 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HCAM -- Hierarchical Cross Attention Model for Multi-modal Emotion Recognition
Apr 14, 2023
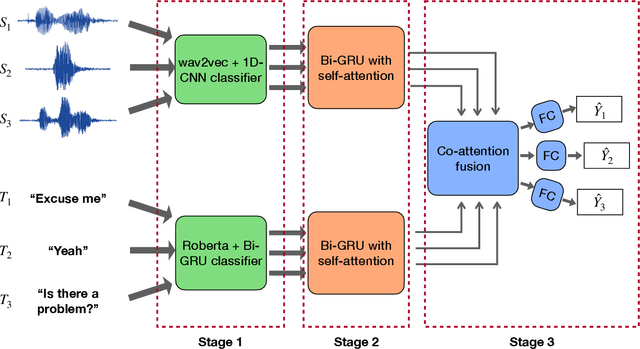
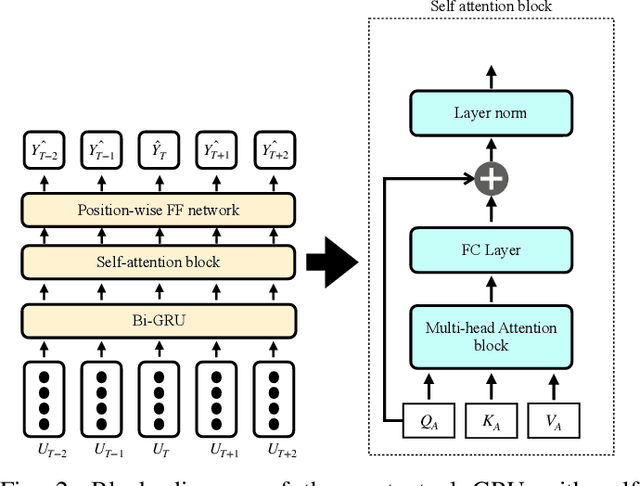
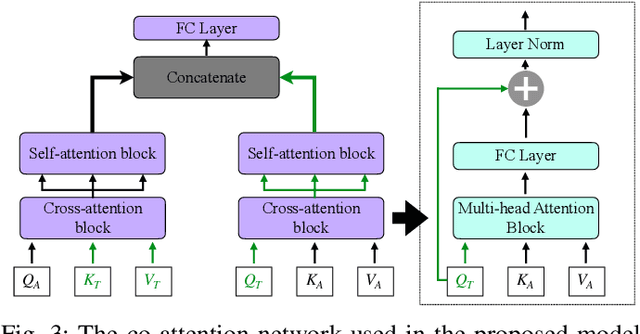
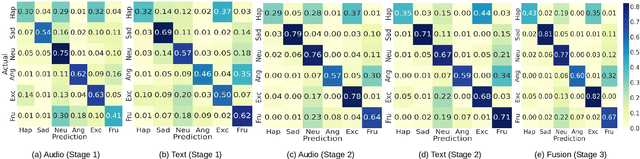
Emotion recognition in conversations is challenging due to the multi-modal nature of the emotion expression. We propose a hierarchical cross-attention model (HCAM) approach to multi-modal emotion recognition using a combination of recurrent and co-attention neural network models. The input to the model consists of two modalities, i) audio data, processed through a learnable wav2vec approach and, ii) text data represented using a bidirectional encoder representations from transformers (BERT) model. The audio and text representations are processed using a set of bi-directional recurrent neural network layers with self-attention that converts each utterance in a given conversation to a fixed dimensional embedding. In order to incorporate contextual knowledge and the information across the two modalities, the audio and text embeddings are combined using a co-attention layer that attempts to weigh the utterance level embeddings relevant to the task of emotion recognition. The neural network parameters in the audio layers, text layers as well as the multi-modal co-attention layers, are hierarchically trained for the emotion classification task. We perform experiments on three established datasets namely, IEMOCAP, MELD and CMU-MOSI, where we illustrate that the proposed model improves significantly over other benchmarks and helps achieve state-of-art results on all these datasets.
LoRCoN-LO: Long-term Recurrent Convolutional Network-based LiDAR Odometry
Mar 21, 2023
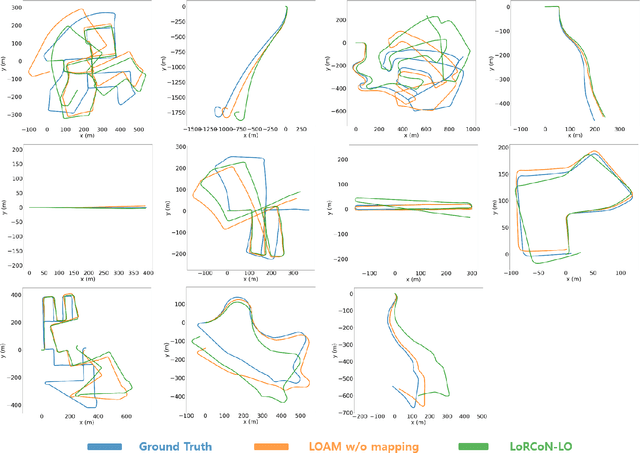
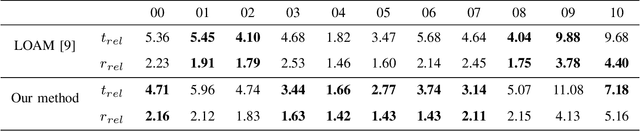
We propose a deep learning-based LiDAR odometry estimation method called LoRCoN-LO that utilizes the long-term recurrent convolutional network (LRCN) structure. The LRCN layer is a structure that can process spatial and temporal information at once by using both CNN and LSTM layers. This feature is suitable for predicting continuous robot movements as it uses point clouds that contain spatial information. Therefore, we built a LoRCoN-LO model using the LRCN layer, and predicted the pose of the robot through this model. For performance verification, we conducted experiments exploiting a public dataset (KITTI). The results of the experiment show that LoRCoN-LO displays accurate odometry prediction in the dataset. The code is available at https://github.com/donghwijung/LoRCoN-LO.
Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
Nov 21, 2022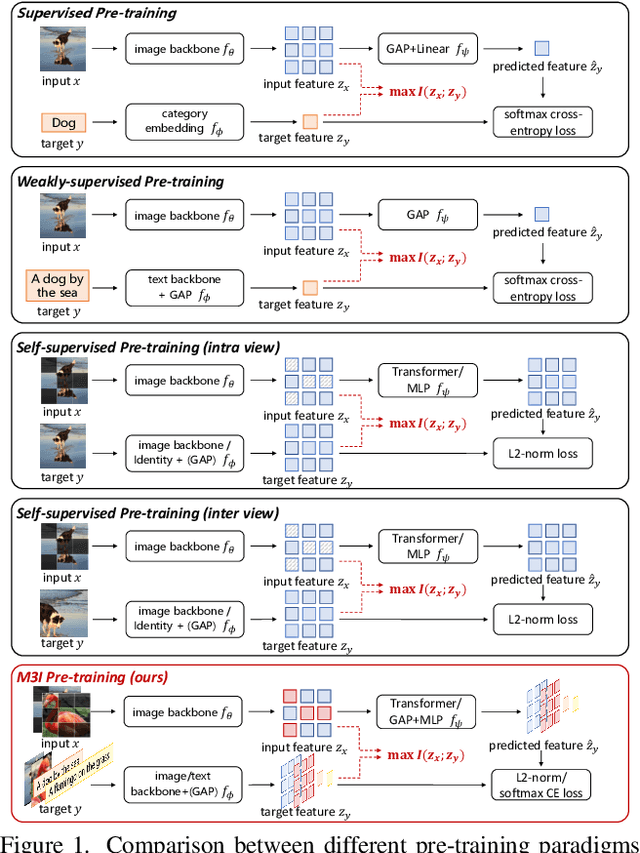
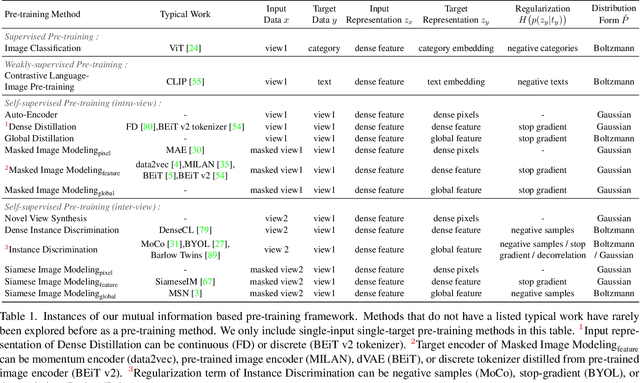
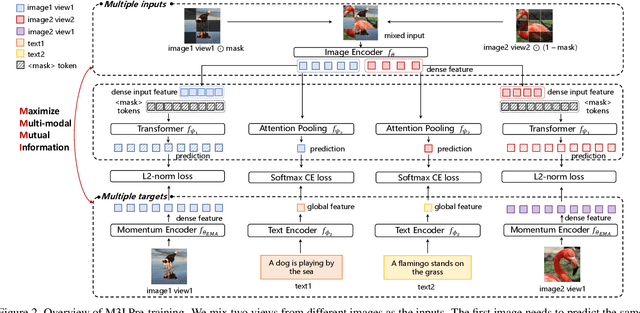
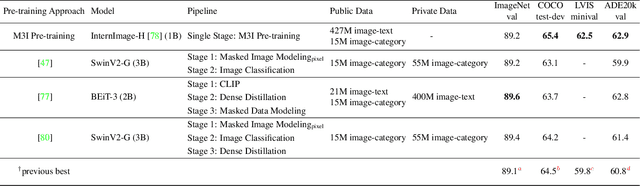
To effectively exploit the potential of large-scale models, various pre-training strategies supported by massive data from different sources are proposed, including supervised pre-training, weakly-supervised pre-training, and self-supervised pre-training. It has been proved that combining multiple pre-training strategies and data from various modalities/sources can greatly boost the training of large-scale models. However, current works adopt a multi-stage pre-training system, where the complex pipeline may increase the uncertainty and instability of the pre-training. It is thus desirable that these strategies can be integrated in a single-stage manner. In this paper, we first propose a general multi-modal mutual information formula as a unified optimization target and demonstrate that all existing approaches are special cases of our framework. Under this unified perspective, we propose an all-in-one single-stage pre-training approach, named Maximizing Multi-modal Mutual Information Pre-training (M3I Pre-training). Our approach achieves better performance than previous pre-training methods on various vision benchmarks, including ImageNet classification, COCO object detection, LVIS long-tailed object detection, and ADE20k semantic segmentation. Notably, we successfully pre-train a billion-level parameter image backbone and achieve state-of-the-art performance on various benchmarks. Code shall be released at https://github.com/OpenGVLab/M3I-Pretraining.
Versatile Depth Estimator Based on Common Relative Depth Estimation and Camera-Specific Relative-to-Metric Depth Conversion
Mar 20, 2023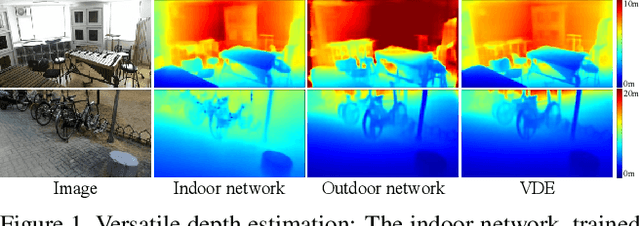

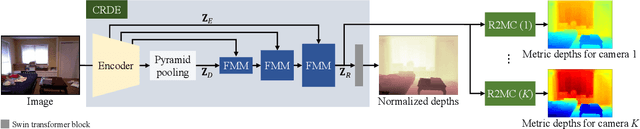

A typical monocular depth estimator is trained for a single camera, so its performance drops severely on images taken with different cameras. To address this issue, we propose a versatile depth estimator (VDE), composed of a common relative depth estimator (CRDE) and multiple relative-to-metric converters (R2MCs). The CRDE extracts relative depth information, and each R2MC converts the relative information to predict metric depths for a specific camera. The proposed VDE can cope with diverse scenes, including both indoor and outdoor scenes, with only a 1.12\% parameter increase per camera. Experimental results demonstrate that VDE supports multiple cameras effectively and efficiently and also achieves state-of-the-art performance in the conventional single-camera scenario.
Multi Modal Facial Expression Recognition with Transformer-Based Fusion Networks and Dynamic Sampling
Mar 19, 2023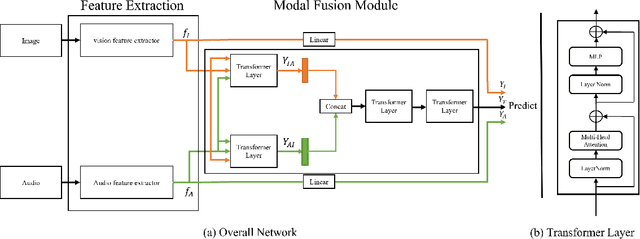
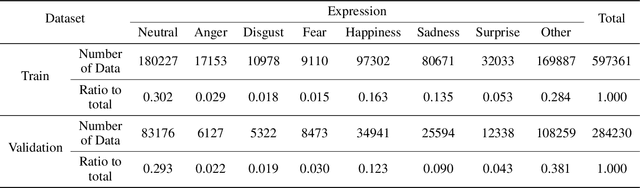
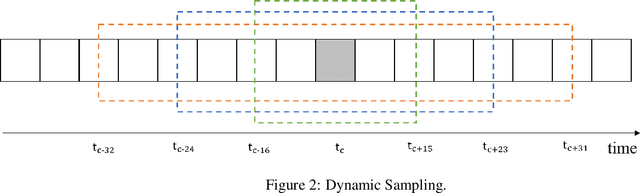
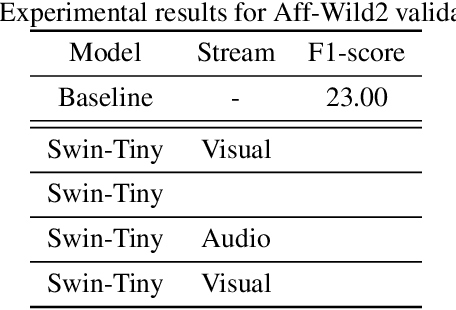
Facial expression recognition is an essential task for various applications, including emotion detection, mental health analysis, and human-machine interactions. In this paper, we propose a multi-modal facial expression recognition method that exploits audio information along with facial images to provide a crucial clue to differentiate some ambiguous facial expressions. Specifically, we introduce a Modal Fusion Module (MFM) to fuse audio-visual information, where image and audio features are extracted from Swin Transformer. Additionally, we tackle the imbalance problem in the dataset by employing dynamic data resampling. Our model has been evaluated in the Affective Behavior in-the-wild (ABAW) challenge of CVPR 2023.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023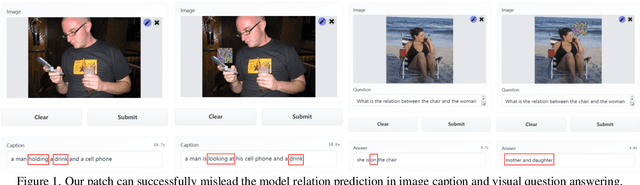
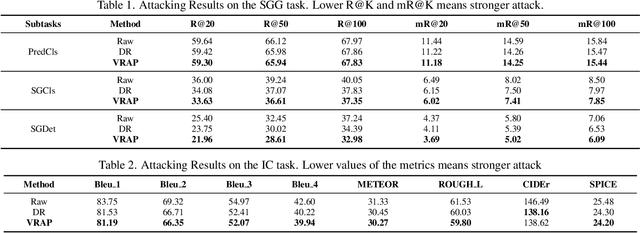
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
BotTriNet: A Unified and Efficient Embedding for Social Bots Detection via Metric Learning
Apr 11, 2023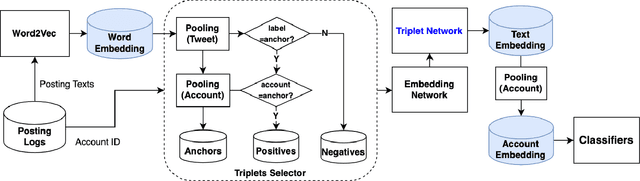
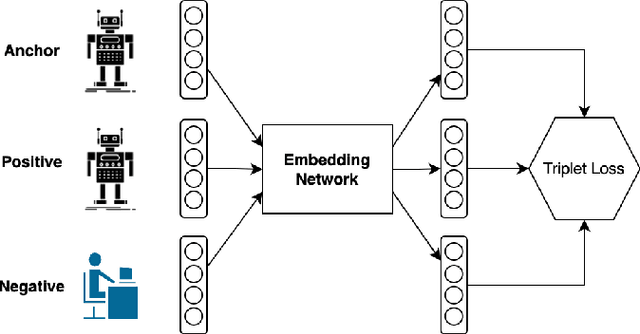

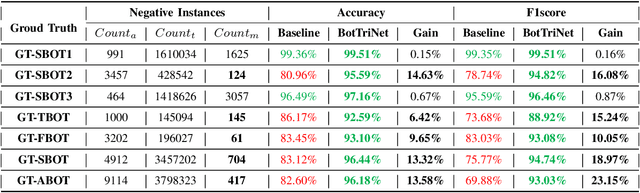
A persistently popular topic in online social networks is the rapid and accurate discovery of bot accounts to prevent their invasion and harassment of genuine users. We propose a unified embedding framework called BotTriNet, which utilizes textual content posted by accounts for bot detection based on the assumption that contexts naturally reveal account personalities and habits. Content is abundant and valuable if the system efficiently extracts bot-related information using embedding techniques. Beyond the general embedding framework that generates word, sentence, and account embeddings, we design a triplet network to tune the raw embeddings (produced by traditional natural language processing techniques) for better classification performance. We evaluate detection accuracy and f1score on a real-world dataset CRESCI2017, comprising three bot account categories and five bot sample sets. Our system achieves the highest average accuracy of 98.34% and f1score of 97.99% on two content-intensive bot sets, outperforming previous work and becoming state-of-the-art. It also makes a breakthrough on four content-less bot sets, with an average accuracy improvement of 11.52% and an average f1score increase of 16.70%.
Shot Noise Reduction in Radiographic and Tomographic Multi-Channel Imaging with Self-Supervised Deep Learning
Mar 25, 2023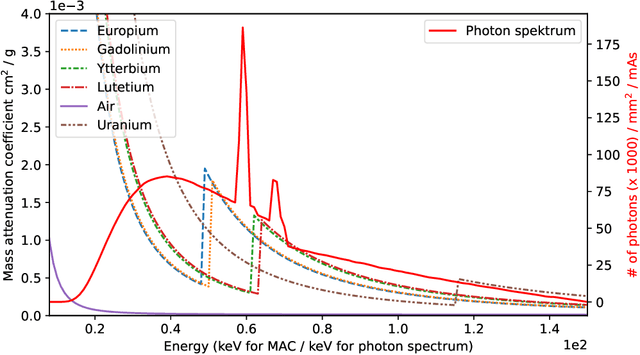
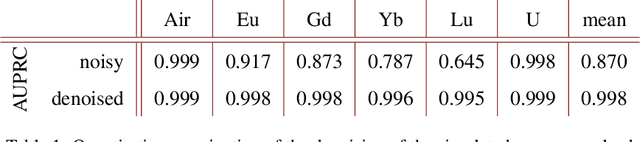
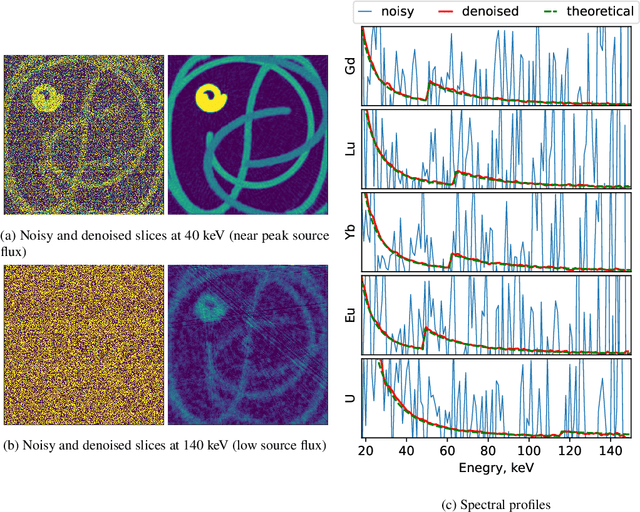

Noise is an important issue for radiographic and tomographic imaging techniques. It becomes particularly critical in applications where additional constraints force a strong reduction of the Signal-to-Noise Ratio (SNR) per image. These constraints may result from limitations on the maximum available flux or permissible dose and the associated restriction on exposure time. Often, a high SNR per image is traded for the ability to distribute a given total exposure capacity per pixel over multiple channels, thus obtaining additional information about the object by the same total exposure time. These can be energy channels in the case of spectroscopic imaging or time channels in the case of time-resolved imaging. In this paper, we report on a method for improving the quality of noisy multi-channel (time or energy-resolved) imaging datasets. The method relies on the recent Noise2Noise (N2N) self-supervised denoising approach that learns to predict a noise-free signal without access to noise-free data. N2N in turn requires drawing pairs of samples from a data distribution sharing identical signals while being exposed to different samples of random noise. The method is applicable if adjacent channels share enough information to provide images with similar enough information but independent noise. We demonstrate several representative case studies, namely spectroscopic (k-edge) X-ray tomography, in vivo X-ray cine-radiography, and energy-dispersive (Bragg edge) neutron tomography. In all cases, the N2N method shows dramatic improvement and outperforms conventional denoising methods. For such imaging techniques, the method can therefore significantly improve image quality, or maintain image quality with further reduced exposure time per image.
Improve Retrieval-based Dialogue System via Syntax-Informed Attention
Mar 12, 2023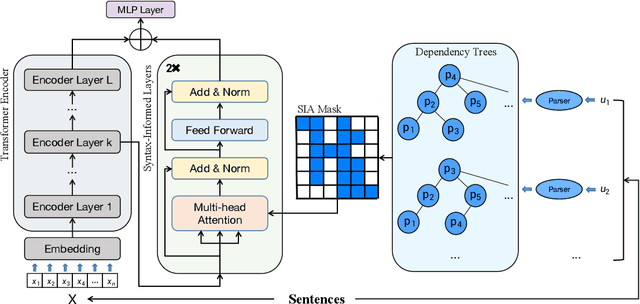
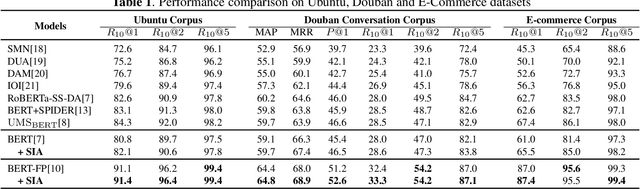

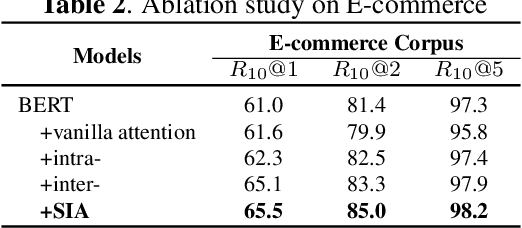
Multi-turn response selection is a challenging task due to its high demands on efficient extraction of the matching features from abundant information provided by context utterances. Since incorporating syntactic information like dependency structures into neural models can promote a better understanding of the sentences, such a method has been widely used in NLP tasks. Though syntactic information helps models achieved pleasing results, its application in retrieval-based dialogue systems has not been fully explored. Meanwhile, previous works focus on intra-sentence syntax alone, which is far from satisfactory for the task of multi-turn response where dialogues usually contain multiple sentences. To this end, we propose SIA, Syntax-Informed Attention, considering both intra- and inter-sentence syntax information. While the former restricts attention scope to only between tokens and corresponding dependents in the syntax tree, the latter allows attention in cross-utterance pairs for those syntactically important tokens. We evaluate our method on three widely used benchmarks and experimental results demonstrate the general superiority of our method on dialogue response selection.