 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contactless Human Activity Recognition using Deep Learning with Flexible and Scalable Software Define Radio
Apr 18, 2023
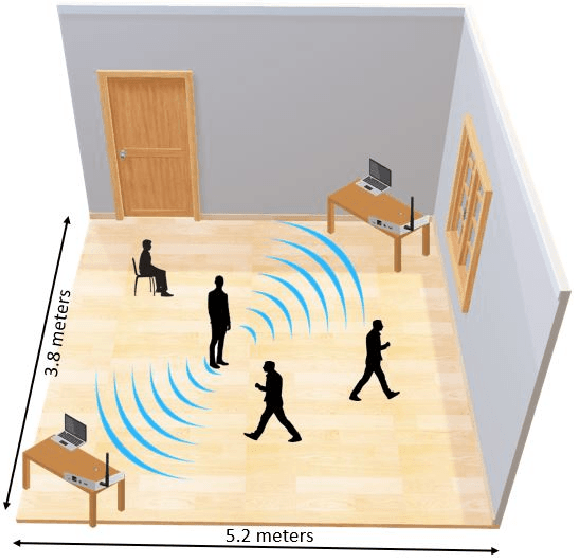

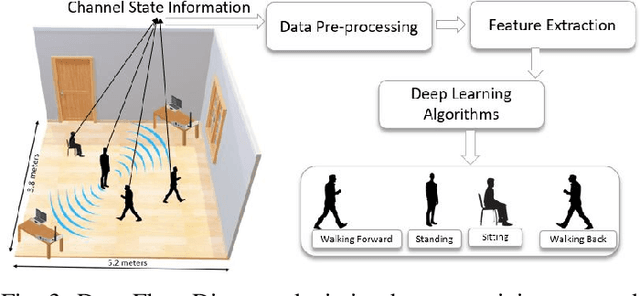
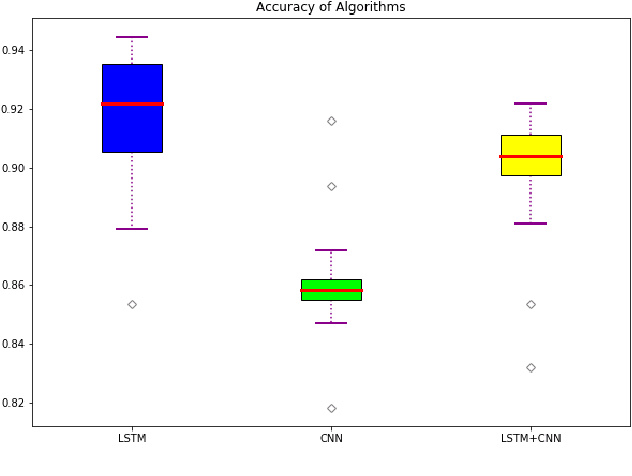
Ambient computing is gaining popularity as a major technological advancement for the future. The modern era has witnessed a surge in the advancement in healthcare systems, with viable radio frequency solutions proposed for remote and unobtrusive human activity recognition (HAR). Specifically, this study investigates the use of Wi-Fi channel state information (CSI) as a novel method of ambient sensing that can be employed as a contactless means of recognizing human activity in indoor environments. These methods avoid additional costly hardware required for vision-based systems, which are privacy-intrusive, by (re)using Wi-Fi CSI for various safety and security applications. During an experiment utilizing universal software-defined radio (USRP) to collect CSI samples, it was observed that a subject engaged in six distinct activities, which included no activity, standing, sitting, and leaning forward, across different areas of the room. Additionally, more CSI samples were collected when the subject walked in two different directions. This study presents a Wi-Fi CSI-based HAR system that assesses and contrasts deep learning approaches, namely convolutional neural network (CNN), long short-term memory (LSTM), and hybrid (LSTM+CNN), employed for accurate activity recognition. The experimental results indicate that LSTM surpasses current models and achieves an average accuracy of 95.3% in multi-activity classification when compared to CNN and hybrid techniques. In the future, research needs to study the significance of resilience in diverse and dynamic environments to identify the activity of multiple users.
Sociocultural knowledge is needed for selection of shots in hate speech detection tasks
Apr 11, 2023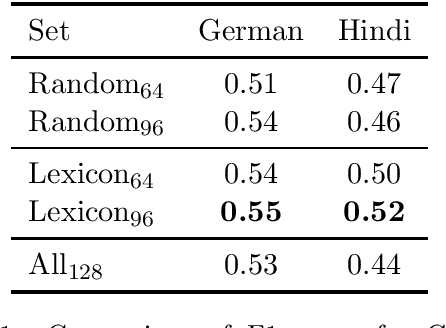
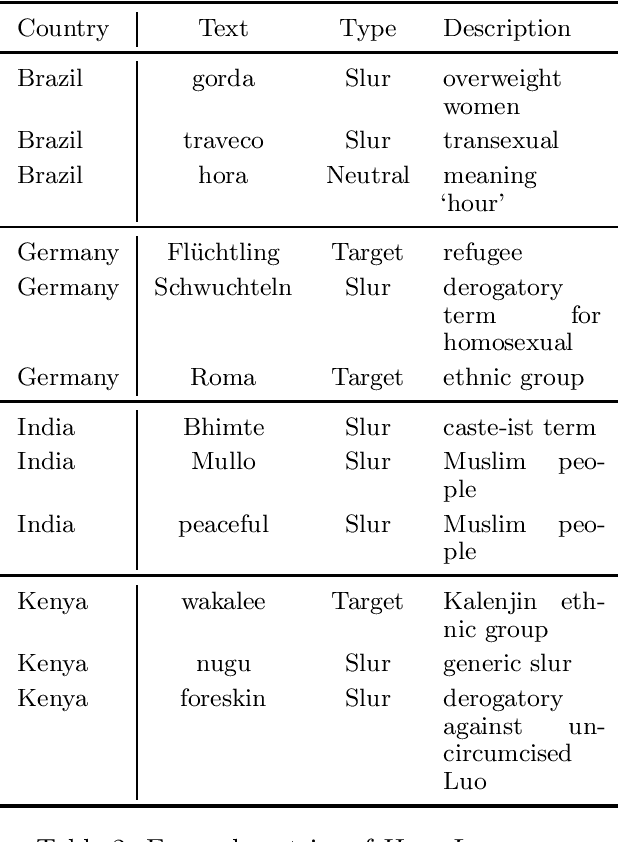
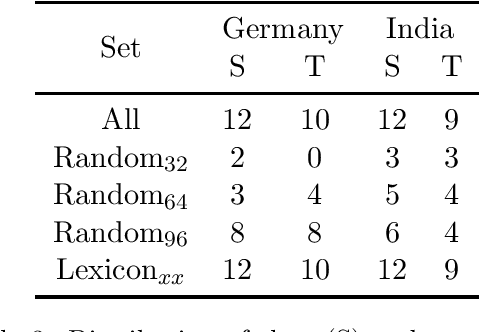
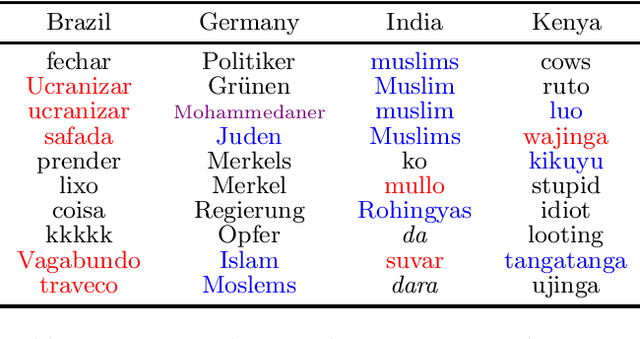
We introduce HATELEXICON, a lexicon of slurs and targets of hate speech for the countries of Brazil, Germany, India and Kenya, to aid training and interpretability of models. We demonstrate how our lexicon can be used to interpret model predictions, showing that models developed to classify extreme speech rely heavily on target words when making predictions. Further, we propose a method to aid shot selection for training in low-resource settings via HATELEXICON. In few-shot learning, the selection of shots is of paramount importance to model performance. In our work, we simulate a few-shot setting for German and Hindi, using HASOC data for training and the Multilingual HateCheck (MHC) as a benchmark. We show that selecting shots based on our lexicon leads to models performing better on MHC than models trained on shots sampled randomly. Thus, when given only a few training examples, using our lexicon to select shots containing more sociocultural information leads to better few-shot performance.
OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction
Apr 11, 2023
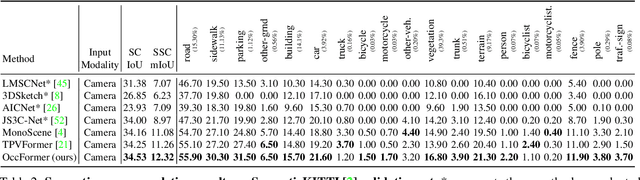
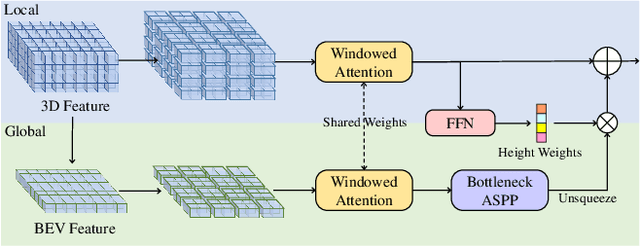
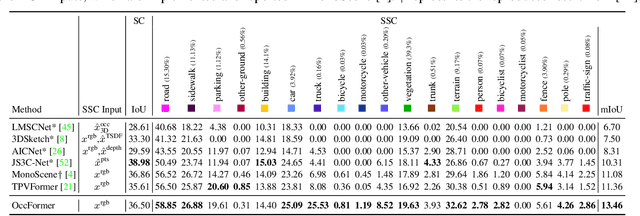
The vision-based perception for autonomous driving has undergone a transformation from the bird-eye-view (BEV) representations to the 3D semantic occupancy. Compared with the BEV planes, the 3D semantic occupancy further provides structural information along the vertical direction. This paper presents OccFormer, a dual-path transformer network to effectively process the 3D volume for semantic occupancy prediction. OccFormer achieves a long-range, dynamic, and efficient encoding of the camera-generated 3D voxel features. It is obtained by decomposing the heavy 3D processing into the local and global transformer pathways along the horizontal plane. For the occupancy decoder, we adapt the vanilla Mask2Former for 3D semantic occupancy by proposing preserve-pooling and class-guided sampling, which notably mitigate the sparsity and class imbalance. Experimental results demonstrate that OccFormer significantly outperforms existing methods for semantic scene completion on SemanticKITTI dataset and for LiDAR semantic segmentation on nuScenes dataset. Code is available at \url{https://github.com/zhangyp15/OccFormer}.
Online Spatio-Temporal Learning with Target Projection
Apr 11, 2023
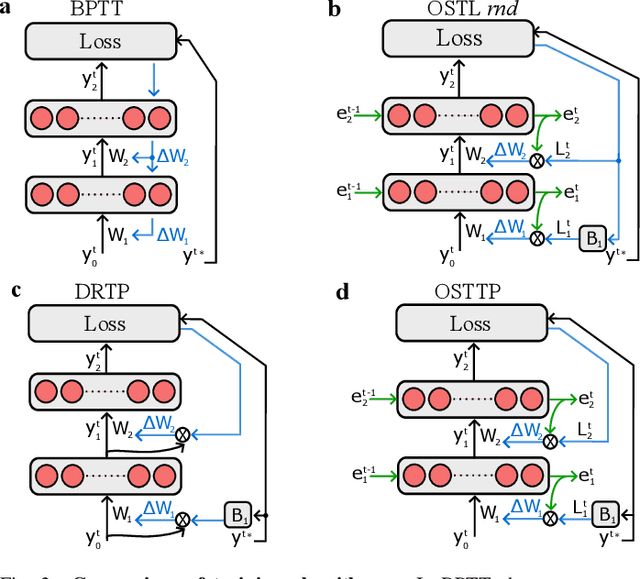
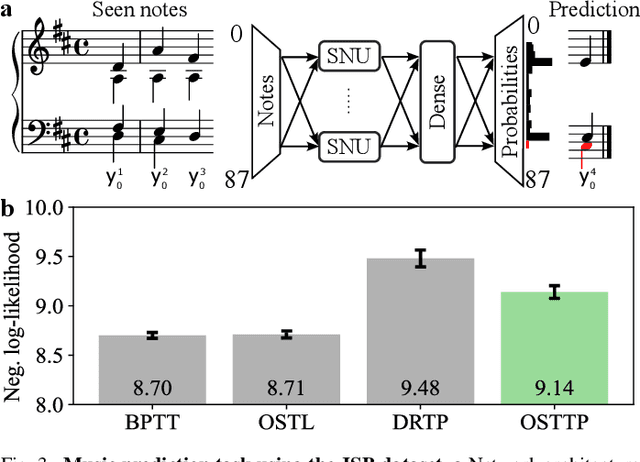
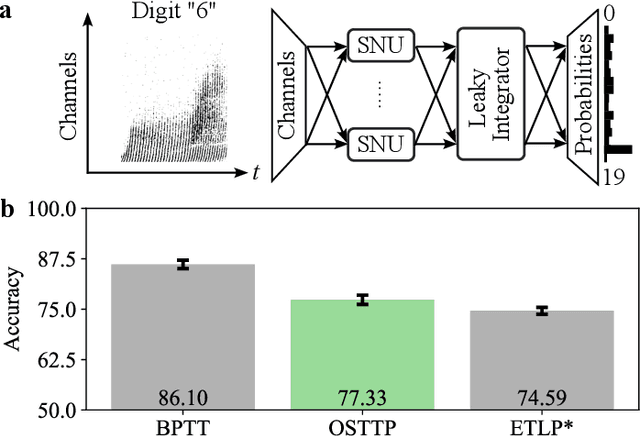
Recurrent neural networks trained with the backpropagation through time (BPTT) algorithm have led to astounding successes in various temporal tasks. However, BPTT introduces severe limitations, such as the requirement to propagate information backwards through time, the weight symmetry requirement, as well as update-locking in space and time. These problems become roadblocks for AI systems where online training capabilities are vital. Recently, researchers have developed biologically-inspired training algorithms, addressing a subset of those problems. In this work, we propose a novel learning algorithm called online spatio-temporal learning with target projection (OSTTP) that resolves all aforementioned issues of BPTT. In particular, OSTTP equips a network with the capability to simultaneously process and learn from new incoming data, alleviating the weight symmetry and update-locking problems. We evaluate OSTTP on two temporal tasks, showcasing competitive performance compared to BPTT. Moreover, we present a proof-of-concept implementation of OSTTP on a memristive neuromorphic hardware system, demonstrating its versatility and applicability to resource-constrained AI devices.
Towards More Robust and Accurate Sequential Recommendation with Cascade-guided Adversarial Training
Apr 11, 2023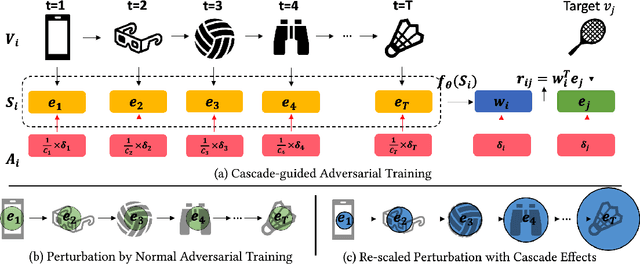
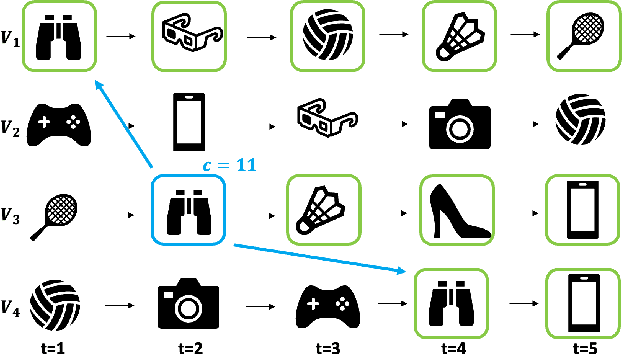
Sequential recommendation models, models that learn from chronological user-item interactions, outperform traditional recommendation models in many settings. Despite the success of sequential recommendation models, their robustness has recently come into question. Two properties unique to the nature of sequential recommendation models may impair their robustness - the cascade effects induced during training and the model's tendency to rely too heavily on temporal information. To address these vulnerabilities, we propose Cascade-guided Adversarial training, a new adversarial training procedure that is specifically designed for sequential recommendation models. Our approach harnesses the intrinsic cascade effects present in sequential modeling to produce strategic adversarial perturbations to item embeddings during training. Experiments on training state-of-the-art sequential models on four public datasets from different domains show that our training approach produces superior model ranking accuracy and superior model robustness to real item replacement perturbations when compared to both standard model training and generic adversarial training.
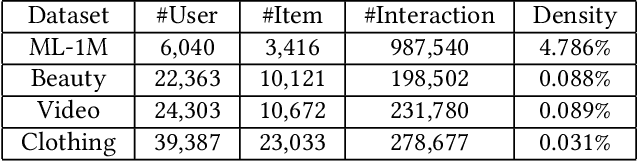
RELS-DQN: A Robust and Efficient Local Search Framework for Combinatorial Optimization
Apr 11, 2023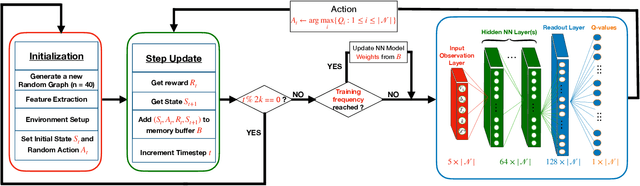
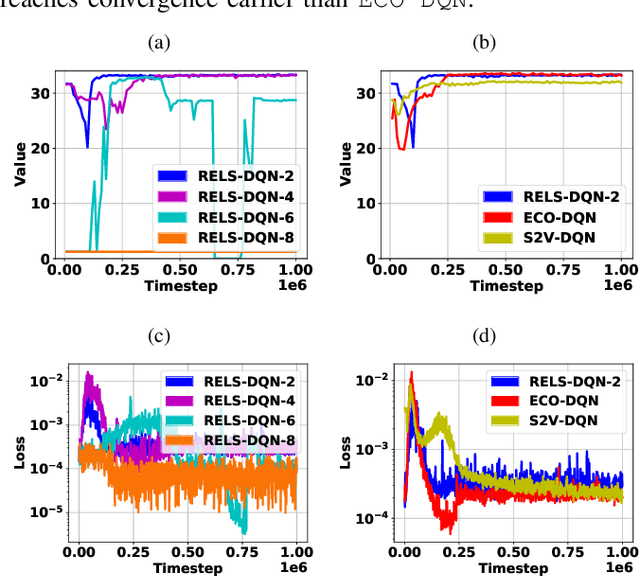
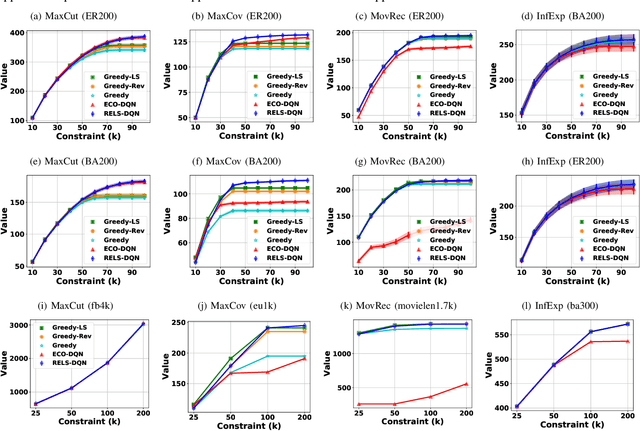
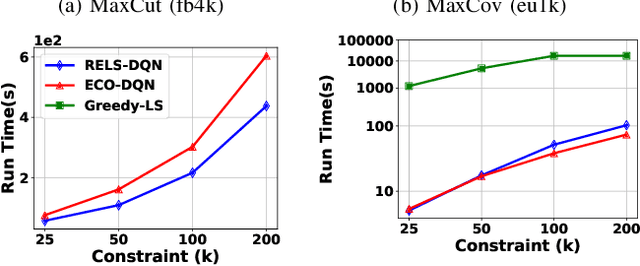
Combinatorial optimization (CO) aims to efficiently find the best solution to NP-hard problems ranging from statistical physics to social media marketing. A wide range of CO applications can benefit from local search methods because they allow reversible action over greedy policies. Deep Q-learning (DQN) using message-passing neural networks (MPNN) has shown promise in replicating the local search behavior and obtaining comparable results to the local search algorithms. However, the over-smoothing and the information loss during the iterations of message passing limit its robustness across applications, and the large message vectors result in memory inefficiency. Our paper introduces RELS-DQN, a lightweight DQN framework that exhibits the local search behavior while providing practical scalability. Using the RELS-DQN model trained on one application, it can generalize to various applications by providing solution values higher than or equal to both the local search algorithms and the existing DQN models while remaining efficient in runtime and memory.
RGBT Tracking via Progressive Fusion Transformer with Dynamically Guided Learning
Mar 26, 2023Existing Transformer-based RGBT tracking methods either use cross-attention to fuse the two modalities, or use self-attention and cross-attention to model both modality-specific and modality-sharing information. However, the significant appearance gap between modalities limits the feature representation ability of certain modalities during the fusion process. To address this problem, we propose a novel Progressive Fusion Transformer called ProFormer, which progressively integrates single-modality information into the multimodal representation for robust RGBT tracking. In particular, ProFormer first uses a self-attention module to collaboratively extract the multimodal representation, and then uses two cross-attention modules to interact it with the features of the dual modalities respectively. In this way, the modality-specific information can well be activated in the multimodal representation. Finally, a feed-forward network is used to fuse two interacted multimodal representations for the further enhancement of the final multimodal representation. In addition, existing learning methods of RGBT trackers either fuse multimodal features into one for final classification, or exploit the relationship between unimodal branches and fused branch through a competitive learning strategy. However, they either ignore the learning of single-modality branches or result in one branch failing to be well optimized. To solve these problems, we propose a dynamically guided learning algorithm that adaptively uses well-performing branches to guide the learning of other branches, for enhancing the representation ability of each branch. Extensive experiments demonstrate that our proposed ProFormer sets a new state-of-the-art performance on RGBT210, RGBT234, LasHeR, and VTUAV datasets.
A Comprehensive Survey on Deep Graph Representation Learning
Apr 19, 2023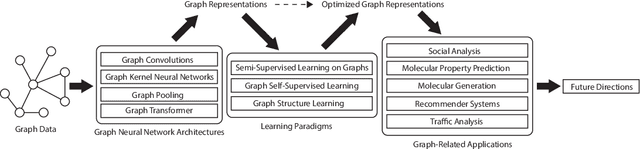
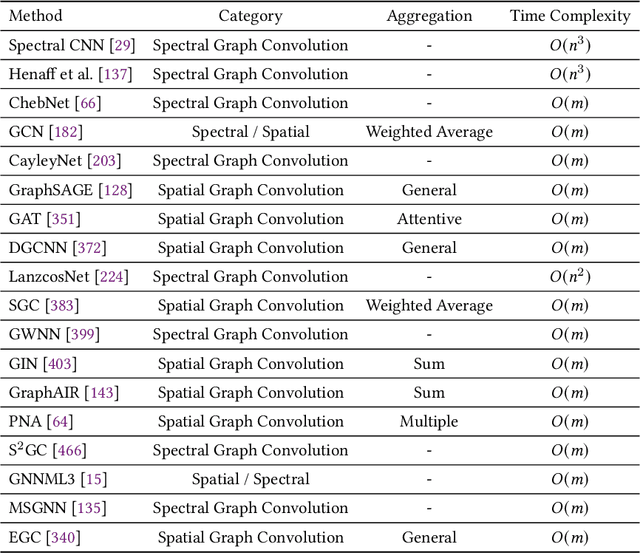
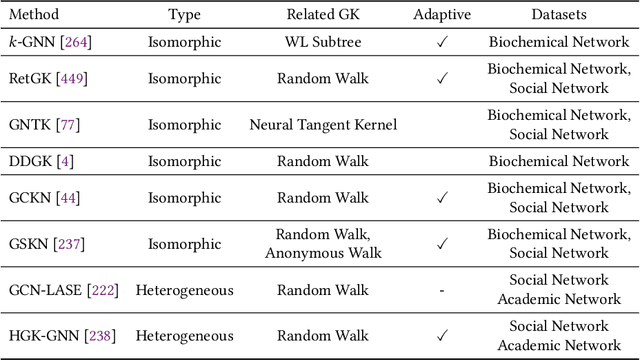
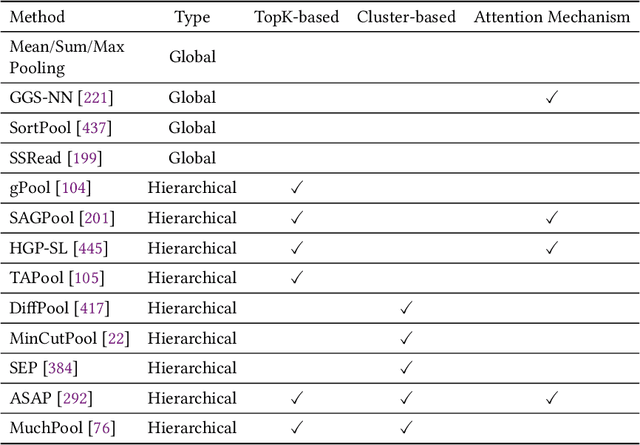
Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied in a range of fields, including machine learning and data mining. Classic graph embedding methods follow the basic idea that the embedding vectors of interconnected nodes in the graph can still maintain a relatively close distance, thereby preserving the structural information between the nodes in the graph. However, this is sub-optimal due to: (i) traditional methods have limited model capacity which limits the learning performance; (ii) existing techniques typically rely on unsupervised learning strategies and fail to couple with the latest learning paradigms; (iii) representation learning and downstream tasks are dependent on each other which should be jointly enhanced. With the remarkable success of deep learning, deep graph representation learning has shown great potential and advantages over shallow (traditional) methods, there exist a large number of deep graph representation learning techniques have been proposed in the past decade, especially graph neural networks. In this survey, we conduct a comprehensive survey on current deep graph representation learning algorithms by proposing a new taxonomy of existing state-of-the-art literature. Specifically, we systematically summarize the essential components of graph representation learning and categorize existing approaches by the ways of graph neural network architectures and the most recent advanced learning paradigms. Moreover, this survey also provides the practical and promising applications of deep graph representation learning. Last but not least, we state new perspectives and suggest challenging directions which deserve further investigations in the future.
Rethinking Benchmarks for Cross-modal Image-text Retrieval
Apr 21, 2023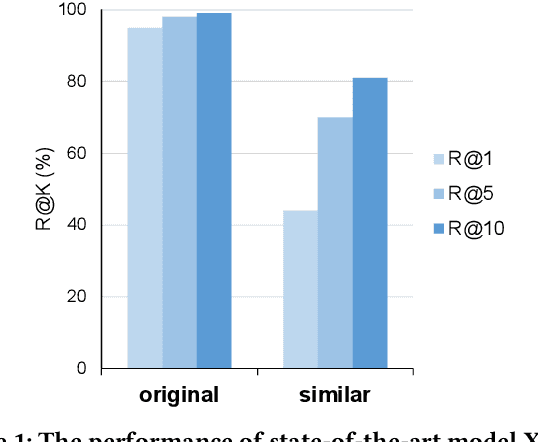


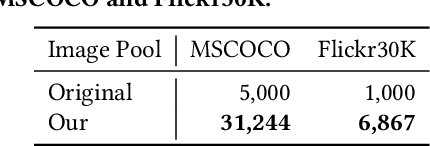
Image-text retrieval, as a fundamental and important branch of information retrieval, has attracted extensive research attentions. The main challenge of this task is cross-modal semantic understanding and matching. Some recent works focus more on fine-grained cross-modal semantic matching. With the prevalence of large scale multimodal pretraining models, several state-of-the-art models (e.g. X-VLM) have achieved near-perfect performance on widely-used image-text retrieval benchmarks, i.e. MSCOCO-Test-5K and Flickr30K-Test-1K. In this paper, we review the two common benchmarks and observe that they are insufficient to assess the true capability of models on fine-grained cross-modal semantic matching. The reason is that a large amount of images and texts in the benchmarks are coarse-grained. Based on the observation, we renovate the coarse-grained images and texts in the old benchmarks and establish the improved benchmarks called MSCOCO-FG and Flickr30K-FG. Specifically, on the image side, we enlarge the original image pool by adopting more similar images. On the text side, we propose a novel semi-automatic renovation approach to refine coarse-grained sentences into finer-grained ones with little human effort. Furthermore, we evaluate representative image-text retrieval models on our new benchmarks to demonstrate the effectiveness of our method. We also analyze the capability of models on fine-grained semantic comprehension through extensive experiments. The results show that even the state-of-the-art models have much room for improvement in fine-grained semantic understanding, especially in distinguishing attributes of close objects in images. Our code and improved benchmark datasets are publicly available at: https://github.com/cwj1412/MSCOCO-Flikcr30K_FG, which we hope will inspire further in-depth research on cross-modal retrieval.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
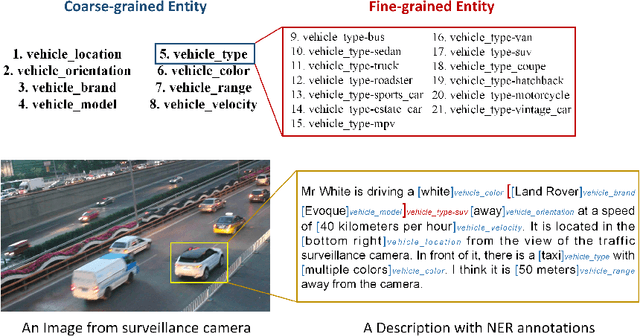
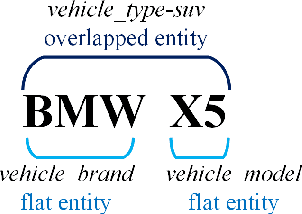
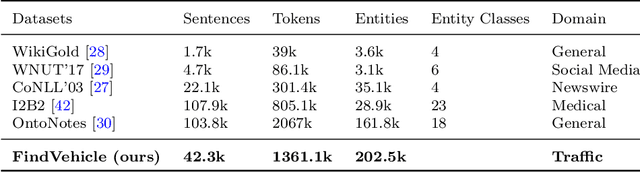
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.