 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023
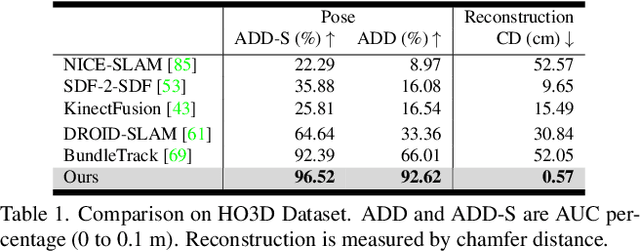
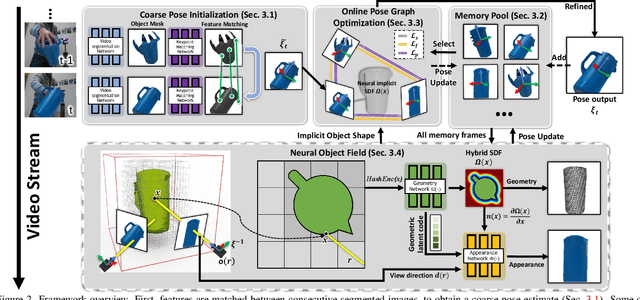
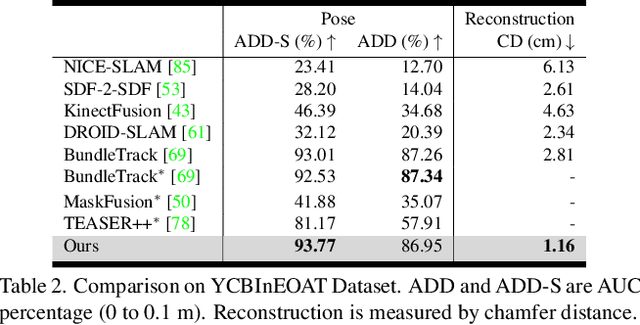
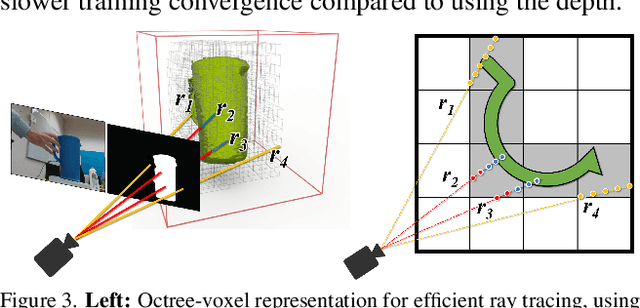
We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020
SymBa: Symmetric Backpropagation-Free Contrastive Learning with Forward-Forward Algorithm for Optimizing Convergence
Mar 15, 2023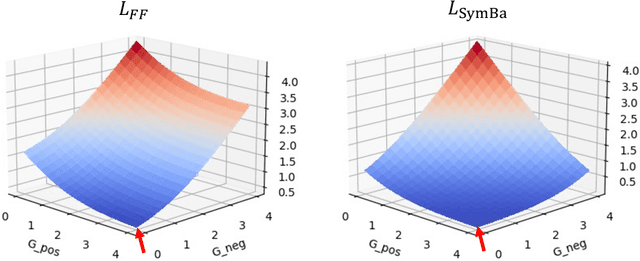
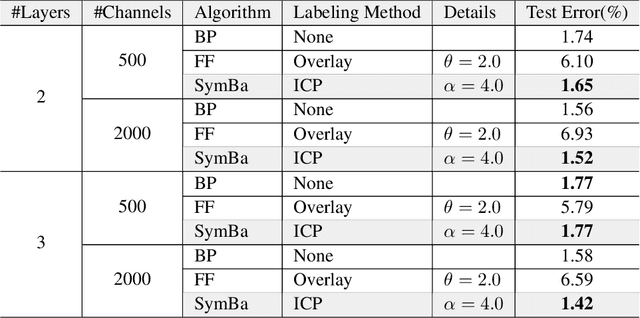

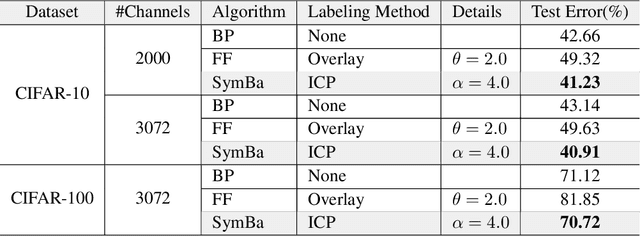
The paper proposes a new algorithm called SymBa that aims to achieve more biologically plausible learning than Back-Propagation (BP). The algorithm is based on the Forward-Forward (FF) algorithm, which is a BP-free method for training neural networks. SymBa improves the FF algorithm's convergence behavior by addressing the problem of asymmetric gradients caused by conflicting converging directions for positive and negative samples. The algorithm balances positive and negative losses to enhance performance and convergence speed. Furthermore, it modifies the FF algorithm by adding Intrinsic Class Pattern (ICP) containing class information to prevent the loss of class information during training. The proposed algorithm has the potential to improve our understanding of how the brain learns and processes information and to develop more effective and efficient artificial intelligence systems. The paper presents experimental results that demonstrate the effectiveness of SymBa algorithm compared to the FF algorithm and BP.
CAT: Learning to Collaborate Channel and Spatial Attention from Multi-Information Fusion
Dec 13, 2022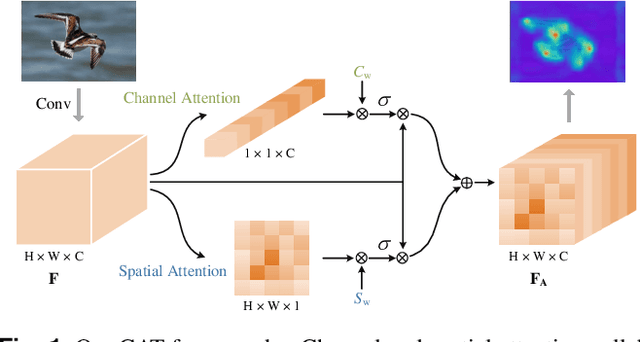
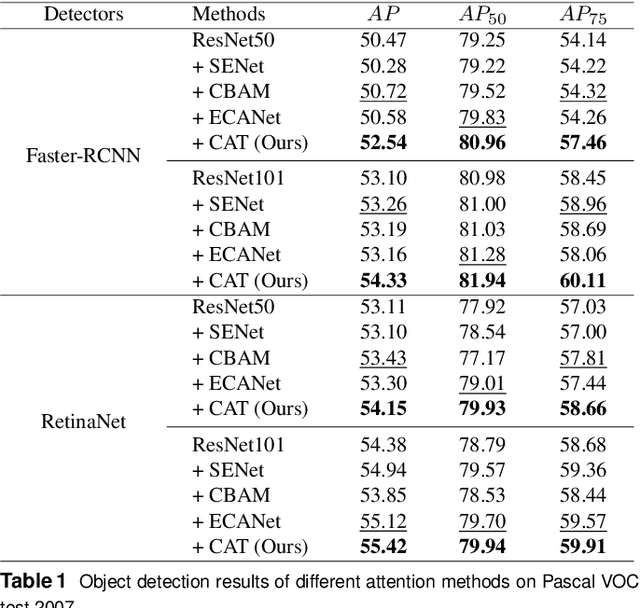
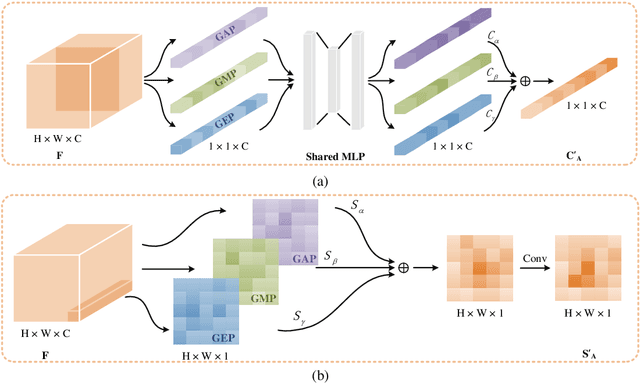
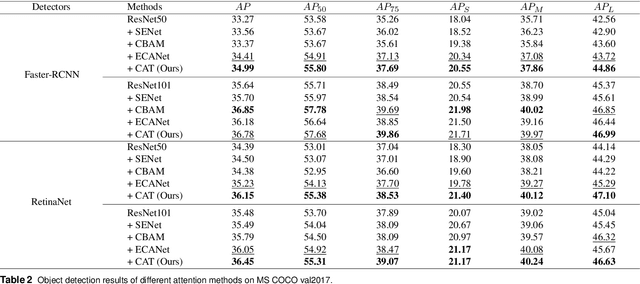
Channel and spatial attention mechanism has proven to provide an evident performance boost of deep convolution neural networks (CNNs). Most existing methods focus on one or run them parallel (series), neglecting the collaboration between the two attentions. In order to better establish the feature interaction between the two types of attention, we propose a plug-and-play attention module, which we term "CAT"-activating the Collaboration between spatial and channel Attentions based on learned Traits. Specifically, we represent traits as trainable coefficients (i.e., colla-factors) to adaptively combine contributions of different attention modules to fit different image hierarchies and tasks better. Moreover, we propose the global entropy pooling (GEP) apart from global average pooling (GAP) and global maximum pooling (GMP) operators, an effective component in suppressing noise signals by measuring the information disorder of feature maps. We introduce a three-way pooling operation into attention modules and apply the adaptive mechanism to fuse their outcomes. Extensive experiments on MS COCO, Pascal-VOC, Cifar-100, and ImageNet show that our CAT outperforms existing state-of-the-art attention mechanisms in object detection, instance segmentation, and image classification. The model and code will be released soon.
* 8 pages, 5 figures
SPeC: A Soft Prompt-Based Calibration on Mitigating Performance Variability in Clinical Notes Summarization
Mar 27, 2023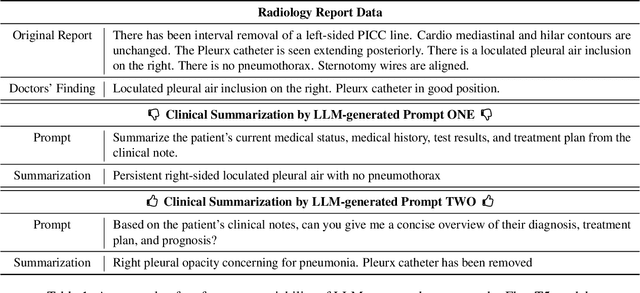
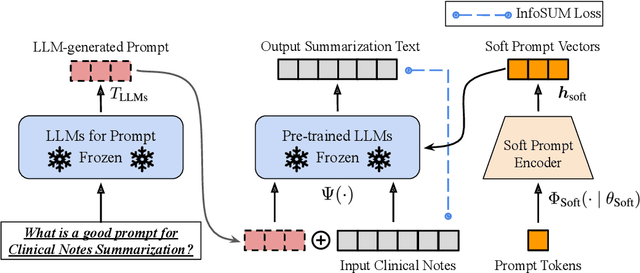

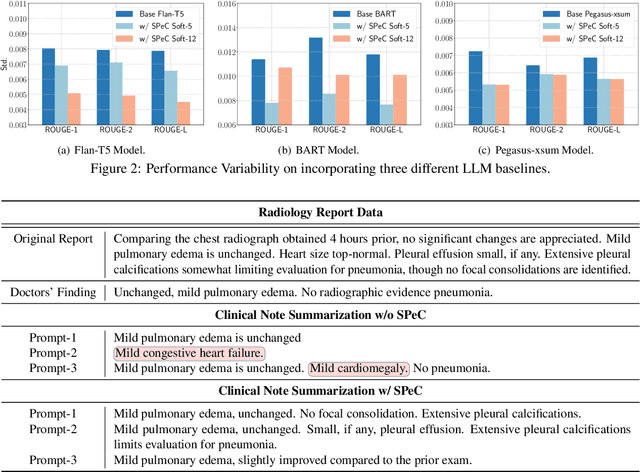
Electronic health records (EHRs) store an extensive array of patient information, encompassing medical histories, diagnoses, treatments, and test outcomes. These records are crucial for enabling healthcare providers to make well-informed decisions regarding patient care. Summarizing clinical notes further assists healthcare professionals in pinpointing potential health risks and making better-informed decisions. This process contributes to reducing errors and enhancing patient outcomes by ensuring providers have access to the most pertinent and current patient data. Recent research has shown that incorporating prompts with large language models (LLMs) substantially boosts the efficacy of summarization tasks. However, we show that this approach also leads to increased output variance, resulting in notably divergent outputs even when prompts share similar meanings. To tackle this challenge, we introduce a model-agnostic Soft Prompt-Based Calibration (SPeC) pipeline that employs soft prompts to diminish variance while preserving the advantages of prompt-based summarization. Experimental findings on multiple clinical note tasks and LLMs indicate that our method not only bolsters performance but also effectively curbs variance for various LLMs, providing a more uniform and dependable solution for summarizing vital medical information.
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities
Mar 27, 2023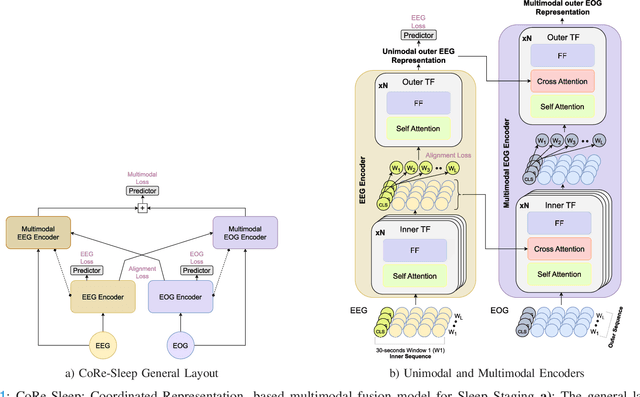
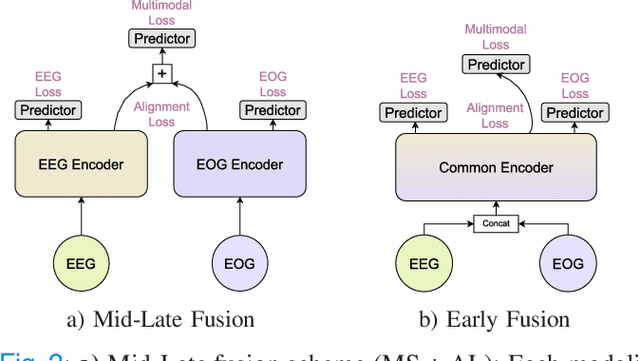
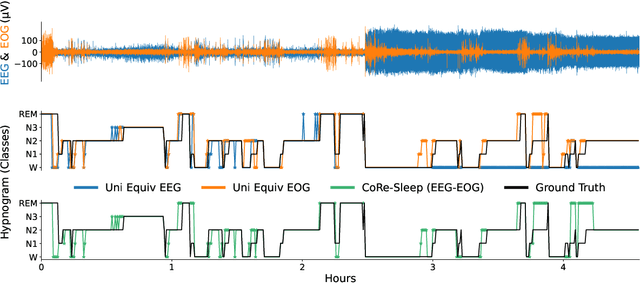
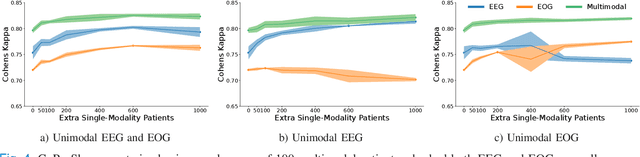
Sleep abnormalities can have severe health consequences. Automated sleep staging, i.e. labelling the sequence of sleep stages from the patient's physiological recordings, could simplify the diagnostic process. Previous work on automated sleep staging has achieved great results, mainly relying on the EEG signal. However, often multiple sources of information are available beyond EEG. This can be particularly beneficial when the EEG recordings are noisy or even missing completely. In this paper, we propose CoRe-Sleep, a Coordinated Representation multimodal fusion network that is particularly focused on improving the robustness of signal analysis on imperfect data. We demonstrate how appropriately handling multimodal information can be the key to achieving such robustness. CoRe-Sleep tolerates noisy or missing modalities segments, allowing training on incomplete data. Additionally, it shows state-of-the-art performance when testing on both multimodal and unimodal data using a single model on SHHS-1, the largest publicly available study that includes sleep stage labels. The results indicate that training the model on multimodal data does positively influence performance when tested on unimodal data. This work aims at bridging the gap between automated analysis tools and their clinical utility.
Recover Triggered States: Protect Model Against Backdoor Attack in Reinforcement Learning
Apr 10, 2023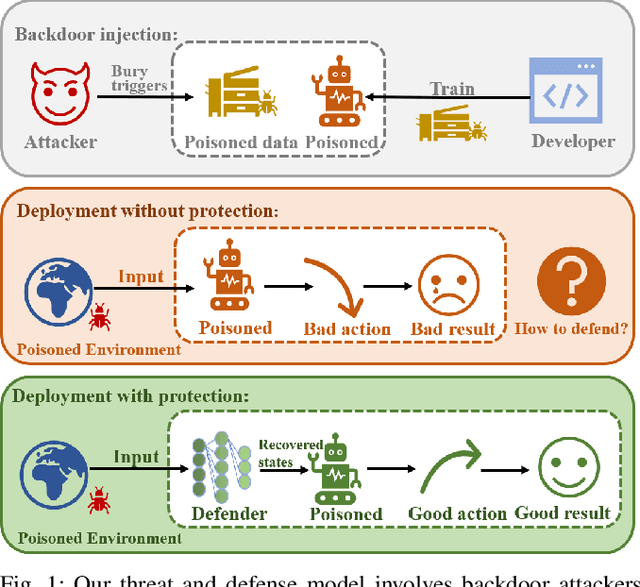
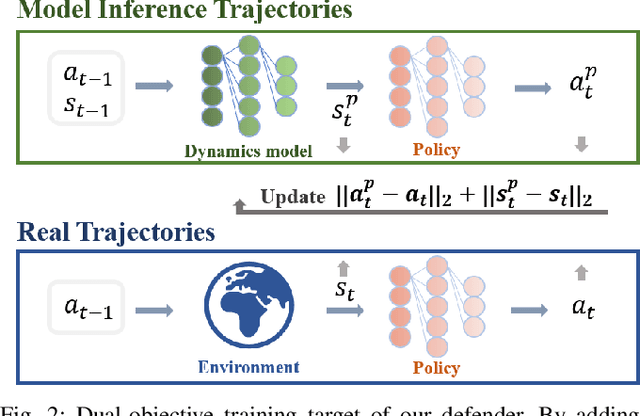
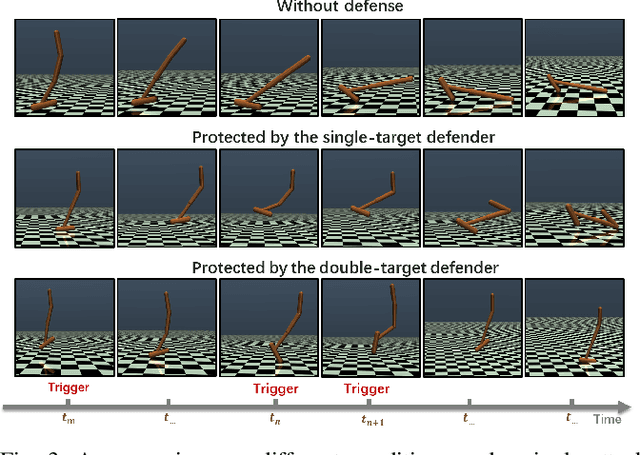
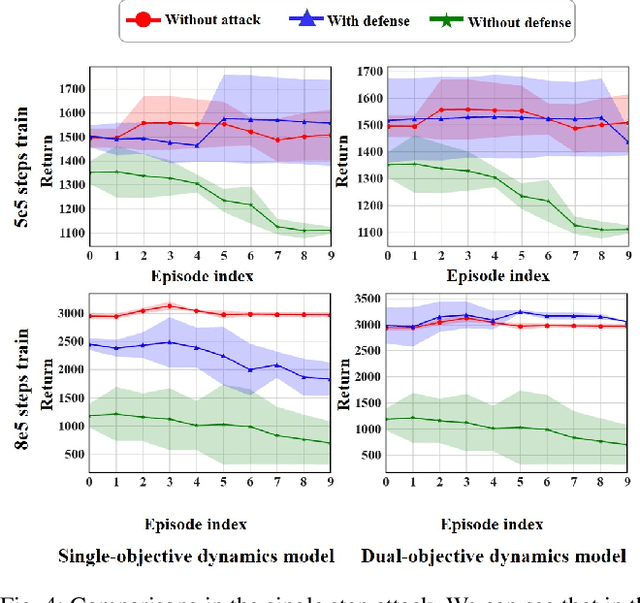
A backdoor attack allows a malicious user to manipulate the environment or corrupt the training data, thus inserting a backdoor into the trained agent. Such attacks compromise the RL system's reliability, leading to potentially catastrophic results in various key fields. In contrast, relatively limited research has investigated effective defenses against backdoor attacks in RL. This paper proposes the Recovery Triggered States (RTS) method, a novel approach that effectively protects the victim agents from backdoor attacks. RTS involves building a surrogate network to approximate the dynamics model. Developers can then recover the environment from the triggered state to a clean state, thereby preventing attackers from activating backdoors hidden in the agent by presenting the trigger. When training the surrogate to predict states, we incorporate agent action information to reduce the discrepancy between the actions taken by the agent on predicted states and the actions taken on real states. RTS is the first approach to defend against backdoor attacks in a single-agent setting. Our results show that using RTS, the cumulative reward only decreased by 1.41% under the backdoor attack.
coExplore: Combining multiple rankings for multi-robot exploration
Apr 10, 2023

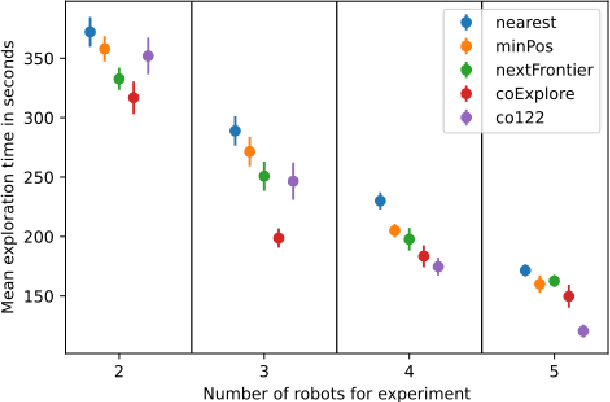
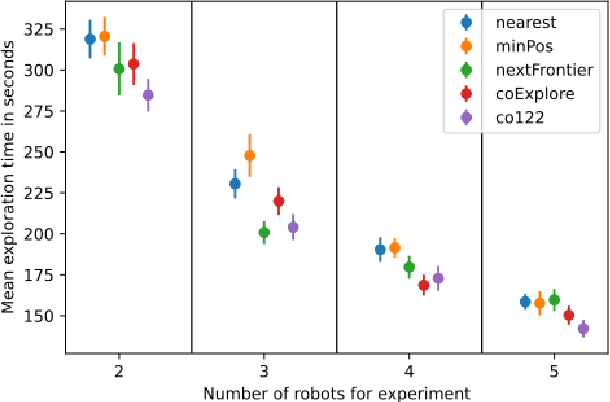
Multi-robot exploration is a field which tackles the challenge of exploring a previously unknown environment with a number of robots. This is especially relevant for search and rescue operations where time is essential. Current state of the art approaches are able to explore a given environment with a large number of robots by assigning them to frontiers. However, this assignment generally favors large frontiers and hence omits potentially valuable medium-sized frontiers. In this paper we showcase a novel multi-robot exploration algorithm, which improves and adapts the existing approaches. Through the addition of information gain based ranking we improve the exploration time for closed urban environments while maintaining similar exploration performance compared to the state-of-the-art for open environments. Accompanying this paper, we further publish our research code in order to lower the barrier to entry for further multi-robot exploration research. We evaluate the performance in three simulated scenarios, two urban and one open scenario, where our algorithm outperforms the state of the art by 5% overall.
Multi-Object Tracking by Iteratively Associating Detections with Uniform Appearance for Trawl-Based Fishing Bycatch Monitoring
Apr 10, 2023
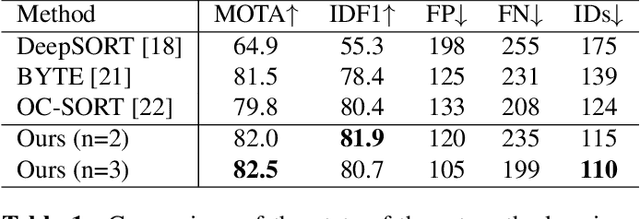

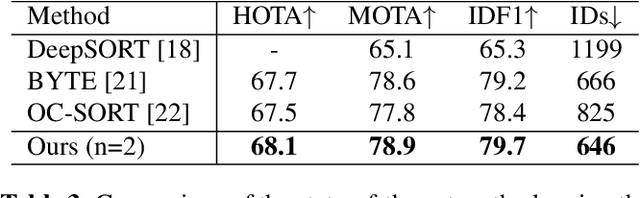
The aim of in-trawl catch monitoring for use in fishing operations is to detect, track and classify fish targets in real-time from video footage. Information gathered could be used to release unwanted bycatch in real-time. However, traditional multi-object tracking (MOT) methods have limitations, as they are developed for tracking vehicles or pedestrians with linear motions and diverse appearances, which are different from the scenarios such as livestock monitoring. Therefore, we propose a novel MOT method, built upon an existing observation-centric tracking algorithm, by adopting a new iterative association step to significantly boost the performance of tracking targets with a uniform appearance. The iterative association module is designed as an extendable component that can be merged into most existing tracking methods. Our method offers improved performance in tracking targets with uniform appearance and outperforms state-of-the-art techniques on our underwater fish datasets as well as the MOT17 dataset, without increasing latency nor sacrificing accuracy as measured by HOTA, MOTA, and IDF1 performance metrics.
ALOFT: A Lightweight MLP-like Architecture with Dynamic Low-frequency Transform for Domain Generalization
Mar 31, 2023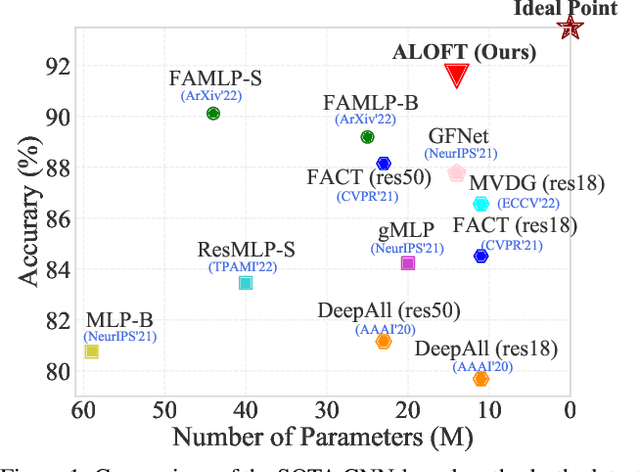
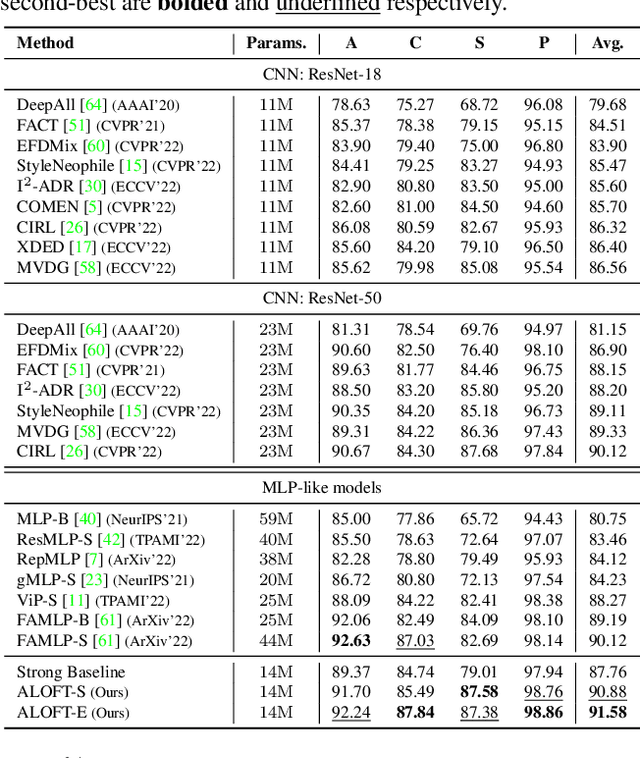
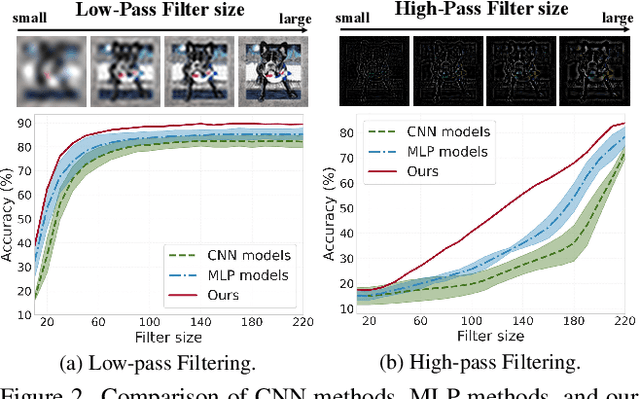
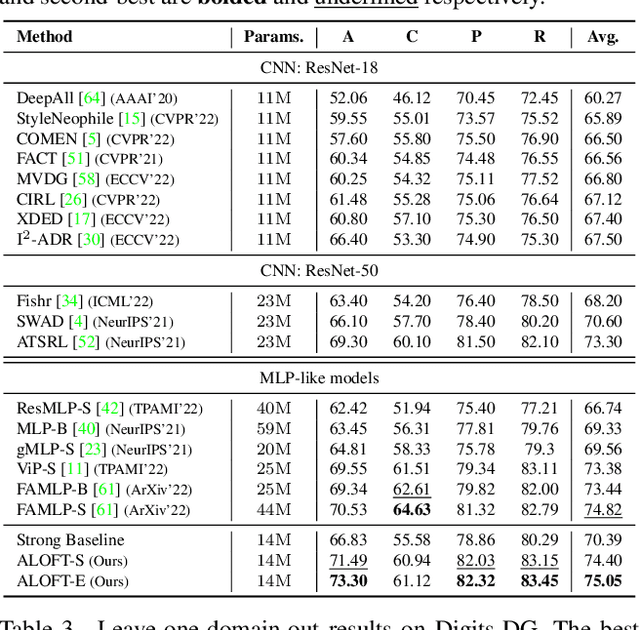
Domain generalization (DG) aims to learn a model that generalizes well to unseen target domains utilizing multiple source domains without re-training. Most existing DG works are based on convolutional neural networks (CNNs). However, the local operation of the convolution kernel makes the model focus too much on local representations (e.g., texture), which inherently causes the model more prone to overfit to the source domains and hampers its generalization ability. Recently, several MLP-based methods have achieved promising results in supervised learning tasks by learning global interactions among different patches of the image. Inspired by this, in this paper, we first analyze the difference between CNN and MLP methods in DG and find that MLP methods exhibit a better generalization ability because they can better capture the global representations (e.g., structure) than CNN methods. Then, based on a recent lightweight MLP method, we obtain a strong baseline that outperforms most state-of-the-art CNN-based methods. The baseline can learn global structure representations with a filter to suppress structure irrelevant information in the frequency space. Moreover, we propose a dynAmic LOw-Frequency spectrum Transform (ALOFT) that can perturb local texture features while preserving global structure features, thus enabling the filter to remove structure-irrelevant information sufficiently. Extensive experiments on four benchmarks have demonstrated that our method can achieve great performance improvement with a small number of parameters compared to SOTA CNN-based DG methods. Our code is available at https://github.com/lingeringlight/ALOFT/.