 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Exploration for Effective Multi-agent Q-Learning
Apr 19, 2023
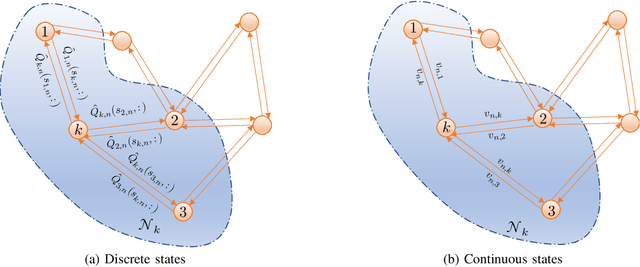
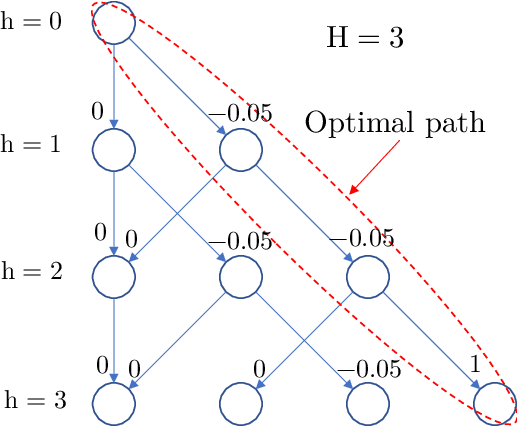
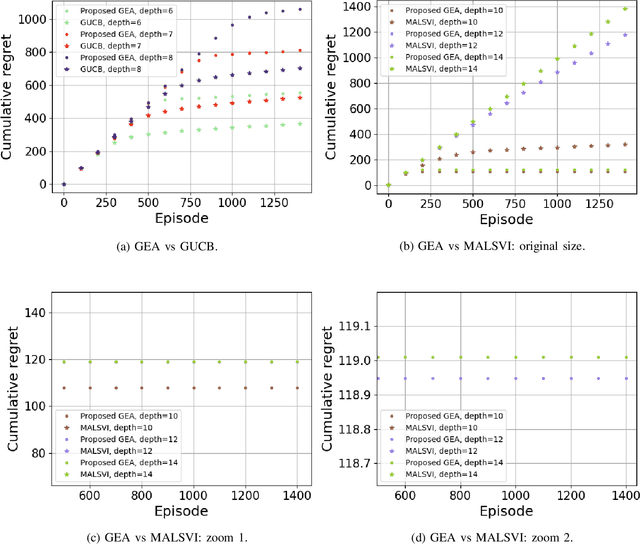
This paper proposes an exploration technique for multi-agent reinforcement learning (MARL) with graph-based communication among agents. We assume the individual rewards received by the agents are independent of the actions by the other agents, while their policies are coupled. In the proposed framework, neighbouring agents collaborate to estimate the uncertainty about the state-action space in order to execute more efficient explorative behaviour. Different from existing works, the proposed algorithm does not require counting mechanisms and can be applied to continuous-state environments without requiring complex conversion techniques. Moreover, the proposed scheme allows agents to communicate in a fully decentralized manner with minimal information exchange. And for continuous-state scenarios, each agent needs to exchange only a single parameter vector. The performance of the algorithm is verified with theoretical results for discrete-state scenarios and with experiments for continuous ones.
LEO-PNT With Starlink: Development of a Burst Detection Algorithm Based on Signal Measurements
Apr 19, 2023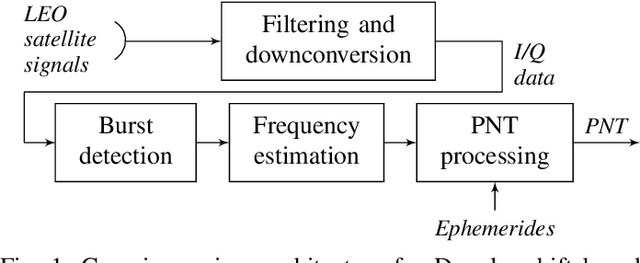
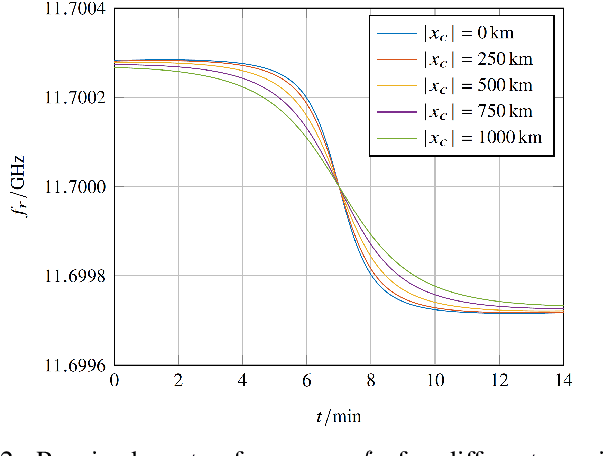
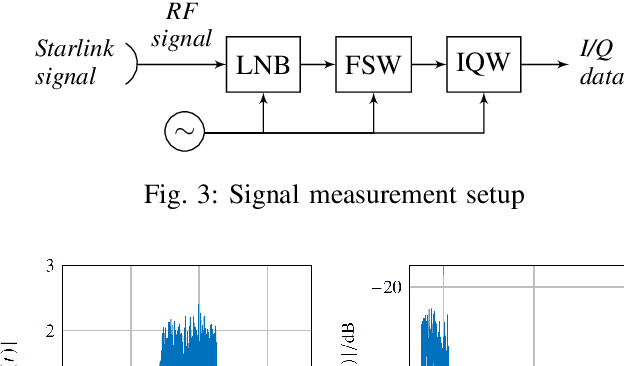
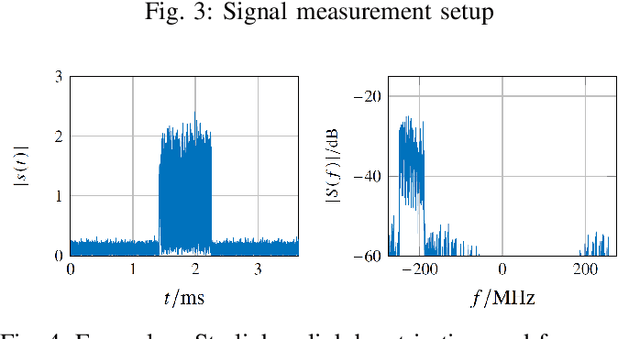
Due to the strong dependency of our societies onGlobal Navigation Satellite Systems and their vulnerability to outages, there is an urgent need for additional navigation systems. A possible approach for such an additional system uses the communication signals of the emerging LEO satellite mega-constellations as signals of opportunity. The Doppler shift of those signals is leveraged to calculate positioning, navigation and timing information. Therefore the signals have to be detected and the frequency has to be estimated. In this paper, we present the results of Starlink signal measurements. The results are used to develope a novel correlation-based detection algorithm for Starlink burst signals. The carrier frequency of the detected bursts is measured and the attainable positioning accuracy is estimated. It is shown, that the presented algorithms are applicable for a navigation solution in an operationally relevant setup using an omnidirectional antenna.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 18, 2023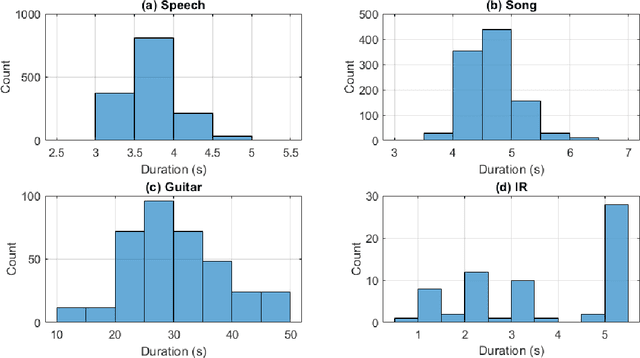
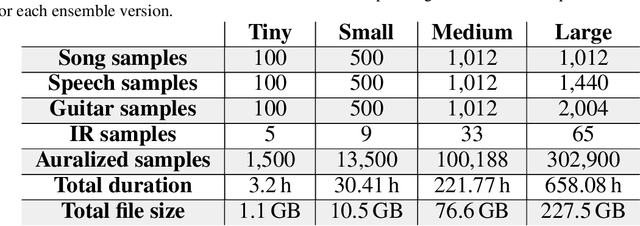
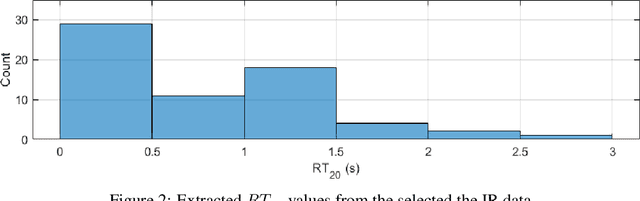
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Incremental Image Labeling via Iterative Refinement
Apr 18, 2023Data quality is critical for multimedia tasks, while various types of systematic flaws are found in image benchmark datasets, as discussed in recent work. In particular, the existence of the semantic gap problem leads to a many-to-many mapping between the information extracted from an image and its linguistic description. This unavoidable bias further leads to poor performance on current computer vision tasks. To address this issue, we introduce a Knowledge Representation (KR)-based methodology to provide guidelines driving the labeling process, thereby indirectly introducing intended semantics in ML models. Specifically, an iterative refinement-based annotation method is proposed to optimize data labeling by organizing objects in a classification hierarchy according to their visual properties, ensuring that they are aligned with their linguistic descriptions. Preliminary results verify the effectiveness of the proposed method.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023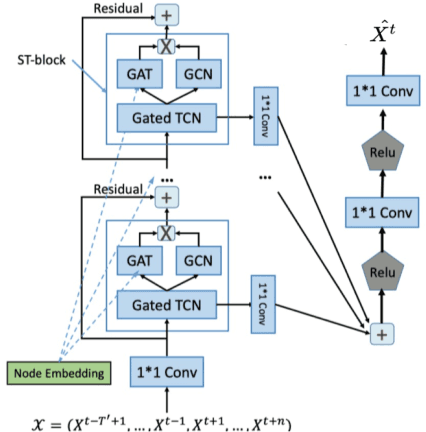
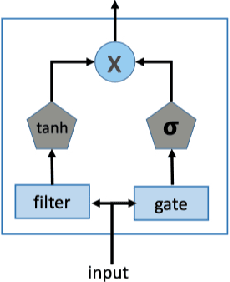

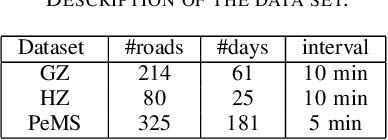
Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
Creating Large Language Model Resistant Exams: Guidelines and Strategies
Apr 18, 2023The proliferation of Large Language Models (LLMs), such as ChatGPT, has raised concerns about their potential impact on academic integrity, prompting the need for LLM-resistant exam designs. This article investigates the performance of LLMs on exams and their implications for assessment, focusing on ChatGPT's abilities and limitations. We propose guidelines for creating LLM-resistant exams, including content moderation, deliberate inaccuracies, real-world scenarios beyond the model's knowledge base, effective distractor options, evaluating soft skills, and incorporating non-textual information. The article also highlights the significance of adapting assessments to modern tools and promoting essential skills development in students. By adopting these strategies, educators can maintain academic integrity while ensuring that assessments accurately reflect contemporary professional settings and address the challenges and opportunities posed by artificial intelligence in education.
Solar Photovoltaic Systems Metadata Inference and Differentially Private Publication
Apr 07, 2023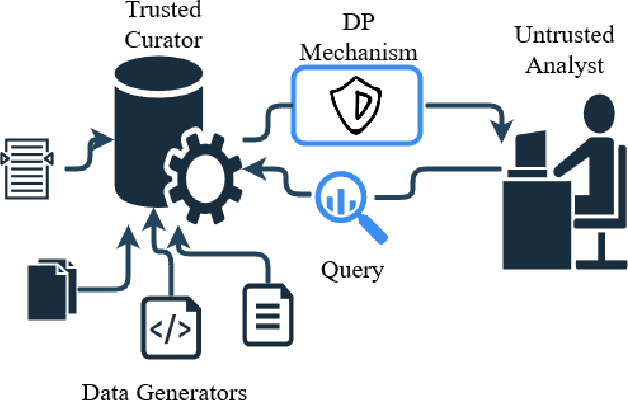
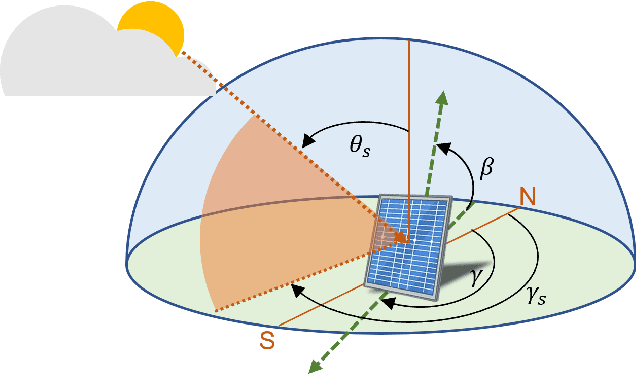
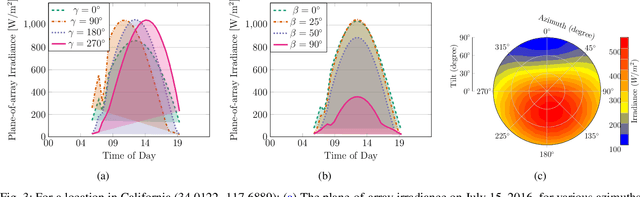
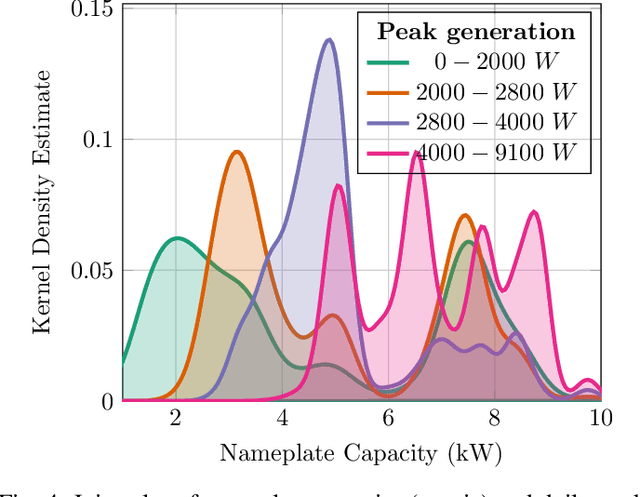
Stakeholders in electricity delivery infrastructure are amassing data about their system demand, use, and operations. Still, they are reluctant to share them, as even sharing aggregated or anonymized electric grid data risks the disclosure of sensitive information. This paper highlights how applying differential privacy to distributed energy resource production data can preserve the usefulness of that data for operations, planning, and research purposes without violating privacy constraints. Differentially private mechanisms can be optimized for queries of interest in the energy sector, with provable privacy and accuracy trade-offs, and can help design differentially private databases for further analysis and research. In this paper, we consider the problem of inference and publication of solar photovoltaic systems' metadata. Metadata such as nameplate capacity, surface azimuth and surface tilt may reveal personally identifiable information regarding the installation behind-the-meter. We describe a methodology to infer the metadata and propose a mechanism based on Bayesian optimization to publish the inferred metadata in a differentially private manner. The proposed mechanism is numerically validated using real-world solar power generation data.
Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Oct 24, 2022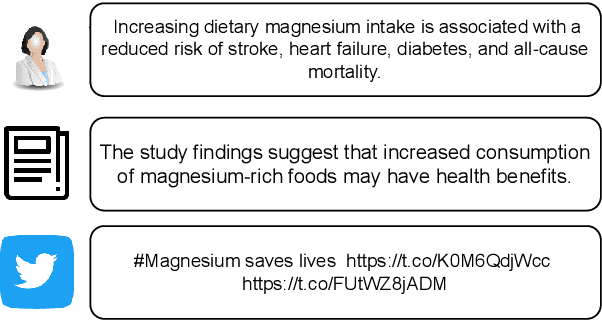


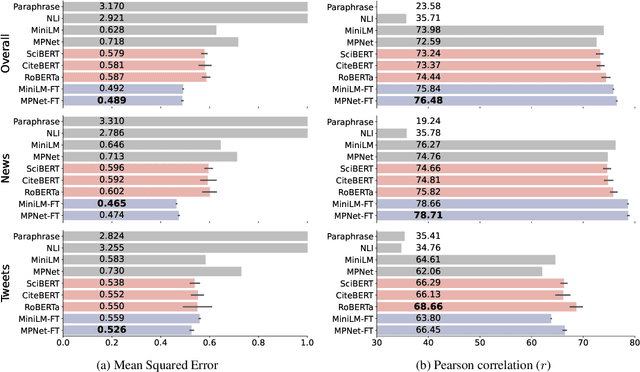
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically identifying paraphrased scientific findings could enable large-scale tracking and analysis of information changes in the science communication process, but this requires systems to understand the similarity between scientific information across multiple domains. To this end, we present the SCIENTIFIC PARAPHRASE AND INFORMATION CHANGE DATASET (SPICED), the first paraphrase dataset of scientific findings annotated for degree of information change. SPICED contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. We demonstrate that SPICED poses a challenging task and that models trained on SPICED improve downstream performance on evidence retrieval for fact checking of real-world scientific claims. Finally, we show that models trained on SPICED can reveal large-scale trends in the degrees to which people and organizations faithfully communicate new scientific findings. Data, code, and pre-trained models are available at http://www.copenlu.com/publication/2022_emnlp_wright/.
RDMNet: Reliable Dense Matching Based Point Cloud Registration for Autonomous Driving
Mar 31, 2023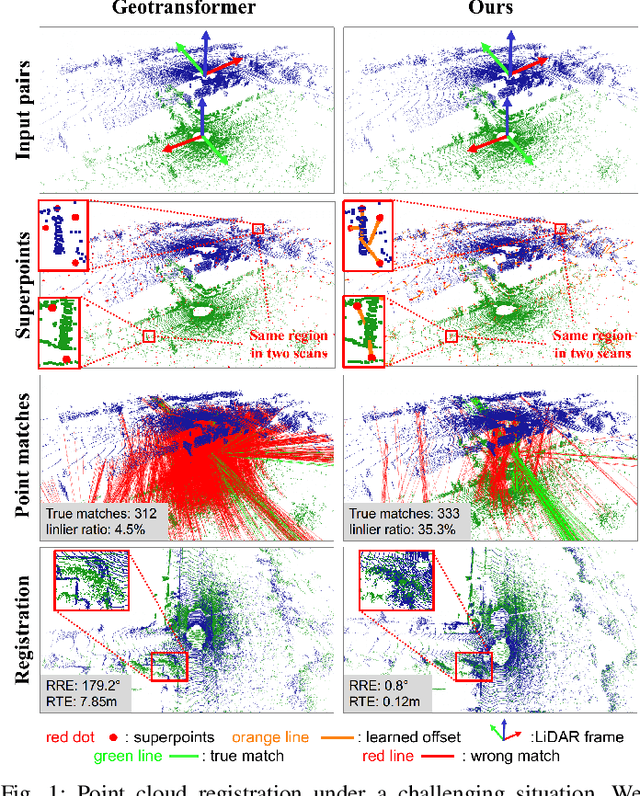
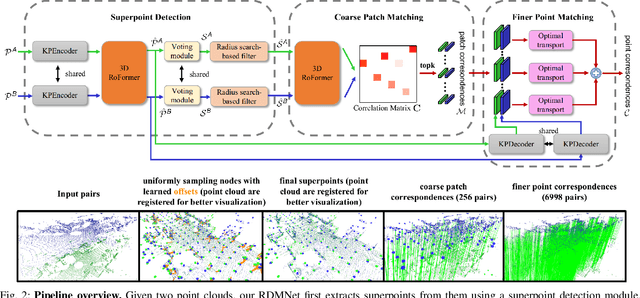
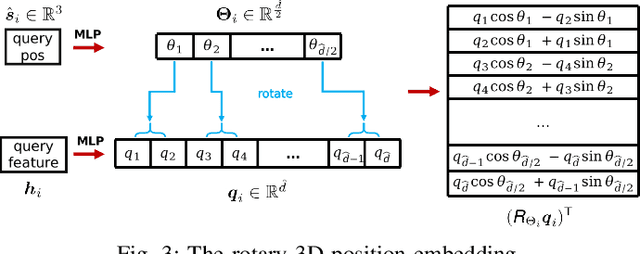
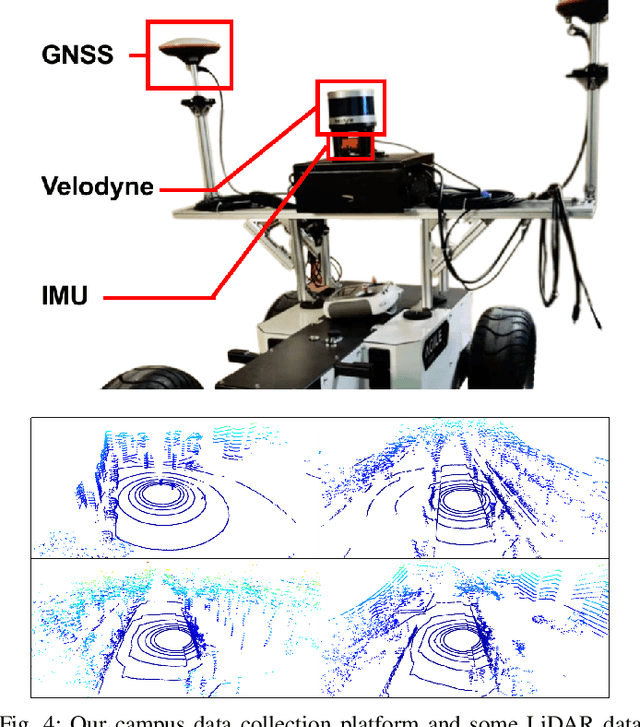
Point cloud registration is an important task in robotics and autonomous driving to estimate the ego-motion of the vehicle. Recent advances following the coarse-to-fine manner show promising potential in point cloud registration. However, existing methods rely on good superpoint correspondences, which are hard to be obtained reliably and efficiently, thus resulting in less robust and accurate point cloud registration. In this paper, we propose a novel network, named RDMNet, to find dense point correspondences coarse-to-fine and improve final pose estimation based on such reliable correspondences. Our RDMNet uses a devised 3D-RoFormer mechanism to first extract distinctive superpoints and generates reliable superpoints matches between two point clouds. The proposed 3D-RoFormer fuses 3D position information into the transformer network, efficiently exploiting point clouds' contextual and geometric information to generate robust superpoint correspondences. RDMNet then propagates the sparse superpoints matches to dense point matches using the neighborhood information for accurate point cloud registration. We extensively evaluate our method on multiple datasets from different environments. The experimental results demonstrate that our method outperforms existing state-of-the-art approaches in all tested datasets with a strong generalization ability.
Vision-Assisted mmWave Beam Management for Next-Generation Wireless Systems: Concepts, Solutions and Open Challenges
Mar 31, 2023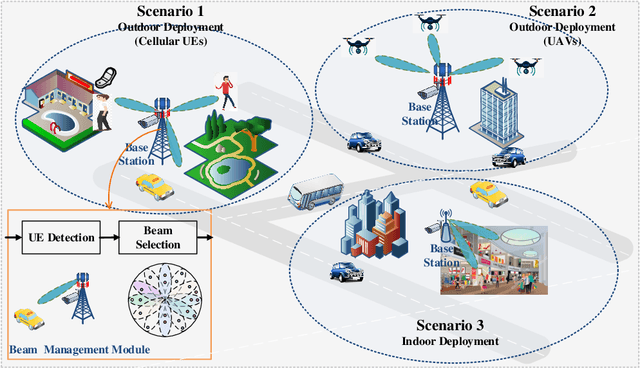
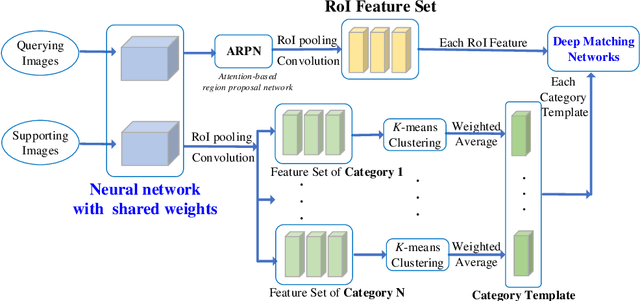
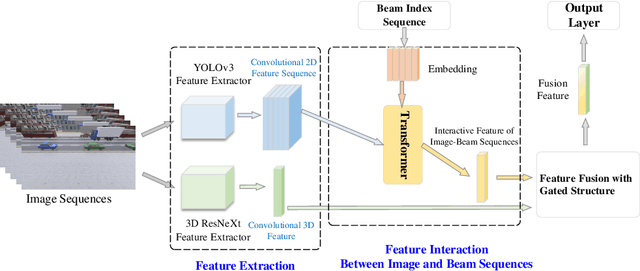
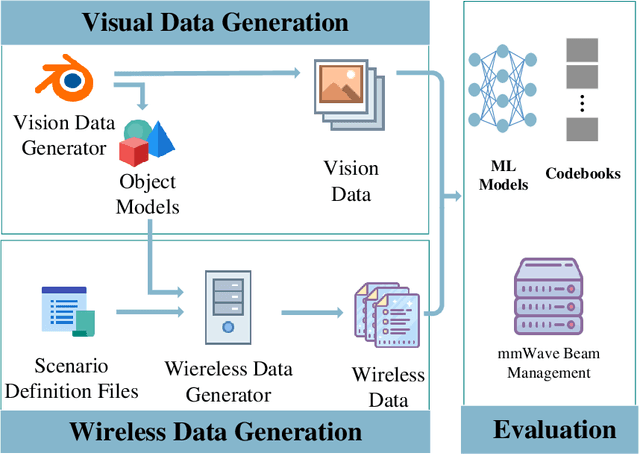
Beamforming techniques have been widely used in the millimeter wave (mmWave) bands to mitigate the path loss of mmWave radio links as the narrow straight beams by directionally concentrating the signal energy. However, traditional mmWave beam management algorithms usually require excessive channel state information overhead, leading to extremely high computational and communication costs. This hinders the widespread deployment of mmWave communications. By contrast, the revolutionary vision-assisted beam management system concept employed at base stations (BSs) can select the optimal beam for the target user equipment (UE) based on its location information determined by machine learning (ML) algorithms applied to visual data, without requiring channel information. In this paper, we present a comprehensive framework for a vision-assisted mmWave beam management system, its typical deployment scenarios as well as the specifics of the framework. Then, some of the challenges faced by this system and their efficient solutions are discussed from the perspective of ML. Next, a new simulation platform is conceived to provide both visual and wireless data for model validation and performance evaluation. Our simulation results indicate that the vision-assisted beam management is indeed attractive for next-generation wireless systems.