 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024

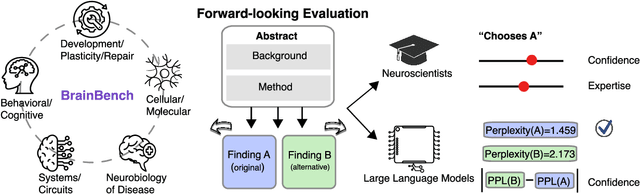
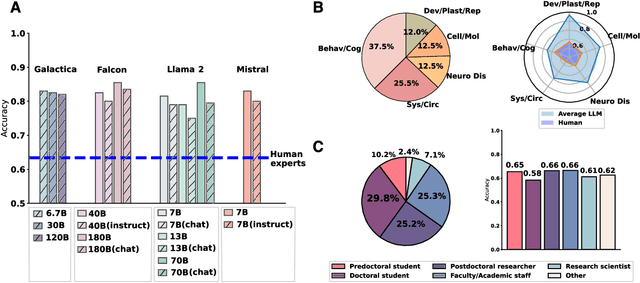
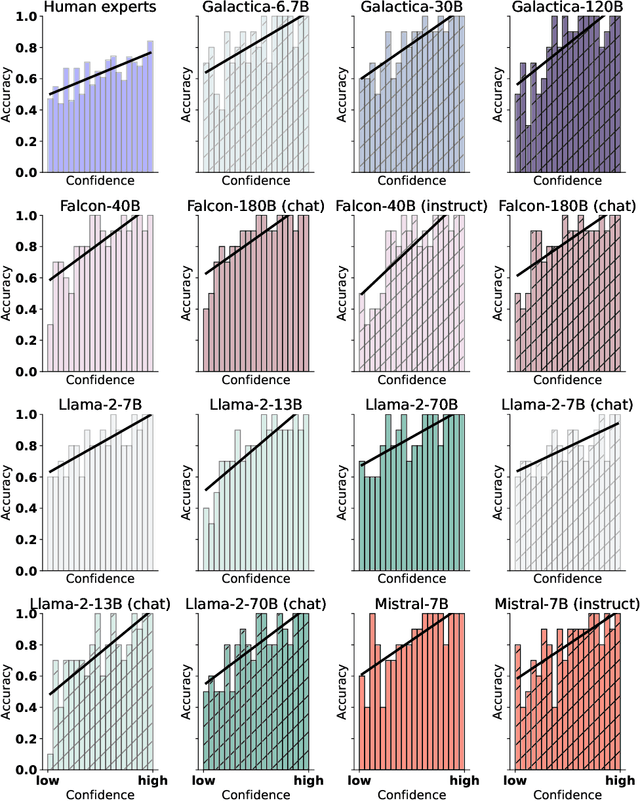
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Evaluating LLMs for Gender Disparities in Notable Persons
Mar 14, 2024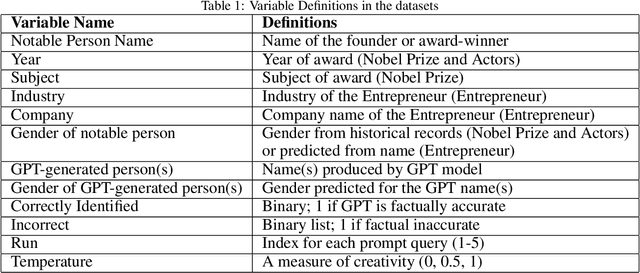
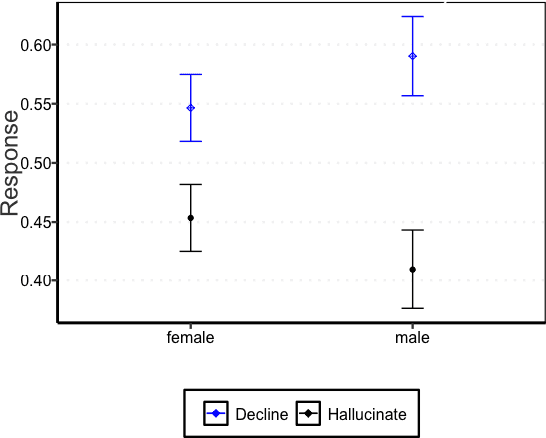
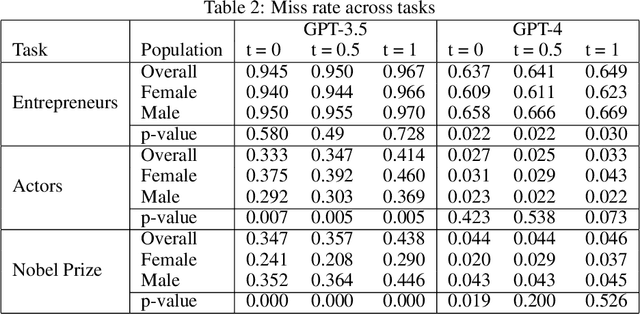
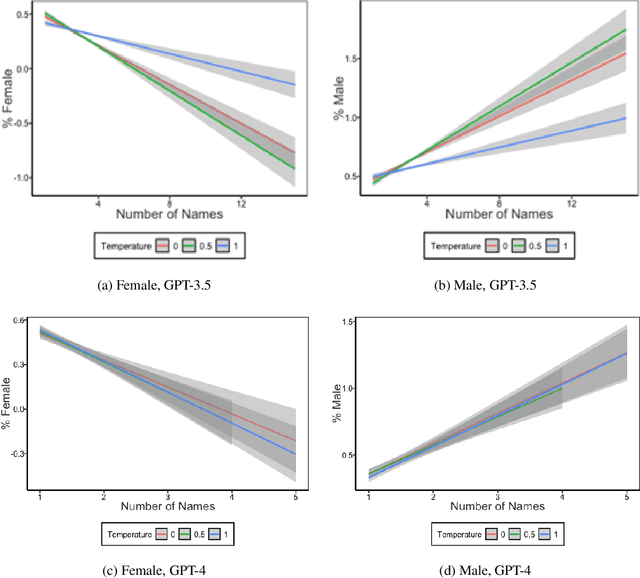
This study examines the use of Large Language Models (LLMs) for retrieving factual information, addressing concerns over their propensity to produce factually incorrect "hallucinated" responses or to altogether decline to even answer prompt at all. Specifically, it investigates the presence of gender-based biases in LLMs' responses to factual inquiries. This paper takes a multi-pronged approach to evaluating GPT models by evaluating fairness across multiple dimensions of recall, hallucinations and declinations. Our findings reveal discernible gender disparities in the responses generated by GPT-3.5. While advancements in GPT-4 have led to improvements in performance, they have not fully eradicated these gender disparities, notably in instances where responses are declined. The study further explores the origins of these disparities by examining the influence of gender associations in prompts and the homogeneity in the responses.
Knowledge of Pretrained Language Models on Surface Information of Tokens
Feb 22, 2024Do pretrained language models have knowledge regarding the surface information of tokens? We examined the surface information stored in word or subword embeddings acquired by pretrained language models from the perspectives of token length, substrings, and token constitution. Additionally, we evaluated the ability of models to generate knowledge regarding token surfaces. We focused on 12 pretrained language models that were mainly trained on English and Japanese corpora. Experimental results demonstrate that pretrained language models have knowledge regarding token length and substrings but not token constitution. Additionally, the results imply that there is a bottleneck on the decoder side in terms of effectively utilizing acquired knowledge.
3D Semantic Segmentation-Driven Representations for 3D Object Detection
Mar 11, 2024
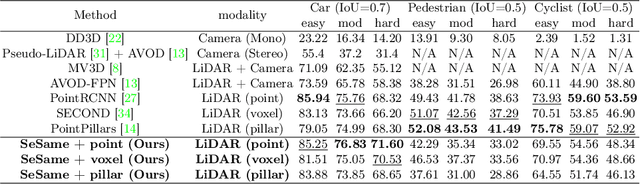

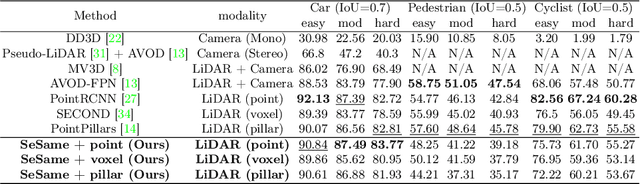
In autonomous driving, 3D detection provides more precise information to downstream tasks, including path planning and motion estimation, compared to 2D detection. Therefore, the need for 3D detection research has emerged. However, although single and multi-view images and depth maps obtained from the camera were used, detection accuracy was relatively low compared to other modality-based detectors due to the lack of geometric information. The proposed multi-modal 3D object detection combines semantic features obtained from images and geometric features obtained from point clouds, but there are difficulties in defining unified representation to fuse data existing in different domains and synchronization between them. In this paper, we propose SeSame : point-wise semantic feature as a new presentation to ensure sufficient semantic information of the existing LiDAR-only based 3D detection. Experiments show that our approach outperforms previous state-of-the-art at different levels of difficulty in car and performance improvement on the KITTI object detection benchmark. Our code is available at https://github.com/HAMA-DL-dev/SeSame
Progressive Divide-and-Conquer via Subsampling Decomposition for Accelerated MRI
Mar 15, 2024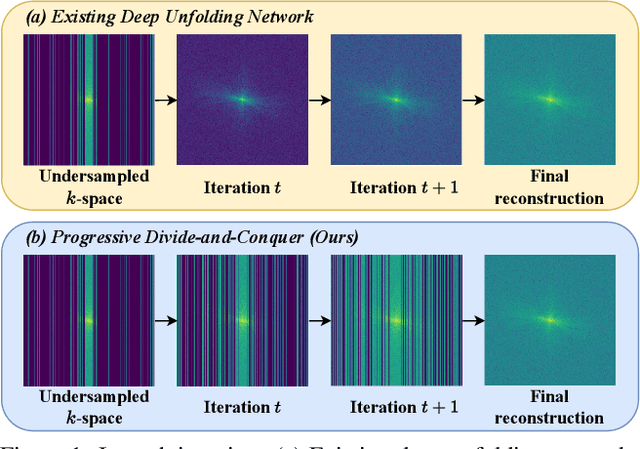
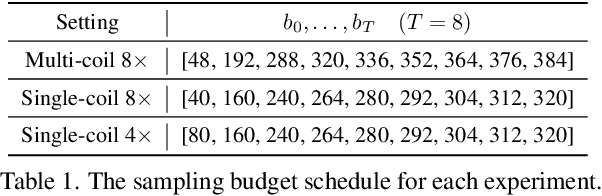
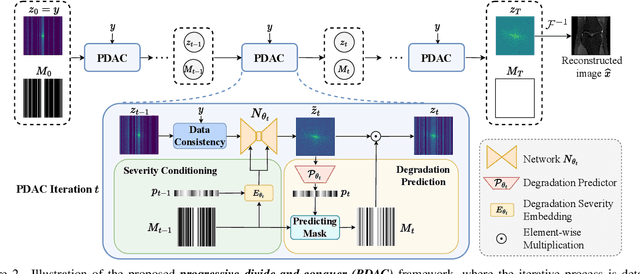
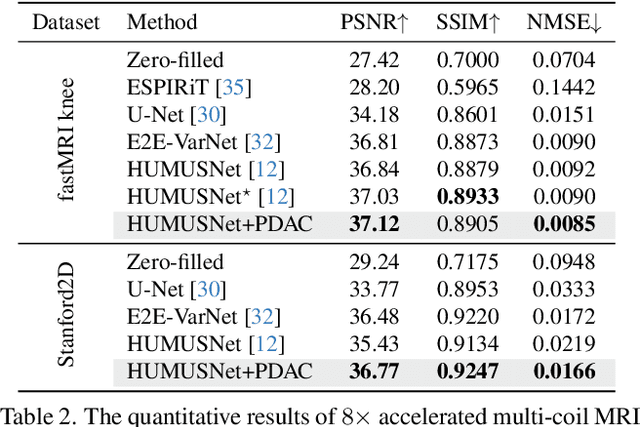
Deep unfolding networks (DUN) have emerged as a popular iterative framework for accelerated magnetic resonance imaging (MRI) reconstruction. However, conventional DUN aims to reconstruct all the missing information within the entire null space in each iteration. Thus it could be challenging when dealing with highly ill-posed degradation, usually leading to unsatisfactory reconstruction. In this work, we propose a Progressive Divide-And-Conquer (PDAC) strategy, aiming to break down the subsampling process in the actual severe degradation and thus perform reconstruction sequentially. Starting from decomposing the original maximum-a-posteriori problem of accelerated MRI, we present a rigorous derivation of the proposed PDAC framework, which could be further unfolded into an end-to-end trainable network. Specifically, each iterative stage in PDAC focuses on recovering a distinct moderate degradation according to the decomposition. Furthermore, as part of the PDAC iteration, such decomposition is adaptively learned as an auxiliary task through a degradation predictor which provides an estimation of the decomposed sampling mask. Following this prediction, the sampling mask is further integrated via a severity conditioning module to ensure awareness of the degradation severity at each stage. Extensive experiments demonstrate that our proposed method achieves superior performance on the publicly available fastMRI and Stanford2D FSE datasets in both multi-coil and single-coil settings.
Process-and-Forward: Deep Joint Source-Channel Coding Over Cooperative Relay Networks
Mar 15, 2024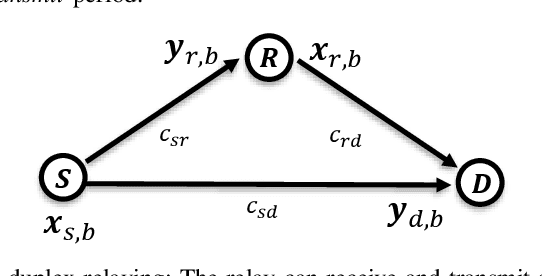
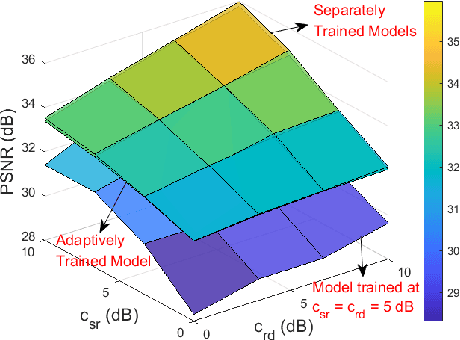

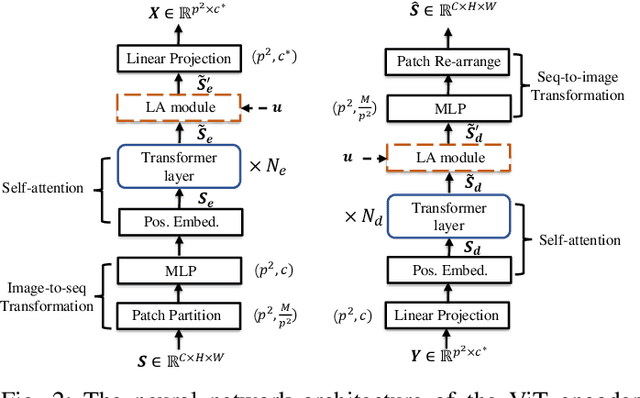
This paper introduces an innovative deep joint source-channel coding (DeepJSCC) approach to image transmission over a cooperative relay channel. The relay either amplifies and forwards a scaled version of its received signal, referred to as DeepJSCC-AF, or leverages neural networks to extract relevant features about the source signal before forwarding it to the destination, which we call DeepJSCC-PF (Process-and-Forward). In the full-duplex scheme, inspired by the block Markov coding (BMC) concept, we introduce a novel block transmission strategy built upon novel vision transformer architecture. In the proposed scheme, the source transmits information in blocks, and the relay updates its knowledge about the input signal after each block and generates its own signal to be conveyed to the destination. To enhance practicality, we introduce an adaptive transmission model, which allows a single trained DeepJSCC model to adapt seamlessly to various channel qualities, making it a versatile solution. Simulation results demonstrate the superior performance of our proposed DeepJSCC compared to the state-of-the-art BPG image compression algorithm, even when operating at the maximum achievable rate of conventional decode-and-forward and compress-and-forward protocols, for both half-duplex and full-duplex relay scenarios.
E4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024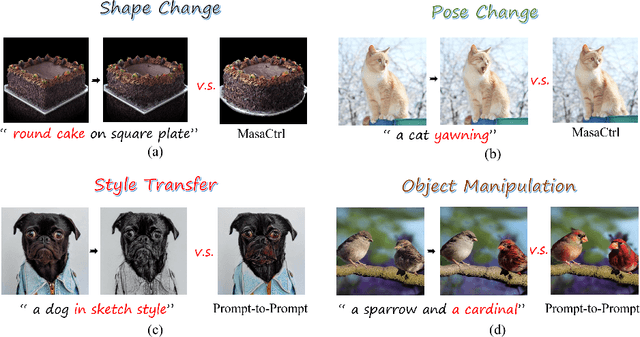
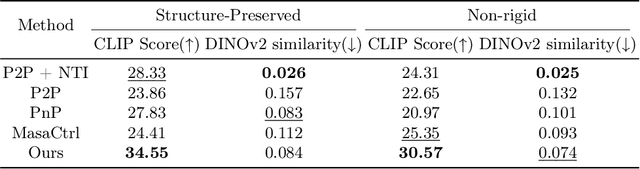
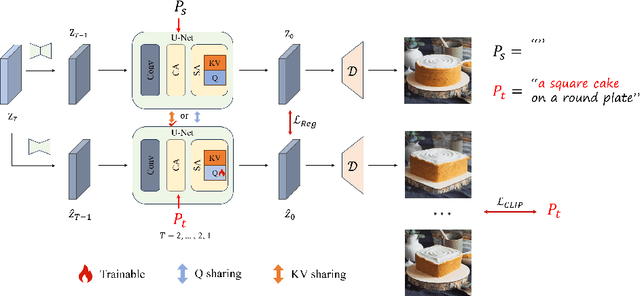

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Reconfigurable Robot Identification from Motion Data
Mar 15, 2024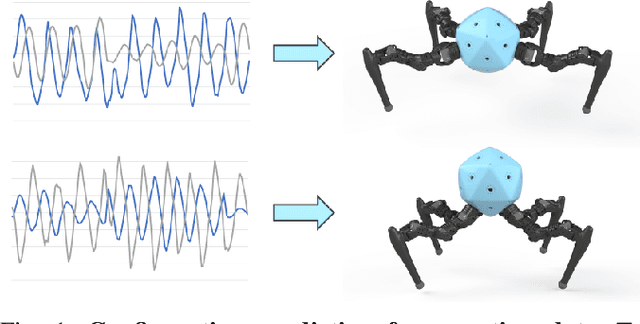
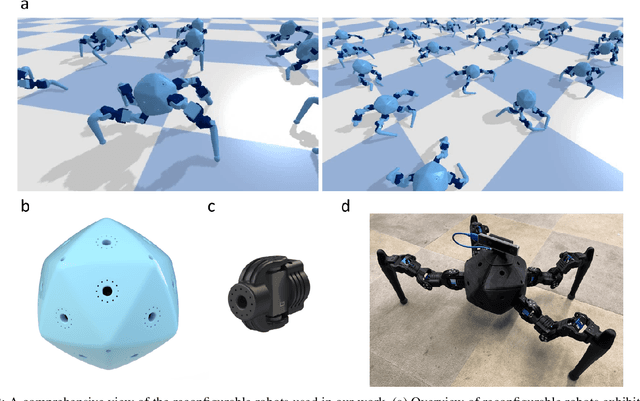
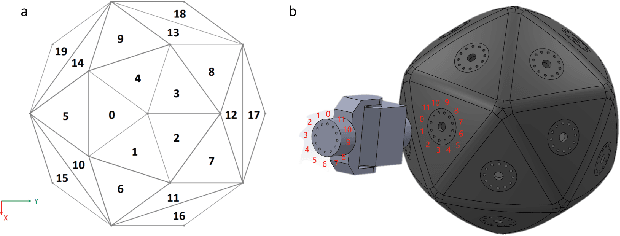
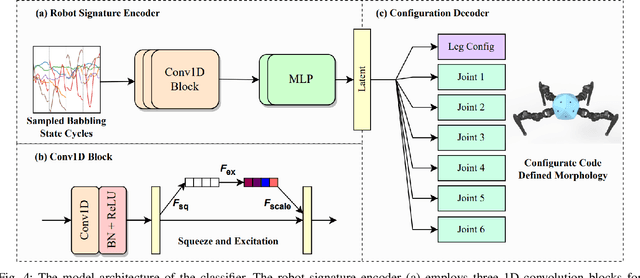
Integrating Large Language Models (VLMs) and Vision-Language Models (VLMs) with robotic systems enables robots to process and understand complex natural language instructions and visual information. However, a fundamental challenge remains: for robots to fully capitalize on these advancements, they must have a deep understanding of their physical embodiment. The gap between AI models cognitive capabilities and the understanding of physical embodiment leads to the following question: Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta self modeling that can deduce robot morphology through proprioception (the internal sense of position and movement). Our study introduces a 12 DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology. Utilizing a deep neural network model comprising a robot signature encoder and a configuration decoder, we demonstrate the capability of our system to accurately predict robot configurations from proprioceptive signals. This research contributes to the field of robotic self-modeling, aiming to enhance understanding of their physical embodiment and adaptability in real world scenarios.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 21, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation
Mar 11, 2024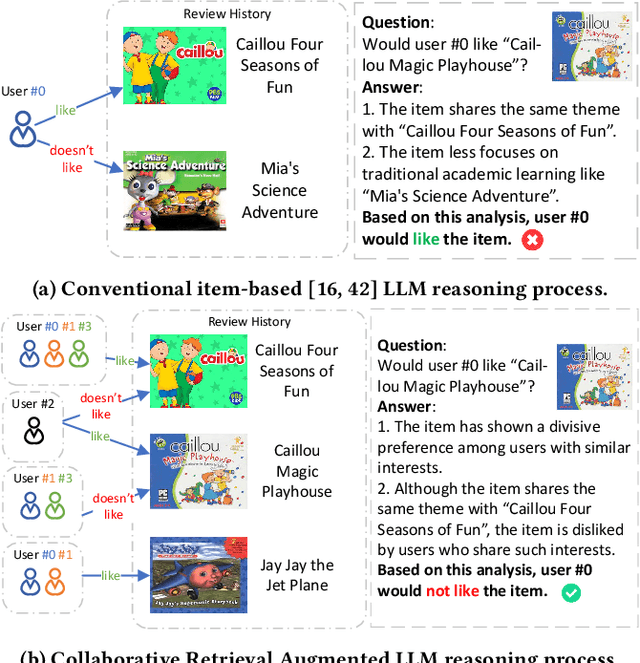
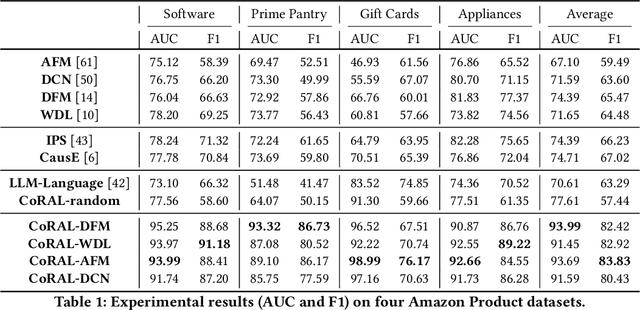
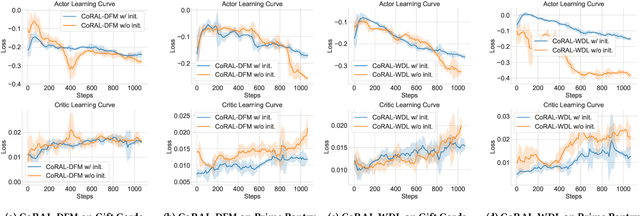
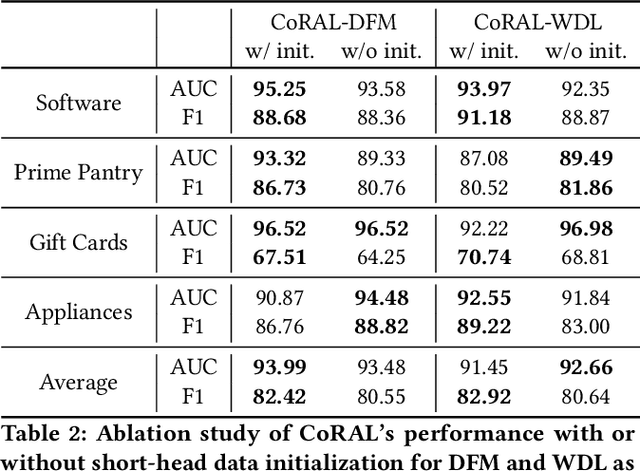
The long-tail recommendation is a challenging task for traditional recommender systems, due to data sparsity and data imbalance issues. The recent development of large language models (LLMs) has shown their abilities in complex reasoning, which can help to deduce users' preferences based on very few previous interactions. However, since most LLM-based systems rely on items' semantic meaning as the sole evidence for reasoning, the collaborative information of user-item interactions is neglected, which can cause the LLM's reasoning to be misaligned with task-specific collaborative information of the dataset. To further align LLMs' reasoning to task-specific user-item interaction knowledge, we introduce collaborative retrieval-augmented LLMs, CoRAL, which directly incorporate collaborative evidence into the prompts. Based on the retrieved user-item interactions, the LLM can analyze shared and distinct preferences among users, and summarize the patterns indicating which types of users would be attracted by certain items. The retrieved collaborative evidence prompts the LLM to align its reasoning with the user-item interaction patterns in the dataset. However, since the capacity of the input prompt is limited, finding the minimally-sufficient collaborative information for recommendation tasks can be challenging. We propose to find the optimal interaction set through a sequential decision-making process and develop a retrieval policy learned through a reinforcement learning (RL) framework, CoRAL. Our experimental results show that CoRAL can significantly improve LLMs' reasoning abilities on specific recommendation tasks. Our analysis also reveals that CoRAL can more efficiently explore collaborative information through reinforcement learning.