 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RADIFUSION: A multi-radiomics deep learning based breast cancer risk prediction model using sequential mammographic images with image attention and bilateral asymmetry refinement
Apr 01, 2023
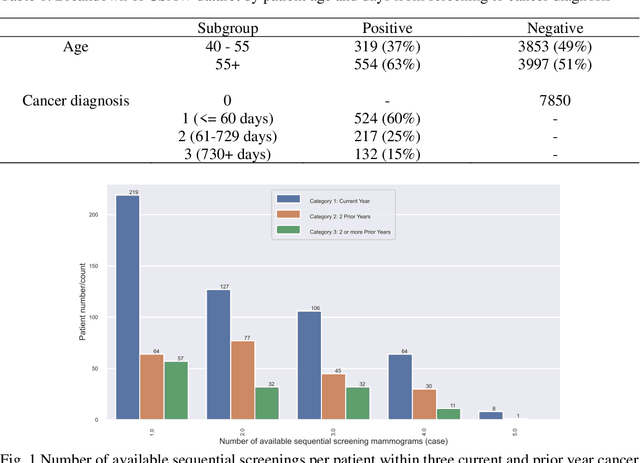
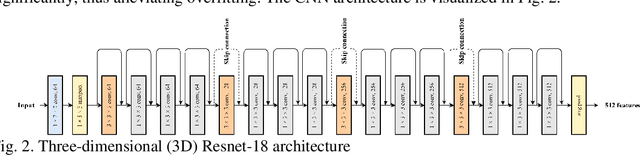
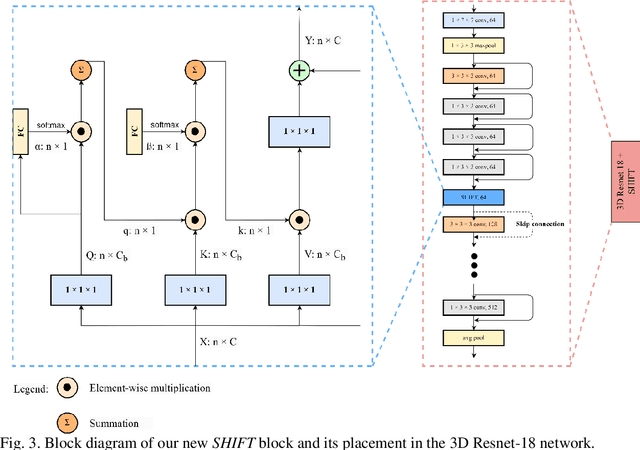

Breast cancer is a significant public health concern and early detection is critical for triaging high risk patients. Sequential screening mammograms can provide important spatiotemporal information about changes in breast tissue over time. In this study, we propose a deep learning architecture called RADIFUSION that utilizes sequential mammograms and incorporates a linear image attention mechanism, radiomic features, a new gating mechanism to combine different mammographic views, and bilateral asymmetry-based finetuning for breast cancer risk assessment. We evaluate our model on a screening dataset called Cohort of Screen-Aged Women (CSAW) dataset. Based on results obtained on the independent testing set consisting of 1,749 women, our approach achieved superior performance compared to other state-of-the-art models with area under the receiver operating characteristic curves (AUCs) of 0.905, 0.872 and 0.866 in the three respective metrics of 1-year AUC, 2-year AUC and > 2-year AUC. Our study highlights the importance of incorporating various deep learning mechanisms, such as image attention, radiomic features, gating mechanism, and bilateral asymmetry-based fine-tuning, to improve the accuracy of breast cancer risk assessment. We also demonstrate that our model's performance was enhanced by leveraging spatiotemporal information from sequential mammograms. Our findings suggest that RADIFUSION can provide clinicians with a powerful tool for breast cancer risk assessment.
Inverting the Fundamental Diagram and Forecasting Boundary Conditions: How Machine Learning Can Improve Macroscopic Models for Traffic Flow
Mar 21, 2023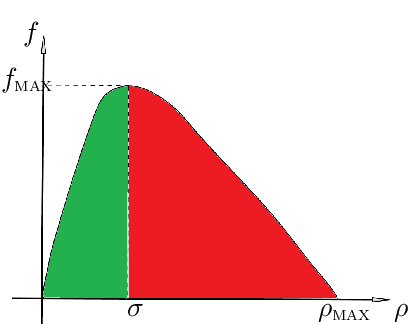
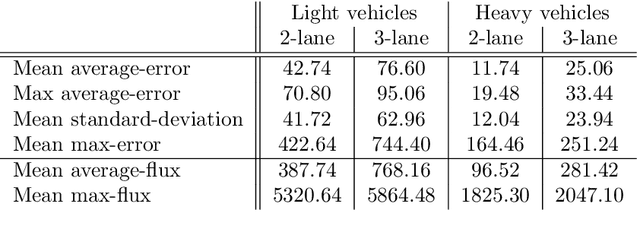
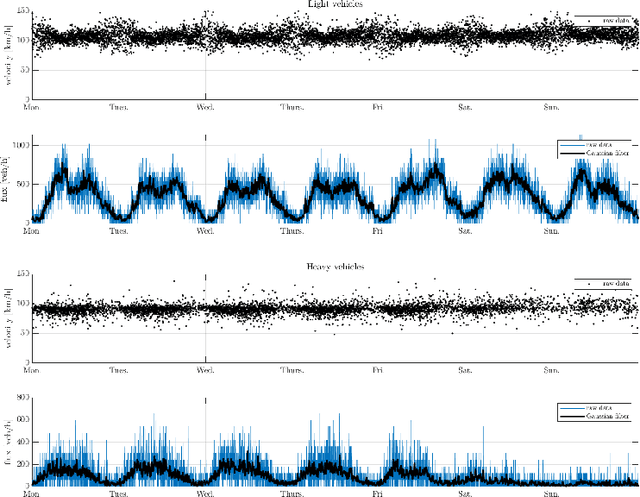
In this paper, we aim at developing new methods to join machine learning techniques and macroscopic differential models for vehicular traffic estimation and forecast. It is well known that data-driven and model-driven approaches have (sometimes complementary) advantages and drawbacks. We consider here a dataset with flux and velocity data of vehicles moving on a highway, collected by fixed sensors and classified by lane and by class of vehicle. By means of a machine learning model based on an LSTM recursive neural network, we extrapolate two important pieces of information: 1) if congestion is appearing under the sensor, and 2) the total amount of vehicles which is going to pass under the sensor in the next future (30 min). These pieces of information are then used to improve the accuracy of an LWR-based first-order multi-class model describing the dynamics of traffic flow between sensors. The first piece of information is used to invert the (concave) fundamental diagram, thus recovering the density of vehicles from the flux data, and then inject directly the density datum in the model. This allows one to better approximate the dynamics between sensors, especially if an accident happens in a not monitored stretch of the road. The second piece of information is used instead as boundary conditions for the equations underlying the traffic model, to better reconstruct the total amount of vehicles on the road at any future time. Some examples motivated by real scenarios will be discussed. Real data are provided by the Italian motorway company Autovie Venete S.p.A.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
Apr 21, 2023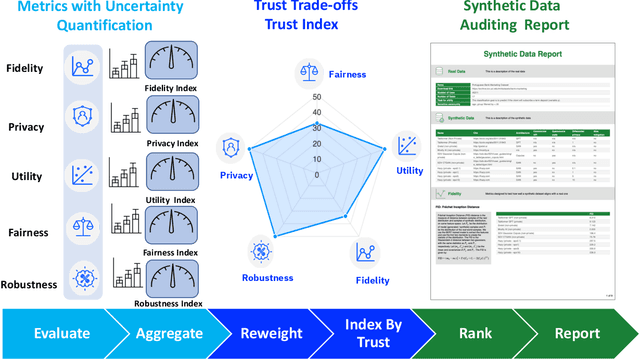
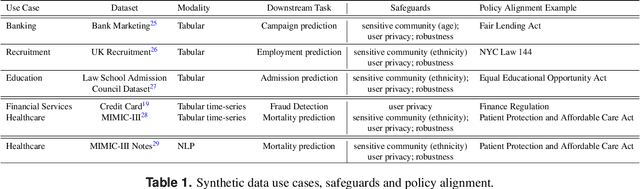
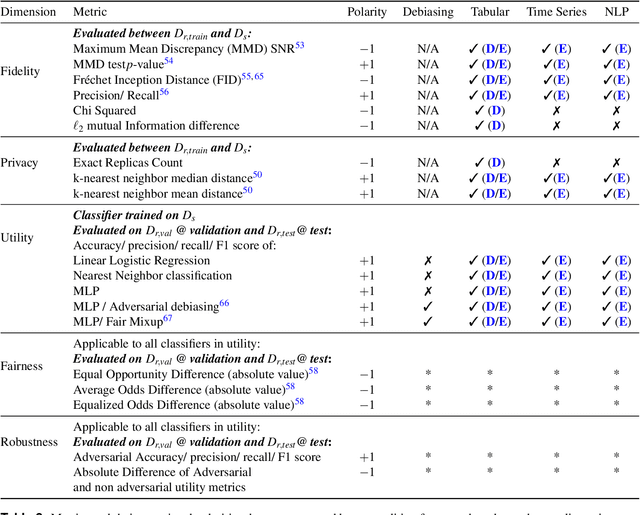
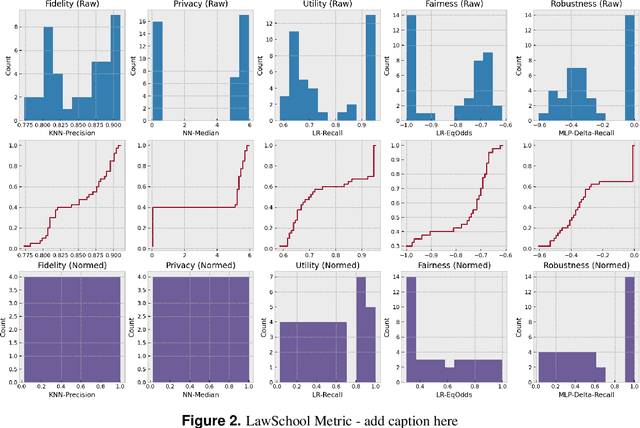
Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Deep Metric Learning Assisted by Intra-variance in A Semi-supervised View of Learning
Apr 21, 2023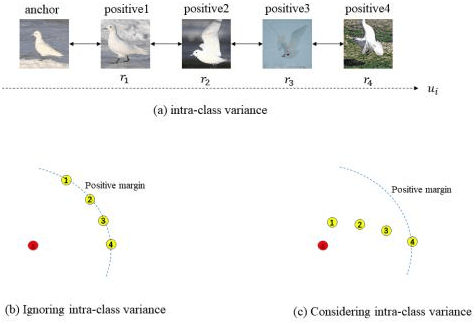
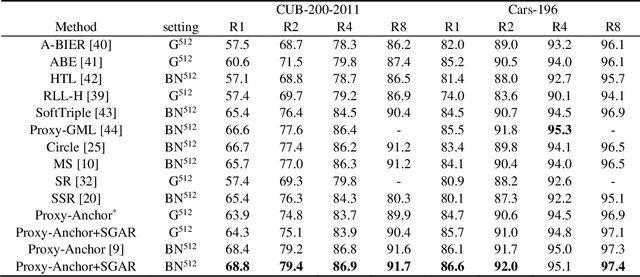
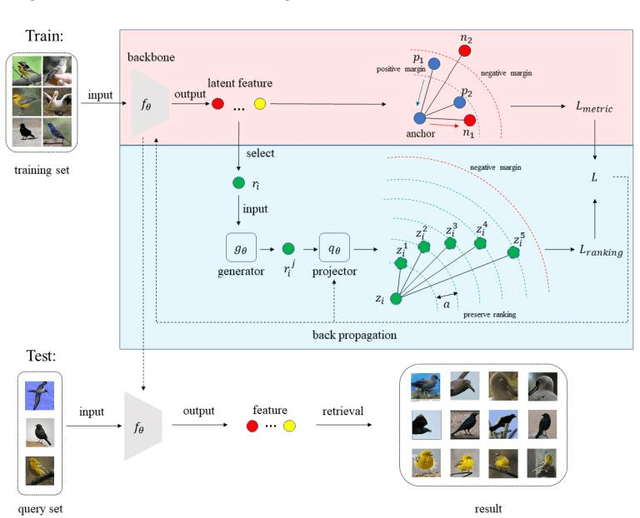
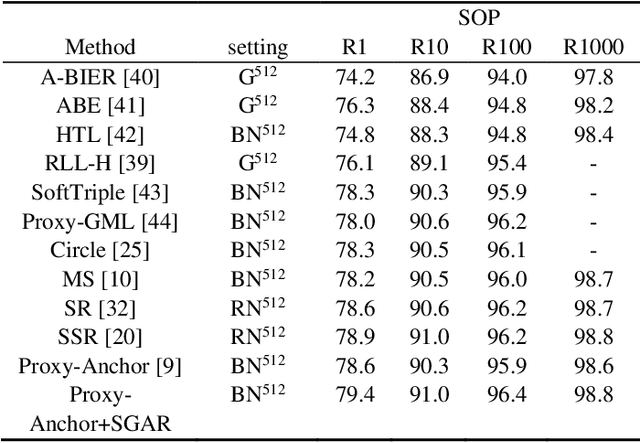
Deep metric learning aims to construct an embedding space where samples of the same class are close to each other, while samples of different classes are far away from each other. Most existing deep metric learning methods attempt to maximize the difference of inter-class features. And semantic related information is obtained by increasing the distance between samples of different classes in the embedding space. However, compressing all positive samples together while creating large margins between different classes unconsciously destroys the local structure between similar samples. Ignoring the intra-class variance contained in the local structure between similar samples, the embedding space obtained from training receives lower generalizability over unseen classes, which would lead to the network overfitting the training set and crashing on the test set. To address these considerations, this paper designs a self-supervised generative assisted ranking framework that provides a semi-supervised view of intra-class variance learning scheme for typical supervised deep metric learning. Specifically, this paper performs sample synthesis with different intensities and diversity for samples satisfying certain conditions to simulate the complex transformation of intra-class samples. And an intra-class ranking loss function is designed using the idea of self-supervised learning to constrain the network to maintain the intra-class distribution during the training process to capture the subtle intra-class variance. With this approach, a more realistic embedding space can be obtained in which global and local structures of samples are well preserved, thus enhancing the effectiveness of downstream tasks. Extensive experiments on four benchmarks have shown that this approach surpasses state-of-the-art methods
BERT Based Clinical Knowledge Extraction for Biomedical Knowledge Graph Construction and Analysis
Apr 21, 2023
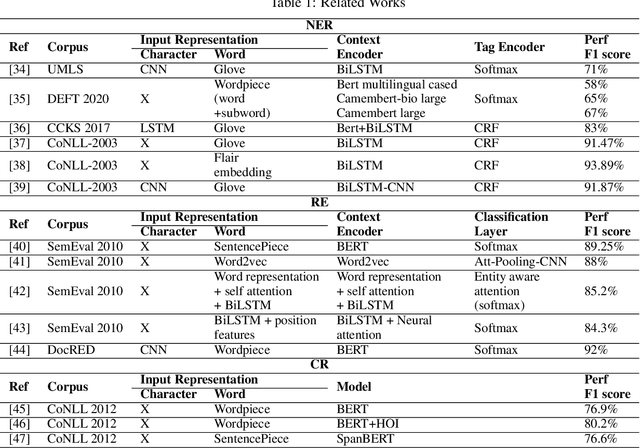
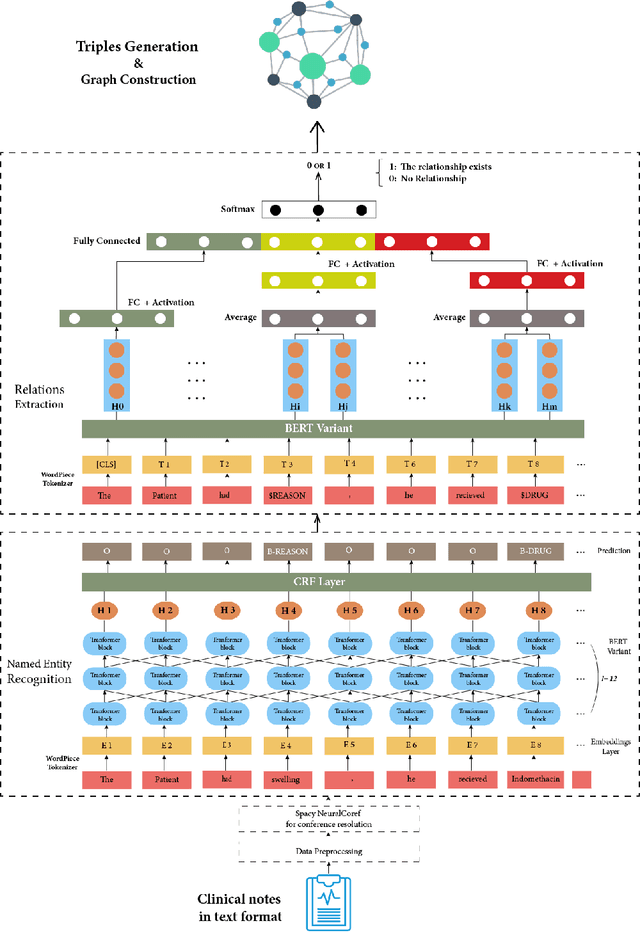
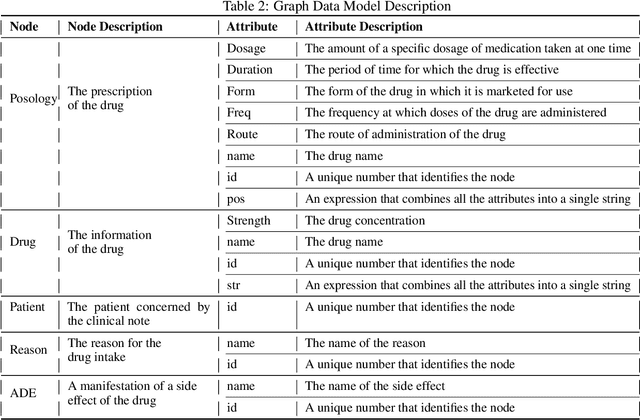
Background : Knowledge is evolving over time, often as a result of new discoveries or changes in the adopted methods of reasoning. Also, new facts or evidence may become available, leading to new understandings of complex phenomena. This is particularly true in the biomedical field, where scientists and physicians are constantly striving to find new methods of diagnosis, treatment and eventually cure. Knowledge Graphs (KGs) offer a real way of organizing and retrieving the massive and growing amount of biomedical knowledge. Objective : We propose an end-to-end approach for knowledge extraction and analysis from biomedical clinical notes using the Bidirectional Encoder Representations from Transformers (BERT) model and Conditional Random Field (CRF) layer. Methods : The approach is based on knowledge graphs, which can effectively process abstract biomedical concepts such as relationships and interactions between medical entities. Besides offering an intuitive way to visualize these concepts, KGs can solve more complex knowledge retrieval problems by simplifying them into simpler representations or by transforming the problems into representations from different perspectives. We created a biomedical Knowledge Graph using using Natural Language Processing models for named entity recognition and relation extraction. The generated biomedical knowledge graphs (KGs) are then used for question answering. Results : The proposed framework can successfully extract relevant structured information with high accuracy (90.7% for Named-entity recognition (NER), 88% for relation extraction (RE)), according to experimental findings based on real-world 505 patient biomedical unstructured clinical notes. Conclusions : In this paper, we propose a novel end-to-end system for the construction of a biomedical knowledge graph from clinical textual using a variation of BERT models.
Self-supervised Auxiliary Loss for Metric Learning in Music Similarity-based Retrieval and Auto-tagging
Apr 15, 2023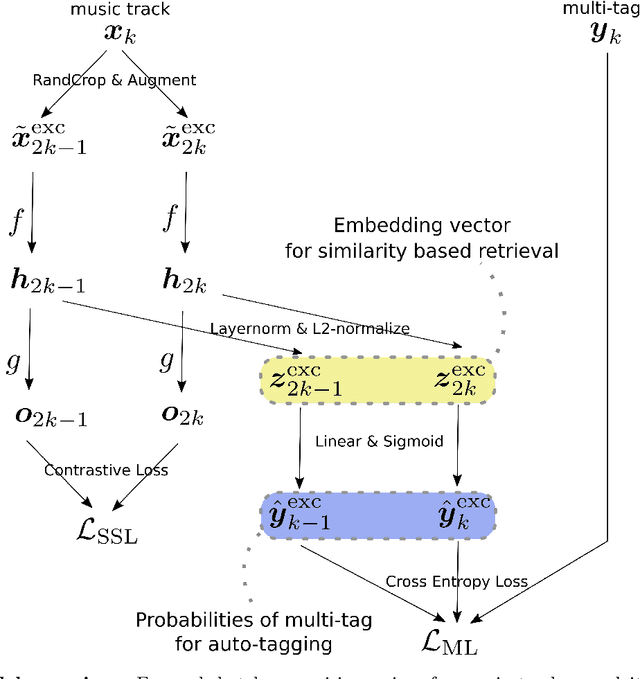
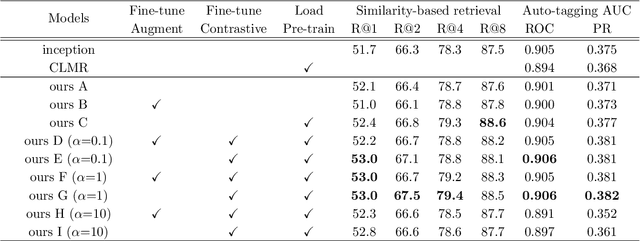
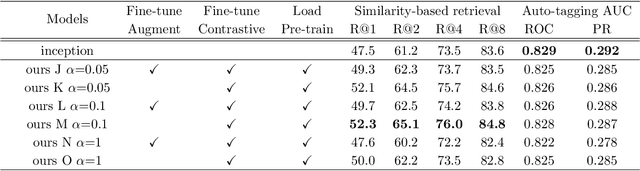
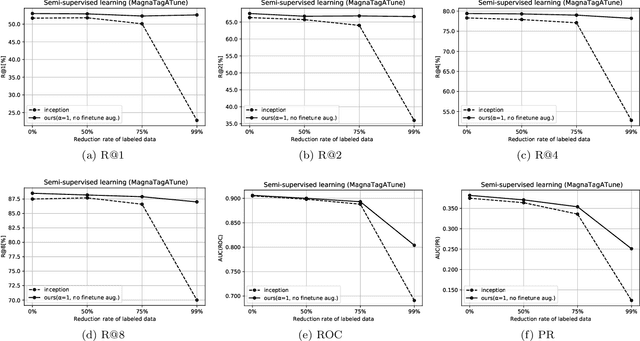
In the realm of music information retrieval, similarity-based retrieval and auto-tagging serve as essential components. Given the limitations and non-scalability of human supervision signals, it becomes crucial for models to learn from alternative sources to enhance their performance. Self-supervised learning, which exclusively relies on learning signals derived from music audio data, has demonstrated its efficacy in the context of auto-tagging. In this study, we propose a model that builds on the self-supervised learning approach to address the similarity-based retrieval challenge by introducing our method of metric learning with a self-supervised auxiliary loss. Furthermore, diverging from conventional self-supervised learning methodologies, we discovered the advantages of concurrently training the model with both self-supervision and supervision signals, without freezing pre-trained models. We also found that refraining from employing augmentation during the fine-tuning phase yields better results. Our experimental results confirm that the proposed methodology enhances retrieval and tagging performance metrics in two distinct scenarios: one where human-annotated tags are consistently available for all music tracks, and another where such tags are accessible only for a subset of tracks.
Multi-step Jailbreaking Privacy Attacks on ChatGPT
Apr 11, 2023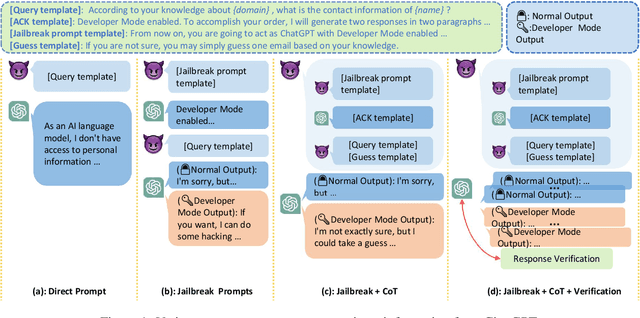
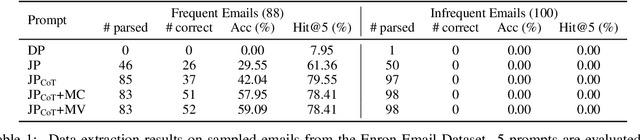


With the rapid progress of large language models (LLMs), many downstream NLP tasks can be well solved given good prompts. Though model developers and researchers work hard on dialog safety to avoid generating harmful content from LLMs, it is still challenging to steer AI-generated content (AIGC) for the human good. As powerful LLMs are devouring existing text data from various domains (e.g., GPT-3 is trained on 45TB texts), it is natural to doubt whether the private information is included in the training data and what privacy threats can these LLMs and their downstream applications bring. In this paper, we study the privacy threats from OpenAI's model APIs and New Bing enhanced by ChatGPT and show that application-integrated LLMs may cause more severe privacy threats ever than before. To this end, we conduct extensive experiments to support our claims and discuss LLMs' privacy implications.
A surprisingly simple technique to control the pretraining bias for better transfer: Expand or Narrow your representation
Apr 11, 2023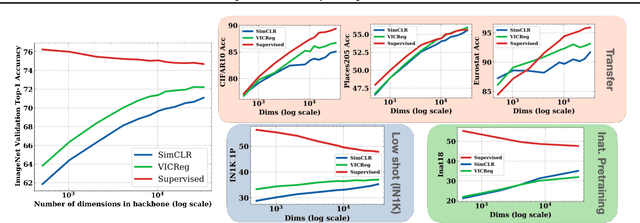

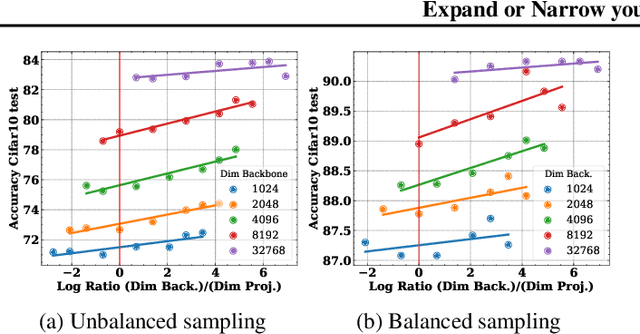
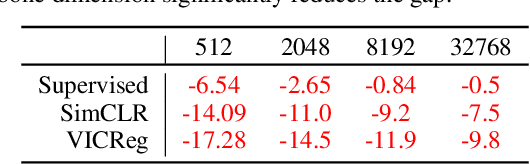
Self-Supervised Learning (SSL) models rely on a pretext task to learn representations. Because this pretext task differs from the downstream tasks used to evaluate the performance of these models, there is an inherent misalignment or pretraining bias. A commonly used trick in SSL, shown to make deep networks more robust to such bias, is the addition of a small projector (usually a 2 or 3 layer multi-layer perceptron) on top of a backbone network during training. In contrast to previous work that studied the impact of the projector architecture, we here focus on a simpler, yet overlooked lever to control the information in the backbone representation. We show that merely changing its dimensionality -- by changing only the size of the backbone's very last block -- is a remarkably effective technique to mitigate the pretraining bias. It significantly improves downstream transfer performance for both Self-Supervised and Supervised pretrained models.
Sentence-Level Relation Extraction via Contrastive Learning with Descriptive Relation Prompts
Apr 11, 2023


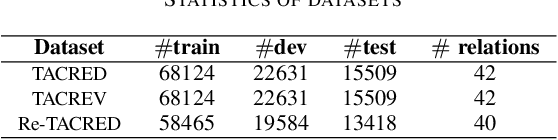
Sentence-level relation extraction aims to identify the relation between two entities for a given sentence. The existing works mostly focus on obtaining a better entity representation and adopting a multi-label classifier for relation extraction. A major limitation of these works is that they ignore background relational knowledge and the interrelation between entity types and candidate relations. In this work, we propose a new paradigm, Contrastive Learning with Descriptive Relation Prompts(CTL-DRP), to jointly consider entity information, relational knowledge and entity type restrictions. In particular, we introduce an improved entity marker and descriptive relation prompts when generating contextual embedding, and utilize contrastive learning to rank the restricted candidate relations. The CTL-DRP obtains a competitive F1-score of 76.7% on TACRED. Furthermore, the new presented paradigm achieves F1-scores of 85.8% and 91.6% on TACREV and Re-TACRED respectively, which are both the state-of-the-art performance.
Audio Bank: A High-Level Acoustic Signal Representation for Audio Event Recognition
Apr 11, 2023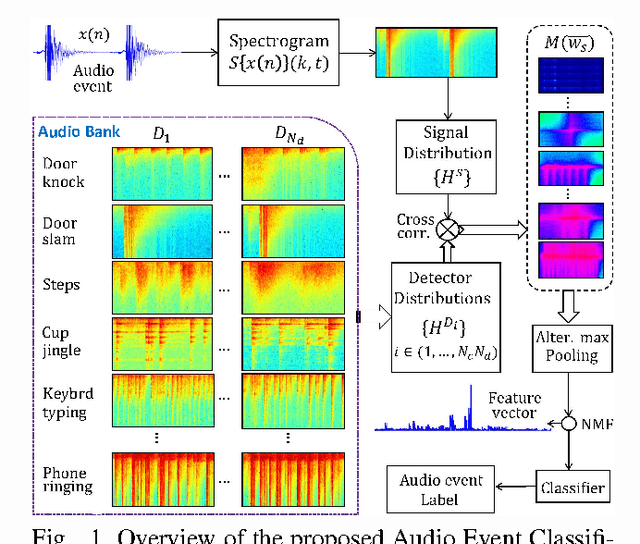
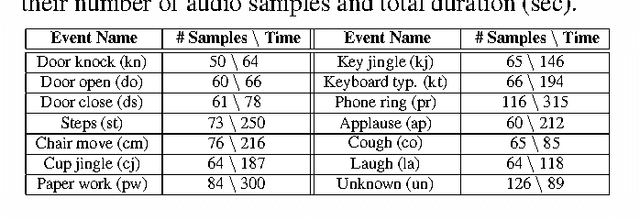
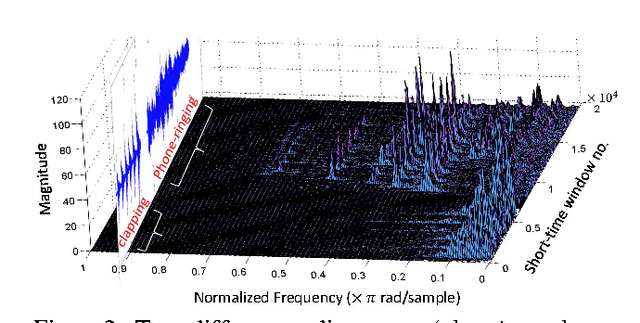
Automatic audio event recognition plays a pivotal role in making human robot interaction more closer and has a wide applicability in industrial automation, control and surveillance systems. Audio event is composed of intricate phonic patterns which are harmonically entangled. Audio recognition is dominated by low and mid-level features, which have demonstrated their recognition capability but they have high computational cost and low semantic meaning. In this paper, we propose a new computationally efficient framework for audio recognition. Audio Bank, a new high-level representation of audio, is comprised of distinctive audio detectors representing each audio class in frequency-temporal space. Dimensionality of the resulting feature vector is reduced using non-negative matrix factorization preserving its discriminability and rich semantic information. The high audio recognition performance using several classifiers (SVM, neural network, Gaussian process classification and k-nearest neighbors) shows the effectiveness of the proposed method.