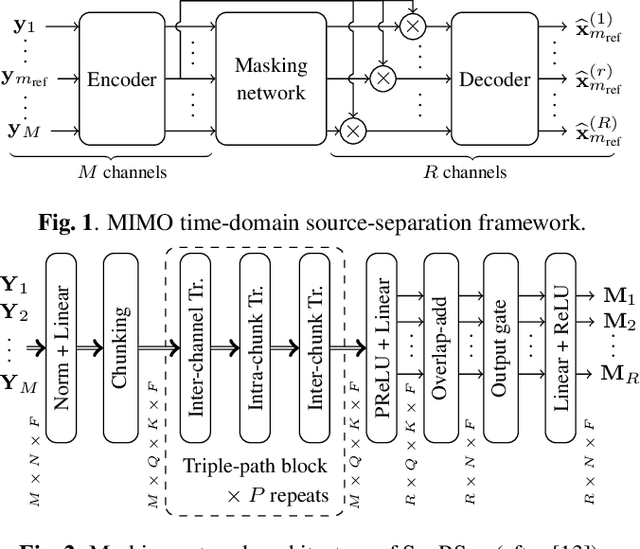
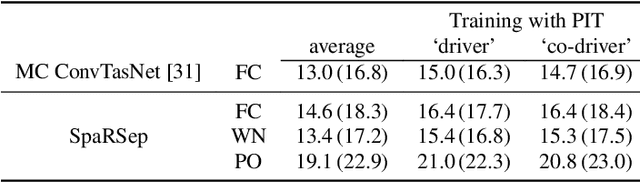
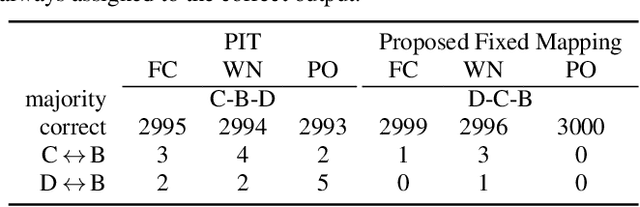

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Level generation for rhythm VR games
Apr 13, 2023
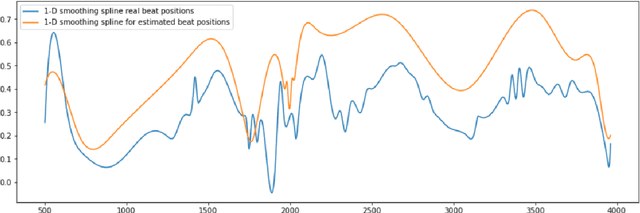
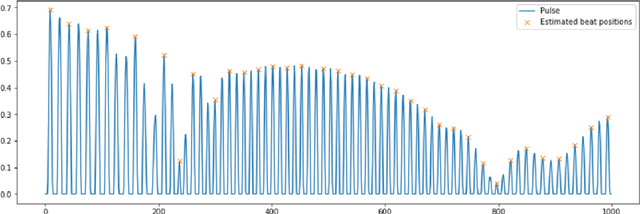
Ragnarock is a virtual reality (VR) rhythm game in which you play a Viking captain competing in a longship race. With two hammers, the task is to crush the incoming runes in sync with epic Viking music. The runes are defined by a beat map which the player can manually create. The creation of beat maps takes hours. This work aims to automate the process of beat map creation, also known as the task of learning to choreograph. The assignment is broken down into three parts: determining the timing of the beats (action placement), determining where in space the runes connected with the chosen beats should be placed (action selection) and web-application creation. For the first task of action placement, extraction of predominant local pulse (PLP) information from music recordings is used. This approach allows to learn where and how many beats are supposed to be placed. For the second task of action selection, Recurrent Neural Networks (RNN) are used, specifically Gated recurrent unit (GRU) to learn sequences of beats, and their patterns to be able to recreate those rules and receive completely new levels. Then the last task was to build a solution for non-technical players, the task was to combine the results of the first and the second parts into a web application for easy use. For this task the frontend was built using JavaScript and React and the backend - python and FastAPI.
Brain Structure Ages -- A new biomarker for multi-disease classification
Apr 13, 2023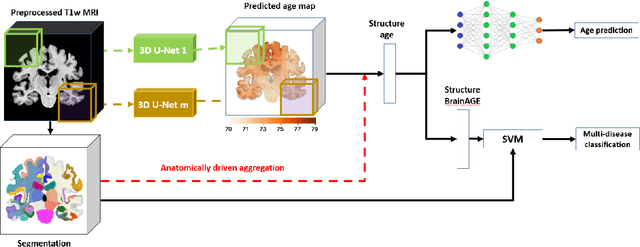
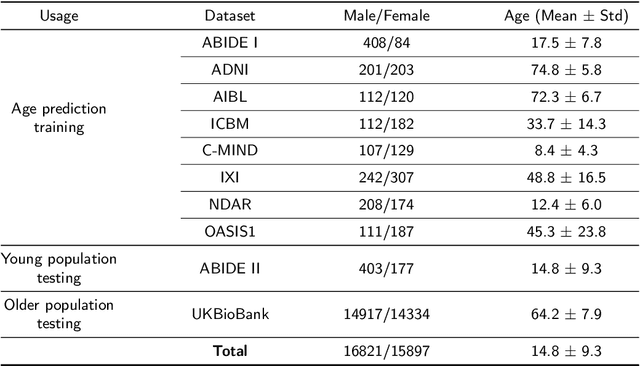
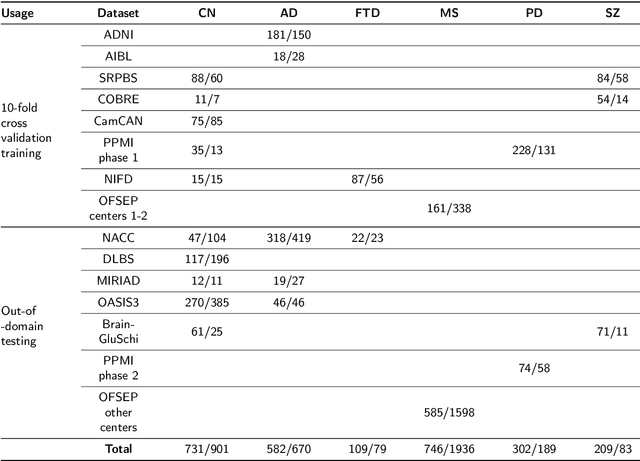
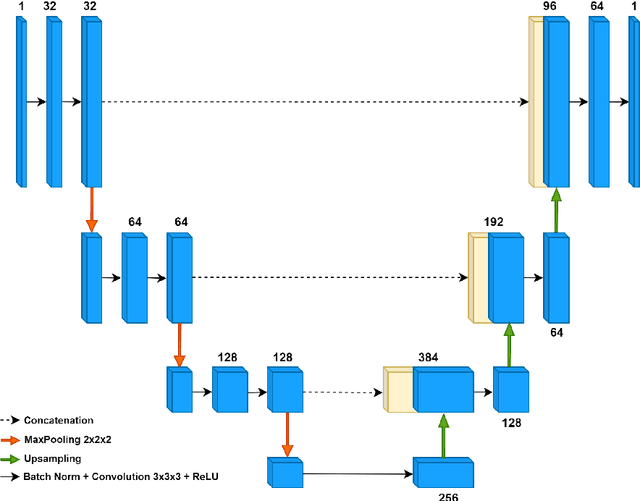
Age is an important variable to describe the expected brain's anatomy status across the normal aging trajectory. The deviation from that normative aging trajectory may provide some insights into neurological diseases. In neuroimaging, predicted brain age is widely used to analyze different diseases. However, using only the brain age gap information (\ie the difference between the chronological age and the estimated age) can be not enough informative for disease classification problems. In this paper, we propose to extend the notion of global brain age by estimating brain structure ages using structural magnetic resonance imaging. To this end, an ensemble of deep learning models is first used to estimate a 3D aging map (\ie voxel-wise age estimation). Then, a 3D segmentation mask is used to obtain the final brain structure ages. This biomarker can be used in several situations. First, it enables to accurately estimate the brain age for the purpose of anomaly detection at the population level. In this situation, our approach outperforms several state-of-the-art methods. Second, brain structure ages can be used to compute the deviation from the normal aging process of each brain structure. This feature can be used in a multi-disease classification task for an accurate differential diagnosis at the subject level. Finally, the brain structure age deviations of individuals can be visualized, providing some insights about brain abnormality and helping clinicians in real medical contexts.
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
Mar 17, 2023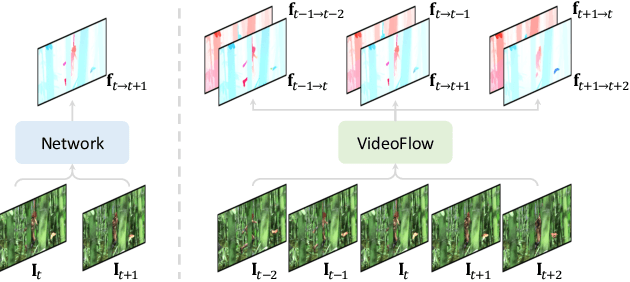
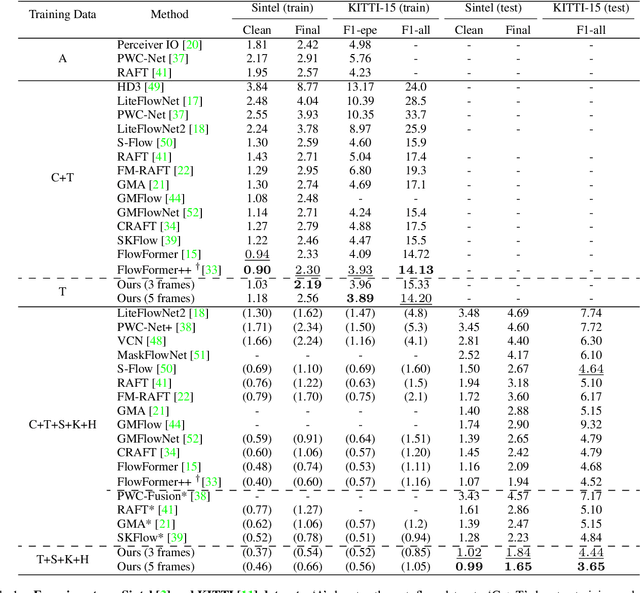
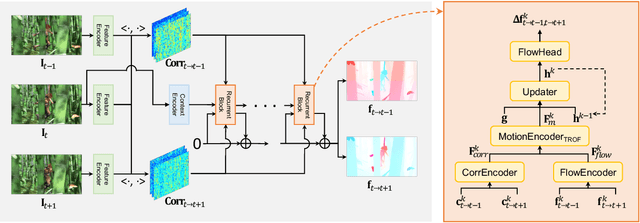
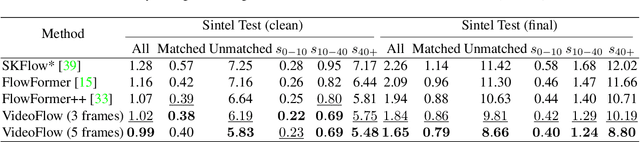
We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best published result (4.52% from FlowFormer++).
Hierarchical Prior Mining for Non-local Multi-View Stereo
Mar 17, 2023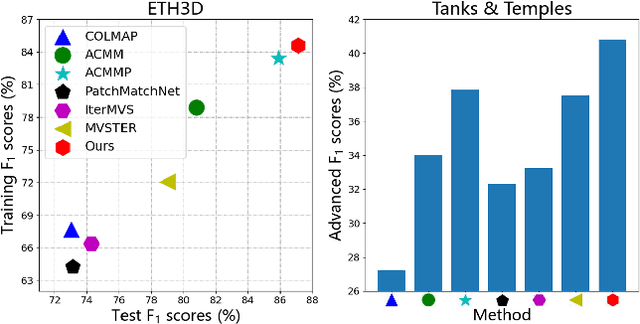
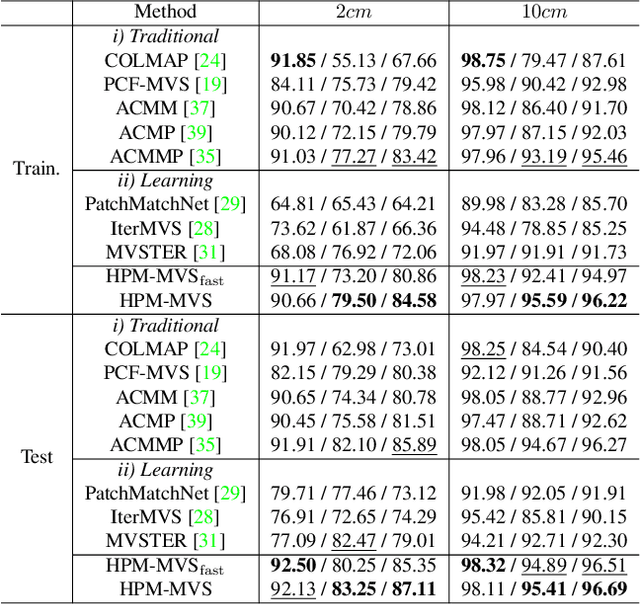
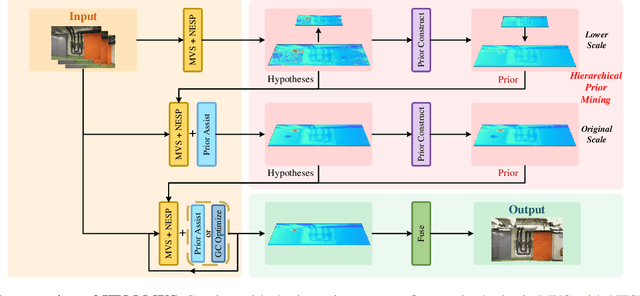
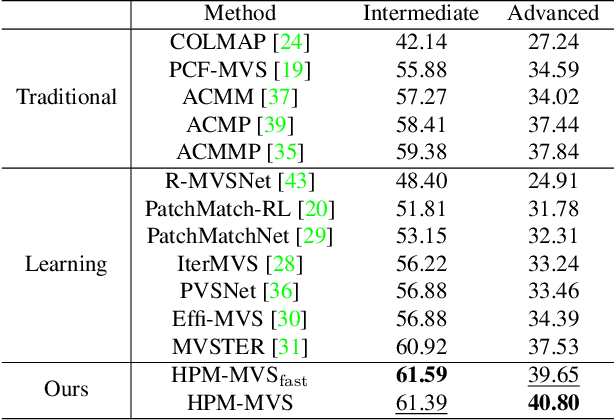
As a fundamental problem in computer vision, multi-view stereo (MVS) aims at recovering the 3D geometry of a target from a set of 2D images. Recent advances in MVS have shown that it is important to perceive non-local structured information for recovering geometry in low-textured areas. In this work, we propose a Hierarchical Prior Mining for Non-local Multi-View Stereo (HPM-MVS). The key characteristics are the following techniques that exploit non-local information to assist MVS: 1) A Non-local Extensible Sampling Pattern (NESP), which is able to adaptively change the size of sampled areas without becoming snared in locally optimal solutions. 2) A new approach to leverage non-local reliable points and construct a planar prior model based on K-Nearest Neighbor (KNN), to obtain potential hypotheses for the regions where prior construction is challenging. 3) A Hierarchical Prior Mining (HPM) framework, which is used to mine extensive non-local prior information at different scales to assist 3D model recovery, this strategy can achieve a considerable balance between the reconstruction of details and low-textured areas. Experimental results on the ETH3D and Tanks \& Temples have verified the superior performance and strong generalization capability of our method. Our code will be released.
Dual Memory Aggregation Network for Event-Based Object Detection with Learnable Representation
Mar 17, 2023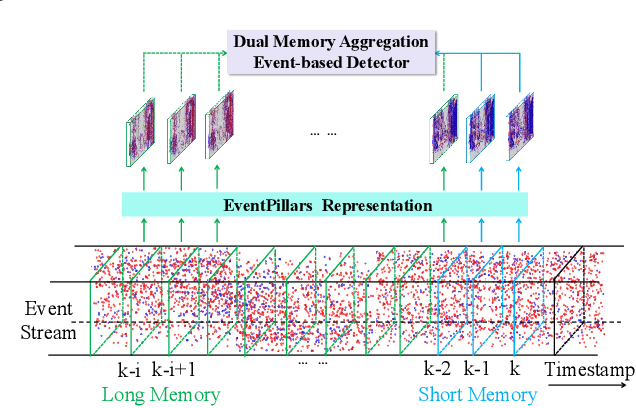

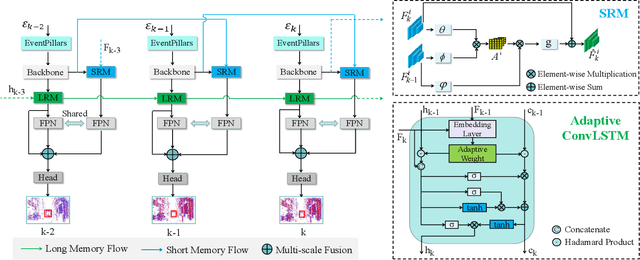
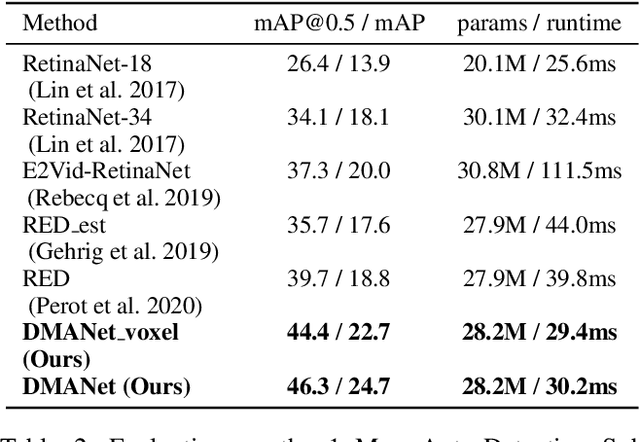
Event-based cameras are bio-inspired sensors that capture brightness change of every pixel in an asynchronous manner. Compared with frame-based sensors, event cameras have microsecond-level latency and high dynamic range, hence showing great potential for object detection under high-speed motion and poor illumination conditions. Due to sparsity and asynchronism nature with event streams, most of existing approaches resort to hand-crafted methods to convert event data into 2D grid representation. However, they are sub-optimal in aggregating information from event stream for object detection. In this work, we propose to learn an event representation optimized for event-based object detection. Specifically, event streams are divided into grids in the x-y-t coordinates for both positive and negative polarity, producing a set of pillars as 3D tensor representation. To fully exploit information with event streams to detect objects, a dual-memory aggregation network (DMANet) is proposed to leverage both long and short memory along event streams to aggregate effective information for object detection. Long memory is encoded in the hidden state of adaptive convLSTMs while short memory is modeled by computing spatial-temporal correlation between event pillars at neighboring time intervals. Extensive experiments on the recently released event-based automotive detection dataset demonstrate the effectiveness of the proposed method.
Unifying Approaches in Data Subset Selection via Fisher Information and Information-Theoretic Quantities
Aug 01, 2022

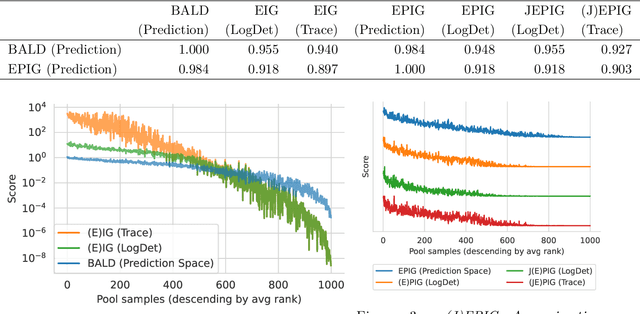
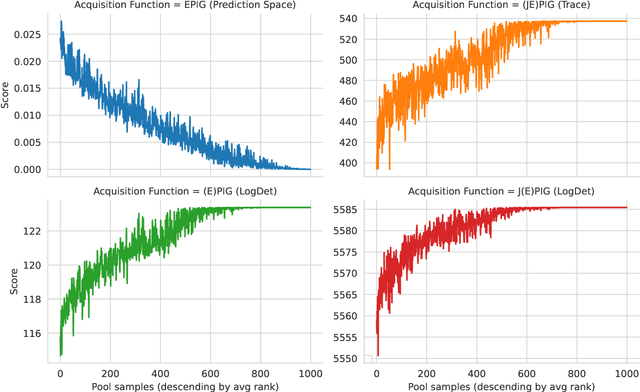
The mutual information between predictions and model parameters -- also referred to as expected information gain or BALD in machine learning -- measures informativeness. It is a popular acquisition function in Bayesian active learning and Bayesian optimal experiment design. In data subset selection, i.e. active learning and active sampling, several recent works use Fisher information, Hessians, similarity matrices based on the gradients, or simply the gradient lengths to compute the acquisition scores that guide sample selection. Are these different approaches connected, and if so how? In this paper, we revisit the Fisher information and use it to show how several otherwise disparate methods are connected as approximations of information-theoretic quantities.
Towards Self-Explainability of Deep Neural Networks with Heatmap Captioning and Large-Language Models
Apr 05, 2023
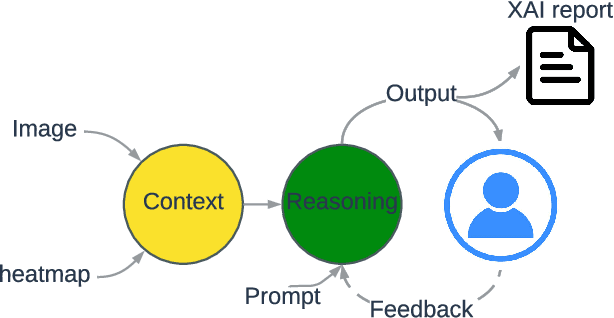
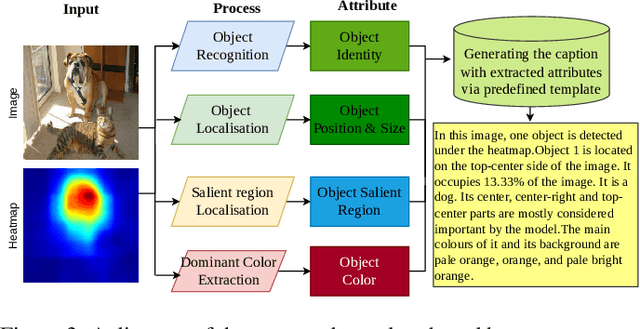
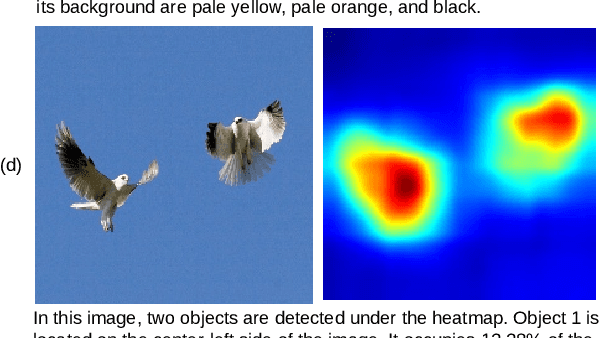
Heatmaps are widely used to interpret deep neural networks, particularly for computer vision tasks, and the heatmap-based explainable AI (XAI) techniques are a well-researched topic. However, most studies concentrate on enhancing the quality of the generated heatmap or discovering alternate heatmap generation techniques, and little effort has been devoted to making heatmap-based XAI automatic, interactive, scalable, and accessible. To address this gap, we propose a framework that includes two modules: (1) context modelling and (2) reasoning. We proposed a template-based image captioning approach for context modelling to create text-based contextual information from the heatmap and input data. The reasoning module leverages a large language model to provide explanations in combination with specialised knowledge. Our qualitative experiments demonstrate the effectiveness of our framework and heatmap captioning approach. The code for the proposed template-based heatmap captioning approach will be publicly available.
Continual Graph Convolutional Network for Text Classification
Apr 09, 2023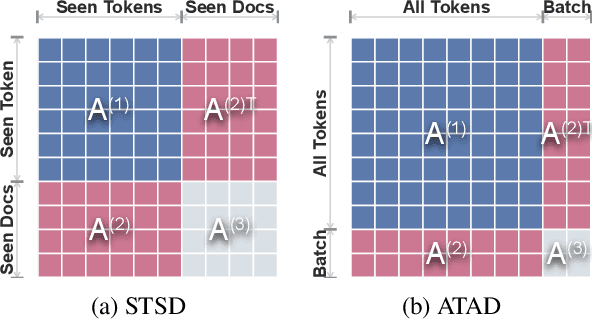
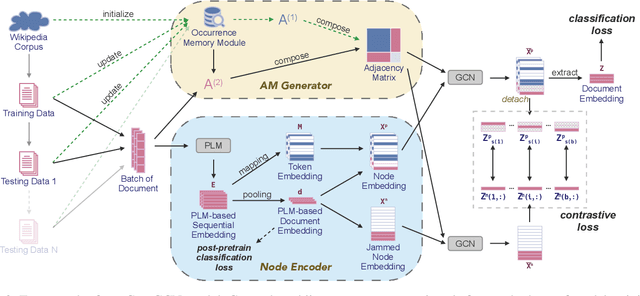
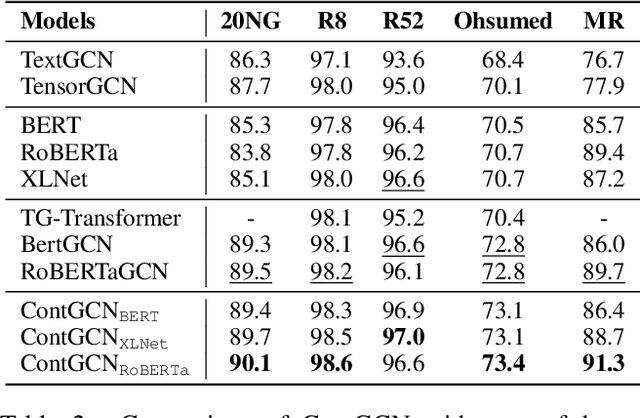
Graph convolutional network (GCN) has been successfully applied to capture global non-consecutive and long-distance semantic information for text classification. However, while GCN-based methods have shown promising results in offline evaluations, they commonly follow a seen-token-seen-document paradigm by constructing a fixed document-token graph and cannot make inferences on new documents. It is a challenge to deploy them in online systems to infer steaming text data. In this work, we present a continual GCN model (ContGCN) to generalize inferences from observed documents to unobserved documents. Concretely, we propose a new all-token-any-document paradigm to dynamically update the document-token graph in every batch during both the training and testing phases of an online system. Moreover, we design an occurrence memory module and a self-supervised contrastive learning objective to update ContGCN in a label-free manner. A 3-month A/B test on Huawei public opinion analysis system shows ContGCN achieves 8.86% performance gain compared with state-of-the-art methods. Offline experiments on five public datasets also show ContGCN can improve inference quality. The source code will be released at https://github.com/Jyonn/ContGCN.
Pretrained Embeddings for E-commerce Machine Learning: When it Fails and Why?
Apr 09, 2023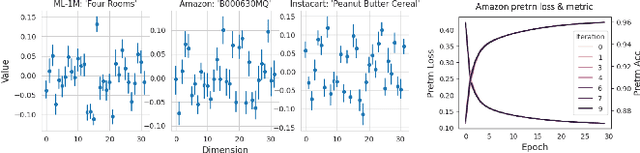
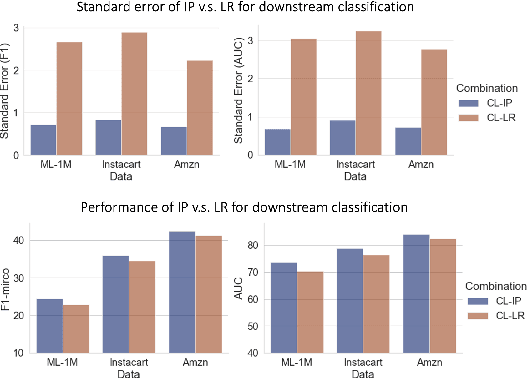
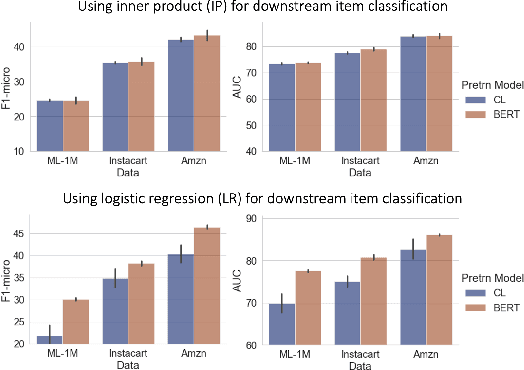
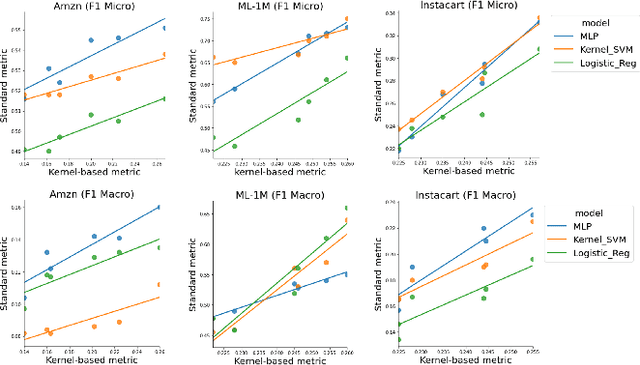
The use of pretrained embeddings has become widespread in modern e-commerce machine learning (ML) systems. In practice, however, we have encountered several key issues when using pretrained embedding in a real-world production system, many of which cannot be fully explained by current knowledge. Unfortunately, we find that there is a lack of a thorough understanding of how pre-trained embeddings work, especially their intrinsic properties and interactions with downstream tasks. Consequently, it becomes challenging to make interactive and scalable decisions regarding the use of pre-trained embeddings in practice. Our investigation leads to two significant discoveries about using pretrained embeddings in e-commerce applications. Firstly, we find that the design of the pretraining and downstream models, particularly how they encode and decode information via embedding vectors, can have a profound impact. Secondly, we establish a principled perspective of pre-trained embeddings via the lens of kernel analysis, which can be used to evaluate their predictability, interactively and scalably. These findings help to address the practical challenges we faced and offer valuable guidance for successful adoption of pretrained embeddings in real-world production. Our conclusions are backed by solid theoretical reasoning, benchmark experiments, as well as online testings.