 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023


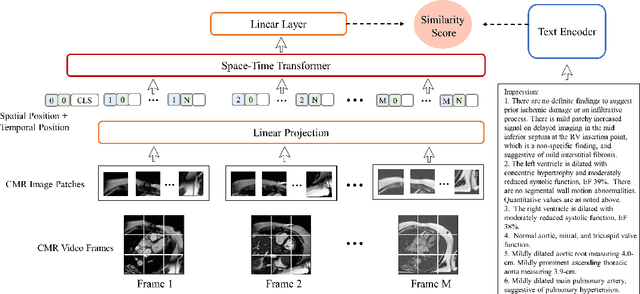
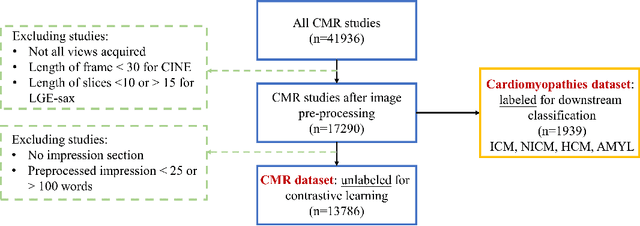
Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
Time-series Anomaly Detection via Contextual Discriminative Contrastive Learning
Apr 16, 2023
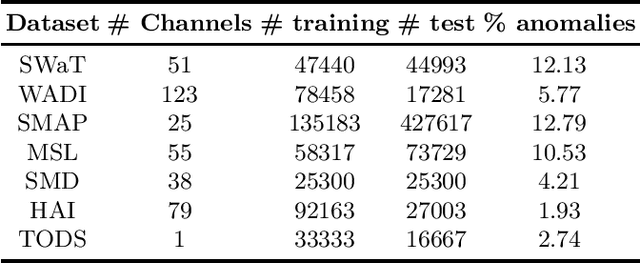
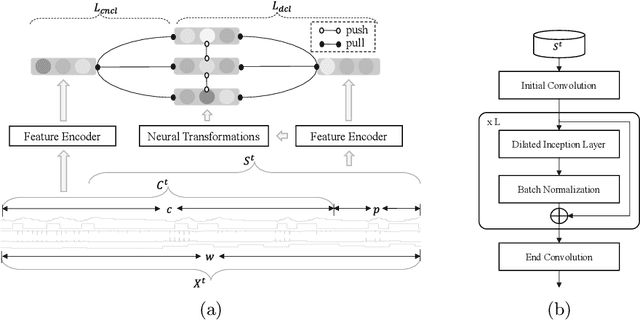
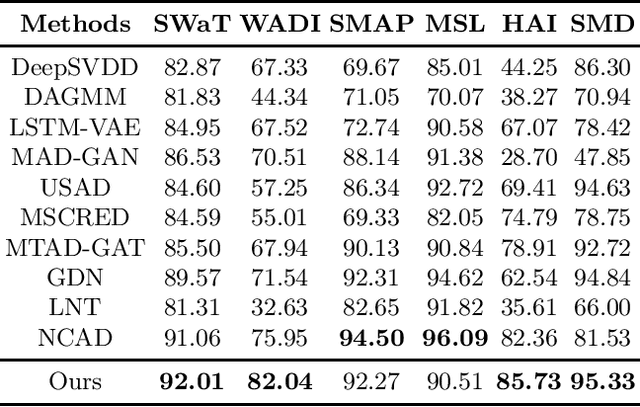
Detecting anomalies in temporal data is challenging due to anomalies being dependent on temporal dynamics. One-class classification methods are commonly used for anomaly detection tasks, but they have limitations when applied to temporal data. In particular, mapping all normal instances into a single hypersphere to capture their global characteristics can lead to poor performance in detecting context-based anomalies where the abnormality is defined with respect to local information. To address this limitation, we propose a novel approach inspired by the loss function of DeepSVDD. Instead of mapping all normal instances into a single hypersphere center, each normal instance is pulled toward a recent context window. However, this approach is prone to a representation collapse issue where the neural network that encodes a given instance and its context is optimized towards a constant encoder solution. To overcome this problem, we combine our approach with a deterministic contrastive loss from Neutral AD, a promising self-supervised learning anomaly detection approach. We provide a theoretical analysis to demonstrate that the incorporation of the deterministic contrastive loss can effectively prevent the occurrence of a constant encoder solution. Experimental results show superior performance of our model over various baselines and model variants on real-world industrial datasets.
Modelling Patient Trajectories Using Multimodal Information
Sep 09, 2022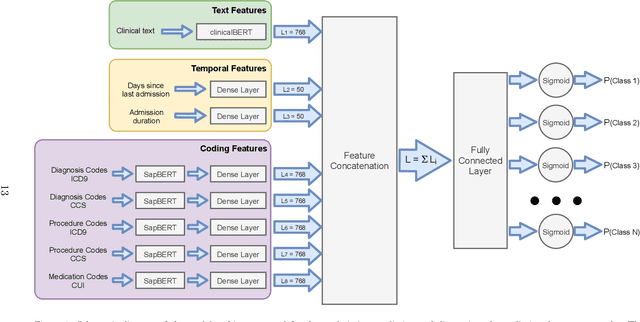
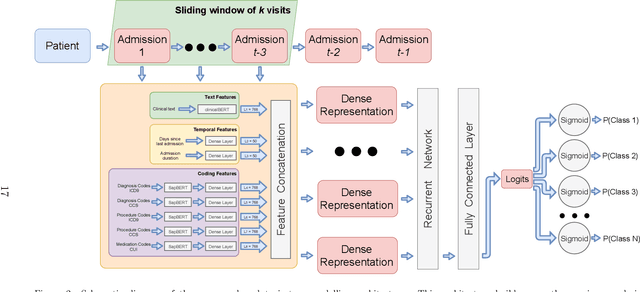

Electronic Health Records (EHRs) aggregate diverse information at the patient level, holding a trajectory representative of the evolution of the patient health status throughout time. Although this information provides context and can be leveraged by physicians to monitor patient health and make more accurate prognoses/diagnoses, patient records can contain information from very long time spans, which combined with the rapid generation rate of medical data makes clinical decision making more complex. Patient trajectory modelling can assist by exploring existing information in a scalable manner, and can contribute in augmenting health care quality by fostering preventive medicine practices. We propose a solution to model patient trajectories that combines different types of information and considers the temporal aspect of clinical data. This solution leverages two different architectures: one supporting flexible sets of input features, to convert patient admissions into dense representations; and a second exploring extracted admission representations in a recurrent-based architecture, where patient trajectories are processed in sub-sequences using a sliding window mechanism. The developed solution was evaluated on two different clinical outcomes, unexpected patient readmission and disease progression, using the publicly available MIMIC-III clinical database. The results obtained demonstrate the potential of the first architecture to model readmission and diagnoses prediction using single patient admissions. While information from clinical text did not show the discriminative power observed in other existing works, this may be explained by the need to fine-tune the clinicalBERT model. Finally, we demonstrate the potential of the sequence-based architecture using a sliding window mechanism to represent the input data, attaining comparable performances to other existing solutions.
Evidence-aware multi-modal data fusion and its application to total knee replacement prediction
Mar 24, 2023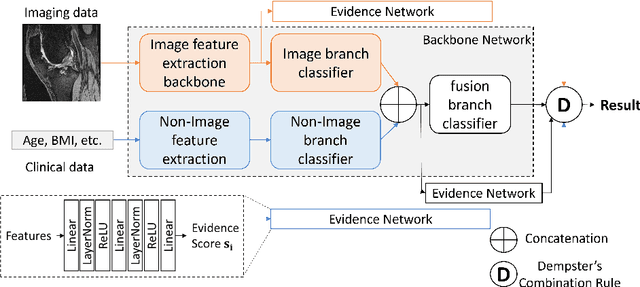
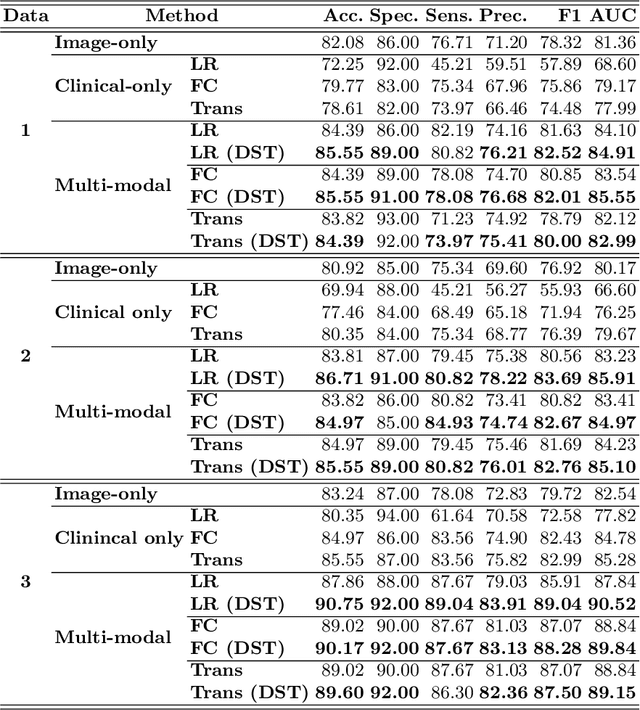

Deep neural networks have been widely studied for predicting a medical condition, such as total knee replacement (TKR). It has shown that data of different modalities, such as imaging data, clinical variables and demographic information, provide complementary information and thus can improve the prediction accuracy together. However, the data sources of various modalities may not always be of high quality, and each modality may have only partial information of medical condition. Thus, predictions from different modalities can be opposite, and the final prediction may fail in the presence of such a conflict. Therefore, it is important to consider the reliability of each source data and the prediction output when making a final decision. In this paper, we propose an evidence-aware multi-modal data fusion framework based on the Dempster-Shafer theory (DST). The backbone models contain an image branch, a non-image branch and a fusion branch. For each branch, there is an evidence network that takes the extracted features as input and outputs an evidence score, which is designed to represent the reliability of the output from the current branch. The output probabilities along with the evidence scores from multiple branches are combined with the Dempster's combination rule to make a final prediction. Experimental results on the public OA initiative (OAI) dataset for the TKR prediction task show the superiority of the proposed fusion strategy on various backbone models.
LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
Mar 30, 2023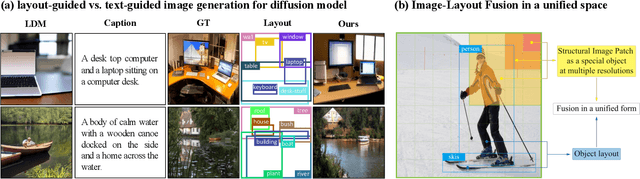
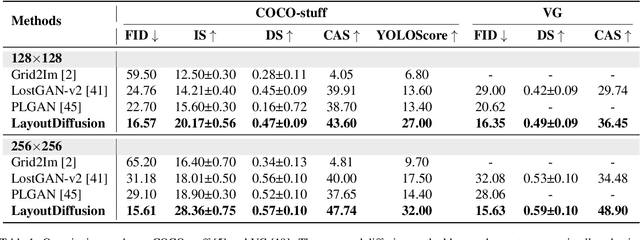
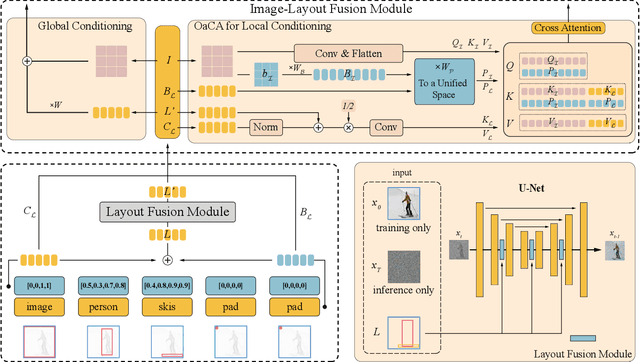

Recently, diffusion models have achieved great success in image synthesis. However, when it comes to the layout-to-image generation where an image often has a complex scene of multiple objects, how to make strong control over both the global layout map and each detailed object remains a challenging task. In this paper, we propose a diffusion model named LayoutDiffusion that can obtain higher generation quality and greater controllability than the previous works. To overcome the difficult multimodal fusion of image and layout, we propose to construct a structural image patch with region information and transform the patched image into a special layout to fuse with the normal layout in a unified form. Moreover, Layout Fusion Module (LFM) and Object-aware Cross Attention (OaCA) are proposed to model the relationship among multiple objects and designed to be object-aware and position-sensitive, allowing for precisely controlling the spatial related information. Extensive experiments show that our LayoutDiffusion outperforms the previous SOTA methods on FID, CAS by relatively 46.35%, 26.70% on COCO-stuff and 44.29%, 41.82% on VG. Code is available at https://github.com/ZGCTroy/LayoutDiffusion.
Event-based Agile Object Catching with a Quadrupedal Robot
Mar 30, 2023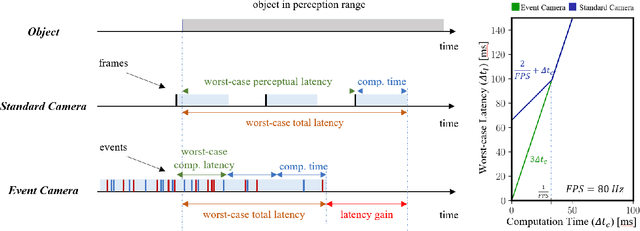
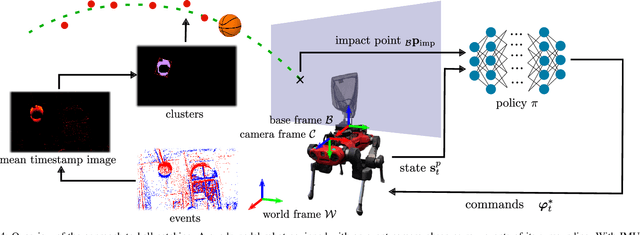


Quadrupedal robots are conquering various indoor and outdoor applications due to their ability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource-constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In leveraging the low latency of the events, we push the limits of quadruped agility and demonstrate high-speed ball catching for the first time. We show that our quadruped equipped with an event camera can catch objects with speeds up to 15 m/s from 4 meters, with a success rate of 83%. Using a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
RoboBEV: Towards Robust Bird's Eye View Perception under Corruptions
Apr 13, 2023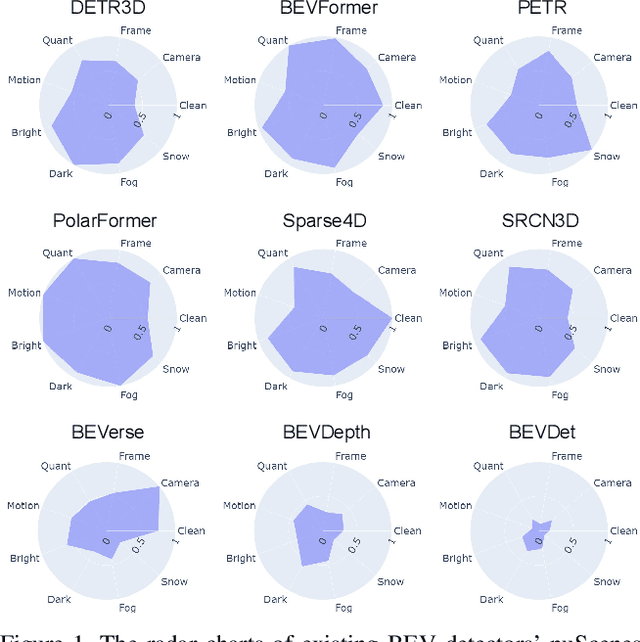
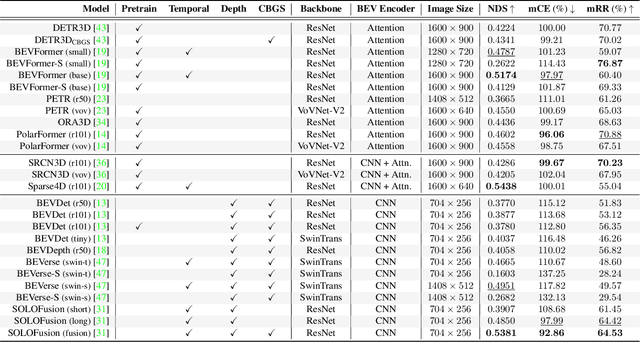

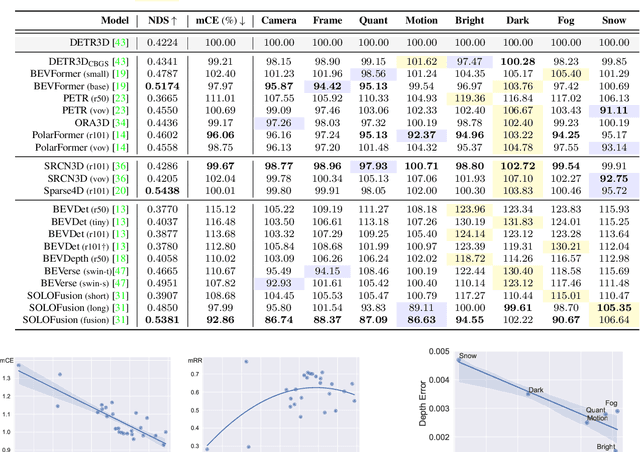
The recent advances in camera-based bird's eye view (BEV) representation exhibit great potential for in-vehicle 3D perception. Despite the substantial progress achieved on standard benchmarks, the robustness of BEV algorithms has not been thoroughly examined, which is critical for safe operations. To bridge this gap, we introduce RoboBEV, a comprehensive benchmark suite that encompasses eight distinct corruptions, including Bright, Dark, Fog, Snow, Motion Blur, Color Quant, Camera Crash, and Frame Lost. Based on it, we undertake extensive evaluations across a wide range of BEV-based models to understand their resilience and reliability. Our findings indicate a strong correlation between absolute performance on in-distribution and out-of-distribution datasets. Nonetheless, there are considerable variations in relative performance across different approaches. Our experiments further demonstrate that pre-training and depth-free BEV transformation has the potential to enhance out-of-distribution robustness. Additionally, utilizing long and rich temporal information largely helps with robustness. Our findings provide valuable insights for designing future BEV models that can achieve both accuracy and robustness in real-world deployments.
Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions
Apr 13, 2023
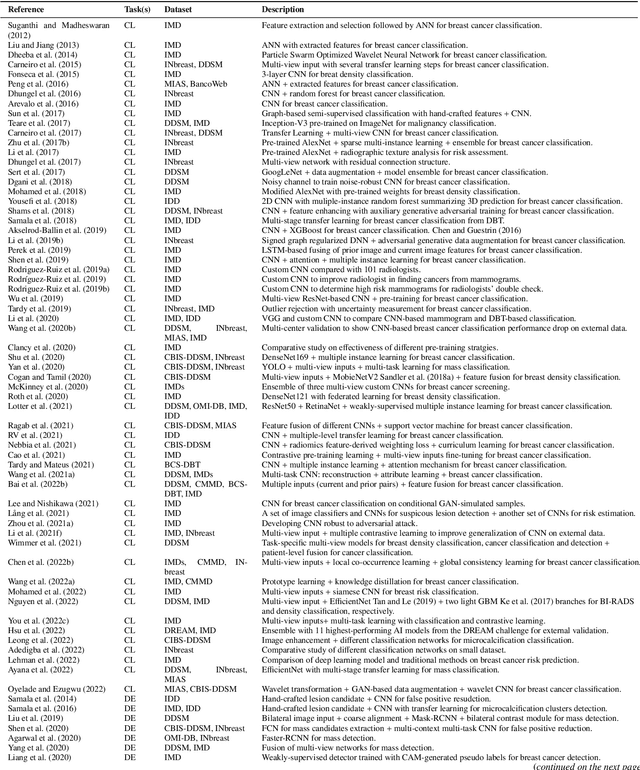
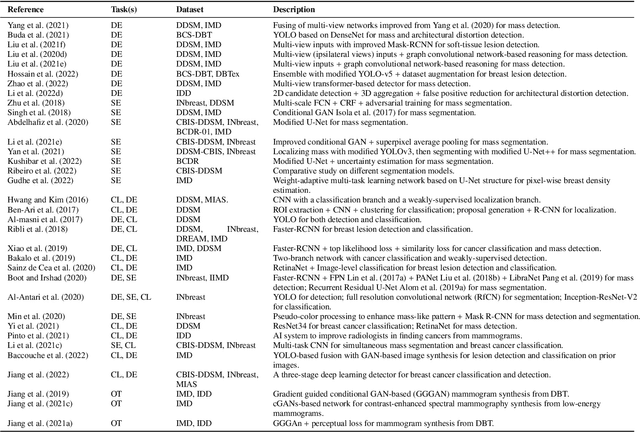
Breast cancer has reached the highest incidence rate worldwide among all malignancies since 2020. Breast imaging plays a significant role in early diagnosis and intervention to improve the outcome of breast cancer patients. In the past decade, deep learning has shown remarkable progress in breast cancer imaging analysis, holding great promise in interpreting the rich information and complex context of breast imaging modalities. Considering the rapid improvement in the deep learning technology and the increasing severity of breast cancer, it is critical to summarize past progress and identify future challenges to be addressed. In this paper, we provide an extensive survey of deep learning-based breast cancer imaging research, covering studies on mammogram, ultrasound, magnetic resonance imaging, and digital pathology images over the past decade. The major deep learning methods, publicly available datasets, and applications on imaging-based screening, diagnosis, treatment response prediction, and prognosis are described in detail. Drawn from the findings of this survey, we present a comprehensive discussion of the challenges and potential avenues for future research in deep learning-based breast cancer imaging.
Priors for symbolic regression
Apr 13, 2023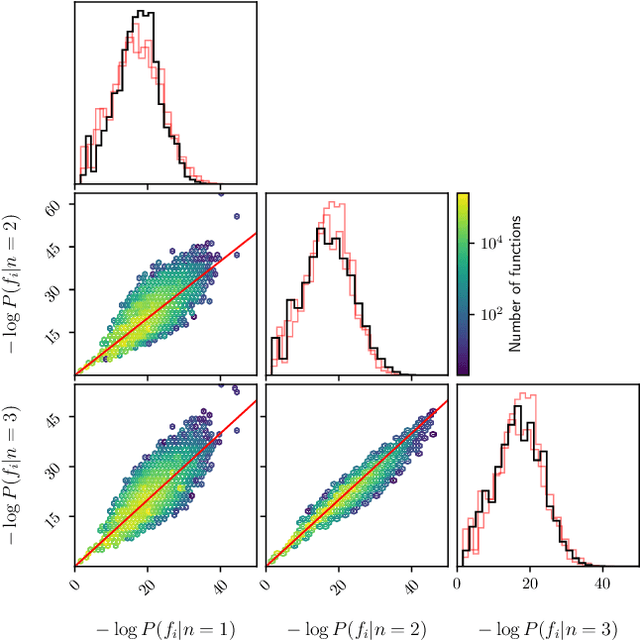
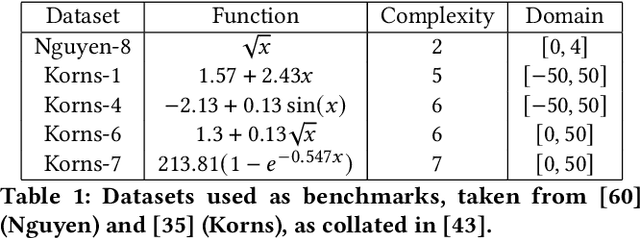
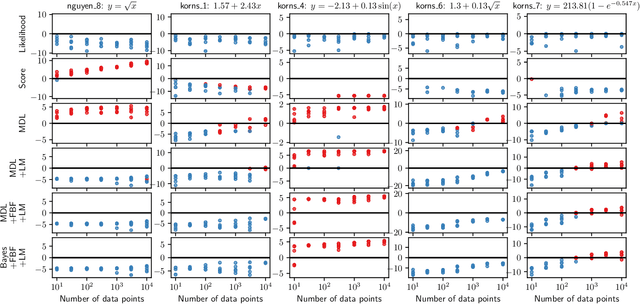
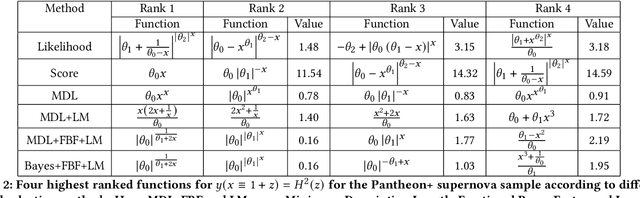
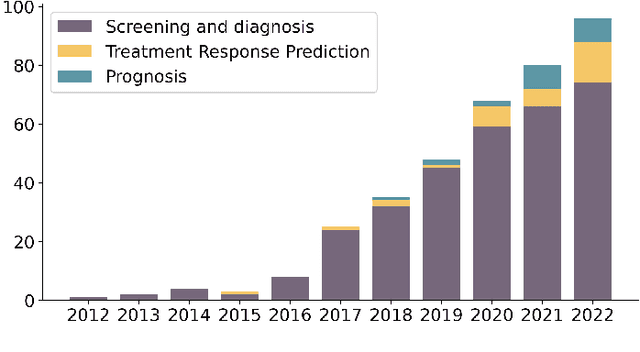
When choosing between competing symbolic models for a data set, a human will naturally prefer the "simpler" expression or the one which more closely resembles equations previously seen in a similar context. This suggests a non-uniform prior on functions, which is, however, rarely considered within a symbolic regression (SR) framework. In this paper we develop methods to incorporate detailed prior information on both functions and their parameters into SR. Our prior on the structure of a function is based on a $n$-gram language model, which is sensitive to the arrangement of operators relative to one another in addition to the frequency of occurrence of each operator. We also develop a formalism based on the Fractional Bayes Factor to treat numerical parameter priors in such a way that models may be fairly compared though the Bayesian evidence, and explicitly compare Bayesian, Minimum Description Length and heuristic methods for model selection. We demonstrate the performance of our priors relative to literature standards on benchmarks and a real-world dataset from the field of cosmology.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022

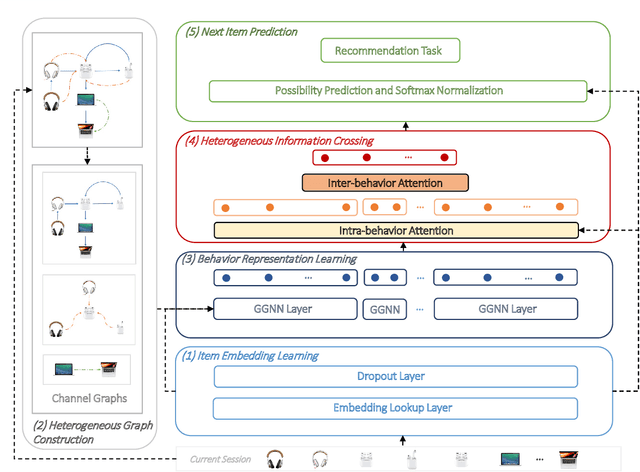
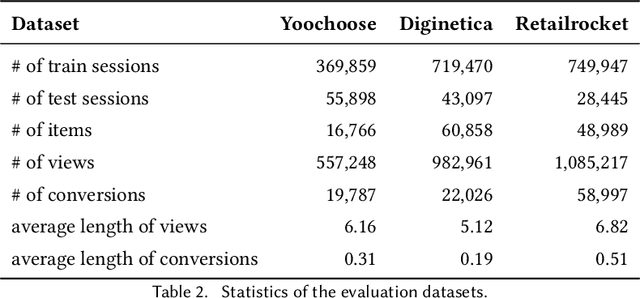
Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.