 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Static Fuzzy Bag-of-Words: a lightweight sentence embedding algorithm
Apr 06, 2023
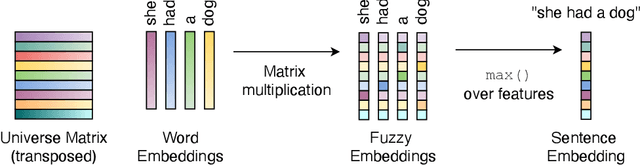

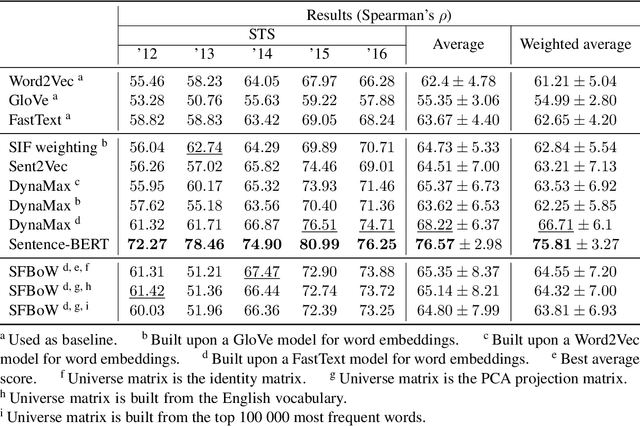
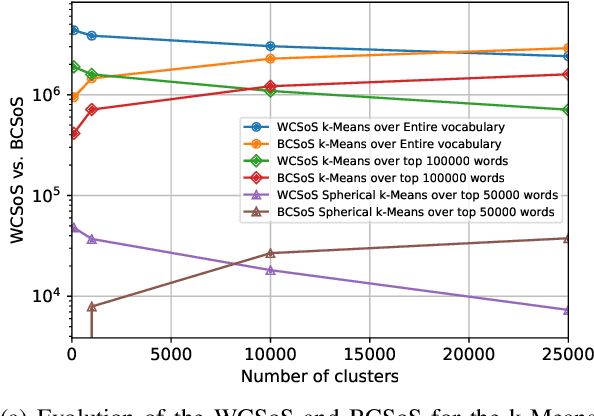
The introduction of embedding techniques has pushed forward significantly the Natural Language Processing field. Many of the proposed solutions have been presented for word-level encoding; anyhow, in the last years, new mechanism to treat information at an higher level of aggregation, like at sentence- and document-level, have emerged. With this work we address specifically the sentence embeddings problem, presenting the Static Fuzzy Bag-of-Word model. Our model is a refinement of the Fuzzy Bag-of-Words approach, providing sentence embeddings with a predefined dimension. SFBoW provides competitive performances in Semantic Textual Similarity benchmarks, while requiring low computational resources.
* 9 pages, 2 figures
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Mar 30, 2023
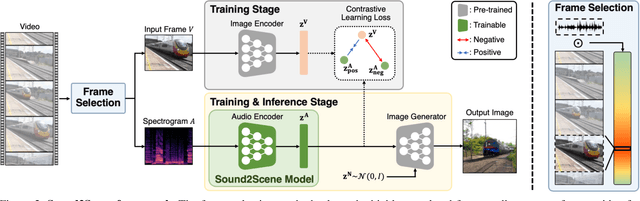


How does audio describe the world around us? In this paper, we propose a method for generating an image of a scene from sound. Our method addresses the challenges of dealing with the large gaps that often exist between sight and sound. We design a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. We translate the input audio to visual features, then use a pre-trained generator to produce an image. To further improve the quality of our generated images, we use sound source localization to select the audio-visual pairs that have strong cross-modal correlations. We obtain substantially better results on the VEGAS and VGGSound datasets than prior approaches. We also show that we can control our model's predictions by applying simple manipulations to the input waveform, or to the latent space.
EEG Cortical Source Feature based Hand Kinematics Decoding using Residual CNN-LSTM Neural Network
Apr 13, 2023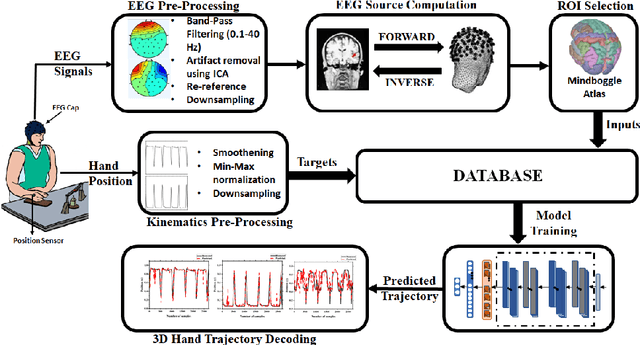
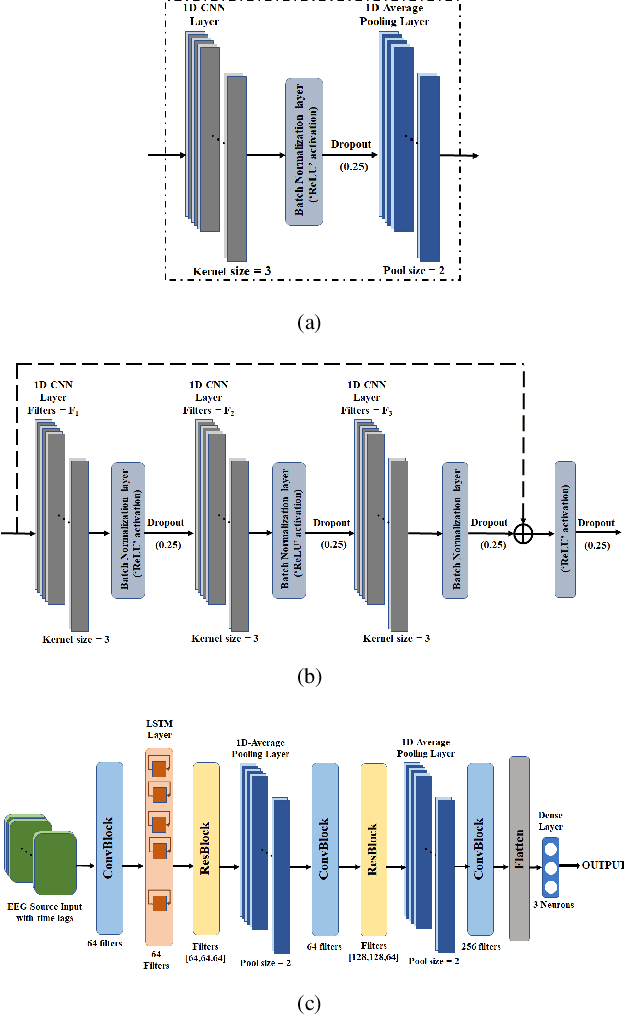
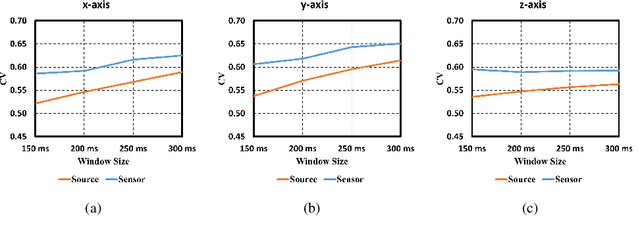
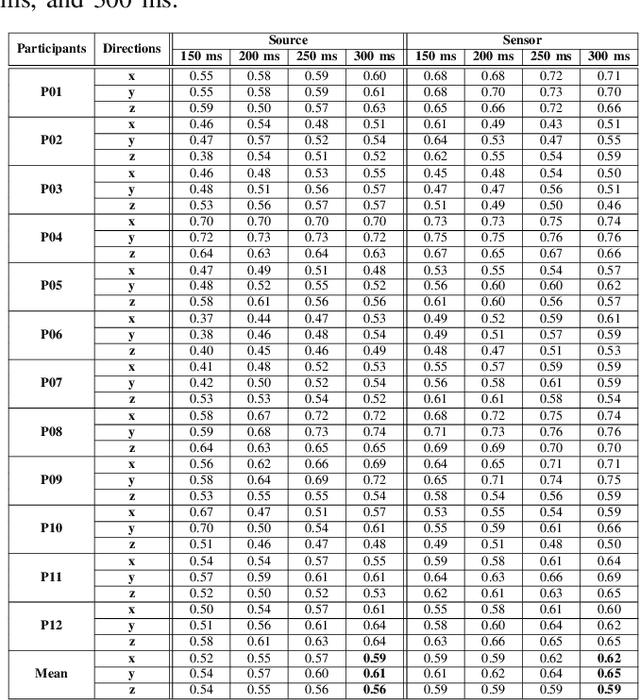
Motor kinematics decoding (MKD) using brain signal is essential to develop Brain-computer interface (BCI) system for rehabilitation or prosthesis devices. Surface electroencephalogram (EEG) signal has been widely utilized for MKD. However, kinematic decoding from cortical sources is sparsely explored. In this work, the feasibility of hand kinematics decoding using EEG cortical source signals has been explored for grasp and lift task. In particular, pre-movement EEG segment is utilized. A residual convolutional neural network (CNN) - long short-term memory (LSTM) based kinematics decoding model is proposed that utilizes motor neural information present in pre-movement brain activity. Various EEG windows at 50 ms prior to movement onset, are utilized for hand kinematics decoding. Correlation value (CV) between actual and predicted hand kinematics is utilized as performance metric for source and sensor domain. The performance of the proposed deep learning model is compared in sensor and source domain. The results demonstrate the viability of hand kinematics decoding using pre-movement EEG cortical source data.
Survey on LiDAR Perception in Adverse Weather Conditions
Apr 13, 2023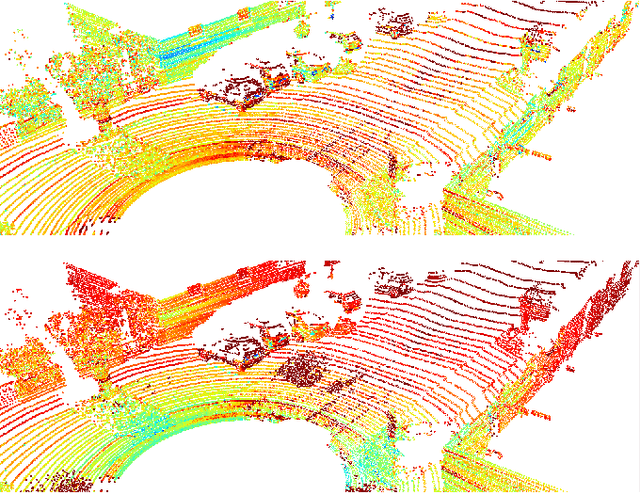
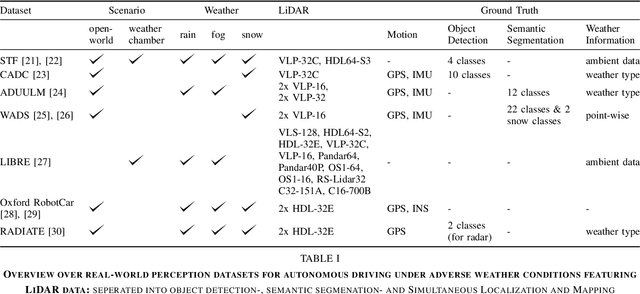
Autonomous vehicles rely on a variety of sensors to gather information about their surrounding. The vehicle's behavior is planned based on the environment perception, making its reliability crucial for safety reasons. The active LiDAR sensor is able to create an accurate 3D representation of a scene, making it a valuable addition for environment perception for autonomous vehicles. Due to light scattering and occlusion, the LiDAR's performance change under adverse weather conditions like fog, snow or rain. This limitation recently fostered a large body of research on approaches to alleviate the decrease in perception performance. In this survey, we gathered, analyzed, and discussed different aspects on dealing with adverse weather conditions in LiDAR-based environment perception. We address topics such as the availability of appropriate data, raw point cloud processing and denoising, robust perception algorithms and sensor fusion to mitigate adverse weather induced shortcomings. We furthermore identify the most pressing gaps in the current literature and pinpoint promising research directions.
PointCLIMB: An Exemplar-Free Point Cloud Class Incremental Benchmark
Apr 13, 2023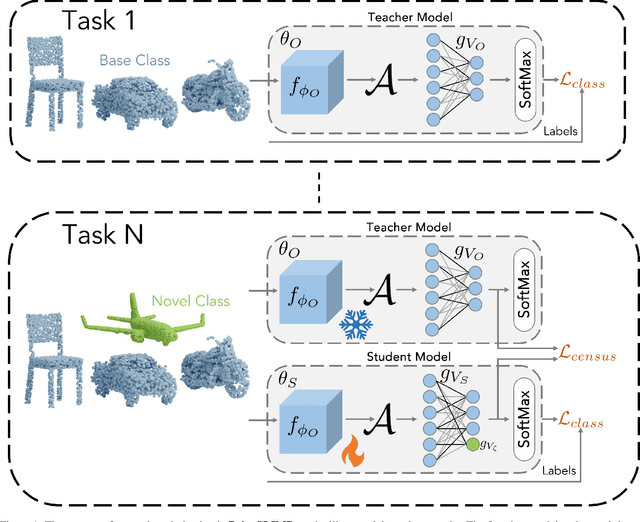
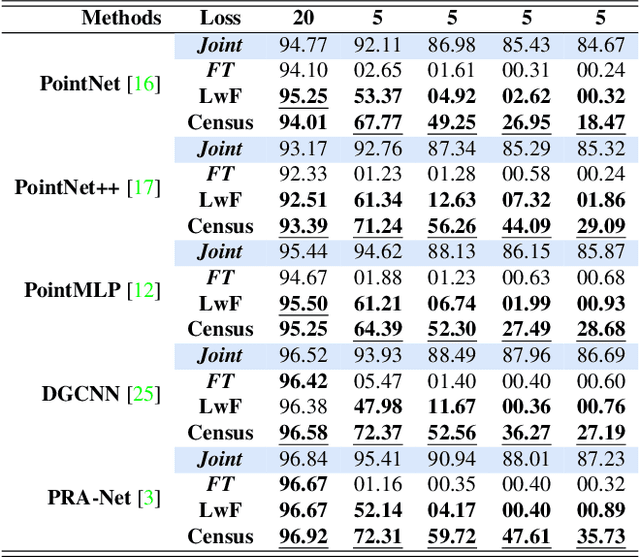


Point clouds offer comprehensive and precise data regarding the contour and configuration of objects. Employing such geometric and topological 3D information of objects in class incremental learning can aid endless application in 3D-computer vision. Well known 3D-point cloud class incremental learning methods for addressing catastrophic forgetting generally entail the usage of previously encountered data, which can present difficulties in situations where there are restrictions on memory or when there are concerns about the legality of the data. Towards this we pioneer to leverage exemplar free class incremental learning on Point Clouds. In this paper we propose PointCLIMB: An exemplar Free Class Incremental Learning Benchmark. We focus on a pragmatic perspective to consider novel classes for class incremental learning on 3D point clouds. We setup a benchmark for 3D Exemplar free class incremental learning. We investigate performance of various backbones on 3D-Exemplar Free Class Incremental Learning framework. We demonstrate our results on ModelNet40 dataset.
CEIL: A General Classification-Enhanced Iterative Learning Framework for Text Clustering
Apr 20, 2023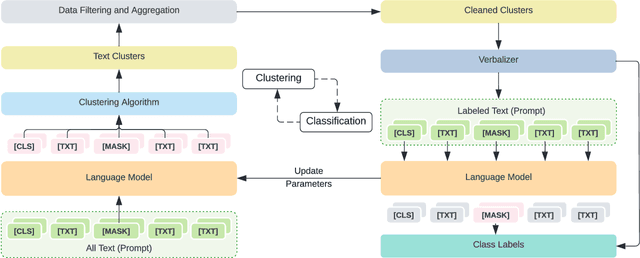
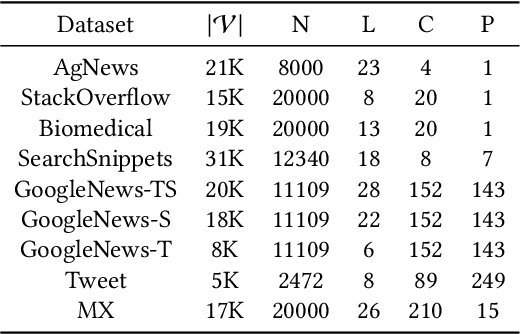

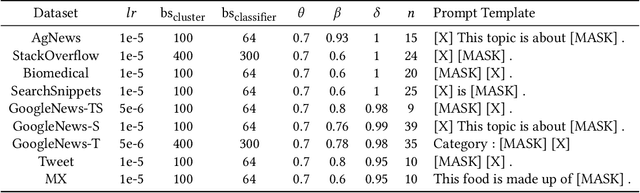
Text clustering, as one of the most fundamental challenges in unsupervised learning, aims at grouping semantically similar text segments without relying on human annotations. With the rapid development of deep learning, deep clustering has achieved significant advantages over traditional clustering methods. Despite the effectiveness, most existing deep text clustering methods rely heavily on representations pre-trained in general domains, which may not be the most suitable solution for clustering in specific target domains. To address this issue, we propose CEIL, a novel Classification-Enhanced Iterative Learning framework for short text clustering, which aims at generally promoting the clustering performance by introducing a classification objective to iteratively improve feature representations. In each iteration, we first adopt a language model to retrieve the initial text representations, from which the clustering results are collected using our proposed Category Disentangled Contrastive Clustering (CDCC) algorithm. After strict data filtering and aggregation processes, samples with clean category labels are retrieved, which serve as supervision information to update the language model with the classification objective via a prompt learning approach. Finally, the updated language model with improved representation ability is used to enhance clustering in the next iteration. Extensive experiments demonstrate that the CEIL framework significantly improves the clustering performance over iterations, and is generally effective on various clustering algorithms. Moreover, by incorporating CEIL on CDCC, we achieve the state-of-the-art clustering performance on a wide range of short text clustering benchmarks outperforming other strong baseline methods.
A geometry-aware deep network for depth estimation in monocular endoscopy
Apr 20, 2023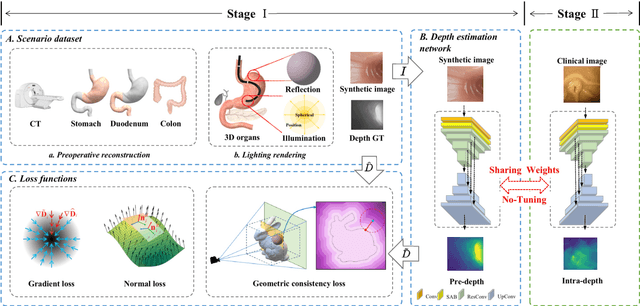
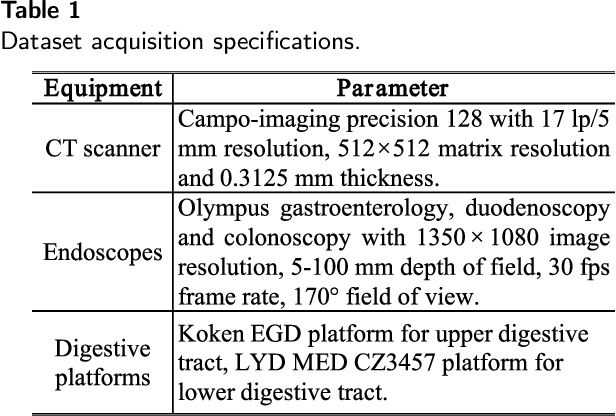
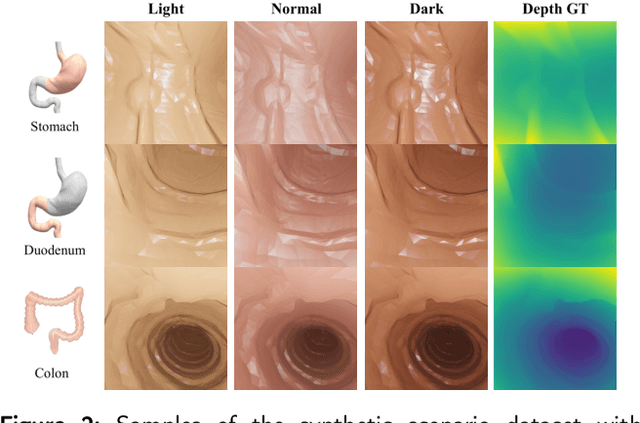
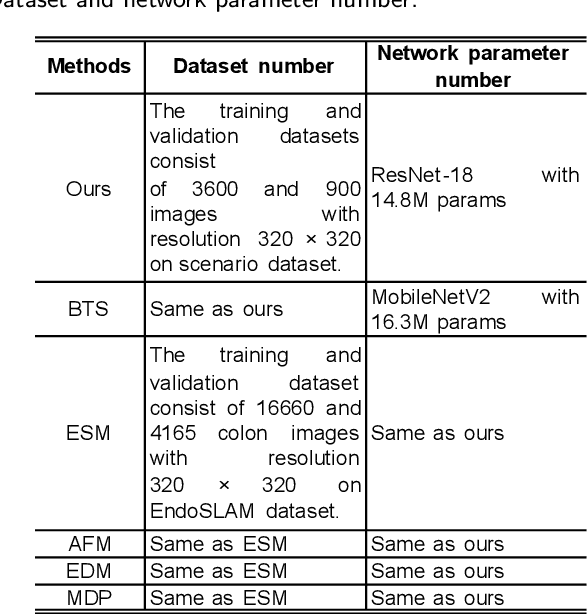
Monocular depth estimation is critical for endoscopists to perform spatial perception and 3D navigation of surgical sites. However, most of the existing methods ignore the important geometric structural consistency, which inevitably leads to performance degradation and distortion of 3D reconstruction. To address this issue, we introduce a gradient loss to penalize edge fluctuations ambiguous around stepped edge structures and a normal loss to explicitly express the sensitivity to frequently small structures, and propose a geometric consistency loss to spreads the spatial information across the sample grids to constrain the global geometric anatomy structures. In addition, we develop a synthetic RGB-Depth dataset that captures the anatomical structures under reflections and illumination variations. The proposed method is extensively validated across different datasets and clinical images and achieves mean RMSE values of 0.066 (stomach), 0.029 (small intestine), and 0.139 (colon) on the EndoSLAM dataset. The generalizability of the proposed method achieves mean RMSE values of 12.604 (T1-L1), 9.930 (T2-L2), and 13.893 (T3-L3) on the ColonDepth dataset. The experimental results show that our method exceeds previous state-of-the-art competitors and generates more consistent depth maps and reasonable anatomical structures. The quality of intraoperative 3D structure perception from endoscopic videos of the proposed method meets the accuracy requirements of video-CT registration algorithms for endoscopic navigation. The dataset and the source code will be available at https://github.com/YYM-SIA/LINGMI-MR.
Too sick for surveillance: Can federal HIV service data improve federal HIV surveillance efforts?
Apr 20, 2023
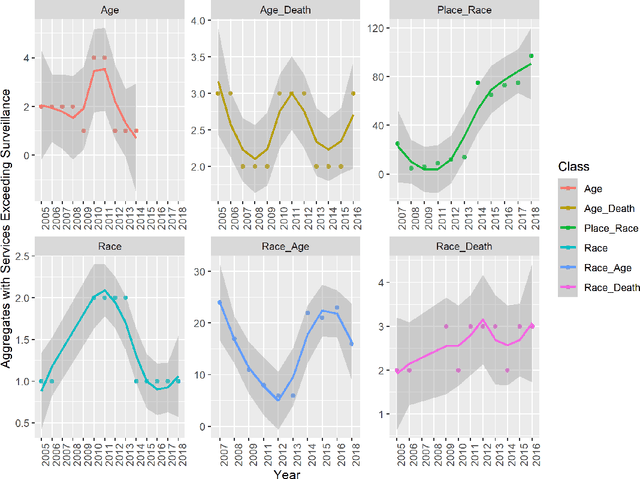
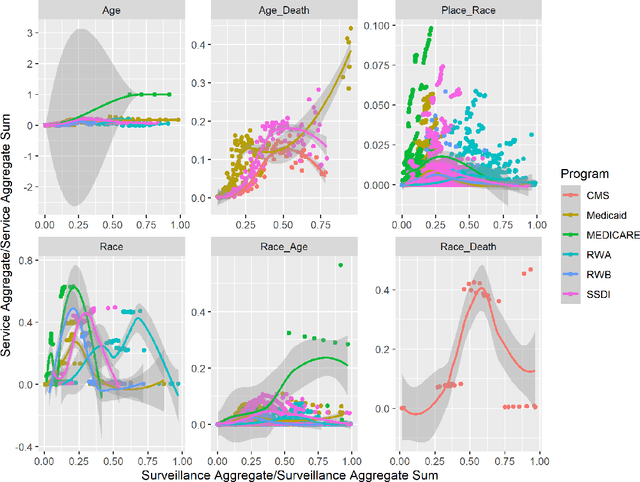
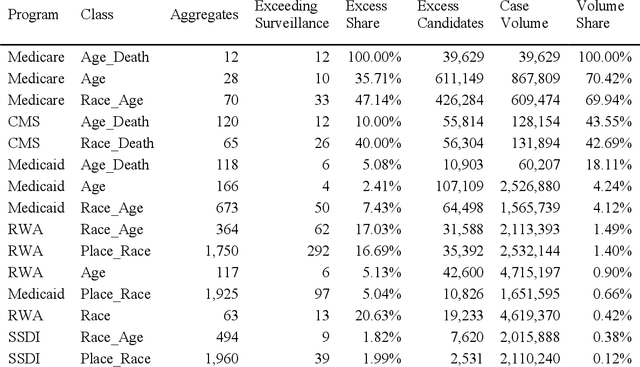
Introduction: The value of integrating federal HIV services data with HIV surveillance is currently unknown. Upstream and complete case capture is essential in preventing future HIV transmission. Methods: This study integrated Ryan White, Social Security Disability Insurance, Medicare, Children Health Insurance Programs and Medicaid demographic aggregates from 2005 to 2018 for people living with HIV and compared them with Centers for Disease Control and Prevention HIV surveillance by demographic aggregate. Surveillance Unknown, Service Known (SUSK) candidate aggregates were identified from aggregates where services aggregate volumes exceeded surveillance aggregate volumes. A distribution approach and a deep learning model series were used to identify SUSK candidate aggregates where surveillance cases exceeded services cases in aggregate. Results: Medicare had the most candidate SUSK aggregates. Medicaid may have candidate SUSK aggregates where cases approach parity with surveillance. Deep learning was able to detect candidate SUSK aggregates even where surveillance cases exceed service cases. Conclusions: Integration of CMS case level records with HIV surveillance records can increase case discovery and life course model quality; especially for cases who die after seeking HIV services but before they become surveillance cases. The ethical implications for both the availability and reuse of clinical HIV Data without the knowledge and consent of the persons described remains an opportunity for the development of big data ethics in public health research. Future work should develop big data ethics to support researchers and assure their subjects that information which describes them is not misused.
Deep reproductive feature generation framework for the diagnosis of COVID-19 and viral pneumonia using chest X-ray images
Apr 20, 2023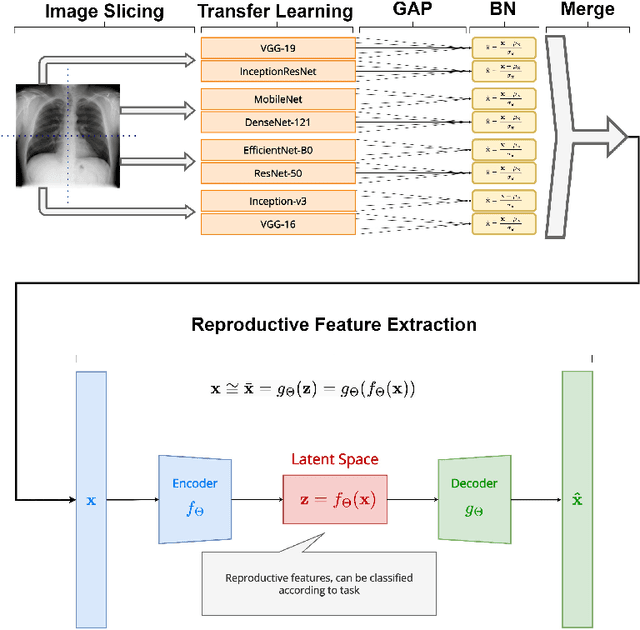
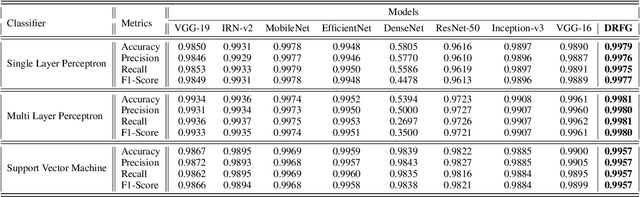
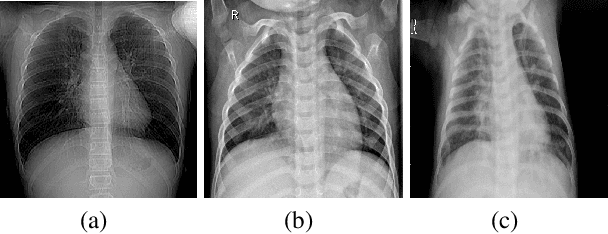
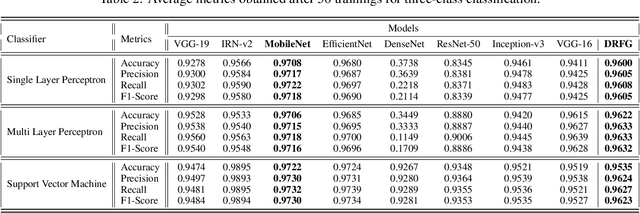
The rapid and accurate detection of COVID-19 cases is critical for timely treatment and preventing the spread of the disease. In this study, a two-stage feature extraction framework using eight state-of-the-art pre-trained deep Convolutional Neural Networks (CNNs) and an autoencoder is proposed to determine the health conditions of patients (COVID-19, Normal, Viral Pneumonia) based on chest X-rays. The X-ray scans are divided into four equally sized sections and analyzed by deep pre-trained CNNs. Subsequently, an autoencoder with three hidden layers is trained to extract reproductive features from the concatenated ouput of CNNs. To evaluate the performance of the proposed framework, three different classifiers, which are single-layer perceptron (SLP), multi-layer perceptron (MLP), and support vector machine (SVM) are used. Furthermore, the deep CNN architectures are used to create benchmark models and trained on the same dataset for comparision. The proposed framework outperforms other frameworks wih pre-trained feature extractors in binary classification and shows competitive results in three-class classification. The proposed methodology is task-independent and suitable for addressing various problems. The results show that the discriminative features are a subset of the reproductive features, suggesting that extracting task-independent features is superior to the extraction only task-based features. The flexibility and task-independence of the reproductive features make the conceptive information approach more favorable. The proposed methodology is novel and shows promising results for analyzing medical image data.
Prompt-Learning for Cross-Lingual Relation Extraction
Apr 20, 2023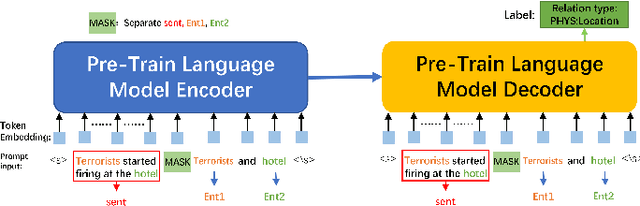
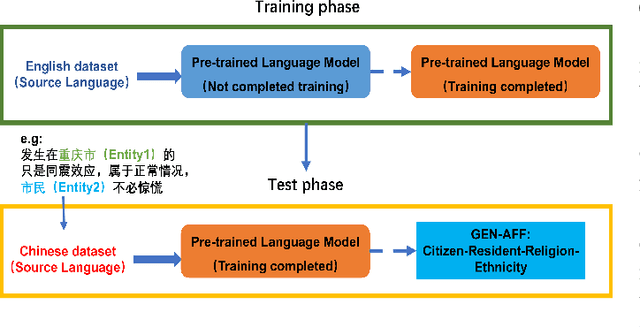
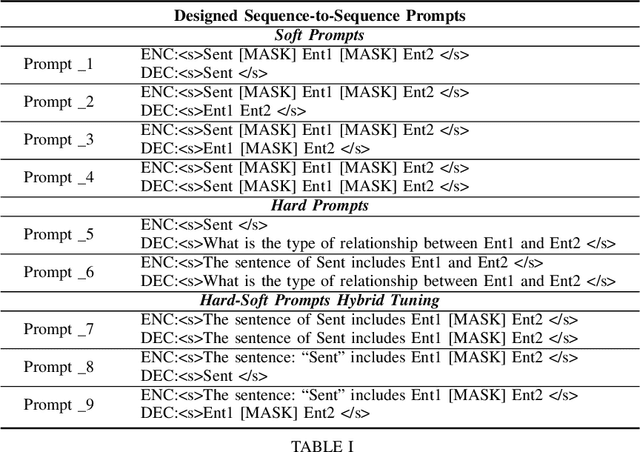
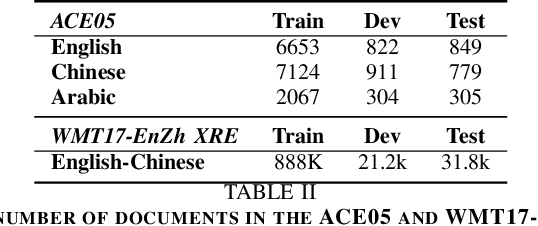
Relation Extraction (RE) is a crucial task in Information Extraction, which entails predicting relationships between entities within a given sentence. However, extending pre-trained RE models to other languages is challenging, particularly in real-world scenarios where Cross-Lingual Relation Extraction (XRE) is required. Despite recent advancements in Prompt-Learning, which involves transferring knowledge from Multilingual Pre-trained Language Models (PLMs) to diverse downstream tasks, there is limited research on the effective use of multilingual PLMs with prompts to improve XRE. In this paper, we present a novel XRE algorithm based on Prompt-Tuning, referred to as Prompt-XRE. To evaluate its effectiveness, we design and implement several prompt templates, including hard, soft, and hybrid prompts, and empirically test their performance on competitive multilingual PLMs, specifically mBART. Our extensive experiments, conducted on the low-resource ACE05 benchmark across multiple languages, demonstrate that our Prompt-XRE algorithm significantly outperforms both vanilla multilingual PLMs and other existing models, achieving state-of-the-art performance in XRE. To further show the generalization of our Prompt-XRE on larger data scales, we construct and release a new XRE dataset- WMT17-EnZh XRE, containing 0.9M English-Chinese pairs extracted from WMT 2017 parallel corpus. Experiments on WMT17-EnZh XRE also show the effectiveness of our Prompt-XRE against other competitive baselines. The code and newly constructed dataset are freely available at \url{https://github.com/HSU-CHIA-MING/Prompt-XRE}.