 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MERMAIDE: Learning to Align Learners using Model-Based Meta-Learning
Apr 10, 2023
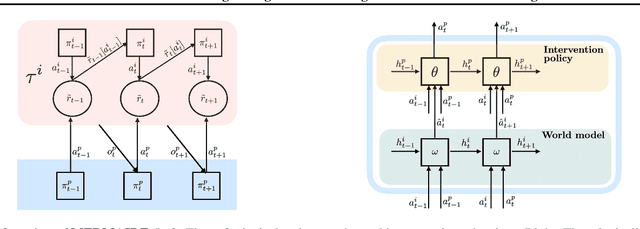
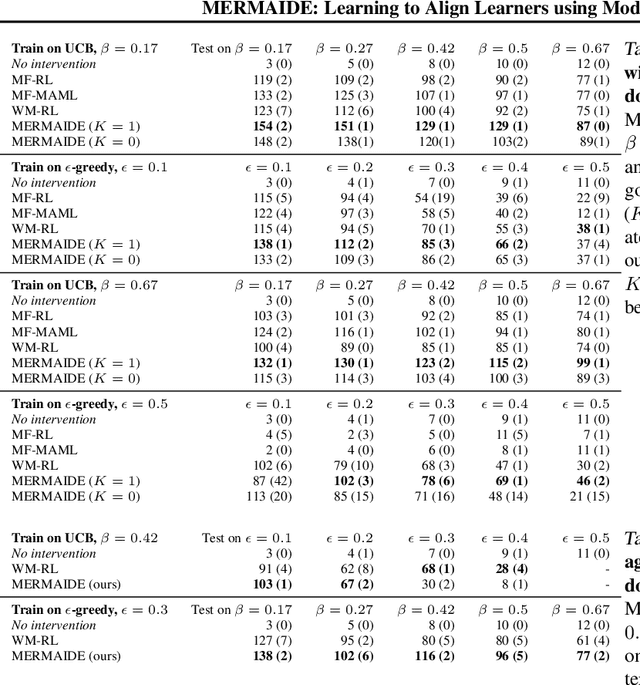
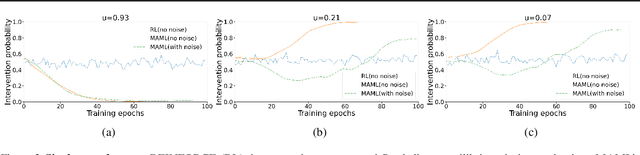
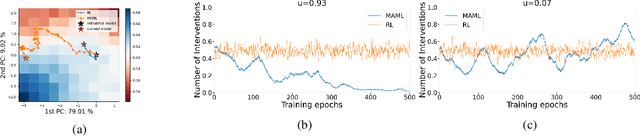
We study how a principal can efficiently and effectively intervene on the rewards of a previously unseen learning agent in order to induce desirable outcomes. This is relevant to many real-world settings like auctions or taxation, where the principal may not know the learning behavior nor the rewards of real people. Moreover, the principal should be few-shot adaptable and minimize the number of interventions, because interventions are often costly. We introduce MERMAIDE, a model-based meta-learning framework to train a principal that can quickly adapt to out-of-distribution agents with different learning strategies and reward functions. We validate this approach step-by-step. First, in a Stackelberg setting with a best-response agent, we show that meta-learning enables quick convergence to the theoretically known Stackelberg equilibrium at test time, although noisy observations severely increase the sample complexity. We then show that our model-based meta-learning approach is cost-effective in intervening on bandit agents with unseen explore-exploit strategies. Finally, we outperform baselines that use either meta-learning or agent behavior modeling, in both $0$-shot and $K=1$-shot settings with partial agent information.
PoseFusion: Robust Object-in-Hand Pose Estimation with SelectLSTM
Apr 10, 2023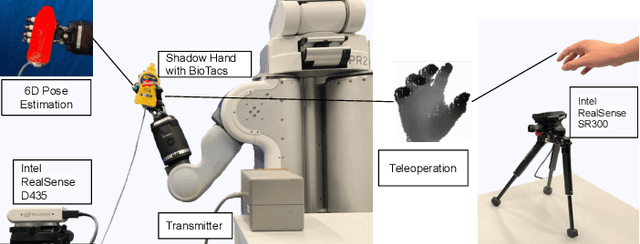
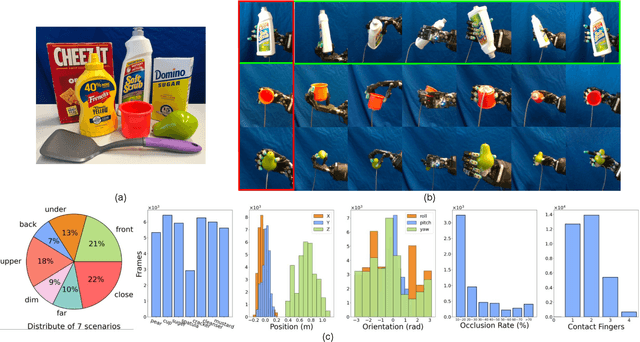

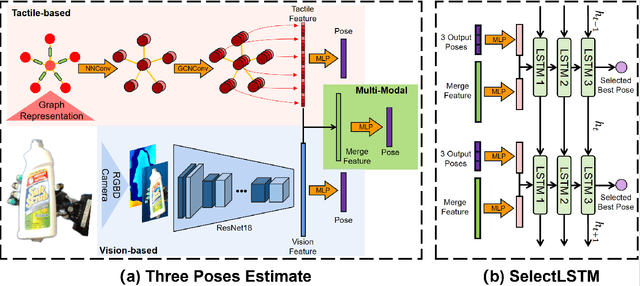
Accurate estimation of the relative pose between an object and a robot hand is critical for many manipulation tasks. However, most of the existing object-in-hand pose datasets use two-finger grippers and also assume that the object remains fixed in the hand without any relative movements, which is not representative of real-world scenarios. To address this issue, a 6D object-in-hand pose dataset is proposed using a teleoperation method with an anthropomorphic Shadow Dexterous hand. Our dataset comprises RGB-D images, proprioception and tactile data, covering diverse grasping poses, finger contact states, and object occlusions. To overcome the significant hand occlusion and limited tactile sensor contact in real-world scenarios, we propose PoseFusion, a hybrid multi-modal fusion approach that integrates the information from visual and tactile perception channels. PoseFusion generates three candidate object poses from three estimators (tactile only, visual only, and visuo-tactile fusion), which are then filtered by a SelectLSTM network to select the optimal pose, avoiding inferior fusion poses resulting from modality collapse. Extensive experiments demonstrate the robustness and advantages of our framework. All data and codes are available on the project website: https://elevenjiang1.github.io/ObjectInHand-Dataset/
Robust Body Exposure (RoBE): A Graph-based Dynamics Modeling Approach to Manipulating Blankets over People
Apr 10, 2023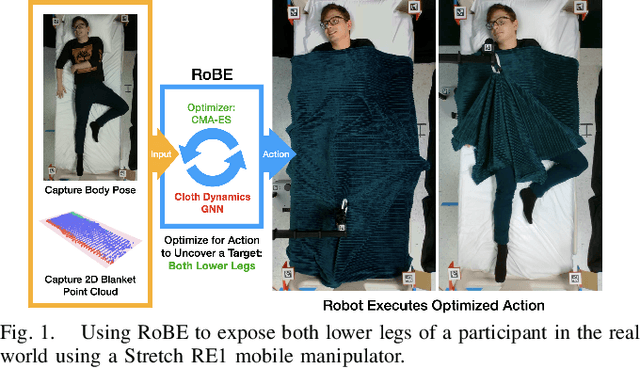



Robotic caregivers could potentially improve the quality of life of many who require physical assistance. However, in order to assist individuals who are lying in bed, robots must be capable of dealing with a significant obstacle: the blanket or sheet that will almost always cover the person's body. We propose a method for targeted bedding manipulation over people lying supine in bed where we first learn a model of the cloth's dynamics. Then, we optimize over this model to uncover a given target limb using information about human body shape and pose that only needs to be provided at run-time. We show how this approach enables greater robustness to variation relative to geometric and reinforcement learning baselines via a number of generalization evaluations in simulation and in the real world. We further evaluate our approach in a human study with 12 participants where we demonstrate that a mobile manipulator can adapt to real variation in human body shape, size, pose, and blanket configuration to uncover target body parts without exposing the rest of the body. Source code and supplementary materials are available online.
MS3D: Leveraging Multiple Detectors for Unsupervised Domain Adaptation in 3D Object Detection
Apr 10, 2023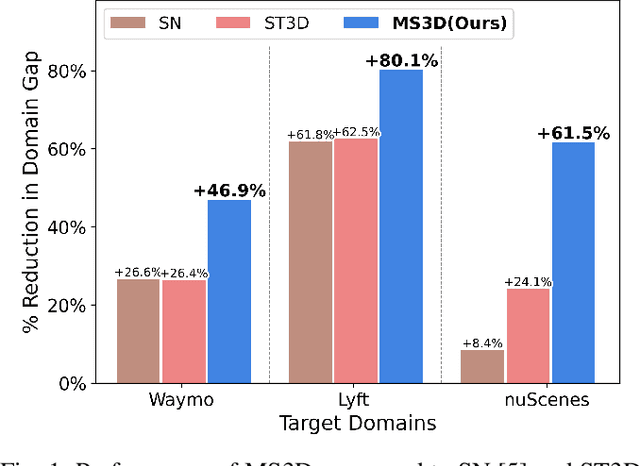
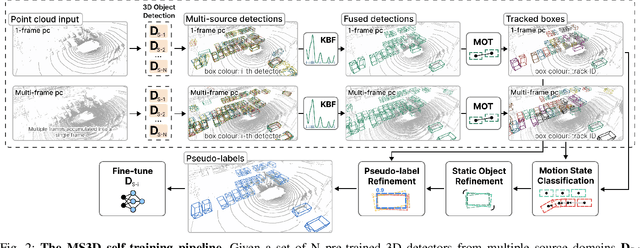
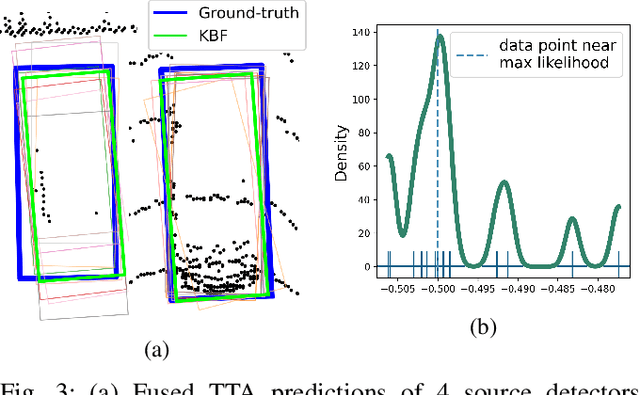
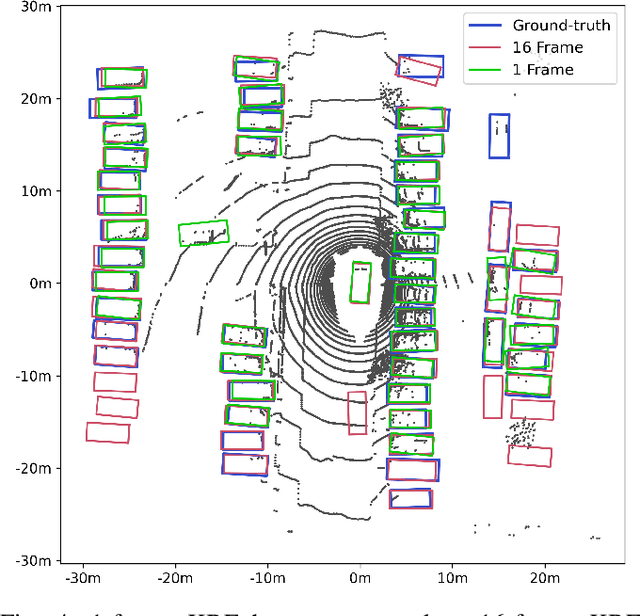
We introduce Multi-Source 3D (MS3D), a new self-training pipeline for unsupervised domain adaptation in 3D object detection. Despite the remarkable accuracy of 3D detectors, they often overfit to specific domain biases, leading to suboptimal performance in various sensor setups and environments. Existing methods typically focus on adapting a single detector to the target domain, overlooking the fact that different detectors possess distinct expertise on different unseen domains. MS3D leverages this by combining different pre-trained detectors from multiple source domains and incorporating temporal information to produce high-quality pseudo-labels for fine-tuning. Our proposed Kernel-Density Estimation (KDE) Box Fusion method fuses box proposals from multiple domains to obtain pseudo-labels that surpass the performance of the best source domain detectors. MS3D exhibits greater robustness to domain shifts and produces accurate pseudo-labels over greater distances, making it well-suited for high-to-low beam domain adaptation and vice versa. Our method achieved state-of-the-art performance on all evaluated datasets, and we demonstrate that the choice of pre-trained source detectors has minimal impact on the self-training result, making MS3D suitable for real-world applications.
Learning solution of nonlinear constitutive material models using physics-informed neural networks: COMM-PINN
Apr 10, 2023
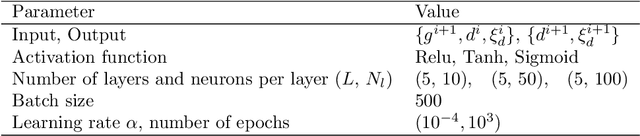
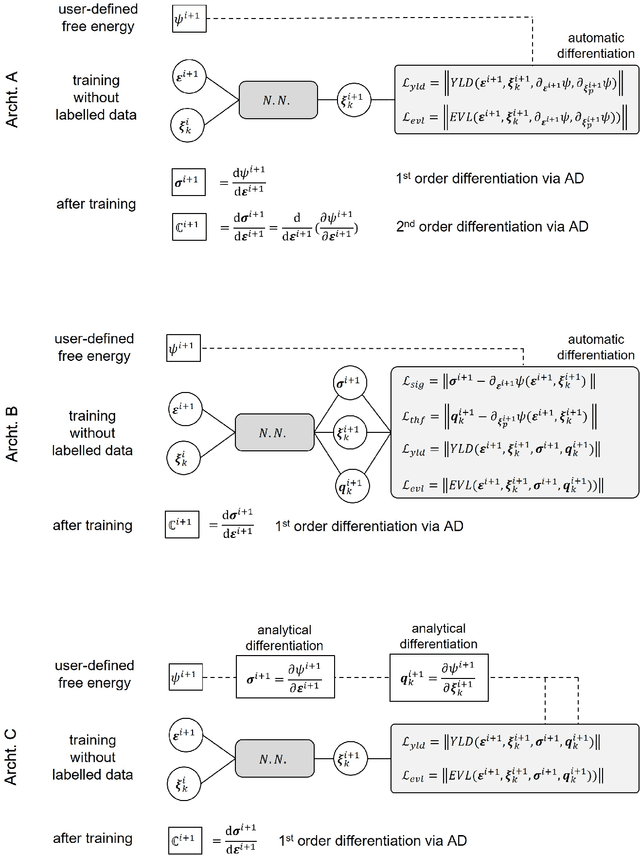

We applied physics-informed neural networks to solve the constitutive relations for nonlinear, path-dependent material behavior. As a result, the trained network not only satisfies all thermodynamic constraints but also instantly provides information about the current material state (i.e., free energy, stress, and the evolution of internal variables) under any given loading scenario without requiring initial data. One advantage of this work is that it bypasses the repetitive Newton iterations needed to solve nonlinear equations in complex material models. Additionally, strategies are provided to reduce the required order of derivation for obtaining the tangent operator. The trained model can be directly used in any finite element package (or other numerical methods) as a user-defined material model. However, challenges remain in the proper definition of collocation points and in integrating several non-equality constraints that become active or non-active simultaneously. We tested this methodology on rate-independent processes such as the classical von Mises plasticity model with a nonlinear hardening law, as well as local damage models for interface cracking behavior with a nonlinear softening law. Finally, we discuss the potential and remaining challenges for future developments of this new approach.
Fast Random Approximation of Multi-channel Room Impulse Response
Apr 17, 2023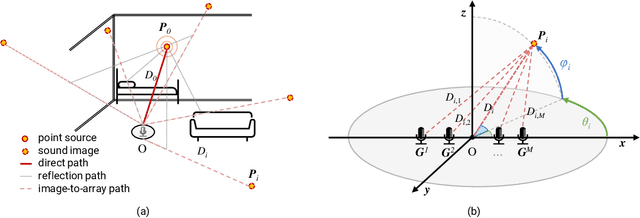
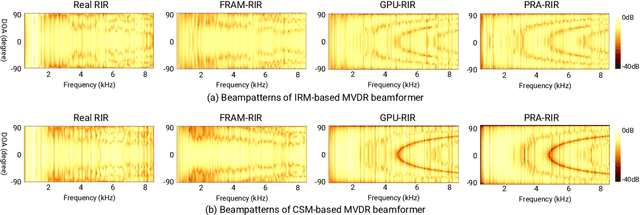
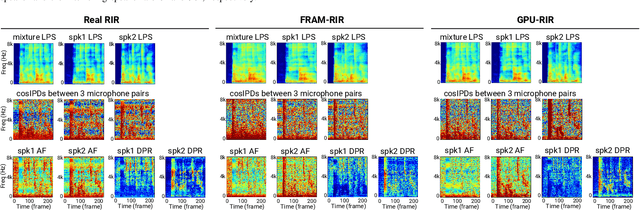
Modern neural-network-based speech processing systems are typically required to be robust against reverberation, and the training of such systems thus needs a large amount of reverberant data. During the training of the systems, on-the-fly simulation pipeline is nowadays preferred as it allows the model to train on infinite number of data samples without pre-generating and saving them on harddisk. An RIR simulation method thus needs to not only generate more realistic artificial room impulse response (RIR) filters, but also generate them in a fast way to accelerate the training process. Existing RIR simulation tools have proven effective in a wide range of speech processing tasks and neural network architectures, but their usage in on-the-fly simulation pipeline remains questionable due to their computational complexity or the quality of the generated RIR filters. In this paper, we propose FRAM-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic multi-channel RIR filters. FRAM-RIR bypasses the explicit calculation of sound propagation paths in ISM-based algorithms by randomly sampling the location and number of reflections of each virtual sound source based on several heuristic assumptions, while still maintains accurate direction-of-arrival (DOA) information of all sound sources. Visualization of oracle beampatterns and directional features shows that FRAM-RIR can generate more realistic RIR filters than existing widely-used ISM-based tools, and experiment results on multi-channel noisy speech separation and dereverberation tasks with a wide range of neural network architectures show that models trained with FRAM-RIR can also achieve on par or better performance on real RIRs compared to other RIR simulation tools with a significantly accelerated training procedure. A Python implementation of FRAM-RIR is released.
Brain Tumor classification and Segmentation using Deep Learning
Apr 16, 2023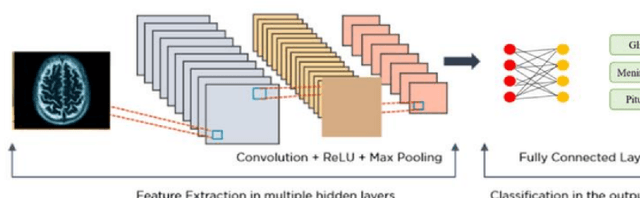
Brain tumors are a complex and potentially life-threatening medical condition that requires accurate diagnosis and timely treatment. In this paper, we present a machine learning-based system designed to assist healthcare professionals in the classification and diagnosis of brain tumors using MRI images. Our system provides a secure login, where doctors can upload or take a photo of MRI and our app can classify the model and segment the tumor, providing the doctor with a folder of each patient's history, name, and results. Our system can also add results or MRI to this folder, draw on the MRI to send it to another doctor, and save important results in a saved page in the app. Furthermore, our system can classify in less than 1 second and allow doctors to chat with a community of brain tumor doctors. To achieve these objectives, our system uses a state-of-the-art machine learning algorithm that has been trained on a large dataset of MRI images. The algorithm can accurately classify different types of brain tumors and provide doctors with detailed information on the size, location, and severity of the tumor. Additionally, our system has several features to ensure its security and privacy, including secure login and data encryption. We evaluated our system using a dataset of real-world MRI images and compared its performance to other existing systems. Our results demonstrate that our system is highly accurate, efficient, and easy to use. We believe that our system has the potential to revolutionize the field of brain tumor diagnosis and treatment and provide healthcare professionals with a powerful tool for improving patient outcomes.
M2GNN: Metapath and Multi-interest Aggregated Graph Neural Network for Tag-based Cross-domain Recommendation
Apr 16, 2023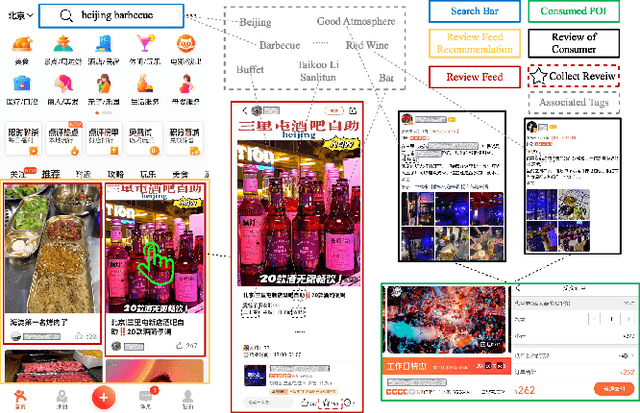
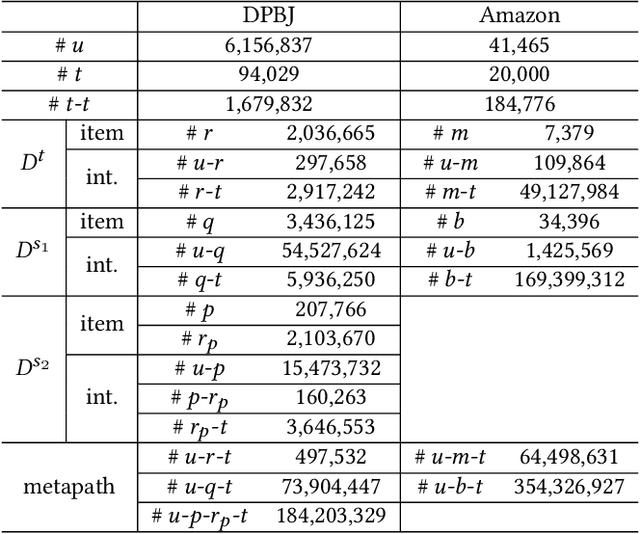
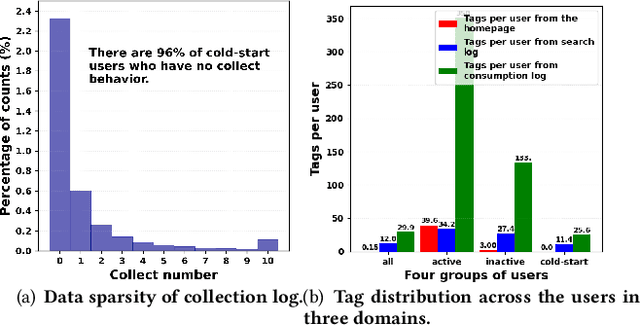
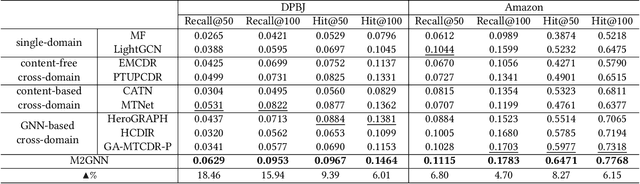
Cross-domain recommendation (CDR) is an effective way to alleviate the data sparsity problem. Content-based CDR is one of the most promising branches since most kinds of products can be described by a piece of text, especially when cold-start users or items have few interactions. However, two vital issues are still under-explored: (1) From the content modeling perspective, sufficient long-text descriptions are usually scarce in a real recommender system, more often the light-weight textual features, such as a few keywords or tags, are more accessible, which is improperly modeled by existing methods. (2) From the CDR perspective, not all inter-domain interests are helpful to infer intra-domain interests. Caused by domain-specific features, there are part of signals benefiting for recommendation in the source domain but harmful for that in the target domain. Therefore, how to distill useful interests is crucial. To tackle the above two problems, we propose a metapath and multi-interest aggregated graph neural network (M2GNN). Specifically, to model the tag-based contents, we construct a heterogeneous information network to hold the semantic relatedness between users, items, and tags in all domains. The metapath schema is predefined according to domain-specific knowledge, with one metapath for one domain. User representations are learned by GNN with a hierarchical aggregation framework, where the intra-metapath aggregation firstly filters out trivial tags and the inter-metapath aggregation further filters out useless interests. Offline experiments and online A/B tests demonstrate that M2GNN achieves significant improvements over the state-of-the-art methods and current industrial recommender system in Dianping, respectively. Further analysis shows that M2GNN offers an interpretable recommendation.
Iteratively Coupled Multiple Instance Learning from Instance to Bag Classifier for Whole Slide Image Classification
Mar 28, 2023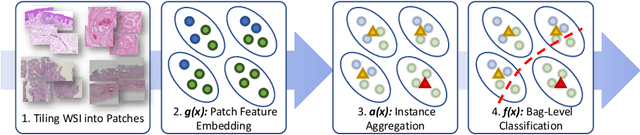

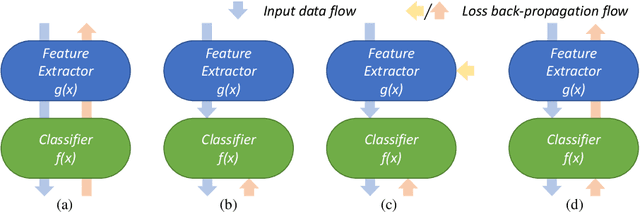
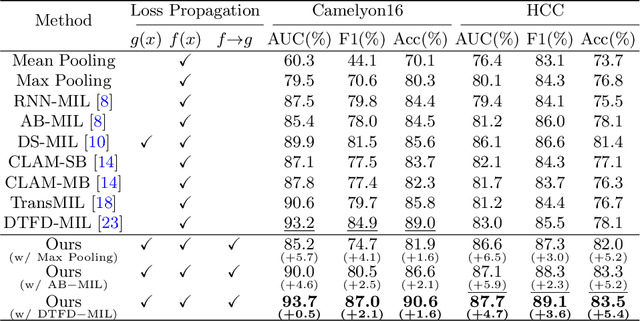
Whole Slide Image (WSI) classification remains a challenge due to their extremely high resolution and the absence of fine-grained labels. Presently, WSIs are usually classified as a Multiple Instance Learning (MIL) problem when only slide-level labels are available. MIL methods involve a patch embedding process and a bag-level classification process, but they are prohibitively expensive to be trained end-to-end. Therefore, existing methods usually train them separately, or directly skip the training of the embedder. Such schemes hinder the patch embedder's access to slide-level labels, resulting in inconsistencies within the entire MIL pipeline. To overcome this issue, we propose a novel framework called Iteratively Coupled MIL (ICMIL), which bridges the loss back-propagation process from the bag-level classifier to the patch embedder. In ICMIL, we use category information in the bag-level classifier to guide the patch-level fine-tuning of the patch feature extractor. The refined embedder then generates better instance representations for achieving a more accurate bag-level classifier. By coupling the patch embedder and bag classifier at a low cost, our proposed framework enables information exchange between the two processes, benefiting the entire MIL classification model. We tested our framework on two datasets using three different backbones, and our experimental results demonstrate consistent performance improvements over state-of-the-art MIL methods. Code will be made available upon acceptance.
PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information
Feb 02, 2023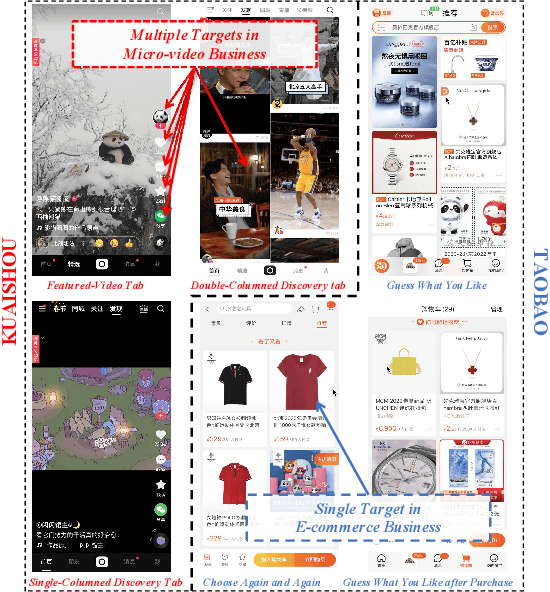
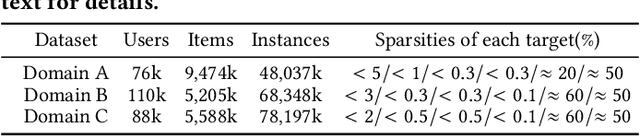
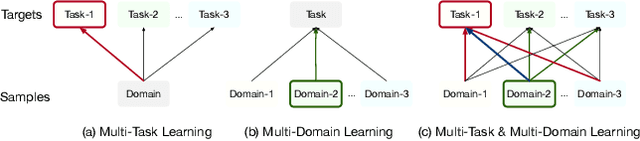
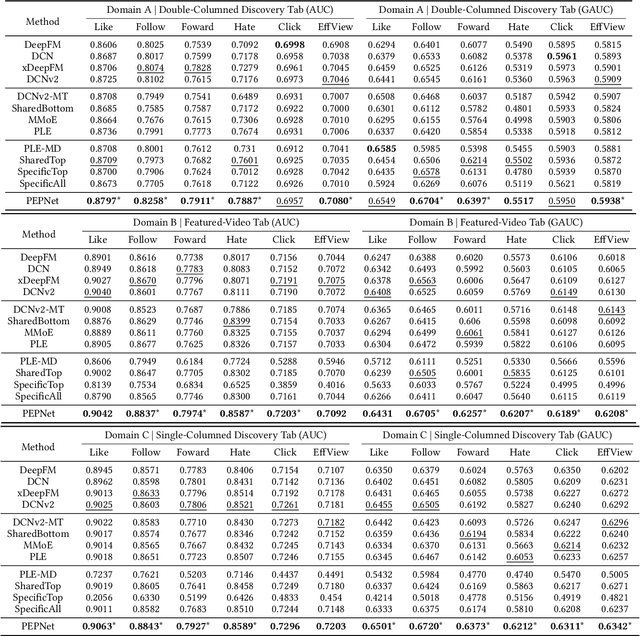
With the increase of pages and buttons in real-world applications, industrial-scale recommender systems face multi-domain and multi-task challenges. On the one hand, users and items in multiple domains suffer inconsistent distributions. On the other hand, multiple tasks have distinctive sparsity and interdependence. Personalization modeling is the core of recommender systems. Accurate personalization estimation helps to capture the degree of user preference for items in different situations, especially in the case of multiple domains and multiple tasks. In multi-task and multi-domain recommendation, how to introduce personalized priors into the model in the right place and in the right way is crucial. In this paper, we propose a plug-and-play Parameter and Embedding Personalized Network (PEPNet) for multi-task recommendation in the multi-domain setting. PEPNet takes features with strong bias as input and dynamically acts on the bottom-layer embeddings or the top-layer DNN hidden units in the model through the gate mechanism. By mapping significant priors to scaling weights ranging from 0 to 2, PEPNet introduces both parameter personalization and embedding personalization. Embedding Personalized Network (EPNet) selects and aligns embeddings with different semantics under multiple domains. Parameter Personalized Network (PPNet) influences DNN parameters to balance interdependent targets in multiple tasks. To further adapt to the characteristics of the model, we have made corresponding engineering optimizations on the Embedding and DNN parameter update strategies. We have deployed the model in Kuaishou and Kuaishou Express apps, serving over 300 million daily users. Both online and offline experiments have demonstrated substantial improvements in multiple metrics. In particular, we have seen a more than 1\% online increase in three major domains.