 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Apr 22, 2023
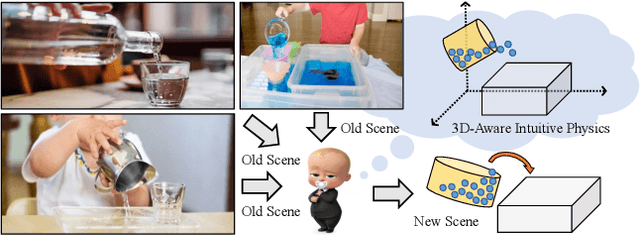
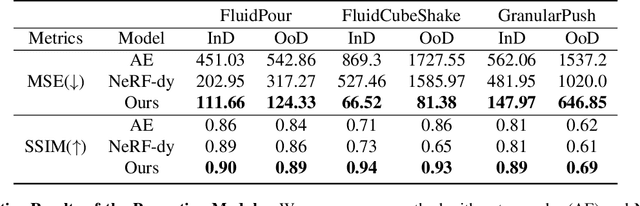
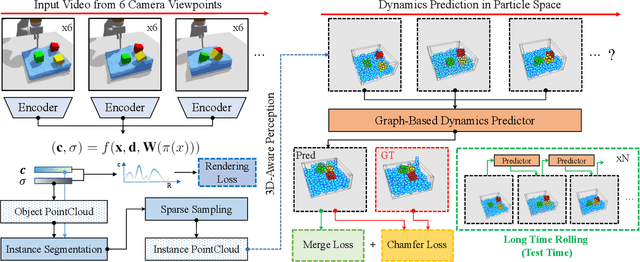
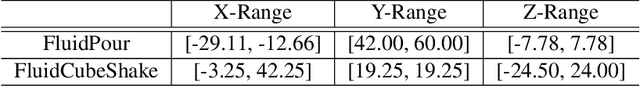
Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
Towards Carbon-Neutral Edge Computing: Greening Edge AI by Harnessing Spot and Future Carbon Markets
Apr 22, 2023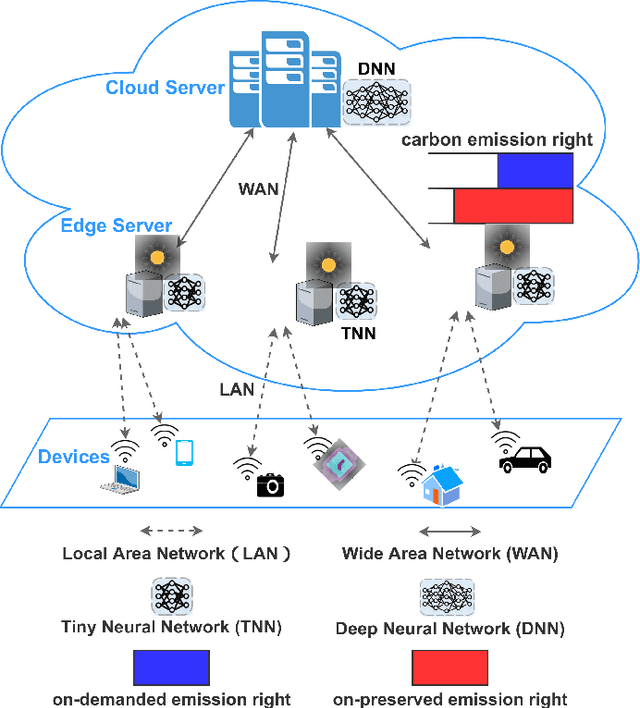
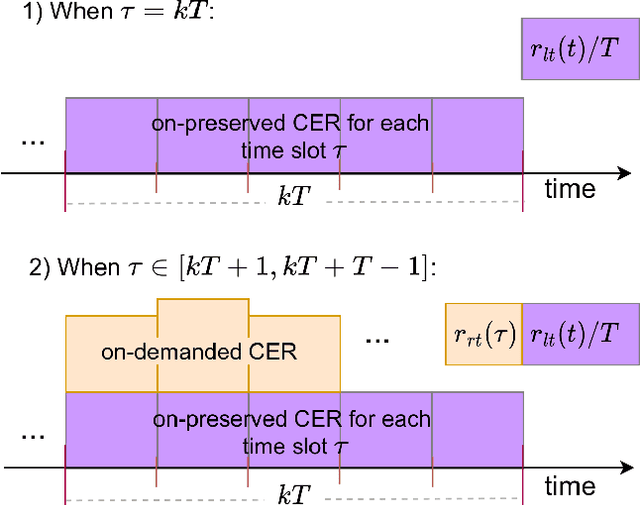
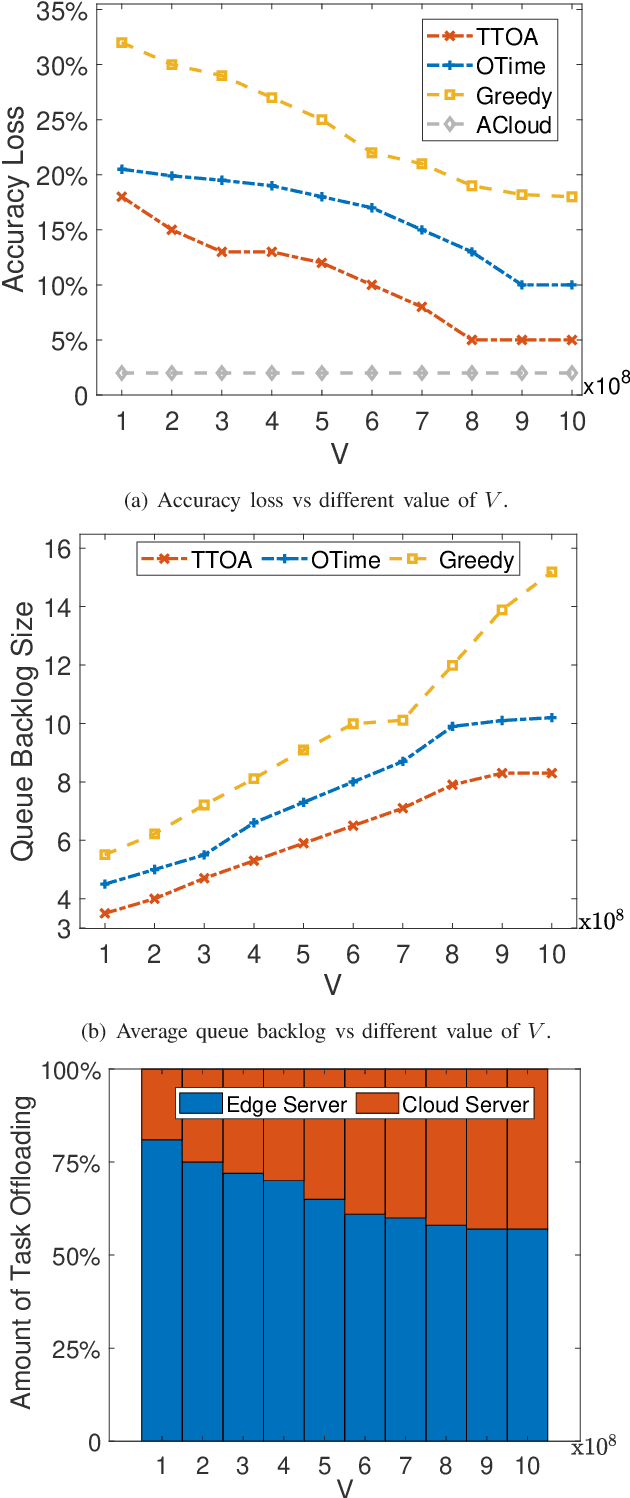
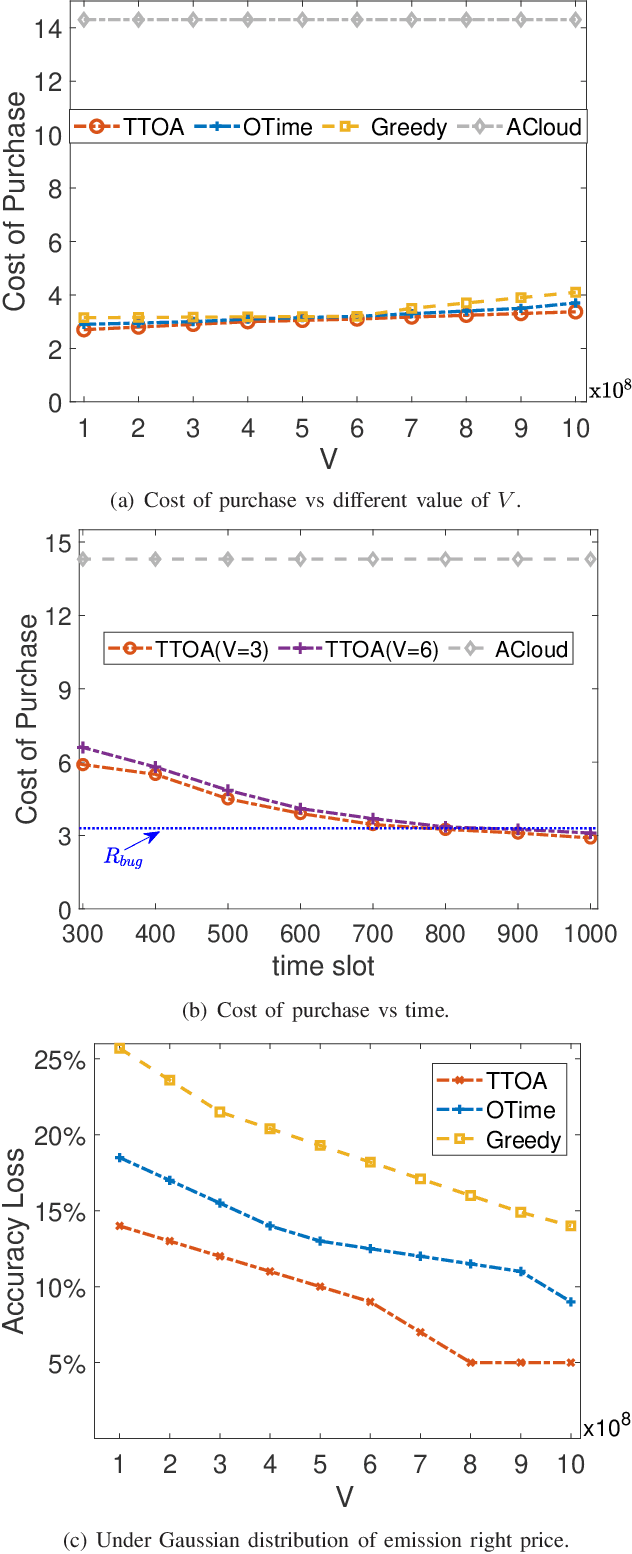
Provisioning dynamic machine learning (ML) inference as a service for artificial intelligence (AI) applications of edge devices faces many challenges, including the trade-off among accuracy loss, carbon emission, and unknown future costs. Besides, many governments are launching carbon emission rights (CER) for operators to reduce carbon emissions further to reverse climate change. Facing these challenges, to achieve carbon-aware ML task offloading under limited carbon emission rights thus to achieve green edge AI, we establish a joint ML task offloading and CER purchasing problem, intending to minimize the accuracy loss under the long-term time-averaged cost budget of purchasing the required CER. However, considering the uncertainty of the resource prices, the CER purchasing prices, the carbon intensity of sites, and ML tasks' arrivals, it is hard to decide the optimal policy online over a long-running period time. To overcome this difficulty, we leverage the two-timescale Lyapunov optimization technique, of which the $T$-slot drift-plus-penalty methodology inspires us to propose an online algorithm that purchases CER in multiple timescales (on-preserved in carbon future market and on-demanded in the carbon spot market) and makes decisions about where to offload ML tasks. Considering the NP-hardness of the $T$-slot problems, we further propose the resource-restricted randomized dependent rounding algorithm to help to gain the near-optimal solution with no help of any future information. Our theoretical analysis and extensive simulation results driven by the real carbon intensity trace show the superior performance of the proposed algorithms.
Silent Abandonment in Contact Centers: Estimating Customer Patience from Uncertain Data
Apr 23, 2023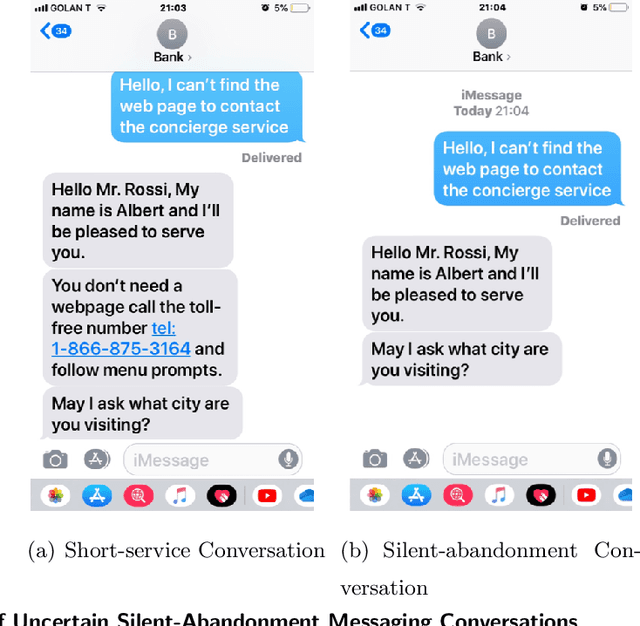
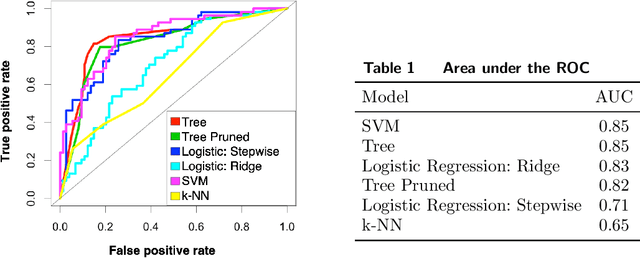

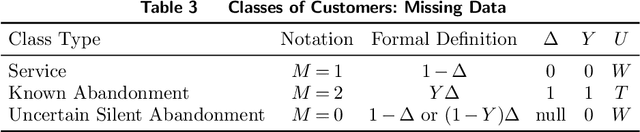
In the quest to improve services, companies offer customers the opportunity to interact with agents through contact centers, where the communication is mainly text-based. This has become one of the favorite channels of communication with companies in recent years. However, contact centers face operational challenges, since the measurement of common proxies for customer experience, such as knowledge of whether customers have abandoned the queue and their willingness to wait for service (patience), are subject to information uncertainty. We focus this research on the impact of a main source of such uncertainty: silent abandonment by customers. These customers leave the system while waiting for a reply to their inquiry, but give no indication of doing so, such as closing the mobile app of the interaction. As a result, the system is unaware that they have left and waste agent time and capacity until this fact is realized. In this paper, we show that 30%-67% of the abandoning customers abandon the system silently, and that such customer behavior reduces system efficiency by 5%-15%. To do so, we develop methodologies to identify silent-abandonment customers in two types of contact centers: chat and messaging systems. We first use text analysis and an SVM model to estimate the actual abandonment level. We then use a parametric estimator and develop an expectation-maximization algorithm to estimate customer patience accurately, as customer patience is an important parameter for fitting queueing models to the data. We show how accounting for silent abandonment in a queueing model improves dramatically the estimation accuracy of key measures of performance. Finally, we suggest strategies to operationally cope with the phenomenon of silent abandonment.
DeID-GPT: Zero-shot Medical Text De-Identification by GPT-4
Mar 20, 2023

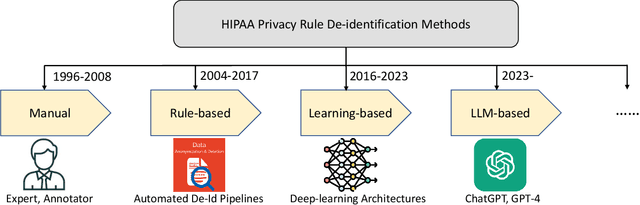
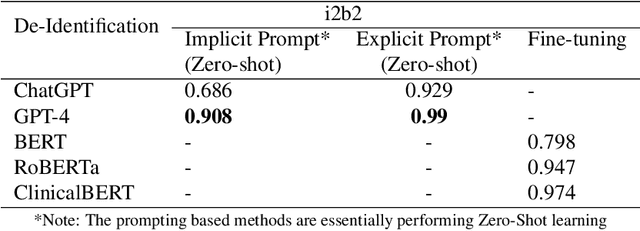
The digitization of healthcare has facilitated the sharing and re-using of medical data but has also raised concerns about confidentiality and privacy. HIPAA (Health Insurance Portability and Accountability Act) mandates removing re-identifying information before the dissemination of medical records. Thus, effective and efficient solutions for de-identifying medical data, especially those in free-text forms, are highly needed. While various computer-assisted de-identification methods, including both rule-based and learning-based, have been developed and used in prior practice, such solutions still lack generalizability or need to be fine-tuned according to different scenarios, significantly imposing restrictions in wider use. The advancement of large language models (LLM), such as ChatGPT and GPT-4, have shown great potential in processing text data in the medical domain with zero-shot in-context learning, especially in the task of privacy protection, as these models can identify confidential information by their powerful named entity recognition (NER) capability. In this work, we developed a novel GPT4-enabled de-identification framework ("DeID-GPT") to automatically identify and remove the identifying information. Compared to existing commonly used medical text data de-identification methods, our developed DeID-GPT showed the highest accuracy and remarkable reliability in masking private information from the unstructured medical text while preserving the original structure and meaning of the text. This study is one of the earliest to utilize ChatGPT and GPT-4 for medical text data processing and de-identification, which provides insights for further research and solution development on the use of LLMs such as ChatGPT/GPT-4 in healthcare. Codes and benchmarking data information are available at https://github.com/yhydhx/ChatGPT-API.
CLIP-Lung: Textual Knowledge-Guided Lung Nodule Malignancy Prediction
Apr 17, 2023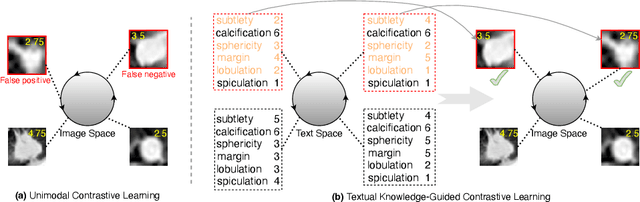
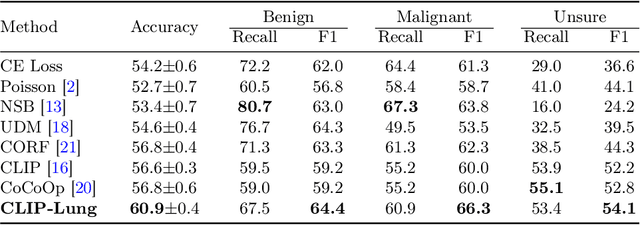


Lung nodule malignancy prediction has been enhanced by advanced deep-learning techniques and effective tricks. Nevertheless, current methods are mainly trained with cross-entropy loss using one-hot categorical labels, which results in difficulty in distinguishing those nodules with closer progression labels. Interestingly, we observe that clinical text information annotated by radiologists provides us with discriminative knowledge to identify challenging samples. Drawing on the capability of the contrastive language-image pre-training (CLIP) model to learn generalized visual representations from text annotations, in this paper, we propose CLIP-Lung, a textual knowledge-guided framework for lung nodule malignancy prediction. First, CLIP-Lung introduces both class and attribute annotations into the training of the lung nodule classifier without any additional overheads in inference. Second, we designed a channel-wise conditional prompt (CCP) module to establish consistent relationships between learnable context prompts and specific feature maps. Third, we align image features with both class and attribute features via contrastive learning, rectifying false positives and false negatives in latent space. The experimental results on the benchmark LIDC-IDRI dataset have demonstrated the superiority of CLIP-Lung, both in classification performance and interpretability of attention maps.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
Apr 17, 2023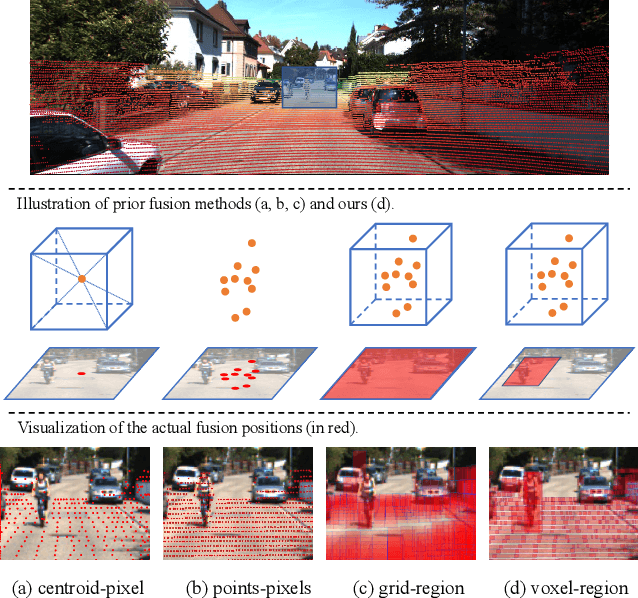
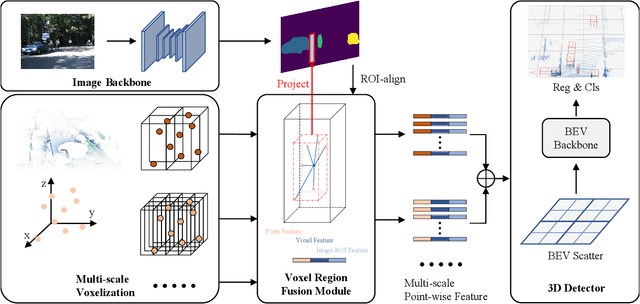
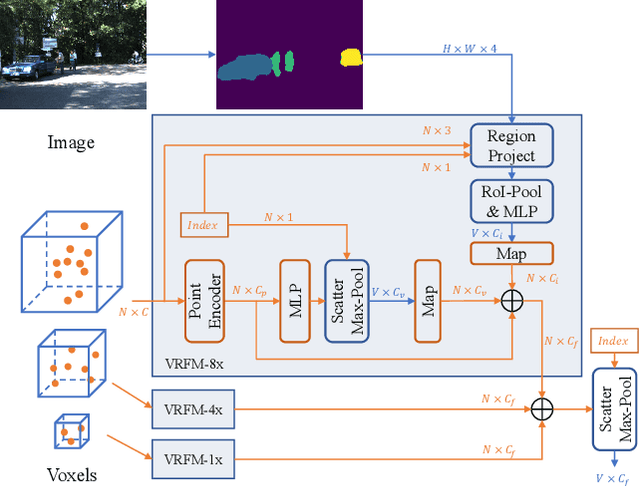

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
Cross or Wait? Predicting Pedestrian Interaction Outcomes at Unsignalized Crossings
Apr 17, 2023

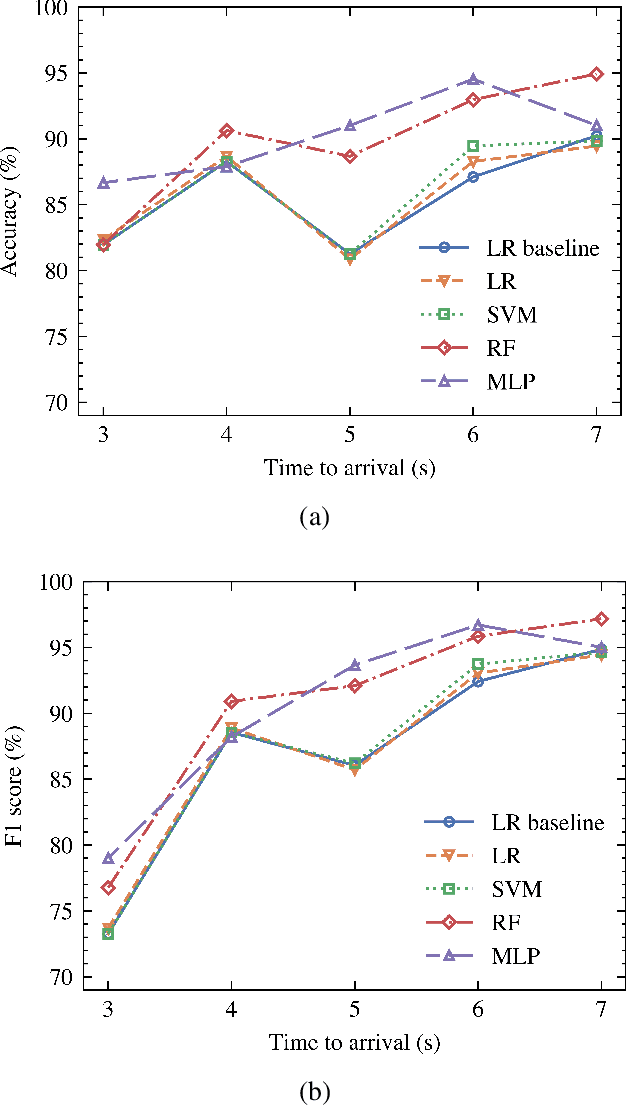
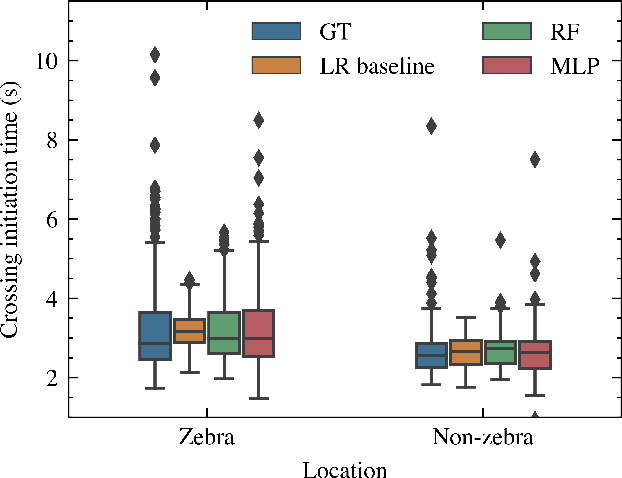
Predicting pedestrian behavior when interacting with vehicles is one of the most critical challenges in the field of automated driving. Pedestrian crossing behavior is influenced by various interaction factors, including time to arrival, pedestrian waiting time, the presence of zebra crossing, and the properties and personality traits of both pedestrians and drivers. However, these factors have not been fully explored for use in predicting interaction outcomes. In this paper, we use machine learning to predict pedestrian crossing behavior including pedestrian crossing decision, crossing initiation time (CIT), and crossing duration (CD) when interacting with vehicles at unsignalized crossings. Distributed simulator data are utilized for predicting and analyzing the interaction factors. Compared with the logistic regression baseline model, our proposed neural network model improves the prediction accuracy and F1 score by 4.46% and 3.23%, respectively. Our model also reduces the root mean squared error (RMSE) for CIT and CD by 21.56% and 30.14% compared with the linear regression model. Additionally, we have analyzed the importance of interaction factors, and present the results of models using fewer factors. This provides information for model selection in different scenarios with limited input features.
Balancing Unobserved Confounding with a Few Unbiased Ratings in Debiased Recommendations
Apr 17, 2023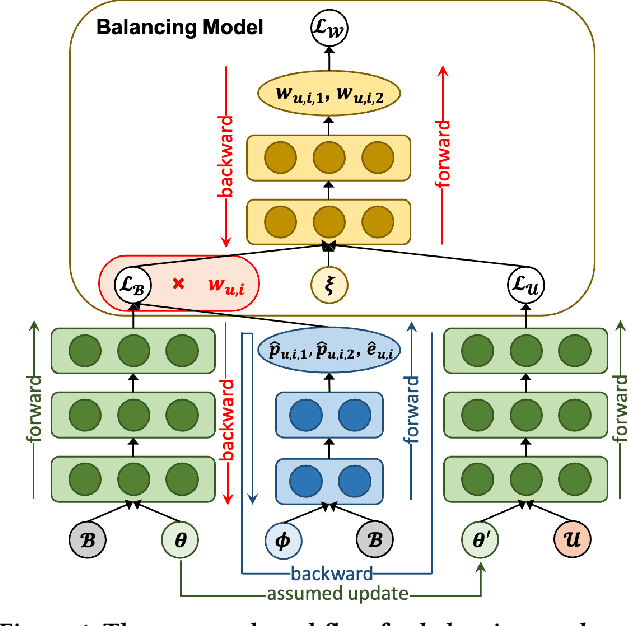
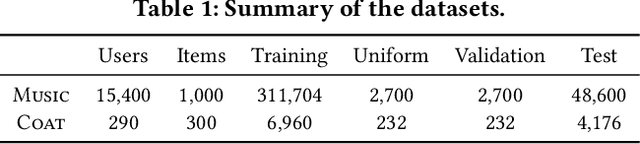
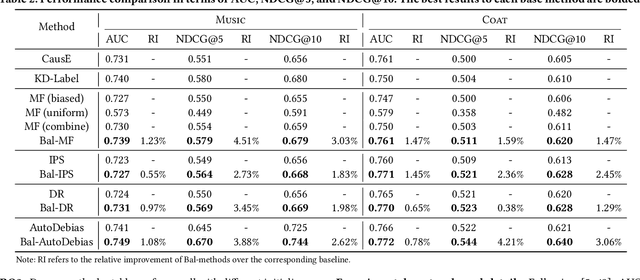
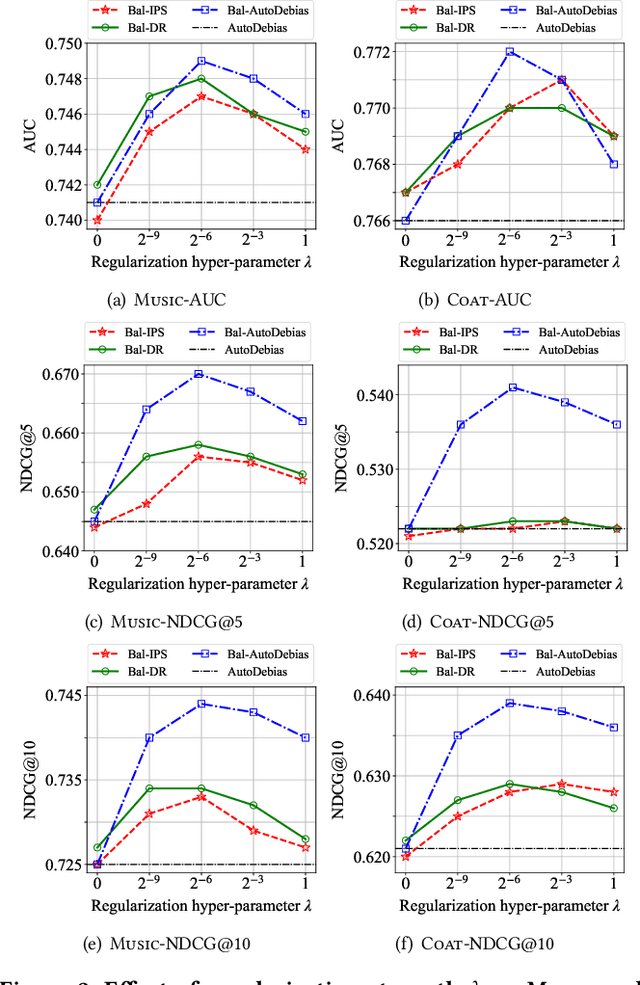
Recommender systems are seen as an effective tool to address information overload, but it is widely known that the presence of various biases makes direct training on large-scale observational data result in sub-optimal prediction performance. In contrast, unbiased ratings obtained from randomized controlled trials or A/B tests are considered to be the golden standard, but are costly and small in scale in reality. To exploit both types of data, recent works proposed to use unbiased ratings to correct the parameters of the propensity or imputation models trained on the biased dataset. However, the existing methods fail to obtain accurate predictions in the presence of unobserved confounding or model misspecification. In this paper, we propose a theoretically guaranteed model-agnostic balancing approach that can be applied to any existing debiasing method with the aim of combating unobserved confounding and model misspecification. The proposed approach makes full use of unbiased data by alternatively correcting model parameters learned with biased data, and adaptively learning balance coefficients of biased samples for further debiasing. Extensive real-world experiments are conducted along with the deployment of our proposal on four representative debiasing methods to demonstrate the effectiveness.
* Accepted Paper in WWW'23
Leveraging Foundation Models for Clinical Text Analysis
Mar 20, 2023
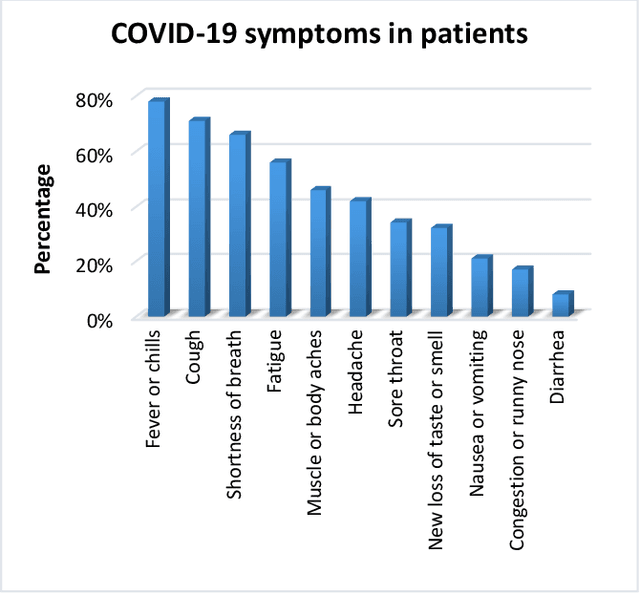
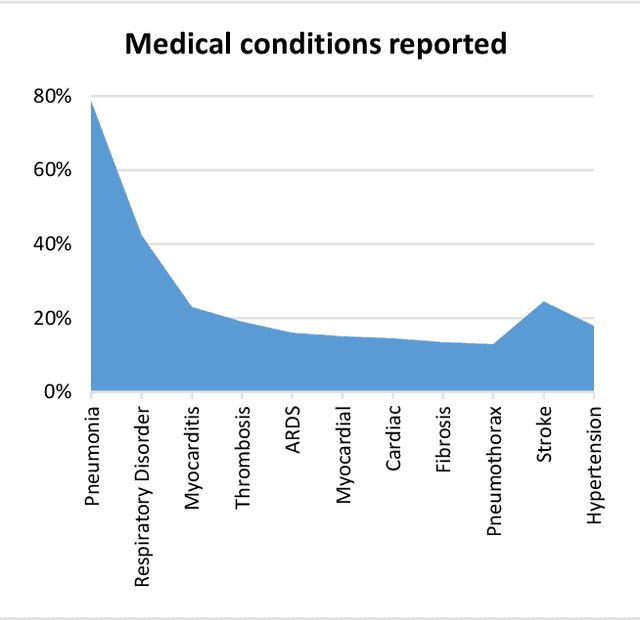
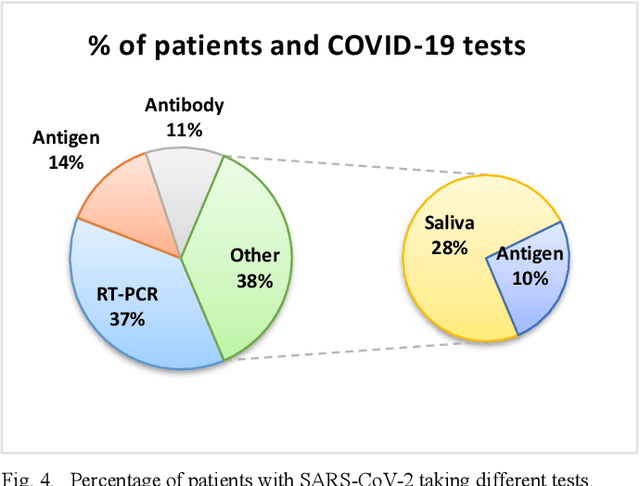
Infectious diseases are a significant public health concern globally, and extracting relevant information from scientific literature can facilitate the development of effective prevention and treatment strategies. However, the large amount of clinical data available presents a challenge for information extraction. To address this challenge, this study proposes a natural language processing (NLP) framework that uses a pre-trained transformer model fine-tuned on task-specific data to extract key information related to infectious diseases from free-text clinical data. The proposed framework includes three components: a data layer for preparing datasets from clinical texts, a foundation model layer for entity extraction, and an assessment layer for performance analysis. The results of the evaluation indicate that the proposed method outperforms standard methods, and leveraging prior knowledge through the pre-trained transformer model makes it useful for investigating other infectious diseases in the future.
Active View Planning for Visual SLAM in Outdoor Environments Based on Continuous Information Modeling
Nov 12, 2022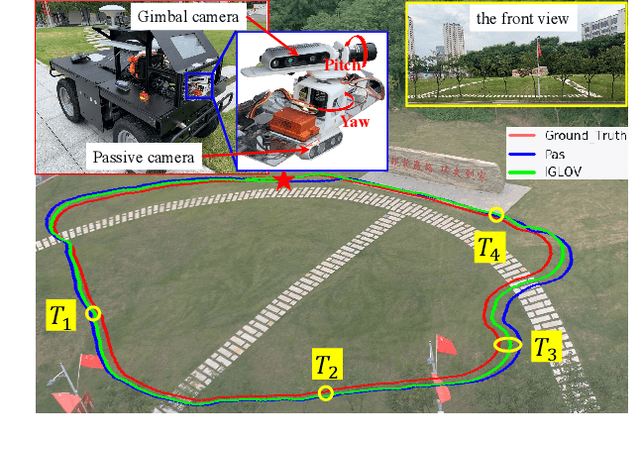
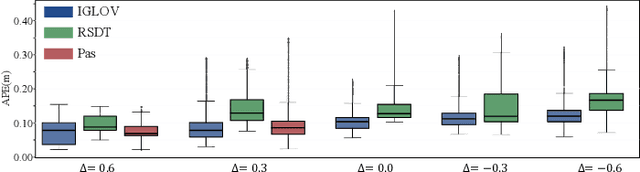
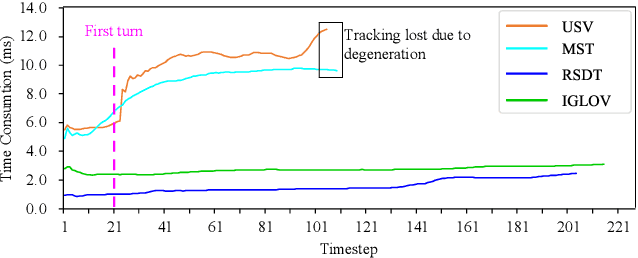
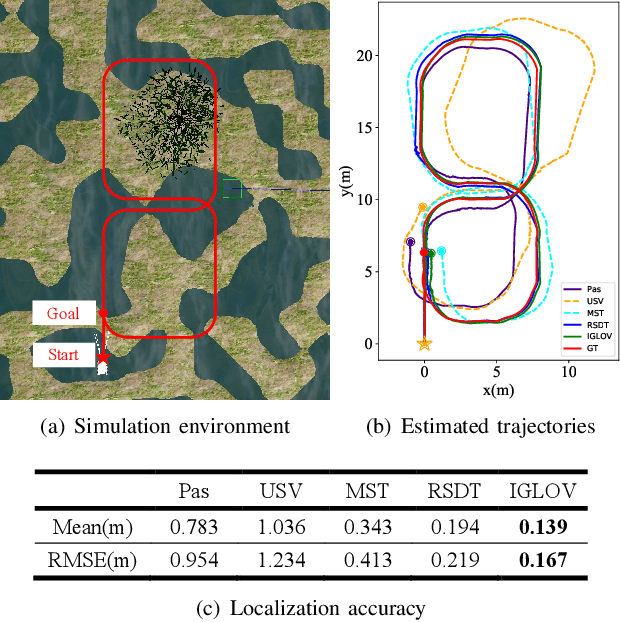
The visual simultaneous localization and mapping(vSLAM) is widely used in GPS-denied and open field environments for ground and surface robots. However, due to the frequent perception failures derived from lacking visual texture or the {swing} of robot view direction on rough terrains, the accuracy and robustness of vSLAM are still to be enhanced. The study develops a novel view planning approach of actively perceiving areas with maximal information to address the mentioned problem; a gimbal camera is used as the main sensor. Firstly, a map representation based on feature distribution-weighted Fisher information is proposed to completely and effectively represent environmental information richness. With the map representation, a continuous environmental information model is further established to convert the discrete information space into a continuous one for numerical optimization in real-time. Subsequently, the receding horizon optimization is utilized to obtain the optimal informative viewpoints with simultaneously considering the robotic perception, exploration and motion cost based on the continuous environmental model. Finally, several simulations and outdoor experiments are performed to verify the improvement of localization robustness and accuracy by the proposed approach.