 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Controllable Face Generation with Semantic Latent Diffusion Models
Mar 19, 2024

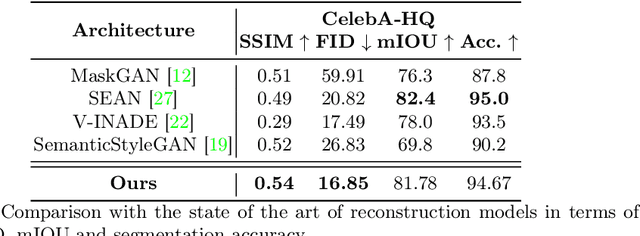
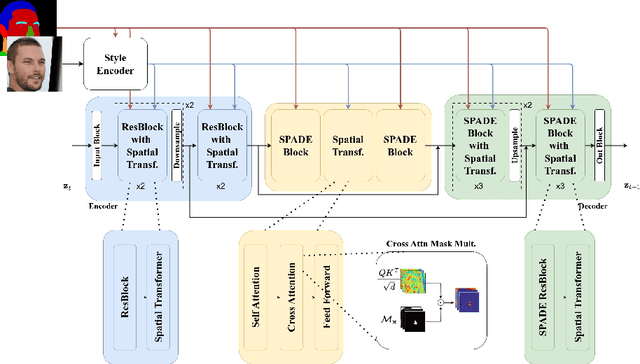

Semantic Image Synthesis (SIS) is among the most popular and effective techniques in the field of face generation and editing, thanks to its good generation quality and the versatility is brings along. Recent works attempted to go beyond the standard GAN-based framework, and started to explore Diffusion Models (DMs) for this task as these stand out with respect to GANs in terms of both quality and diversity. On the other hand, DMs lack in fine-grained controllability and reproducibility. To address that, in this paper we propose a SIS framework based on a novel Latent Diffusion Model architecture for human face generation and editing that is both able to reproduce and manipulate a real reference image and generate diversity-driven results. The proposed system utilizes both SPADE normalization and cross-attention layers to merge shape and style information and, by doing so, allows for a precise control over each of the semantic parts of the human face. This was not possible with previous methods in the state of the art. Finally, we performed an extensive set of experiments to prove that our model surpasses current state of the art, both qualitatively and quantitatively.
TransformMix: Learning Transformation and Mixing Strategies from Data
Mar 19, 2024
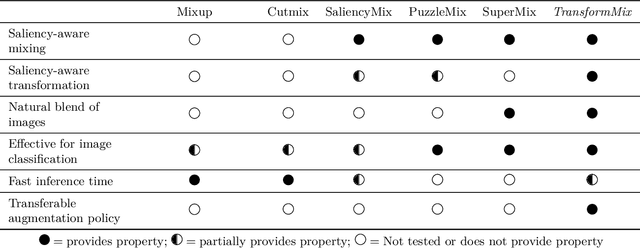

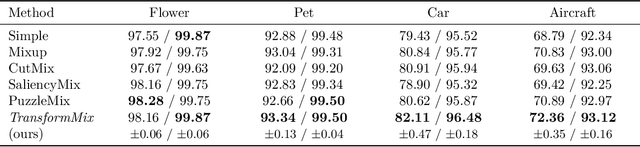
Data augmentation improves the generalization power of deep learning models by synthesizing more training samples. Sample-mixing is a popular data augmentation approach that creates additional data by combining existing samples. Recent sample-mixing methods, like Mixup and Cutmix, adopt simple mixing operations to blend multiple inputs. Although such a heuristic approach shows certain performance gains in some computer vision tasks, it mixes the images blindly and does not adapt to different datasets automatically. A mixing strategy that is effective for a particular dataset does not often generalize well to other datasets. If not properly configured, the methods may create misleading mixed images, which jeopardize the effectiveness of sample-mixing augmentations. In this work, we propose an automated approach, TransformMix, to learn better transformation and mixing augmentation strategies from data. In particular, TransformMix applies learned transformations and mixing masks to create compelling mixed images that contain correct and important information for the target tasks. We demonstrate the effectiveness of TransformMix on multiple datasets in transfer learning, classification, object detection, and knowledge distillation settings. Experimental results show that our method achieves better performance as well as efficiency when compared with strong sample-mixing baselines.
UniDexFPM: Universal Dexterous Functional Pre-grasp Manipulation Via Diffusion Policy
Mar 19, 2024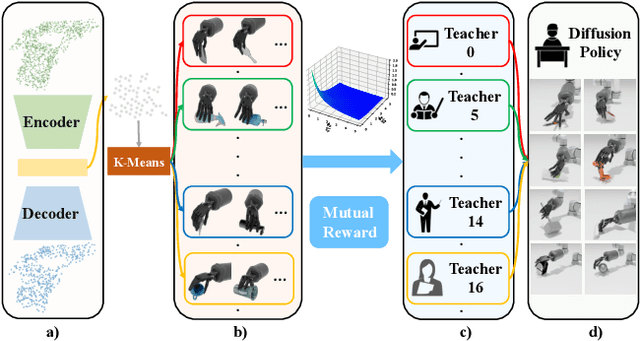
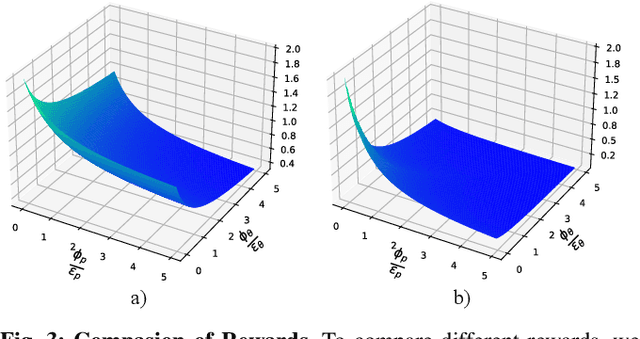
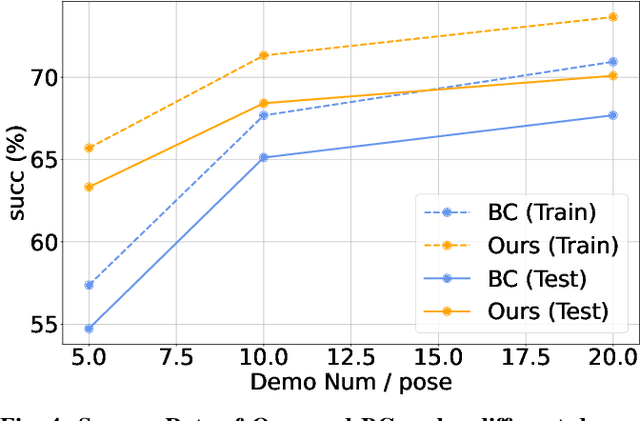
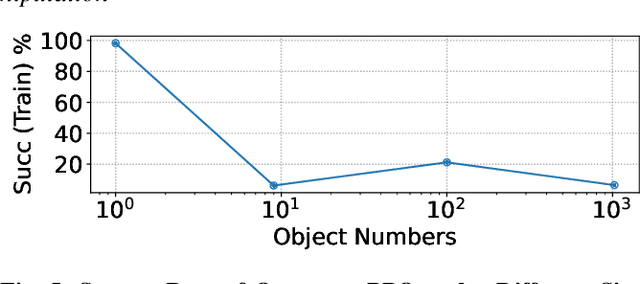
Objects in the real world are often not naturally positioned for functional grasping, which usually requires repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. However, effective learning of universal dexterous functional pre-grasp manipulation necessitates precise control over relative position, relative orientation, and contact between the hand and object, while generalizing to diverse dynamic scenarios with varying objects and goal poses. We address the challenge by using teacher-student learning. We propose a novel mutual reward that incentivizes agents to jointly optimize three key criteria. Furthermore, we introduce a pipeline that leverages a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across 30+ object categories encompassing 1400+ objects and 10k+ goal poses. Notably, our method relies solely on object pose information for universal dexterous functional pre-grasp manipulation by using extrinsic dexterity and adjusting from feedback. Additional experiments under noisy object pose observation showcase the robustness of our method and its potential for real-world applications. The demonstrations can be viewed at https://unidexfpm.github.io.
Multi-View Active Sensing for Human-Robot Interaction via Hierarchically Connected Tree
Mar 19, 2024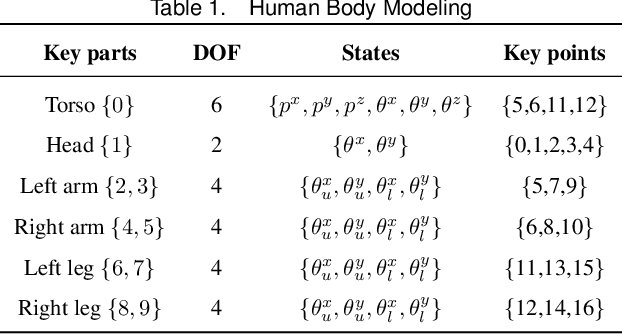
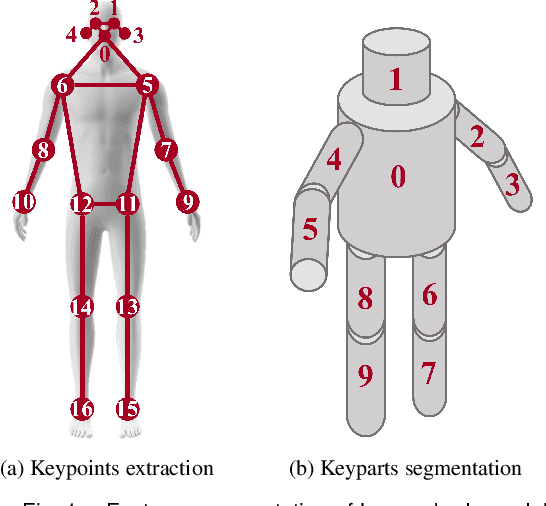
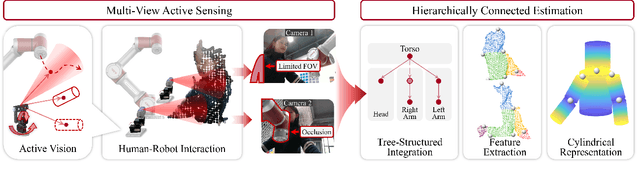
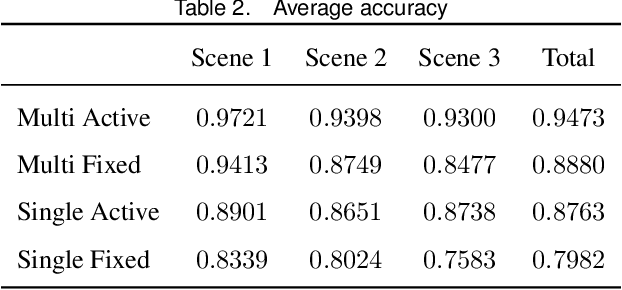
Comprehensive perception of human beings is the prerequisite to ensure the safety of human-robot interaction. Currently, prevailing visual sensing approach typically involves a single static camera, resulting in a restricted and occluded field of view. In our work, we develop an active vision system using multiple cameras to dynamically capture multi-source RGB-D data. An integrated human sensing strategy based on a hierarchically connected tree structure is proposed to fuse localized visual information. Constituting the tree model are the nodes representing keypoints and the edges representing keyparts, which are consistently interconnected to preserve the structural constraints during multi-source fusion. Utilizing RGB-D data and HRNet, the 3D positions of keypoints are analytically estimated, and their presence is inferred through a sliding widow of confidence scores. Subsequently, the point clouds of reliable keyparts are extracted by drawing occlusion-resistant masks, enabling fine registration between data clouds and cylindrical model following the hierarchical order. Experimental results demonstrate that our method enhances keypart recognition recall from 69.20% to 90.10%, compared to employing a single static camera. Furthermore, in overcoming challenges related to localized and occluded perception, the robotic arm's obstacle avoidance capabilities are effectively improved.
Smart Resource Allocation at mmWave/THz Frequencies with Cooperative Rate-Splitting
Mar 19, 2024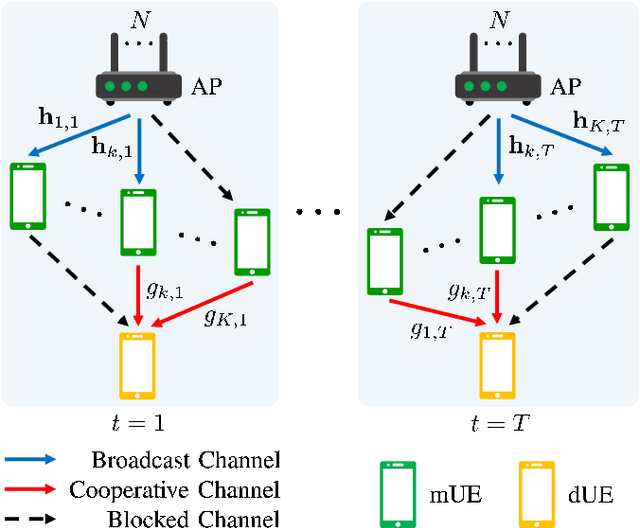
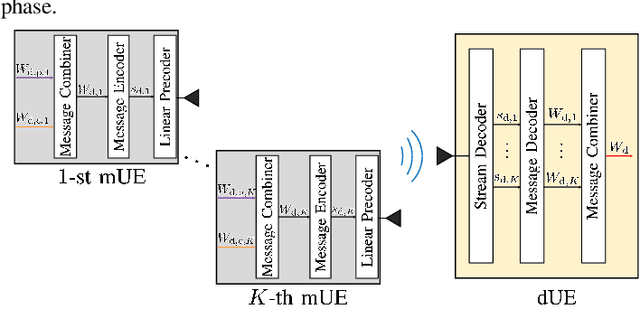
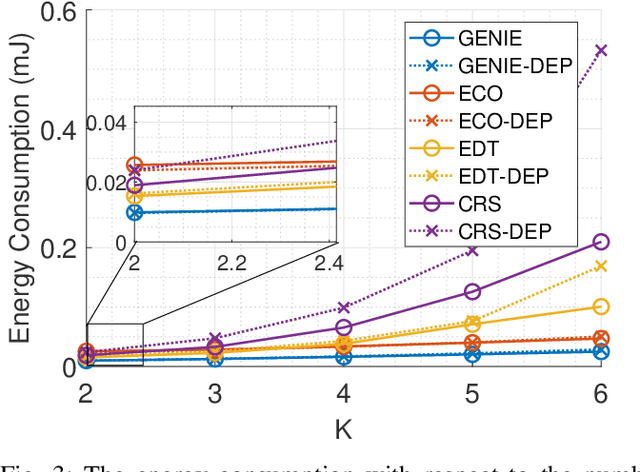
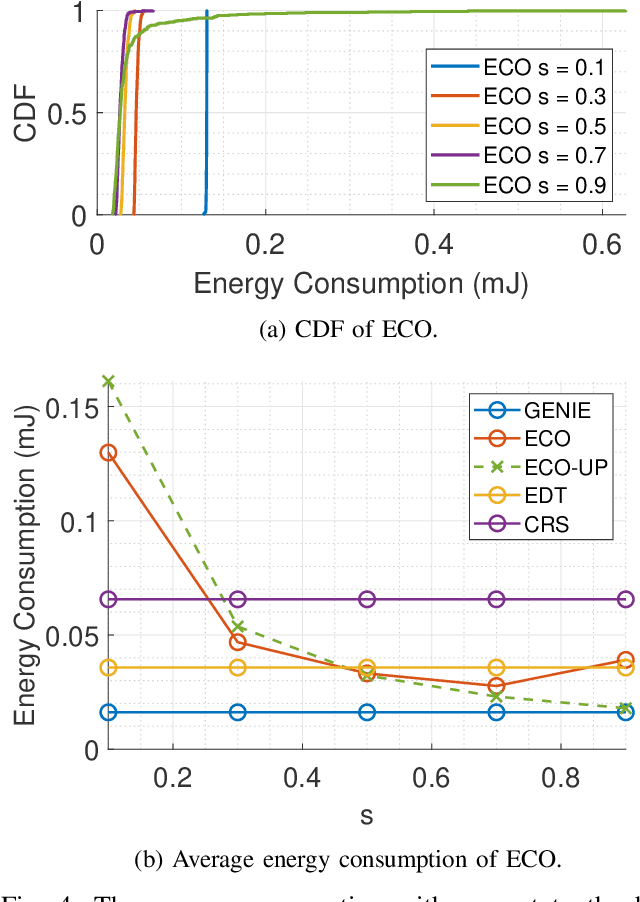
In this paper, we propose algorithms to minimize the energy consumption in millimeter wave/terahertz multi-user downlink communication systems. To ensure coverage in blockage-vulnerable high frequency systems, we consider cooperative rate-splitting (CRS) and transmission over multiple time blocks, where via CRS, multiple users cooperate to assist a blocked user. Moreover, we show that transmission over multiple time blocks provides benefits through smart resource allocation. We first propose a communication framework named improved distinct extraction-based CRS (iDeCRS) that utilizes the benefits of rate-splitting. With our transmission framework, we derive a performance benchmark assuming genie channel state information (CSI), i.e., the channels of the present and future time blocks are known, denoted as GENIE. Using the results from GENIE, we derive a novel efficiency constrained optimization (ECO) algorithm assuming instantaneous CSI. In addition, a simple but effective even data transmission (EDT) algorithm that promotes steady transmission along the time blocks is proposed. Simulation results show that ECO and EDT have satisfactory performances compared to GENIE. The results also show that ECO outperforms EDT when many users are cooperating, and vise versa.
Assessing effect sizes, variability, and power in the on-line study of language production
Mar 19, 2024With the pandemic, many experimental psychologists and linguists have started to collect data over the internet (hereafter on-line data). The feasibility of such experiments and the sample sizes required to achieve sufficient statistical power in future experiments have to be assessed. This in turn requires information on effect sizes and variability. In a series of analyses, we compare response time data obtained in the same word production experiment conducted in the lab and on-line. These analyses allow us to determine whether the two settings differ in effect sizes, in the consistency of responses over the course of the experiment, in the variability of average response times across participants, in the magnitude of effect sizes across participants, or in the amount of unexplained variability. We assess the impact of these differences on the power of the design in a series of simulations. Our findings temper the enthusiasm raised by previous studies and suggest that on-line production studies might be feasible but at a non-negligible cost. The sample sizes required to achieve sufficient power in on-line language production studies come with a non-negligible increase in the amount of manual labour.
AI-enhanced Collective Intelligence: The State of the Art and Prospects
Mar 19, 2024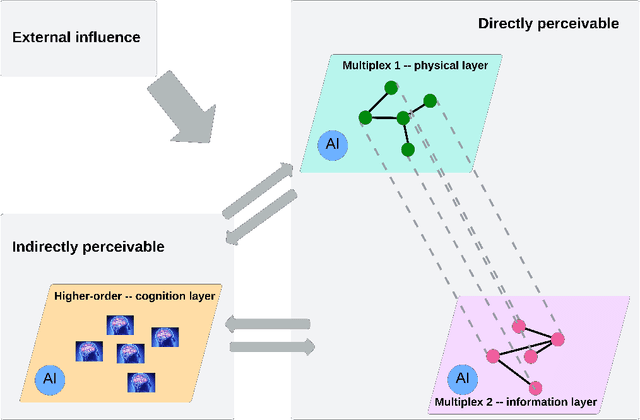
The current societal challenges exceed the capacity of human individual or collective effort alone. As AI evolves, its role within human collectives is poised to vary from an assistive tool to a participatory member. Humans and AI possess complementary capabilities that, when synergized, can achieve a level of collective intelligence that surpasses the collective capabilities of either humans or AI in isolation. However, the interactions in human-AI systems are inherently complex, involving intricate processes and interdependencies. This review incorporates perspectives from network science to conceptualize a multilayer representation of human-AI collective intelligence, comprising a cognition layer, a physical layer, and an information layer. Within this multilayer network, humans and AI agents exhibit varying characteristics; humans differ in diversity from surface-level to deep-level attributes, while AI agents range in degrees of functionality and anthropomorphism. The interplay among these agents shapes the overall structure and dynamics of the system. We explore how agents' diversity and interactions influence the system's collective intelligence. Furthermore, we present an analysis of real-world instances of AI-enhanced collective intelligence. We conclude by addressing the potential challenges in AI-enhanced collective intelligence and offer perspectives on future developments in this field.
Fair Distributed Cooperative Bandit Learning on Networks for Intelligent Internet of Things Systems (Technical Report)
Mar 18, 2024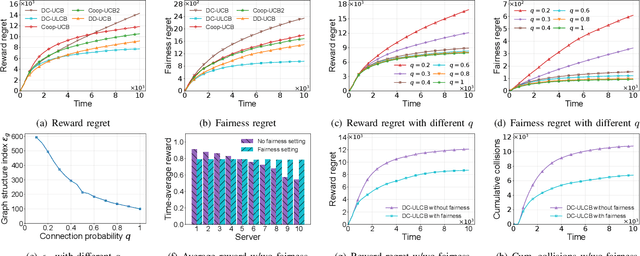
In intelligent Internet of Things (IoT) systems, edge servers within a network exchange information with their neighbors and collect data from sensors to complete delivered tasks. In this paper, we propose a multiplayer multi-armed bandit model for intelligent IoT systems to facilitate data collection and incorporate fairness considerations. In our model, we establish an effective communication protocol that helps servers cooperate with their neighbors. Then we design a distributed cooperative bandit algorithm, DC-ULCB, enabling servers to collaboratively select sensors to maximize data rates while maintaining fairness in their choices. We conduct an analysis of the reward regret and fairness regret of DC-ULCB, and prove that both regrets have logarithmic instance-dependent upper bounds. Additionally, through extensive simulations, we validate that DC-ULCB outperforms existing algorithms in maximizing reward and ensuring fairness.
Fuzzy Rough Choquet Distances for Classification
Mar 18, 2024
This paper introduces a novel Choquet distance using fuzzy rough set based measures. The proposed distance measure combines the attribute information received from fuzzy rough set theory with the flexibility of the Choquet integral. This approach is designed to adeptly capture non-linear relationships within the data, acknowledging the interplay of the conditional attributes towards the decision attribute and resulting in a more flexible and accurate distance. We explore its application in the context of machine learning, with a specific emphasis on distance-based classification approaches (e.g. k-nearest neighbours). The paper examines two fuzzy rough set based measures that are based on the positive region. Moreover, we explore two procedures for monotonizing the measures derived from fuzzy rough set theory, making them suitable for use with the Choquet integral, and investigate their differences.
Prediction of Vessel Arrival Time to Pilotage Area Using Multi-Data Fusion and Deep Learning
Mar 15, 2024This paper investigates the prediction of vessels' arrival time to the pilotage area using multi-data fusion and deep learning approaches. Firstly, the vessel arrival contour is extracted based on Multivariate Kernel Density Estimation (MKDE) and clustering. Secondly, multiple data sources, including Automatic Identification System (AIS), pilotage booking information, and meteorological data, are fused before latent feature extraction. Thirdly, a Temporal Convolutional Network (TCN) framework that incorporates a residual mechanism is constructed to learn the hidden arrival patterns of the vessels. Extensive tests on two real-world data sets from Singapore have been conducted and the following promising results have been obtained: 1) fusion of pilotage booking information and meteorological data improves the prediction accuracy, with pilotage booking information having a more significant impact; 2) using discrete embedding for the meteorological data performs better than using continuous embedding; 3) the TCN outperforms the state-of-the-art baseline methods in regression tasks, exhibiting Mean Absolute Error (MAE) ranging from 4.58 min to 4.86 min; and 4) approximately 89.41% to 90.61% of the absolute prediction residuals fall within a time frame of 10 min.