 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Event-based Agile Object Catching with a Quadrupedal Robot
Apr 06, 2023
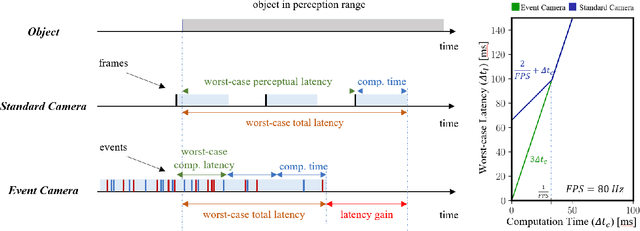
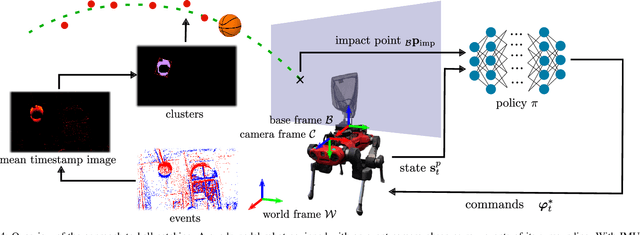


Quadrupedal robots are conquering various indoor and outdoor applications due to their ability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource-constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In leveraging the low latency of the events, we push the limits of quadruped agility and demonstrate high-speed ball catching for the first time. We show that our quadruped equipped with an event camera can catch objects with speeds up to 15 m/s from 4 meters, with a success rate of 83%. Using a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
Expert-Independent Generalization of Well and Seismic Data Using Machine Learning Methods for Complex Reservoirs Predicting During Early-Stage Geological Exploration
Apr 06, 2023

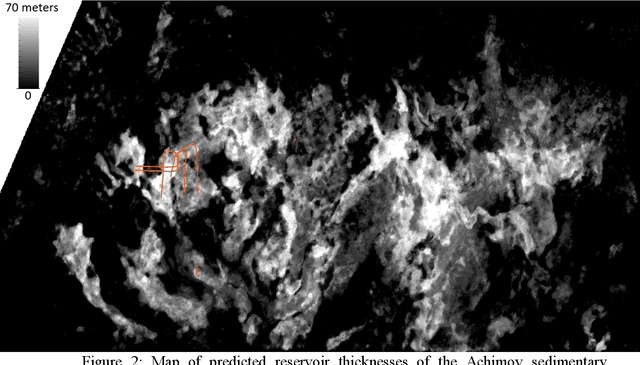
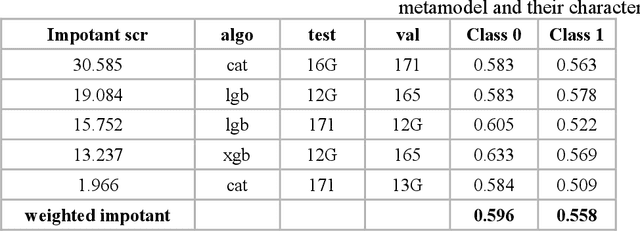
The aim of this study is to develop and apply an autonomous approach for predicting the probability of hydrocarbon reservoirs spreading in the studied area. Autonomy means that after preparing and inputting geological-geophysical information, the influence of an expert on the algorithms is minimized. The study was made based on the 3D seismic survey data and well information on the early exploration stage of the studied field. As a result, a forecast of the probability of spatial distribution of reservoirs was made for two sets of input data: the base set and the set after reverse-calibration, and three-dimensional cubes of calibrated probabilities of belonging of the studied space to the identified classes were obtained. The approach presented in the paper allows for expert-independent generalization of geological and geophysical data, and to use this generalization for hypothesis testing and creating geological models based on a probabilistic representation of the reservoir. The quality of the probabilistic representation depends on the quality and quantity of the input data. Depending on the input data, the approach can be a useful tool for exploration and prospecting of geological objects, identifying potential resources, optimizing and designing field development.
Implementation of a Sustainable Security Architecture using Radio Frequency Identification (RFID) Technology for Access Control
Apr 10, 2023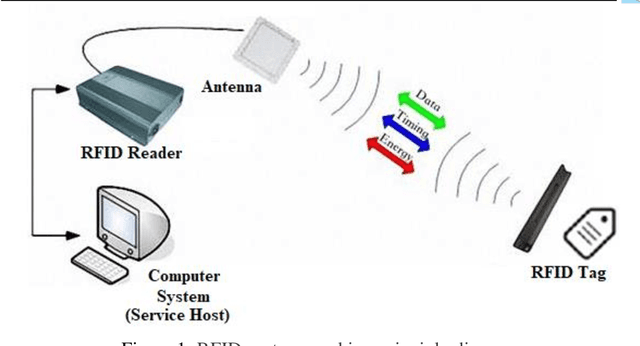
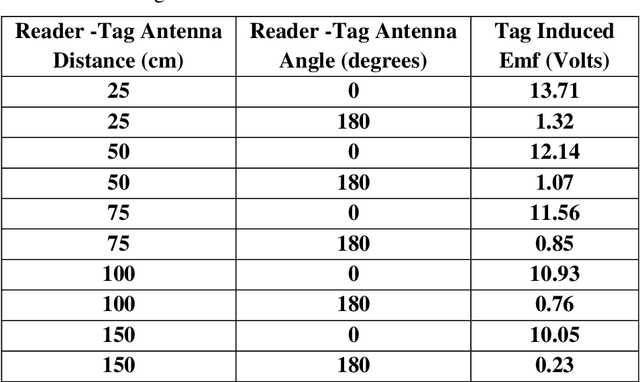
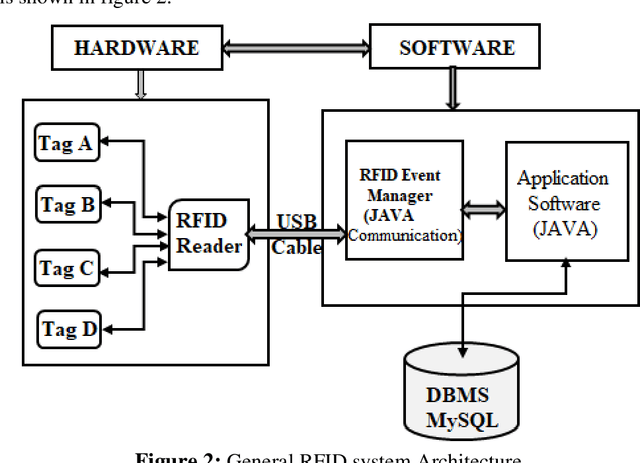
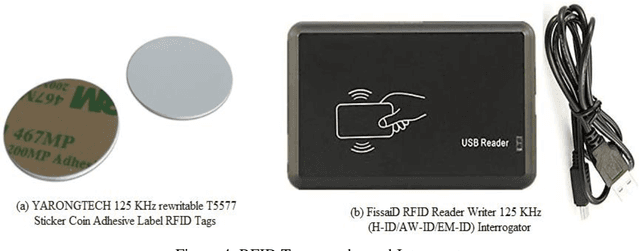
Implementation of a sustainable security architecture has been quite a challenging task with several technology deployed to achieve the feat. Automatic IDentification (Auto-ID) procedures exist to provide information about people, animals, goods and products in transit and found several applications in purchasing and distribution logistics, industries, manufacturing companies and material flow systems. This work focuses on the development and implementation of an access control system using Radio Frequency Identification (RFID) technology to enhance a sustainable security architecture. The system controls access into a restricted area by granting access only to authorized persons, which incorporates the RFID hardware (RFID tags and readers and their antennas) and the software. The antenna are to be configured for a read range of about 1.5 m and TMBE kit reader module was used to test the RFID tags. The encoding and decoding process for the reading and writing to the tag as well as interfacing of the hardware and software was achieved through the use of a FissaiD RFID Reader Writer. The software that controls the whole system was designed using in Java Language. The database required for saving the necessary information, staff/guest was designed using appropriate DataBase Management System (DBMS). The system designed and implemented provide records of all accesses (check-in and check-out) made into the restricted area with time records. Other than this system, Model based modeling through the MATLAB/Simulink, Arduino platform, etc. can be used for similar implementation.
Multi-crop Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 24, 2023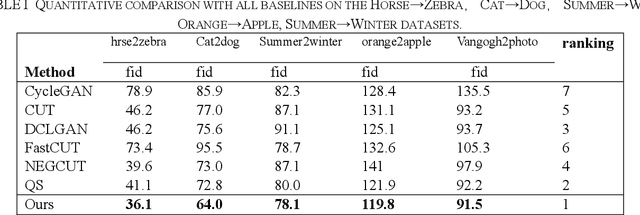
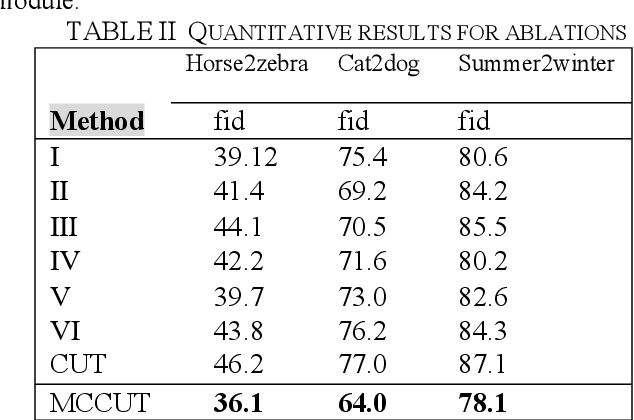
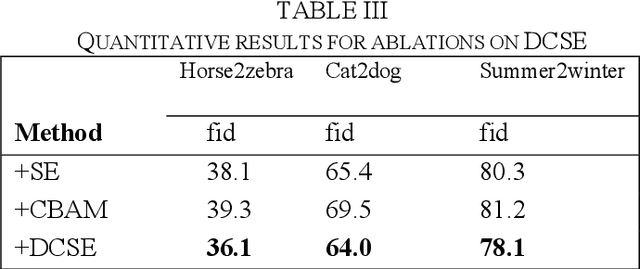
Recently, image-to-image translation methods based on contrastive learning achieved state-of-the-art results in many tasks. However, the negatives are sampled from the input feature spaces in the previous work, which makes the negatives lack diversity. Moreover, in the latent space of the embedings,the previous methods ignore domain consistency between the generated image and the real images of target domain. In this paper, we propose a novel contrastive learning framework for unpaired image-to-image translation, called MCCUT. We utilize the multi-crop views to generate the negatives via the center-crop and the random-crop, which can improve the diversity of negatives and meanwhile increase the quality of negatives. To constrain the embedings in the deep feature space,, we formulate a new domain consistency loss function, which encourages the generated images to be close to the real images in the embedding space of same domain. Furthermore, we present a dual coordinate channel attention network by embedding positional information into SENet, which called DCSE module. We employ the DCSE module in the design of generator, which makes the generator pays more attention to channels with greater weight. In many image-to-image translation tasks, our method achieves state-of-the-art results, and the advantages of our method have been proved through extensive comparison experiments and ablation research.
Immunohistochemistry Biomarkers-Guided Image Search for Histopathology
Apr 24, 2023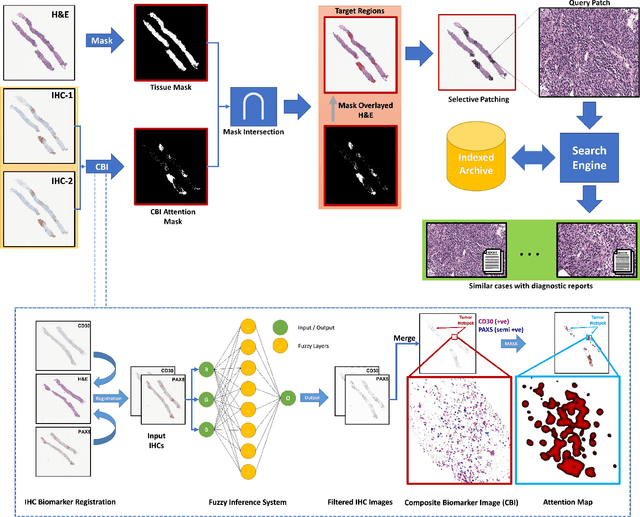
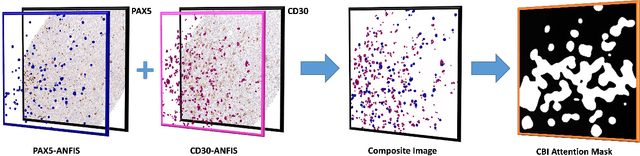
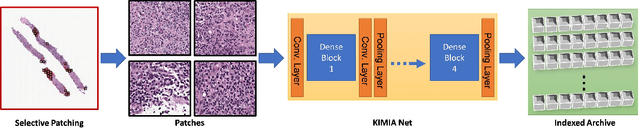
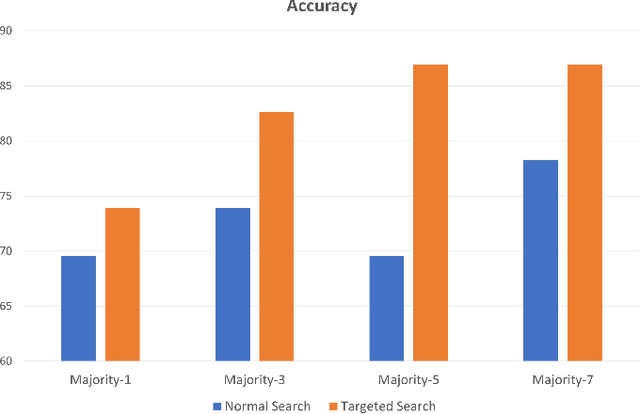
Medical practitioners use a number of diagnostic tests to make a reliable diagnosis. Traditionally, Haematoxylin and Eosin (H&E) stained glass slides have been used for cancer diagnosis and tumor detection. However, recently a variety of immunohistochemistry (IHC) stained slides can be requested by pathologists to examine and confirm diagnoses for determining the subtype of a tumor when this is difficult using H&E slides only. Deep learning (DL) has received a lot of interest recently for image search engines to extract features from tissue regions, which may or may not be the target region for diagnosis. This approach generally fails to capture high-level patterns corresponding to the malignant or abnormal content of histopathology images. In this work, we are proposing a targeted image search approach, inspired by the pathologists workflow, which may use information from multiple IHC biomarker images when available. These IHC images could be aligned, filtered, and merged together to generate a composite biomarker image (CBI) that could eventually be used to generate an attention map to guide the search engine for localized search. In our experiments, we observed that an IHC-guided image search engine can retrieve relevant data more accurately than a conventional (i.e., H&E-only) search engine without IHC guidance. Moreover, such engines are also able to accurately conclude the subtypes through majority votes.
A novel Multi to Single Module for small object detection
Mar 27, 2023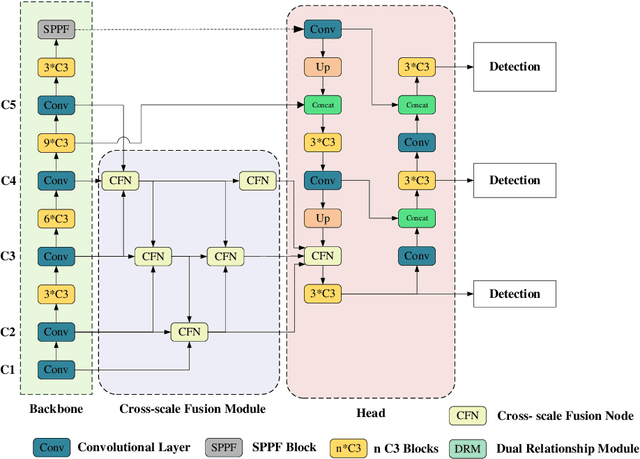
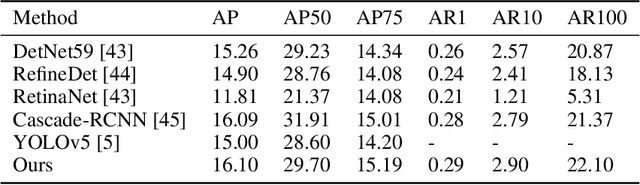
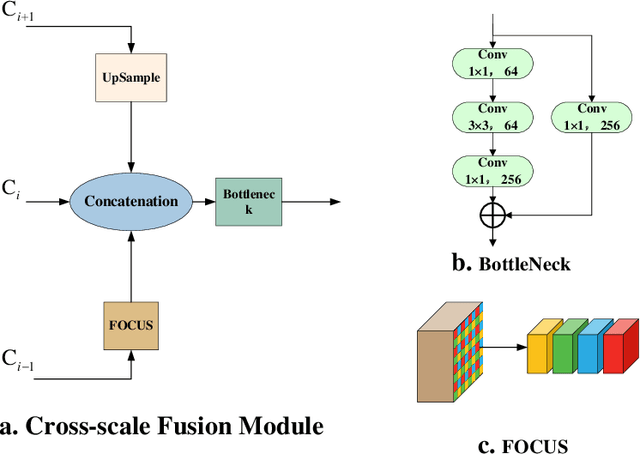
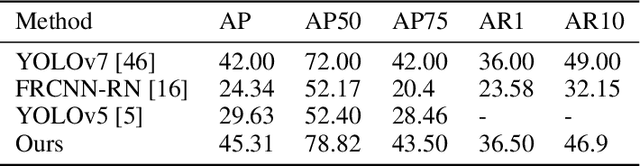
Small object detection presents a significant challenge in computer vision and object detection. The performance of small object detectors is often compromised by a lack of pixels and less significant features. This issue stems from information misalignment caused by variations in feature scale and information loss during feature processing. In response to this challenge, this paper proposes a novel the Multi to Single Module (M2S), which enhances a specific layer through improving feature extraction and refining features. Specifically, M2S includes the proposed Cross-scale Aggregation Module (CAM) and explored Dual Relationship Module (DRM) to improve information extraction capabilities and feature refinement effects. Moreover, this paper enhances the accuracy of small object detection by utilizing M2S to generate an additional detection head. The effectiveness of the proposed method is evaluated on two datasets, VisDrone2021-DET and SeaDronesSeeV2. The experimental results demonstrate its improved performance compared with existing methods. Compared to the baseline model (YOLOv5s), M2S improves the accuracy by about 1.1\% on the VisDrone2021-DET testing dataset and 15.68\% on the SeaDronesSeeV2 validation set.
Towards Making the Most of ChatGPT for Machine Translation
Mar 24, 2023
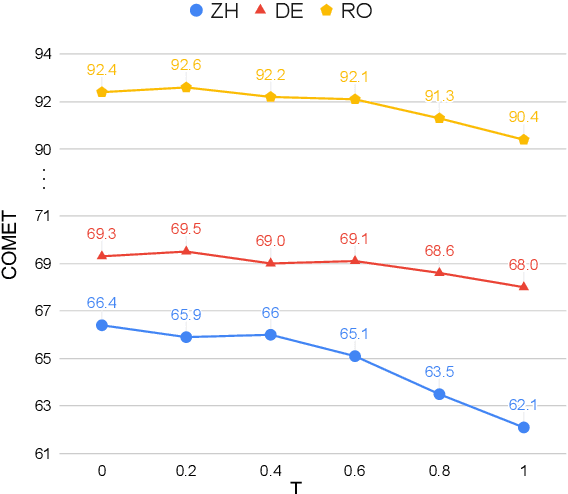
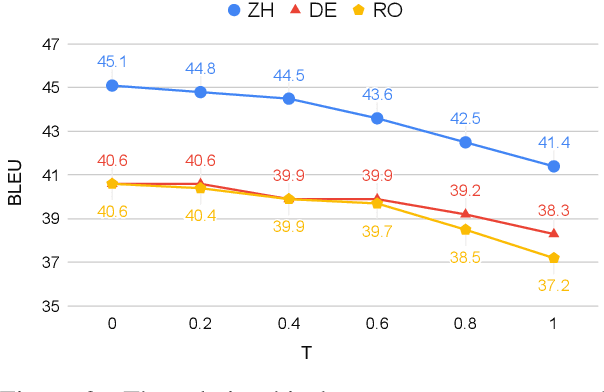

ChatGPT shows remarkable capabilities for machine translation (MT). Several prior studies have shown that it achieves comparable results to commercial systems for high-resource languages, but lags behind in complex tasks, e.g, low-resource and distant-language-pairs translation. However, they usually adopt simple prompts which can not fully elicit the capability of ChatGPT. In this report, we aim to further mine ChatGPT's translation ability by revisiting several aspects: temperature, task information, and domain information, and correspondingly propose two (simple but effective) prompts: Task-Specific Prompts (TSP) and Domain-Specific Prompts (DSP). We show that: 1) The performance of ChatGPT depends largely on temperature, and a lower temperature usually can achieve better performance; 2) Emphasizing the task information further improves ChatGPT's performance, particularly in complex MT tasks; 3) Introducing domain information can elicit ChatGPT's generalization ability and improve its performance in the specific domain; 4) ChatGPT tends to generate hallucinations for non-English-centric MT tasks, which can be partially addressed by our proposed prompts but still need to be highlighted for the MT/NLP community. We also explore the effects of advanced in-context learning strategies and find a (negative but interesting) observation: the powerful chain-of-thought prompt leads to word-by-word translation behavior, thus bringing significant translation degradation.
PFT-SSR: Parallax Fusion Transformer for Stereo Image Super-Resolution
Mar 24, 2023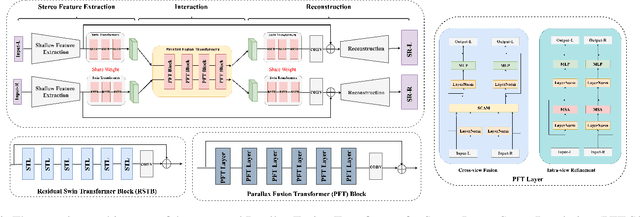
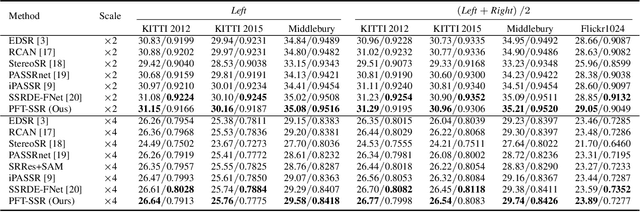

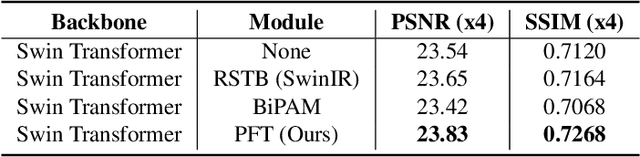
Stereo image super-resolution aims to boost the performance of image super-resolution by exploiting the supplementary information provided by binocular systems. Although previous methods have achieved promising results, they did not fully utilize the information of cross-view and intra-view. To further unleash the potential of binocular images, in this letter, we propose a novel Transformerbased parallax fusion module called Parallax Fusion Transformer (PFT). PFT employs a Cross-view Fusion Transformer (CVFT) to utilize cross-view information and an Intra-view Refinement Transformer (IVRT) for intra-view feature refinement. Meanwhile, we adopted the Swin Transformer as the backbone for feature extraction and SR reconstruction to form a pure Transformer architecture called PFT-SSR. Extensive experiments and ablation studies show that PFT-SSR achieves competitive results and outperforms most SOTA methods. Source code is available at https://github.com/MIVRC/PFT-PyTorch.
* 5 pages, 3 figures
An Electromagnetic-Information-Theory Based Model for Efficient Characterization of MIMO Systems in Complex Space
Jan 13, 2023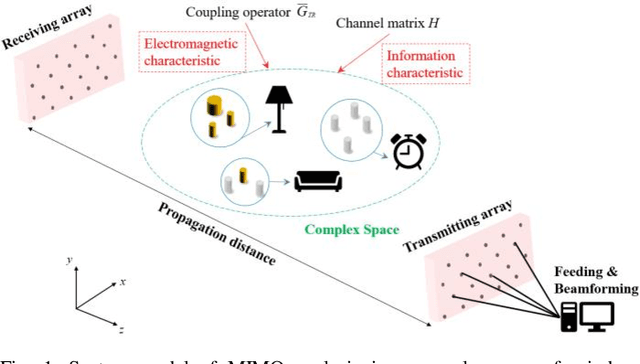
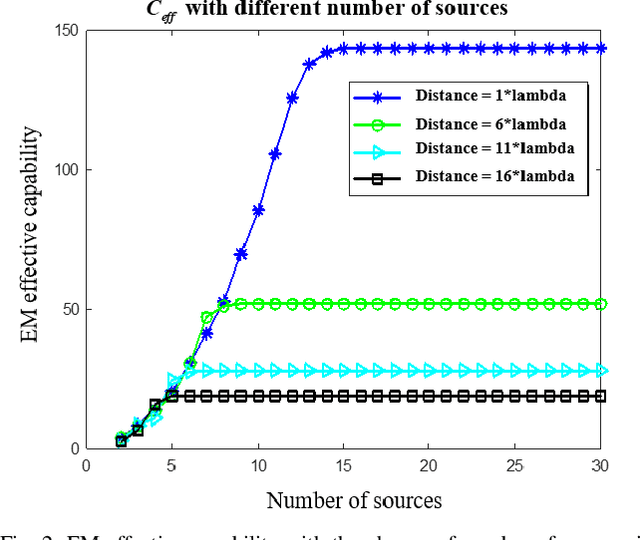
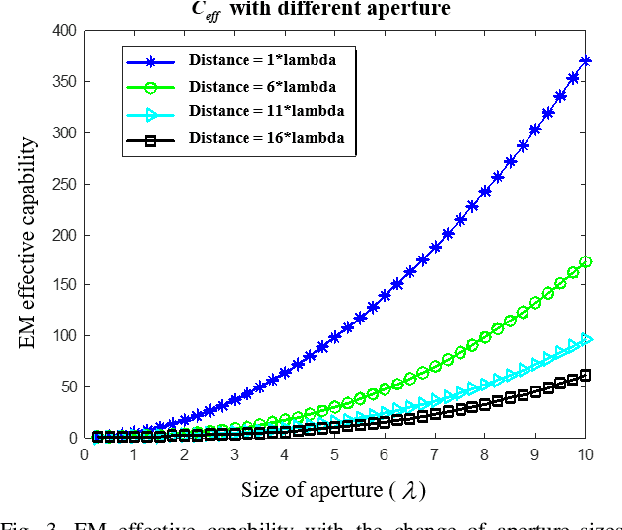
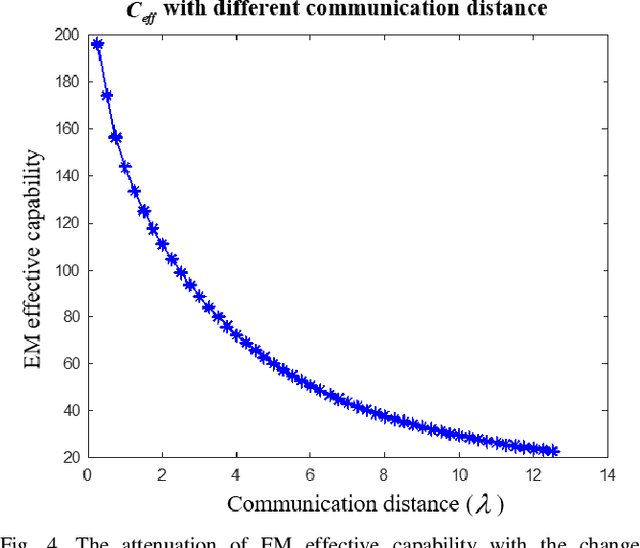
It is the pursuit of a multiple-input-multiple-output (MIMO) system to approach and even break the limit of channel capacity. However, it is always a big challenge to efficiently characterize the MIMO systems in complex space and get better propagation performance than the conventional MIMO systems considering only free space, which is important for guiding the power and phase allocation of antenna units. In this manuscript, an Electromagnetic-Information-Theory (EMIT) based model is developed for efficient characterization of MIMO systems in complex space. The group-T-matrix-based multiple scattering fast algorithm, the mode-decomposition-based characterization method, and their joint theoretical framework in complex space are discussed. Firstly, key informatics parameters in free electromagnetic space based on a dyadic Green's function are derived. Next, a novel group-T-matrix-based multiple scattering fast algorithm is developed to describe a representative inhomogeneous electromagnetic space. All the analytical results are validated by simulations. In addition, the complete form of the EMIT-based model is proposed to derive the informatics parameters frequently used in electromagnetic propagation, through integrating the mode analysis method with the dyadic Green's function matrix. Finally, as a proof-or-concept, microwave anechoic chamber measurements of a cylindrical array is performed, demonstrating the effectiveness of the EMIT-based model. Meanwhile, a case of image transmission with limited power is presented to illustrate how to use this EMIT-based model to guide the power and phase allocation of antenna units for real MIMO applications.
* 13 pages, 14 figures
Differential Privacy via Distributionally Robust Optimization
Apr 25, 2023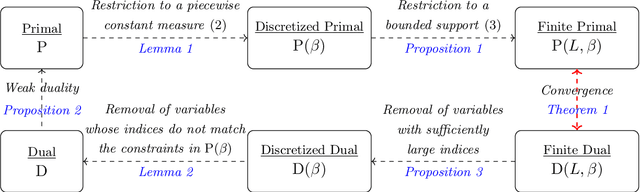
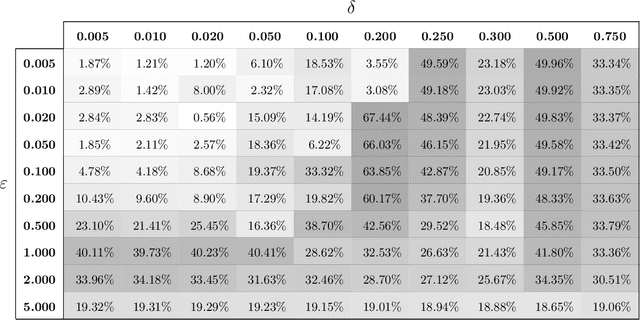
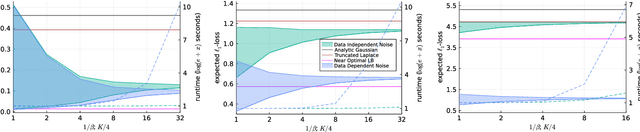
In recent years, differential privacy has emerged as the de facto standard for sharing statistics of datasets while limiting the disclosure of private information about the involved individuals. This is achieved by randomly perturbing the statistics to be published, which in turn leads to a privacy-accuracy trade-off: larger perturbations provide stronger privacy guarantees, but they result in less accurate statistics that offer lower utility to the recipients. Of particular interest are therefore optimal mechanisms that provide the highest accuracy for a pre-selected level of privacy. To date, work in this area has focused on specifying families of perturbations a priori and subsequently proving their asymptotic and/or best-in-class optimality. In this paper, we develop a class of mechanisms that enjoy non-asymptotic and unconditional optimality guarantees. To this end, we formulate the mechanism design problem as an infinite-dimensional distributionally robust optimization problem. We show that the problem affords a strong dual, and we exploit this duality to develop converging hierarchies of finite-dimensional upper and lower bounding problems. Our upper (primal) bounds correspond to implementable perturbations whose suboptimality can be bounded by our lower (dual) bounds. Both bounding problems can be solved within seconds via cutting plane techniques that exploit the inherent problem structure. Our numerical experiments demonstrate that our perturbations can outperform the previously best results from the literature on artificial as well as standard benchmark problems.