 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pretrained Language Models as Visual Planners for Human Assistance
Apr 17, 2023
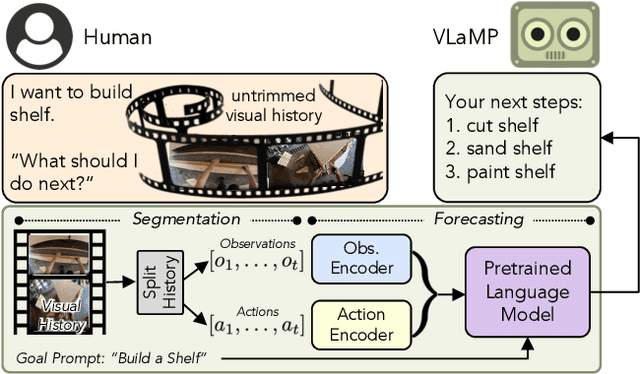
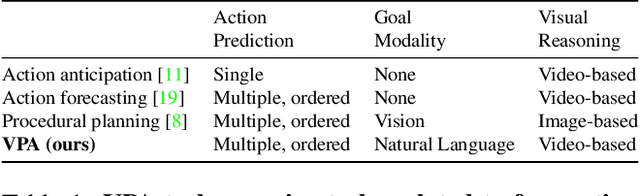
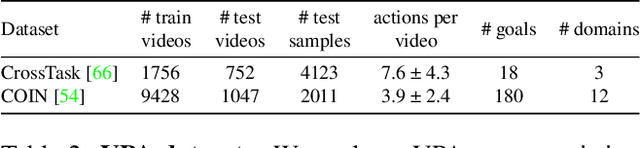
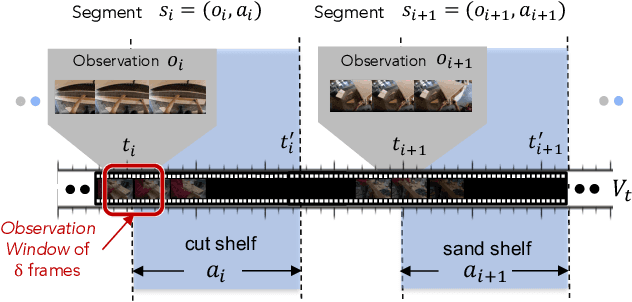
To make progress towards multi-modal AI assistants which can guide users to achieve complex multi-step goals, we propose the task of Visual Planning for Assistance (VPA). Given a goal briefly described in natural language, e.g., "make a shelf", and a video of the user's progress so far, the aim of VPA is to obtain a plan, i.e., a sequence of actions such as "sand shelf", "paint shelf", etc., to achieve the goal. This requires assessing the user's progress from the untrimmed video, and relating it to the requirements of underlying goal, i.e., relevance of actions and ordering dependencies amongst them. Consequently, this requires handling long video history, and arbitrarily complex action dependencies. To address these challenges, we decompose VPA into video action segmentation and forecasting. We formulate the forecasting step as a multi-modal sequence modeling problem and present Visual Language Model based Planner (VLaMP), which leverages pre-trained LMs as the sequence model. We demonstrate that VLaMP performs significantly better than baselines w.r.t all metrics that evaluate the generated plan. Moreover, through extensive ablations, we also isolate the value of language pre-training, visual observations, and goal information on the performance. We will release our data, model, and code to enable future research on visual planning for assistance.
A Contrastive Method Based on Elevation Data for Remote Sensing with Scarce and High Level Semantic Labels
Apr 17, 2023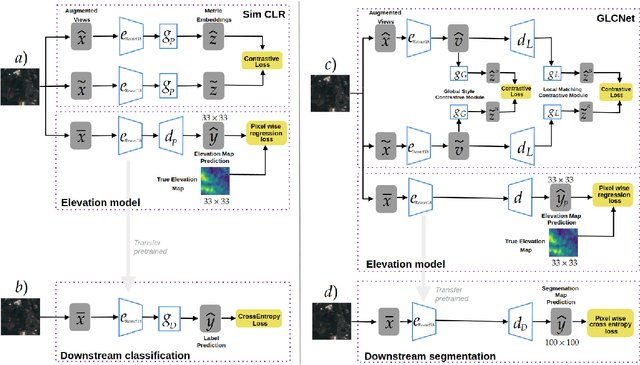
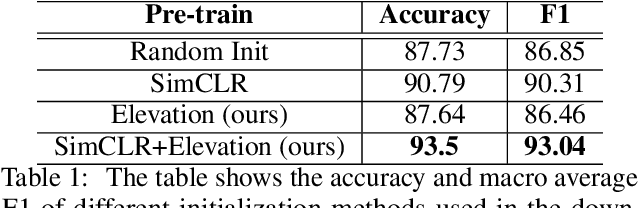
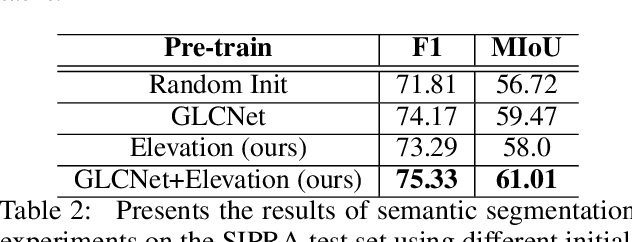
This work proposes a hybrid unsupervised/supervised learning method to pretrain models applied in earth observation downstream tasks where only a handful of labels denoting very general semantic concepts are available. We combine a contrastive approach to pretrain models with a pretext task to predict spatially coarse elevation maps which are commonly available worldwide. The intuition behind is that there is generally some correlation between the elevation and targets in many remote sensing tasks, allowing the model to pre-learn useful representations. We assess the performance of our approach on a segmentation downstream task on labels gathering many possible subclasses (pixel level classification of farmlands vs. other) and an image binary classification task derived from the former, on a dataset on the north-east of Colombia. On both cases we pretrain our models with 39K unlabeled images, fine tune the downstream task only with 80 labeled images and test it with 2944 labeled images. Our experiments show that our methods, GLCNet+Elevation for segmentation and SimCLR+Elevation for classification, outperform their counterparts without the elevation pretext task in terms of accuracy and macro-average F1, which supports the notion that including additional information correlated to targets in downstream tasks can lead to improved performance.
DRIFT: A Federated Recommender System with Implicit Feedback on the Items
Apr 17, 2023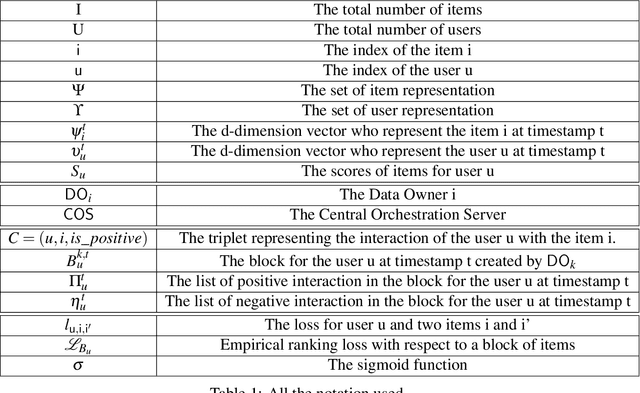
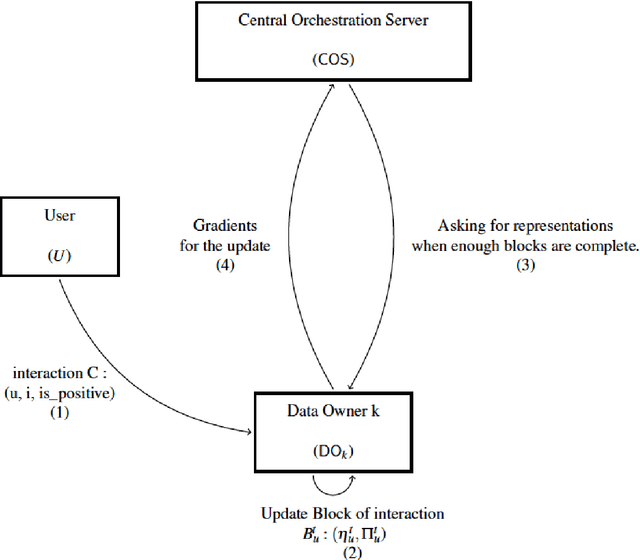
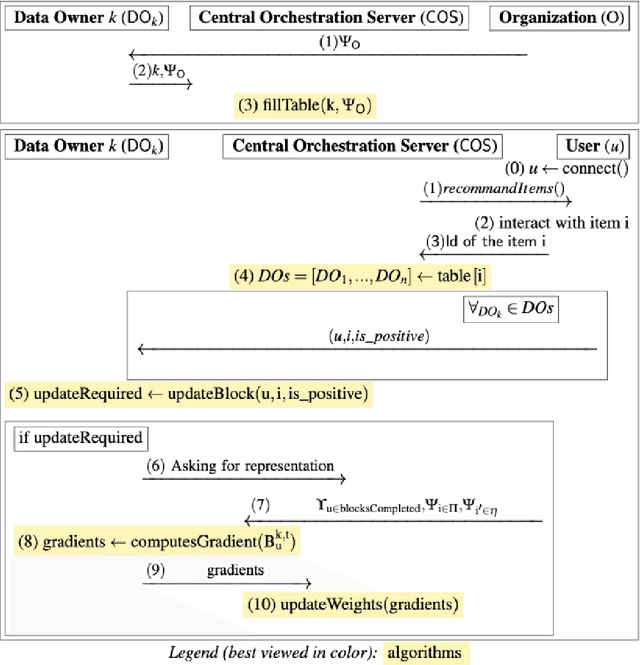
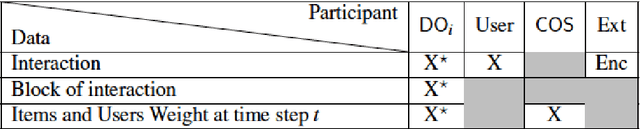
Nowadays there are more and more items available online, this makes it hard for users to find items that they like. Recommender systems aim to find the item who best suits the user, using his historical interactions. Depending on the context, these interactions may be more or less sensitive and collecting them brings an important problem concerning the users' privacy. Federated systems have shown that it is possible to make accurate and efficient recommendations without storing users' personal information. However, these systems use instantaneous feedback from the user. In this report, we propose DRIFT, a federated architecture for recommender systems, using implicit feedback. Our learning model is based on a recent algorithm for recommendation with implicit feedbacks SAROS. We aim to make recommendations as precise as SAROS, without compromising the users' privacy. In this report we show that thanks to our experiments, but also thanks to a theoretical analysis on the convergence. We have shown also that the computation time has a linear complexity with respect to the number of interactions made. Finally, we have shown that our algorithm is secure, and participants in our federated system cannot guess the interactions made by the user, except DOs that have the item involved in the interaction.
(LC)$^2$: LiDAR-Camera Loop Constraints For Cross-Modal Place Recognition
Apr 17, 2023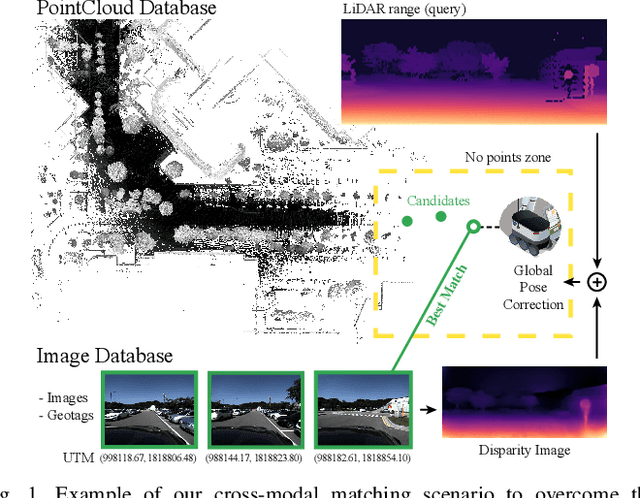
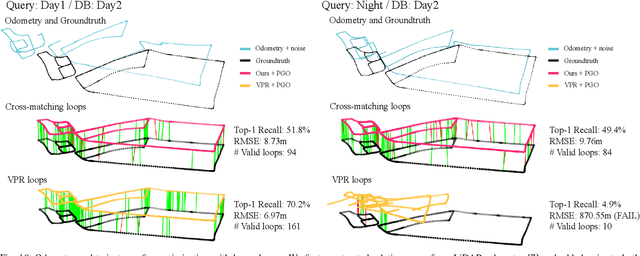

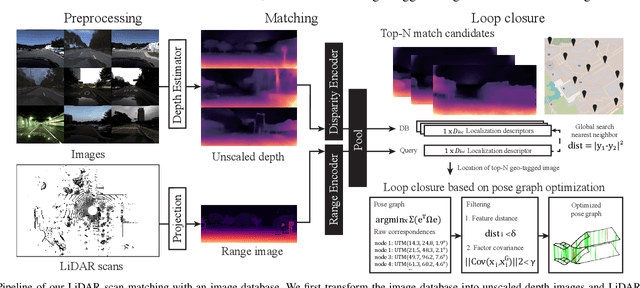
Localization has been a challenging task for autonomous navigation. A loop detection algorithm must overcome environmental changes for the place recognition and re-localization of robots. Therefore, deep learning has been extensively studied for the consistent transformation of measurements into localization descriptors. Street view images are easily accessible; however, images are vulnerable to appearance changes. LiDAR can robustly provide precise structural information. However, constructing a point cloud database is expensive, and point clouds exist only in limited places. Different from previous works that train networks to produce shared embedding directly between the 2D image and 3D point cloud, we transform both data into 2.5D depth images for matching. In this work, we propose a novel cross-matching method, called (LC)$^2$, for achieving LiDAR localization without a prior point cloud map. To this end, LiDAR measurements are expressed in the form of range images before matching them to reduce the modality discrepancy. Subsequently, the network is trained to extract localization descriptors from disparity and range images. Next, the best matches are employed as a loop factor in a pose graph. Using public datasets that include multiple sessions in significantly different lighting conditions, we demonstrated that LiDAR-based navigation systems could be optimized from image databases and vice versa.
SplitAMC: Split Learning for Robust Automatic Modulation Classification
Apr 17, 2023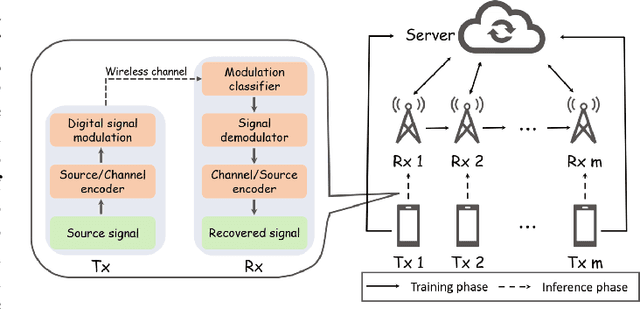
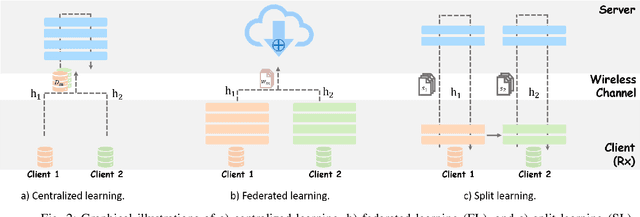
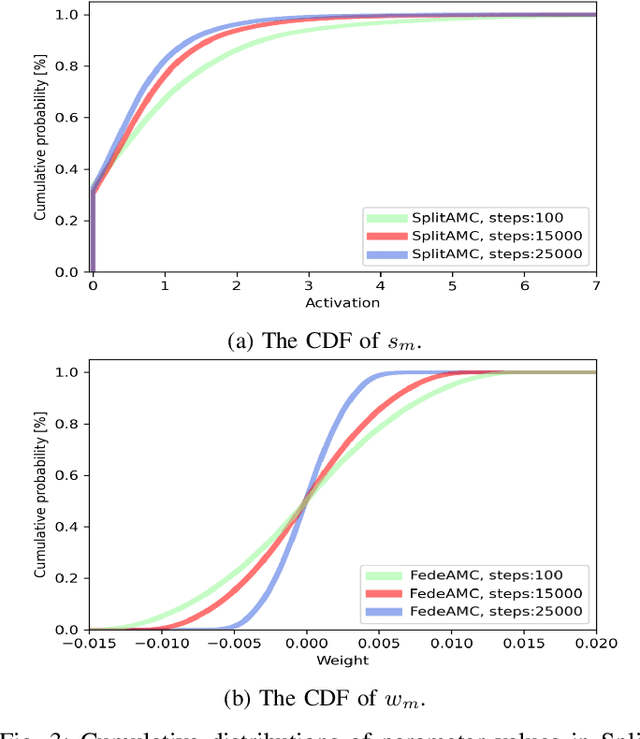
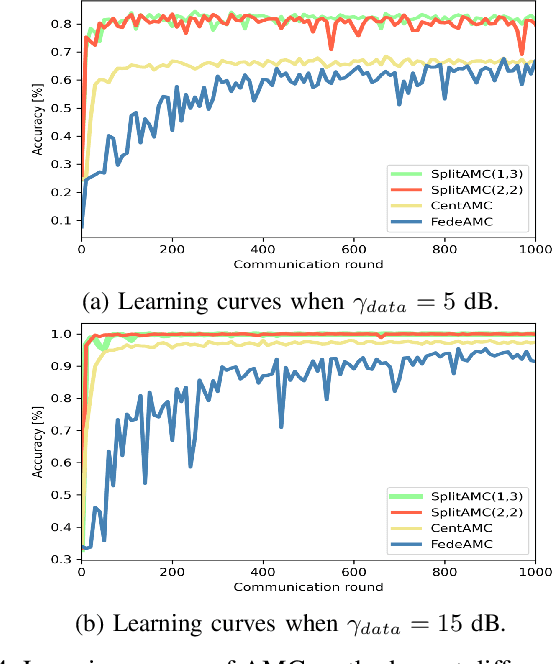
Automatic modulation classification (AMC) is a technology that identifies a modulation scheme without prior signal information and plays a vital role in various applications, including cognitive radio and link adaptation. With the development of deep learning (DL), DL-based AMC methods have emerged, while most of them focus on reducing computational complexity in a centralized structure. This centralized learning-based AMC (CentAMC) violates data privacy in the aspect of direct transmission of client-side raw data. Federated learning-based AMC (FedeAMC) can bypass this issue by exchanging model parameters, but causes large resultant latency and client-side computational load. Moreover, both CentAMC and FedeAMC are vulnerable to large-scale noise occured in the wireless channel between the client and the server. To this end, we develop a novel AMC method based on a split learning (SL) framework, coined SplitAMC, that can achieve high accuracy even in poor channel conditions, while guaranteeing data privacy and low latency. In SplitAMC, each client can benefit from data privacy leakage by exchanging smashed data and its gradient instead of raw data, and has robustness to noise with the help of high scale of smashed data. Numerical evaluations validate that SplitAMC outperforms CentAMC and FedeAMC in terms of accuracy for all SNRs as well as latency.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023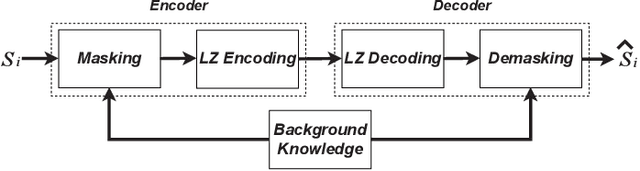
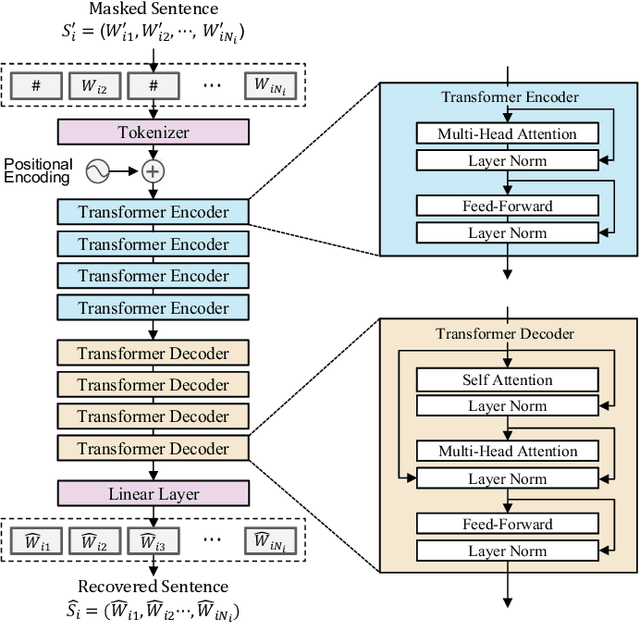
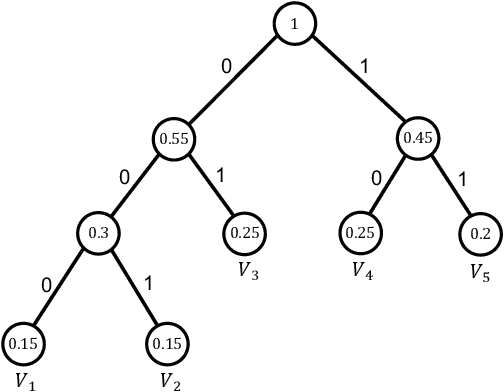
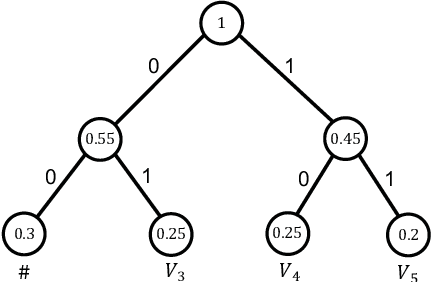
The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
Quantitative Method for Security Situation of the Power Information Network Based on the Evolutionary Neural Network
Nov 26, 2022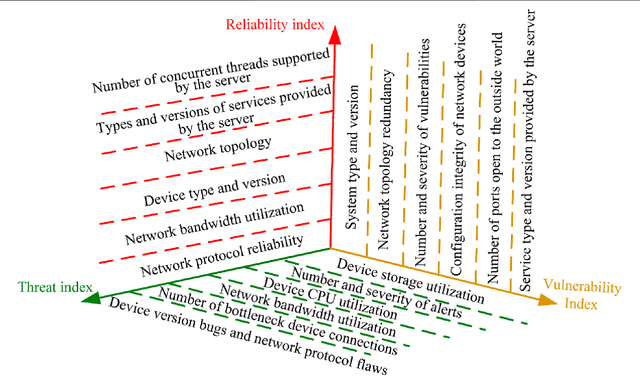
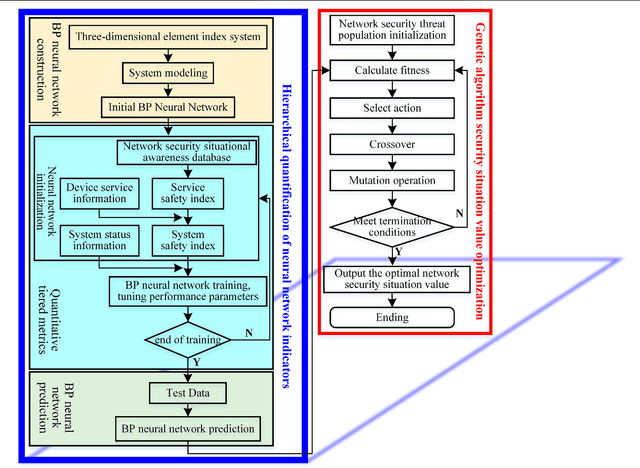
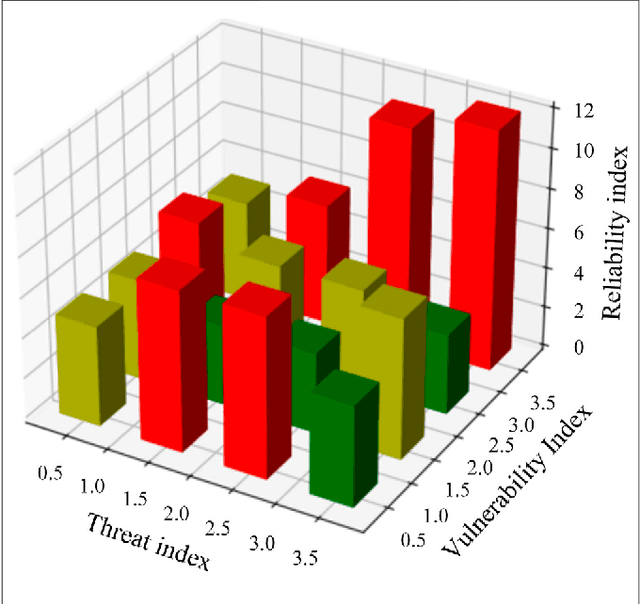
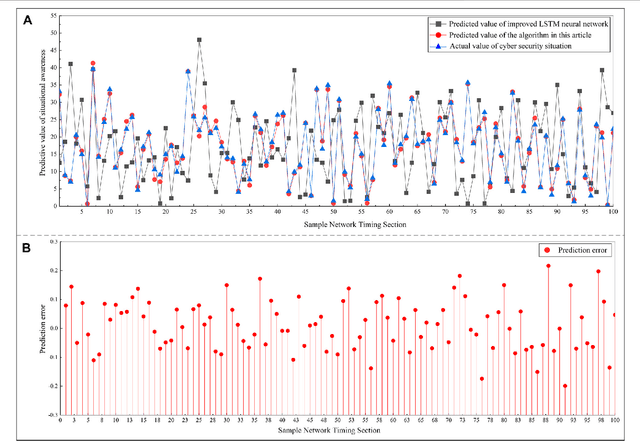
Cybersecurity is the security cornerstone of digital transformation of the power grid and construction of new power systems. The traditional network security situation quantification method only analyzes from the perspective of network performance, ignoring the impact of various power application services on the security situation, so the quantification results cannot fully reflect the power information network risk state. This study proposes a method for quantifying security situation of the power information network based on the evolutionary neural network. First, the security posture system architecture is designed by analyzing the business characteristics of power information network applications. Second, combining the importance of power application business, the spatial element index system of coupled interconnection is established from three dimensions of network reliability, threat, and vulnerability. Then, the BP neural network optimized by the genetic evolutionary algorithm is incorporated into the element index calculation process, and the quantitative model of security posture of the power information network based on the evolutionary neural network is constructed. Finally, a simulation experiment environment is built according to a power sector network topology, and the effectiveness and robustness of the method proposed in the study are verified.
Semantic Prompt for Few-Shot Image Recognition
Mar 24, 2023
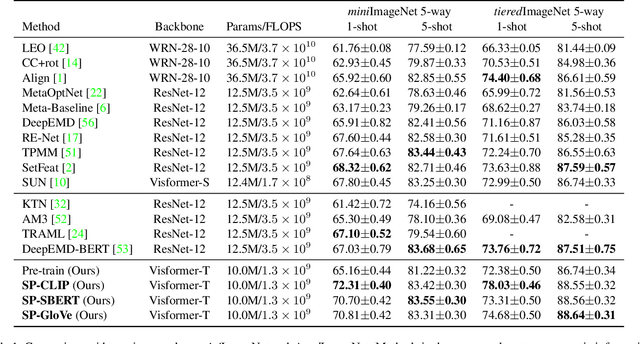
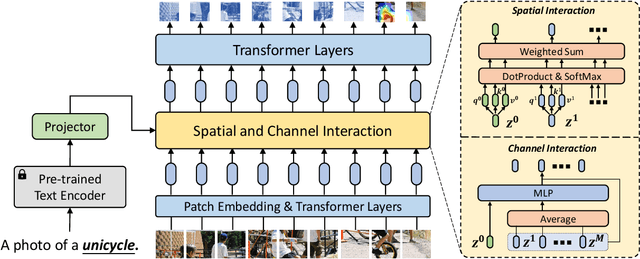
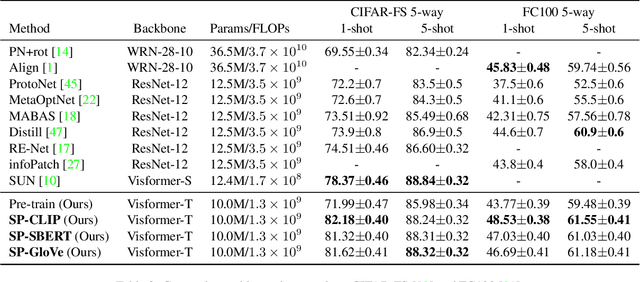
Few-shot learning is a challenging problem since only a few examples are provided to recognize a new class. Several recent studies exploit additional semantic information, e.g. text embeddings of class names, to address the issue of rare samples through combining semantic prototypes with visual prototypes. However, these methods still suffer from the spurious visual features learned from the rare support samples, resulting in limited benefits. In this paper, we propose a novel Semantic Prompt (SP) approach for few-shot learning. Instead of the naive exploitation of semantic information for remedying classifiers, we explore leveraging semantic information as prompts to tune the visual feature extraction network adaptively. Specifically, we design two complementary mechanisms to insert semantic prompts into the feature extractor: one is to enable the interaction between semantic prompts and patch embeddings along the spatial dimension via self-attention, another is to supplement visual features with the transformed semantic prompts along the channel dimension. By combining these two mechanisms, the feature extractor presents a better ability to attend to the class-specific features and obtains more generalized image representations with merely a few support samples. Through extensive experiments on four datasets, the proposed approach achieves promising results, improving the 1-shot learning accuracy by 3.67% on average.
A robust estimator of mutual information for deep learning interpretability
Oct 31, 2022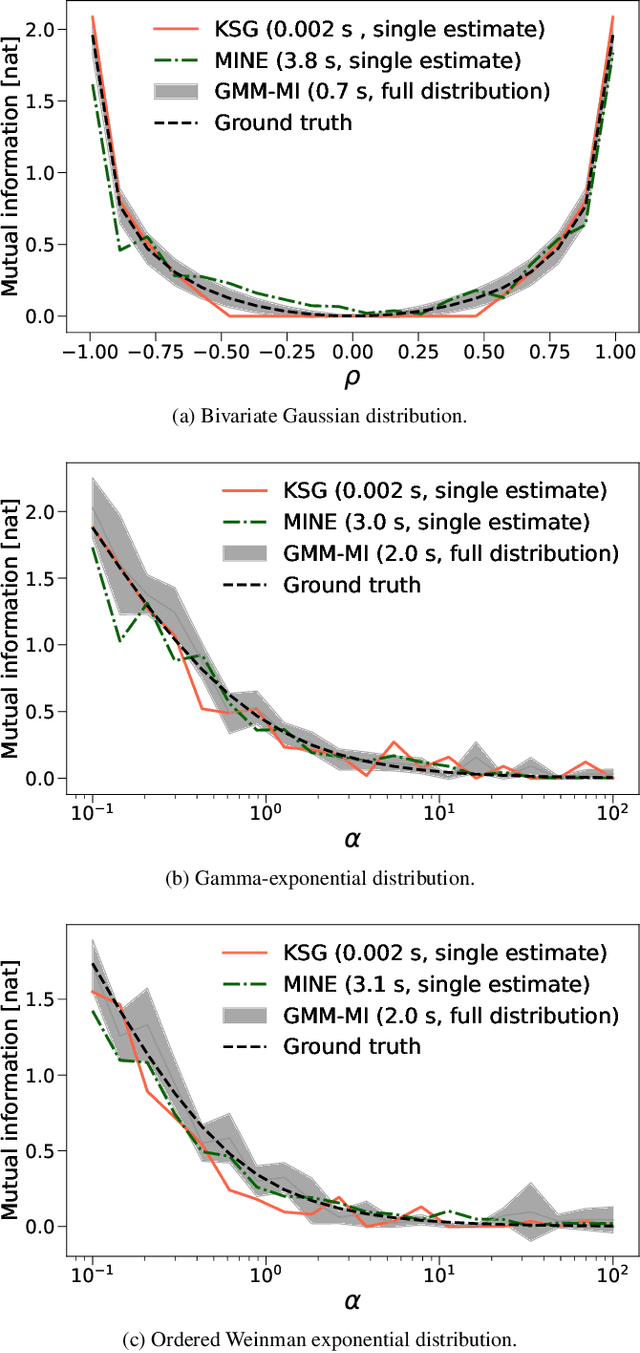
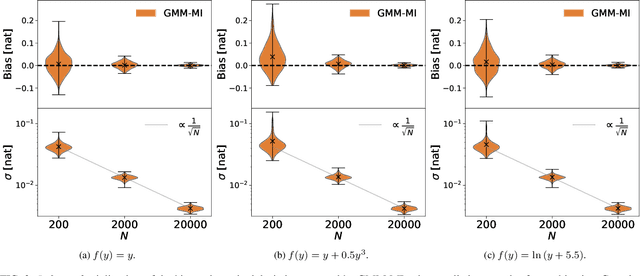
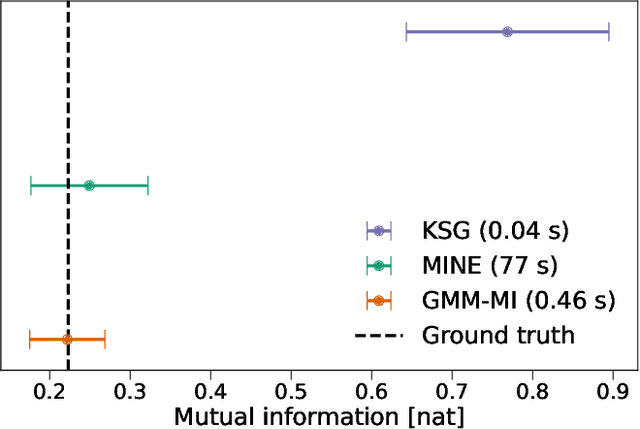
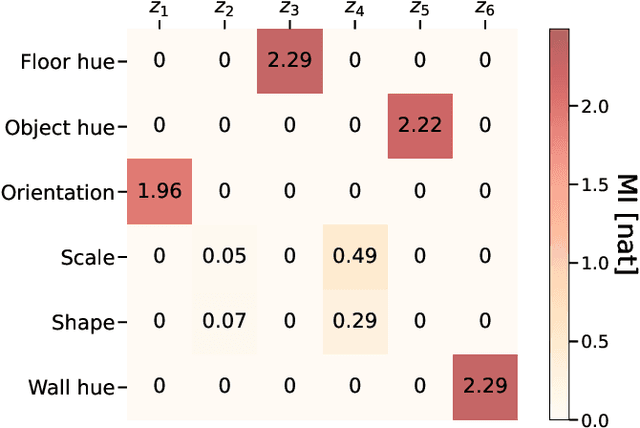
We develop the use of mutual information (MI), a well-established metric in information theory, to interpret the inner workings of deep learning models. To accurately estimate MI from a finite number of samples, we present GMM-MI (pronounced $``$Jimmie$"$), an algorithm based on Gaussian mixture models that can be applied to both discrete and continuous settings. GMM-MI is computationally efficient, robust to the choice of hyperparameters and provides the uncertainty on the MI estimate due to the finite sample size. We extensively validate GMM-MI on toy data for which the ground truth MI is known, comparing its performance against established mutual information estimators. We then demonstrate the use of our MI estimator in the context of representation learning, working with synthetic data and physical datasets describing highly non-linear processes. We train deep learning models to encode high-dimensional data within a meaningful compressed (latent) representation, and use GMM-MI to quantify both the level of disentanglement between the latent variables, and their association with relevant physical quantities, thus unlocking the interpretability of the latent representation. We make GMM-MI publicly available.
Disentangled Text Representation Learning with Information-Theoretic Perspective for Adversarial Robustness
Oct 26, 2022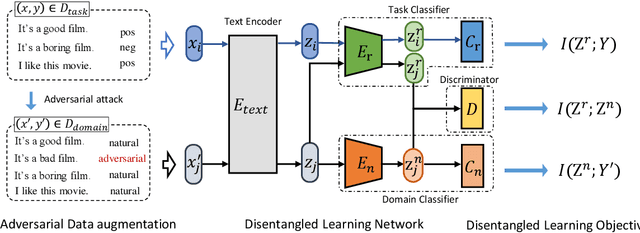
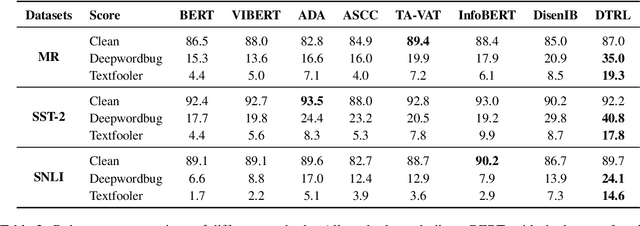
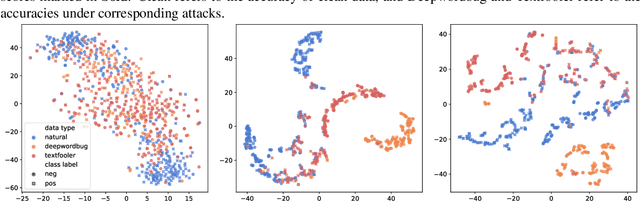
Adversarial vulnerability remains a major obstacle to constructing reliable NLP systems. When imperceptible perturbations are added to raw input text, the performance of a deep learning model may drop dramatically under attacks. Recent work argues the adversarial vulnerability of the model is caused by the non-robust features in supervised training. Thus in this paper, we tackle the adversarial robustness challenge from the view of disentangled representation learning, which is able to explicitly disentangle robust and non-robust features in text. Specifically, inspired by the variation of information (VI) in information theory, we derive a disentangled learning objective composed of mutual information to represent both the semantic representativeness of latent embeddings and differentiation of robust and non-robust features. On the basis of this, we design a disentangled learning network to estimate these mutual information. Experiments on text classification and entailment tasks show that our method significantly outperforms the representative methods under adversarial attacks, indicating that discarding non-robust features is critical for improving adversarial robustness.