 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023
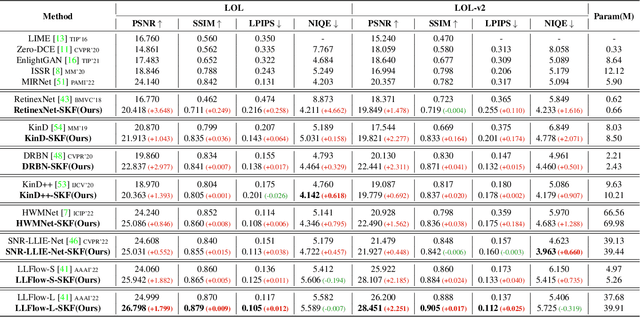
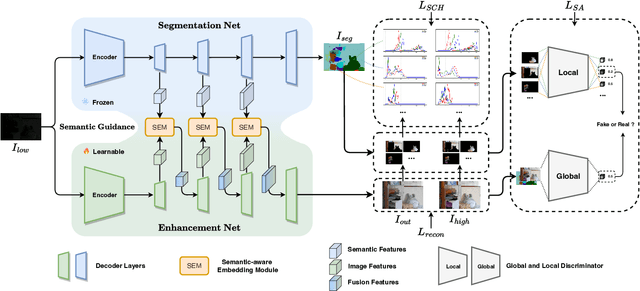
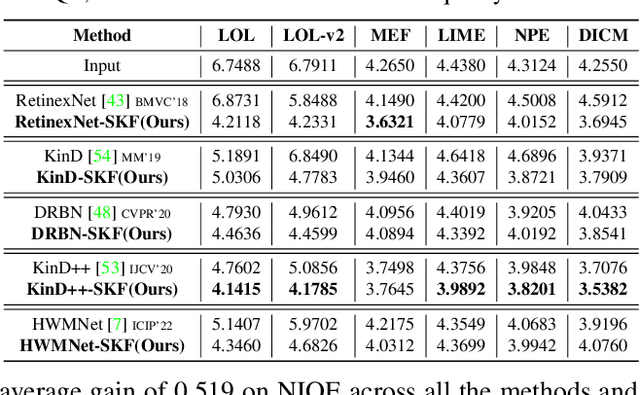
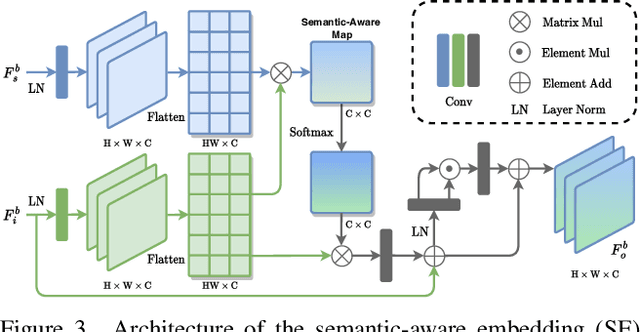
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023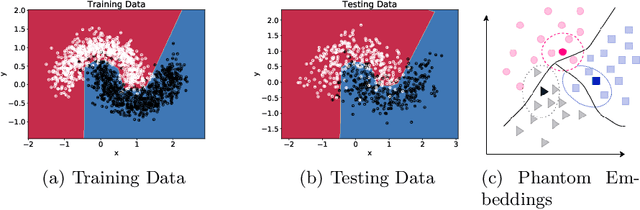
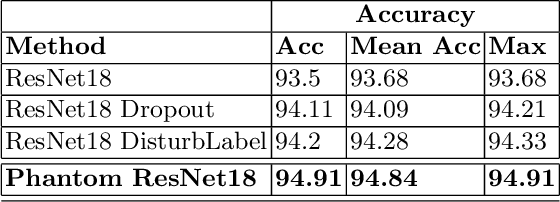
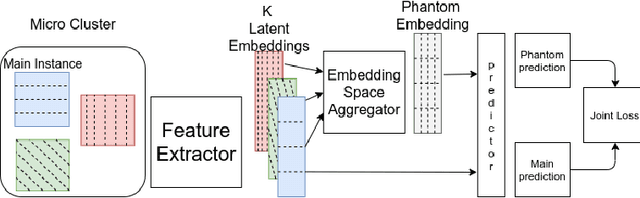
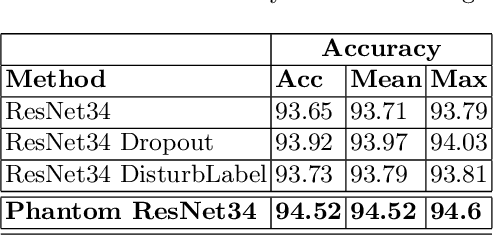
The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
Memory Efficient Diffusion Probabilistic Models via Patch-based Generation
Apr 14, 2023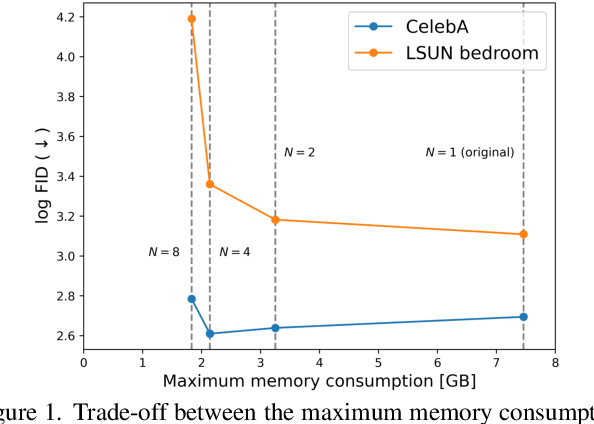
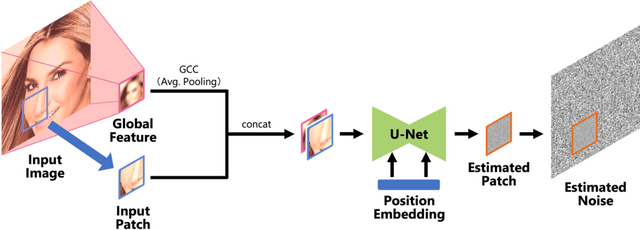

Diffusion probabilistic models have been successful in generating high-quality and diverse images. However, traditional models, whose input and output are high-resolution images, suffer from excessive memory requirements, making them less practical for edge devices. Previous approaches for generative adversarial networks proposed a patch-based method that uses positional encoding and global content information. Nevertheless, designing a patch-based approach for diffusion probabilistic models is non-trivial. In this paper, we resent a diffusion probabilistic model that generates images on a patch-by-patch basis. We propose two conditioning methods for a patch-based generation. First, we propose position-wise conditioning using one-hot representation to ensure patches are in proper positions. Second, we propose Global Content Conditioning (GCC) to ensure patches have coherent content when concatenated together. We evaluate our model qualitatively and quantitatively on CelebA and LSUN bedroom datasets and demonstrate a moderate trade-off between maximum memory consumption and generated image quality. Specifically, when an entire image is divided into 2 x 2 patches, our proposed approach can reduce the maximum memory consumption by half while maintaining comparable image quality.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022

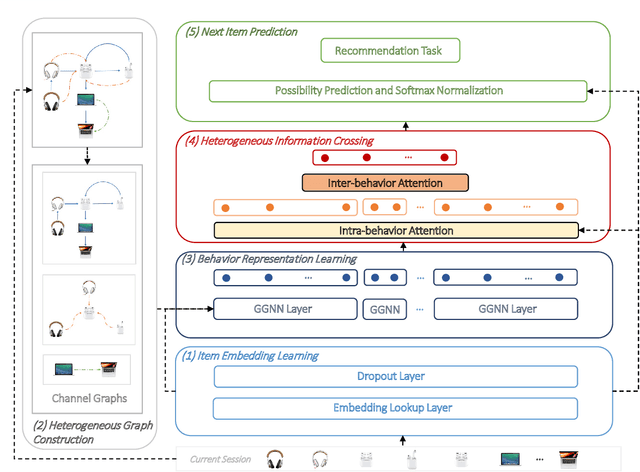
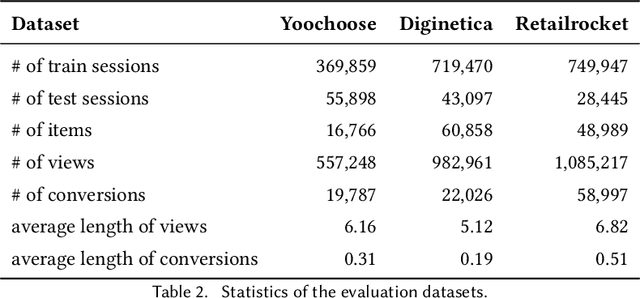
Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.
PEOPL: Characterizing Privately Encoded Open Datasets with Public Labels
Mar 31, 2023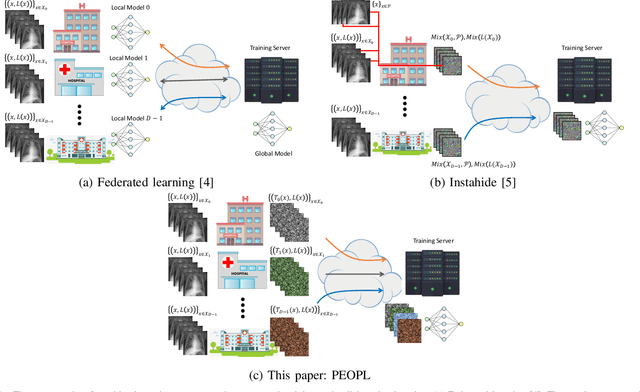
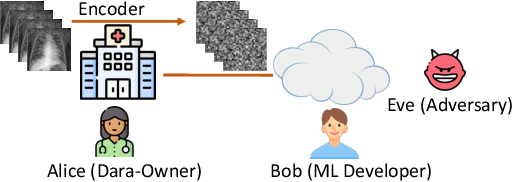
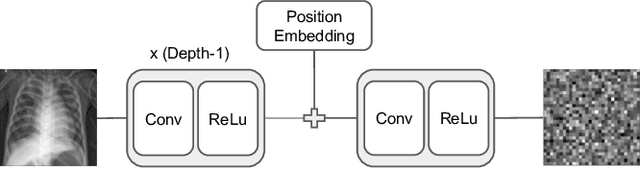

Allowing organizations to share their data for training of machine learning (ML) models without unintended information leakage is an open problem in practice. A promising technique for this still-open problem is to train models on the encoded data. Our approach, called Privately Encoded Open Datasets with Public Labels (PEOPL), uses a certain class of randomly constructed transforms to encode sensitive data. Organizations publish their randomly encoded data and associated raw labels for ML training, where training is done without knowledge of the encoding realization. We investigate several important aspects of this problem: We introduce information-theoretic scores for privacy and utility, which quantify the average performance of an unfaithful user (e.g., adversary) and a faithful user (e.g., model developer) that have access to the published encoded data. We then theoretically characterize primitives in building families of encoding schemes that motivate the use of random deep neural networks. Empirically, we compare the performance of our randomized encoding scheme and a linear scheme to a suite of computational attacks, and we also show that our scheme achieves competitive prediction accuracy to raw-sample baselines. Moreover, we demonstrate that multiple institutions, using independent random encoders, can collaborate to train improved ML models.
Modelling Patient Trajectories Using Multimodal Information
Sep 09, 2022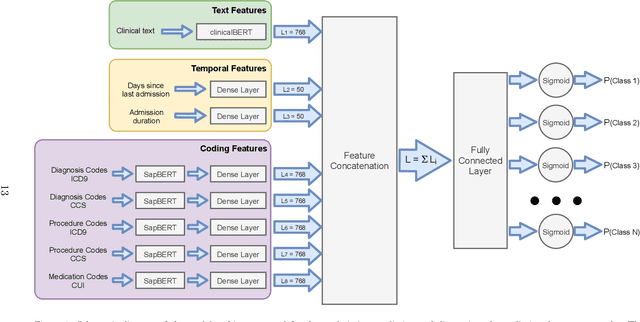
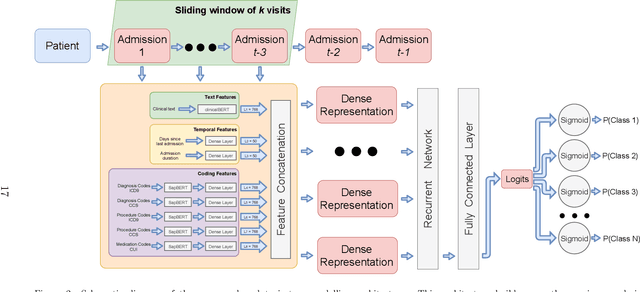

Electronic Health Records (EHRs) aggregate diverse information at the patient level, holding a trajectory representative of the evolution of the patient health status throughout time. Although this information provides context and can be leveraged by physicians to monitor patient health and make more accurate prognoses/diagnoses, patient records can contain information from very long time spans, which combined with the rapid generation rate of medical data makes clinical decision making more complex. Patient trajectory modelling can assist by exploring existing information in a scalable manner, and can contribute in augmenting health care quality by fostering preventive medicine practices. We propose a solution to model patient trajectories that combines different types of information and considers the temporal aspect of clinical data. This solution leverages two different architectures: one supporting flexible sets of input features, to convert patient admissions into dense representations; and a second exploring extracted admission representations in a recurrent-based architecture, where patient trajectories are processed in sub-sequences using a sliding window mechanism. The developed solution was evaluated on two different clinical outcomes, unexpected patient readmission and disease progression, using the publicly available MIMIC-III clinical database. The results obtained demonstrate the potential of the first architecture to model readmission and diagnoses prediction using single patient admissions. While information from clinical text did not show the discriminative power observed in other existing works, this may be explained by the need to fine-tune the clinicalBERT model. Finally, we demonstrate the potential of the sequence-based architecture using a sliding window mechanism to represent the input data, attaining comparable performances to other existing solutions.
Hierarchical Catalogue Generation for Literature Review: A Benchmark
Apr 10, 2023

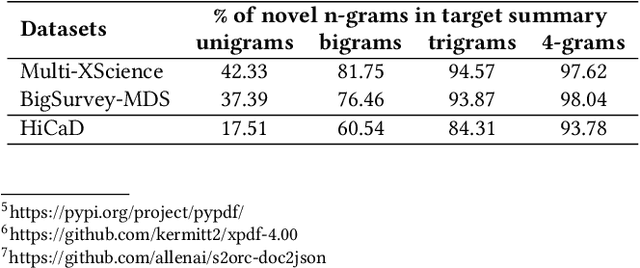
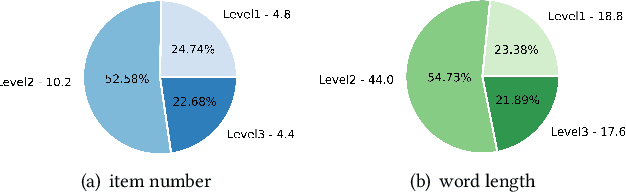
Multi-document scientific summarization can extract and organize important information from an abundant collection of papers, arousing widespread attention recently. However, existing efforts focus on producing lengthy overviews lacking a clear and logical hierarchy. To alleviate this problem, we present an atomic and challenging task named Hierarchical Catalogue Generation for Literature Review (HiCatGLR), which aims to generate a hierarchical catalogue for a review paper given various references. We carefully construct a novel English Hierarchical Catalogues of Literature Reviews Dataset (HiCaD) with 13.8k literature review catalogues and 120k reference papers, where we benchmark diverse experiments via the end-to-end and pipeline methods. To accurately assess the model performance, we design evaluation metrics for similarity to ground truth from semantics and structure. Besides, our extensive analyses verify the high quality of our dataset and the effectiveness of our evaluation metrics. Furthermore, we discuss potential directions for this task to motivate future research.
Electromagnetic Interference Cancellation for RIS-Assisted Communications
Apr 10, 2023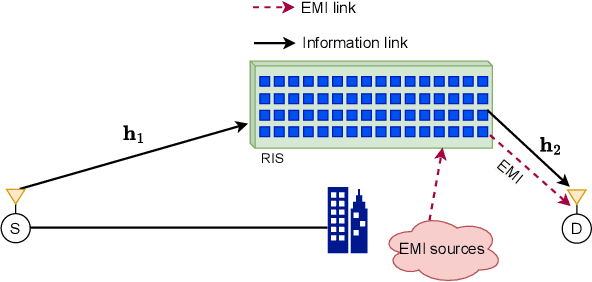
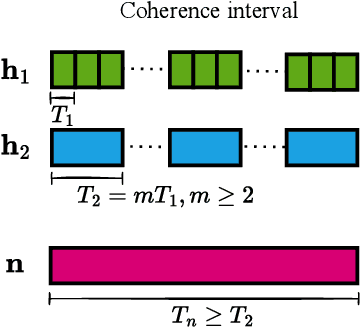
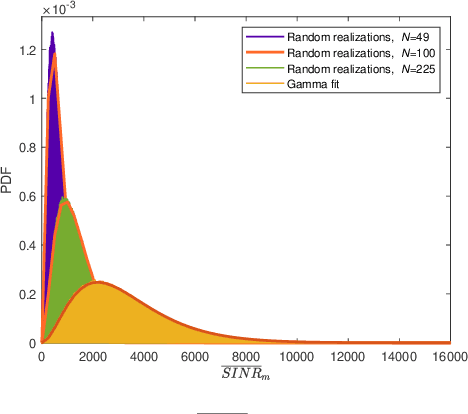
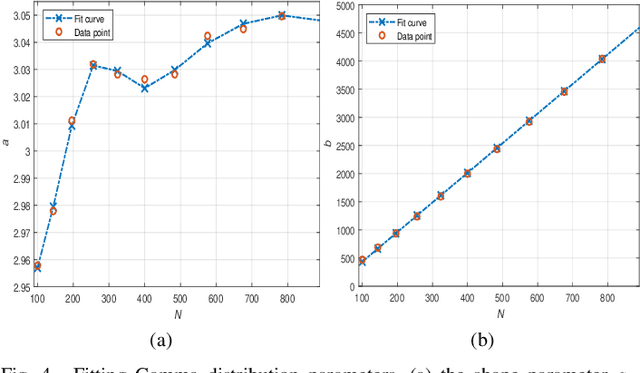
Reconfigurable intelligent surface (RIS)-empowered communication is an emerging technology that has recently received growing attention as a potential candidate for next-generation wireless communications. Although RISs have shown the potential of manipulating the wireless channel through passive beamforming, it is shown that they can also bring undesired side effects, such as reflecting the electromagnetic interference (EMI) from the surrounding environment to the receiver side. In this study, we propose a novel EMI cancellation scheme to mitigate the impact of the EMI by exploiting its special time-domain structure and considering a clever passive beamforming method at the RIS. Compared to its benchmark, computer simulations show that the proposed scheme achieves superior performance in terms of the average signal-to-interference-plus-noise ratio (SINR) and outage probability (OP), especially when the EMI power is comparable to the power of the information signal impinging on the RIS surface.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 21, 2023


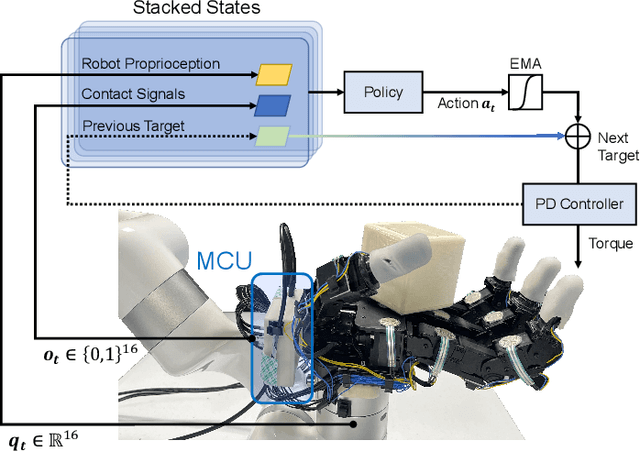
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
Self-Paced Neutral Expression-Disentangled Learning for Facial Expression Recognition
Mar 21, 2023
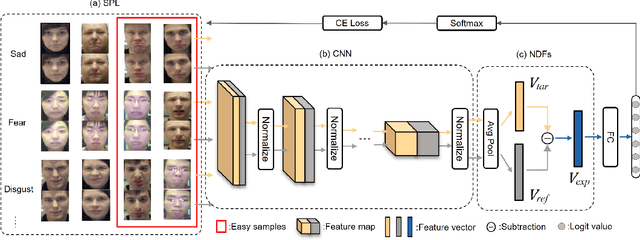
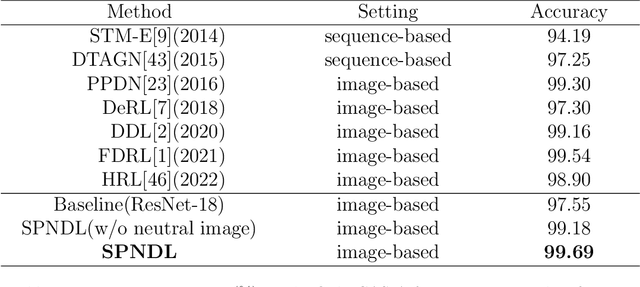
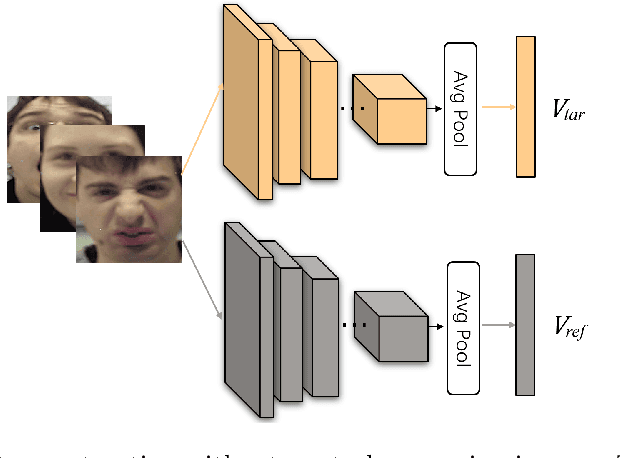
The accuracy of facial expression recognition is typically affected by the following factors: high similarities across different expressions, disturbing factors, and micro-facial movement of rapid and subtle changes. One potentially viable solution for addressing these barriers is to exploit the neutral information concealed in neutral expression images. To this end, in this paper we propose a self-Paced Neutral Expression-Disentangled Learning (SPNDL) model. SPNDL disentangles neutral information from facial expressions, making it easier to extract key and deviation features. Specifically, it allows to capture discriminative information among similar expressions and perceive micro-facial movements. In order to better learn these neutral expression-disentangled features (NDFs) and to alleviate the non-convex optimization problem, a self-paced learning (SPL) strategy based on NDFs is proposed in the training stage. SPL learns samples from easy to complex by increasing the number of samples selected into the training process, which enables to effectively suppress the negative impacts introduced by low-quality samples and inconsistently distributed NDFs. Experiments on three popular databases (i.e., CK+, Oulu-CASIA, and RAF-DB) show the effectiveness of our proposed method.