 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Q-RBSA: High-Resolution 3D EBSD Map Generation Using An Efficient Quaternion Transformer Network
Mar 19, 2023
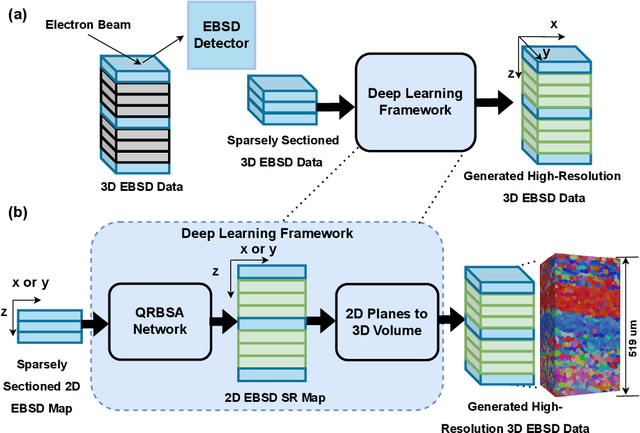

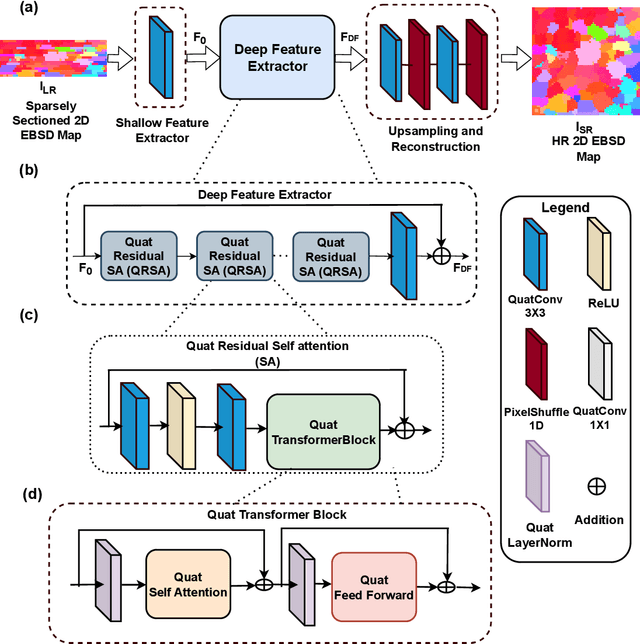
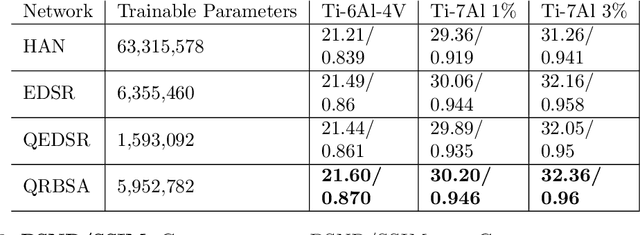
Gathering 3D material microstructural information is time-consuming, expensive, and energy-intensive. Acquisition of 3D data has been accelerated by developments in serial sectioning instrument capabilities; however, for crystallographic information, the electron backscatter diffraction (EBSD) imaging modality remains rate limiting. We propose a physics-based efficient deep learning framework to reduce the time and cost of collecting 3D EBSD maps. Our framework uses a quaternion residual block self-attention network (QRBSA) to generate high-resolution 3D EBSD maps from sparsely sectioned EBSD maps. In QRBSA, quaternion-valued convolution effectively learns local relations in orientation space, while self-attention in the quaternion domain captures long-range correlations. We apply our framework to 3D data collected from commercially relevant titanium alloys, showing both qualitatively and quantitatively that our method can predict missing samples (EBSD information between sparsely sectioned mapping points) as compared to high-resolution ground truth 3D EBSD maps.
Language Agnostic Multilingual Information Retrieval with Contrastive Learning
Oct 12, 2022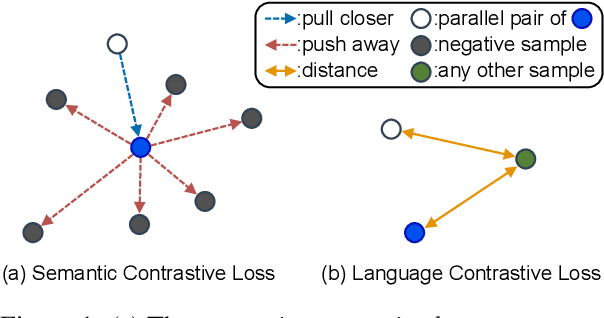
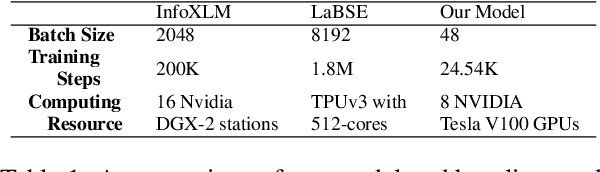
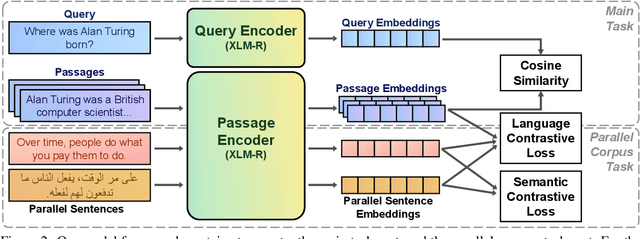
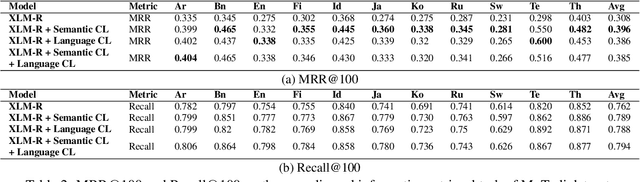
Multilingual information retrieval is challenging due to the lack of training datasets for many low-resource languages. We present an effective method by leveraging parallel and non-parallel corpora to improve the pretrained multilingual language models' cross-lingual transfer ability for information retrieval. We design the semantic contrastive loss as regular contrastive learning to improve the cross-lingual alignment of parallel sentence pairs, and we propose a new contrastive loss, the language contrastive loss, to leverage both parallel corpora and non-parallel corpora to further improve multilingual representation learning. We train our model on an English information retrieval dataset, and test its zero-shot transfer ability to other languages. Our experiment results show that our method brings significant improvement to prior work on retrieval performance, while it requires much less computational effort. Our model can work well even with a small number of parallel corpora. And it can be used as an add-on module to any backbone and other tasks. Our code is available at: https://github.com/xiyanghu/multilingualIR.
Human Pose Estimation in Extremely Low-Light Conditions
Mar 27, 2023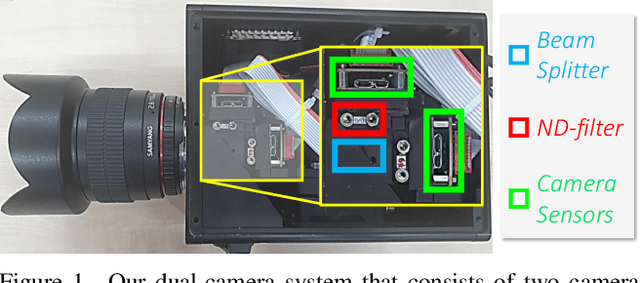


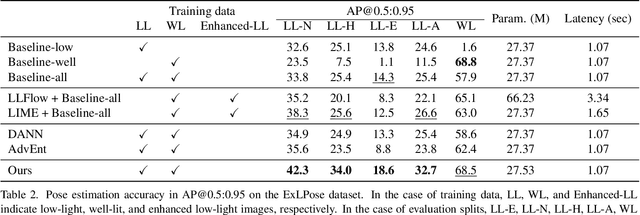
We study human pose estimation in extremely low-light images. This task is challenging due to the difficulty of collecting real low-light images with accurate labels, and severely corrupted inputs that degrade prediction quality significantly. To address the first issue, we develop a dedicated camera system and build a new dataset of real low-light images with accurate pose labels. Thanks to our camera system, each low-light image in our dataset is coupled with an aligned well-lit image, which enables accurate pose labeling and is used as privileged information during training. We also propose a new model and a new training strategy that fully exploit the privileged information to learn representation insensitive to lighting conditions. Our method demonstrates outstanding performance on real extremely low light images, and extensive analyses validate that both of our model and dataset contribute to the success.
The ImSPOC snapshot imaging spectrometer: image formation model and device characterization
Mar 27, 2023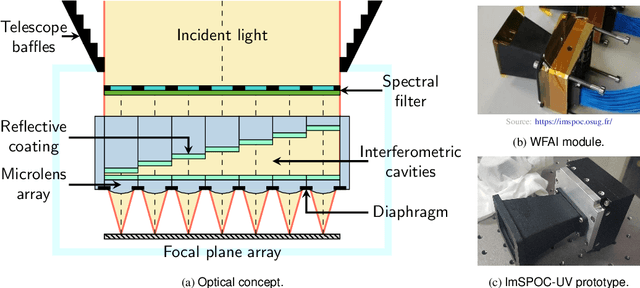
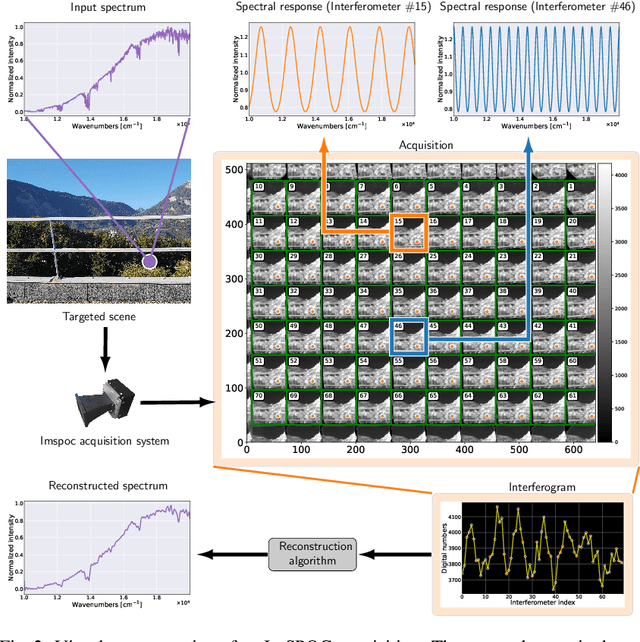
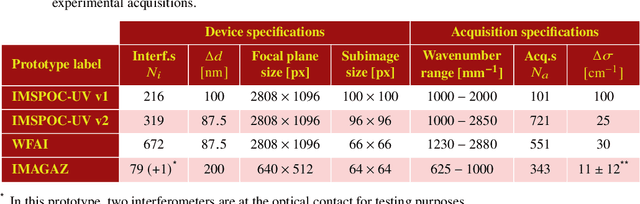
In recent years, the demand for capturing spectral information with finer detail has increased, requiring hyperspectral imaging devices capable of acquiring the required information with increased temporal, spatial and spectral resolution. In this work, we present the image acquisition model of the Image SPectrometer On Chip (ImSPOC), a novel compact snapshot image spectrometer based on the interferometry of Fabry-Perot. Additionally, we propose the interferometer response characterization algorithm (IRCA), a robust three-step procedure to characterize the ImSPOC device that estimates the optical parameters of the composing interferometers' transfer function. The proposed algorithm processes the image output from a set of monochromatic light sources, refining the results through nonlinear regression after an ad-hoc initialization. Experimental analysis confirms the performances of the proposed approach for the characterization of four different ImSPOC prototypes. The source code associated to this paper is available at https://github.com/danaroth83/irca.
Can Shadows Reveal Biometric Information?
Sep 21, 2022


We study the problem of extracting biometric information of individuals by looking at shadows of objects cast on diffuse surfaces. We show that the biometric information leakage from shadows can be sufficient for reliable identity inference under representative scenarios via a maximum likelihood analysis. We then develop a learning-based method that demonstrates this phenomenon in real settings, exploiting the subtle cues in the shadows that are the source of the leakage without requiring any labeled real data. In particular, our approach relies on building synthetic scenes composed of 3D face models obtained from a single photograph of each identity. We transfer what we learn from the synthetic data to the real data using domain adaptation in a completely unsupervised way. Our model is able to generalize well to the real domain and is robust to several variations in the scenes. We report high classification accuracies in an identity classification task that takes place in a scene with unknown geometry and occluding objects.
The Face of Populism: Examining Differences in Facial Emotional Expressions of Political Leaders Using Machine Learning
Apr 19, 2023
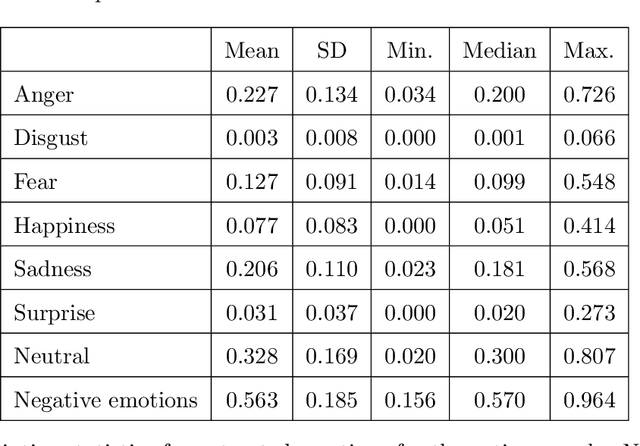
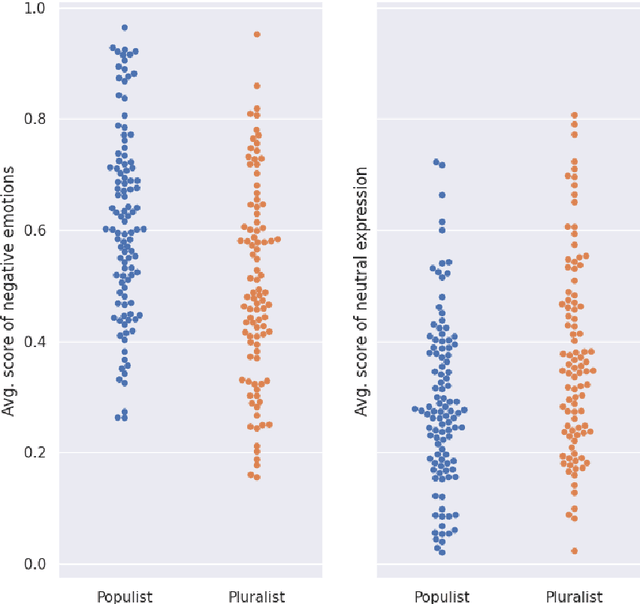
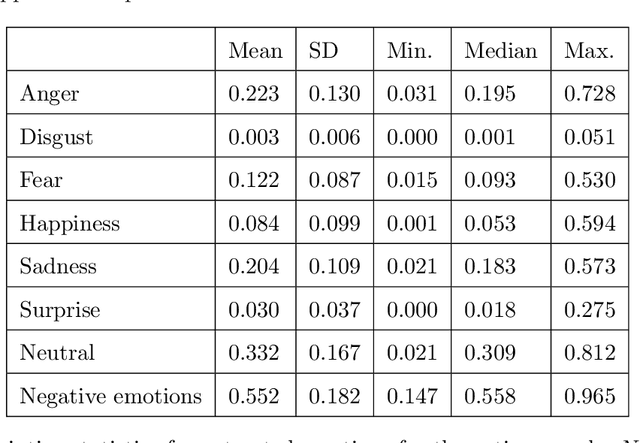
Online media has revolutionized the way political information is disseminated and consumed on a global scale, and this shift has compelled political figures to adopt new strategies of capturing and retaining voter attention. These strategies often rely on emotional persuasion and appeal, and as visual content becomes increasingly prevalent in virtual space, much of political communication too has come to be marked by evocative video content and imagery. The present paper offers a novel approach to analyzing material of this kind. We apply a deep-learning-based computer-vision algorithm to a sample of 220 YouTube videos depicting political leaders from 15 different countries, which is based on an existing trained convolutional neural network architecture provided by the Python library fer. The algorithm returns emotion scores representing the relative presence of 6 emotional states (anger, disgust, fear, happiness, sadness, and surprise) and a neutral expression for each frame of the processed YouTube video. We observe statistically significant differences in the average score of expressed negative emotions between groups of leaders with varying degrees of populist rhetoric as defined by the Global Party Survey (GPS), indicating that populist leaders tend to express negative emotions to a greater extent during their public performance than their non-populist counterparts. Overall, our contribution provides insight into the characteristics of visual self-representation among political leaders, as well as an open-source workflow for further computational studies of their non-verbal communication.
mHealth hyperspectral learning for instantaneous spatiospectral imaging of hemodynamics
Apr 05, 2023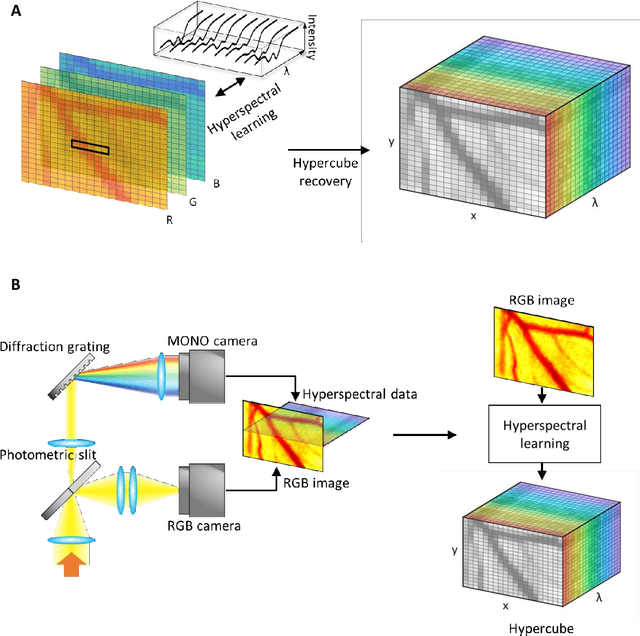
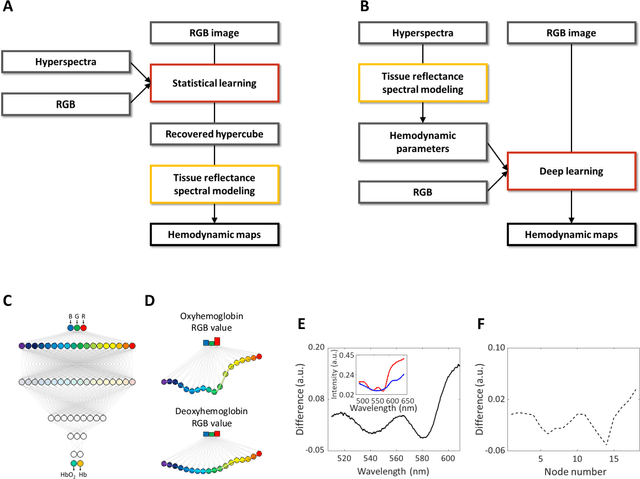
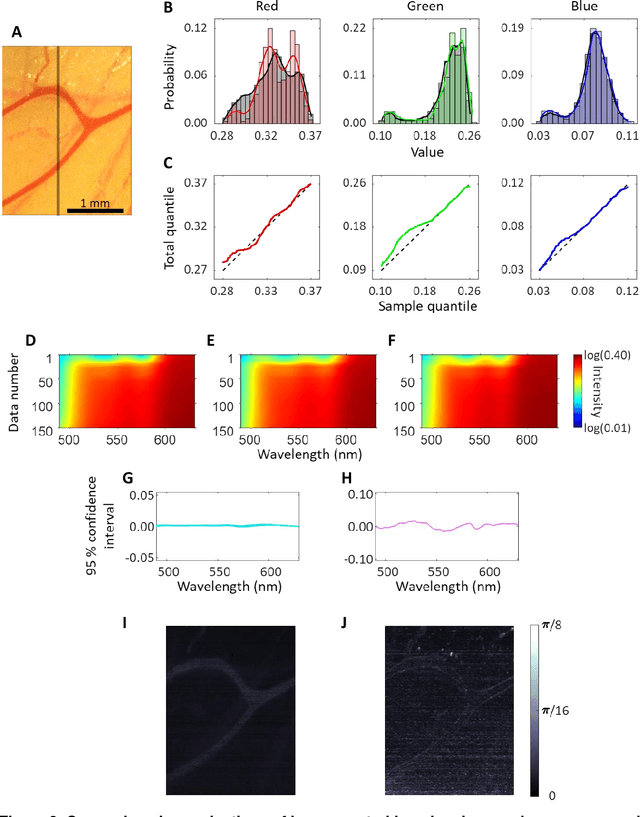
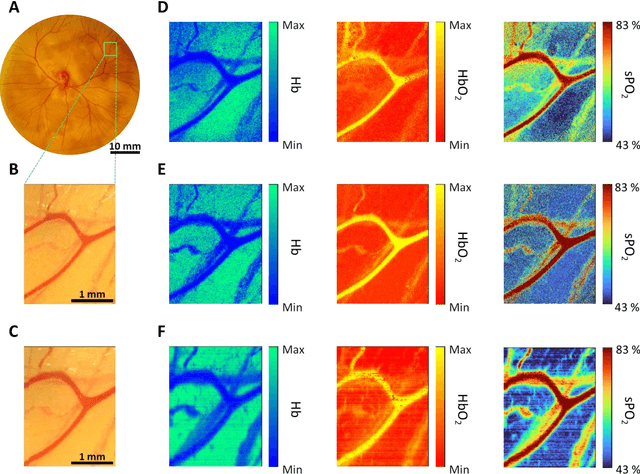
Hyperspectral imaging acquires data in both the spatial and frequency domains to offer abundant physical or biological information. However, conventional hyperspectral imaging has intrinsic limitations of bulky instruments, slow data acquisition rate, and spatiospectral tradeoff. Here we introduce hyperspectral learning for snapshot hyperspectral imaging in which sampled hyperspectral data in a small subarea are incorporated into a learning algorithm to recover the hypercube. Hyperspectral learning exploits the idea that a photograph is more than merely a picture and contains detailed spectral information. A small sampling of hyperspectral data enables spectrally informed learning to recover a hypercube from an RGB image. Hyperspectral learning is capable of recovering full spectroscopic resolution in the hypercube, comparable to high spectral resolutions of scientific spectrometers. Hyperspectral learning also enables ultrafast dynamic imaging, leveraging ultraslow video recording in an off-the-shelf smartphone, given that a video comprises a time series of multiple RGB images. To demonstrate its versatility, an experimental model of vascular development is used to extract hemodynamic parameters via statistical and deep-learning approaches. Subsequently, the hemodynamics of peripheral microcirculation is assessed at an ultrafast temporal resolution up to a millisecond, using a conventional smartphone camera. This spectrally informed learning method is analogous to compressed sensing; however, it further allows for reliable hypercube recovery and key feature extractions with a transparent learning algorithm. This learning-powered snapshot hyperspectral imaging method yields high spectral and temporal resolutions and eliminates the spatiospectral tradeoff, offering simple hardware requirements and potential applications of various machine-learning techniques.
FACE-AUDITOR: Data Auditing in Facial Recognition Systems
Apr 05, 2023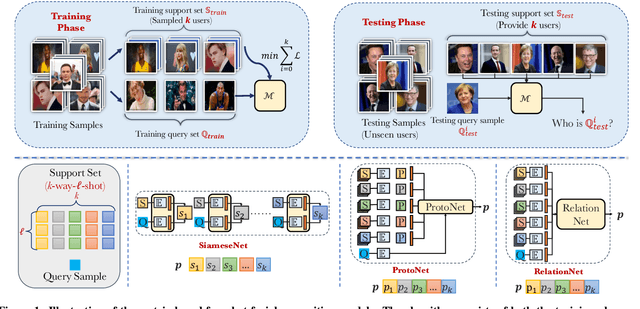

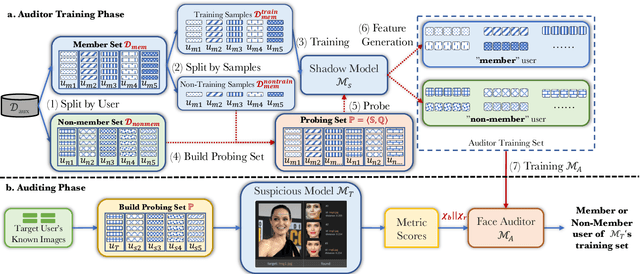
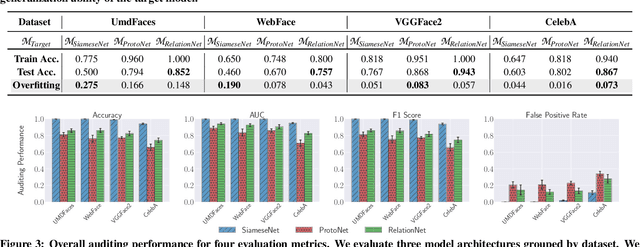
Few-shot-based facial recognition systems have gained increasing attention due to their scalability and ability to work with a few face images during the model deployment phase. However, the power of facial recognition systems enables entities with moderate resources to canvas the Internet and build well-performed facial recognition models without people's awareness and consent. To prevent the face images from being misused, one straightforward approach is to modify the raw face images before sharing them, which inevitably destroys the semantic information, increases the difficulty of retroactivity, and is still prone to adaptive attacks. Therefore, an auditing method that does not interfere with the facial recognition model's utility and cannot be quickly bypassed is urgently needed. In this paper, we formulate the auditing process as a user-level membership inference problem and propose a complete toolkit FACE-AUDITOR that can carefully choose the probing set to query the few-shot-based facial recognition model and determine whether any of a user's face images is used in training the model. We further propose to use the similarity scores between the original face images as reference information to improve the auditing performance. Extensive experiments on multiple real-world face image datasets show that FACE-AUDITOR can achieve auditing accuracy of up to $99\%$. Finally, we show that FACE-AUDITOR is robust in the presence of several perturbation mechanisms to the training images or the target models. The source code of our experiments can be found at \url{https://github.com/MinChen00/Face-Auditor}.
GAM : Gradient Attention Module of Optimization for Point Clouds Analysis
Mar 21, 2023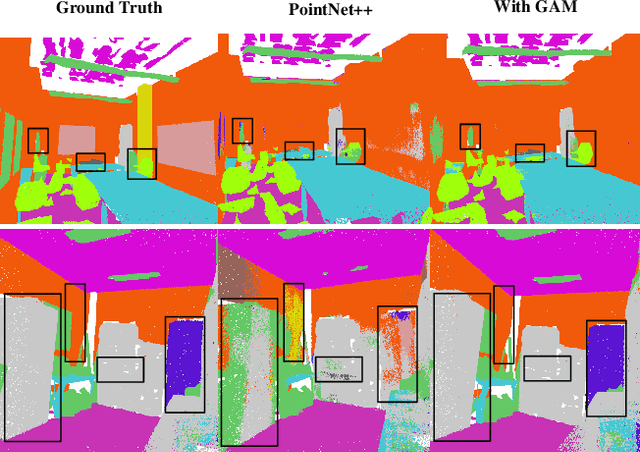
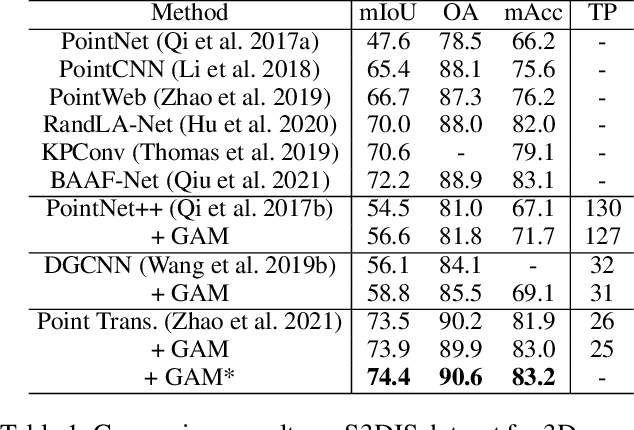
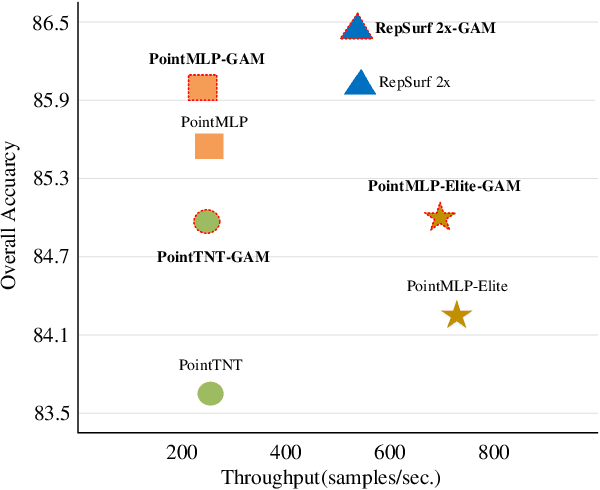
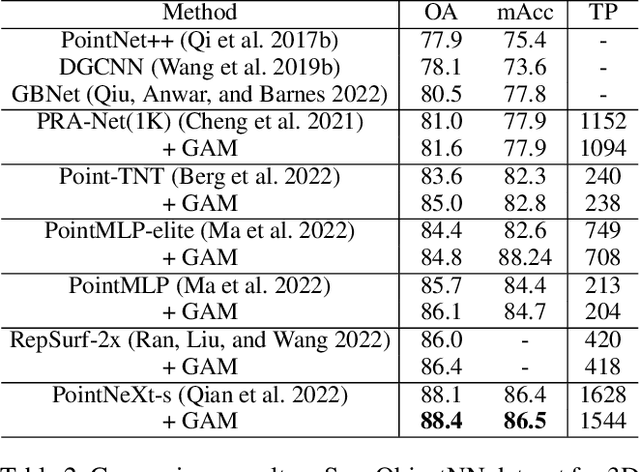
In point cloud analysis tasks, the existing local feature aggregation descriptors (LFAD) are unable to fully utilize information in the neighborhood of central points. Previous methods rely solely on Euclidean distance to constrain the local aggregation process, which can be easily affected by abnormal points and cannot adequately fit with the original geometry of the point cloud. We believe that fine-grained geometric information (FGGI) is significant for the aggregation of local features. Therefore, we propose a gradient-based local attention module, termed as Gradient Attention Module (GAM), to address the aforementioned problem. Our proposed GAM simplifies the process that extracts gradient information in the neighborhood and uses the Zenith Angle matrix and Azimuth Angle matrix as explicit representation, which accelerates the module by 35X. Comprehensive experiments were conducted on five benchmark datasets to demonstrate the effectiveness and generalization capability of the proposed GAM for 3D point cloud analysis. Especially on S3DIS dataset, GAM achieves the best performance among current point-based models with mIoU/OA/mAcc of 74.4%/90.6%/83.2%, respectively.
* In AAAI, 2023
RO-MAP: Real-Time Multi-Object Mapping with Neural Radiance Fields
Apr 12, 2023
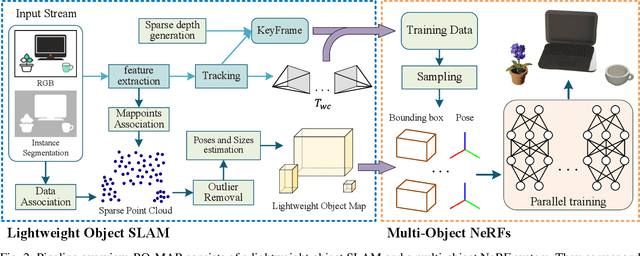
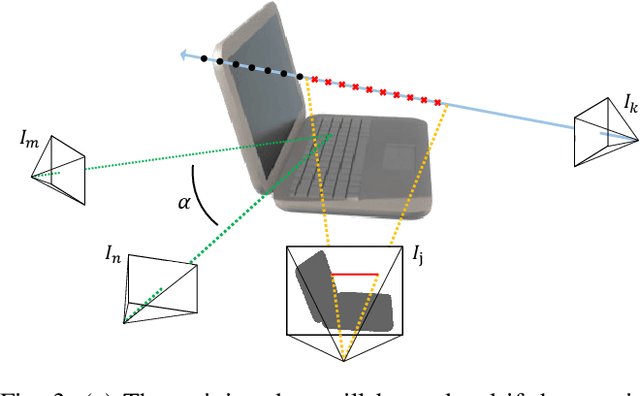

Accurate perception of objects in the environment is important for improving the scene understanding capability of SLAM systems. In robotic and augmented reality applications, object maps with semantic and metric information show attractive advantages. In this paper, we present RO-MAP, a novel multi-object mapping pipeline that does not rely on 3D priors. Given only monocular input, we use neural radiance fields to represent objects and couple them with a lightweight object SLAM based on multi-view geometry, to simultaneously localize objects and implicitly learn their dense geometry. We create separate implicit models for each detected object and train them dynamically and in parallel as new observations are added. Experiments on synthetic and real-world datasets demonstrate that our method can generate semantic object map with shape reconstruction, and be competitive with offline methods while achieving real-time performance (25Hz). The code and dataset will be available at: https://github.com/XiaoHan-Git/RO-MAP