 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-guided pixel augmentation for pixel-wise contrastive learning
Nov 14, 2022
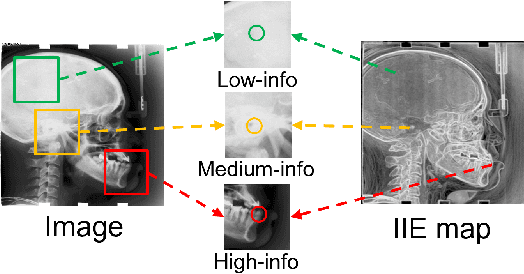
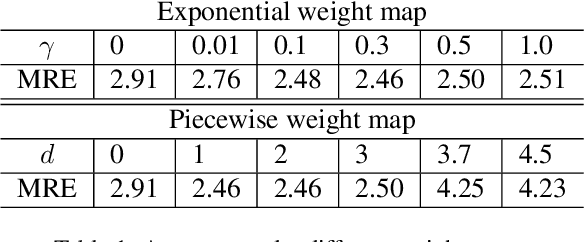
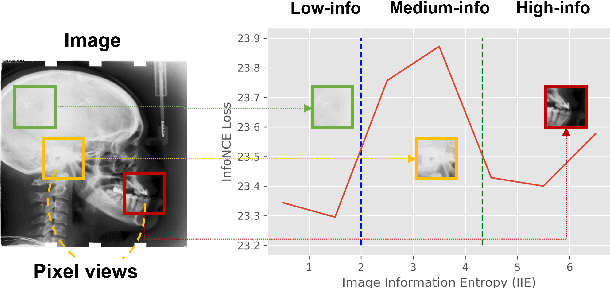

Contrastive learning (CL) is a form of self-supervised learning and has been widely used for various tasks. Different from widely studied instance-level contrastive learning, pixel-wise contrastive learning mainly helps with pixel-wise tasks such as medical landmark detection. The counterpart to an instance in instance-level CL is a pixel, along with its neighboring context, in pixel-wise CL. Aiming to build better feature representation, there is a vast literature about designing instance augmentation strategies for instance-level CL; but there is little similar work on pixel augmentation for pixel-wise CL with a pixel granularity. In this paper, we attempt to bridge this gap. We first classify a pixel into three categories, namely low-, medium-, and high-informative, based on the information quantity the pixel contains. Inspired by the ``InfoMin" principle, we then design separate augmentation strategies for each category in terms of augmentation intensity and sampling ratio. Extensive experiments validate that our information-guided pixel augmentation strategy succeeds in encoding more discriminative representations and surpassing other competitive approaches in unsupervised local feature matching. Furthermore, our pretrained model improves the performance of both one-shot and fully supervised models. To the best of our knowledge, we are the first to propose a pixel augmentation method with a pixel granularity for enhancing unsupervised pixel-wise contrastive learning.
Multi-stage Information Retrieval for Vietnamese Legal Texts
Sep 29, 2022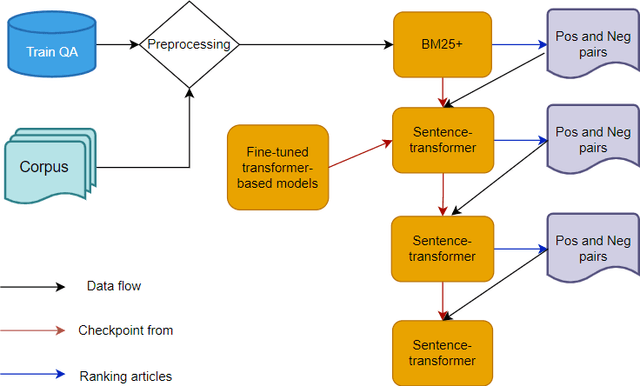

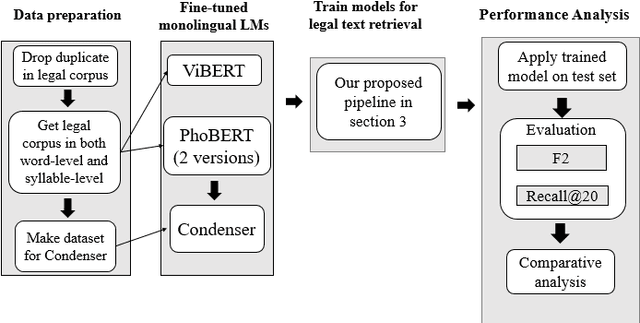
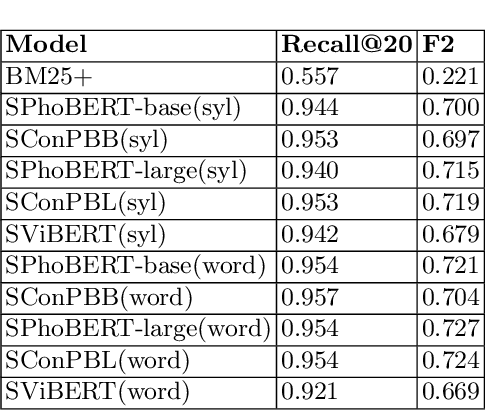
This study deals with the problem of information retrieval (IR) for Vietnamese legal texts. Despite being well researched in many languages, information retrieval has still not received much attention from the Vietnamese research community. This is especially true for the case of legal documents, which are hard to process. This study proposes a new approach for information retrieval for Vietnamese legal documents using sentence-transformer. Besides, various experiments are conducted to make comparisons between different transformer models, ranking scores, syllable-level, and word-level training. The experiment results show that the proposed model outperforms models used in current research on information retrieval for Vietnamese documents.
Modeling Fine-grained Information via Knowledge-aware Hierarchical Graph for Zero-shot Entity Retrieval
Nov 20, 2022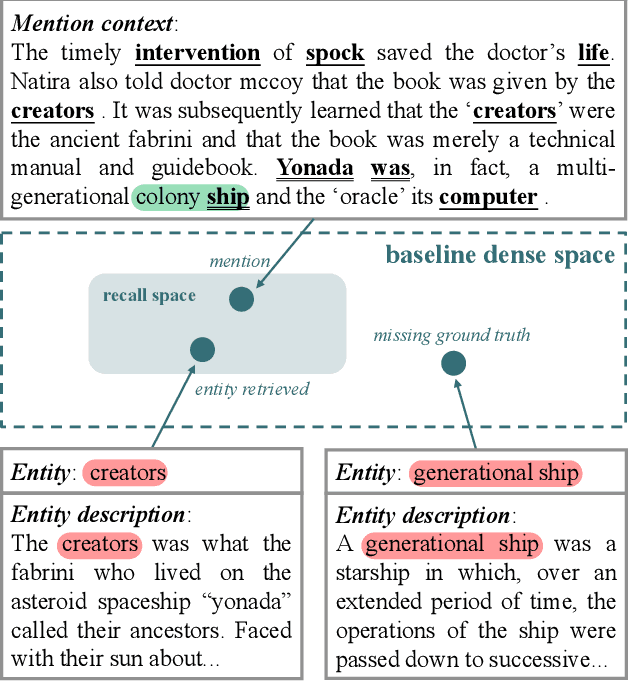
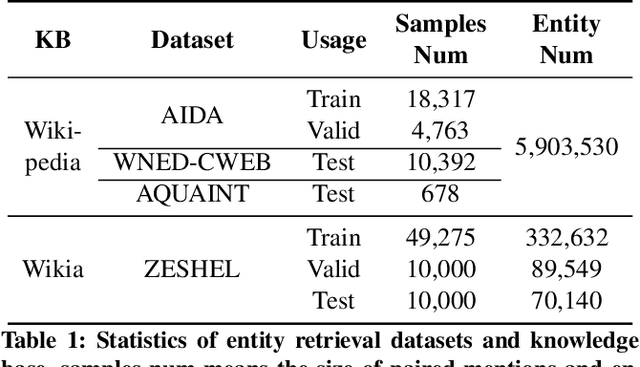
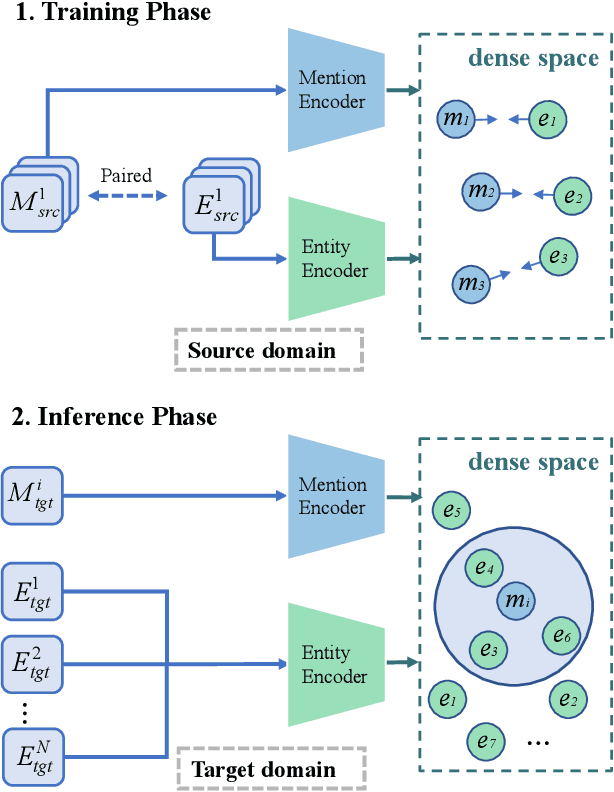
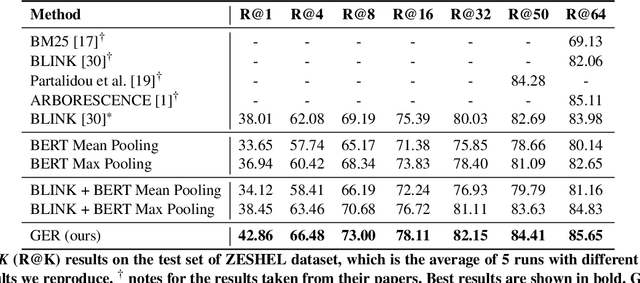
Zero-shot entity retrieval, aiming to link mentions to candidate entities under the zero-shot setting, is vital for many tasks in Natural Language Processing. Most existing methods represent mentions/entities via the sentence embeddings of corresponding context from the Pre-trained Language Model. However, we argue that such coarse-grained sentence embeddings can not fully model the mentions/entities, especially when the attention scores towards mentions/entities are relatively low. In this work, we propose GER, a \textbf{G}raph enhanced \textbf{E}ntity \textbf{R}etrieval framework, to capture more fine-grained information as complementary to sentence embeddings. We extract the knowledge units from the corresponding context and then construct a mention/entity centralized graph. Hence, we can learn the fine-grained information about mention/entity by aggregating information from these knowledge units. To avoid the graph information bottleneck for the central mention/entity node, we construct a hierarchical graph and design a novel Hierarchical Graph Attention Network~(HGAN). Experimental results on popular benchmarks demonstrate that our proposed GER framework performs better than previous state-of-the-art models. The code has been available at https://github.com/wutaiqiang/GER-WSDM2023.
* 9 pages, 5 figures
Hebbian fast plasticity and working memory
Apr 13, 2023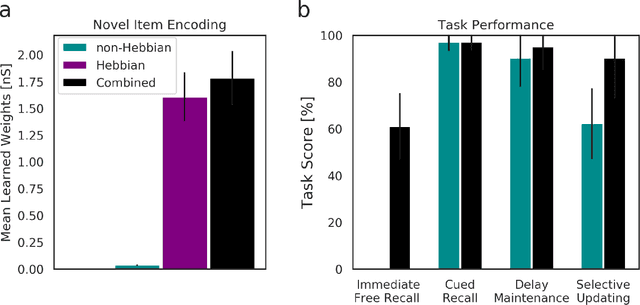
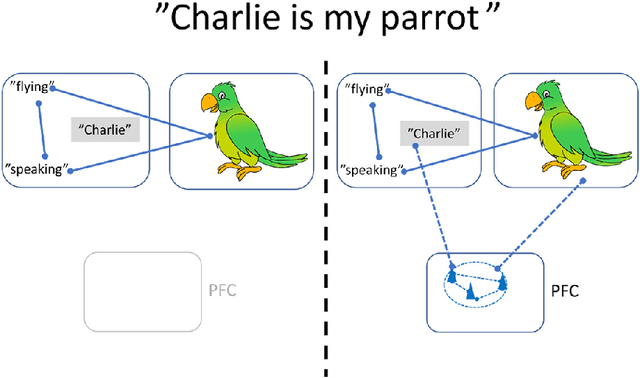
Theories and models of working memory (WM) were at least since the mid-1990s dominated by the persistent activity hypothesis. The past decade has seen rising concerns about the shortcomings of sustained activity as the mechanism for short-term maintenance of WM information in the light of accumulating experimental evidence for so-called activity-silent WM and the fundamental difficulty in explaining robust multi-item WM. In consequence, alternative theories are now explored mostly in the direction of fast synaptic plasticity as the underlying mechanism.The question of non-Hebbian vs Hebbian synaptic plasticity emerges naturally in this context. In this review we focus on fast Hebbian plasticity and trace the origins of WM theories and models building on this form of associative learning.
HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose Estimation
Mar 28, 2023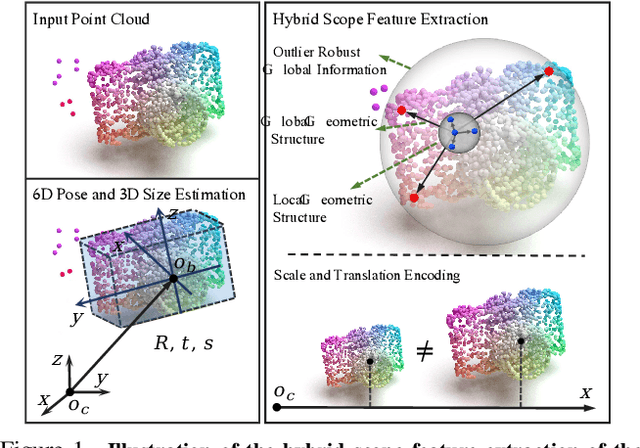
In this paper, we focus on the problem of category-level object pose estimation, which is challenging due to the large intra-category shape variation. 3D graph convolution (3D-GC) based methods have been widely used to extract local geometric features, but they have limitations for complex shaped objects and are sensitive to noise. Moreover, the scale and translation invariant properties of 3D-GC restrict the perception of an object's size and translation information. In this paper, we propose a simple network structure, the HS-layer, which extends 3D-GC to extract hybrid scope latent features from point cloud data for category-level object pose estimation tasks. The proposed HS-layer: 1) is able to perceive local-global geometric structure and global information, 2) is robust to noise, and 3) can encode size and translation information. Our experiments show that the simple replacement of the 3D-GC layer with the proposed HS-layer on the baseline method (GPV-Pose) achieves a significant improvement, with the performance increased by 14.5% on 5d2cm metric and 10.3% on IoU75. Our method outperforms the state-of-the-art methods by a large margin (8.3% on 5d2cm, 6.9% on IoU75) on the REAL275 dataset and runs in real-time (50 FPS).
Multi-frame-based Cross-domain Image Denoising for Low-dose Computed Tomography
Apr 21, 2023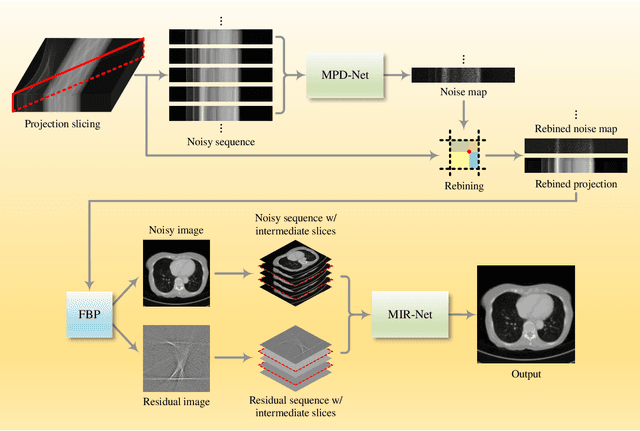
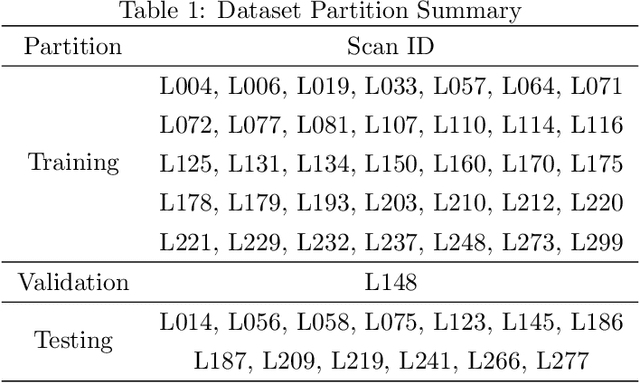
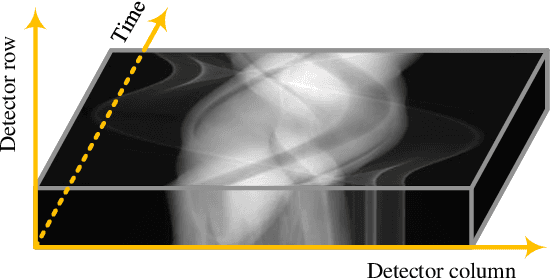
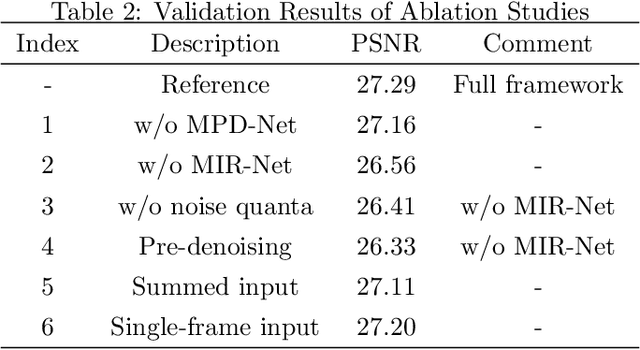
Computed tomography (CT) has been used worldwide for decades as one of the most important non-invasive tests in assisting diagnosis. However, the ionizing nature of X-ray exposure raises concerns about potential health risks such as cancer. The desire for lower radiation dose has driven researchers to improve the reconstruction quality, especially by removing noise and artifacts. Although previous studies on low-dose computed tomography (LDCT) denoising have demonstrated the effectiveness of learning-based methods, most of them were developed on the simulated data collected using Radon transform. However, the real-world scenario significantly differs from the simulation domain, and the joint optimization of denoising with modern CT image reconstruction pipeline is still missing. In this paper, for the commercially available third-generation multi-slice spiral CT scanners, we propose a two-stage method that better exploits the complete reconstruction pipeline for LDCT denoising across different domains. Our method makes good use of the high redundancy of both the multi-slice projections and the volumetric reconstructions while avoiding the collapse of information in conventional cascaded frameworks. The dedicated design also provides a clearer interpretation of the workflow. Through extensive evaluations, we demonstrate its superior performance against state-of-the-art methods.
Deep Learning-empowered Predictive Precoder Design for OTFS Transmission in URLLC
Apr 21, 2023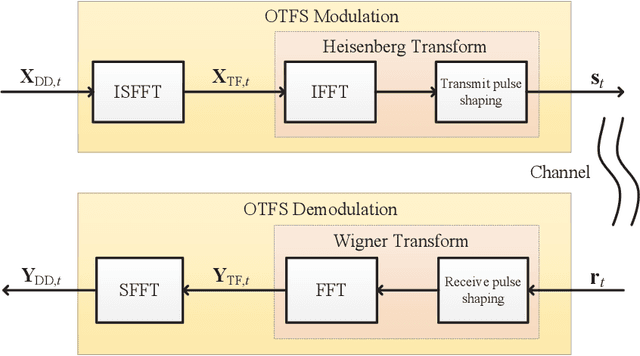
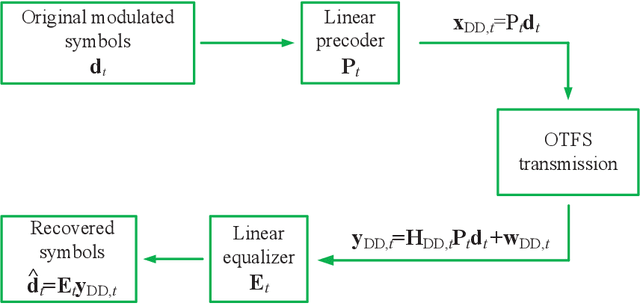
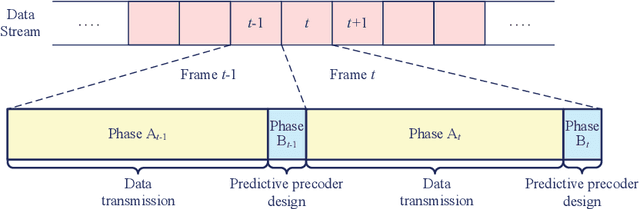
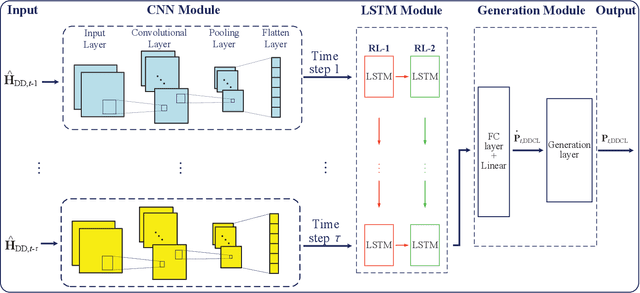
To guarantee excellent reliability performance in ultra-reliable low-latency communications (URLLC), pragmatic precoder design is an effective approach. However, an efficient precoder design highly depends on the accurate instantaneous channel state information at the transmitter (ICSIT), which however, is not always available in practice. To overcome this problem, in this paper, we focus on the orthogonal time frequency space (OTFS)-based URLLC system and adopt a deep learning (DL) approach to directly predict the precoder for the next time frame to minimize the frame error rate (FER) via implicitly exploiting the features from estimated historical channels in the delay-Doppler domain. By doing this, we can guarantee the system reliability even without the knowledge of ICSIT. To this end, a general precoder design problem is formulated where a closed-form theoretical FER expression is specifically derived to characterize the system reliability. Then, a delay-Doppler domain channels-aware convolutional long short-term memory (CLSTM) network (DDCL-Net) is proposed for predictive precoder design. In particular, both the convolutional neural network and LSTM modules are adopted in the proposed neural network to exploit the spatial-temporal features of wireless channels for improving the learning performance. Finally, simulation results demonstrated that the FER performance of the proposed method approaches that of the perfect ICSI-aided scheme.
Large language models can rate news outlet credibility
Apr 01, 2023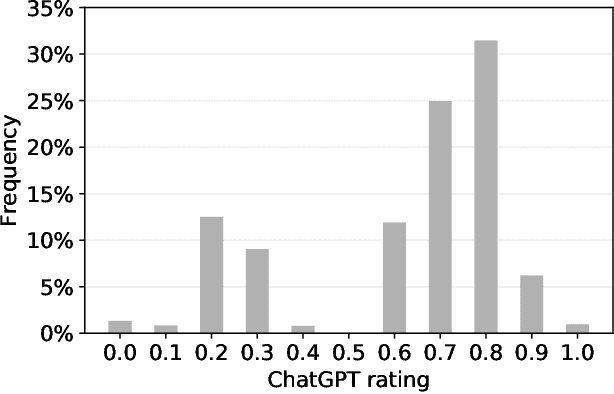
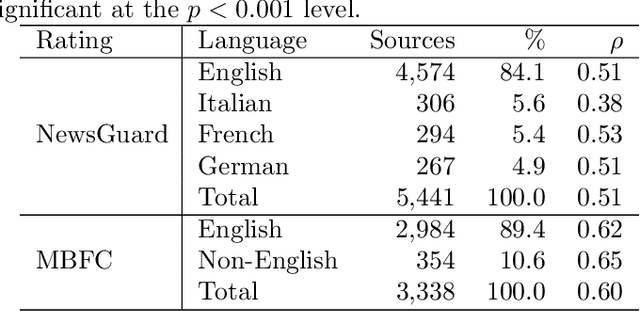
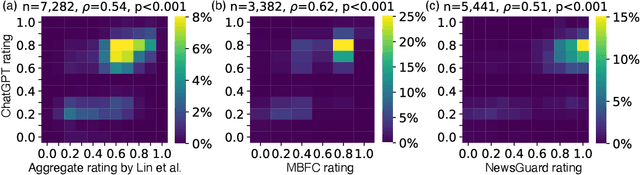
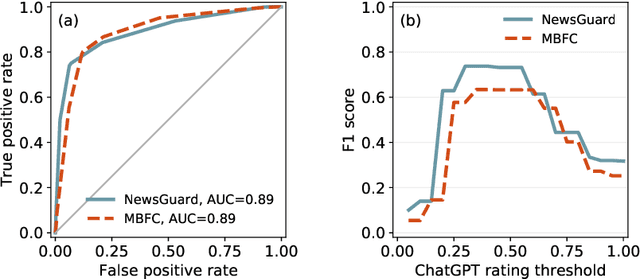
Although large language models (LLMs) have shown exceptional performance in various natural language processing tasks, they are prone to hallucinations. State-of-the-art chatbots, such as the new Bing, attempt to mitigate this issue by gathering information directly from the internet to ground their answers. In this setting, the capacity to distinguish trustworthy sources is critical for providing appropriate accuracy contexts to users. Here we assess whether ChatGPT, a prominent LLM, can evaluate the credibility of news outlets. With appropriate instructions, ChatGPT can provide ratings for a diverse set of news outlets, including those in non-English languages and satirical sources, along with contextual explanations. Our results show that these ratings correlate with those from human experts (Spearmam's $\rho=0.54, p<0.001$). These findings suggest that LLMs could be an affordable reference for credibility ratings in fact-checking applications. Future LLMs should enhance their alignment with human expert judgments of source credibility to improve information accuracy.
Multi-Channel Time-Series Person and Soft-Biometric Identification
Apr 04, 2023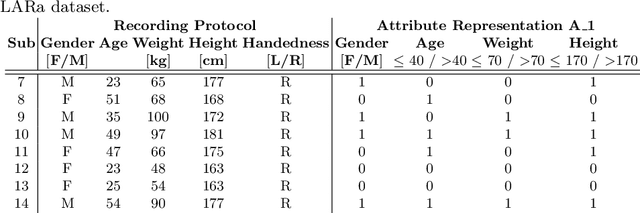
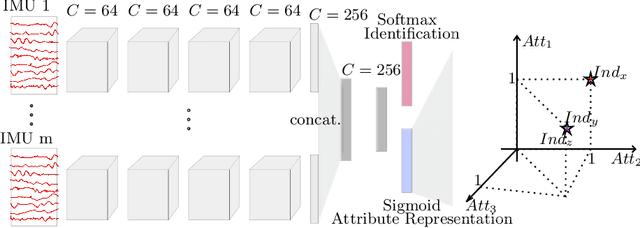
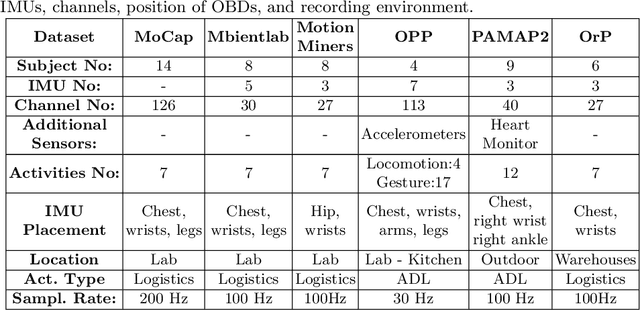
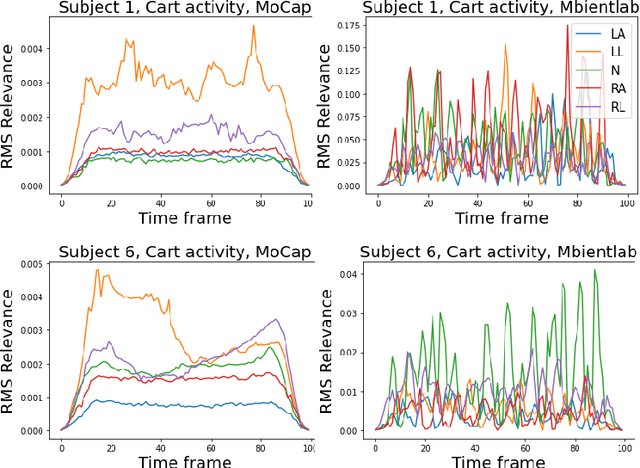
Multi-channel time-series datasets are popular in the context of human activity recognition (HAR). On-body device (OBD) recordings of human movements are often preferred for HAR applications not only for their reliability but as an approach for identity protection, e.g., in industrial settings. Contradictory, the gait activity is a biometric, as the cyclic movement is distinctive and collectable. In addition, the gait cycle has proven to contain soft-biometric information of human groups, such as age and height. Though general human movements have not been considered a biometric, they might contain identity information. This work investigates person and soft-biometrics identification from OBD recordings of humans performing different activities using deep architectures. Furthermore, we propose the use of attribute representation for soft-biometric identification. We evaluate the method on four datasets of multi-channel time-series HAR, measuring the performance of a person and soft-biometrics identification and its relation concerning performed activities. We find that person identification is not limited to gait activity. The impact of activities on the identification performance was found to be training and dataset specific. Soft-biometric based attribute representation shows promising results and emphasis the necessity of larger datasets.
In ChatGPT We Trust? Measuring and Characterizing the Reliability of ChatGPT
Apr 18, 2023
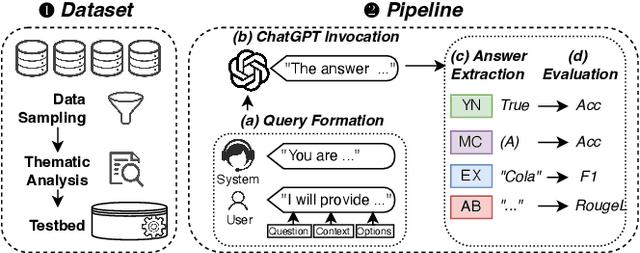

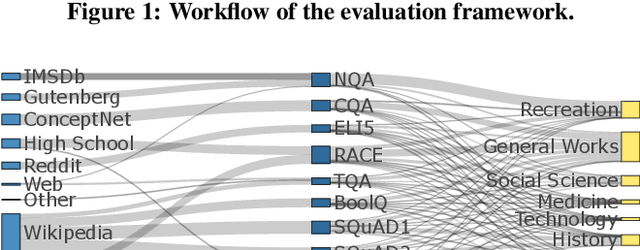
The way users acquire information is undergoing a paradigm shift with the advent of ChatGPT. Unlike conventional search engines, ChatGPT retrieves knowledge from the model itself and generates answers for users. ChatGPT's impressive question-answering (QA) capability has attracted more than 100 million users within a short period of time but has also raised concerns regarding its reliability. In this paper, we perform the first large-scale measurement of ChatGPT's reliability in the generic QA scenario with a carefully curated set of 5,695 questions across ten datasets and eight domains. We find that ChatGPT's reliability varies across different domains, especially underperforming in law and science questions. We also demonstrate that system roles, originally designed by OpenAI to allow users to steer ChatGPT's behavior, can impact ChatGPT's reliability. We further show that ChatGPT is vulnerable to adversarial examples, and even a single character change can negatively affect its reliability in certain cases. We believe that our study provides valuable insights into ChatGPT's reliability and underscores the need for strengthening the reliability and security of large language models (LLMs).