 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ALADIN-NST: Self-supervised disentangled representation learning of artistic style through Neural Style Transfer
Apr 12, 2023

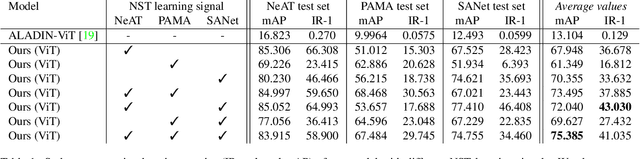
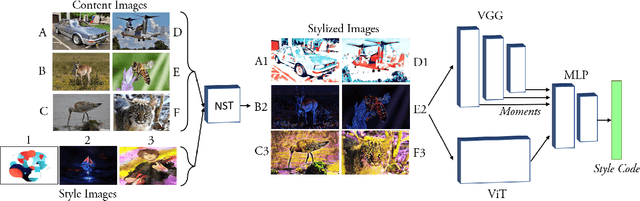
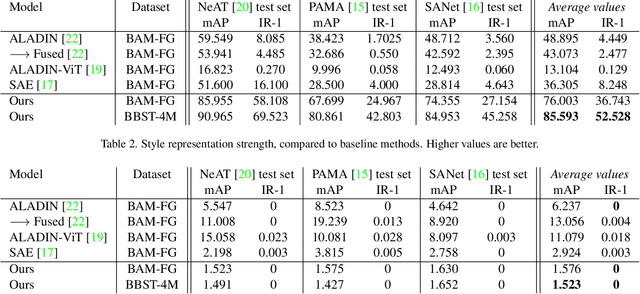
Representation learning aims to discover individual salient features of a domain in a compact and descriptive form that strongly identifies the unique characteristics of a given sample respective to its domain. Existing works in visual style representation literature have tried to disentangle style from content during training explicitly. A complete separation between these has yet to be fully achieved. Our paper aims to learn a representation of visual artistic style more strongly disentangled from the semantic content depicted in an image. We use Neural Style Transfer (NST) to measure and drive the learning signal and achieve state-of-the-art representation learning on explicitly disentangled metrics. We show that strongly addressing the disentanglement of style and content leads to large gains in style-specific metrics, encoding far less semantic information and achieving state-of-the-art accuracy in downstream multimodal applications.
Bi-level Latent Variable Model for Sample-Efficient Multi-Agent Reinforcement Learning
Apr 12, 2023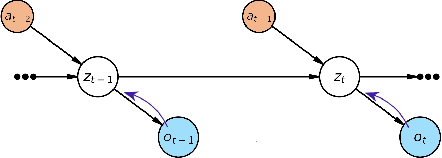
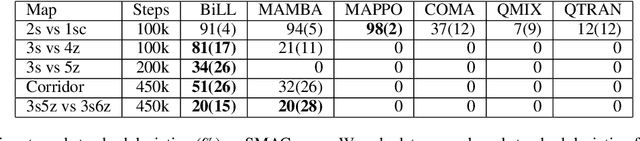
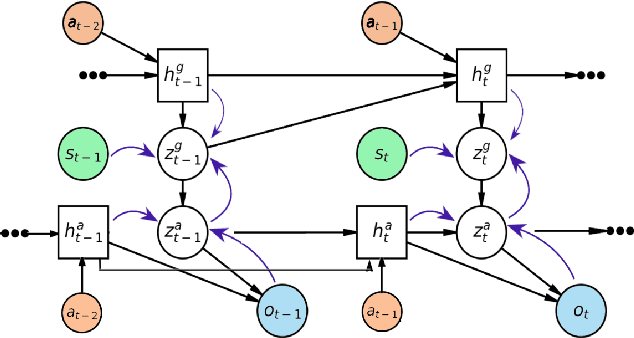
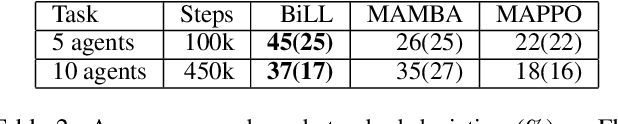
Despite their potential in real-world applications, multi-agent reinforcement learning (MARL) algorithms often suffer from high sample complexity. To address this issue, we present a novel model-based MARL algorithm, BiLL (Bi-Level Latent Variable Model-based Learning), that learns a bi-level latent variable model from high-dimensional inputs. At the top level, the model learns latent representations of the global state, which encode global information relevant to behavior learning. At the bottom level, it learns latent representations for each agent, given the global latent representations from the top level. The model generates latent trajectories to use for policy learning. We evaluate our algorithm on complex multi-agent tasks in the challenging SMAC and Flatland environments. Our algorithm outperforms state-of-the-art model-free and model-based baselines in sample efficiency, including on two extremely challenging Super Hard SMAC maps.
Data-driven Knowledge Fusion for Deep Multi-instance Learning
Apr 24, 2023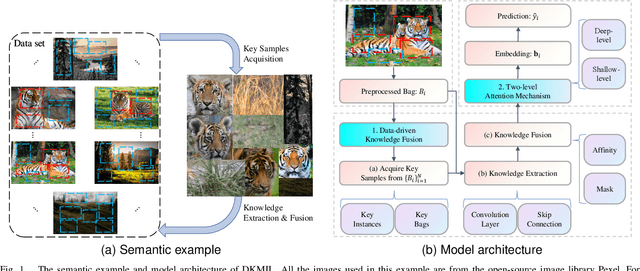
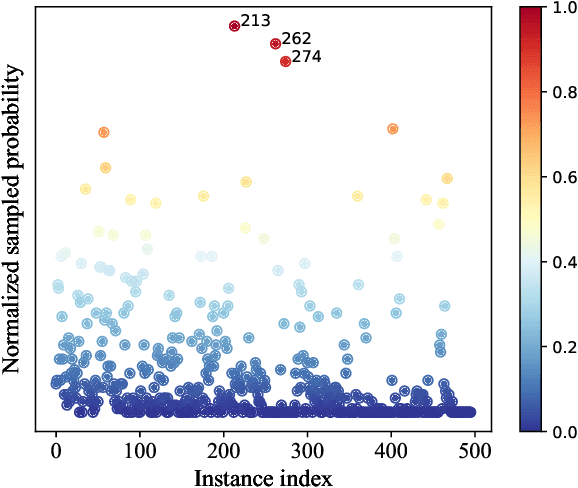
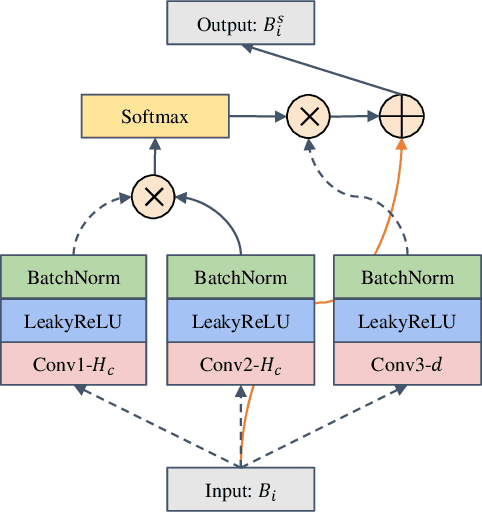
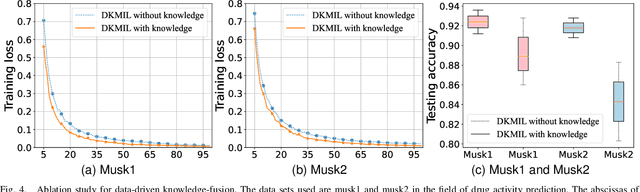
Multi-instance learning (MIL) is a widely-applied technique in practical applications that involve complex data structures. MIL can be broadly categorized into two types: traditional methods and those based on deep learning. These approaches have yielded significant results, especially with regards to their problem-solving strategies and experimental validation, providing valuable insights for researchers in the MIL field. However, a considerable amount of knowledge is often trapped within the algorithm, leading to subsequent MIL algorithms that solely rely on the model's data fitting to predict unlabeled samples. This results in a significant loss of knowledge and impedes the development of more intelligent models. In this paper, we propose a novel data-driven knowledge fusion for deep multi-instance learning (DKMIL) algorithm. DKMIL adopts a completely different idea from existing deep MIL methods by analyzing the decision-making of key samples in the data set (referred to as the data-driven) and using the knowledge fusion module designed to extract valuable information from these samples to assist the model's training. In other words, this module serves as a new interface between data and the model, providing strong scalability and enabling the use of prior knowledge from existing algorithms to enhance the learning ability of the model. Furthermore, to adapt the downstream modules of the model to more knowledge-enriched features extracted from the data-driven knowledge fusion module, we propose a two-level attention module that gradually learns shallow- and deep-level features of the samples to achieve more effective classification. We will prove the scalability of the knowledge fusion module while also verifying the efficacy of the proposed architecture by conducting experiments on 38 data sets across 6 categories.
ShapeShift: Superquadric-based Object Pose Estimation for Robotic Grasping
Apr 10, 2023
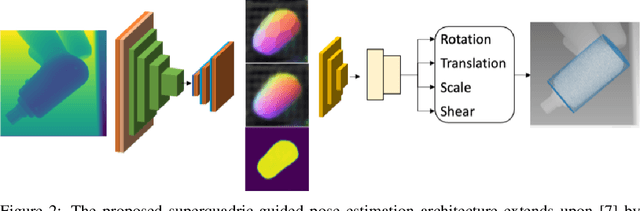
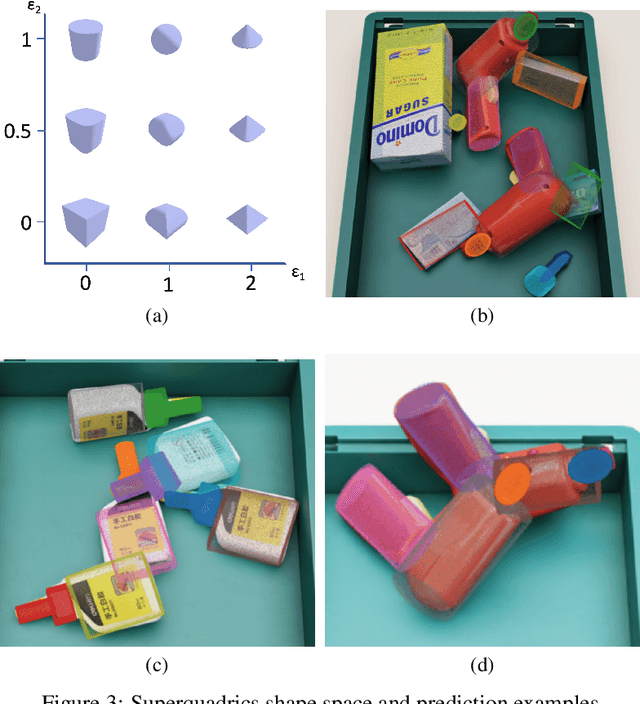
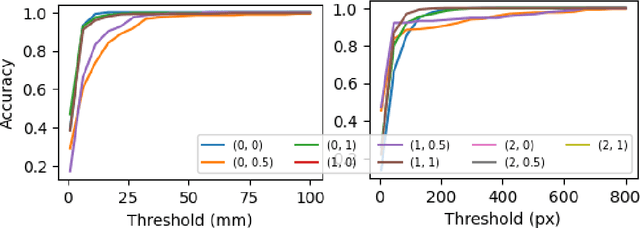
Object pose estimation is a critical task in robotics for precise object manipulation. However, current techniques heavily rely on a reference 3D object, limiting their generalizability and making it expensive to expand to new object categories. Direct pose predictions also provide limited information for robotic grasping without referencing the 3D model. Keypoint-based methods offer intrinsic descriptiveness without relying on an exact 3D model, but they may lack consistency and accuracy. To address these challenges, this paper proposes ShapeShift, a superquadric-based framework for object pose estimation that predicts the object's pose relative to a primitive shape which is fitted to the object. The proposed framework offers intrinsic descriptiveness and the ability to generalize to arbitrary geometric shapes beyond the training set.
DASS Good: Explainable Data Mining of Spatial Cohort Data
Apr 10, 2023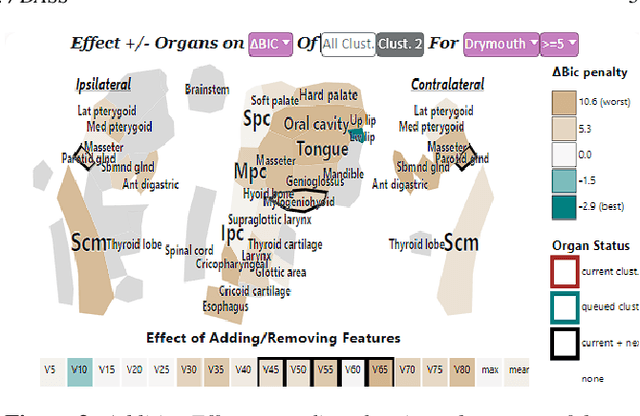
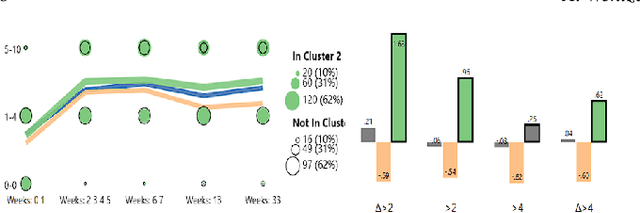
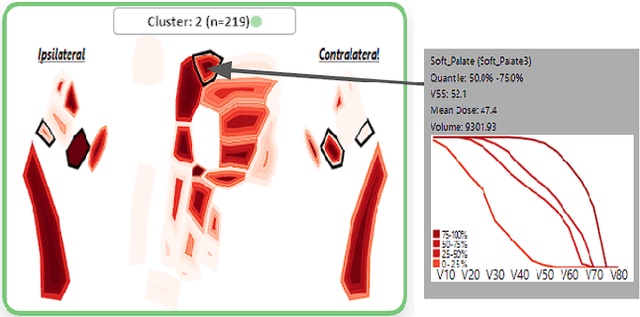
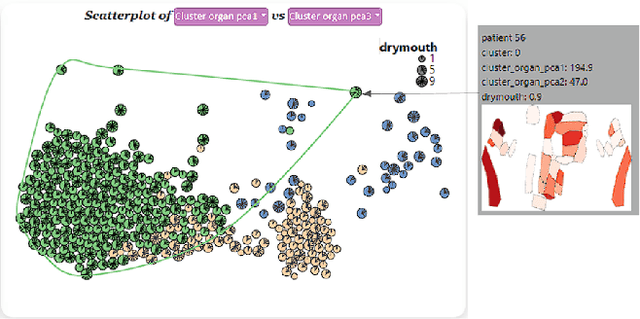
Developing applicable clinical machine learning models is a difficult task when the data includes spatial information, for example, radiation dose distributions across adjacent organs at risk. We describe the co-design of a modeling system, DASS, to support the hybrid human-machine development and validation of predictive models for estimating long-term toxicities related to radiotherapy doses in head and neck cancer patients. Developed in collaboration with domain experts in oncology and data mining, DASS incorporates human-in-the-loop visual steering, spatial data, and explainable AI to augment domain knowledge with automatic data mining. We demonstrate DASS with the development of two practical clinical stratification models and report feedback from domain experts. Finally, we describe the design lessons learned from this collaborative experience.
Silent Abandonment in Contact Centers: Estimating Customer Patience from Uncertain Data
Apr 23, 2023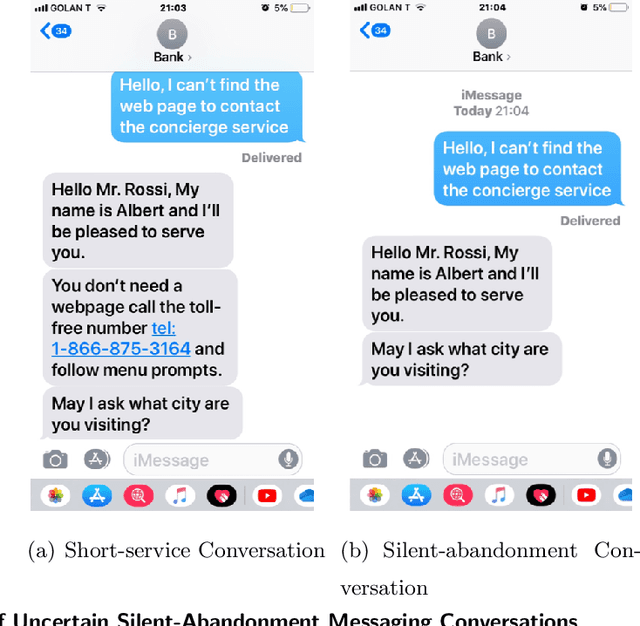
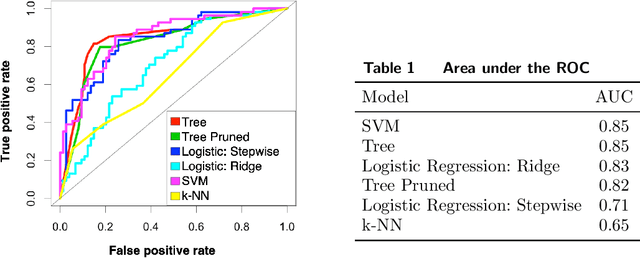

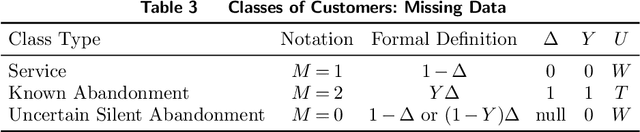
In the quest to improve services, companies offer customers the opportunity to interact with agents through contact centers, where the communication is mainly text-based. This has become one of the favorite channels of communication with companies in recent years. However, contact centers face operational challenges, since the measurement of common proxies for customer experience, such as knowledge of whether customers have abandoned the queue and their willingness to wait for service (patience), are subject to information uncertainty. We focus this research on the impact of a main source of such uncertainty: silent abandonment by customers. These customers leave the system while waiting for a reply to their inquiry, but give no indication of doing so, such as closing the mobile app of the interaction. As a result, the system is unaware that they have left and waste agent time and capacity until this fact is realized. In this paper, we show that 30%-67% of the abandoning customers abandon the system silently, and that such customer behavior reduces system efficiency by 5%-15%. To do so, we develop methodologies to identify silent-abandonment customers in two types of contact centers: chat and messaging systems. We first use text analysis and an SVM model to estimate the actual abandonment level. We then use a parametric estimator and develop an expectation-maximization algorithm to estimate customer patience accurately, as customer patience is an important parameter for fitting queueing models to the data. We show how accounting for silent abandonment in a queueing model improves dramatically the estimation accuracy of key measures of performance. Finally, we suggest strategies to operationally cope with the phenomenon of silent abandonment.
Soft Dynamic Time Warping for Multi-Pitch Estimation and Beyond
Apr 11, 2023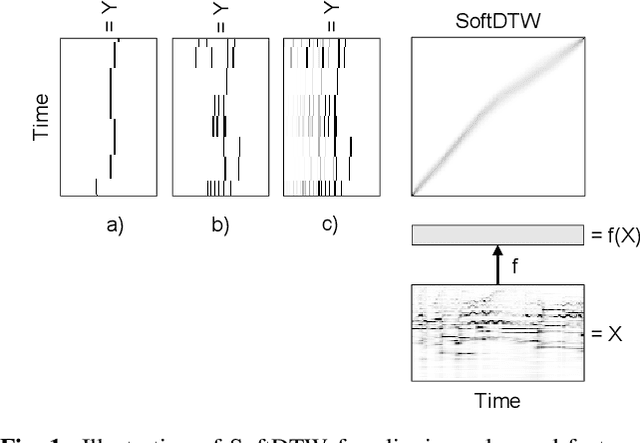
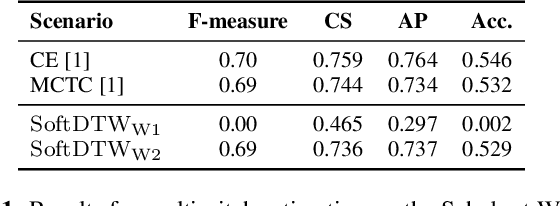
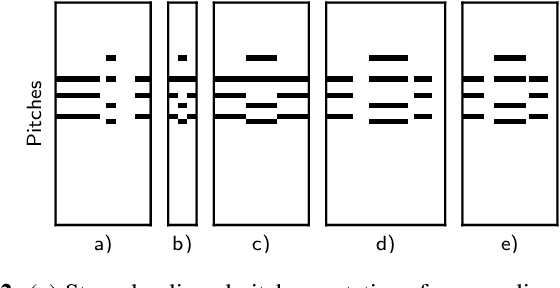
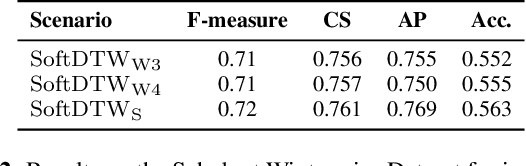
Many tasks in music information retrieval (MIR) involve weakly aligned data, where exact temporal correspondences are unknown. The connectionist temporal classification (CTC) loss is a standard technique to learn feature representations based on weakly aligned training data. However, CTC is limited to discrete-valued target sequences and can be difficult to extend to multi-label problems. In this article, we show how soft dynamic time warping (SoftDTW), a differentiable variant of classical DTW, can be used as an alternative to CTC. Using multi-pitch estimation as an example scenario, we show that SoftDTW yields results on par with a state-of-the-art multi-label extension of CTC. In addition to being more elegant in terms of its algorithmic formulation, SoftDTW naturally extends to real-valued target sequences.
DOAD: Decoupled One Stage Action Detection Network
Apr 04, 2023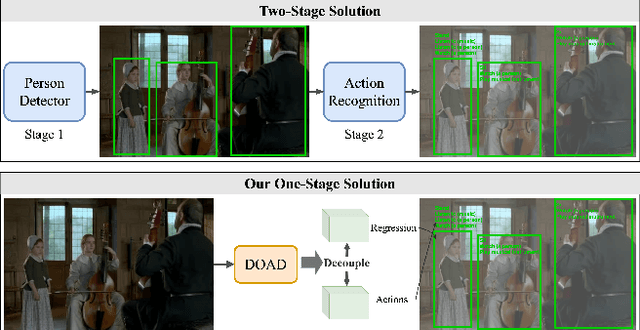

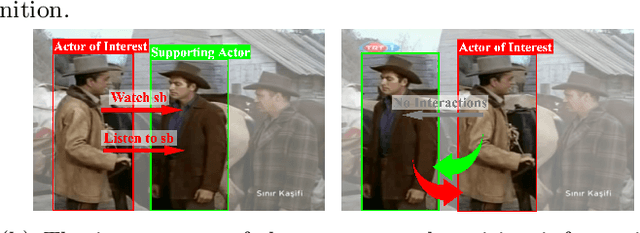

Localizing people and recognizing their actions from videos is a challenging task towards high-level video understanding. Existing methods are mostly two-stage based, with one stage for person bounding box generation and the other stage for action recognition. However, such two-stage methods are generally with low efficiency. We observe that directly unifying detection and action recognition normally suffers from (i) inferior learning due to different desired properties of context representation for detection and action recognition; (ii) optimization difficulty with insufficient training data. In this work, we present a decoupled one-stage network dubbed DOAD, to mitigate above issues and improve the efficiency for spatio-temporal action detection. To achieve it, we decouple detection and action recognition into two branches. Specifically, one branch focuses on detection representation for actor detection, and the other one for action recognition. For the action branch, we design a transformer-based module (TransPC) to model pairwise relationships between people and context. Different from commonly used vector-based dot product in self-attention, it is built upon a novel matrix-based key and value for Hadamard attention to model person-context information. It not only exploits relationships between person pairs but also takes into account context and relative position information. The results on AVA and UCF101-24 datasets show that our method is competitive with two-stage state-of-the-art methods with significant efficiency improvement.
Learning to Recover Spectral Reflectance from RGB Images
Apr 04, 2023
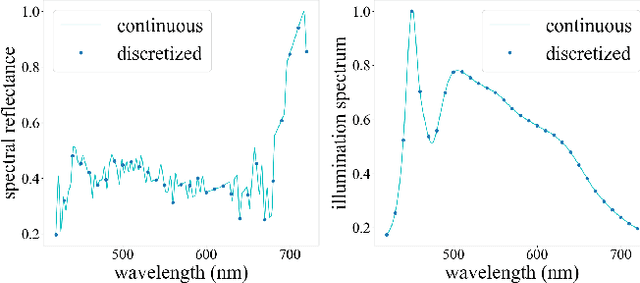
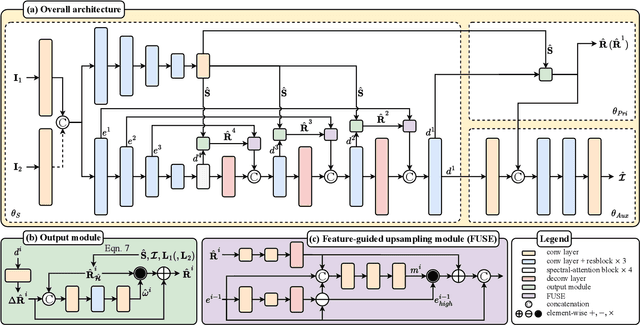

This paper tackles spectral reflectance recovery (SRR) from RGB images. Since capturing ground-truth spectral reflectance and camera spectral sensitivity are challenging and costly, most existing approaches are trained on synthetic images and utilize the same parameters for all unseen testing images, which are suboptimal especially when the trained models are tested on real images because they never exploit the internal information of the testing images. To address this issue, we adopt a self-supervised meta-auxiliary learning (MAXL) strategy that fine-tunes the well-trained network parameters with each testing image to combine external with internal information. To the best of our knowledge, this is the first work that successfully adapts the MAXL strategy to this problem. Instead of relying on naive end-to-end training, we also propose a novel architecture that integrates the physical relationship between the spectral reflectance and the corresponding RGB images into the network based on our mathematical analysis. Besides, since the spectral reflectance of a scene is independent to its illumination while the corresponding RGB images are not, we recover the spectral reflectance of a scene from its RGB images captured under multiple illuminations to further reduce the unknown. Qualitative and quantitative evaluations demonstrate the effectiveness of our proposed network and of the MAXL. Our code and data are available at https://github.com/Dong-Huo/SRR-MAXL.
MRET: Multi-resolution Transformer for Video Quality Assessment
Mar 29, 2023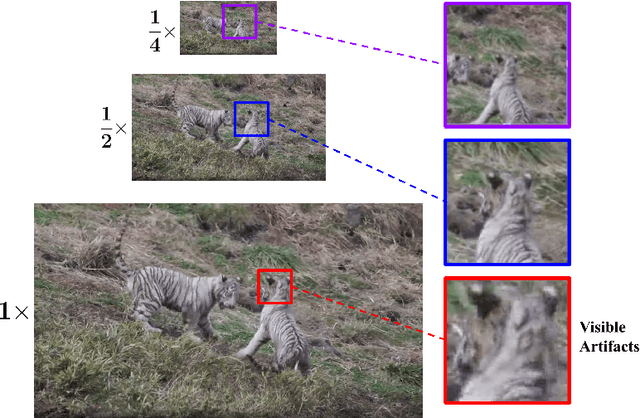
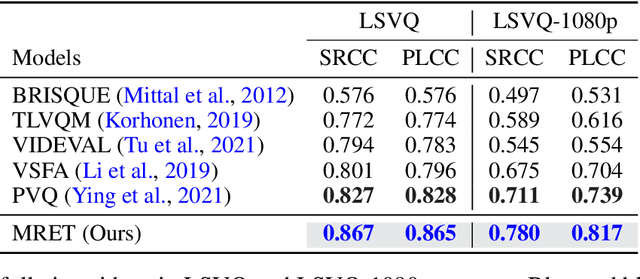
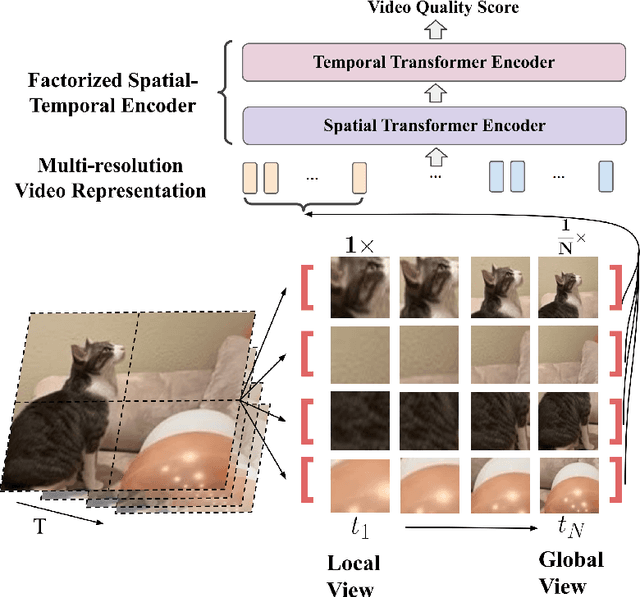
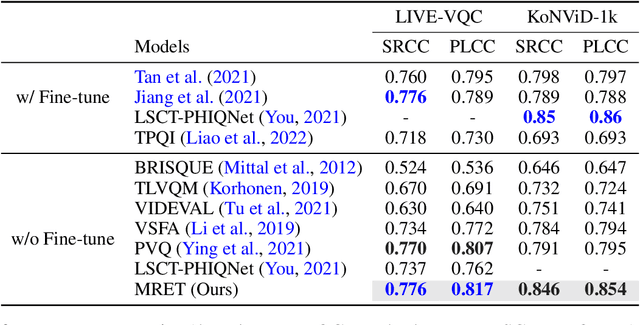
No-reference video quality assessment (NR-VQA) for user generated content (UGC) is crucial for understanding and improving visual experience. Unlike video recognition tasks, VQA tasks are sensitive to changes in input resolution. Since large amounts of UGC videos nowadays are 720p or above, the fixed and relatively small input used in conventional NR-VQA methods results in missing high-frequency details for many videos. In this paper, we propose a novel Transformer-based NR-VQA framework that preserves the high-resolution quality information. With the multi-resolution input representation and a novel multi-resolution patch sampling mechanism, our method enables a comprehensive view of both the global video composition and local high-resolution details. The proposed approach can effectively aggregate quality information across different granularities in spatial and temporal dimensions, making the model robust to input resolution variations. Our method achieves state-of-the-art performance on large-scale UGC VQA datasets LSVQ and LSVQ-1080p, and on KoNViD-1k and LIVE-VQC without fine-tuning.