 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Specializing Multi-domain NMT via Penalizing Low Mutual Information
Oct 24, 2022
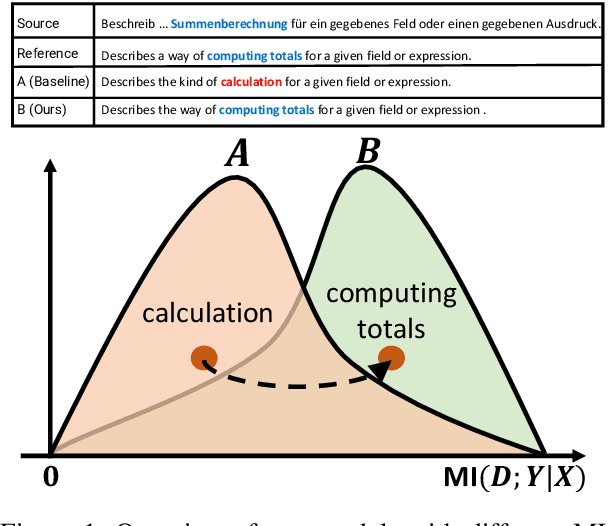
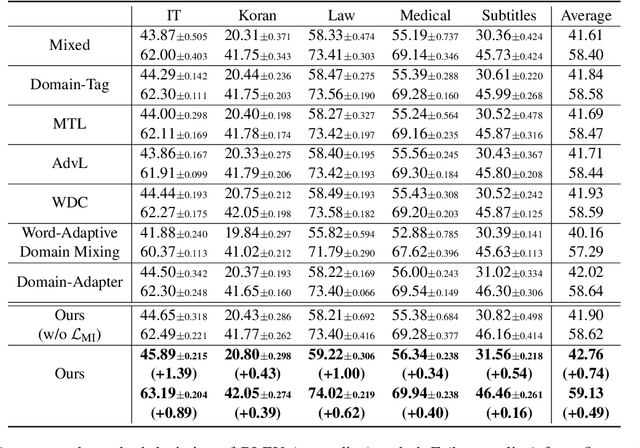
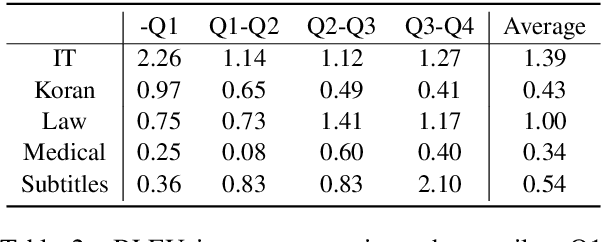
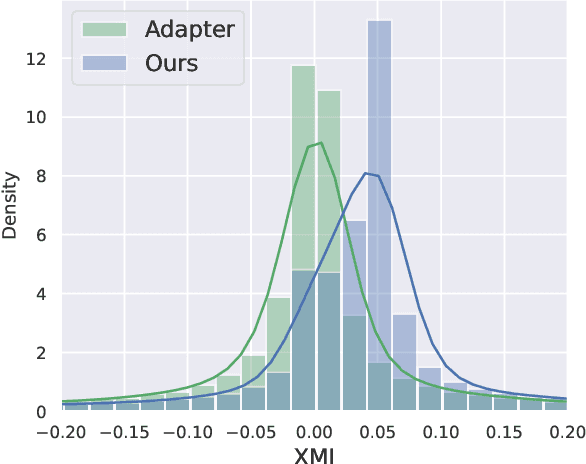
Multi-domain Neural Machine Translation (NMT) trains a single model with multiple domains. It is appealing because of its efficacy in handling multiple domains within one model. An ideal multi-domain NMT should learn distinctive domain characteristics simultaneously, however, grasping the domain peculiarity is a non-trivial task. In this paper, we investigate domain-specific information through the lens of mutual information (MI) and propose a new objective that penalizes low MI to become higher. Our method achieved the state-of-the-art performance among the current competitive multi-domain NMT models. Also, we empirically show our objective promotes low MI to be higher resulting in domain-specialized multi-domain NMT.
Weakly-Supervised Temporal Action Localization with Bidirectional Semantic Consistency Constraint
Apr 25, 2023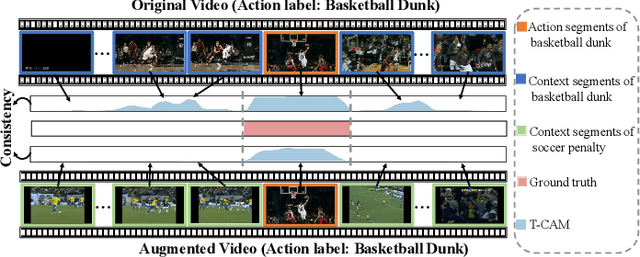
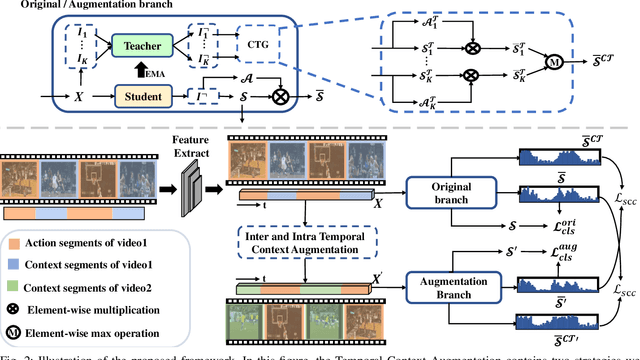
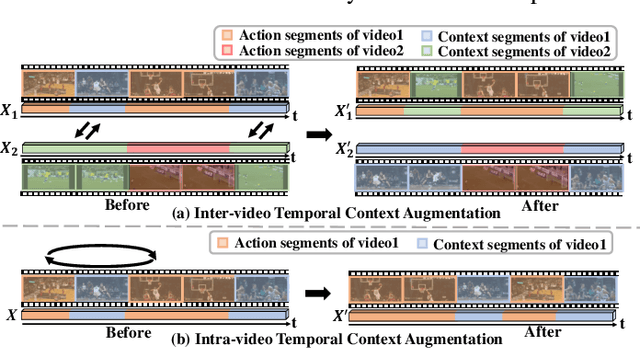
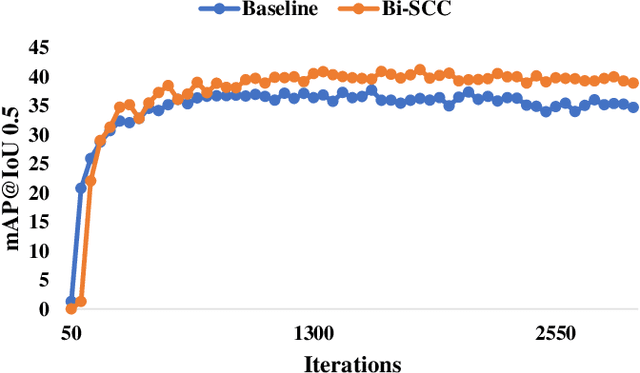
Weakly Supervised Temporal Action Localization (WTAL) aims to classify and localize temporal boundaries of actions for the video, given only video-level category labels in the training datasets. Due to the lack of boundary information during training, existing approaches formulate WTAL as a classificationproblem, i.e., generating the temporal class activation map (T-CAM) for localization. However, with only classification loss, the model would be sub-optimized, i.e., the action-related scenes are enough to distinguish different class labels. Regarding other actions in the action-related scene ( i.e., the scene same as positive actions) as co-scene actions, this sub-optimized model would misclassify the co-scene actions as positive actions. To address this misclassification, we propose a simple yet efficient method, named bidirectional semantic consistency constraint (Bi-SCC), to discriminate the positive actions from co-scene actions. The proposed Bi-SCC firstly adopts a temporal context augmentation to generate an augmented video that breaks the correlation between positive actions and their co-scene actions in the inter-video; Then, a semantic consistency constraint (SCC) is used to enforce the predictions of the original video and augmented video to be consistent, hence suppressing the co-scene actions. However, we find that this augmented video would destroy the original temporal context. Simply applying the consistency constraint would affect the completeness of localized positive actions. Hence, we boost the SCC in a bidirectional way to suppress co-scene actions while ensuring the integrity of positive actions, by cross-supervising the original and augmented videos. Finally, our proposed Bi-SCC can be applied to current WTAL approaches, and improve their performance. Experimental results show that our approach outperforms the state-of-the-art methods on THUMOS14 and ActivityNet.
Structured Epipolar Matcher for Local Feature Matching
Apr 13, 2023
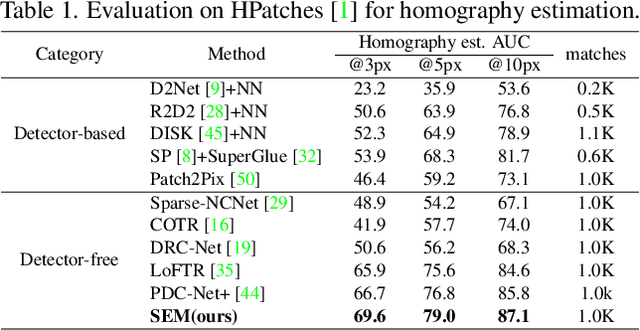

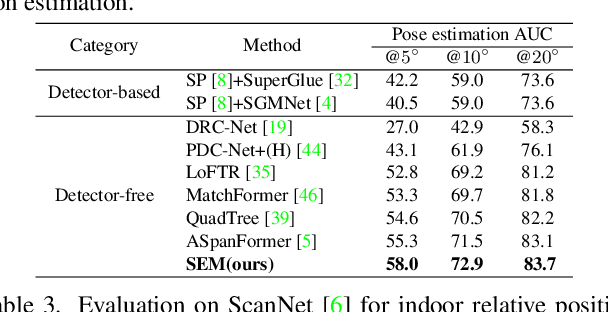
Local feature matching is challenging due to textureless and repetitive patterns. Existing methods focus on using appearance features and global interaction and matching, while the importance of geometry priors in local feature matching has not been fully exploited. Different from these methods, in this paper, we delve into the importance of geometry prior and propose Structured Epipolar Matcher (SEM) for local feature matching, which can leverage the geometric information in an iterative matching way. The proposed model enjoys several merits. First, our proposed Structured Feature Extractor can model the relative positional relationship between pixels and high-confidence anchor points. Second, our proposed Epipolar Attention and Matching can filter out irrelevant areas by utilizing the epipolar constraint. Extensive experimental results on five standard benchmarks demonstrate the superior performance of our SEM compared to state-of-the-art methods. Project page: https://sem2023.github.io.
counterfactuals: An R Package for Counterfactual Explanation Methods
Apr 13, 2023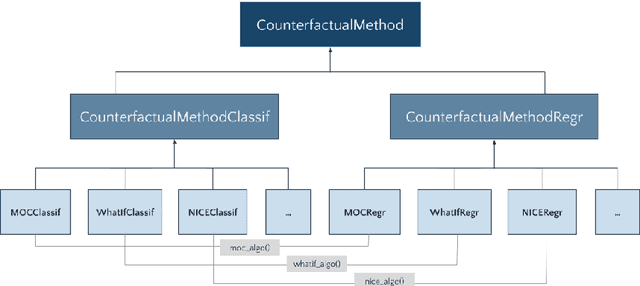

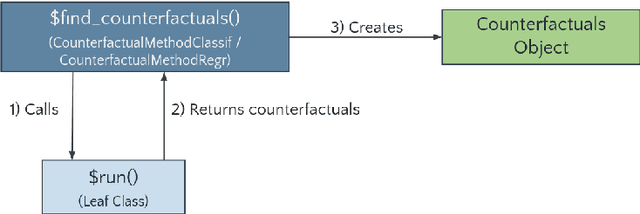

Counterfactual explanation methods provide information on how feature values of individual observations must be changed to obtain a desired prediction. Despite the increasing amount of proposed methods in research, only a few implementations exist whose interfaces and requirements vary widely. In this work, we introduce the counterfactuals R package, which provides a modular and unified R6-based interface for counterfactual explanation methods. We implemented three existing counterfactual explanation methods and propose some optional methodological extensions to generalize these methods to different scenarios and to make them more comparable. We explain the structure and workflow of the package using real use cases and show how to integrate additional counterfactual explanation methods into the package. In addition, we compared the implemented methods for a variety of models and datasets with regard to the quality of their counterfactual explanations and their runtime behavior.
ALR-GAN: Adaptive Layout Refinement for Text-to-Image Synthesis
Apr 13, 2023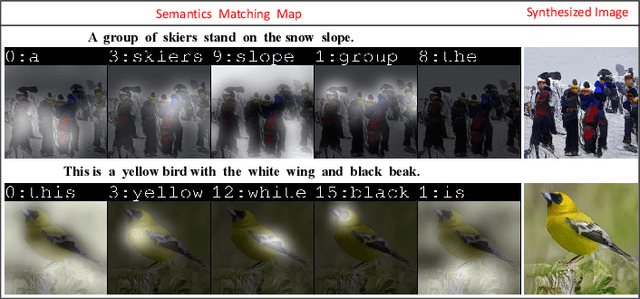
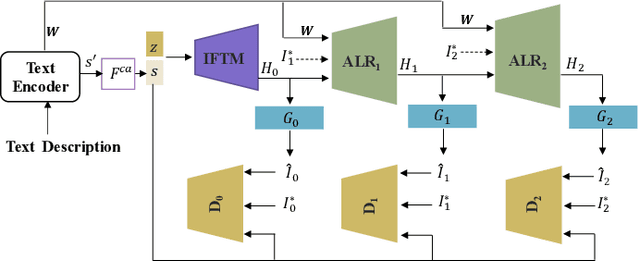
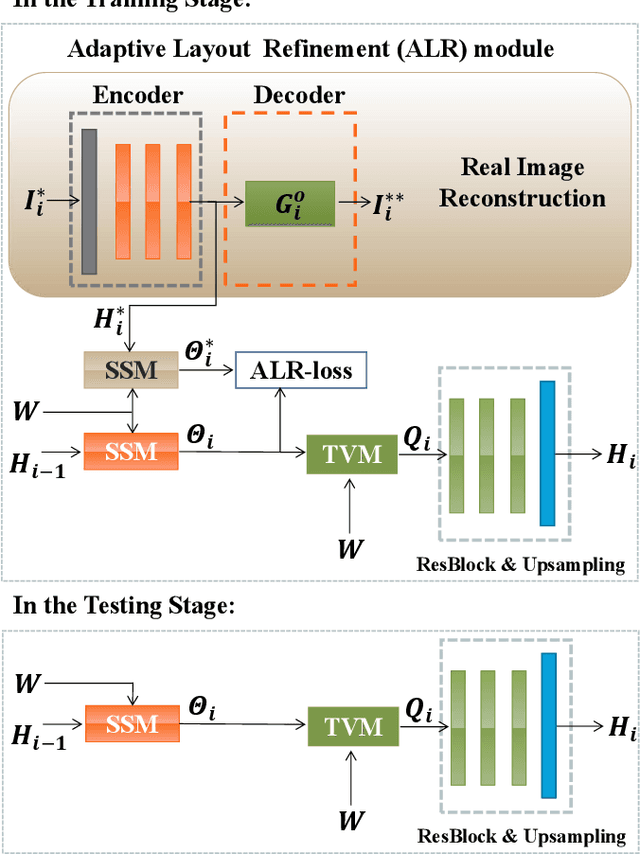

We propose a novel Text-to-Image Generation Network, Adaptive Layout Refinement Generative Adversarial Network (ALR-GAN), to adaptively refine the layout of synthesized images without any auxiliary information. The ALR-GAN includes an Adaptive Layout Refinement (ALR) module and a Layout Visual Refinement (LVR) loss. The ALR module aligns the layout structure (which refers to locations of objects and background) of a synthesized image with that of its corresponding real image. In ALR module, we proposed an Adaptive Layout Refinement (ALR) loss to balance the matching of hard and easy features, for more efficient layout structure matching. Based on the refined layout structure, the LVR loss further refines the visual representation within the layout area. Experimental results on two widely-used datasets show that ALR-GAN performs competitively at the Text-to-Image generation task.
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
Apr 10, 2023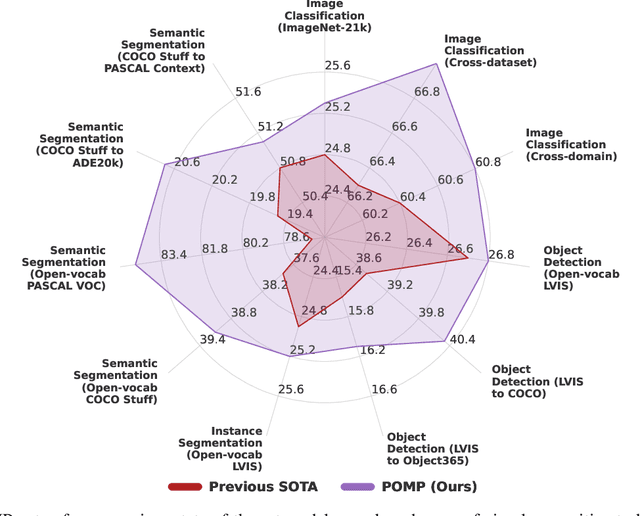
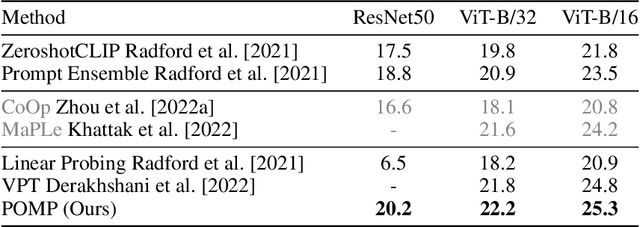
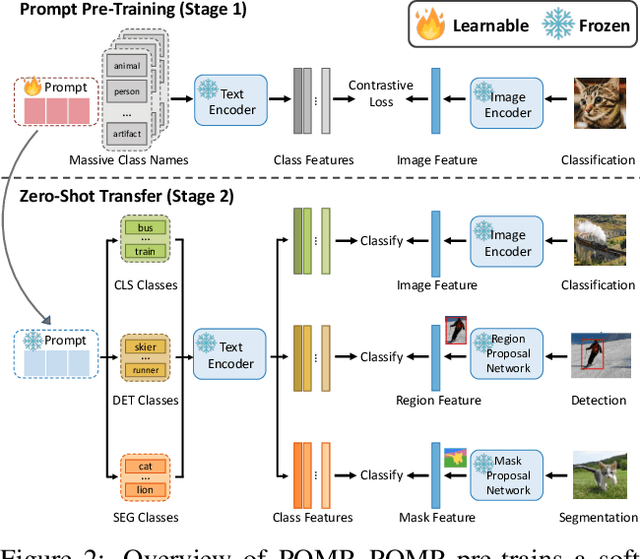
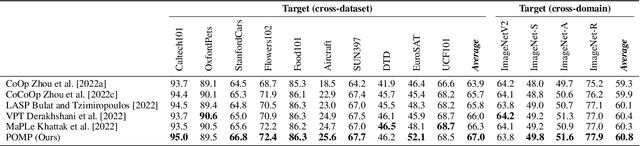
This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 downstream datasets, e.g., 67.0% average accuracy on 10 classification dataset (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg).
Towards preserving word order importance through Forced Invalidation
Apr 11, 2023
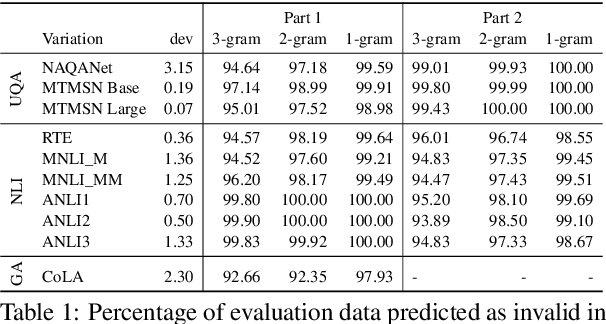
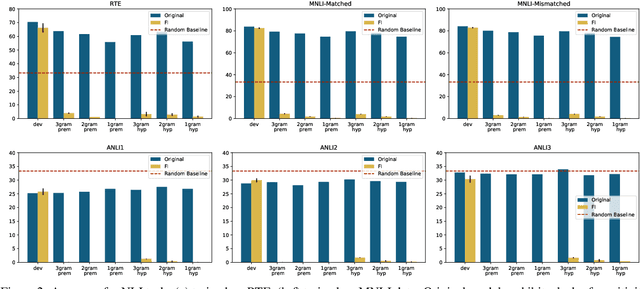
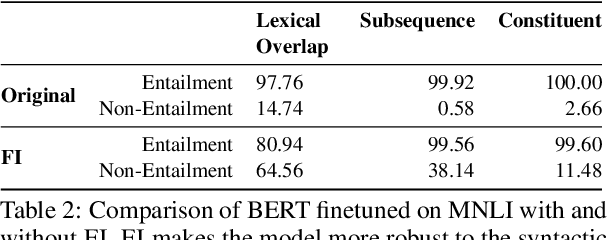
Large pre-trained language models such as BERT have been widely used as a framework for natural language understanding (NLU) tasks. However, recent findings have revealed that pre-trained language models are insensitive to word order. The performance on NLU tasks remains unchanged even after randomly permuting the word of a sentence, where crucial syntactic information is destroyed. To help preserve the importance of word order, we propose a simple approach called Forced Invalidation (FI): forcing the model to identify permuted sequences as invalid samples. We perform an extensive evaluation of our approach on various English NLU and QA based tasks over BERT-based and attention-based models over word embeddings. Our experiments demonstrate that Forced Invalidation significantly improves the sensitivity of the models to word order.
BanditQ -- No-Regret Learning with Guaranteed Per-User Rewards in Adversarial Environments
Apr 11, 2023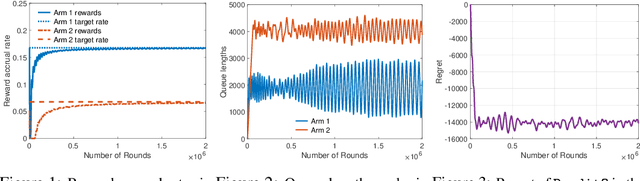
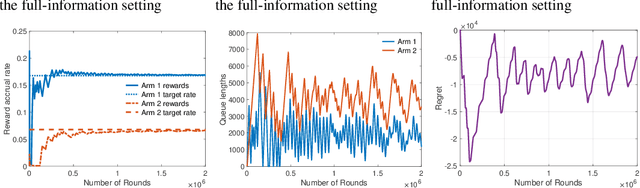
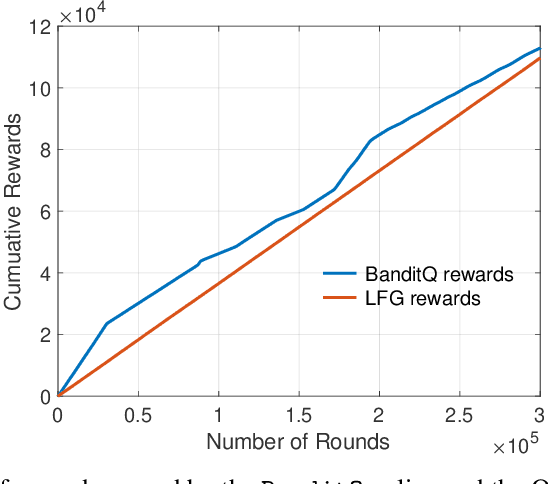
Classic online prediction algorithms, such as Hedge, are inherently unfair by design, as they try to play the most rewarding arm as many times as possible while ignoring the sub-optimal arms to achieve sublinear regret. In this paper, we consider a fair online prediction problem in the adversarial setting with hard lower bounds on the rate of accrual of rewards for all arms. By combining elementary queueing theory with online learning, we propose a new online prediction policy, called BanditQ, that achieves the target rate constraints while achieving a regret of $O(T^{3/4})$ in the full-information setting. The design and analysis of BanditQ involve a novel use of the potential function method and are of independent interest.
Relational Context Learning for Human-Object Interaction Detection
Apr 11, 2023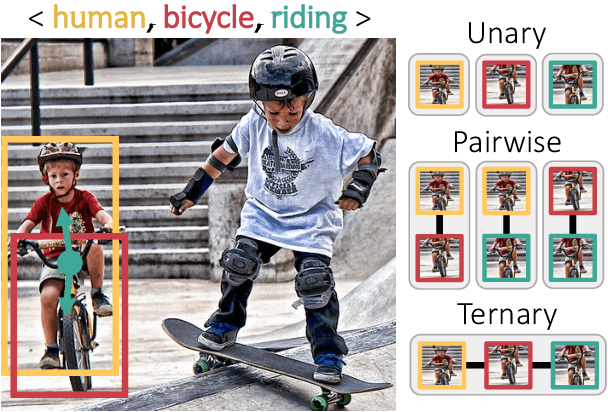
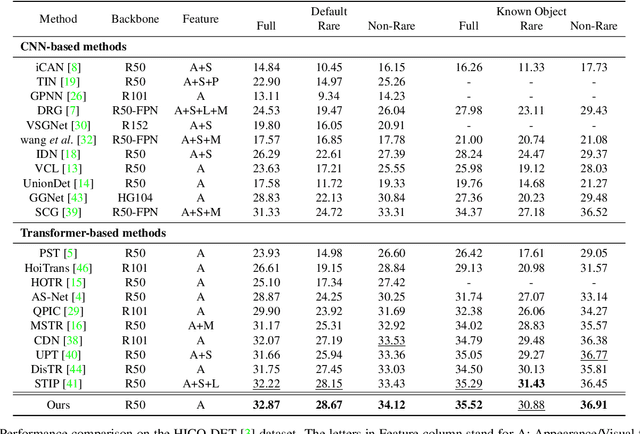
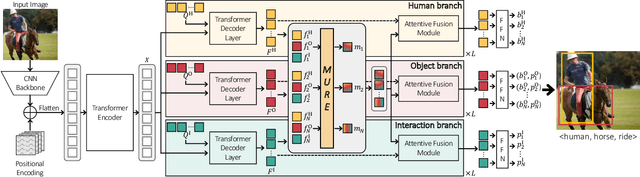
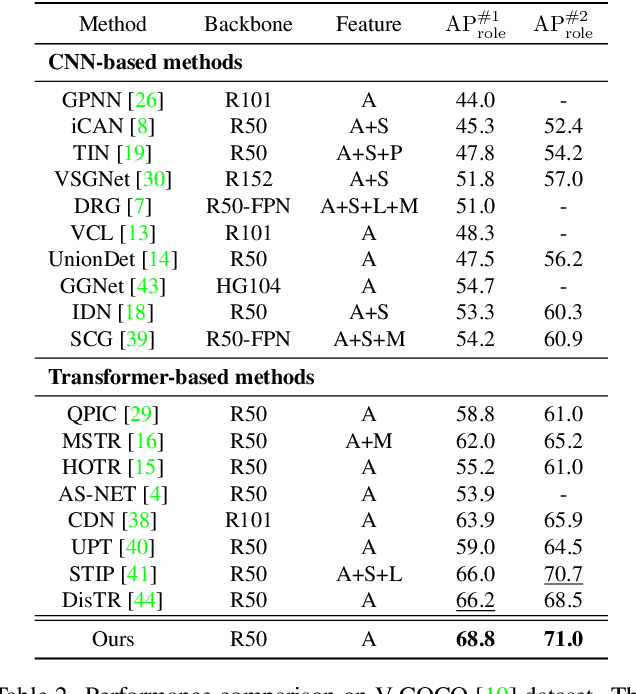
Recent state-of-the-art methods for HOI detection typically build on transformer architectures with two decoder branches, one for human-object pair detection and the other for interaction classification. Such disentangled transformers, however, may suffer from insufficient context exchange between the branches and lead to a lack of context information for relational reasoning, which is critical in discovering HOI instances. In this work, we propose the multiplex relation network (MUREN) that performs rich context exchange between three decoder branches using unary, pairwise, and ternary relations of human, object, and interaction tokens. The proposed method learns comprehensive relational contexts for discovering HOI instances, achieving state-of-the-art performance on two standard benchmarks for HOI detection, HICO-DET and V-COCO.
Integrating Semantic Information into Sketchy Reading Module of Retro-Reader for Vietnamese Machine Reading Comprehension
Jan 01, 2023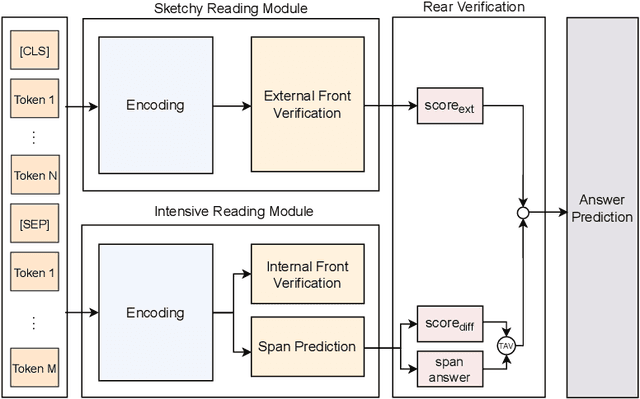
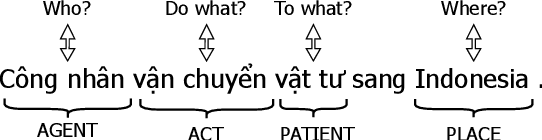
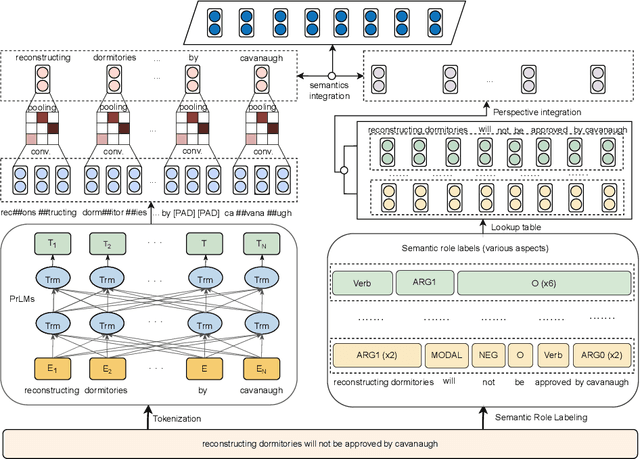
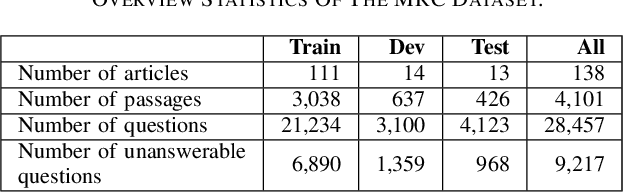
Machine Reading Comprehension has become one of the most advanced and popular research topics in the fields of Natural Language Processing in recent years. The classification of answerability questions is a relatively significant sub-task in machine reading comprehension; however, there haven't been many studies. Retro-Reader is one of the studies that has solved this problem effectively. However, the encoders of most traditional machine reading comprehension models in general and Retro-Reader, in particular, have not been able to exploit the contextual semantic information of the context completely. Inspired by SemBERT, we use semantic role labels from the SRL task to add semantics to pre-trained language models such as mBERT, XLM-R, PhoBERT. This experiment was conducted to compare the influence of semantics on the classification of answerability for the Vietnamese machine reading comprehension. Additionally, we hope this experiment will enhance the encoder for the Retro-Reader model's Sketchy Reading Module. The improved Retro-Reader model's encoder with semantics was first applied to the Vietnamese Machine Reading Comprehension task and obtained positive results.