 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real-Time Character Rise Motions
Apr 11, 2023
This paper presents an uncomplicated dynamic controller for generating physically-plausible three-dimensional full-body biped character rise motions on-the-fly at run-time. Our low-dimensional controller uses fundamental reference information (e.g., center-of-mass, hands, and feet locations) to produce balanced biped get-up poses by means of a real-time physically-based simulation. The key idea is to use a simple approximate model (i.e., similar to the inverted-pendulum stepping model) to create continuous reference trajectories that can be seamlessly tracked by an articulated biped character to create balanced rise-motions. Our approach does not use any key-framed data or any computationally expensive processing (e.g., offline-optimization or search algorithms). We demonstrate the effectiveness and ease of our technique through example (i.e., a biped character picking itself up from different laying positions).
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Mar 30, 2023
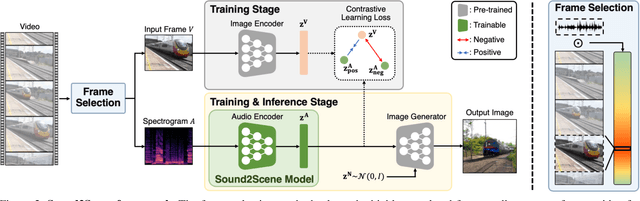


How does audio describe the world around us? In this paper, we propose a method for generating an image of a scene from sound. Our method addresses the challenges of dealing with the large gaps that often exist between sight and sound. We design a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. We translate the input audio to visual features, then use a pre-trained generator to produce an image. To further improve the quality of our generated images, we use sound source localization to select the audio-visual pairs that have strong cross-modal correlations. We obtain substantially better results on the VEGAS and VGGSound datasets than prior approaches. We also show that we can control our model's predictions by applying simple manipulations to the input waveform, or to the latent space.
Beta-VAE has 2 Behaviors: PCA or ICA?
Mar 25, 2023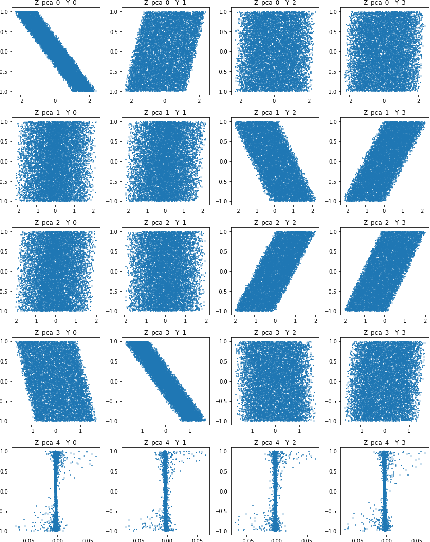
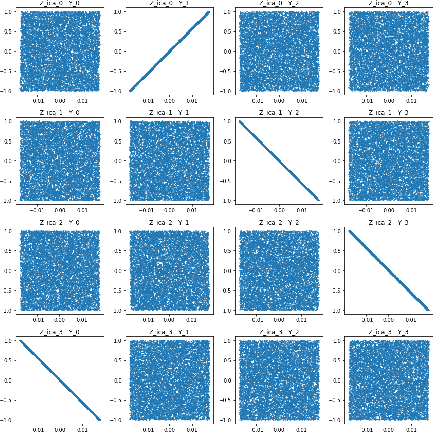
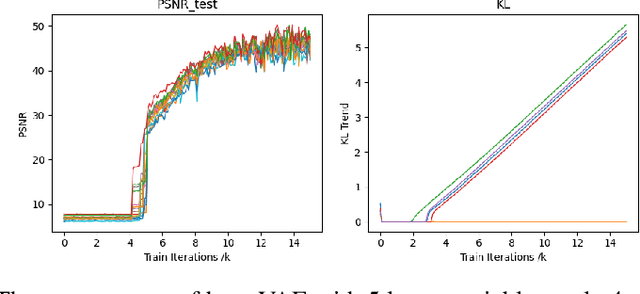
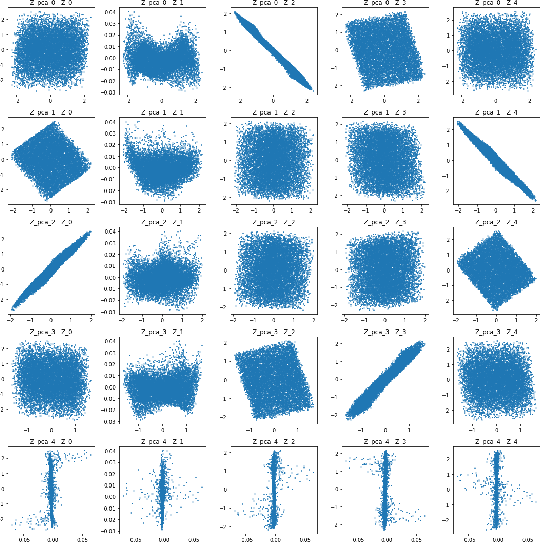
Beta-VAE is a very classical model for disentangled representation learning, the use of an expanding bottleneck that allow information into the decoder gradually is key to representation disentanglement as well as high-quality reconstruction. During recent experiments on such fascinating structure, we discovered that the total amount of latent variables can affect the representation learnt by the network: with very few latent variables, the network tend to learn the most important or principal variables, acting like a PCA; with very large numbers of latent variables, the variables tend to be more disentangled, and act like an ICA. Our assumption is that the competition between latent variables while trying to gain the most information bandwidth can lead to this phenomenon.
Revisiting Transformer for Point Cloud-based 3D Scene Graph Generation
Mar 23, 2023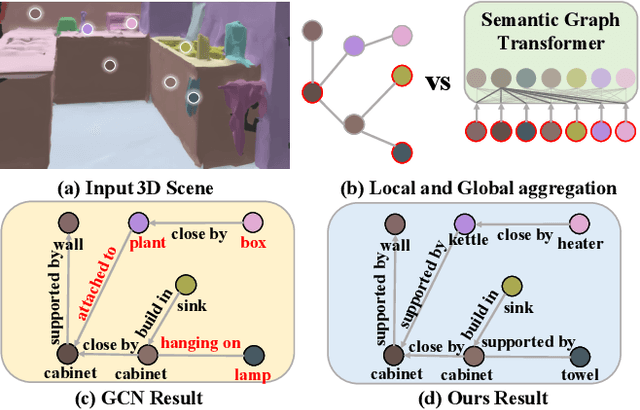
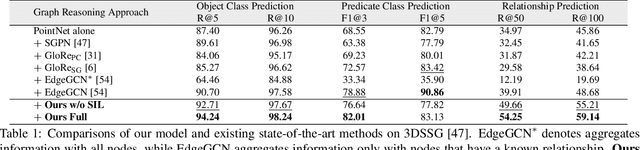
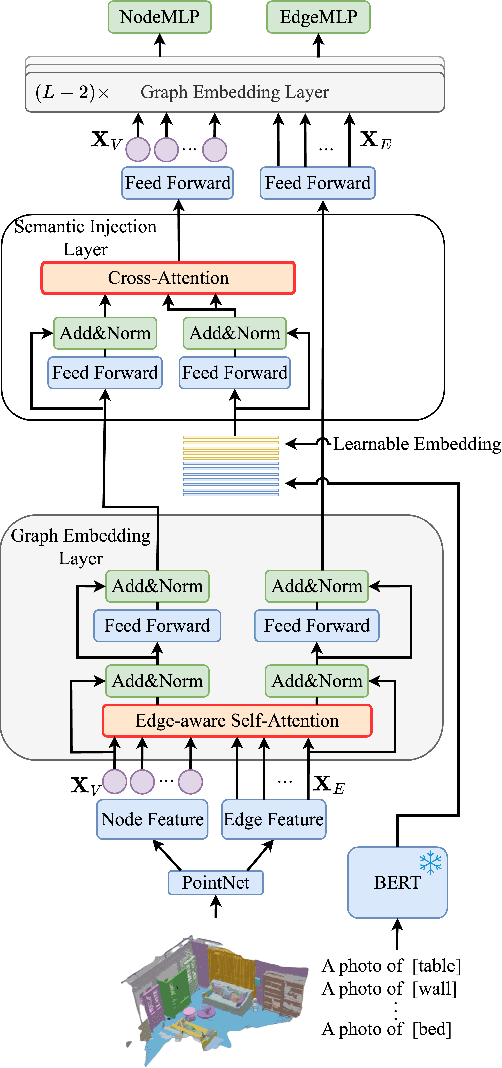
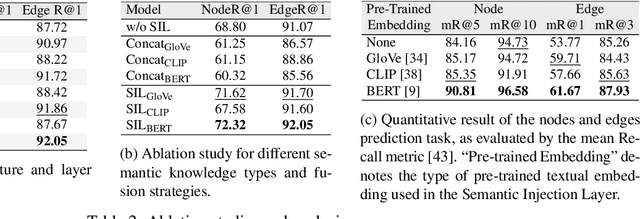
In this paper, we propose the semantic graph Transformer (SGT) for 3D scene graph generation. The task aims to parse a cloud point-based scene into a semantic structural graph, with the core challenge of modeling the complex global structure. Existing methods based on graph convolutional networks (GCNs) suffer from the over-smoothing dilemma and could only propagate information from limited neighboring nodes. In contrast, our SGT uses Transformer layers as the base building block to allow global information passing, with two types of proposed Transformer layers tailored for the 3D scene graph generation task. Specifically, we introduce the graph embedding layer to best utilize the global information in graph edges while maintaining comparable computation costs. Additionally, we propose the semantic injection layer to leverage categorical text labels and visual object knowledge. We benchmark our SGT on the established 3DSSG benchmark and achieve a 35.9% absolute improvement in relationship prediction's R@50 and an 80.4% boost on the subset with complex scenes over the state-of-the-art. Our analyses further show SGT's superiority in the long-tailed and zero-shot scenarios. We will release the code and model.
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Jan 11, 2023
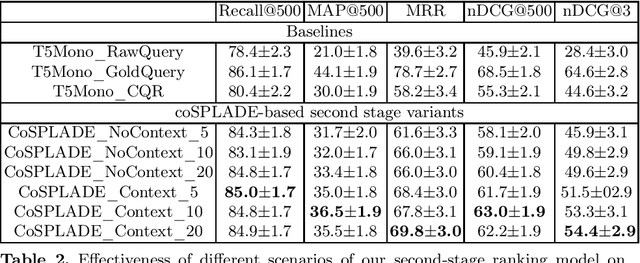
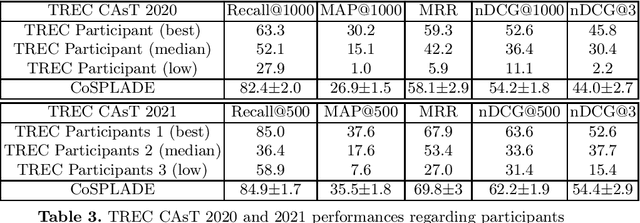
Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.
Causal Information Bottleneck Boosts Adversarial Robustness of Deep Neural Network
Oct 25, 2022

The information bottleneck (IB) method is a feasible defense solution against adversarial attacks in deep learning. However, this method suffers from the spurious correlation, which leads to the limitation of its further improvement of adversarial robustness. In this paper, we incorporate the causal inference into the IB framework to alleviate such a problem. Specifically, we divide the features obtained by the IB method into robust features (content information) and non-robust features (style information) via the instrumental variables to estimate the causal effects. With the utilization of such a framework, the influence of non-robust features could be mitigated to strengthen the adversarial robustness. We make an analysis of the effectiveness of our proposed method. The extensive experiments in MNIST, FashionMNIST, and CIFAR-10 show that our method exhibits the considerable robustness against multiple adversarial attacks. Our code would be released.
Specializing Multi-domain NMT via Penalizing Low Mutual Information
Oct 24, 2022
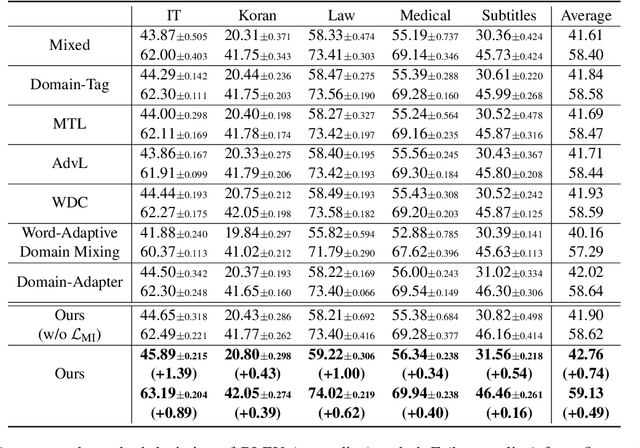
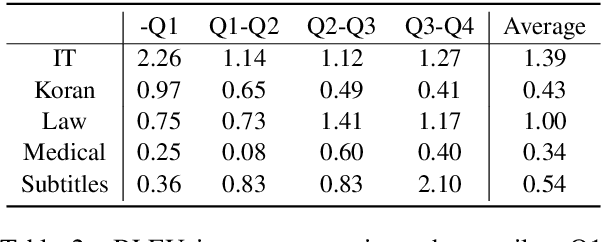
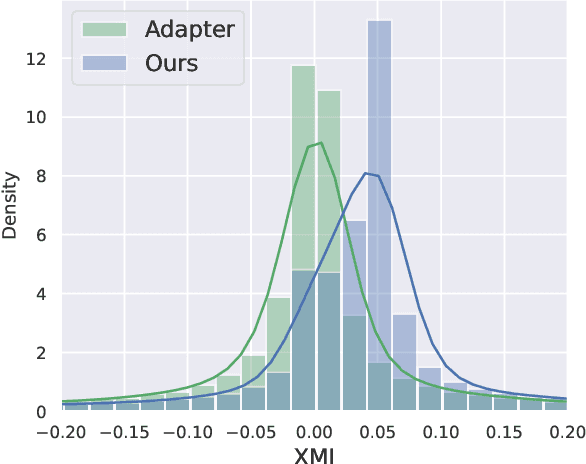
Multi-domain Neural Machine Translation (NMT) trains a single model with multiple domains. It is appealing because of its efficacy in handling multiple domains within one model. An ideal multi-domain NMT should learn distinctive domain characteristics simultaneously, however, grasping the domain peculiarity is a non-trivial task. In this paper, we investigate domain-specific information through the lens of mutual information (MI) and propose a new objective that penalizes low MI to become higher. Our method achieved the state-of-the-art performance among the current competitive multi-domain NMT models. Also, we empirically show our objective promotes low MI to be higher resulting in domain-specialized multi-domain NMT.
Self-supervised Learning with Speech Modulation Dropout
Mar 22, 2023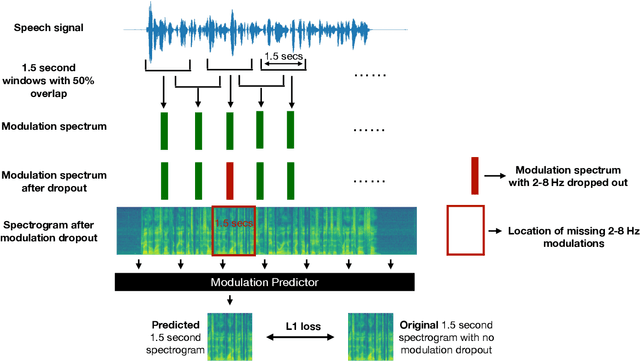

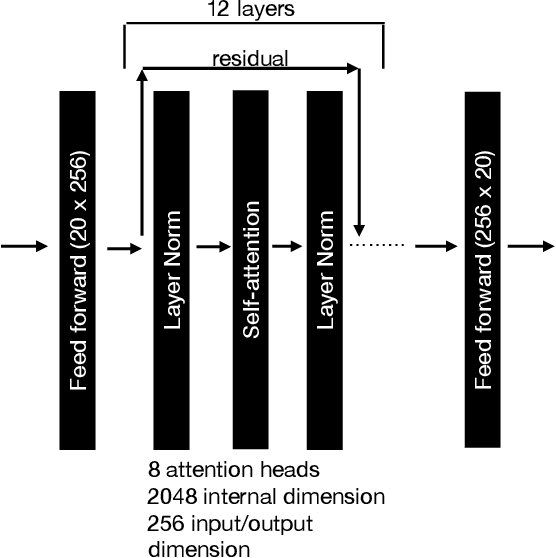
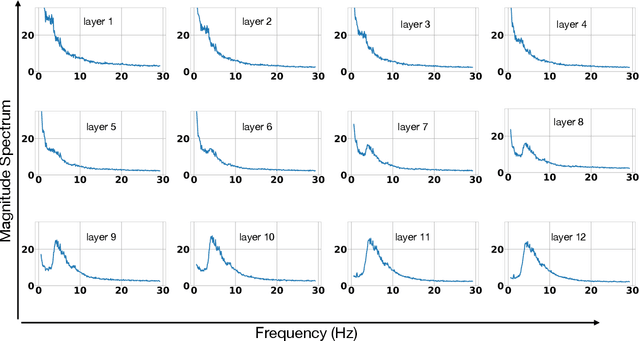
We show that training a multi-headed self-attention-based deep network to predict deleted, information-dense 2-8 Hz speech modulations over a 1.5-second section of a speech utterance is an effective way to make machines learn to extract speech modulations using time-domain contextual information. Our work exhibits that, once trained on large volumes of unlabelled data, the outputs of the self-attention layers vary in time with a modulation peak at 4 Hz. These pre-trained layers can be used to initialize parts of an Automatic Speech Recognition system to reduce its reliance on labeled speech data greatly.
smProbLog: Stable Model Semantics in ProbLog for Probabilistic Argumentation
Apr 17, 2023
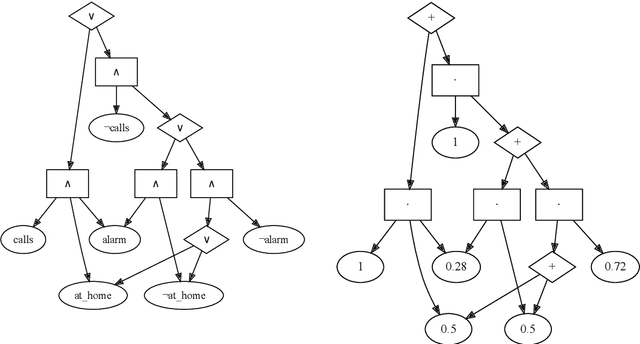

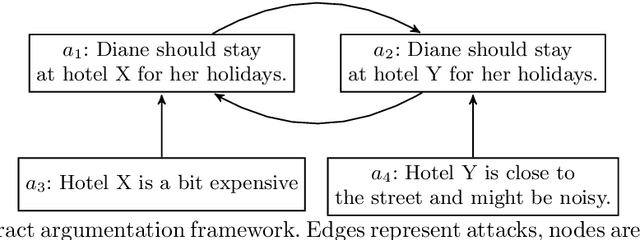
Argumentation problems are concerned with determining the acceptability of a set of arguments from their relational structure. When the available information is uncertain, probabilistic argumentation frameworks provide modelling tools to account for it. The first contribution of this paper is a novel interpretation of probabilistic argumentation frameworks as probabilistic logic programs. Probabilistic logic programs are logic programs in which some of the facts are annotated with probabilities. We show that the programs representing probabilistic argumentation frameworks do not satisfy a common assumption in probabilistic logic programming (PLP) semantics, which is, that probabilistic facts fully capture the uncertainty in the domain under investigation. The second contribution of this paper is then a novel PLP semantics for programs where a choice of probabilistic facts does not uniquely determine the truth assignment of the logical atoms. The third contribution of this paper is the implementation of a PLP system supporting this semantics: smProbLog. smProbLog is a novel PLP framework based on the probabilistic logic programming language ProbLog. smProbLog supports many inference and learning tasks typical of PLP, which, together with our first contribution, provide novel reasoning tools for probabilistic argumentation. We evaluate our approach with experiments analyzing the computational cost of the proposed algorithms and their application to a dataset of argumentation problems.
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
Apr 17, 2023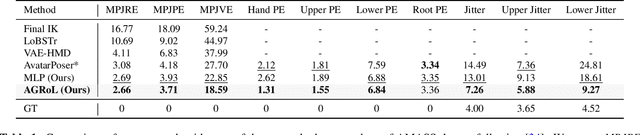
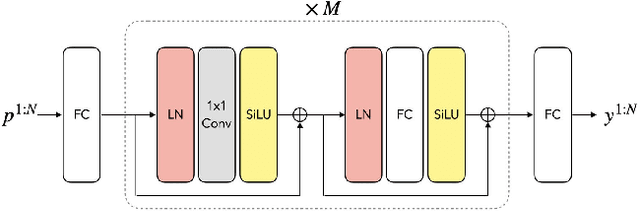
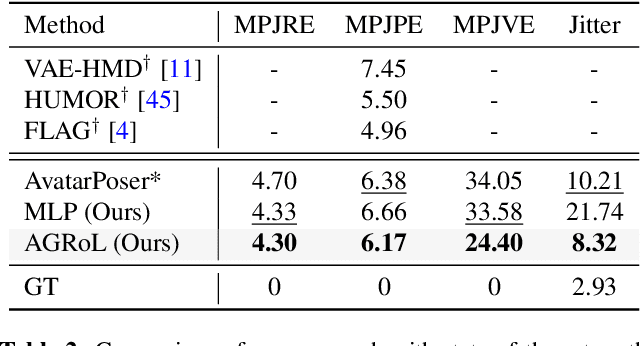
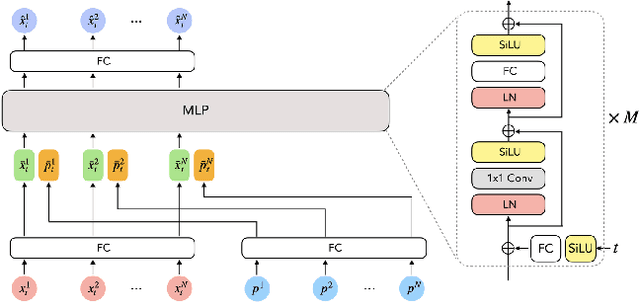
With the recent surge in popularity of AR/VR applications, realistic and accurate control of 3D full-body avatars has become a highly demanded feature. A particular challenge is that only a sparse tracking signal is available from standalone HMDs (Head Mounted Devices), often limited to tracking the user's head and wrists. While this signal is resourceful for reconstructing the upper body motion, the lower body is not tracked and must be synthesized from the limited information provided by the upper body joints. In this paper, we present AGRoL, a novel conditional diffusion model specifically designed to track full bodies given sparse upper-body tracking signals. Our model is based on a simple multi-layer perceptron (MLP) architecture and a novel conditioning scheme for motion data. It can predict accurate and smooth full-body motion, particularly the challenging lower body movement. Unlike common diffusion architectures, our compact architecture can run in real-time, making it suitable for online body-tracking applications. We train and evaluate our model on AMASS motion capture dataset, and demonstrate that our approach outperforms state-of-the-art methods in generated motion accuracy and smoothness. We further justify our design choices through extensive experiments and ablation studies.