 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Diffusion Models for Unsupervised Video Anomaly Detection
Apr 12, 2023
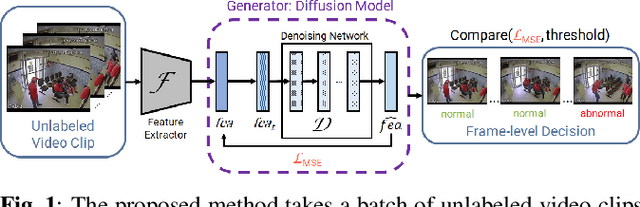

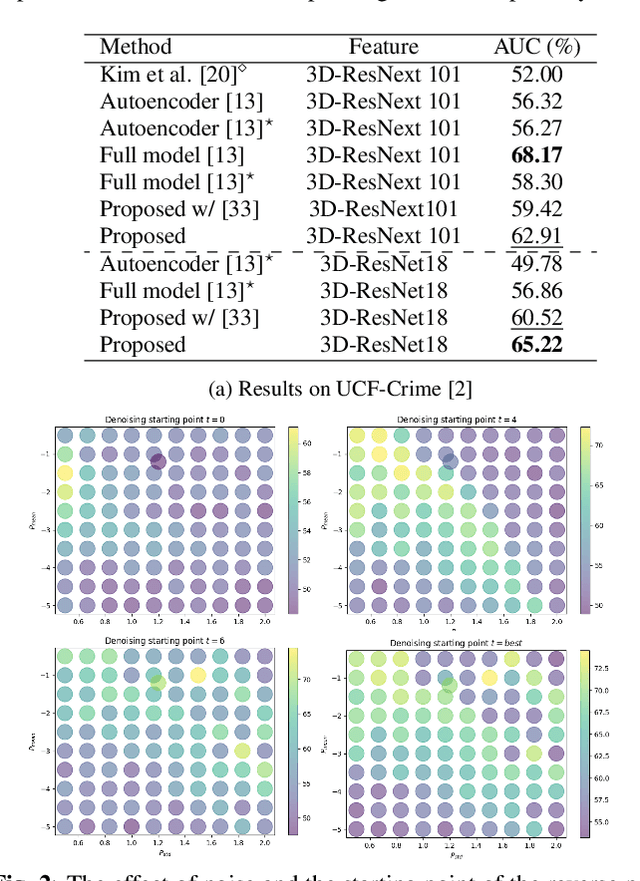
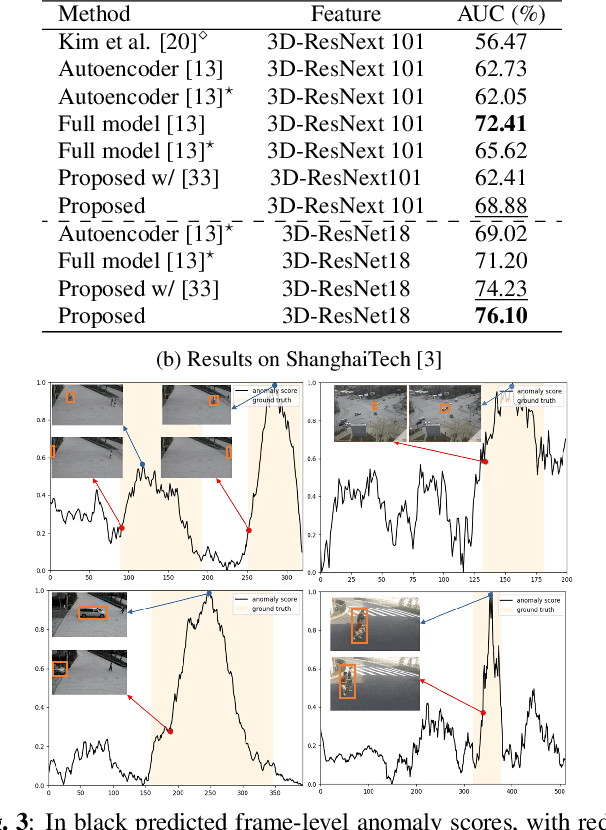
This paper investigates the performance of diffusion models for video anomaly detection (VAD) within the most challenging but also the most operational scenario in which the data annotations are not used. As being sparse, diverse, contextual, and often ambiguous, detecting abnormal events precisely is a very ambitious task. To this end, we rely only on the information-rich spatio-temporal data, and the reconstruction power of the diffusion models such that a high reconstruction error is utilized to decide the abnormality. Experiments performed on two large-scale video anomaly detection datasets demonstrate the consistent improvement of the proposed method over the state-of-the-art generative models while in some cases our method achieves better scores than the more complex models. This is the first study using a diffusion model and examining its parameters' influence to present guidance for VAD in surveillance scenarios.
ALADIN-NST: Self-supervised disentangled representation learning of artistic style through Neural Style Transfer
Apr 12, 2023
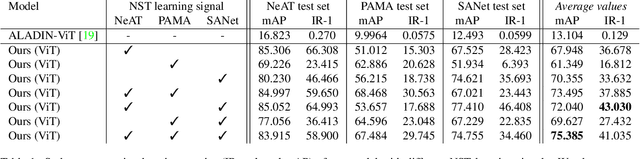
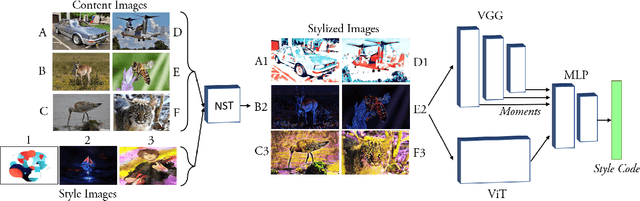
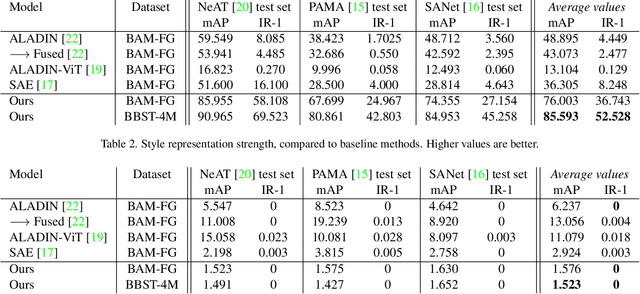
Representation learning aims to discover individual salient features of a domain in a compact and descriptive form that strongly identifies the unique characteristics of a given sample respective to its domain. Existing works in visual style representation literature have tried to disentangle style from content during training explicitly. A complete separation between these has yet to be fully achieved. Our paper aims to learn a representation of visual artistic style more strongly disentangled from the semantic content depicted in an image. We use Neural Style Transfer (NST) to measure and drive the learning signal and achieve state-of-the-art representation learning on explicitly disentangled metrics. We show that strongly addressing the disentanglement of style and content leads to large gains in style-specific metrics, encoding far less semantic information and achieving state-of-the-art accuracy in downstream multimodal applications.
Bi-level Latent Variable Model for Sample-Efficient Multi-Agent Reinforcement Learning
Apr 12, 2023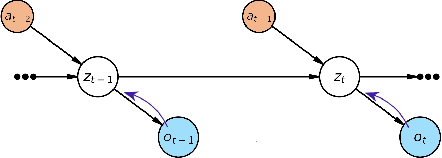
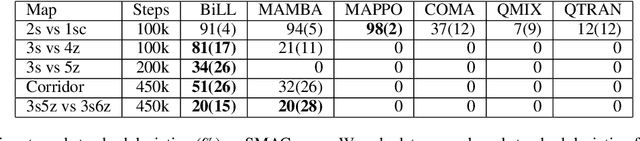
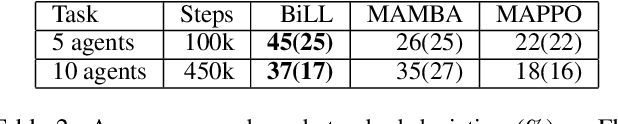
Despite their potential in real-world applications, multi-agent reinforcement learning (MARL) algorithms often suffer from high sample complexity. To address this issue, we present a novel model-based MARL algorithm, BiLL (Bi-Level Latent Variable Model-based Learning), that learns a bi-level latent variable model from high-dimensional inputs. At the top level, the model learns latent representations of the global state, which encode global information relevant to behavior learning. At the bottom level, it learns latent representations for each agent, given the global latent representations from the top level. The model generates latent trajectories to use for policy learning. We evaluate our algorithm on complex multi-agent tasks in the challenging SMAC and Flatland environments. Our algorithm outperforms state-of-the-art model-free and model-based baselines in sample efficiency, including on two extremely challenging Super Hard SMAC maps.
Spatio-Temporal Pixel-Level Contrastive Learning-based Source-Free Domain Adaptation for Video Semantic Segmentation
Mar 25, 2023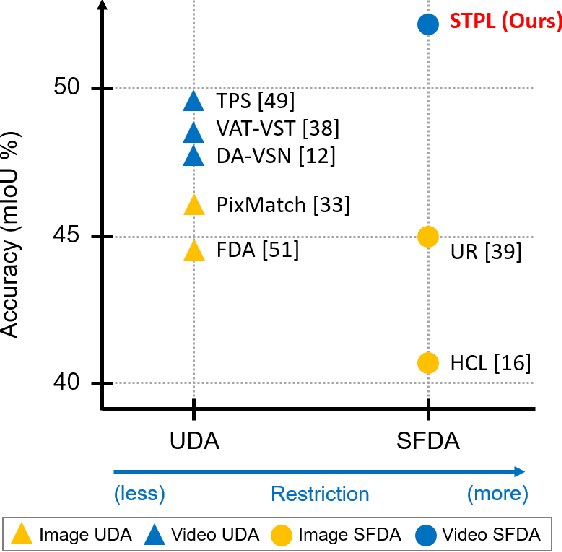

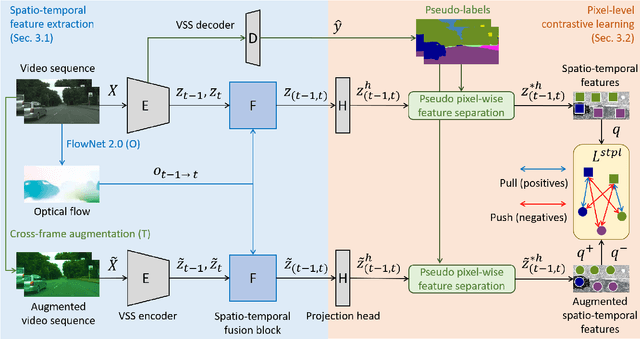
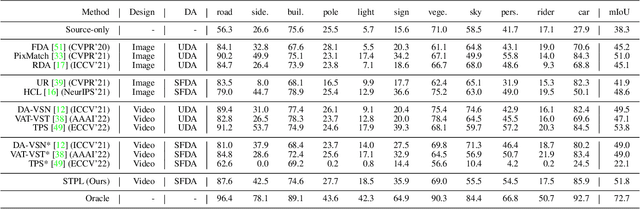
Unsupervised Domain Adaptation (UDA) of semantic segmentation transfers labeled source knowledge to an unlabeled target domain by relying on accessing both the source and target data. However, the access to source data is often restricted or infeasible in real-world scenarios. Under the source data restrictive circumstances, UDA is less practical. To address this, recent works have explored solutions under the Source-Free Domain Adaptation (SFDA) setup, which aims to adapt a source-trained model to the target domain without accessing source data. Still, existing SFDA approaches use only image-level information for adaptation, making them sub-optimal in video applications. This paper studies SFDA for Video Semantic Segmentation (VSS), where temporal information is leveraged to address video adaptation. Specifically, we propose Spatio-Temporal Pixel-Level (STPL) contrastive learning, a novel method that takes full advantage of spatio-temporal information to tackle the absence of source data better. STPL explicitly learns semantic correlations among pixels in the spatio-temporal space, providing strong self-supervision for adaptation to the unlabeled target domain. Extensive experiments show that STPL achieves state-of-the-art performance on VSS benchmarks compared to current UDA and SFDA approaches. Code is available at: https://github.com/shaoyuanlo/STPL
Soft Dynamic Time Warping for Multi-Pitch Estimation and Beyond
Apr 11, 2023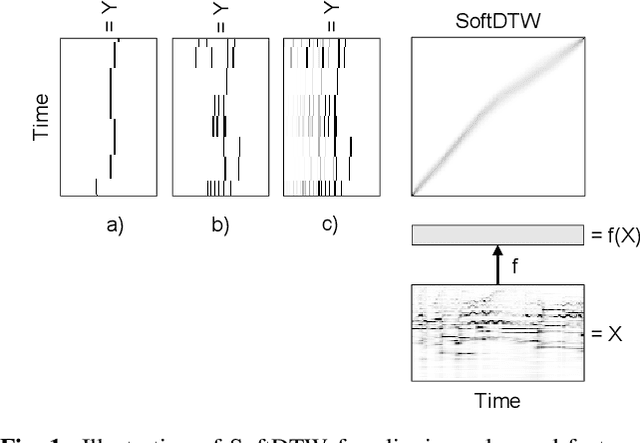
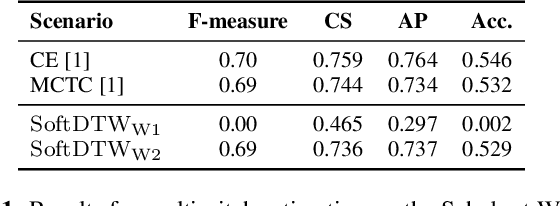
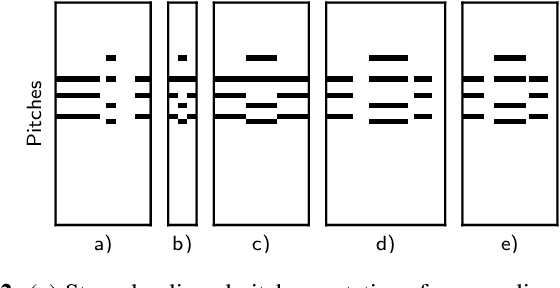
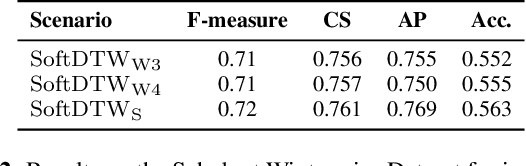
Many tasks in music information retrieval (MIR) involve weakly aligned data, where exact temporal correspondences are unknown. The connectionist temporal classification (CTC) loss is a standard technique to learn feature representations based on weakly aligned training data. However, CTC is limited to discrete-valued target sequences and can be difficult to extend to multi-label problems. In this article, we show how soft dynamic time warping (SoftDTW), a differentiable variant of classical DTW, can be used as an alternative to CTC. Using multi-pitch estimation as an example scenario, we show that SoftDTW yields results on par with a state-of-the-art multi-label extension of CTC. In addition to being more elegant in terms of its algorithmic formulation, SoftDTW naturally extends to real-valued target sequences.
ShapeShift: Superquadric-based Object Pose Estimation for Robotic Grasping
Apr 10, 2023
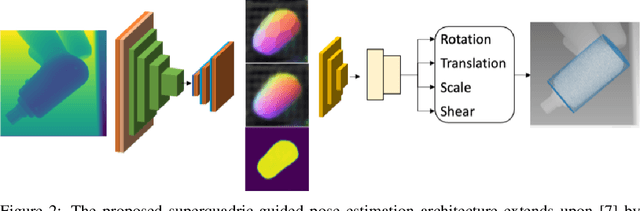
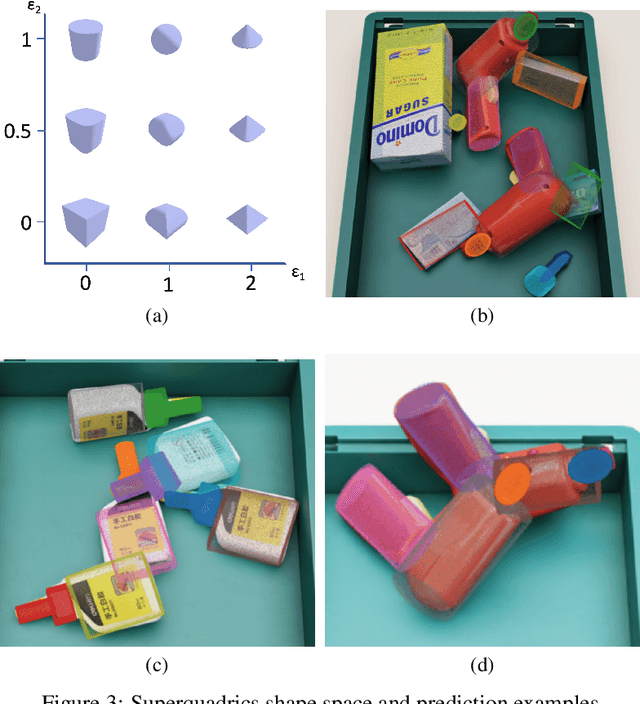
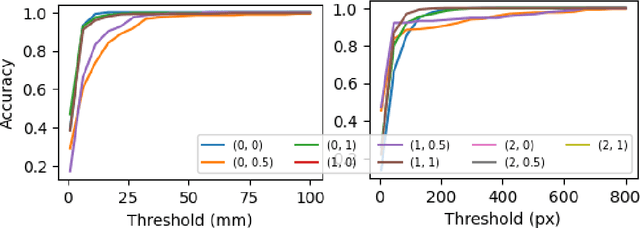
Object pose estimation is a critical task in robotics for precise object manipulation. However, current techniques heavily rely on a reference 3D object, limiting their generalizability and making it expensive to expand to new object categories. Direct pose predictions also provide limited information for robotic grasping without referencing the 3D model. Keypoint-based methods offer intrinsic descriptiveness without relying on an exact 3D model, but they may lack consistency and accuracy. To address these challenges, this paper proposes ShapeShift, a superquadric-based framework for object pose estimation that predicts the object's pose relative to a primitive shape which is fitted to the object. The proposed framework offers intrinsic descriptiveness and the ability to generalize to arbitrary geometric shapes beyond the training set.
DASS Good: Explainable Data Mining of Spatial Cohort Data
Apr 10, 2023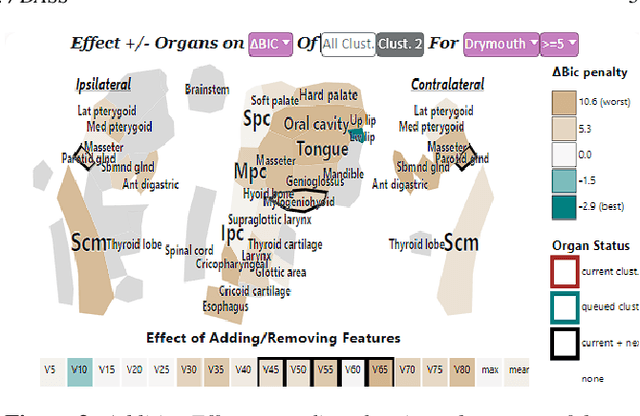
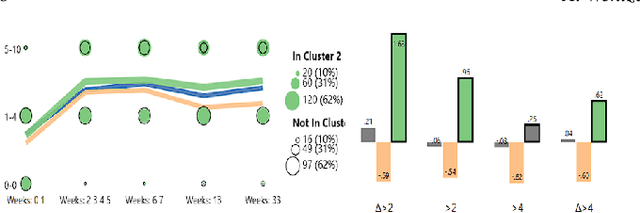
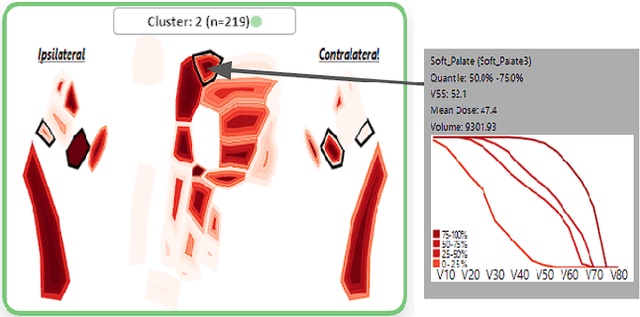
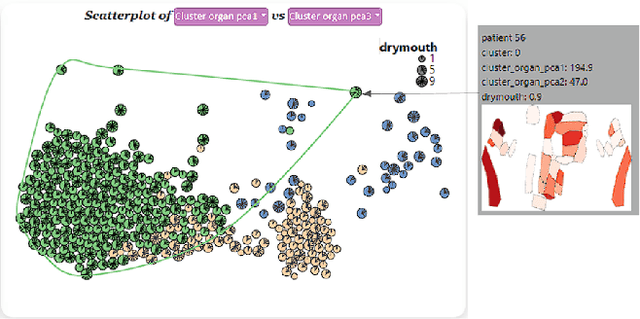
Developing applicable clinical machine learning models is a difficult task when the data includes spatial information, for example, radiation dose distributions across adjacent organs at risk. We describe the co-design of a modeling system, DASS, to support the hybrid human-machine development and validation of predictive models for estimating long-term toxicities related to radiotherapy doses in head and neck cancer patients. Developed in collaboration with domain experts in oncology and data mining, DASS incorporates human-in-the-loop visual steering, spatial data, and explainable AI to augment domain knowledge with automatic data mining. We demonstrate DASS with the development of two practical clinical stratification models and report feedback from domain experts. Finally, we describe the design lessons learned from this collaborative experience.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023
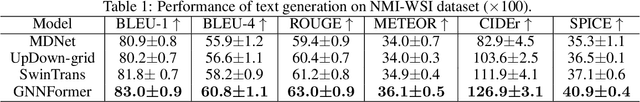
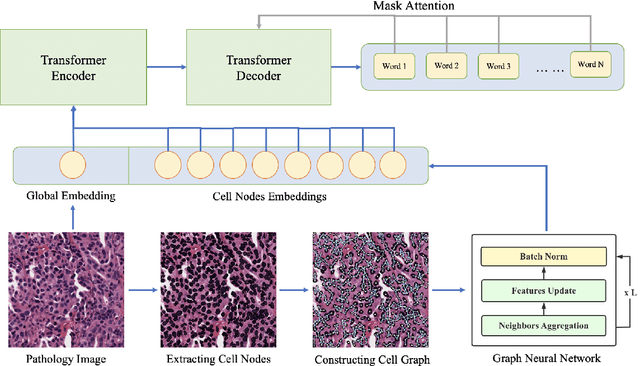
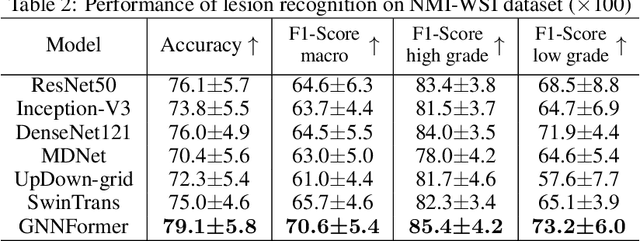
Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
Can Shadows Reveal Biometric Information?
Sep 21, 2022
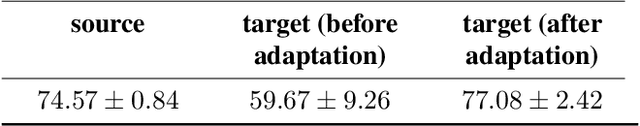


We study the problem of extracting biometric information of individuals by looking at shadows of objects cast on diffuse surfaces. We show that the biometric information leakage from shadows can be sufficient for reliable identity inference under representative scenarios via a maximum likelihood analysis. We then develop a learning-based method that demonstrates this phenomenon in real settings, exploiting the subtle cues in the shadows that are the source of the leakage without requiring any labeled real data. In particular, our approach relies on building synthetic scenes composed of 3D face models obtained from a single photograph of each identity. We transfer what we learn from the synthetic data to the real data using domain adaptation in a completely unsupervised way. Our model is able to generalize well to the real domain and is robust to several variations in the scenes. We report high classification accuracies in an identity classification task that takes place in a scene with unknown geometry and occluding objects.
Language Agnostic Multilingual Information Retrieval with Contrastive Learning
Oct 12, 2022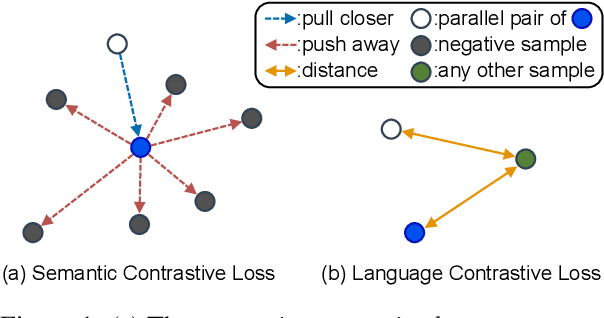
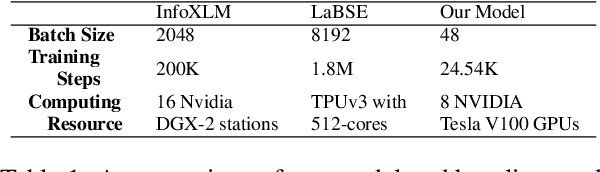
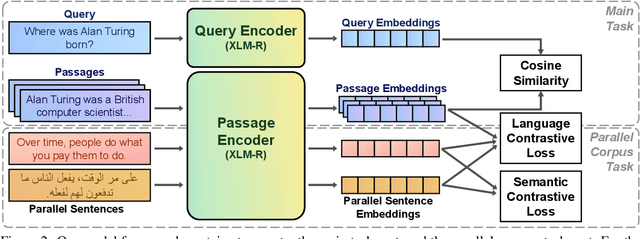
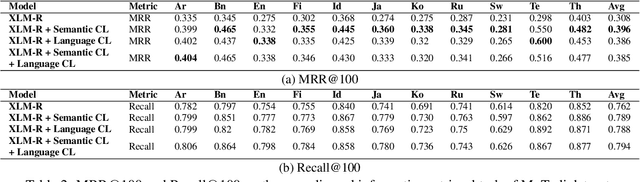
Multilingual information retrieval is challenging due to the lack of training datasets for many low-resource languages. We present an effective method by leveraging parallel and non-parallel corpora to improve the pretrained multilingual language models' cross-lingual transfer ability for information retrieval. We design the semantic contrastive loss as regular contrastive learning to improve the cross-lingual alignment of parallel sentence pairs, and we propose a new contrastive loss, the language contrastive loss, to leverage both parallel corpora and non-parallel corpora to further improve multilingual representation learning. We train our model on an English information retrieval dataset, and test its zero-shot transfer ability to other languages. Our experiment results show that our method brings significant improvement to prior work on retrieval performance, while it requires much less computational effort. Our model can work well even with a small number of parallel corpora. And it can be used as an add-on module to any backbone and other tasks. Our code is available at: https://github.com/xiyanghu/multilingualIR.