 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Delving into E-Commerce Product Retrieval with Vision-Language Pre-training
Apr 17, 2023
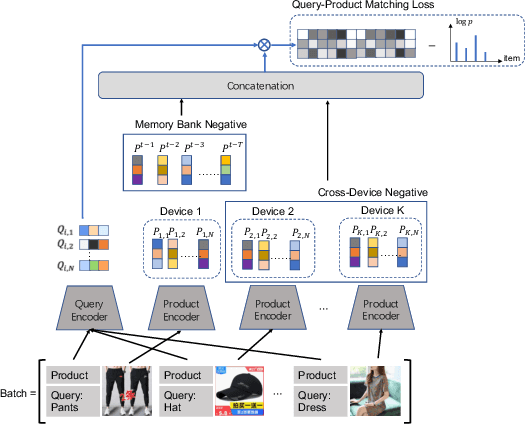
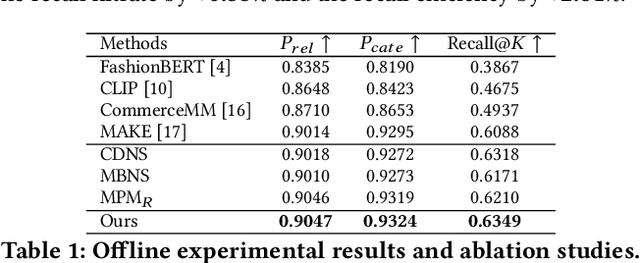
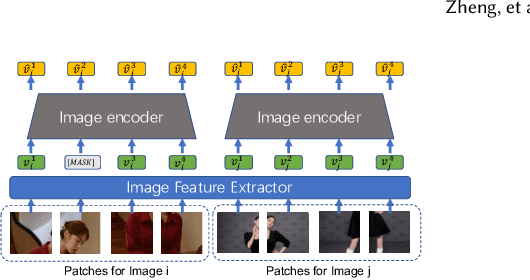

E-commerce search engines comprise a retrieval phase and a ranking phase, where the first one returns a candidate product set given user queries. Recently, vision-language pre-training, combining textual information with visual clues, has been popular in the application of retrieval tasks. In this paper, we propose a novel V+L pre-training method to solve the retrieval problem in Taobao Search. We design a visual pre-training task based on contrastive learning, outperforming common regression-based visual pre-training tasks. In addition, we adopt two negative sampling schemes, tailored for the large-scale retrieval task. Besides, we introduce the details of the online deployment of our proposed method in real-world situations. Extensive offline/online experiments demonstrate the superior performance of our method on the retrieval task. Our proposed method is employed as one retrieval channel of Taobao Search and serves hundreds of millions of users in real time.
Leveraging sparse and shared feature activations for disentangled representation learning
Apr 17, 2023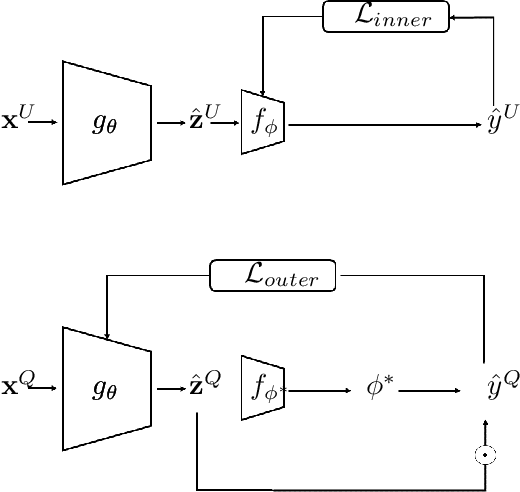
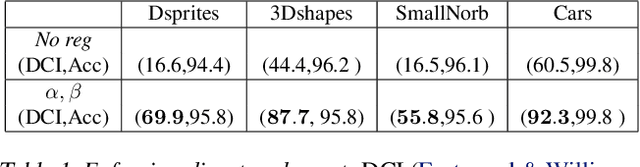
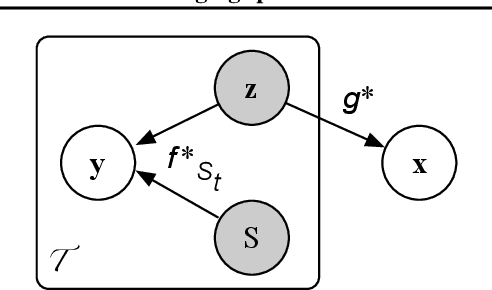
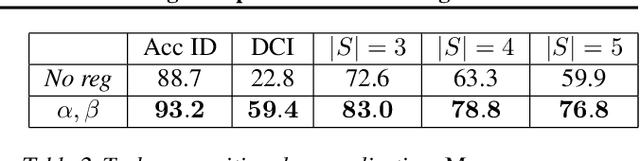
Recovering the latent factors of variation of high dimensional data has so far focused on simple synthetic settings. Mostly building on unsupervised and weakly-supervised objectives, prior work missed out on the positive implications for representation learning on real world data. In this work, we propose to leverage knowledge extracted from a diversified set of supervised tasks to learn a common disentangled representation. Assuming each supervised task only depends on an unknown subset of the factors of variation, we disentangle the feature space of a supervised multi-task model, with features activating sparsely across different tasks and information being shared as appropriate. Importantly, we never directly observe the factors of variations but establish that access to multiple tasks is sufficient for identifiability under sufficiency and minimality assumptions. We validate our approach on six real world distribution shift benchmarks, and different data modalities (images, text), demonstrating how disentangled representations can be transferred to real settings.
PerCoNet: News Recommendation with Explicit Persona and Contrastive Learning
Apr 17, 2023
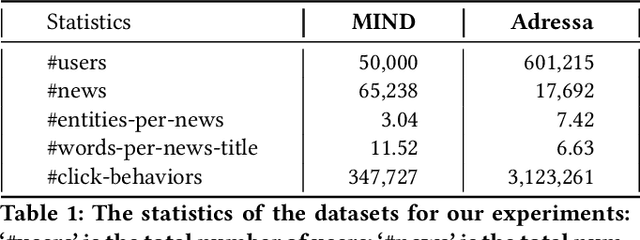
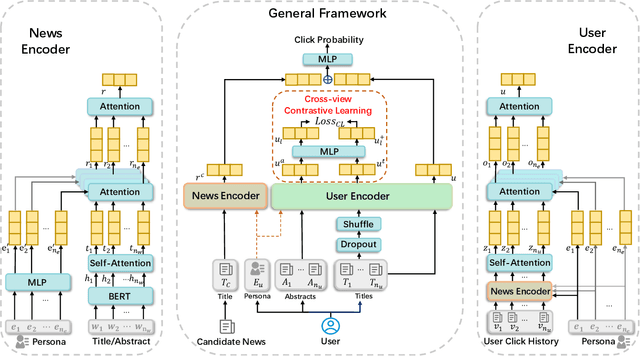
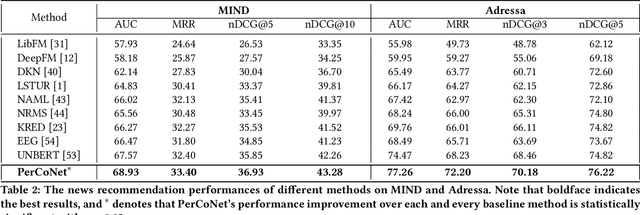
Personalized news recommender systems help users quickly find content of their interests from the sea of information. Today, the mainstream technology for personalized news recommendation is based on deep neural networks that can accurately model the semantic match between news items and users' interests. In this paper, we present \textbf{PerCoNet}, a novel deep learning approach to personalized news recommendation which features two new findings: (i) representing users through \emph{explicit persona analysis} based on the prominent entities in their recent news reading history could be more effective than latent persona analysis employed by most existing work, with a side benefit of enhanced explainability; (ii) utilizing the title and abstract of each news item via cross-view \emph{contrastive learning} would work better than just combining them directly. Extensive experiments on two real-world news datasets clearly show the superior performance of our proposed approach in comparison with current state-of-the-art techniques.
Bayes correlated equilibria and no-regret dynamics
Apr 11, 2023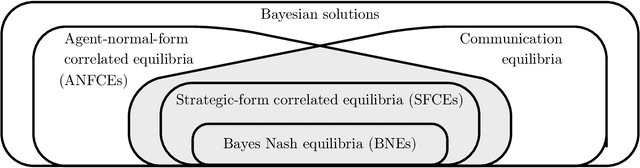

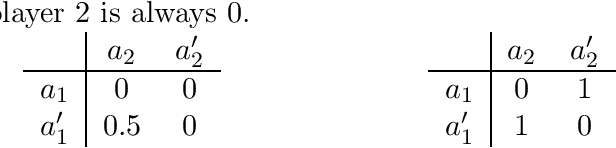
This paper explores equilibrium concepts for Bayesian games, which are fundamental models of games with incomplete information. We aim at three desirable properties of equilibria. First, equilibria can be naturally realized by introducing a mediator into games. Second, an equilibrium can be computed efficiently in a distributed fashion. Third, any equilibrium in that class approximately maximizes social welfare, as measured by the price of anarchy, for a broad class of games. These three properties allow players to compute an equilibrium and realize it via a mediator, thereby settling into a stable state with approximately optimal social welfare. Our main result is the existence of an equilibrium concept that satisfies these three properties. Toward this goal, we characterize various (non-equivalent) extensions of correlated equilibria, collectively known as Bayes correlated equilibria. In particular, we focus on communication equilibria (also known as coordination mechanisms), which can be realized by a mediator who gathers each player's private information and then sends correlated recommendations to the players. We show that if each player minimizes a variant of regret called untruthful swap regret in repeated play of Bayesian games, the empirical distribution of these dynamics converges to a communication equilibrium. We present an efficient algorithm for minimizing untruthful swap regret with a sublinear upper bound, which we prove to be tight up to a multiplicative constant. As a result, by simulating the dynamics with our algorithm, we can efficiently compute an approximate communication equilibrium. Furthermore, we extend existing lower bounds on the price of anarchy based on the smoothness arguments from Bayes Nash equilibria to equilibria obtained by the proposed dynamics.
RecUP-FL: Reconciling Utility and Privacy in Federated Learning via User-configurable Privacy Defense
Apr 11, 2023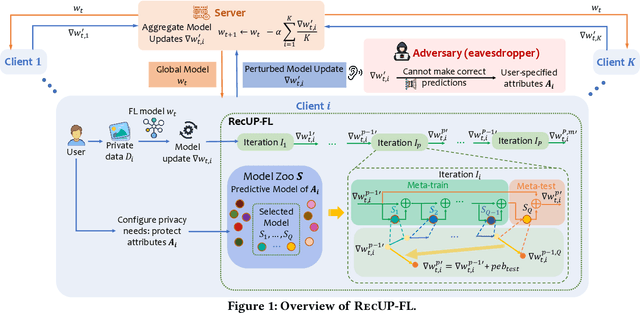
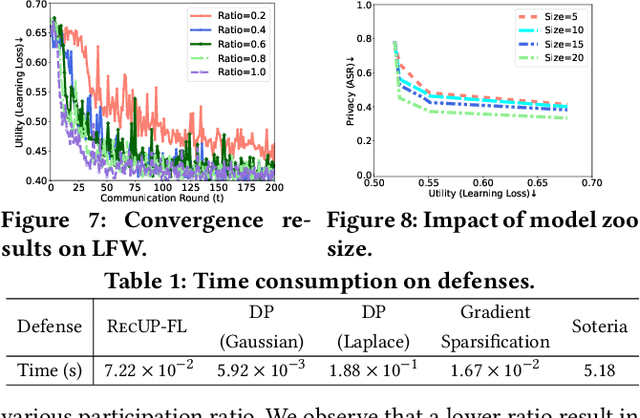
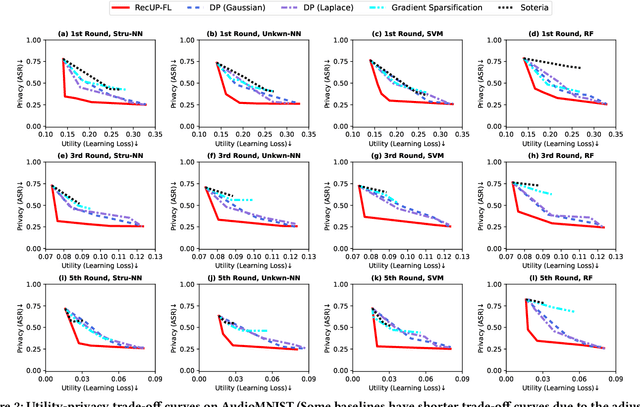
Federated learning (FL) provides a variety of privacy advantages by allowing clients to collaboratively train a model without sharing their private data. However, recent studies have shown that private information can still be leaked through shared gradients. To further minimize the risk of privacy leakage, existing defenses usually require clients to locally modify their gradients (e.g., differential privacy) prior to sharing with the server. While these approaches are effective in certain cases, they regard the entire data as a single entity to protect, which usually comes at a large cost in model utility. In this paper, we seek to reconcile utility and privacy in FL by proposing a user-configurable privacy defense, RecUP-FL, that can better focus on the user-specified sensitive attributes while obtaining significant improvements in utility over traditional defenses. Moreover, we observe that existing inference attacks often rely on a machine learning model to extract the private information (e.g., attributes). We thus formulate such a privacy defense as an adversarial learning problem, where RecUP-FL generates slight perturbations that can be added to the gradients before sharing to fool adversary models. To improve the transferability to un-queryable black-box adversary models, inspired by the idea of meta-learning, RecUP-FL forms a model zoo containing a set of substitute models and iteratively alternates between simulations of the white-box and the black-box adversarial attack scenarios to generate perturbations. Extensive experiments on four datasets under various adversarial settings (both attribute inference attack and data reconstruction attack) show that RecUP-FL can meet user-specified privacy constraints over the sensitive attributes while significantly improving the model utility compared with state-of-the-art privacy defenses.
VPFusion: Towards Robust Vertical Representation Learning for 3D Object Detection
Apr 06, 2023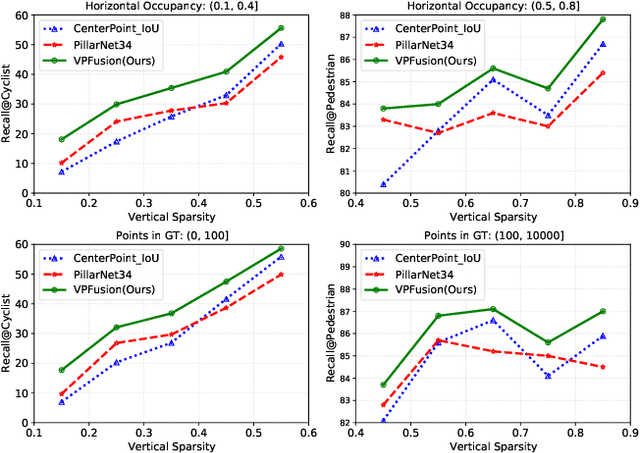
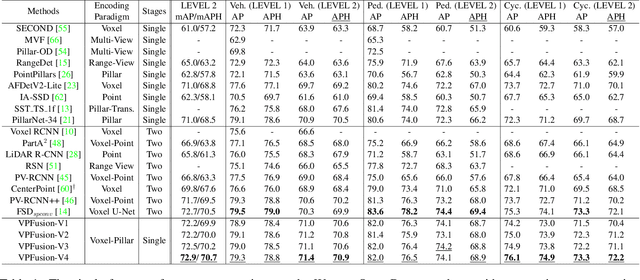
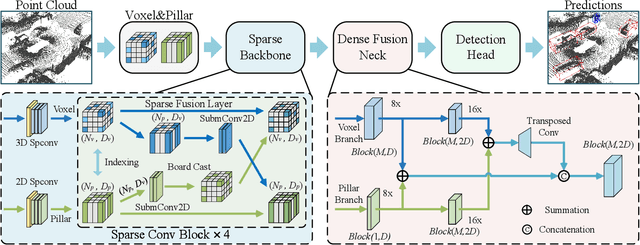
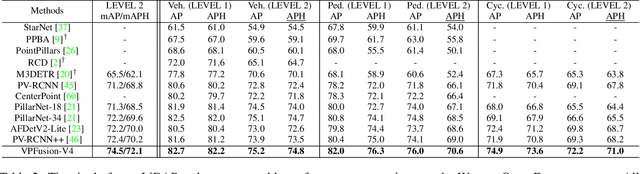
Efficient point cloud representation is a fundamental element of Lidar-based 3D object detection. Recent grid-based detectors usually divide point clouds into voxels or pillars and construct single-stream networks in Bird's Eye View. However, these point cloud encoding paradigms underestimate the point representation in the vertical direction, which cause the loss of semantic or fine-grained information, especially for vertical sensitive objects like pedestrian and cyclists. In this paper, we propose an explicit vertical multi-scale representation learning framework, VPFusion, to combine the complementary information from both voxel and pillar streams. Specifically, VPFusion first builds upon a sparse voxel-pillar-based backbone. The backbone divides point clouds into voxels and pillars, then encodes features with 3D and 2D sparse convolution simultaneously. Next, we introduce the Sparse Fusion Layer (SFL), which establishes a bidirectional pathway for sparse voxel and pillar features to enable the interaction between them. Additionally, we present the Dense Fusion Neck (DFN) to effectively combine the dense feature maps from voxel and pillar branches with multi-scale. Extensive experiments on the large-scale Waymo Open Dataset and nuScenes Dataset demonstrate that VPFusion surpasses the single-stream baselines by a large margin and achieves state-of-the-art performance with real-time inference speed.
On the Evaluations of ChatGPT and Emotion-enhanced Prompting for Mental Health Analysis
Apr 06, 2023
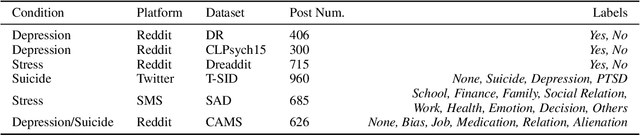
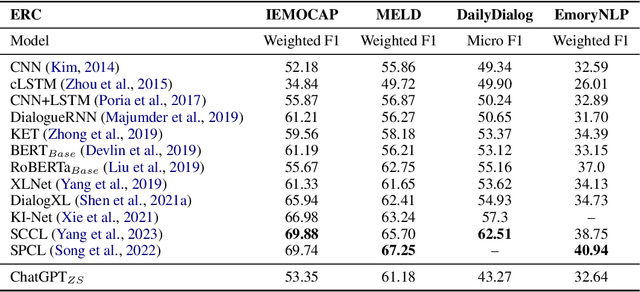
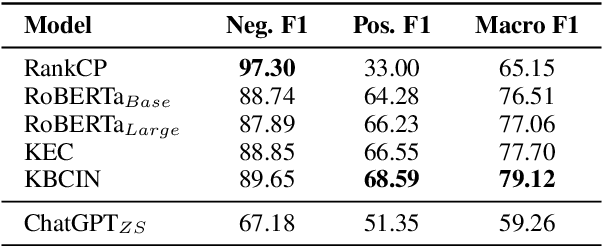
Automated mental health analysis shows great potential for enhancing the efficiency and accessibility of mental health care, whereas the recent dominant methods utilized pre-trained language models (PLMs) as the backbone and incorporated emotional information. The latest large language models (LLMs), such as ChatGPT, exhibit dramatic capabilities on diverse natural language processing tasks. However, existing studies on ChatGPT's zero-shot performance for mental health analysis have limitations in inadequate evaluation, utilization of emotional information, and explainability of methods. In this work, we comprehensively evaluate the mental health analysis and emotional reasoning ability of ChatGPT on 11 datasets across 5 tasks, including binary and multi-class mental health condition detection, cause/factor detection of mental health conditions, emotion recognition in conversations, and causal emotion entailment. We empirically analyze the impact of different prompting strategies with emotional cues on ChatGPT's mental health analysis ability and explainability. Experimental results show that ChatGPT outperforms traditional neural network methods but still has a significant gap with advanced task-specific methods. The qualitative analysis shows its potential in explainability compared with advanced black-box methods but also limitations on robustness and inaccurate reasoning. Prompt engineering with emotional cues is found to be effective in improving its performance on mental health analysis but requires the proper way of emotion infusion.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 27, 2023


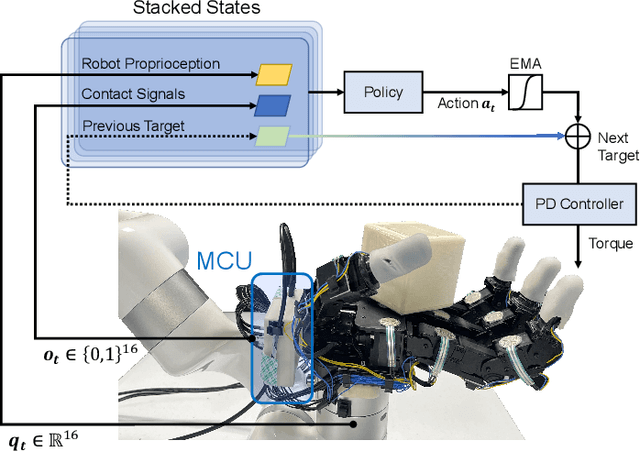
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
Self-discipline on multiple channels
Apr 27, 2023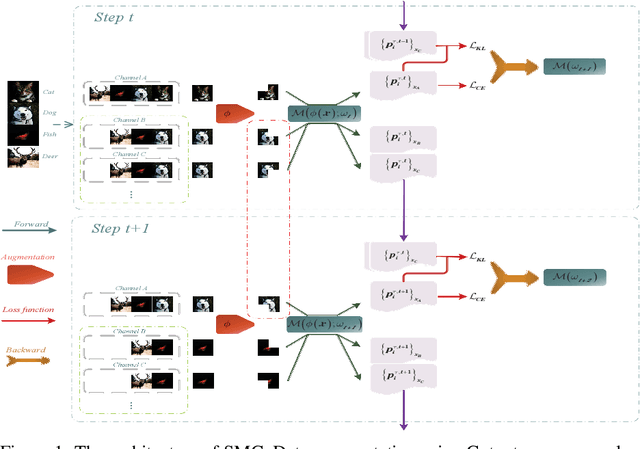
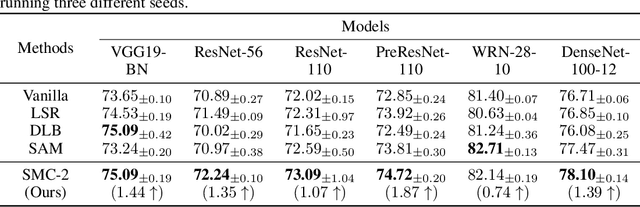
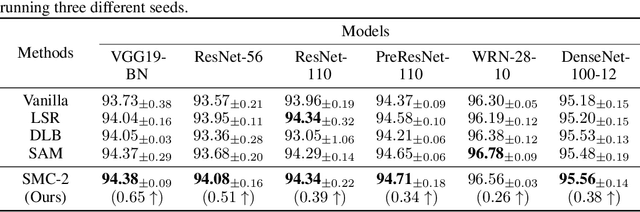
Self-distillation relies on its own information to improve the generalization ability of the model and has a bright future. Existing self-distillation methods either require additional models, model modification, or batch size expansion for training, which increases the difficulty of use, memory consumption, and computational cost. This paper developed Self-discipline on multiple channels(SMC), which combines consistency regularization with self-distillation using the concept of multiple channels. Conceptually, SMC consists of two steps: 1) each channel data is simultaneously passed through the model to obtain its corresponding soft label, and 2) the soft label saved in the previous step is read together with the soft label obtained from the current channel data through the model to calculate the loss function. SMC uses consistent regularization and self-distillation to improve the generalization ability of the model and the robustness of the model to noisy labels. We named the SMC containing only two channels as SMC-2. Comparative experimental results on both datasets show that SMC-2 outperforms Label Smoothing Regularizaion and Self-distillation From The Last Mini-batch on all models, and outperforms the state-of-the-art Sharpness-Aware Minimization method on 83% of the models.Compatibility of SMC-2 and data augmentation experimental results show that using both SMC-2 and data augmentation improves the generalization ability of the model between 0.28% and 1.80% compared to using only data augmentation. Ultimately, the results of the label noise interference experiments show that SMC-2 curbs the tendency that the model's generalization ability decreases in the late training period due to the interference of label noise. The code is available at https://github.com/JiuTiannn/SMC-Self-discipline-on-multiple-channels.
Road Genome: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving
Apr 20, 2023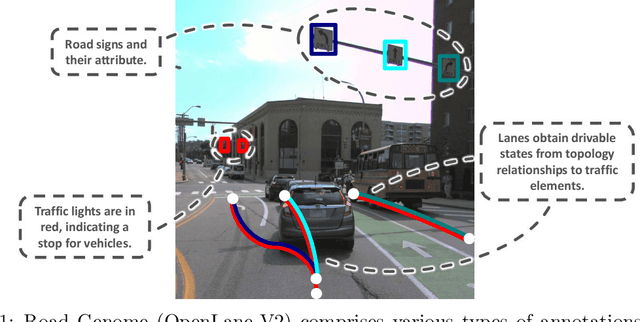
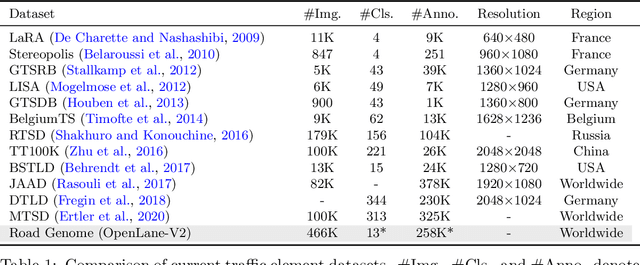
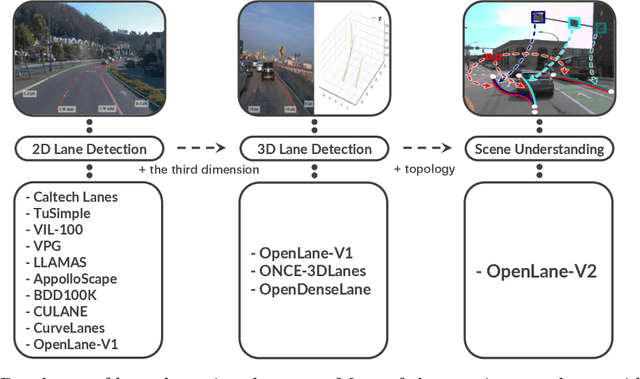

Understanding the complex traffic environment is crucial for self-driving vehicles. Existing benchmarks in autonomous driving mainly cast scene understanding as perception problems, e.g., perceiving lanelines with vanilla detection or segmentation methods. As such, we argue that the perception pipeline provides limited information for autonomous vehicles to drive in the right way, especially without the aid of high-definition (HD) map. For instance, following the wrong traffic signal at a complicated crossroad would lead to a catastrophic incident. By introducing Road Genome (OpenLane-V2), we intend to shift the community's attention and take a step further beyond perception - to the task of topology reasoning for scene structure. The goal of Road Genome is to understand the scene structure by investigating the relationship of perceived entities among traffic elements and lanes. Built on top of prevailing datasets, the newly minted benchmark comprises 2,000 sequences of multi-view images captured from diverse real-world scenarios. We annotate data with high-quality manual checks in the loop. Three subtasks compromise the gist of Road Genome, including the 3D lane detection inherited from OpenLane. We have/will host Challenges in the upcoming future at top-tiered venues.