 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
WYTIWYR: A User Intent-Aware Framework with Multi-modal Inputs for Visualization Retrieval
Apr 14, 2023
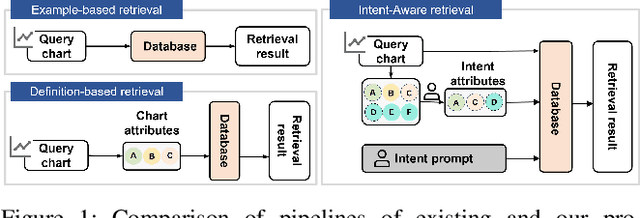

Retrieving charts from a large corpus is a fundamental task that can benefit numerous applications such as visualization recommendations.The retrieved results are expected to conform to both explicit visual attributes (e.g., chart type, colormap) and implicit user intents (e.g., design style, context information) that vary upon application scenarios. However, existing example-based chart retrieval methods are built upon non-decoupled and low-level visual features that are hard to interpret, while definition-based ones are constrained to pre-defined attributes that are hard to extend. In this work, we propose a new framework, namely WYTIWYR (What-You-Think-Is-What-You-Retrieve), that integrates user intents into the chart retrieval process. The framework consists of two stages: first, the Annotation stage disentangles the visual attributes within the bitmap query chart; and second, the Retrieval stage embeds the user's intent with customized text prompt as well as query chart, to recall targeted retrieval result. We develop a prototype WYTIWYR system leveraging a contrastive language-image pre-training (CLIP) model to achieve zero-shot classification, and test the prototype on a large corpus with charts crawled from the Internet. Quantitative experiments, case studies, and qualitative interviews are conducted. The results demonstrate the usability and effectiveness of our proposed framework.
Frequency Decomposition to Tap the Potential of Single Domain for Generalization
Apr 14, 2023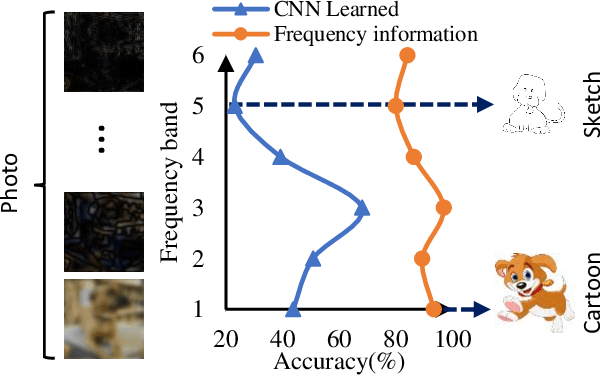
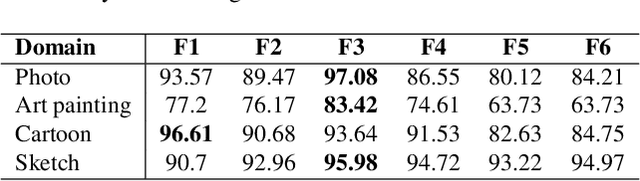
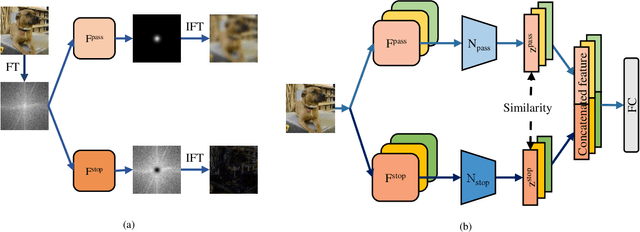
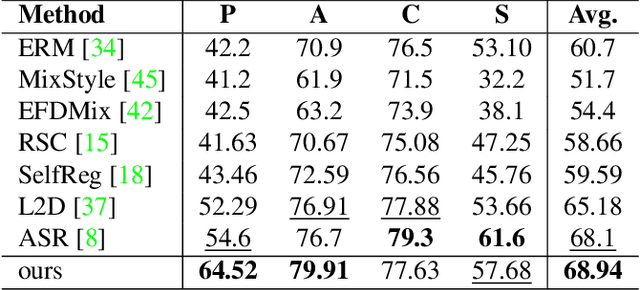
Domain generalization (DG), aiming at models able to work on multiple unseen domains, is a must-have characteristic of general artificial intelligence. DG based on single source domain training data is more challenging due to the lack of comparable information to help identify domain invariant features. In this paper, it is determined that the domain invariant features could be contained in the single source domain training samples, then the task is to find proper ways to extract such domain invariant features from the single source domain samples. An assumption is made that the domain invariant features are closely related to the frequency. Then, a new method that learns through multiple frequency domains is proposed. The key idea is, dividing the frequency domain of each original image into multiple subdomains, and learning features in the subdomain by a designed two branches network. In this way, the model is enforced to learn features from more samples of the specifically limited spectrum, which increases the possibility of obtaining the domain invariant features that might have previously been defiladed by easily learned features. Extensive experimental investigation reveals that 1) frequency decomposition can help the model learn features that are difficult to learn. 2) the proposed method outperforms the state-of-the-art methods of single-source domain generalization.
HCAM -- Hierarchical Cross Attention Model for Multi-modal Emotion Recognition
Apr 14, 2023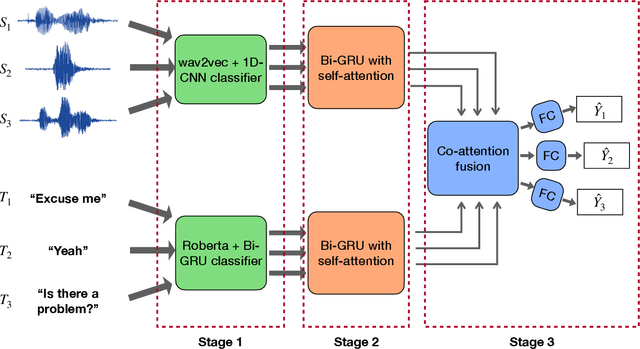
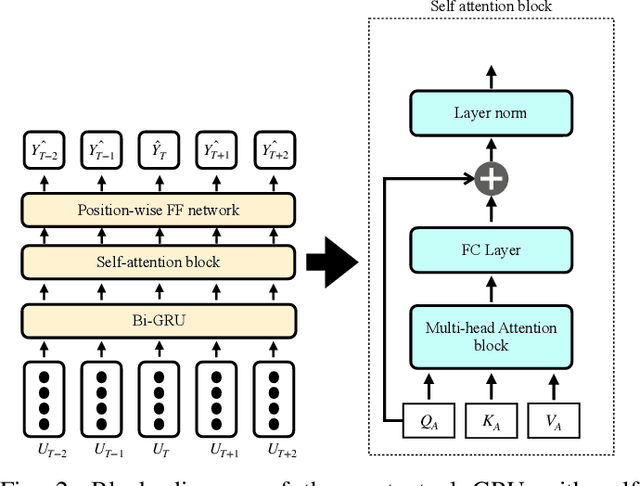
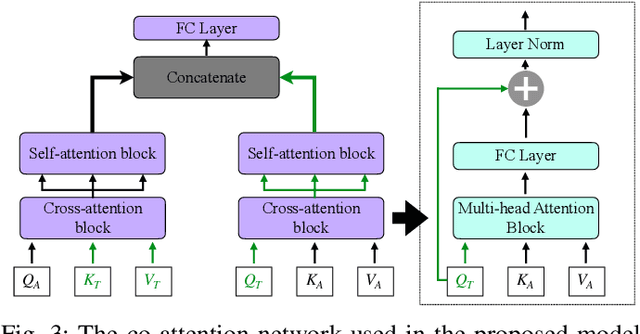
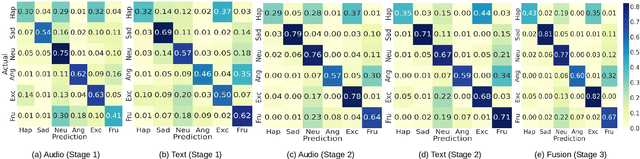
Emotion recognition in conversations is challenging due to the multi-modal nature of the emotion expression. We propose a hierarchical cross-attention model (HCAM) approach to multi-modal emotion recognition using a combination of recurrent and co-attention neural network models. The input to the model consists of two modalities, i) audio data, processed through a learnable wav2vec approach and, ii) text data represented using a bidirectional encoder representations from transformers (BERT) model. The audio and text representations are processed using a set of bi-directional recurrent neural network layers with self-attention that converts each utterance in a given conversation to a fixed dimensional embedding. In order to incorporate contextual knowledge and the information across the two modalities, the audio and text embeddings are combined using a co-attention layer that attempts to weigh the utterance level embeddings relevant to the task of emotion recognition. The neural network parameters in the audio layers, text layers as well as the multi-modal co-attention layers, are hierarchically trained for the emotion classification task. We perform experiments on three established datasets namely, IEMOCAP, MELD and CMU-MOSI, where we illustrate that the proposed model improves significantly over other benchmarks and helps achieve state-of-art results on all these datasets.
Information retrieval in single cell chromatin analysis using TF-IDF transformation methods
Dec 10, 2022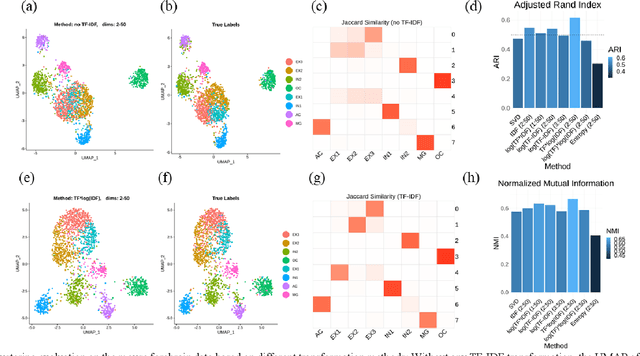
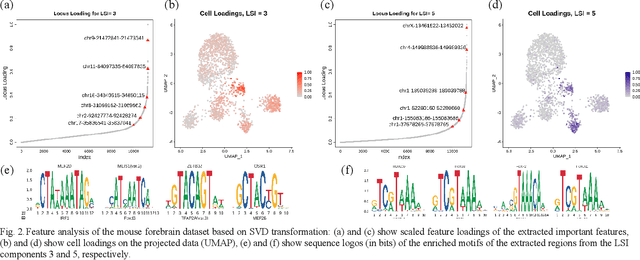
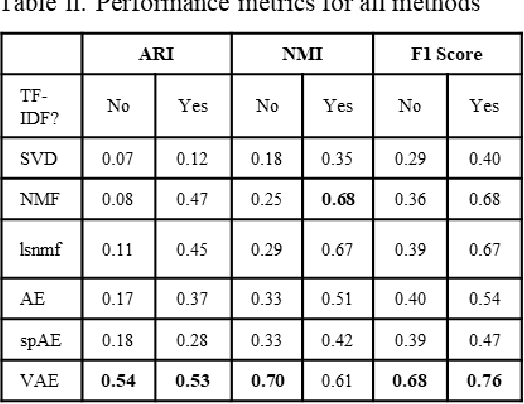
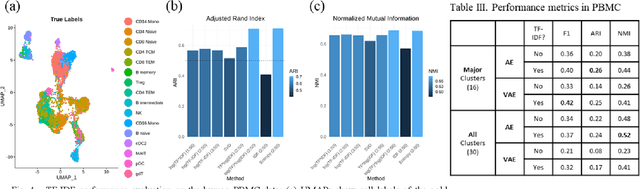
Single-cell sequencing assay for transposase-accessible chromatin (scATAC-seq) assesses genome-wide chromatin accessibility in thousands of cells to reveal regulatory landscapes in high resolutions. However, the analysis presents challenges due to the high dimensionality and sparsity of the data. Several methods have been developed, including transformation techniques of term-frequency inverse-document frequency (TF-IDF), dimension reduction methods such as singular value decomposition (SVD), factor analysis, and autoencoders. Yet, a comprehensive study on the mentioned methods has not been fully performed. It is not clear what is the best practice when analyzing scATAC-seq data. We compared several scenarios for transformation and dimension reduction as well as the SVD-based feature analysis to investigate potential enhancements in scATAC-seq information retrieval. Additionally, we investigate if autoencoders benefit from the TF-IDF transformation. Our results reveal that the TF-IDF transformation generally leads to improved clustering and biologically relevant feature extraction.
AutoPV: Automated photovoltaic forecasts with limited information using an ensemble of pre-trained models
Dec 13, 2022
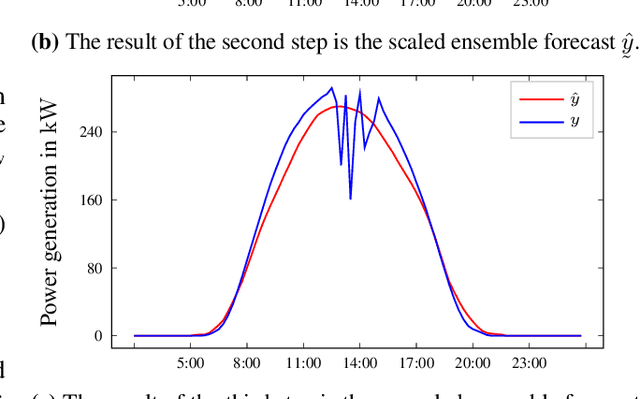
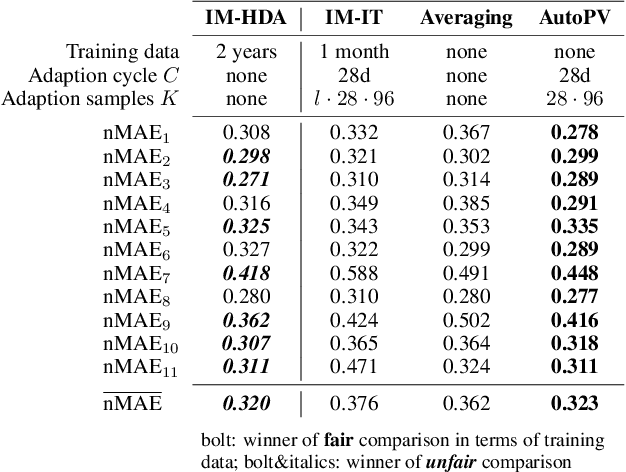
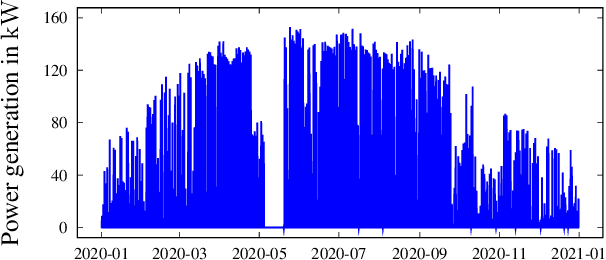
Accurate PhotoVoltaic (PV) power generation forecasting is vital for the efficient operation of Smart Grids. The automated design of such accurate forecasting models for individual PV plants includes two challenges: First, information about the PV mounting configuration (i.e. inclination and azimuth angles) is often missing. Second, for new PV plants, the amount of historical data available to train a forecasting model is limited (cold-start problem). We address these two challenges by proposing a new method for day-ahead PV power generation forecasts called AutoPV. AutoPV is a weighted ensemble of forecasting models that represent different PV mounting configurations. This representation is achieved by pre-training each forecasting model on a separate PV plant and by scaling the model's output with the peak power rating of the corresponding PV plant. To tackle the cold-start problem, we initially weight each forecasting model in the ensemble equally. To tackle the problem of missing information about the PV mounting configuration, we use new data that become available during operation to adapt the ensemble weights to minimize the forecasting error. AutoPV is advantageous as the unknown PV mounting configuration is implicitly reflected in the ensemble weights, and only the PV plant's peak power rating is required to re-scale the ensemble's output. AutoPV also allows to represent PV plants with panels distributed on different roofs with varying alignments, as these mounting configurations can be reflected proportionally in the weighting. Additionally, the required computing memory is decoupled when scaling AutoPV to hundreds of PV plants, which is beneficial in Smart Grids with limited computing capabilities. For a real-world data set with 11 PV plants, the accuracy of AutoPV is comparable to a model trained on two years of data and outperforms an incrementally trained model.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023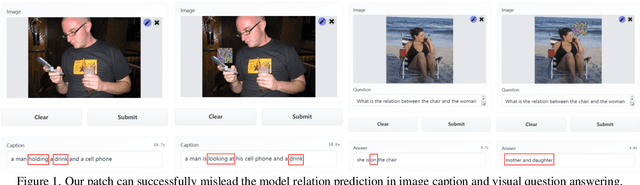
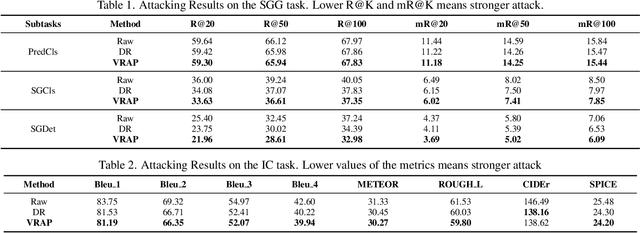
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
BotTriNet: A Unified and Efficient Embedding for Social Bots Detection via Metric Learning
Apr 11, 2023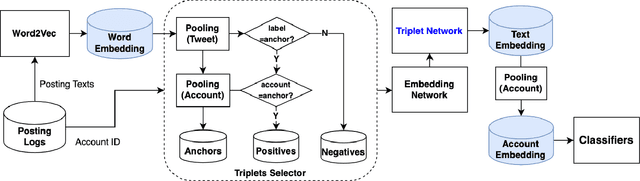
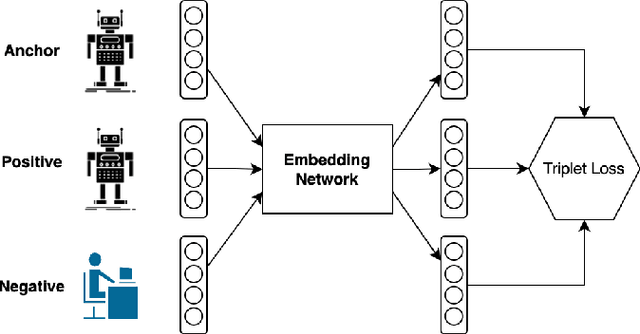

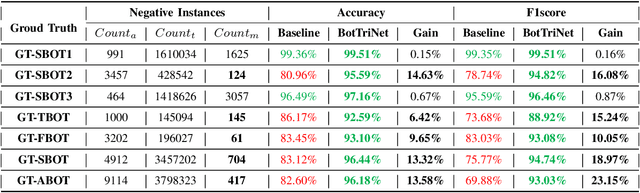
A persistently popular topic in online social networks is the rapid and accurate discovery of bot accounts to prevent their invasion and harassment of genuine users. We propose a unified embedding framework called BotTriNet, which utilizes textual content posted by accounts for bot detection based on the assumption that contexts naturally reveal account personalities and habits. Content is abundant and valuable if the system efficiently extracts bot-related information using embedding techniques. Beyond the general embedding framework that generates word, sentence, and account embeddings, we design a triplet network to tune the raw embeddings (produced by traditional natural language processing techniques) for better classification performance. We evaluate detection accuracy and f1score on a real-world dataset CRESCI2017, comprising three bot account categories and five bot sample sets. Our system achieves the highest average accuracy of 98.34% and f1score of 97.99% on two content-intensive bot sets, outperforming previous work and becoming state-of-the-art. It also makes a breakthrough on four content-less bot sets, with an average accuracy improvement of 11.52% and an average f1score increase of 16.70%.
Transition Propagation Graph Neural Networks for Temporal Networks
Apr 15, 2023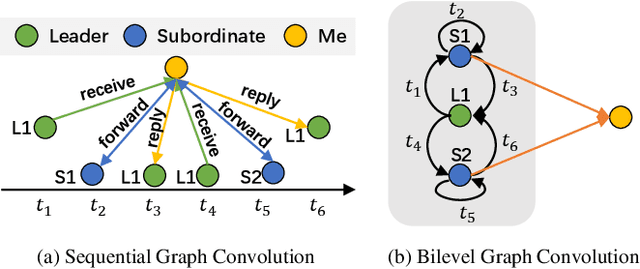
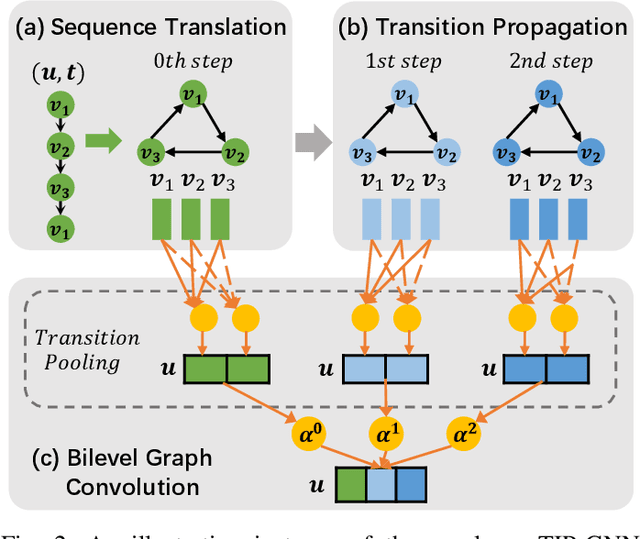
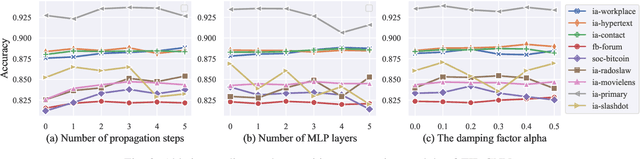
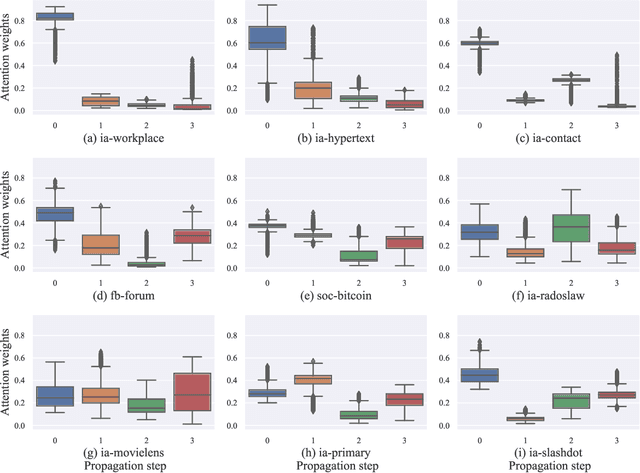
Researchers of temporal networks (e.g., social networks and transaction networks) have been interested in mining dynamic patterns of nodes from their diverse interactions. Inspired by recently powerful graph mining methods like skip-gram models and Graph Neural Networks (GNNs), existing approaches focus on generating temporal node embeddings sequentially with nodes' sequential interactions. However, the sequential modeling of previous approaches cannot handle the transition structure between nodes' neighbors with limited memorization capacity. Detailedly, an effective method for the transition structures is required to both model nodes' personalized patterns adaptively and capture node dynamics accordingly. In this paper, we propose a method, namely Transition Propagation Graph Neural Networks (TIP-GNN), to tackle the challenges of encoding nodes' transition structures. The proposed TIP-GNN focuses on the bilevel graph structure in temporal networks: besides the explicit interaction graph, a node's sequential interactions can also be constructed as a transition graph. Based on the bilevel graph, TIP-GNN further encodes transition structures by multi-step transition propagation and distills information from neighborhoods by a bilevel graph convolution. Experimental results over various temporal networks reveal the efficiency of our TIP-GNN, with at most 7.2\% improvements of accuracy on temporal link prediction. Extensive ablation studies further verify the effectiveness and limitations of the transition propagation module. Our code is available at \url{https://github.com/doujiang-zheng/TIP-GNN}.
Multi-View Graph Representation Learning Beyond Homophily
Apr 15, 2023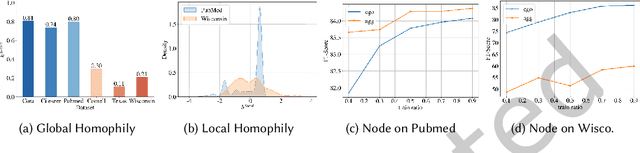
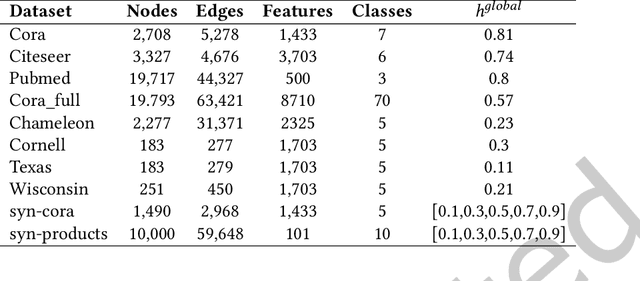
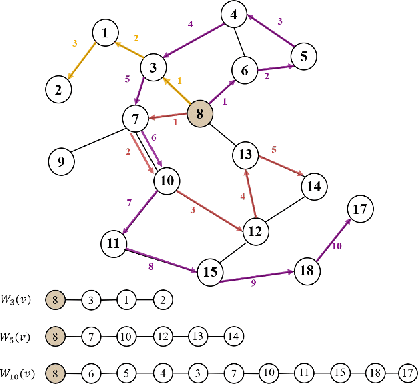
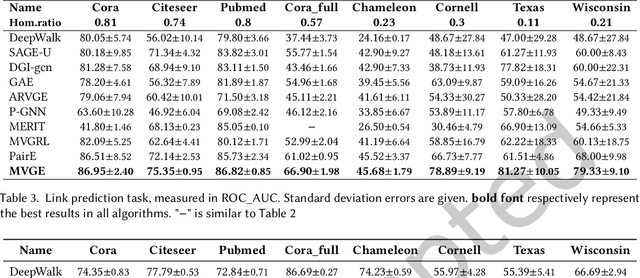
Unsupervised graph representation learning(GRL) aims to distill diverse graph information into task-agnostic embeddings without label supervision. Due to a lack of support from labels, recent representation learning methods usually adopt self-supervised learning, and embeddings are learned by solving a handcrafted auxiliary task(so-called pretext task). However, partially due to the irregular non-Euclidean data in graphs, the pretext tasks are generally designed under homophily assumptions and cornered in the low-frequency signals, which results in significant loss of other signals, especially high-frequency signals widespread in graphs with heterophily. Motivated by this limitation, we propose a multi-view perspective and the usage of diverse pretext tasks to capture different signals in graphs into embeddings. A novel framework, denoted as Multi-view Graph Encoder(MVGE), is proposed, and a set of key designs are identified. More specifically, a set of new pretext tasks are designed to encode different types of signals, and a straightforward operation is propxwosed to maintain both the commodity and personalization in both the attribute and the structural levels. Extensive experiments on synthetic and real-world network datasets show that the node representations learned with MVGE achieve significant performance improvements in three different downstream tasks, especially on graphs with heterophily. Source code is available at \url{https://github.com/G-AILab/MVGE}.