 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BotTriNet: A Unified and Efficient Embedding for Social Bots Detection via Metric Learning
Apr 18, 2023
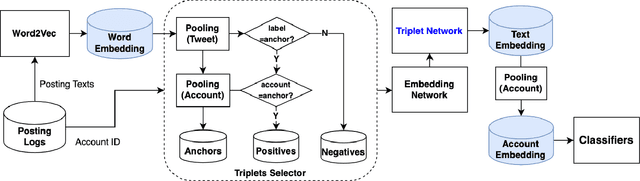
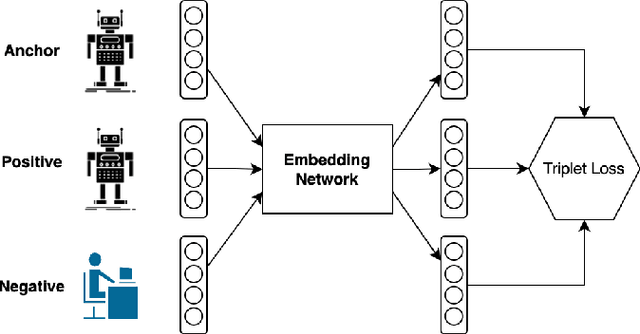

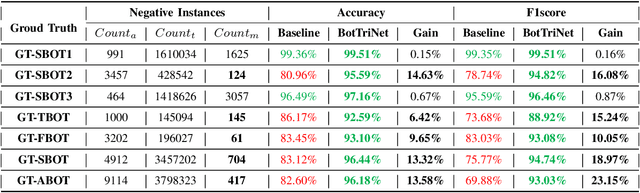
A persistently popular topic in online social networks is the rapid and accurate discovery of bot accounts to prevent their invasion and harassment of genuine users. We propose a unified embedding framework called BotTriNet, which utilizes textual content posted by accounts for bot detection based on the assumption that contexts naturally reveal account personalities and habits. Content is abundant and valuable if the system efficiently extracts bot-related information using embedding techniques. Beyond the general embedding framework that generates word, sentence, and account embeddings, we design a triplet network to tune the raw embeddings (produced by traditional natural language processing techniques) for better classification performance. We evaluate detection accuracy and f1score on a real-world dataset CRESCI2017, comprising three bot account categories and five bot sample sets. Our system achieves the highest average accuracy of 98.34% and f1score of 97.99% on two content-intensive bot sets, outperforming previous work and becoming state-of-the-art. It also makes a breakthrough on four content-less bot sets, with an average accuracy improvement of 11.52% and an average f1score increase of 16.70%.
SViTT: Temporal Learning of Sparse Video-Text Transformers
Apr 18, 2023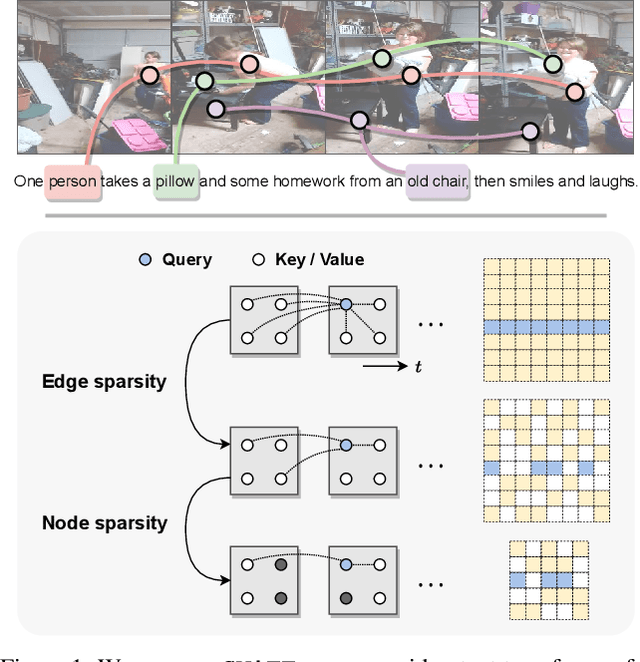
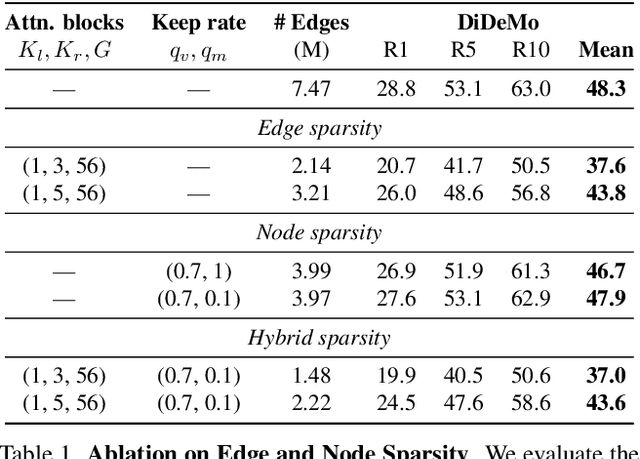
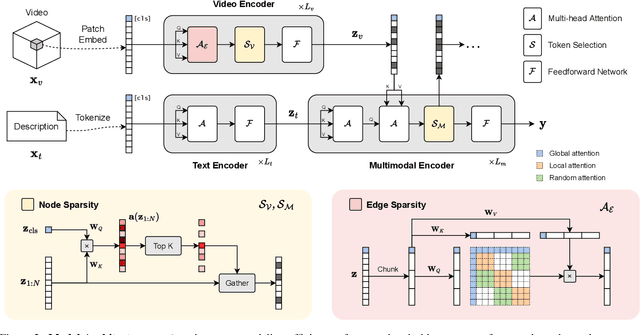
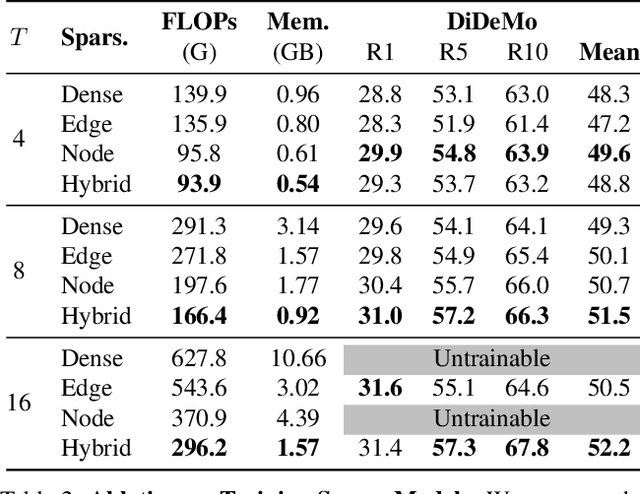
Do video-text transformers learn to model temporal relationships across frames? Despite their immense capacity and the abundance of multimodal training data, recent work has revealed the strong tendency of video-text models towards frame-based spatial representations, while temporal reasoning remains largely unsolved. In this work, we identify several key challenges in temporal learning of video-text transformers: the spatiotemporal trade-off from limited network size; the curse of dimensionality for multi-frame modeling; and the diminishing returns of semantic information by extending clip length. Guided by these findings, we propose SViTT, a sparse video-text architecture that performs multi-frame reasoning with significantly lower cost than naive transformers with dense attention. Analogous to graph-based networks, SViTT employs two forms of sparsity: edge sparsity that limits the query-key communications between tokens in self-attention, and node sparsity that discards uninformative visual tokens. Trained with a curriculum which increases model sparsity with the clip length, SViTT outperforms dense transformer baselines on multiple video-text retrieval and question answering benchmarks, with a fraction of computational cost. Project page: http://svcl.ucsd.edu/projects/svitt.
Learning Sim-to-Real Dense Object Descriptors for Robotic Manipulation
Apr 18, 2023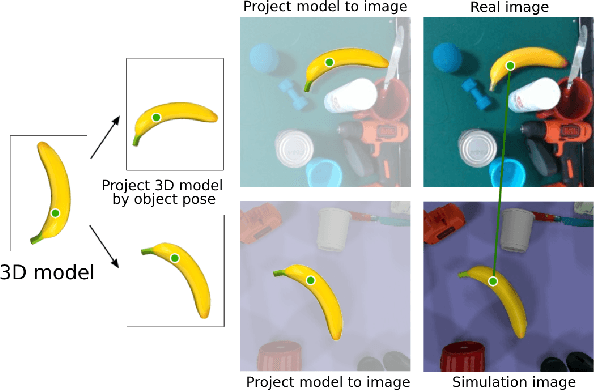
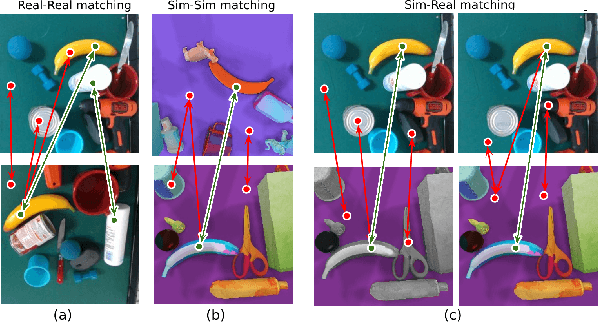
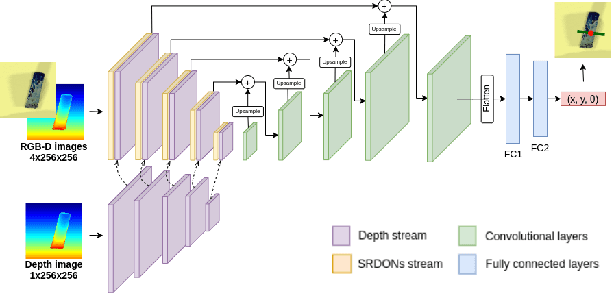

It is crucial to address the following issues for ubiquitous robotics manipulation applications: (a) vision-based manipulation tasks require the robot to visually learn and understand the object with rich information like dense object descriptors; and (b) sim-to-real transfer in robotics aims to close the gap between simulated and real data. In this paper, we present Sim-to-Real Dense Object Nets (SRDONs), a dense object descriptor that not only understands the object via appropriate representation but also maps simulated and real data to a unified feature space with pixel consistency. We proposed an object-to-object matching method for image pairs from different scenes and different domains. This method helps reduce the effort of training data from real-world by taking advantage of public datasets, such as GraspNet. With sim-to-real object representation consistency, our SRDONs can serve as a building block for a variety of sim-to-real manipulation tasks. We demonstrate in experiments that pre-trained SRDONs significantly improve performances on unseen objects and unseen visual environments for various robotic tasks with zero real-world training.
Learning to Transmit with Provable Guarantees in Wireless Federated Learning
Apr 18, 2023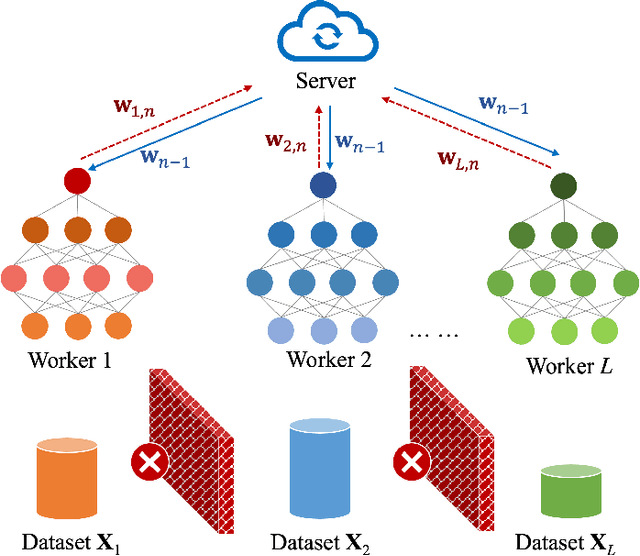
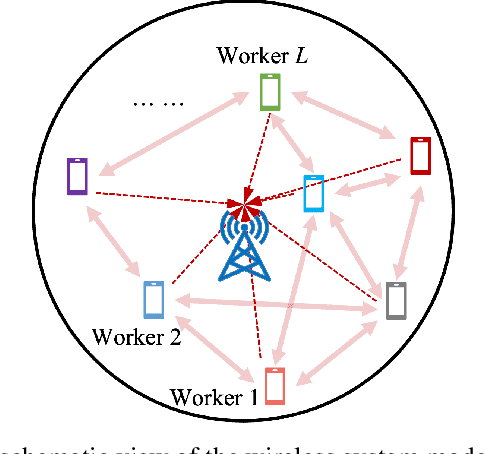
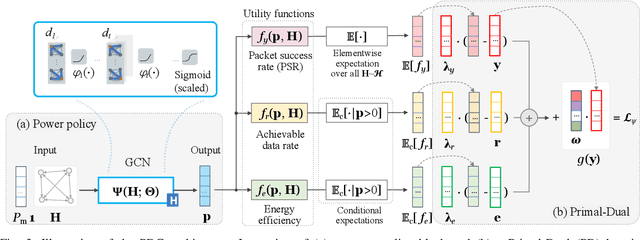
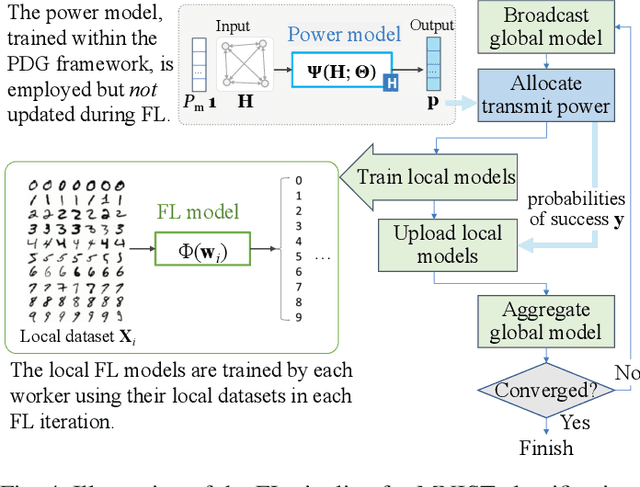
We propose a novel data-driven approach to allocate transmit power for federated learning (FL) over interference-limited wireless networks. The proposed method is useful in challenging scenarios where the wireless channel is changing during the FL training process and when the training data are not independent and identically distributed (non-i.i.d.) on the local devices. Intuitively, the power policy is designed to optimize the information received at the server end during the FL process under communication constraints. Ultimately, our goal is to improve the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual (PD) algorithm. Theoretically, we show that the formulated problem has zero duality gap and, once the power policy is parameterized, optimality depends on how expressive this parameterization is. Numerically, we demonstrate that the proposed method outperforms existing baselines under different wireless channel settings and varying degrees of data heterogeneity.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023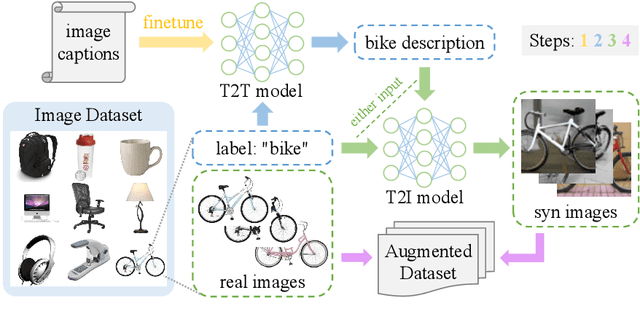
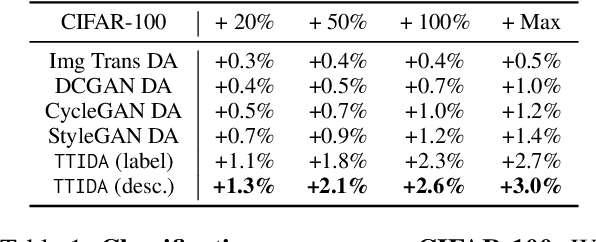
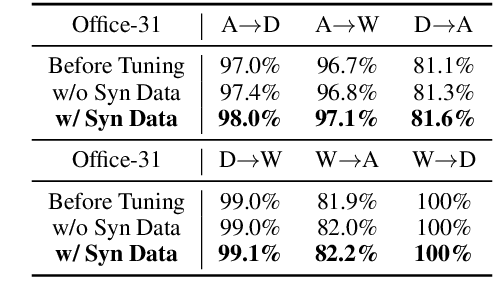
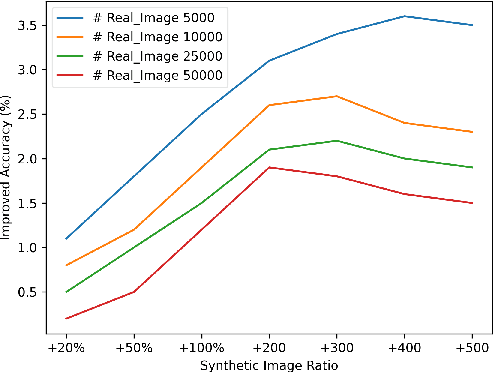
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
Learning Energy-Based Representations of Quantum Many-Body States
Apr 08, 2023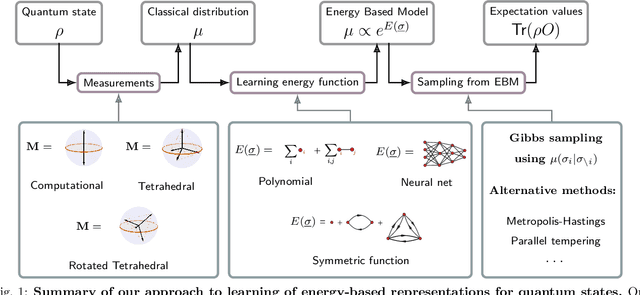
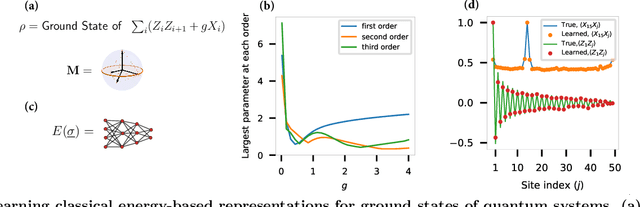
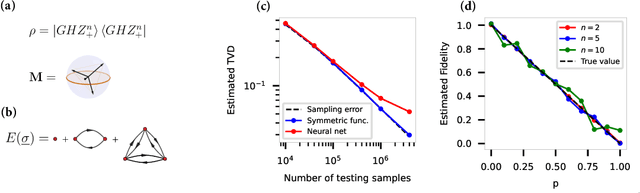
Efficient representation of quantum many-body states on classical computers is a problem of enormous practical interest. An ideal representation of a quantum state combines a succinct characterization informed by the system's structure and symmetries, along with the ability to predict the physical observables of interest. A number of machine learning approaches have been recently used to construct such classical representations [1-6] which enable predictions of observables [7] and account for physical symmetries [8]. However, the structure of a quantum state gets typically lost unless a specialized ansatz is employed based on prior knowledge of the system [9-12]. Moreover, most such approaches give no information about what states are easier to learn in comparison to others. Here, we propose a new generative energy-based representation of quantum many-body states derived from Gibbs distributions used for modeling the thermal states of classical spin systems. Based on the prior information on a family of quantum states, the energy function can be specified by a small number of parameters using an explicit low-degree polynomial or a generic parametric family such as neural nets, and can naturally include the known symmetries of the system. Our results show that such a representation can be efficiently learned from data using exact algorithms in a form that enables the prediction of expectation values of physical observables. Importantly, the structure of the learned energy function provides a natural explanation for the hardness of learning for a given class of quantum states.
Active View Planning for Visual SLAM in Outdoor Environments Based on Continuous Information Modeling
Nov 12, 2022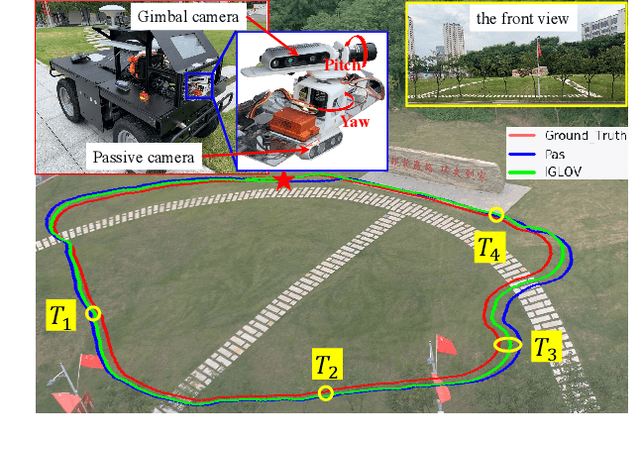
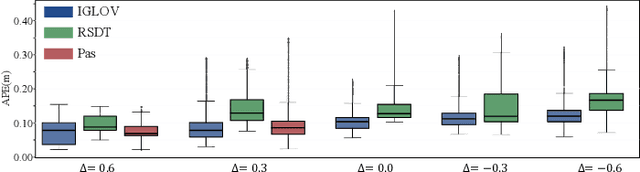
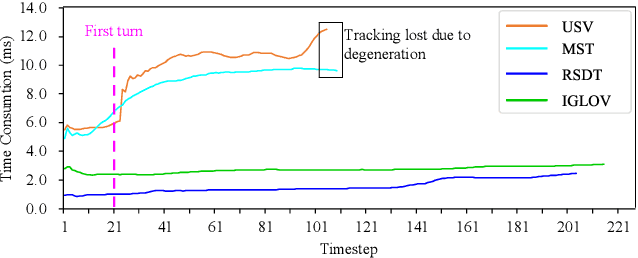
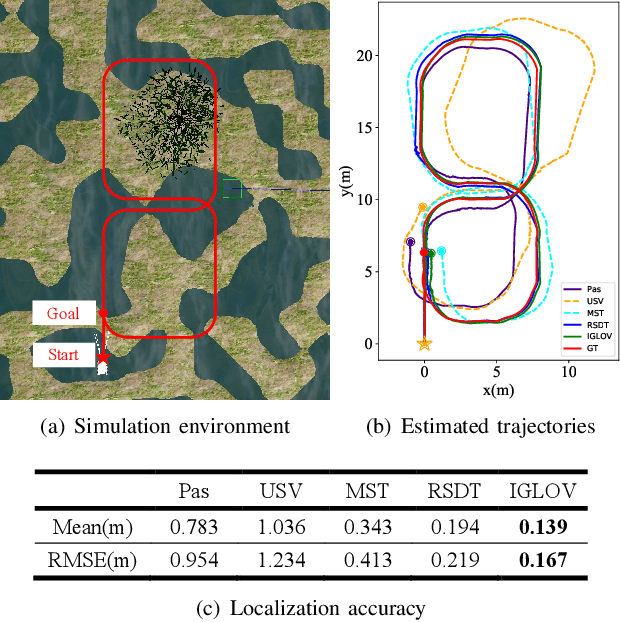
The visual simultaneous localization and mapping(vSLAM) is widely used in GPS-denied and open field environments for ground and surface robots. However, due to the frequent perception failures derived from lacking visual texture or the {swing} of robot view direction on rough terrains, the accuracy and robustness of vSLAM are still to be enhanced. The study develops a novel view planning approach of actively perceiving areas with maximal information to address the mentioned problem; a gimbal camera is used as the main sensor. Firstly, a map representation based on feature distribution-weighted Fisher information is proposed to completely and effectively represent environmental information richness. With the map representation, a continuous environmental information model is further established to convert the discrete information space into a continuous one for numerical optimization in real-time. Subsequently, the receding horizon optimization is utilized to obtain the optimal informative viewpoints with simultaneously considering the robotic perception, exploration and motion cost based on the continuous environmental model. Finally, several simulations and outdoor experiments are performed to verify the improvement of localization robustness and accuracy by the proposed approach.
Quantifying and Learning Static vs. Dynamic Information in Deep Spatiotemporal Networks
Nov 03, 2022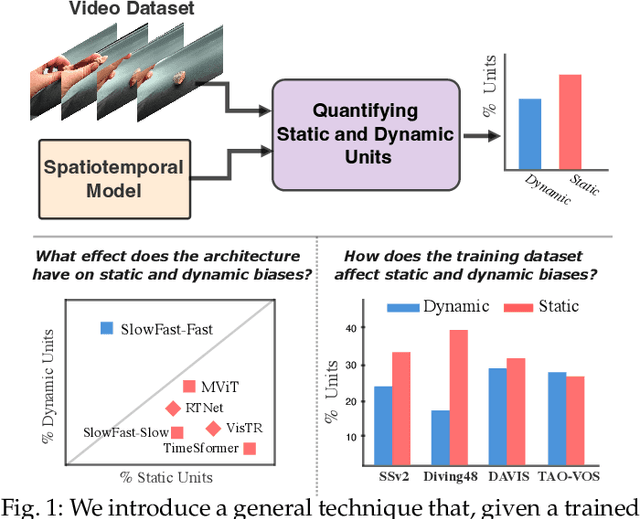
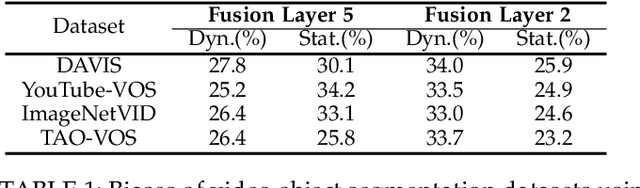
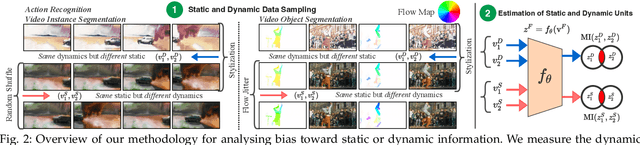
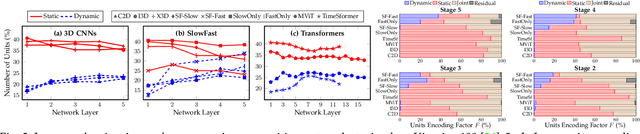
There is limited understanding of the information captured by deep spatiotemporal models in their intermediate representations. For example, while evidence suggests that action recognition algorithms are heavily influenced by visual appearance in single frames, no quantitative methodology exists for evaluating such static bias in the latent representation compared to bias toward dynamics. We tackle this challenge by proposing an approach for quantifying the static and dynamic biases of any spatiotemporal model, and apply our approach to three tasks, action recognition, automatic video object segmentation (AVOS) and video instance segmentation (VIS). Our key findings are: (i) Most examined models are biased toward static information. (ii) Some datasets that are assumed to be biased toward dynamics are actually biased toward static information. (iii) Individual channels in an architecture can be biased toward static, dynamic or a combination of the two. (iv) Most models converge to their culminating biases in the first half of training. We then explore how these biases affect performance on dynamically biased datasets. For action recognition, we propose StaticDropout, a semantically guided dropout that debiases a model from static information toward dynamics. For AVOS, we design a better combination of fusion and cross connection layers compared with previous architectures.
Higher-order mutual information reveals synergistic sub-networks for multi-neuron importance
Nov 01, 2022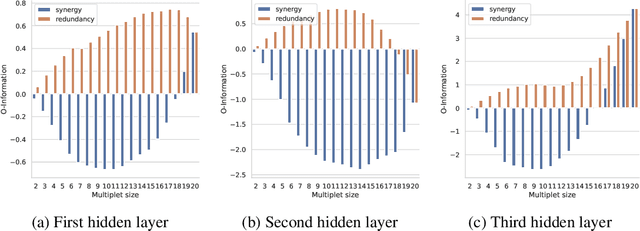
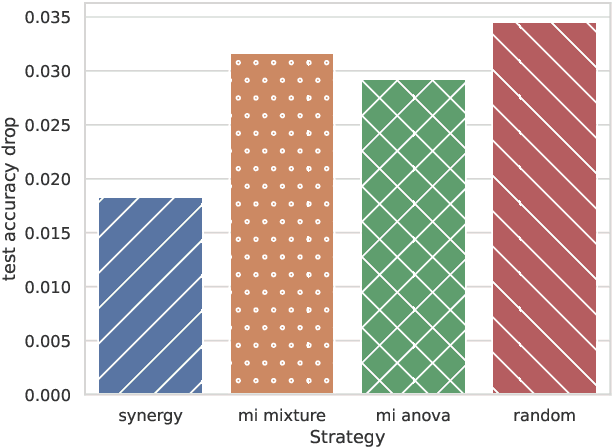
Quantifying which neurons are important with respect to the classification decision of a trained neural network is essential for understanding their inner workings. Previous work primarily attributed importance to individual neurons. In this work, we study which groups of neurons contain synergistic or redundant information using a multivariate mutual information method called the O-information. We observe the first layer is dominated by redundancy suggesting general shared features (i.e. detecting edges) while the last layer is dominated by synergy indicating local class-specific features (i.e. concepts). Finally, we show the O-information can be used for multi-neuron importance. This can be demonstrated by re-training a synergistic sub-network, which results in a minimal change in performance. These results suggest our method can be used for pruning and unsupervised representation learning.
Dehazing-NeRF: Neural Radiance Fields from Hazy Images
Apr 22, 2023

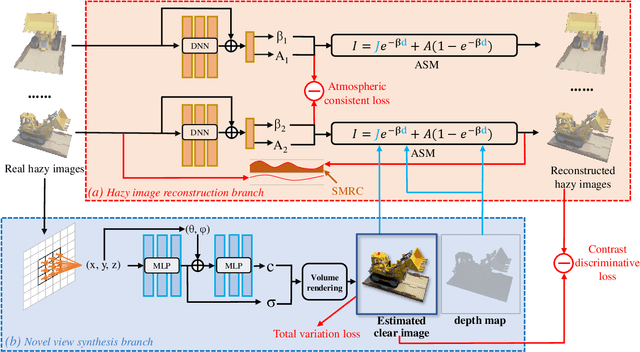

Neural Radiance Field (NeRF) has received much attention in recent years due to the impressively high quality in 3D scene reconstruction and novel view synthesis. However, image degradation caused by the scattering of atmospheric light and object light by particles in the atmosphere can significantly decrease the reconstruction quality when shooting scenes in hazy conditions. To address this issue, we propose Dehazing-NeRF, a method that can recover clear NeRF from hazy image inputs. Our method simulates the physical imaging process of hazy images using an atmospheric scattering model, and jointly learns the atmospheric scattering model and a clean NeRF model for both image dehazing and novel view synthesis. Different from previous approaches, Dehazing-NeRF is an unsupervised method with only hazy images as the input, and also does not rely on hand-designed dehazing priors. By jointly combining the depth estimated from the NeRF 3D scene with the atmospheric scattering model, our proposed model breaks through the ill-posed problem of single-image dehazing while maintaining geometric consistency. Besides, to alleviate the degradation of image quality caused by information loss, soft margin consistency regularization, as well as atmospheric consistency and contrast discriminative loss, are addressed during the model training process. Extensive experiments demonstrate that our method outperforms the simple combination of single-image dehazing and NeRF on both image dehazing and novel view image synthesis.