 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identifying Health Risks from Family History: A Survey of Natural Language Processing Techniques
Mar 15, 2024
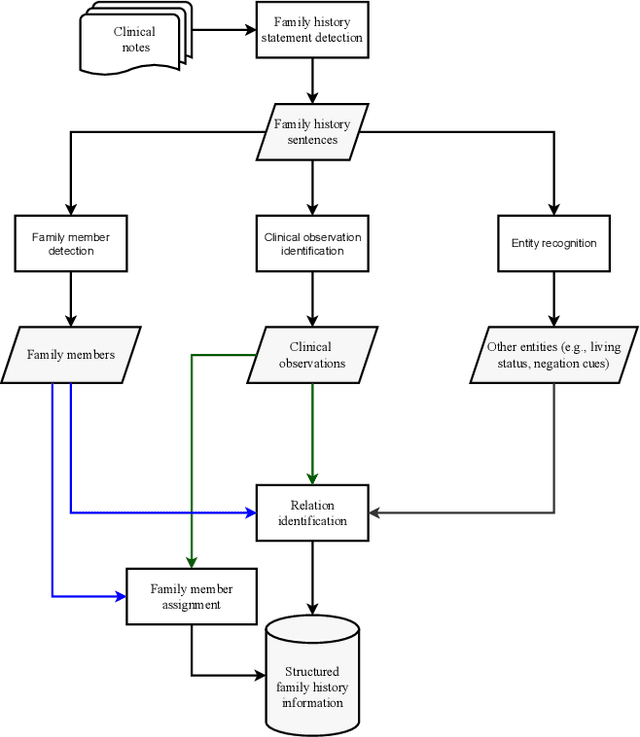

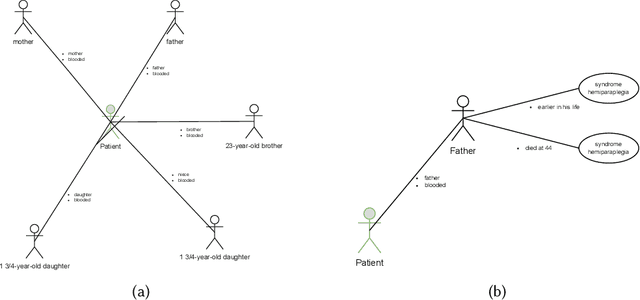
Electronic health records include information on patients' status and medical history, which could cover the history of diseases and disorders that could be hereditary. One important use of family history information is in precision health, where the goal is to keep the population healthy with preventative measures. Natural Language Processing (NLP) and machine learning techniques can assist with identifying information that could assist health professionals in identifying health risks before a condition is developed in their later years, saving lives and reducing healthcare costs. We survey the literature on the techniques from the NLP field that have been developed to utilise digital health records to identify risks of familial diseases. We highlight that rule-based methods are heavily investigated and are still actively used for family history extraction. Still, more recent efforts have been put into building neural models based on large-scale pre-trained language models. In addition to the areas where NLP has successfully been utilised, we also identify the areas where more research is needed to unlock the value of patients' records regarding data collection, task formulation and downstream applications.
Adaptive Random Feature Regularization on Fine-tuning Deep Neural Networks
Mar 15, 2024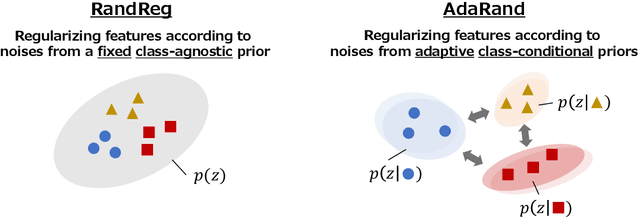

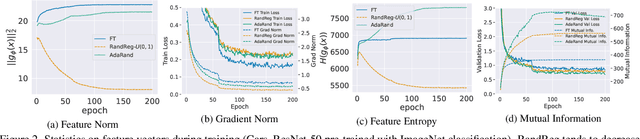
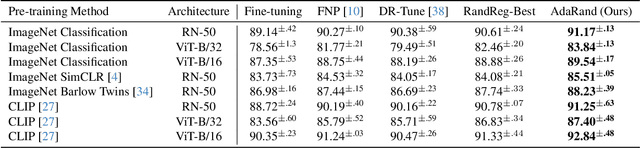
While fine-tuning is a de facto standard method for training deep neural networks, it still suffers from overfitting when using small target datasets. Previous methods improve fine-tuning performance by maintaining knowledge of the source datasets or introducing regularization terms such as contrastive loss. However, these methods require auxiliary source information (e.g., source labels or datasets) or heavy additional computations. In this paper, we propose a simple method called adaptive random feature regularization (AdaRand). AdaRand helps the feature extractors of training models to adaptively change the distribution of feature vectors for downstream classification tasks without auxiliary source information and with reasonable computation costs. To this end, AdaRand minimizes the gap between feature vectors and random reference vectors that are sampled from class conditional Gaussian distributions. Furthermore, AdaRand dynamically updates the conditional distribution to follow the currently updated feature extractors and balance the distance between classes in feature spaces. Our experiments show that AdaRand outperforms the other fine-tuning regularization, which requires auxiliary source information and heavy computation costs.
Improving Legal Case Retrieval with Brain Signals
Mar 20, 2024
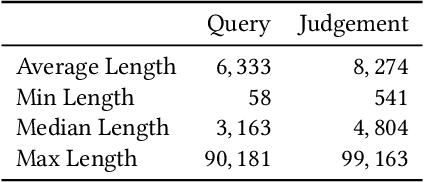
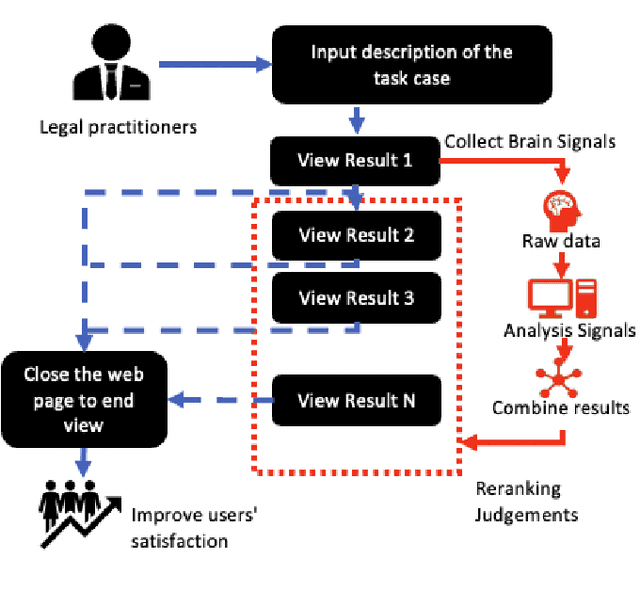
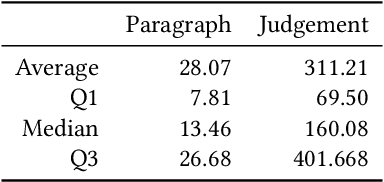
The tasks of legal case retrieval have received growing attention from the IR community in the last decade. Relevance feedback techniques with implicit user feedback (e.g., clicks) have been demonstrated to be effective in traditional search tasks (e.g., Web search). In legal case retrieval, however, collecting relevance feedback faces a couple of challenges that are difficult to resolve under existing feedback paradigms. First, legal case retrieval is a complex task as users often need to understand the relationship between legal cases in detail to correctly judge their relevance. Traditional feedback signal such as clicks is too coarse to use as they do not reflect any fine-grained relevance information. Second, legal case documents are usually long, users often need even tens of minutes to read and understand them. Simple behavior signal such as clicks and eye-tracking fixations can hardly be useful when users almost click and examine every part of the document. In this paper, we explore the possibility of solving the feedback problem in legal case retrieval with brain signal. Recent advances in brain signal processing have shown that human emotional can be collected in fine grains through Brain-Machine Interfaces (BMI) without interrupting the users in their tasks. Therefore, we propose a framework for legal case retrieval that uses EEG signal to optimize retrieval results. We collected and create a legal case retrieval dataset with users EEG signal and propose several methods to extract effective EEG features for relevance feedback. Our proposed features achieve a 71% accuracy for feedback prediction with an SVM-RFE model, and our proposed ranking method that takes into account the diverse needs of users can significantly improve user satisfaction for legal case retrieval. Experiment results show that re-ranked result list make user more satisfied.
OMG: Occlusion-friendly Personalized Multi-concept Generation in Diffusion Models
Mar 16, 2024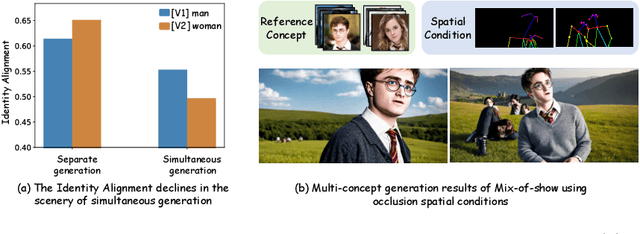
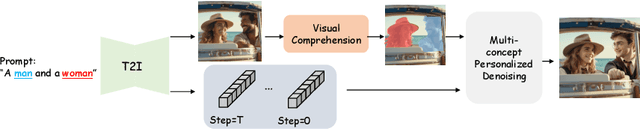
Personalization is an important topic in text-to-image generation, especially the challenging multi-concept personalization. Current multi-concept methods are struggling with identity preservation, occlusion, and the harmony between foreground and background. In this work, we propose OMG, an occlusion-friendly personalized generation framework designed to seamlessly integrate multiple concepts within a single image. We propose a novel two-stage sampling solution. The first stage takes charge of layout generation and visual comprehension information collection for handling occlusions. The second one utilizes the acquired visual comprehension information and the designed noise blending to integrate multiple concepts while considering occlusions. We also observe that the initiation denoising timestep for noise blending is the key to identity preservation and layout. Moreover, our method can be combined with various single-concept models, such as LoRA and InstantID without additional tuning. Especially, LoRA models on civitai.com can be exploited directly. Extensive experiments demonstrate that OMG exhibits superior performance in multi-concept personalization.
Texture Edge detection by Patch consensus (TEP)
Mar 16, 2024
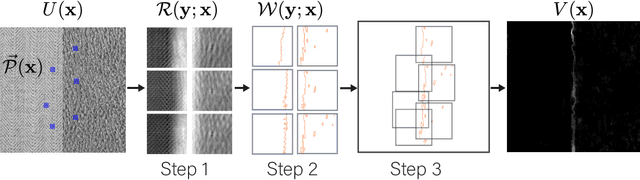

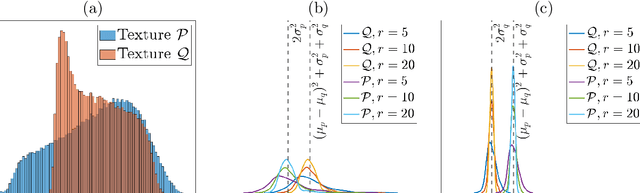
We propose Texture Edge detection using Patch consensus (TEP) which is a training-free method to detect the boundary of texture. We propose a new simple way to identify the texture edge location, using the consensus of segmented local patch information. While on the boundary, even using local patch information, the distinction between textures are typically not clear, but using neighbor consensus give a clear idea of the boundary. We utilize local patch, and its response against neighboring regions, to emphasize the similarities and the differences across different textures. The step of segmentation of response further emphasizes the edge location, and the neighborhood voting gives consensus and stabilize the edge detection. We analyze texture as a stationary process to give insight into the patch width parameter verses the quality of edge detection. We derive the necessary condition for textures to be distinguished, and analyze the patch width with respect to the scale of textures. Various experiments are presented to validate the proposed model.
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024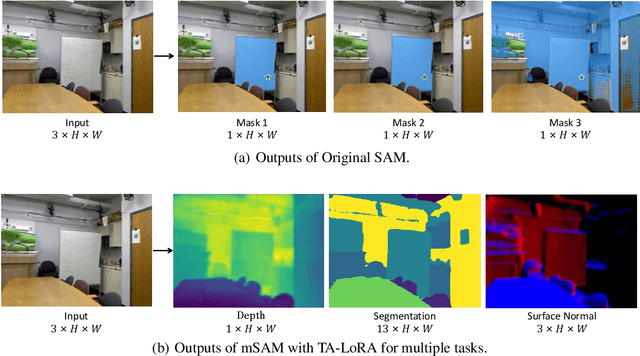
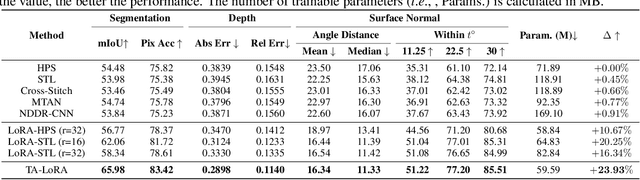
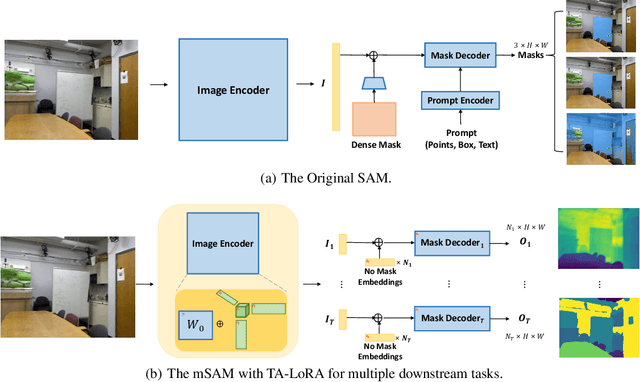
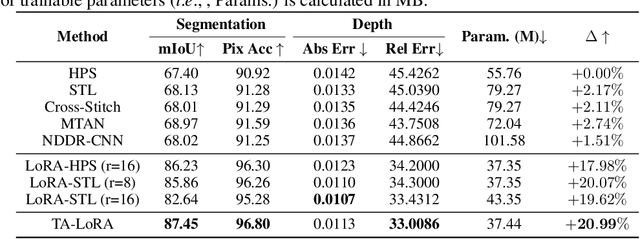
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.
Target Speaker Extraction by Directly Exploiting Contextual Information in the Time-Frequency Domain
Feb 27, 2024In target speaker extraction, many studies rely on the speaker embedding which is obtained from an enrollment of the target speaker and employed as the guidance. However, solely using speaker embedding may not fully utilize the contextual information contained in the enrollment. In this paper, we directly exploit this contextual information in the time-frequency (T-F) domain. Specifically, the T-F representations of the enrollment and the mixed signal are interacted to compute the weighting matrices through an attention mechanism. These weighting matrices reflect the similarity among different frames of the T-F representations and are further employed to obtain the consistent T-F representations of the enrollment. These consistent representations are served as the guidance, allowing for better exploitation of the contextual information. Furthermore, the proposed method achieves the state-of-the-art performance on the benchmark dataset and shows its effectiveness in the complex scenarios.
FutureDepth: Learning to Predict the Future Improves Video Depth Estimation
Mar 19, 2024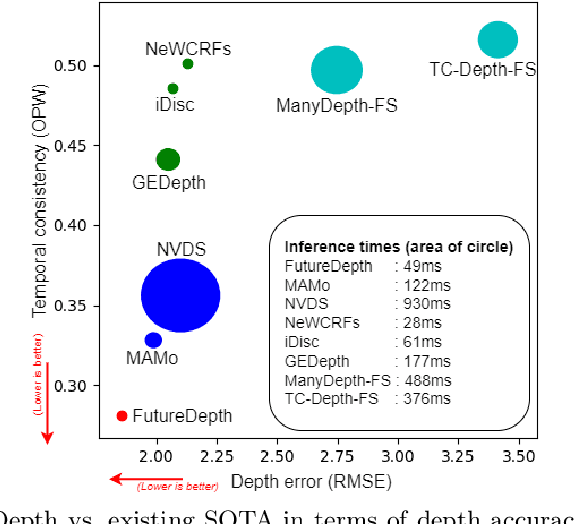
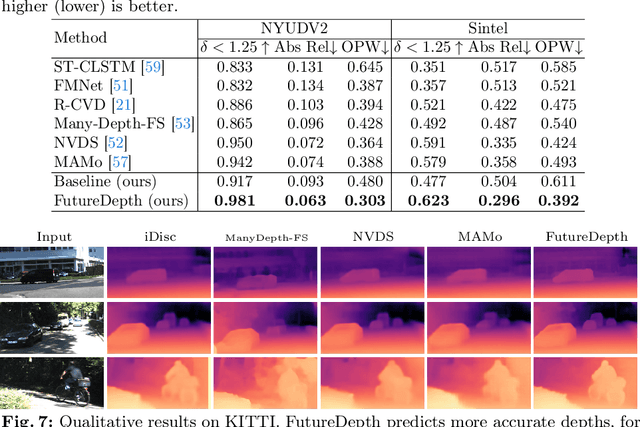
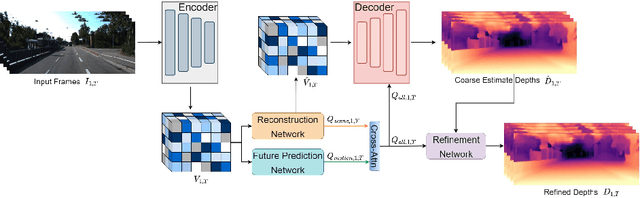
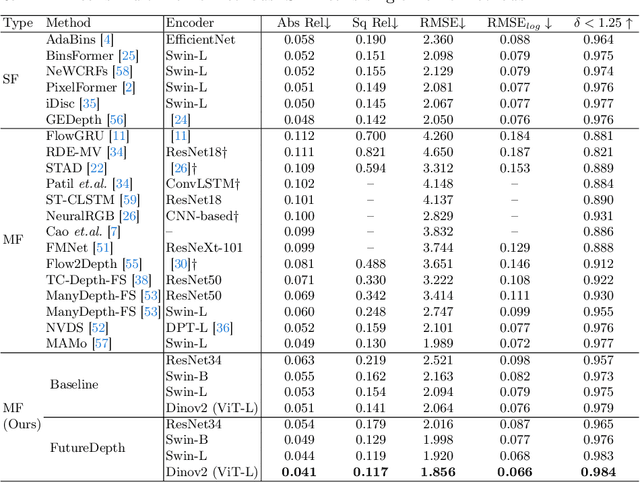
In this paper, we propose a novel video depth estimation approach, FutureDepth, which enables the model to implicitly leverage multi-frame and motion cues to improve depth estimation by making it learn to predict the future at training. More specifically, we propose a future prediction network, F-Net, which takes the features of multiple consecutive frames and is trained to predict multi-frame features one time step ahead iteratively. In this way, F-Net learns the underlying motion and correspondence information, and we incorporate its features into the depth decoding process. Additionally, to enrich the learning of multiframe correspondence cues, we further leverage a reconstruction network, R-Net, which is trained via adaptively masked auto-encoding of multiframe feature volumes. At inference time, both F-Net and R-Net are used to produce queries to work with the depth decoder, as well as a final refinement network. Through extensive experiments on several benchmarks, i.e., NYUDv2, KITTI, DDAD, and Sintel, which cover indoor, driving, and open-domain scenarios, we show that FutureDepth significantly improves upon baseline models, outperforms existing video depth estimation methods, and sets new state-of-the-art (SOTA) accuracy. Furthermore, FutureDepth is more efficient than existing SOTA video depth estimation models and has similar latencies when comparing to monocular models
Supporting Energy Policy Research with Large Language Models
Mar 19, 2024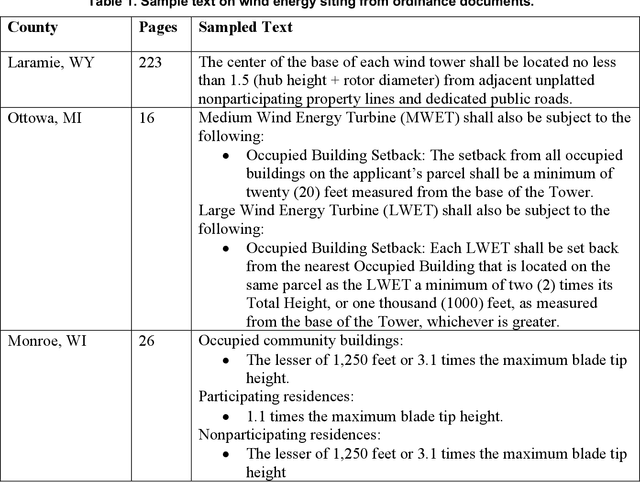
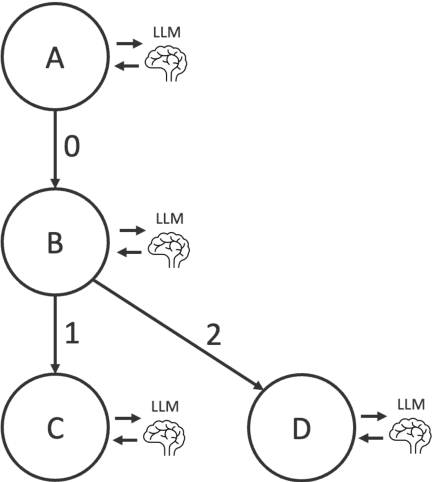

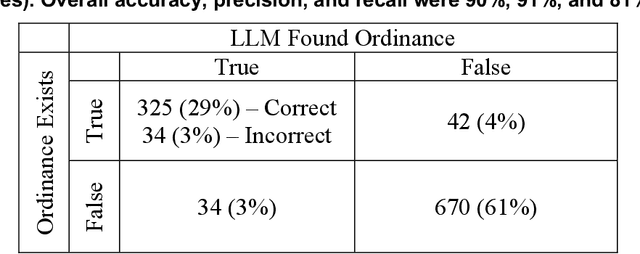
The recent growth in renewable energy development in the United States has been accompanied by a simultaneous surge in renewable energy siting ordinances. These zoning laws play a critical role in dictating the placement of wind and solar resources that are critical for achieving low-carbon energy futures. In this context, efficient access to and management of siting ordinance data becomes imperative. The National Renewable Energy Laboratory (NREL) recently introduced a public wind and solar siting database to fill this need. This paper presents a method for harnessing Large Language Models (LLMs) to automate the extraction of these siting ordinances from legal documents, enabling this database to maintain accurate up-to-date information in the rapidly changing energy policy landscape. A novel contribution of this research is the integration of a decision tree framework with LLMs. Our results show that this approach is 85 to 90% accurate with outputs that can be used directly in downstream quantitative modeling. We discuss opportunities to use this work to support similar large-scale policy research in the energy sector. By unlocking new efficiencies in the extraction and analysis of legal documents using LLMs, this study enables a path forward for automated large-scale energy policy research.
CLASSLA-web: Comparable Web Corpora of South Slavic Languages Enriched with Linguistic and Genre Annotation
Mar 19, 2024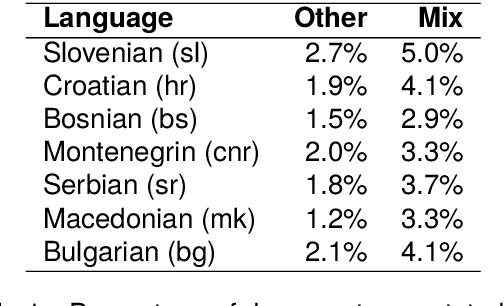
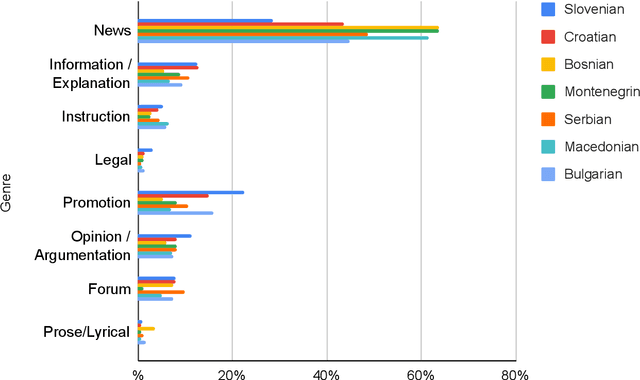
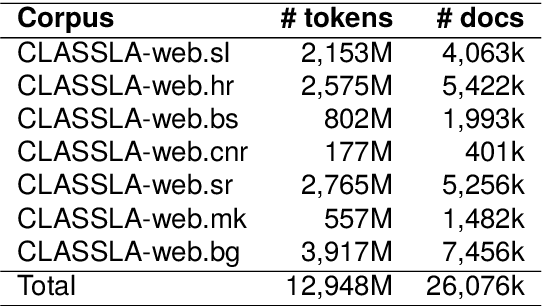
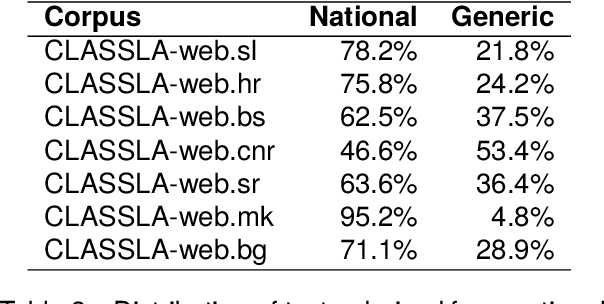
This paper presents a collection of highly comparable web corpora of Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian, and Bulgarian, covering thereby the whole spectrum of official languages in the South Slavic language space. The collection of these corpora comprises a total of 13 billion tokens of texts from 26 million documents. The comparability of the corpora is ensured by a comparable crawling setup and the usage of identical crawling and post-processing technology. All the corpora were linguistically annotated with the state-of-the-art CLASSLA-Stanza linguistic processing pipeline, and enriched with document-level genre information via the Transformer-based multilingual X-GENRE classifier, which further enhances comparability at the level of linguistic annotation and metadata enrichment. The genre-focused analysis of the resulting corpora shows a rather consistent distribution of genres throughout the seven corpora, with variations in the most prominent genre categories being well-explained by the economic strength of each language community. A comparison of the distribution of genre categories across the corpora indicates that web corpora from less developed countries primarily consist of news articles. Conversely, web corpora from economically more developed countries exhibit a smaller proportion of news content, with a greater presence of promotional and opinionated texts.